Введение в разработку CatBoost. Доклад Яндекса
Меня зовут Стас Кириллов, я ведущий разработчик в группе ML-платформ в Яндексе. Мы занимаемся разработкой инструментов машинного обучения, поддержкой и развитием инфраструктуры для них. Ниже — мой недавний доклад о том, как устроена библиотека CatBoost. В докладе я рассказал о входных точках и особенностях кода для тех, кто хочет его понять или стать нашим контрибьютором.
— CatBoost у нас живет на GitHub под лицензией Apache 2.0, то есть открыт и бесплатен для всех. Проект активно развивается, сейчас у нашего репозитория больше четырех тысяч звездочек. CatBoost написан на C++, это библиотека для градиентного бустинга на деревьях решений. В ней поддержано несколько видов деревьев, в том числе так называемые «симметричные» деревья, которые используются в библиотеке по умолчанию.
В чем профит наших oblivious-деревьев? Они быстро учатся, быстро применяются и помогают обучению быть более устойчивым к изменению параметров с точки зрения изменений итогового качества модели, что сильно уменьшает необходимость в подборе параметров. Наша библиотека — про то, чтобы было удобно использовать в продакшене, быстро учиться и сразу получать хорошее качество.

Градиентный бустинг — это алгоритм, в котором мы строим простые предсказатели, которые улучшают нашу целевую функцию. То есть вместо того, чтобы сразу строить сложную модель, мы строим много маленьких моделей по очереди.

Как происходит процесс обучения в CatBoost? Расскажу, как это устроено с точки зрения кода. Сначала мы парсим параметры обучения, которые передает пользователь, валидируем их и дальше смотрим, нужно ли нам загружать данные. Потому что данные уже могут быть загружены — например, в Python или R. Далее мы загружаем данные и строим сетку из бордеров с целью квантизовать численные фичи. Это нужно, чтобы делать обучение быстрым.
Категориальные фичи мы процессим немножечко по-другому. Категориальные фичи мы в самом начале хэшируем, а потом перенумеровываем хэши от нуля до количества уникальных значений категориальной фичи, чтобы быстро считать комбинации категориальных фич.
Дальше мы запускаем непосредственно training loop — главный цикл нашего машинного обучения, где мы итеративно строим деревья. После этого цикла происходит экспорт модели.
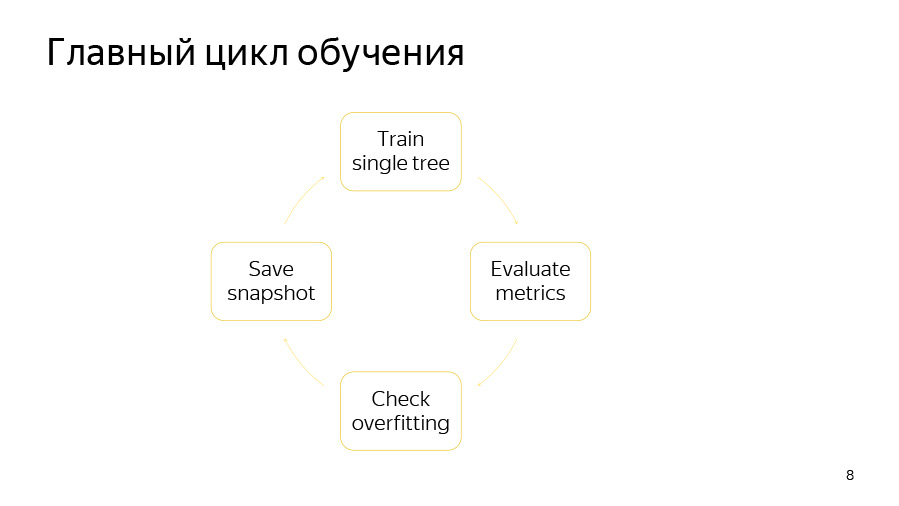
Сам цикл обучения состоит из четырех пунктов. Первый — мы пытаемся построить одно дерево. Дальше смотрим, какой прирост или убыль качества оно дает. Потом проверяем, не сработал ли наш детектор переобучения. Далее мы, если пришло время, сохраняем снэпшот.

Обучение одного дерева — это цикл по уровням дерева. В самом начале мы случайным образом выбираем перестановку данных, если у нас используется ordered boosting или имеются категориальные фичи. Затем мы подсчитываем на этой перестановке счетчики. Дальше мы пытаемся жадным образом подобрать хорошие сплиты в этом дереве. Под сплитами мы понимаем просто некие бинарные условия: такая-то числовая фича больше такого-то значения, либо такой-то счетчик по категориальной фиче больше такого-то значения.
Как устроен цикл жадного подбора уровней дерева? В самом начале делается бутстрап — мы перевзвешиваем либо сэмплируем объекты, после чего только выбранные объекты будут использоваться для построения дерева. Бутстрап также может пересчитываться перед выбором каждого сплита, если включена опция сэмплирования на каждом уровне.
Дальше мы агрегируем производные в гистограммки, так мы делаем для каждого сплит-кандидата. С помощью гистограмм мы пытаемся оценить изменение целевой функции, которое произойдет, если мы выберем этого сплит-кандидата.
Мы выбираем кандидата с лучшими скором и добавляем его в дерево. Потом мы подсчитываем статистики с использованием этого подобранного дерева на оставшихся перестановках, обновляем значение в листьях на этих перестановках, считаем значения в листьях для модели и переходим к следующей итерации цикла.

Очень сложно выделить какое-то одно место, в котором происходит обучение, так что на этом слайде — его можно использовать как некоторую точку входа — перечислены основные файлы, которые у нас применяются для обучения. Это greedy_tensor_search, в котором у нас живет сама процедура жадного подбора сплитов. Это train.cpp, где у нас находится главная фабрика CPU-обучения. Это aprox_calcer, где лежат функции обновления значений в листьях. А также score_calcer — функция оценки какого-то кандидата.
Не менее важные части — catboost.pyx и core.py. Это код питоновской обертки, скорее всего, многие из вас будут внедрять какие-то вещи в питоновскую обертку. Наша питоновская обертка написана на Cython, Cython транслируется в C++, так что этот код должен быть быстрым.
Наша R-обертка лежит в папке R-package. Возможно, кому-то придется добавлять или исправлять какие-то опции, для опций у нас есть отдельная библиотека — catboost/libs/options.
Мы пришли из Arcadia в GitHub, поэтому у нас есть много интересных артефактов, с которыми вам придется столкнуться.


Начнем со структуры репозитория. У нас есть папка util, где лежат базовые примитивы: вектора, мапы, файловые системы, работа со строками, потоки.
У нас есть library, где лежат библиотеки общего пользования, которыми пользуются в Яндексе, — многие, не только CatBoost.
Папка CatBoost и contrib — это код сторонних библиотек, с которыми мы линкуемся.
Давайте теперь поговорим про примитивы C++, с которыми вам придется столкнуться. Первое — умные указатели. В Яндексе у нас со времен std: unique_ptr используется THolder, а вместо std: make_unique используется MakeHolder.

У нас есть свой SharedPtr. Причем он существует в двух ипостасях, SimpleSharedPtr и AtomicSharedPtr, которые отличаются типом счетчика. В одном случае он атомарный, это значит, что объектом могут владеть как будто бы несколько потоков. Так будет безопасно с точки зрения передачи между потоками.
Отдельный класс IntrusivePtr позволяет владеть объектами, унаследованными от класса TRefCounted, то есть классами, у которых внутри встроен счетчик ссылок. Это чтобы аллоцировать такие объекты за один раз, не аллоцируя дополнительно контрольный блок со счетчиком.
Также у нас своя система для ввода и вывода. IInputStream и IOutputStream — это интерфейсы для ввода и вывода. У них есть полезные методы, такие как ReadTo, ReadLine, ReadAll, в общем, всё, что можно ожидать от InputStreams. И у нас есть реализации этих стримов для работы с консолью: Cin, Cout, Cerr и отдельно Endl, который похож на std: endl, то есть он флашит поток.

Еще у нас есть свои реализации интерфейсов для файлов: TInputFile, TOutputFile. Это буферизованное чтение. Они реализуют буферизованное чтение и буферизованную запись в файл, поэтому можно ими пользоваться.
У util/system/fs.h есть методы NFs: Exists и NFs: Copy, если вдруг вам что-то понадобится скопировать или проверить, что какой-то файл действительно существует.

У нас свои контейнеры. Они довольно давно переехали на использование std: vector, то есть они просто наследуются от std: vector, std: set и std: map, но у нас есть и свои THashMap и THashSet, у которых отчасти интерфейсы совместимы с unordered_map и unordered_set. Но для некоторых задач они оказались быстрее, поэтому они у нас до сих пор используются.

Ссылки на массивы — аналог std: span из C++. Правда, появился он у нас не в двадцатом году, а сильно раньше. Мы его активно используем, чтобы передавать ссылки на массивы, как будто бы аллоцированные на больших буферах, чтобы не аллоцировать временные буферы каждый раз. Допустим, для подсчета производных или каких-то аппроксов мы можем выделять память на каком-то предаллоцированном большом буфере и передавать функцию подсчета только TArrayRef. Это очень удобно, и мы много где это используем.

В Arcadia применяется свой набор классов для работы со строками. Это, во-первых, TStingBuf — аналог str: string_view из C++17.
TString — совсем не std: sting, это CopyOnWrite-строка, поэтому нужно с ней работать довольно аккуратно. Кроме того, TUtf16String — такая же TString, только у нее базовый тип — не char, а 16-битный wchar.
И у нас есть инструменты для преобразованиия из строк и в строку. Это ToString, который является аналогом std: to_string и FromString в паре с TryFromString, которые позволяют превратить строку в необходимый вам тип.

У нас есть своя структура исключений, базовым исключением в аркадийных библиотеках является yexception, который наследуется от std: exception. У нас есть макрос ythrow, который добавляет информацию о месте, откуда бросилось исключение в yexception, это просто удобная обертка.
Есть свой аналог std: current_exception — CurrentExceptionMessage, эта функция выводит текущее исключение в виде строки.
Есть свои макросы для asserts и verifies — это Y_ASSERT и Y_VERIFY.

И у нас есть своя встроенная сериализация, она бинарная и не предназначена для того, чтобы передавать данные между разными ревизиями. Скорее эта сериализация нужна для того, чтобы передавать данные между двумя бинарниками одинаковой ревизии, например, при распределенном обучении.
Так получилось, что у нас в CatBoost используются две версии сериализации. Первый вариант работает через интерфейсные методы Save и Load, которые сериализуют в поток. Другой вариант используется в нашем распределенном обучении, там применяется довольно старая внутренняя библиотека BinSaver, удобная для сериализации полиморфных объектов, которые должны быть зарегистрированы в специальной фабрике. Это нужно для распределенного обучения, про которое мы здесь в силу недостатка времени вряд ли успеем рассказать.

Также у нас есть свой аналог boost_optional или std: optional — TMaybe. Аналог std: variant — TVariant. Нужно пользоваться ими.

Есть и некое соглашение, что внутри CatBoost-кода мы вместо yexception бросаем TCatBoostException. Это тот же самый yexception, только в нем всегда при бросании добавляется stack trace.
И еще мы используем макрос CB_ENSURE, чтобы удобно проверять какие-то вещи и бросать исключения, если они не выполняются. Например, мы это часто используем для парсинга опций или парсинга переданных пользователем параметров.

Ссылки со слайда: первая, вторая
Обязательно перед началом работы рекомендуем ознакомиться с code style, он состоит из двух частей. Первая — общеаркадийный code style, который лежит прямо в корне репозитория в файле CPP_STYLE_GUIDE.md. Также в корне репозитория лежит отдельный гайд для нашей команды: catboost_command_style_guide_extension.md.
Python-код мы стараемся оформлять по PEP8. Не всегда получается, потому что для Cython кода у нас не работает линтер, и иногда там что-то разъезжается с PEP8.

Каковы особенности нашей сборки? Аркадийная сборка изначально была нацелена на то, чтобы собирать максимально герметичные приложения, то есть чтобы был минимум внешних зависимостей за счет статической линковки. Это позволяет использовать один и тот же бинарник на разных версиях Linux без рекомпиляции, что довольно удобно. Цели сборки описываются в ya.make-файлах. Пример ya.make можно посмотреть на следующем слайде.

Если вдруг вам захочется добавить какую-то библиотеку, программу или еще что-то, можно, во-первых, просто посмотреть в соседних ya.make-файлах, а во-вторых, воспользоваться этим примером. Здесь у нас перечислены самые важные элементы ya.make. В самом начале файла мы говорим о том, что хотим объявить библиотеку, дальше перечисляем единицы компиляции, которые хотим в эту библиотеку поместить. Здесь могут быть как cpp-файлы, так и, например, pyx-файлы, для которых автоматически запустится Cython, а потом компилятор. Зависимости библиотеки перечисляются через макрос PEERDIR. Здесь просто пишутся пути до папки с library либо с другим артефактом внутри, относительно корня репозитория.
Есть полезная штука, GENERATE_ENUM_SERIALIZATION, необходимая для того, чтобы сгенерировать ToString, FromString методы для enum classes и enums, описанных в каком-то заголовочном файле, который вы передаете в этот макрос.

Теперь о самом важном — как скомпилировать и запустить какой-нибудь тест. В корне репозитория лежит скрипт ya, который загружает необходимые toolkits и инструменты, и у него есть команда ya make — подкоманда make, — которая позволяет собрать с ключиком -r релиз, с ключиком -d дебаг-версию. Артефакты в ней передаются далее и разделяются через пробел.
Для сборки Python я здесь сразу же указал флаги, которые могут быть полезны. Речь идет про сборку с системным Python, в данном случае с Python 3. Если вдруг на вашем ноутбуке или разработческой машине есть установленный CUDA Toolkit, то для более быстрой сборки рекомендуем указывать флаг –d have_cuda no. CUDA собирается довольно долго, особенно на 4-ядерных системах.

Еще уже должна работать ya ide. Это инструмент, который сгенерирует для вас clion либо qt solution. И для тех, кто пришел с Windows, у нас есть Microsoft Visual Studio solution, который лежит в папке msvs.
Слушатель:
— А у вас все тесты через Python-обертку?
Стас:
— Нет, у нас отдельно есть тесты, которые лежат в папке pytest. Это тесты нашего CLI-интерфейса, то есть нашего приложения. Правда, они работают через pytest, то есть это Python-функции, в которых мы делаем subprocess check call и проверяем то, что программа не падает и правильно работает при каких-то параметрах.
Слушатель:
— А юнит-тесты на C++?
Стас:
— Юнит-тесты на C++ у нас тоже есть. Они обычно лежат в папке lib в подпапках ut. И они так и пишутся — unit test либо unit test for. Там есть примеры. Есть специальные макросы для того, чтобы объявить класс с юнит-тестами, и отдельные регистры для функции юнит-тестов.
Слушатель:
— Для проверки того, что ничего не сломалось, лучше запускать и те, и те?
Стас:
— Да. Единственное, наши тесты в опенсорсе зеленые только на Linux. Поэтому если вы компилируетесь, например, под Mac, если там пять тестов будет падать — ничего страшного. Из-за разной реализации экспоненты на разных платформах или еще каких-то мелких различий результаты могут сильно разъезжаться.

Для примера возьмем задачку. Хочется показать какой-то пример. У нас есть файлик с задачками — open_problems.md. Решим задачку №4 из open_problems.md. Она формулируется так: если пользователь задал learning rate нулевым, то мы должны падать с TCatBoostException. Нужно добавить валидацию опций.
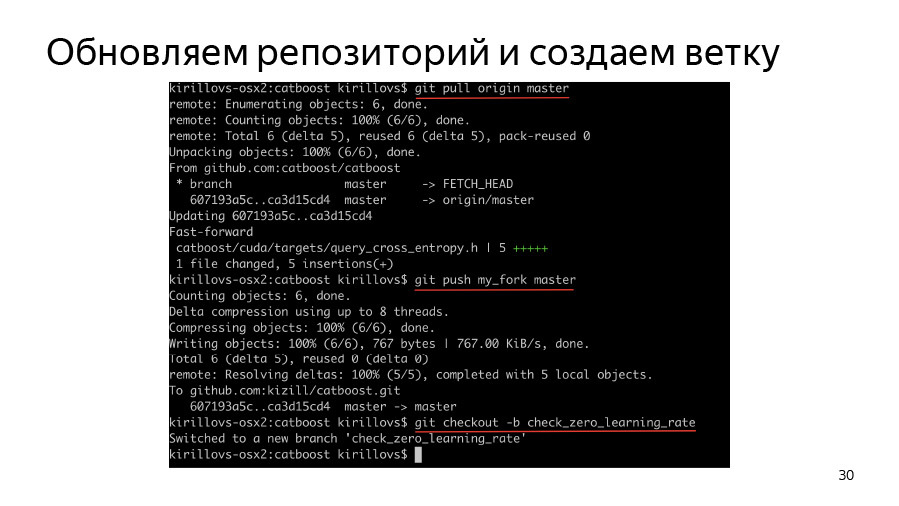
Для начала мы должны создать веточку, склонировать себе свой fork, склонировать origin, запулить origin, запушить origin в свой fork и дальше создать веточку и начать в ней работать.
Как вообще происходит парсинг опций? Как я уже сказал, у нас есть важная папка catboost/libs/options, где хранится парсинг всех опций.

У нас все опции хранятся в обертке TOption, которая позволяет понять, была ли опция переопределена пользователем. Если не была — она хранит в себе какое-то дефолтное значение. Вообще, CatBoost парсит все опции в виде большого JSON-словаря, который в процессе парсинга превращается во вложенные словари и вложенные структуры.

Мы каким-то образом узнали — например, поискав грепом или прочитав код, — что learning rate у нас находится в TBoostingOptions. Попробуем написать код, который просто добавляет CB_ENSURE, что наш learning rate больше чем std: numeric_limits: epsilon, что пользователь ввел нечто более-менее разумное.

Мы здесь как раз воспользовались макросом CB_ENSURE, написали какой-то код и теперь хотим добавить тесты.

В данном случае мы добавляем тест на Command Line Interface. В папке pytest у нас лежит скрипт test.py, где уже есть довольно много примеров тестов и можно просто подобрать похожий на вашу задачу, скопировать его и поменять параметры так, чтобы он начал падать либо не падать — в зависимости от переданных вами параметров. В данном случае мы просто берем и создаем простой пул из двух строчек. (Пулами мы в Яндексе называем датасет. Такая у нас особенность.) И дальше проверяем то, что наш бинарник правда падает, если передать learning rate 0.0.

Также мы добавляем в python-package тест, который находится в сatBoost/python-package/ut/medium. У нас есть еще large, большие тесты, которые связаны с тестами на сборку python wheel-пакетов.

Дальше у нас есть ключики для ya make — -t и -A. -t запускает тесты, -A заставляет запускать все тесты вне зависимости от того, какие у них теги: large или medium.
Здесь я для красоты также использовал фильтр по имени теста. Он задается с помощью опции -F и указанного дальше имени теста, которым могут быть wild char-звездочки. В данном случае я использовал test.py: test_zero_learning_rate*, потому что, посмотрев на наши тесты python-package, вы увидите: почти все функции принимают внутрь себя фикстуру task type. Это чтобы по коду наши тесты python-package выглядели одинаково и для CPU-, и для GPU-обучения и могли использоваться для тестов GPU и CPU trainer.

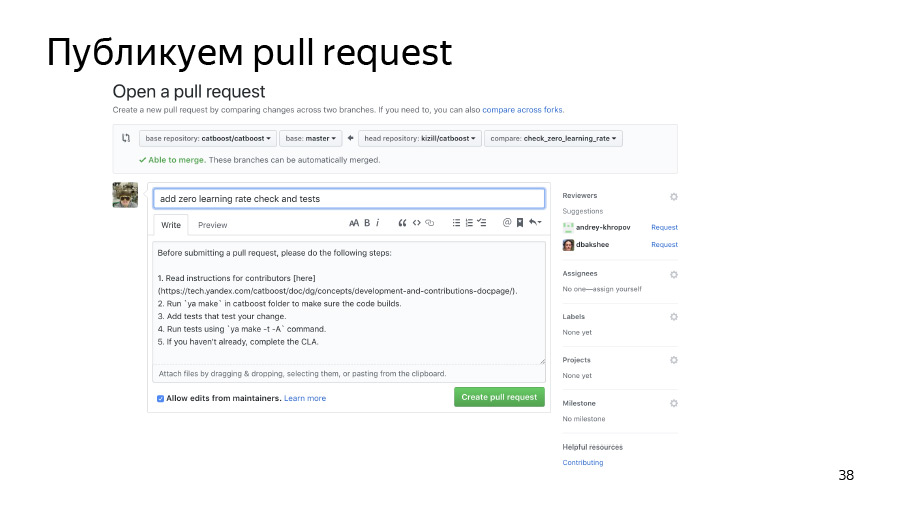
Дальше коммитим наши изменения и пушим их в наш форкнутый репозиторий. Публикуем пул-реквест. Он уже влился, всё хорошо.
