[Перевод] Как разрабатываются и производятся процессоры: будущее компьютерных архитектур

Несмотря на постоянные усовершенствования и постепенный прогресс в каждом новом поколении, в индустрии процессоров уже долгое время не происходит фундаментальных изменений. Огромным шагом вперёд стал переход от вакуума к транзисторам, а также переход от отдельных компонентов к интегральным схемам. Однако после них серьёзных сдвигов парадигмы такого же масштаба не происходило.
Да, транзисторы стали меньше, чипы — быстрее, а производительность повысилась в сотни раз, но мы начинаем наблюдать стагнацию…
Это четвёртая и последняя часть серии статей о разработке ЦП, рассказывающей о проектировании и изготовлении процессоров. Начав с высокого уровня, мы узнали о том, как компьютерный код компилируется в язык ассемблера, а затем в двоичные инструкции, которые интерпретирует ЦП. Мы обсудили то, как проектируется архитектура процессоров и они обрабатывают инструкции. Затем мы рассмотрели различные структуры, из которых составлен процессор.
Немного углубившись в эту тему, мы увидели, как создаются эти структуры, и как внутри процессора совместно работают миллиарды транзисторов. Мы рассмотрели процесс физического изготовления процессоров из необработанного кремния. Узнали о свойствах полупроводников и о том, как выглядят внутренности чипа. Если вы пропустили какую-то из тем, то вот список статей серии:
Часть 1: Основы архитектуры компьютеров (архитектуры наборов команд, кэширование, конвейеры, hyperthreading)
Часть 2: Процесс проектирования ЦП (электрические схемы, транзисторы, логические элементы, синхронизация)
Часть 3: Компонование и физическое производство чипа (VLSI и изготовление кремния)
Часть 4: Современные тенденции и важные будущие направления в архитектуре компьютеров (море ускорителей, трёхмерное интегрирование, FPGA, Near Memory Computing)
Перейдём к четвёртой части. Компании-разработчики не делятся с общественностью своими исследованиями или подробностями современных технологий, поэтому нам сложно чётко представить, что именно находится внутри ЦП компьютера. Однако мы можем взглянуть на современные исследования и узнать, в каком направлении движется отрасль.
Одним из знаменитых образов индустрии процессоров является закон Мура. Он гласит, что количество транзисторов в чипе удваивается каждые 18 месяцев. Долгое время это эмпирическое правило было справедливым, но рост начинает замедляться. Транзисторы становятся такими крошечными, что мы начинаем приближаться к пределу физически достижимых размеров. Без революционной новой технологии нам придётся в будущем исследовать другие возможности роста производительности.
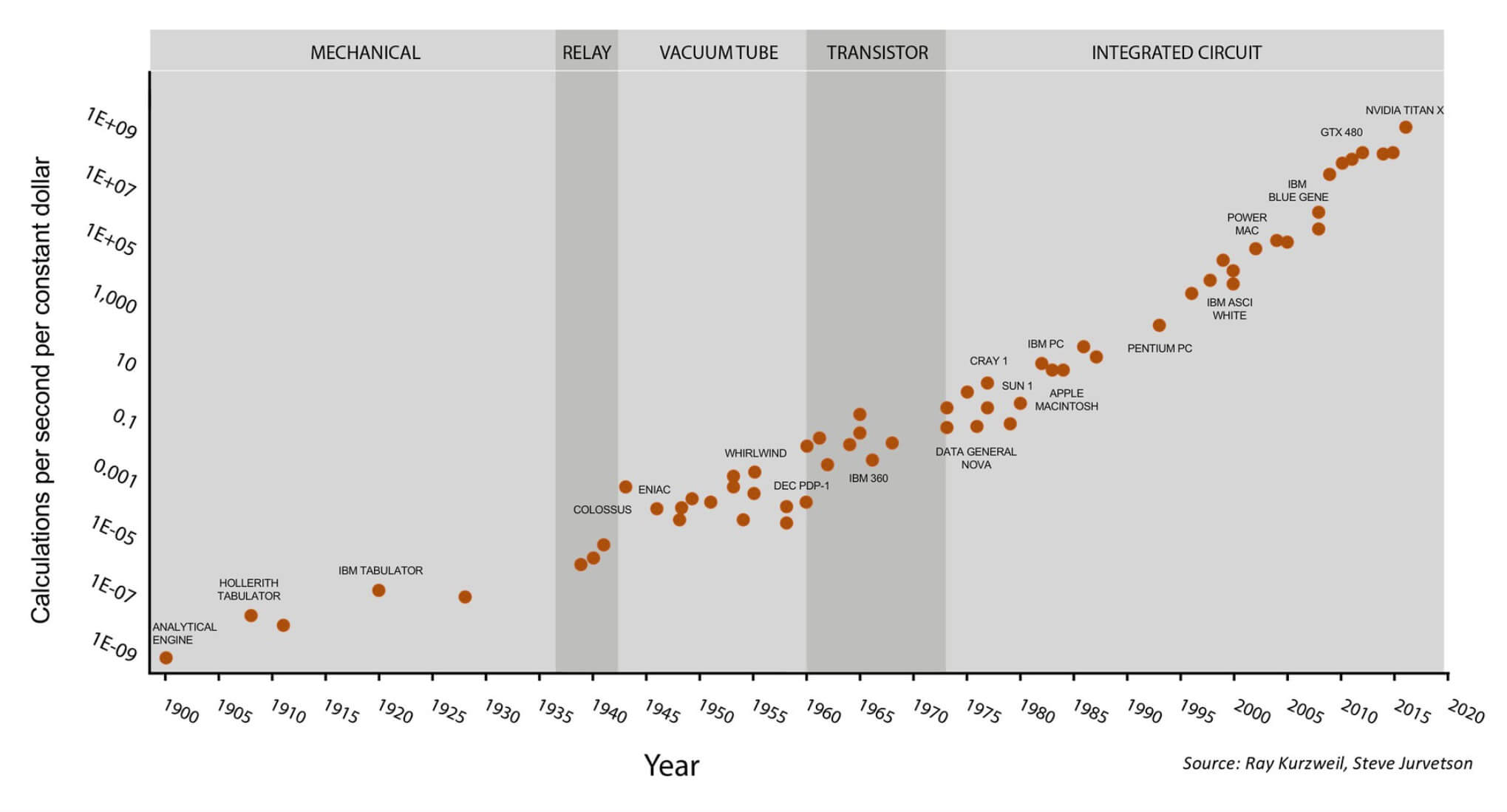
Закон Мура на протяжении 120 лет. Этот график становится ещё интереснее, если узнать, что последние 7 точек относятся к GPU компании Nvidia, а не к процессорам общего назначения. Иллюстрация Стива Джарветсона
Из этого разбора следует один вывод: для повышения производительности компании начали увеличивать вместо частоты количество ядер. По этой причине мы наблюдаем, как широкое распространение получают восьмиядерные процессоры, а не двухядерные процессоры с частотой 10 ГГц. У нас просто осталось не так много пространства для роста, кроме как добавление новых ядер.
С другой стороны, огромное пространство для будущего роста обещает область квантовых вычислений. Я не специалист, и поскольку её технологии по-прежнему разрабатываются, в этой области в любом случае пока мало реальных «специалистов». Чтобы развеять мифы, скажу, что квантовые вычисления не смогут обеспечить вам 1000 кадров в секунду в реалистичном рендере, или нечто подобное. Пока основное преимущество квантовых компьютеров заключается в том, что они позволяют использовать более сложные алгоритмы, ранее бывшие недостижимыми.

Один из прототипов квантовых компьютеров IBM
В традиционных компьютерах транзистор находится или во включенном, или в отключенном состоянии, что соответствует 0 или 1. В квантовом компьютере возможна суперпозиция, то есть бит одновременно может находиться в состоянии 0 и 1. Благодаря этой новой возможности учёные могут разрабатывать новые методы вычислений и у них появится возможность решать задачи, на которые у нас пока не хватает вычислительной мощности. Дело не столько в том, что квантовые компьютеры быстрее, а в том, что они являются новой моделью вычислений, которая позволит нам решать другие виды задач.
До массового внедрения этой технологии осталось ещё одно-два десятилетия, поэтому какие же тенденции мы начинаем видеть в реальных процессора сегодня? Ведутся десятки активных исследований, но я коснусь только некоторых областей, которые, по моему мнению, окажут наибольшее влияние.
Нарастает тенденция влияния гетерогенных вычислений. Эта методика заключается во включении в одну систему множества различных вычислительных элементов. Большинство из нас пользуется преимуществами такого подхода в виде отдельных GPU в компьютерах. Центральный процессор очень гибок и может с приличной скоростью выполнять широкий диапазон вычислительных задач. С другой стороны, GPU спроектированы специально для выполнения графических вычислений, например, перемножения матриц. Они очень хорошо с этим справляются и на порядки величин быстрее ЦП в подобных видах инструкций. Перенеся часть графических вычислений с ЦП на GPU, мы можем ускорить расчёты. Любой программист может оптимизировать ПО, изменив алгоритм, но оптимизировать оборудование гораздо сложнее.
Но GPU — не единственная область, в которой акселераторы становятся всё популярнее. В большинстве смартфонов есть десятки аппаратных акселераторов, предназначенных для ускорения очень специфических задач. Такой стиль вычислений называется морем акселераторов (Sea of Accelerators), его примерами могут быть криптографические процессоры, процессоры изображений, ускорители машинного обучения, кодеры/декодеры видео, биометрические процессоры и многое другое.
Нагрузки становятся всё более и более специализированными, поэтому проектировщики включают в свои чипы всё больше акселераторов. Поставщики облачных услуг, например AWS, начали предоставлять разработчикам FPGA-карты для ускорения их вычислений в облаках. В отличие от традиционных вычислительных элементов наподобие ЦП и GPU, имеющих фиксированную внутреннюю архитектуру, FPGA гибки. Это почти программируемое оборудование, которое можно настраивать в соответствии с нуждами компании.
Если кому-то нужно распознавание изображений, то он реализует эти алгоритмы в «железе». Если кто-то хочет симулировать работу новой аппаратной архитектуры, то перед изготовлением её можно протестировать на FPGA. FPGA обеспечивает бОльшую производительность и энергоэффективность, чем GPU, но всё равно меньше, чем у ASIC (application specific integrated circuit — интегральная схема специального назначения). Другие компании, например, Google и Nvidia, разрабатывают отдельные ASIC машинного обучения для ускорения распознавания и анализа изображений.

Снимки кристаллов популярных мобильных процессоров, демонстрирующие их структуру.
Взглянув на снимки кристаллов относительно современных процессоров, можно увидеть, что бОльшую часть площади ЦП на самом деле занимает не само ядро. Всё бОльшую долю занимают различные акселераторы. Это позволило ускорить очень специализированные вычисления, а также значительно снизить энергопотребление.
Раньше при необходимости добавления в систему обработки видео разработчикам приходилось устанавливать в неё новый чип. Однако это очень неэффективно с точки зрения энергопотребления. Каждый раз, когда сигналу нужно выходить из чипа по физическому проводнику к другому чипу, на бит требуется огромное количество энергии. Сама по себе крошечная доля джоуля не кажется особо большими тратами, но передача данных внутри, а не снаружи чипа может быть на 3–4 порядка величин эффективнее. Благодаря интеграции таких акселераторов с ЦП мы наблюдали в последнее время рост количества чипов с сверхнизким энергопотреблением.
Однако акселераторы не идеальны. Чем больше мы добавляем их в схемы, тем менее гибким становится чип и мы начинаем жертвовать общей производительностью в пользу пиковой производительности специализированных видов вычислений. На каком-то этапе весь чип просто превращается в набор акселераторов и перестаёт быть полезным ЦП. Баланс между производительностью специализированных вычислений и общей производительностью всегда очень тщательно настраивается. Это разногласие между оборудованием общего назначения и специализированными нагрузками называется разрывом специализации (specialization gap).
Хотя кое-кто считает. что мы находимся на пике пузыря GPU/Machine Learning, скорее всего стоит ожидать, что всё больший объём вычислений будет передаваться специализированным ускорителям. Облачные вычисления и ИИ продолжают развиваться, поэтому GPU выглядят лучшим решением для достижения уровня требуемых объёмных вычислений.
Ещё одна область, в которой проектировщики ищут способы повышения производительности — это память. Традиционно считывание и запись значений всегда были одним из самых серьёзных «узких мест» процессоров. Нам могут помочь быстрые и большие кэши, но считывание из ОЗУ или с SSD может занимать десятки тысяч тактовых циклов. Поэтому инженеры часто рассматривают доступ к памяти как более затратный, чем сами вычисления. Если процессор хочет сложить два числа, то ему сначала нужно вычислить адреса памяти, по которым хранятся числа, выяснить, на каком уровне иерархии памяти есть эти данные, считать данные в регистры, выполнить вычисления, вычислить адрес приёмника и записать значение в нужное место. Для простых инструкций, выполнение которых может занимать один-два цикла, это чрезвычайно неэффективно.
Новая идея, которую сейчас активно исследуют — это техника под названием Near Memory Computing. Вместо того, чтобы извлекать небольшие фрагменты данных из памяти и вычислять их быстрым процессором, исследователи переворачивают работу вниз головой. Они экспериментируют с созданием небольших процессоров непосредственно в контроллерах памяти ОЗУ или SSD. Благодаря тому, что вычисления становятся ближе к памяти, существует потенциал огромной экономии энергии и времени, ведь данные теперь не надо передавать так часто. Вычислительные модули имеют прямой доступ к нужным им данным, потому что находятся непосредственно в памяти. Эта идея всё ещё находится в зачаточном состоянии, но результаты выглядят многообещающе.
Одно из препятствий, которое нужно преодолеть для near memory computing — это ограничения процесса изготовления. Как говорилось в третьей части, процесс производства кремния очень сложен и в нём задействованы десятки этапов. Эти процессы обычно специализированы для изготовления или быстрых логических элементов, или плотно расположенных накопительных элементов. Если попытаться создать чип памяти с помощью оптимизированного для вычислений процесса изготовления, то получится чип с чрезвычайно низкой плотностью элементов. Если попробовать создать процессор с помощью процесса изготовления накопителей, то получим очень низкую производительность и большие тайминги.

Пример 3D-интеграции, демонстрирующий вертикальные соединения между слоями транзисторов.
Одно из потенциальных решений этой проблемы — 3D-интеграция. Традиционные процессоры обладают одним очень широким слоем транзисторов, но это имеет свои ограничения. Как понятно из названия, трёхмерная интеграция — это процесс расположения нескольких слоёв транзисторов друг над другом для повышения плотности и снижения задержек. Вертикальные столбцы, производимые на разных процессах изготовления, могут быть затем использованы для соединений между слоями. Эта идея была предложена уже давно, но индустрия потеряла к ней интерес из-за серьёзных сложностей в её реализации. В последнее время мы наблюдаем возникновение технологии накопителей 3D NAND и возрождение этой области исследований.
Кроме физических и архитектурных изменений, на всю полупроводниковую отрасль сильно повлияет ещё одна тенденция — больший упор на безопасность. До недавнего времени о безопасности процессоров думали чуть ли не в последний момент. Это похоже на то, как Интернет, электронная почта и многие другие системы, которые мы сегодня активно используем, разрабатывались почти без оглядки на безопасность. Все существующие меры защиты «прикручивались» по мере случавшихся инцидентов, чтобы мы чувствовали себя в безопасности. В области процессоров такая тактика больно ударила по компаниям, и особенно по Intel.
Баги Spectre и Meltdown — это, вероятно, самые известные примеры того, как проектировщики добавляют функции, значительно ускоряющие процессор, не в полной мере осознавая связанные с этим угрозы безопасности. При разработке современных процессоров гораздо большее внимание уделяется безопасности как ключевой части архитектуры. При повышении безопасности часто страдает производительность, но учитывая ущерб, который могут нанести серьёзные баги безопасности, можно с уверенностью сказать, что лучше фокусироваться на безопасности в той же степени, что и на производительности.
В предыдущих частях серии мы коснулись таких техник, как высокоуровневый синтез, позволяющий проектировщикам сначала описать структуру на языке высокого уровня, а затем позволить сложным алгоритмам определить оптимальную для выполнения функции аппаратную конфигурацию. С каждым поколением циклы проектирования становятся всё более затратными, поэтому инженеры ищут способы ускорения разработки. Следует ожидать, что в дальнейшем эта тенденция проектирования оборудования при помощи ПО будет только усиливаться.
Конечно, мы не способны предсказать будущее, но рассмотренные нами в статье инновационные идеи и области исследований могут служить ориентирами ожиданий в проектировании процессоров будущего. Мы можем с уверенностью сказать, что мы близимся к концу обычных усовершенствований процесса производства. Чтобы и дальше продолжать увеличивать производительность в каждом поколении, инженерам придётся изобретать ещё более сложные решения.
Надеемся, что наша серия из четырёх статей подстегнула ваш интерес к изучению проектирования, верификации и производства процессоров. Существует бесконечное количество материалов по этой теме, и если бы мы попытались раскрыть их все, то каждая из статей могла бы разрастись на целый университетский курс. Надеюсь, вы узнали что-то новое и теперь лучше понимаете, насколько сложны компьютеры на каждом из уровней.
