[Перевод] Практические рекомендации по разработке крупномасштабных React-приложений. Планирование, действия, источники данных
Сегодня мы представляем вашему вниманию первую часть перевода материала, который посвящён разработке крупномасштабных React-приложений. При создании одностраничного приложения с помощью React очень легко привести его кодовую базу в беспорядок. Это усложняет отладку приложения, затрудняет обновление или расширение кода проекта.
В экосистеме React существует множество хороших библиотек, с помощью которых можно управлять определёнными аспектами приложения. Мы довольно подробно остановимся на некоторых из них. Кроме того, здесь будут приведены некоторые практические рекомендации. Если проект должен хорошо масштабироваться — этим рекомендациям полезно будет следовать с самого начала работы над ним. В этой части перевода материала мы поговорим о планировании, о действиях, об источниках данных и об API. Первым шагом разработки крупномасштабных React-приложений, который мы рассмотрим, является планирование.
Планирование
Чаще всего разработчики пропускают данный этап работы над приложением. Это происходит из-за того, что в ходе планирования никакой работы по написанию кода не ведётся. Но важность этого шага нельзя недооценивать. Скоро вы узнаете о том, почему это так.
▍Зачем заниматься планированием при разработке приложений?
Разработка программного обеспечения требует согласования множества процессов. При этом всё очень легко способно выйти из-под контроля. Препятствия и неопределённости, с которыми приходится сталкиваться в процессе разработки, могут поставить под угрозу сроки сдачи проекта.
Помочь уложиться в срок — это то, в чём вам может помочь фаза планирования проекта. На этом этапе «раскладывают по полочкам» все те возможности, которые должно иметь приложение. Гораздо легче предсказать то, сколько времени займёт создание маленьких отдельных модулей, список которых лежит перед программистами, чем попытаться, в уме, прикинуть сроки разработки всего проекта.
Если в некоем большом проекте принимают участие несколько программистов (а так обычно и бывает), то наличие заранее разработанного плана, некоего документа, значительно облегчит их взаимодействие друг с другом. На самом деле, отдельным разработчикам могут быть назначены различные задания, сформулированные в этом документе. Его наличие поможет членам команды быть в курсе того, чем заняты их сослуживцы.
И, наконец, благодаря этому документу вы сможете очень чётко видеть то, как продвигается работа над проектом. Программисты часто переходят от работы над одной частью приложения к другой, и возвращаются к тому, чем занимались раньше, гораздо позже, чем хотелось бы.
Рассмотрим процесс планирования приложения.
▍Шаг 1: страницы и компоненты
Нужно определить внешний вид и функциональность каждой страницы приложения. Один из лучших подходов здесь заключается в том, чтобы нарисовать каждую страницу. Сделать это можно либо с помощью инструмента для создания макетов, либо вручную, на бумаге. Это даст вам хорошее понимание того, какая информация должна присутствовать на каждой из страниц. Вот как может выглядеть макет страницы.
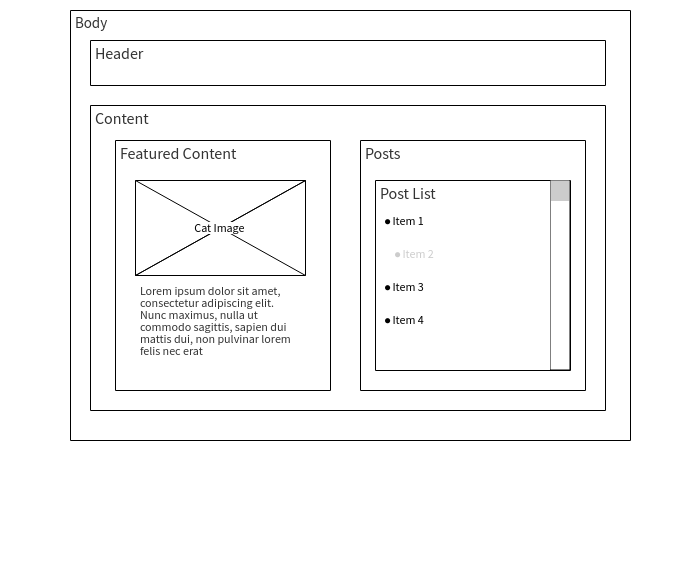
Макет страницы (взято отсюда)
На вышеприведённом макете можно легко идентифицировать родительские сущности-контейнеры и их дочерние элементы. Позже родительские контейнеры станут страницами приложения, а более мелкие элементы попадут в папку components проекта. После того, как вы закончили рисовать макеты — напишите на каждом из них имена страниц и компонентов.
▍Шаг 2: действия и события
После того, как вы определились с компонентами приложения, подумайте о том, какие действия будут выполняться в каждом из них. Позже из данных компонентов будет выполняться отправка этих действий.
Рассмотрим интернет-магазин, на домашней странице которого выводится список рекомендованных товаров. Каждый из элементов этого списка будет представлен в проекте в виде отдельного компонента. Пусть имя этого компонента будет ListItem.
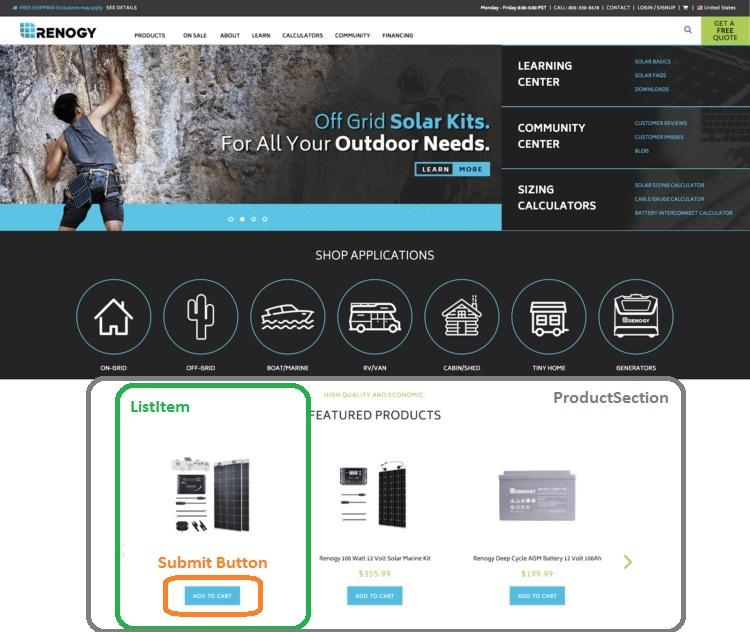
Пример домашней страницы интернет-магазина (взято отсюда)
В этом приложении действие, которое выполняется компонентом из раздела Product, называется getItems. Среди некоторых других действий, которые могут быть включены в эту страницу, могут быть getUserDetails, getSearchResults, и так далее.
▍Шаг 3: данные и модели
С каждым компонентом приложения связаны некие данные. Если одни и те же данные используются несколькими компонентами приложения — тогда они будут частью централизованного дерева состояния. Управление деревом состояния осуществляется с помощью Redux.
Эти данные используются множеством компонентов. В результате, когда данные изменяет один компонент, это отражается и на других компонентах.
Создайте список подобных данных вашего приложения. Он станет схемой моделей. На основе этого списка можно будет создать редьюсеры.
products: {
productId: {productId, productName, category, image, price},
productId: {productId, productName, category, image, price},
productId: {productId, productName, category, image, price},
}
Вернёмся к вышеприведённому примеру с интернет-магазином. В разделе рекомендованных товаров и новых товаров используется один и тот же тип данных, применяемый для представления отдельных товаров (нечто вроде product). Этот тип послужит основой для создания одного из редьюсеров приложения.
После документирования плана действий пришло время рассмотреть некоторые детали, необходимые для настройки слоя приложения, ответственного за работу с данными.
Действия, источники данных и API
По мере роста приложения часто бывает так, что с хранилищем Redux оказывается связанным избыточное число методов. Случается, что ухудшается, отступая от реальных нужд приложения, структура директорий. Всё это становится тяжело поддерживать, усложняется добавление в приложение новых возможностей.
Поговорим о том, как можно скорректировать некоторые вещи для того, чтобы обеспечить чистоту кода хранилища Redux в долгосрочной перспективе. Можно избежать множества проблем в том случае, если с самого начала делать модули такими, чтобы они подходили бы для повторного использования. Поступать стоит именно так, даже несмотря на то, что поначалу это может показаться излишеством, неоправданно усложняющим проект.
▍Дизайн API и клиентские приложения
В процессе первоначальной настройки хранилища формат данных, которые поступают из API, сильно влияет на структуру хранилища. Часто данные, прежде чем они будут переданы редьюсерам, нуждаются в преобразовании.
В последнее время много говорят о том, что нужно и что не нужно делать при проектировании API. Такие факторы, как бэкенд-фреймворк и размер приложения, оказывают дополнительное влияние на то, как проектируют API.
Рекомендуется, так же, как и при разработке серверных приложений, хранить в отдельной папке вспомогательные функции. Это могут быть, например, функции для форматирования и мэппинга данных. Позаботьтесь о том, чтобы эти функции не имели бы побочных эффектов (посмотрите этот материал о чистых функциях).
export function formatTweet (tweet, author, authedUser, parentTweet) {
const { id, likes, replies, text, timestamp } = tweet
const { name, avatarURL } = author
return {
name,
id,
timestamp,
text,
avatar: avatarURL,
likes: likes.length,
replies: replies.length,
hasLiked: likes.includes(authedUser),
parent: !parentTweet ? null : {
author: parentTweet.author,
id: parentTweet.id,
}
В этом примере кода функция formatTweet добавляет новый ключ (parent) в объект твита фронтенд-приложения. Эта функция возвращает данные, основываясь на переданных ей параметрах, не влияя на данные, находящиеся за её пределами.
Тут можно пойти и ещё дальше, выполняя мэппинг данных на заранее описанный объект, структура которого соответствует нуждам вашего фронтенд-приложения. При этом можно выполнять валидацию некоторых ключей.
Теперь поговорим о тех частях приложений, которые ответственны за выполнение обращений к API.
▍Организация работы с источниками данных
То, о чём мы будем говорить в этом разделе, будет напрямую использоваться действиями Redux для модификации состояния приложения. В зависимости от размера приложения (и, кроме того, от времени, которое есть у программиста), к проектированию хранилища данных можно подойти с использованием одного из следующих двух подходов:
- Без использования агента (courier).
- С использованием агента.
▍Проектирование хранилища без использования агента
При таком подходе в ходе настройки хранилища механизмы выполнения запросов GET, POST и PUT для каждой модели создают по отдельности.
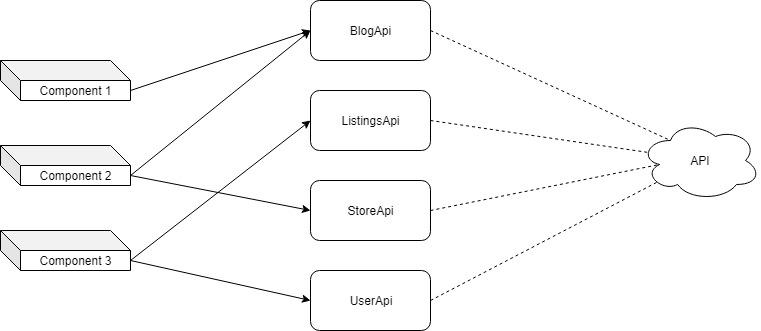
Компоненты взаимодействуют с API без использования агента
На предыдущей схеме показано, что каждый из компонентов отправляет действия, которые вызывают методы различных хранилищ данных. Вот как, при таком подходе, будет выглядеть метод updateBlog из файла BlogApi:
function updateBlog(blog){
let blog_object = new BlogModel(blog)
axios.put('/blog', { ...blog_object })
.then(function (response) {
console.log(response);
})
.catch(function (error) {
console.log(error);
});
}
Такой подход позволяет экономить время… И поначалу он ещё и позволяет вносить в код изменения, не особенно беспокоясь о побочных эффектах. Но из-за этого в проекте будет присутствовать большой объём избыточного кода. Кроме того, выполнение операций над группами объектов потребует немало времени.
▍Проектирование хранилища с использованием агента
При таком подходе, в долгосрочной перспективе, проект легче поддерживать, в него легче вносить изменения. Кодовая база с течением времени не загрязняется так как разработчик избавлен от проблемы выполнения параллельных запросов средствами axios.
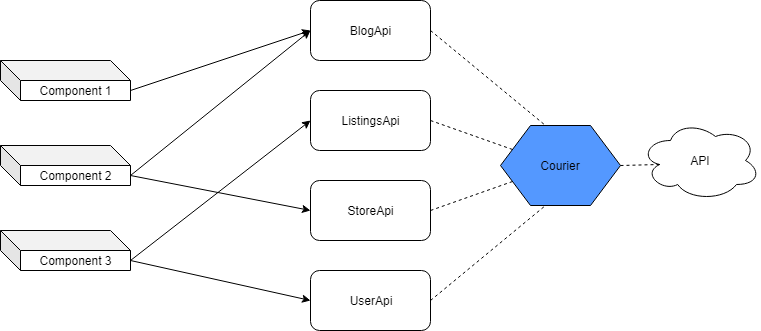
Компоненты взаимодействуют с API с использованием агента
Однако при таком подходе определённое время требуется на первоначальную настройку системы. Она оказывается менее гибкой. Это одновременно и хорошо и плохо, так как не даёт разработчику сделать нечто необычное.
export default function courier(query, payload) {
let path = `${SITE_URL}`;
path += `/${query.model}`;
if (query.id) path += `/${query.id}`;
if (query.url) path += `/${query.url}`;
if (query.var) path += `?${QueryString.stringify(query.var)}`;
return axios({ url: path, ...payload })
.then(response => response)
.catch(error => ({ error }));
}
Здесь показан код базового метода courier. Все обработчики API могут его вызывать, передавая ему следующие данные:
- Объект запроса, содержащий сведения, имеющие отношение к URL. Например — имя модели, строку запроса, и так далее.
- Полезная нагрузка, содержащая заголовки запроса и его тело.
▍Обращения к API и внутренние действия приложения
В ходе работы с Redux особое внимание уделяют использованию заранее определённых действий. Это делает изменения данных, происходящие в приложении, предсказуемыми.
Определение целой кучи констант в большом приложении может показаться неподъёмной задачей. Однако выполнение этой задачи значительно упрощается благодаря фазе планирования, рассмотренной нами ранее.
export const BOOK_ACTIONS = {
GET:'GET_BOOK',
LIST:'GET_BOOKS',
POST:'POST_BOOK',
UPDATE:'UPDATE_BOOK',
DELETE:'DELETE_BOOK',
}
export function createBook(book) {
return {
type: BOOK_ACTIONS.POST,
book
}
export function handleCreateBook (book) {
return (dispatch) => {
return createBookAPI(book)
.then(() => {
dispatch(createBook(book))
})
.catch((e) => {
console.warn('error in creating book', e);
alert('Error Creating book')
})
}
export default {
handleCreateBook,
}
В вышеприведённом фрагменте кода показан простой способ использования методов источника данных createBookApi с действиями Redux. Метод createBook можно без проблем передать методу Redux dispatch.
Кроме того, обратите внимание на то, что этот код хранится в папке, в которой хранятся файлы действий проекта. Похожим образом можно создавать JavaScript-файлы, в которых объявлены действия и обработчики для других моделей приложения.
Итоги
Сегодня мы поговорили о роли фазы планирования в разработке крупномасштабных проектов. Также мы обсудили здесь особенности организации работы приложения с источниками данных. В следующей части этого материала речь пойдёт об управлении состоянием приложения и о разработке масштабируемого пользовательского интерфейса.
Уважаемые читатели! С чего вы начинаете разработку React-приложений?

