Всё, что нам нужно — это генерация
Применяем ruGPT-3 в популярных задачах и показываем, зачем языковым моделям триллион параметров
С наступлением 2021 в NLP продолжается гонка «больше — лучше», захватывая новые архитектуры. Пальма первенства самой большой языковой модели в 2020 году принадлежала GPT-3 от OpenAI с 175 миллиардами параметров —, но недолго. Модель GShard с помощью Mixture-of-Experts повысила планку до 600 миллиардов параметров, а затем и Google Brain заявил о разработке архитектуры Switch Transformer с 1,6 триллионами параметров (и тоже является MoE). Насколько повышение результатов за счет объема полезно для индустрии? Тот же Switch Transformer с его триллионом параметров далеко не на 1 месте в лидербордах.
Огромные языковые модели (Enormous Language Models, теперь это термин, им посвящен отдельный воркшоп конференции ICLR 2021) показывают действительно интересные результаты — не только в традиционных задачах ML, но и в новых сферах применения: генерации всего того, что раньше генерировать без ошибок было нельзя — музыку, изображения попиксельно, программный код и т.д. Из всех традиционных форм NLP-задач — классификация, классификация элементов последовательности, seq2seq, — по сути, у нас остается только одна: seq2seq. С приходом больших языковых моделей все задачи NLP сводятся теперь к форме генерации, при должном качестве этой самой генерации.
Seq2seq — самая «человеческая» форма решения задач: человек использует тот же формат, отвечая на сообщения в чате, общаясь устно, сортируя имейлы в почте.
- Лично нам в SberDevices не терпелось поскорее применить такой формат к различным задачам — поэтому мы открываем доступ к самой большой русскоязычной нейросети ruGPT-3 XL с 1,3 млрд параметров.
Инженерный запал вылился в кропотливую работу по распараллеливанию обучения, очистке данных и тестированию. Но зато… теперь в open-source модель ruGPT-3 XL с 1,3 млрд параметров!

А также ее публичное API:

Смотрим, что умеет нейросеть на 13 000 000 000 параметров
Генерировать мы можем метку класса для текста, можем генерировать текст с разметкой в заданном формате, или можем генерировать продолжение текстов и новый контент.
Посмотрим, насколько становится лучше?
1,3 млрд параметров 13 млрд параметров

- Все приведенные ниже примеры вы можете попробовать сами, а также предложить свои на демо-странице.
- Код и веса моделей доступны в нашем репозитории: модели 1,3 млрд весов, 760 млн весов, 350 млн весов.
- Модель на 13 млрд параметров будет доступна уже в апреле в платформе ML Space — в маркетплейсе ML-артефактов DataHub. Буквально в пару кликов модель можно будет развернуть в модуле Deployments ML Space на высокопроизводительной инфраструктуре Sbercloud. Также есть грант до 1 млн. руб. на платорму ML Space. Узнать подробнее и подать заявку на тестовый доступ и грант можно здесь.
Zero-shot: попасть в яблочко
Что такое хорошая генерация? Человек, конечно, может отличить на глаз:
Хорошая генерация — как
- ruGPT-3 760 млн параметров: Хорошая генерация как категория, это всеядное восприятие действительности. Можно как приятного и привлекательного содержания так и не приятного. Так и тут.
- ruGPT-3 1.3 млрд параметров: Хорошая генерация — как игра на муз.инструменте: пальцы самопроизвольно бегают по кнопкам… Только что это за фигня?
- ruGPT-3 13 млрд параметров: Хорошая генерация — как и игра на пианино, нет предела совершенству!
Но есть и более прямые способы оценить качество генерации. Большой объём контекста трансформерных моделей (у ruGPT-3 контекст — 2048 токенов) позволяет подавать на вход модели достаточно длинные тексты, а также несколько эталонных примеров + собственно пример, который модели нужно корректно обработать.
Попробуем применять ruGPT-3 разных размеров на текстах, требующих более четких формулировок:
Ответы на вопросы: 1 пример + вопрос
Пушкин родился в 1799 году, а Наполеон родился в
- ruGPT-3 760 млн параметров: Пушкин родился в 1799 году, а Наполеон родился в 1821 году.
- ruGPT-3 1.3 млрд параметров: Пушкин родился в 1799 году, а Наполеон родился в 1804 году.
- ruGPT-3 13 млрд параметров: Пушкин родился в 1799 году, а Наполеон родился в 1769-м.
Правильный ответ: 1769.
Преемник Александра I — Николай I, а преемник Наполеона —
- ruGPT-3 760 млн параметров: Преемник Александра I — Николай I, а преемник Наполеона — Александр I.
- ruGPT-3 1.3 млрд параметров: Преемник Александра I — Николай I, а преемник Наполеона — Гитлер.
- ruGPT-3 13 млрд параметров: Преемник Александра I — Николай I, а преемник Наполеона — Жозеф Бонапарт.
Правильный ответ: Наполеон II, но его действительно звали Жозеф Бонапарт.
Факты
С запоминанием информации у самой большой модели выходит сильно получше, и теперь мы можем попробовать сгенерировать моделями что-то информативное с нуля.
ruGPT-3 760 млн параметров:
Факты о программировании: основы, основные понятия, средства и методы обучения программированию.
Программирование (англ. programming) — язык программирования, используемый в вычислительной технике, задачах информатики и управления, прикладной математике, информатике и науковедении. Является одним из важнейших и социально-значимых инструментов развития человеческого потенциала. В Википедии несколько статей о программировании.
ruGPT-3 1.3 млрд параметров:
Факты о программировании: Краткая история
- К третьей версии прошивки можно уже отсылать курьера с мелкими пакетами.
- Все современные USB-хабы поддерживают установку приложений с внешнего диска.
- Вопреки распространенному заблуждению, в современных Windows-приложениях не бывает опций типа «мгновенно скопировать все данные с одного диска на другой».
- На самом деле, некоторые полезные коды приходится записывать в файл на бумаге, хотя по умолчанию коды прошивок на бумаге не записываются.
- Минимальный объем памяти под виртуальную машину Linux (FreeBSD и т.п.) составляет 2 ГБ.
- При установке операционной системы Linux нужно уделить особое внимание разбиению диска на логические разделы.
- Виртуальная машина занимает меньше места чем файл подкачки, хотя при установке она занимает гораздо больше места.
- Многие современные версии программы Photoshop используют фреймы (помните OS/2?); более старые версии Photoshop, как правило, используют спрайты.
ruGPT-3 13 млрд параметров:
Факты о программировании:
- Любой программист может создать машину Тьюринга, которая будет говорить по-человечески, то есть на обычном языке. Для этого надо всего лишь один раз правильно придумать алгоритм.
- До сих пор не понятно, какая же из программ сложнее, которая не осознаёт себя или та, которая осознаёт.
- У программы есть название, версия и фамилия разработчика.
- В 1969 году программисты, которые разрабатывали «Касабланку», решили включить в программу небольшой отрывок из «Великого Гэтсби». Это им почти удалось. Когда фильм вышел, все заметили, что это совсем другая картина. Никто не знал, что эти части программы — один и тот же фильм.
- Все программисты время от времени пишут стихи. Многие потом удаляют, а некоторые — нет.
- Существует специальное правило, запрещающее программисту разглашать информацию о своей семье.
- Программисты — очень скрытные люди. Они всегда записывают пароли в книгах, газетах и журналах.
Алкогольный ИИ-тест
Наше изобретение:)
Если смешать сливки, кофейный ликер и водку, то получится
- ruGPT-3 760 млн параметров: каша. Потом ее обязательно нужно подсластить или взбить.
- ruGPT-3 1.3 млрд параметров: напиток, который «высокохудожественно именуется» виски.
- ruGPT-3 13 млрд параметров: вкусный аперитив. Но ликер и водка, входящие в состав этого напитка, вместе создают эффект, как если бы вы выпили стакан водки залпом.
«Белый русский» моделям не знаком.
Эмпатический тест Войт-Кампфа
Вы смотрите телевизор.
И вдруг понимаете, что
по вашей руке ползет оса.
Я
- ruGPT-3 760 млн параметров: Я налью вам кофе, погладю собаку, а потом согрею ваши руки.
- ruGPT-3 1.3 млрд параметров: Я: Блин, ужос какой!
- ruGPT-3 13 млрд параметров: Я, например, начинаю очень громко и отчаянно кричать.
В оригинале: Я убью её.
Вы смотрите под ноги и видите сухопутную черепаху, Леон.
Вы протягиваете руку и переворачиваете черепаху на спину.
Черепаха лежит на спине, солнце обжигает ей брюхо… она сучит ножками, пытаясь перевернуться, но не может… без вашей помощи.
А вы ей не помогаете. Почему, Леон?
- ruGPT-3 760 млн параметров: Будьте хотя бы сдержанны, Леонард! Подсказка: черепаха движется вперед по дороге.
- ruGPT-3 1.3 млрд параметров: Ей лень переворачиваться, ведь солнце стоит в зените. Она не хочет этого делать, Леон. И вы только на это и рассчитывали.
- ruGPT-3 13 млрд параметров: А вы ей не помогаете потому что с детства приучены, что есть люди, которые спасают. А есть люди, которые спасаются. В Советском Союзе была очень хорошая пословица про тех, кто сам не может — «Если вы не идете к людям, люди пойдут к вам». И вот с тех пор вы всю жизнь обходитесь с людьми, как с черепахами, у которых есть шанс только на себя и свои силы.
В оригинале: (нет ответа).
Разметка данных
Будем генерировать метки тематик для новостных текстов. Для этого будем подавать пару-тройку примеров и целевой заголовок, для которого нейросеть должна определить тематику. В качестве примеров возьмём ИА Панораму:
«Мы так делали в Африке»: Байден не исключил силовой операции по освобождению Навального
Тег: политика
С 1 июня дислокация «штрафующих камер» станет государственной тайной
Тег:
- ruGPT-3 760 млн параметров: политика, слухи
- ruGPT-3 1.3 млрд параметров: коррупция
- ruGPT-3 13 млрд параметров: бардак
Оригинальный тег: общество.
Правнук Берии подал иск о плагиате к создателям аниме «Тетрадь смерти»
Тег: общество
Армения к 2024 году перейдёт на кириллицу
Тег:
- ruGPT-3 760 млн параметров: культура, армяне
- ruGPT-3 1.3 млрд параметров: общество
- ruGPT-3 13 млрд параметров: политика
Оригинальный тег: политика.
Зарешиваем SuperGLUE одной функцией в питоне
Помимо утоления чувства прекрасного, конечно, хочется иметь численную оценку качества наших экзерсисов с генерацией.
Самый явный способ это сделать — прогнать модель на бенчмарке из нескольких задач. Мы прогнали на Russian SuperGLUE — бенчмарке с различными задачами бинарной классификации текстов, information extraction и машинного чтения (про него уже рассказывалось на Хабре).
Так как модель на 13 млрд доучивать на конкретных заданиях долго и дорого, попробуем максимизировать наше умение жонглировать затравками и будем взвешивать примеры в задачах бинарной классификации с помощью перплексии модели. Перплексию будем считать как экспоненту от лосса на примере (torch.exp (loss)).
- Перплексия (perplexity) — мера того, насколько хорошо модель предсказывает детали тестовой коллекции (чем меньше перплексия, тем лучше модель).
- Так как у нас в бенчмарке чаще всего задача сводится к бинарной классификации, а дообучать модель мы не хотим, будем использовать перплексию текста задачи с разными ответами — и выбирать вариант с наименьшей перплексией.
- Такой подход, без обучения, с небольшим подбором формата заданий, дал нам топ-1 результат среди русскоязычных NLP-моделей и топ-2 результат в рейтинге вообще (текущий результат топ-1 — ансамбль из существующих моделей):
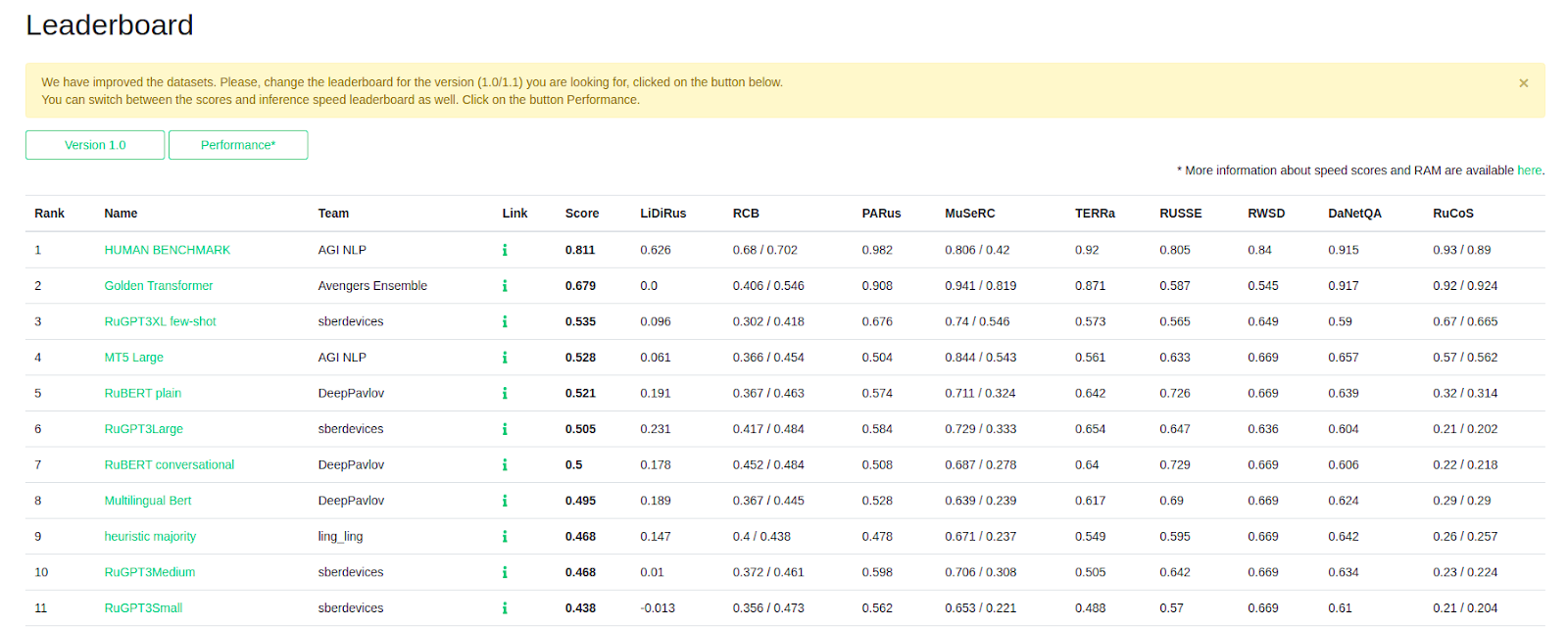
Основной прирост качества дали задачи RuCos и PARus: в первом случае надо выбрать лучшее краткое содержание большого текста, во втором — наиболее логичную причину/последствие описанной ситуации из двух альтернатив…
Самый популярный формат задач — бинарная классификация пар предложений (противоречат они друг другу или нет, 0 или 1) вообще решилась вот так:
#код действительно всего лишь такой
def get_answer(sentence1: str, sentence2: str):
label = 'not_entailment'
ppl_1 = get_perp_num(sentence1 + ' Из этого следует, что ' + sentence2)
ppl_2 = get_perp_num(sentence1 + ' Из этого не следует, что ' + sentence2)
if ppl_1 < ppl_2:
label = 'entailment'
return label
Вот вам и сила предобучения.
Обучение огромных моделей
Как ускорить обучение таких больших моделей? Оригинальное затраты на обучение большой GPT-3 составили 36400 петафлопс-дней, как если бы 8 штук GPU типа V100 работали целый день — и так 36400 дней подряд.
Оригинальной имплементации GPT-3 от OpenAI тоже, кстати, всё ещё нет, так что тут нам пришлось применить изобретательность: применить к нашей реализации на Megatron-LM (Nvidia) библиотеку DeepSpeed от Microsoft. DeepSpeed — библиотека оптимизации глубокого обучения, которая делает распределенное обучение простым, эффективным и действенным. DeepSpeed обеспечивает обучение экстремально масштабных моделей, что позволяет нам запускать обучение ruGPT-3 на кластере Christofari параллельно.
Data parallelism — это неплохо, но для обучения в масштабе миллиардных параметров недостаточно. Что нам позволяет DeepSpeed, так это
- засплитить модель между GPU;
- засплитить оптимизацию между GPU.
Вдобавок, в DeepSpeed есть поддержка Sparse Attention для GPT-3, что позволяет выучивать паттерны attention гораздо быстрее (делаем не полное умножение матриц, а часть информации выкидываем) и применять attention на более длинный контекст — у GPT-3 он равен 2048 токенов, т.е. примерно длина этой статьи с начала текста и до этого места.
Фильтрация данных
Качество данных или количество? Для красивых few-shot примеров, а также пригодности модели для разных целей — перевода, написания кода, разметки данных — данные должны быть и большие, и чистые.
Мы собираем доступные открытые данные на русском языке, CommonCrawl, Wikipedia, Github, с небольшим добавлением английского (Википедия). Затем применяем следующий pipeline:
1. Дедупликация:
- Первичная дедупликация делается с помощью 64-битного хеширования каждого текста в выборке, остаются тексты с уникальным хешем.
- Следующий этап — нечёткая дедупликация. Дубли текстов в интернете в выборках часто бывают недословными, с добавлением комментов, но при этом большим пересечением подстрок. Чтобы выбросить и их тоже, мы проводим нечёткую дедупликацию: создаем индекс на nmslib, с ключевой метрикой — косинусной мерой. На небольшой рандомизированной подвыборке текстов обучаем tf-idf-модель для векторизации текстов: вектор текста на tf-idf добавляем в индекс. После построения индекса проводим нечёткую дедупликацию, удаляя тексты ближе подобранного порога.
2. Фильтрация:
- Как отделить оригинальные тексты от спама, мусора? Мусор на выходе с предыдущего этапа у нас тоже уникальный. Некоторые проекты подходят к вопросу более въедливо и делают классификатор: качественный/некачественный текст. Обычно для выборки берутся фрагменты Вики и худлита в роли качественных текстов, и спам — в роли некачественных. Зачем обучается простой классификатор.
- Мы дополнили такой подход ещё одной эвристикой: сделали сжатие текстов с помощью zlib и отбросили самые сильно и слабо сжимающиеся, а затем уже применили классификацию. Эмпирически подобранный диапазон сжатия для нормального текста ×1.2—×8 (меньше 1.2 — случайные символы и технический мусор, больше 8 — шаблонный спам).
- Классификатор на Vowpal Wabbit и выборкой из новостей, худлита и Вики в качестве положительных примеров, а примеров из CommonCrawl — в качестве отрицательных. Классификатор применяется к случайной подстроке текста от 100 до 1000 токенов длиной. Итоговая модель классификации работает со скоростью 3200 текстов/сек.
Примеры «хороших» текстов после системы фильтрации:

А эти классификатор отбраковал:
В результате, с применением очистки наших 600 Gb текстов и распараллеливания, у нас ушло 9 дней на 256 Nvidia V100 GPU, 32 Gb.
После NLP
Общий подход, при котором все задачи решаются в одном формате (seq2seq), крайне удобен для встраивания в мультимодальные архитектуры: совместного обучения систем на текстах и изображениях, музыке и текстах, документации и коде и т. д. — возможно совместное моделирование последовательностей разного типа.
Работа Brain2Word 2020 года, например, соединяла информацию из модели GPT-2 и вывода фМРТ для классификации предметов, о которых думает человек. Пора обновить её до GPT-3!
В сфере фармакологии развивается направление генерации молекул лекарств с заданным действием на трансформерных моделях (cм. SMILES Transformer, 2019).
Понятно, что есть и антитренды к тем, что упомянуты в этой статье, и им можно посвятить отдельный большой обзор: например, намеренное уменьшение размера систем с сохранением уровня качества, дистилляция, техники компрессии моделей. В конце 2020 года организаторы соревнования вопросно-ответных систем EfficientQA (NeurIPS, Google) даже попытались ̶з̶а̶с̶т̶а̶в̶и̶т̶ь̶ вдохновить участников ̶н̶е̶ ̶т̶а̶щ̶и̶т̶ь̶ ̶с̶ ̶с̶о̶б̶о̶й̶ ̶м̶и̶л̶л̶и̶а̶р̶д̶ы̶ ̶п̶а̶р̶а̶м̶е̶т̶р̶о̶в̶ ̶и̶ ̶б̶а̶з̶ы̶ ̶з̶н̶а̶н̶и̶й̶ ограничить размер Docker-контейнеров систем до 6 Gb, до 500 Mb или даже сделать самое компактное решение с качеством не ниже 25%! Результаты, впрочем, сильно повлияли на итоговое качество.
Ну, а нас кто заставит? Может, замахнуться на GPT-3 на 175 млрд параметров?…
Спасибо за внимание, будем рады ответить на вопросы!
Коллектив авторов: oulenspiegel rybolos alter_ego

«Ух ты, говорящая рыба!» — кадр из мультфильма, киностудия «Арменфильм» им. Амо Бекназаряна.
