Энтерпрайз-домино. 0x13 вредных советов для ниндзя-разработчика
Практически любая enterprise-система (под которой мы будем подразумевать некоторое ПО, где пользователи работают постоянно в течение всего рабочего дня) в современном мире стремится вырасти вместе с управляемым ей бизнесом в высоконагруженное web-решение вроде нашего СБИС.
Оно и понятно: доступность с любого устройства, где есть браузер, минимальные вложения «на старте» — все, что бизнес так любит. Но с развитием системы растет не только ее размер, но и сложность архитектуры решения, а с ней — и цена любой ошибки, вызывающей сразу каскад возможных проблем и «эффект домино».
Когда, где и как их может вызвать затаившийся до поры ниндзя-разработчик?

Выращиваем архитектуру
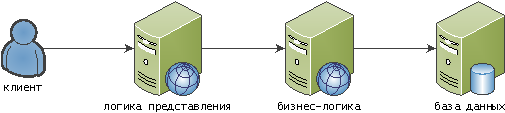
Начинаем выращивать наше решение с классической трехзвенки:
клиент, он же браузер
сервер, он же бизнес-логика, он же БЛ
база, она же… база и есть база

В самом простом начальном варианте логика работы и отображения никак не разделены, существуют в едином кодовом пространстве (видимо, ниндзя уже приложил руку) в, не в обиду самому языку, классическом PHP-стиле:

Разделим логику представления и логику работы. Это может быть как логическое выделение шаблонов отображения в коде, так и физический вынос таких статичных данных на независимый от БЛ ресурс:
Проблема: блокировка бизнес-логики
Теперь наш ниндзя готов нанести первый удар: написать настолько медленный код, чтобы вся бизнес-логика оказалась заблокированной целиком — например, содержащий бесконечный цикл или постоянное потребление памяти. Даже если такой запрос блокирует всего лишь один процесс на БЛ, то нетерпеливый пользователь, не дождавшись ответа, «дернет» его снова и снова, пока не заблокируется все:

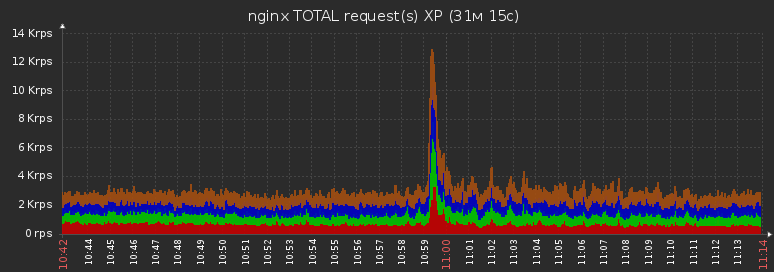
Посмотрите, как красиво «покраснели» все участки, где сбой «сыграл» — ни один клиент ничего не получает, ниндзя доволен, диверсия удалась!
Но мы добавим перед БЛ некоторый диспетчер (например, на базе nginx), который умеет «отстреливать» конкретный узел, если он перестал отзываться, а самих узлов сделаем несколько:

Проблема: монолитная база
Хитрый ниндзя заметил, что чем по более глубокому слою он нанесет удар, тем больше эффект. В текущей нашей схеме таким удобным местом является база данных. Опередим его, разделив данные по некоторым прикладным критериям — например, оперативные текущие данные и статистические отчеты:
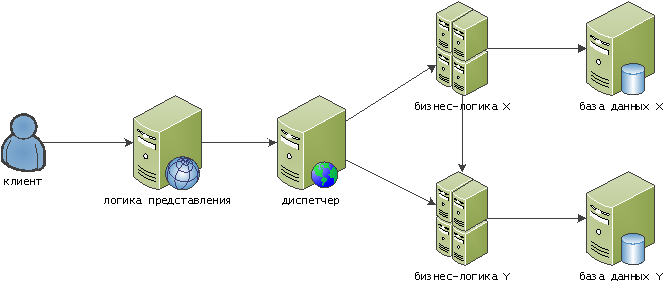
Фактически, в этот момент мы получили уже сервисную архитектуру. Насколько она будет «микро» еще вопрос, но сервисы уже получают некоторую прикладную «цветовую дифференциацию штанов».
Проблема: жесткая взаимозависимость сервисов
Смотрим на схему выше — и видим, что в случае проблем на сервисе Y, сервис X тоже начнет страдать, хотя в большинстве случаев мог бы этого не делать. Например, если после оформления заказа нам надо отправить его клиенту на email, синхронный вызов здесь вовсе не нужен.
Поэтому мы можем разорвать некоторые цепочки вызовов и «размазать» пиковую нагрузку во времени, превратив их в асинхронные с помощью межсервисной шины:

Проблема: DDoS на базу
Если в качестве базы данных для своего решения вы использовали PostgreSQL (больше возможностей, чем MySQL, почти такой же enterprise, как Oracle, надежно, да еще и бесплатно!), то рано или поздно начинаете понимать, что работать в web-системах с большим количеством коротко живущих подключений ему некомфортно. Ведь каждый коннект к PG — это отдельный процесс на сервере СУБД, выделяющий себе при старте не менее 8MB памяти.
Чтобы нивелировать эти негативные эффекты, умные люди придумали пулеры соединений — например, pgbouncer или Одиссей. На вход они принимают множество подключений, а на выходе кроссируют их в небольшое количество постоянно активных соединений с PostgreSQL.
В результате, наша архитектура превращается во что-то такое:
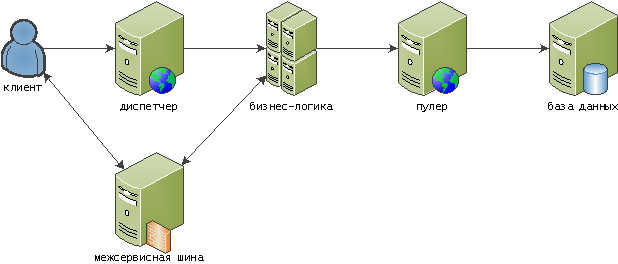
Тут мы дополнительно научили межсервисную шину общаться с клиентом для донесения оперативных событий с серверсайда, а логику представления также загнали «под диспетчер».

Ниндзя вступает в бой
Итак, с точки зрения взаимодействия с пользователем, у нас есть следующая цепочка:
браузер
диспетчер
бизнес-логика
межсервисная шина
пулер соединений
база данных
Чем более «низкое» звено в этой цепочке удастся «вальнуть», тем больше пользователей пострадает. Но начнем с самого верха…

«Роняем» браузер
Чтобы заставить Chrome затупить, существует (минимум!) три простых метода:
Заставить его выкачивать много трафика.
Скормить ему «жирный» JS-файл. Поскольку трансляция JS пока идет в том же единственном потоке, что и его исполнение, то «пусть весь мир подождет».
Заставить его сгенерировать тучу HTTP-запросов. Даже если они у вас все закэшированы, то где-то в районе 700-го запроса Chrome «ломается» и начинает отдавать файлы с дискового кэша по несколько секунд.

TODO #01: Используйте минификацию.
TODO #02: Оптимизируйте количество кода.
TODO #03: Применяйте пакетирование. И следите, чтобы оно реально использовалось.
«Роняем» диспетчер
Чем можно «прижать» диспетчер? По сути, только большим количеством запросов и/или трафика за короткое время.
Чтобы добиться такого эффекта, уже понадобится напрячься — синхронизировать большое количество клиентских браузеров, потому что с одной машины значимо нагрузить не получится.
Для этого лучше всего…
разослать некоторое событие «на всех» пользователей
повесить на его приход «мгновенную» обработку
независимо из каждой вкладки
… и запросить с сервера что-то объемное и несжимаемое (фотки, например) или сжимаемое динамически
TODO #04: Кэшируйте заголовками максимально, чтобы хотя бы часть запросов на сервер таки не долетела.
TODO #05: Убедитесь по заголовкам ответа, что диспетчер не пытается «сжимать несжимаемое» и тупить на этом — бинарники или заведомо мелкие ответы.
TODO #06: Делайте обработку события из единственной вкладки, раздавая остальным ответ через localStorage.
TODO #07: Делайте рандомизированную задержку в пределах нескольких секунд от момента прихода события на клиента до запроса на сервер.
«Роняем» бизнес-логику
Исчерпание ресурсов
Если ваша БЛ заточена под последовательную синхронную обработку каждого входящего запроса в отдельном процессе/потоке (ex: Apache, IIS), то достаточно занять их все, чтобы начала копиться очередь и расти время выполнения.
Если же БЛ у вас асинхронная (ex: NodeJS), то стоит усилить воздействие, вогнав event loop процесса в клинч чем-то вроде бесконечного цикла или множественных операций над строками.
Для этого нам отлично пригодится методика из предыдущего пункта, генерирующая тучу запросов.

TODO #08: Используйте различные варианты rate-limiter — лучше прямо на диспетчере.
Прикладной deadlock
Эффективным вариантом также будет организовать deadlock — отправить свои методы синхронно выполнять методы стороннего сервиса, а из них — снова в исходном сервисе!
TODO #09: Моделируйте возможность появления цепочек вызовов A → B → A. Нашли — избавляйтесь или обвешивайте «жесткими» таймаутами в пределах сотен миллисекунд.
«Роняем» межсервисную шину
Мультипликация данных
Сгенерировать «на вход» относительно немного сообщений с большим количеством получателей у каждого. Внутри они «помножатся», и если не «порвет» при синхронизации узлов, то «ляжет» выходной канал. Не лег — добавить получателей.
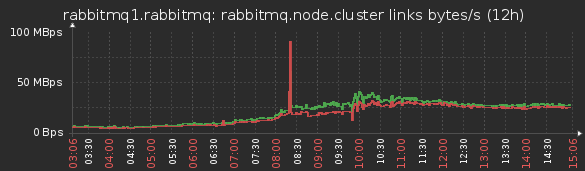
TODO #0A: А нужна ли вам тут именно общая шина обмена? Подумайте над поднятием специализированной БЛ для обмена такими событиями.
Mailbombing
Генерируем большое количество объемных сообщений в адрес другой БЛ. Вот тут точно на синхронизации узлов «порвет».
TODO #0B: Передавать не сам контент, а ссылку на него. Или смотри #0A.
«Роняем» пулер соединений
Жил-был pgbouncer в transaction mode… Почему именно в таком? Потому что именно этот режим позволяет, в большинстве случаев, наилучшим образом утилизировать соединение к БД.
А это значит, что для каждой отдельной транзакции идет новое пересопоставление «клиентского» соединения «серверному».
То есть если не «обернуть» в транзакцию, метод с тучей мелких запросов к БД, каждый из них будет восприниматься как отдельная транзакция, обрабатываться независимо на отдельном соединении, и издержки на эту обработку будут существенно выше времени самого выполнения каждого SQL-запроса.
TODO #0C: Оборачивайте свои методы в транзакции целиком, если это не противоречит прикладной задаче.
TODO #0D: Используйте session mode и prepared statements.
Автогенерируемые запросы/данные
Лучше всего заходит в комбинации с ORM, для которого в радость выдать тело запроса на пару мегабайт или IN (...) с сотней тысяч свежевычитанных из базы же идентификаторов. Для пулера это означает бесполезную трату ресурсов на перекладывание байтиков между сокетами.
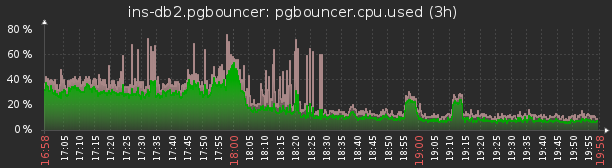
TODO #0E: Не стоит использовать ORM, пока вы детально не понимаете, как он работает.
«Роняем» базу данных
Настоящее раздолье для ценителя.
DDoS
«А давайте в нашем методе делать X на базе одновременно в несколько потоков!» И в нескольких процессах БЛ, до кучи… и без разумного ограничителя количества процессов-потоков.
Точно-точно надо именно одновременно? В таком-то количестве? А #6 и #7 — не ваш ли вариант?…
«Ладно, у нас будет не больше Y одновременных запросов…» Ага, зато каждый читает гигабайты данных из кэша БД — тут-то пропускная способность памяти и кончается…
TODO #0F: Используйте кэширование ответов на стороне БЛ.
TODO #10: Оптимизируйте уже свои запросы! См. статью »Рецепты для хворающих SQL-запросов».
Блокировки
»Ну, я тогда сейчас заблокирую!… advisory locks не просто так мне даны! … и тысячи их! »

TODO #11: pg_try_advisory_xact_lock — при завершении транзакции снимаются автоматически. См. статью »Фантастические advisory locks, и где они обитают».
»Мне надо поменять поле/накатить индекс прямо сейчас! » и компания ALTER TABLE.
TODO #12: См. статью »DBA: когда почти закончился serial».
TODO #13: В целом, активность разных «ниндзя-разработчиков» на базе стоит мониторить и анализировать всегда. Как это делаем мы в «Тензоре» можно прочитать в статьях «Мониторим базу PostgreSQL — кто виноват, и что делать» и «Массовая оптимизация запросов PostgreSQL».
В общем, проверяйте почаще, что ваши ниндзя все еще работают именно на вас.

