Внутри S3. Доклад Яндекса
Привет, я Паша, разработчик в Yandex Infrastructure, и я катаю гусей. С 2019 года я развиваю S3-хранилище как для внутренних пользователей Яндекса, так и для клиентов Yandex Cloud. А «гусём» называется наш бэкенд S3 API: он написан на Go, а из словосочетания Go + S3 получился goose. Возможно, вы также слышали про GeeseFS — это наш высокопроизводительный FUSE‑клиент для S3. C его помощью вы можете на своём ноутбуке или виртуалке подмонтировать папку, которая будет работать с бакетом S3.
Для чего нам «гуси» и прочая орнитология? Яндексовая инсталляция хранилища S3 хранит миллиарды файлов. Это огромные объёмы данных, а также метаданных. Для хранения метаданных мы научились использовать умное шардирование, и теперь сами управляем распределением занятого места и нагрузкой между шардами баз.
Так что сегодня я расскажу, как сделать так, чтобы ни один клиент, даже с самым неудобным паттерном нагрузки, не положил сервис.
Продумываем собственную реализацию S3
Протокол Simple Storage Service за многие годы стал стандартом объектного облачного хранилища. Когда мы создавали свою реализацию S3, то понимали, что в ней будет храниться огромное количество объектов, будет идти высокая нагрузка по RPS, поэтому нам нужно было сразу уметь масштабироваться по этим параметрам.
Разумеется, наш сервис должен быть отказоустойчивым: при выпадении любого хоста и даже целого дата‑центра он должен продолжить работать и обслуживать нагрузку от клиентов. И, конечно, сервис должен быть консистентным. Если пользователь залил в сервис какой‑то файлик, то следующий запрос на чтение или на листинг должен этот файлик вернуть.
Это очевидные запросы к хорошему сервису, но на масштабе появляются новые трудности. Типичные требования крупного клиента S3 — больше миллиарда объектов в бакете общим объёмом больше одного Пб и нагрузка больше одной тысячи RPS. Сейчас у самых крупных клиентов Yandex Cloud значения этих показателей в десятки раз больше. А всего в наших инсталляциях сейчас сотни миллиардов объектов, сотни Пб и сотни тысяч RPS.
Для примера — график RPS‑запросов от наших клиентов в Yandex Cloud за последний год.

За 12 месяцев нагрузка выросла в два раза и в пике достигала больше 120 тысяч RPS
Начнём с очень простой, даже примитивной схемы устройства нашего сервиса. Мы храним отдельно метаданные и отдельно данные. В качестве хранилища метаданных используем PostgreSQL, а для данных — сервис MDS (MeDia Storage). И наш бэкенд‑гусь отдельно ходит за метаданными и за данными.
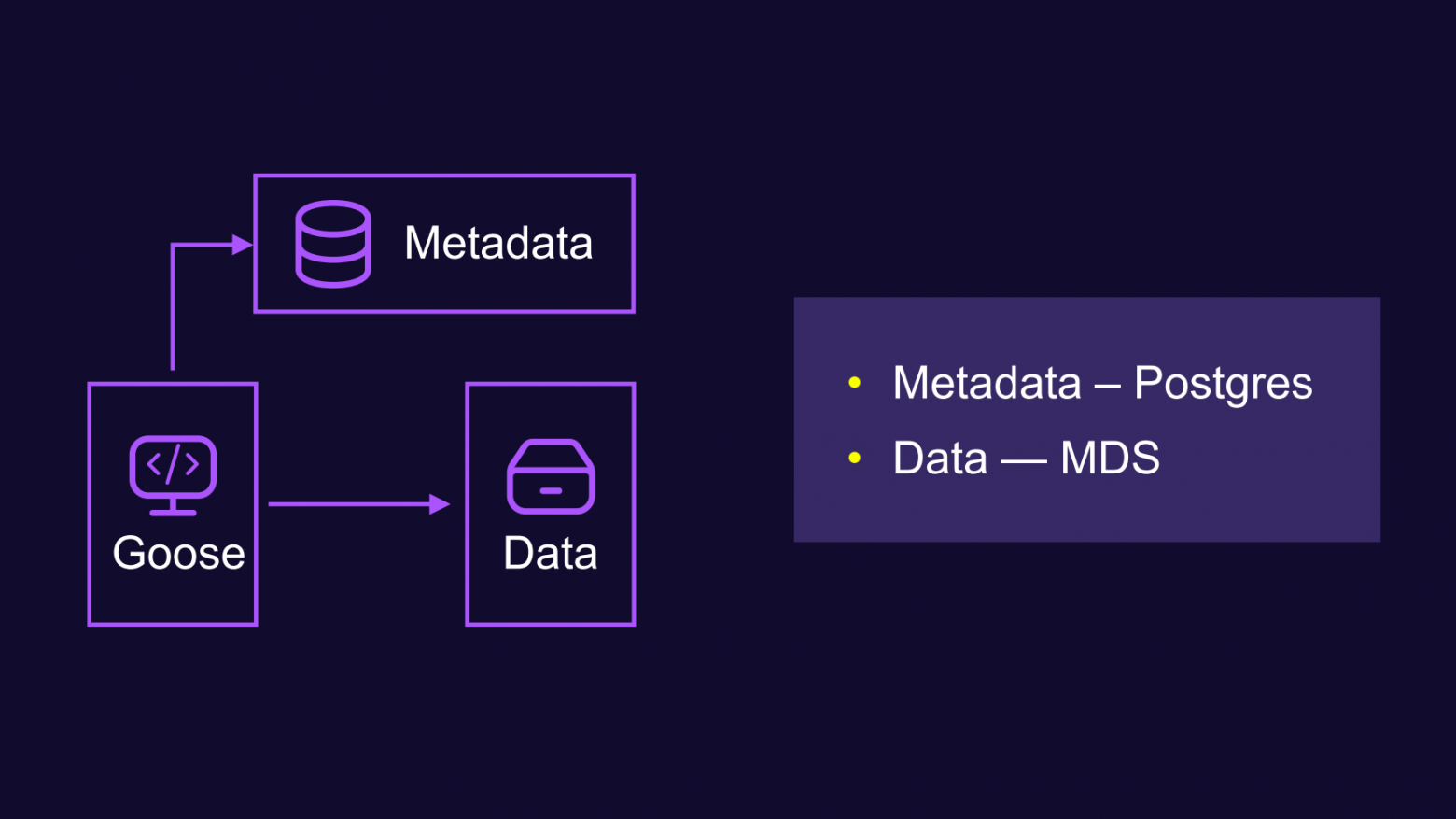
Чуть подробнее про хранилище данных.
MDS — низкоуровневый сервис, который работает напрямую c жёсткими дисками. Раньше он использовался для хранения медиафайлов, а впоследствии стал универсальным хранилищем для всех типов данных.
Этот сервис был создан внутри Яндекса нашей командой примерно десять лет назад. Его клиенты — другие сервисы Яндекса, например, Диск, Почта и другие, собственно, и наш S3. За годы он зарекомендовал себя как надёжное и масштабируемое хранилище.
Немного цифр про MDS:

Если хочется узнать больше про MDS, можно обратиться к докладу с Saint HighLoad++.
А я подытожу: когда мы создавали свою реализацию S3, у нас уже было идеальное низкоуровневое хранилище. Нам нужно было только создать поверх него протокол S3, и суть этой самой прослойки S3 — в метаданных, точнее, в умении их хранить и обрабатывать.
Запускаем умное шардирование
Посмотрим на более подробную схему сервиса.

Запрос от пользователя приходит на балансировщик, который перенаправляет запрос на какого‑то конкретного гуся. Гусь ходит в метабазу PostgreSQL, получает оттуда метаданные по объекту и путь объекта в MDS, идёт в MDS, читает данные и возвращает данные клиенту.
При создании своей реализации S3 мы понимали, что в одном бакете может лежать огромное количество ключей. Бакетов много, и рано или поздно все данные не влезут на один сервер PostgreSQL. Поэтому очевидно, что нам нужно шардирование, то есть возможность хранить разные куски данных на разных шардах.
Один шард PostgreSQL — это мастер плюс две реплики. Мастер находится в одном дата‑центре, одна реплика — в другом дата‑центре, ещё одна реплика — в третьем.
Мы используем кворумную репликацию. Это значит, что когда на мастер приходит какой‑то пишущий запрос, он записывает эти данные к себе, а также ждёт, пока эти же самые данные будут записаны ещё хотя бы на одну реплику. В случае если мастер падает, то происходит автоматическое переключение мастера на самую актуальную реплику без потери данных.
Как именно разместить разные куски данных на разных шардах? Если лексикографически расположить всё пространство имён объектов от пустой строки до бесконечности и разбить эту прямую на кусочки, то вот эти кусочки мы называем чанки (chunk).

Чанк — это диапазон имён ключей бакета. И вот эти самые чанки мы можем хранить на разных шардах.
Следующая задача — придумать, по какому правилу распределять эти чанки на разных шардах. Тут часто встречаются два варианта.
Статическое шардирование. Это популярный подход, когда мы берём хэш от сущности, затем берём остаток от деления на количество шардов и таким образом понимаем, на каком шарде должна лежать эта сущность.
Но здесь есть некоторые минусы:
В этом случае сложно управлять нагрузкой. Если нагрузка от клиентов совпала таким образом, что какой‑то шард начинает перегружаться по месту или по CPU, то в моменте сложно что‑то с этим сделать.
И также в этой схеме сложно делать решардинг, то есть накидывать новых шардов в инсталляцию. Если нужно докинуть новых шардов, то нужно все данные как‑то перешадировать.
Поэтому мы использовали другой подход.
Динамическое шардирование. Чанк может лежать на совершенно произвольном шарде. Маппинг, где какой чанк лежит, мы сохраняем в отдельную метабазу.

На схеме для примера изображены чанки какого‑то бакета. На первом шарде лежат два чанка этого бакета, на втором шарде два чанка этого бакета, на третьем шарде вообще нет чанков этого бакета, на четвёртом и пятом шарде по одному чанку.
Вот этот маппинг мы и сохраняем отдельно. Это даёт нам возможность легко управлять нагрузкой. Если какой‑то шард начинает перегружаться по месту или по CPU, то мы просто переносим чанки с этого шарда на другие, менее нагруженные.
В этой схеме нам легко делать решардинг. То есть если нам нужно докинуть новых шардов, мы просто их добавляем, они какое‑то время лежат пустыми. Потом мы постепенно переносим на них чанки, и на них начинает идти нагрузка. Таким образом мы можем накидывать шарды без всякого даунтайма.
Добавляем вспомогательные процессы
Для работы схемы нам понадобилось несколько поддерживающих фоновых процессов. Самый важный из них — это mover. Когда один шард начинает перегружаться по месту или по CPU, то mover переносит чанки с этого шарда на другой, менее нагруженный шард.
Для примера возьмём чанки бакета из примера выше. Допустим, второй шард начинает перегружаться по месту или по CPU. В этот момент приходит mover и переносит чанк. Например, переносит чанк от буквы Y до буквы Z на третий шард, который менее загружен.

Mover запущен на нескольких серверах. Он перемещает параллельно с разных шардов, но с одного шарда в один момент времени возможен только один мув.
Теперь чуть более детально, как работает mover.
Сначала он блокирует чанк на запись, потом копирует объекты в новый шард, удаляет объекты из старого шарда и разблокирует чанк на запись. Блокировка нужна для поддержания консистентности, чтобы перенести на другой шард абсолютно все объекты, которые пользователь мог заливать в этот чанк.
Mover использует двухфазный коммит. Он работает с разными шардами, и тут не может быть какой‑то одной единой транзакции. Есть краевой случай, когда, например, mover в середине своей работы падает и остаётся висящий двухфазный коммит как отдельный процесс. Потом приходит отдельный процесс, смотрит состояние этого коммита на разных шардах и в зависимости от состояния либо откатывает везде, где надо, либо, наоборот, коммитит везде, где надо.
Mover работает единицы секунд. Во время его работы запросы на чтение продолжают выполняться, а запросы на запись покрываются ретраями бэкенда. Почему mover должен работать вот это самое короткое время? Когда пользователь натыкается на работу с чанком, который сейчас перевозит mover, важно, чтобы пользователю недолго было ждать вот этот запрос, пока бэкенд ретраит во время работы mover.
Чтобы наша схема работала и мув чанка происходил достаточно быстро, почти незаметно для пользователя, чанки должны быть небольшими.
Экспериментально мы выяснили, что чанки должны быть порядка 100 тысяч объектов. Поэтому для работы нашей схемы нам нужен ещё один вспомогательный процесс — это splitter.
Splitter приходит и делит большие чанки на более маленькие чанки.

Вот для примера на схемке чанки какого‑то бакета. Допустим, клиент каким‑то таким образом подавал нагрузку, что чанк от буквы C до буквы Y разросся, стал большим. И в этот момент приходит splitter и делит этот чанк на два кусочка поменьше.
Тоже более детально, как работает splitter.
Он блокирует чанк на запись, определяет границы деления, пересчитывает объекты в одном кусочке, в другом кусочке. После этого делит чанк на два маленьких кусочка, и затем разблокирует чанк. Здесь блокировка нужна для поддержания консистентности счётчиков. Про счётчики я расскажу чуть позже.
Splitter тоже работает быстро — единицы секунд и даже быстрее. Пока он работает, чтение работает, а запись покрывается ретраями бэкенда.
Есть разные возможные политики деления чанка.
Примитивная политика — это делить чанк пополам. Но мы в основном используем политику деления 80/20 процентов. Достаточно частый паттерн записи клиента, когда он больше пишет возрастающие ключи, допустим, больше пишет в конец чанка. Поэтому здесь могут быть разные политики.
У нас есть несколько типов баз данных.
s3meta. На ней как раз-таки хранится тот самый mapping чанков, на каком шарде какой чанк лежит. Кроме того, на s3meta лежит информация по бакетам и статистика по количеству и по размеру.
s3meta у нас тоже имеет возможность шардироваться, но в текущих инсталляциях нам этого не требуется, поэтому нам хватает одного шарда s3meta.s3db. Это уже те самые основные шарды, на которых лежат чанки, на которых лежат объекты. Иначе говоря, там лежит информация по каждому объекту: имя, метаданные и путь объекта в MDS. Этих шардов у нас как раз много, десятки.
pgmeta. Она служит для Discovery. В ней хранится список шардов s3meta и s3db. Гусь на старте получает только параметры подключения к pgmeta, потом уже ходит в pgmeta, получает списки шардов и устанавливает подключение к каждому отдельному шарду.
В итоге нужно показать ещё чуть более детальную схему нашего сервиса с уклоном на работу с базой данных.

Запрос от пользователя приходит на балансировщик, который перенаправляет на гуся. Гусь когда‑то давно уже сходил в pgmeta, получил списки всех шардов. После этого он идёт в s3meta, чтобы понять, в каком чанке лежит запрашиваемый объект и на каком шарде этот чанк лежит. И после этого он идёт уже в нужный ему шард s3db.
На этой картинке он идёт во второй шард, в s3db02, получает там информацию по запрашиваемому объекту, метаданные, путь в MDS, идёт в MDS, читает данные, возвращает данные клиенту.
Улучшаем счётчики
Ещё одна важная задача, которую нам нужно было уметь решать, — это уметь оперативно понимать, сколько всего у пользователя в бакете лежит объектов по количеству и по размеру. Это нужно:
для пользователя, чтобы он мог видеть, сколько у него в бакете объектов;
для определения квоты, можно или нельзя очередной новый объект записать, не превысили ли мы квоту;
на уровне отдельных чанков — для работы наших фоновых процессов, splitter и mover.
Примитивный подход — это на каждый запрос обновлять счётчик. Допустим, пользователь записал файлик, мы обновили счётчик, там удалил файлик — обновили счётчик. Этот подход имеет минусы: когда нагрузка от клиента становится достаточно высокой, то разные запросы начинают конкурировать, начинают хотеть обновить одну и ту же строчку, ждут друг друга. Начинают страдать тайминги. Поэтому мы использовали другой подход.
Мы использовали очередь счётчиков. Когда пользователь делает какое‑то мутирующее действие, то мы сохраняем запись об этом событии в отдельную очередь. Например, залил объект — мы пишем «плюс один объект, плюс 15 мегабайт». Удалил объект — пишем «минус один объект, минус два мегабайта». И потом отдельный фоновый процесс схлопывает эту очередь и обновляет уже исходные счётчики.
Это избавило нас от конкурентности, от блокирования разных запросов на одной и той же строчке.
И ещё одна задача, которую нам нужно было уметь решать, — это биллинг. В Yandex Cloud мы тарифицируем все объекты в бакете с точностью до байтосекунды. Если у пользователя в бакете какой‑то объект пролежал, например, пятнадцать минут и пять секунд, то мы должны забиллить этот объект ровно за это время с точностью до секунды, а не за час, не за сутки и так далее.
И эту задачу нам также помогает решать тот же самый процесс, который схлопывает очередь.

Этот процесс видит и понимает, в какую точно секунду объект был добавлен и в какую секунду объект был удален. Это даёт нам возможность считать биллинг с точностью до байтосекунды.
Избавляемся от неприятных паттернов
В целом уже всё хорошо, и та архитектура, про которую я рассказал, даёт нам возможность неограниченно масштабироваться. Но всё‑таки есть некоторые паттерны, которые нам мешают.
Запись по временной метке. Самый очевидный неприятный паттерн для нас — это когда клиент записывает объекты в бакет и использует timestamp в качестве ключа. Это могут быть логи, это могут быть ещё какие‑то события. В этом случае все ключи, которые записывает клиент, всё время монотонно возрастают, каждый следующий больше предыдущего. В этом случае вся нагрузка от клиента идёт в самый последний чанк.
А раз это идёт в какой‑то конкретный чанк, то, значит, и в какой‑то конкретный шард. И это плохо, потому что это не даёт нам возможности размазывать нагрузку от этого клиента и масштабироваться.
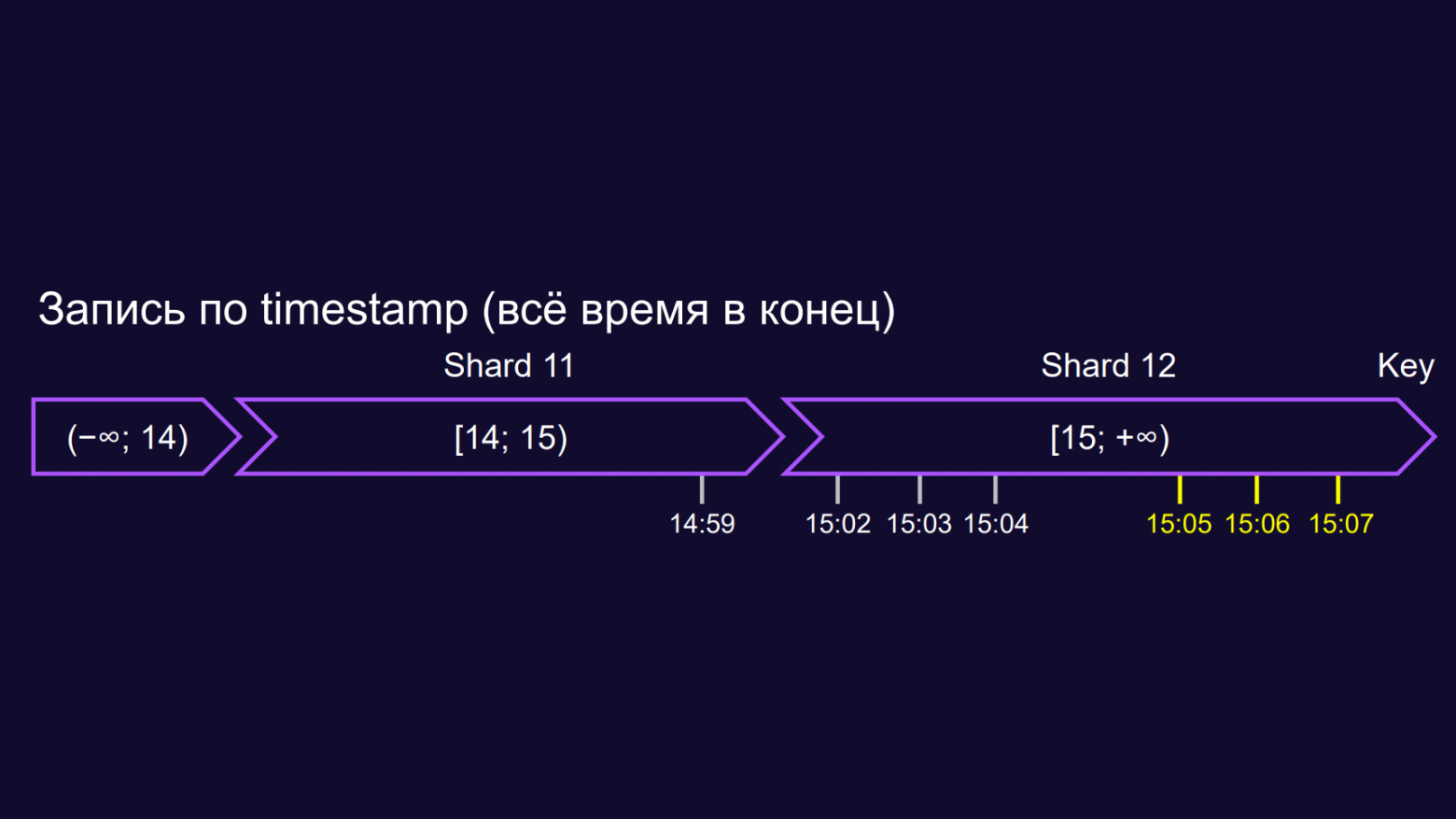
Пример паттерна на схеме: есть три чанка от пустой строки до 14, от 14 до 15 и от 15 до плюс бесконечности.
Клиент пишет 14.59 — и попадает в средний чанк.
Но потом идут 15.02, 15.03, 15.04, 15.05 — все эти последующие запросы попадают в последний чанк, в какой‑то конкретный шард.
Если нагрузка от клиента достаточно большая, разные запросы могут иметь разный вес. Но порядок — это сотни RPS или тысяча RPS от клиента, которые могут заставить шард деградировать. Начнут страдать другие пользователи, начнут расти тайминги и так далее.
Запись по алфавиту. Вот пример графика нагрузки от клиента со сходным неприятным паттерном. Это похожий случай, когда клиент ходит по алфавиту.

Разными цветами на графике изображена нагрузка в разные шарды. Видимо, клиент полистил все свои файлики и что‑то с ними делает подряд. То есть видно, что в каждый момент времени вся нагрузка приходится в какой‑ то один шард. Потом что‑то меняется, вся нагрузка начинает идти в другой шард, потом в третий, потом снова в первый. И это плохо, потому что в этом случае мы не можем размазать нагрузку от этого пользователя.
Как решить и что учесть
Здесь нам на помощь приходят ханки. Вот большой и сильный гусь, который прёт вперёд благодаря ханкам.

Что такое ханки? Если чанк — это диапазон имён ключей бакета, то ханк — это диапазон хэшей имён ключей. Ханк — сокращение от hash chunk. Если графически расположить не пространство имен, а пространство хэшей и разбить эти хэши на кусочки, то вот эти кусочки — и будут ханки.

Теперь уже эти ханки мы можем хранить на разных шардах. Посмотрим на тот же самый паттерн от клиента, который пишет всё время последовательно.
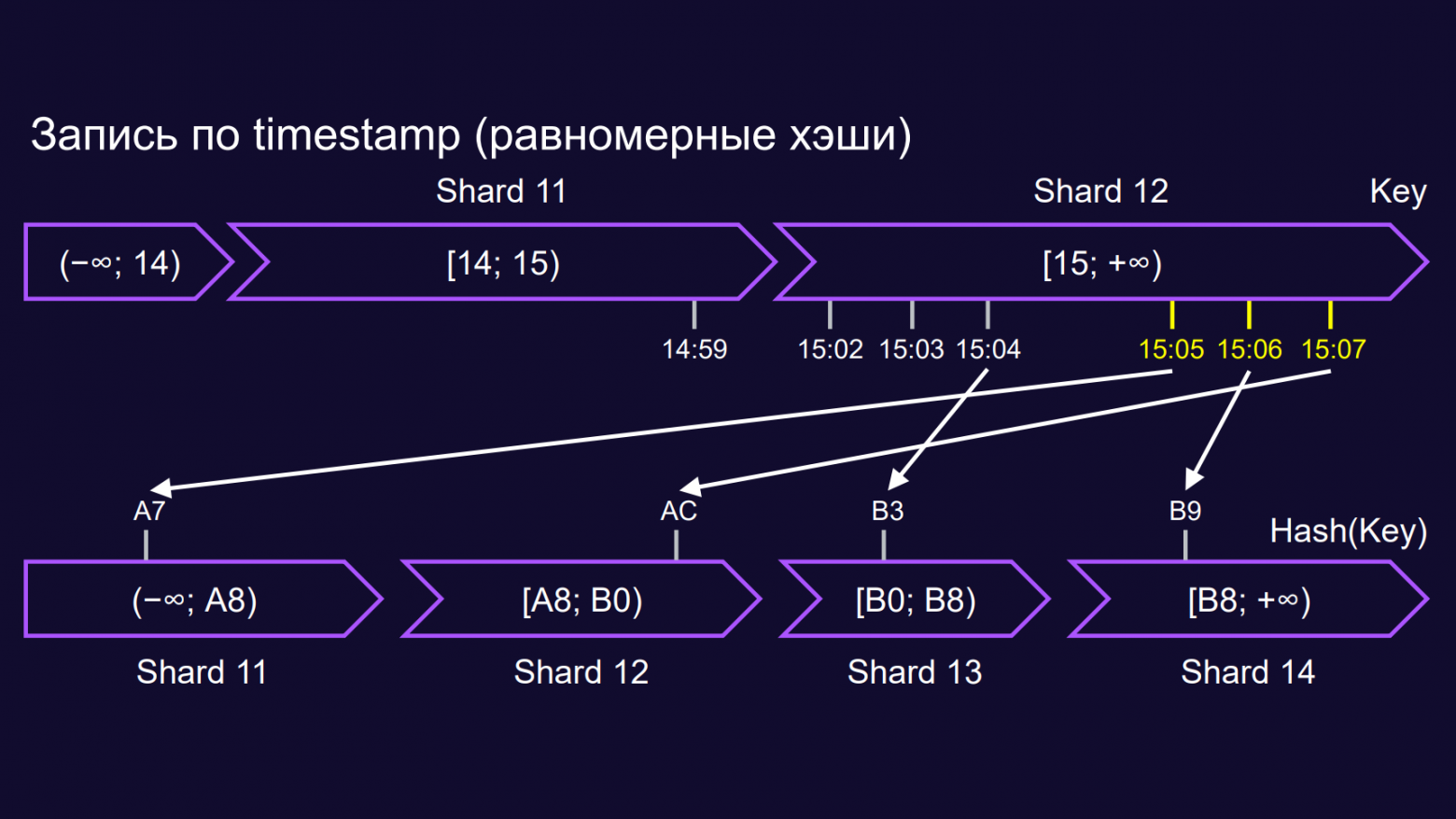
Если ключи 15:04, 15:05, 15:06 шли подряд и попадали в один чанк, то хэши от этих ключей попадают в совершенно различные ханки и, соответственно, в рандомные шарды. Происходит автоматическое равномерное распределение нагрузки.
Теперь посмотрим на график нагрузки бакета, где всё по алфавиту. Видим важный момент, когда мы перевезли бакет в ханки.
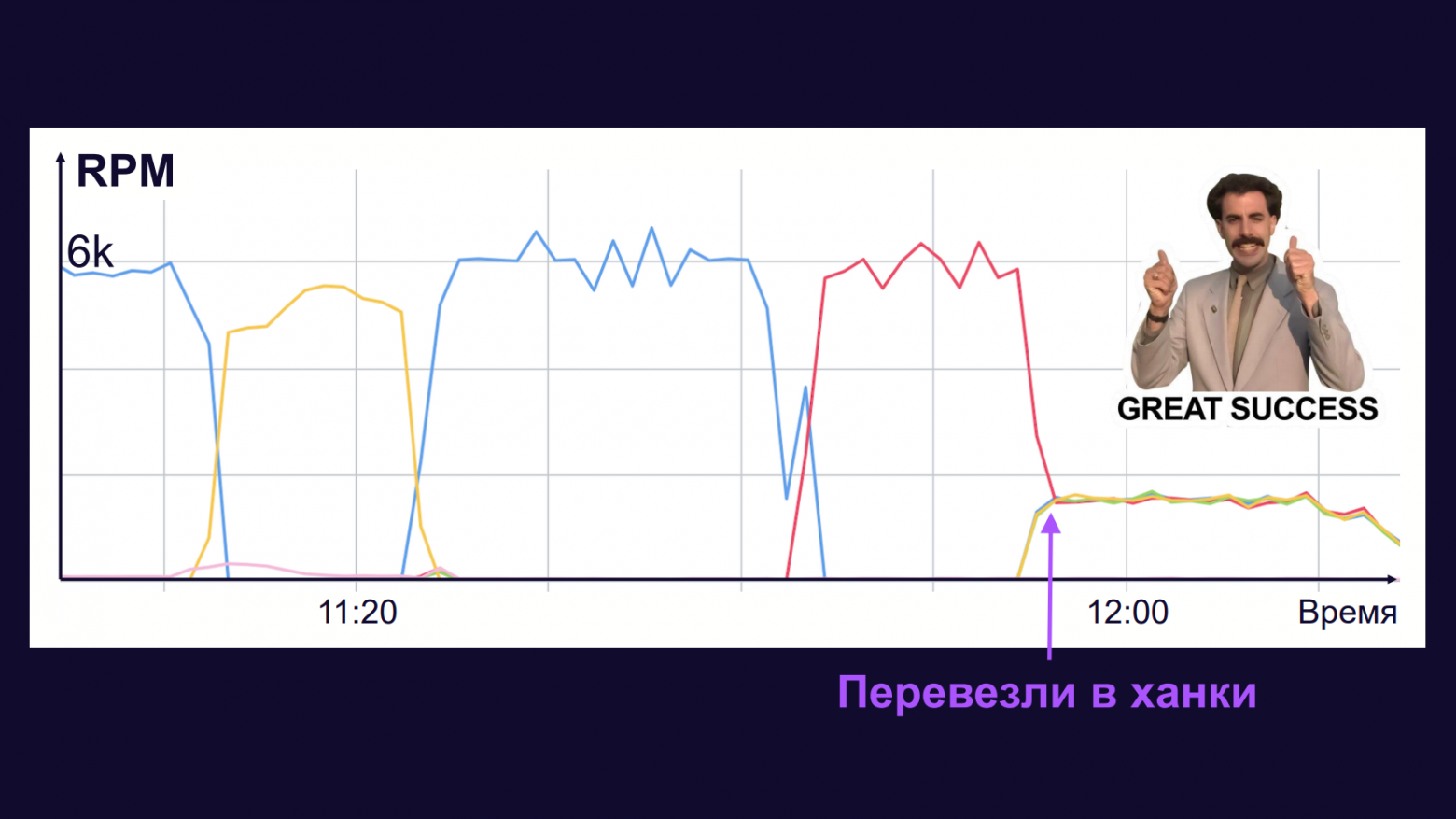
Нагрузка пошла равномерно сразу на несколько шардов. И абсолютное значение этой нагрузки снизилось в несколько раз на каждый отдельный конкретный шард.
Осталось учесть некоторые изменения, которые происходят при переходе на модель ханков.
Изменения в запросах листингов. Листинг — это клиентский запрос на список ключей. В модели по чанкам в ответ на запрос листинга мы могли ходить только на часть шардов бакета, а на оставшуюся часть шардов не ходить, — если мы понимаем, что на оставшихся шардах не может быть ключей, удовлетворяющих параметрам запроса.
В случае модели с ханками нам нужно всегда ходить на все шарды, собирать листинг со всех шардов. Но поскольку в модели с ханками бакеты умещаются на меньшем количестве шардов благодаря равномерному размазыванию нагрузки, то этот минус нивелируется.
Изменения в том, как работает mover. В модели с чанками mover работает точечно: привозит какие‑то конкретные чанки, развозит конкретные шарды.
В модели с ханками всё иначе. Если мы понимаем, что нагрузка от бакета на шарде превышает какой‑то порог, то mover просто удваивает количество шардов, на котором присутствует бакет. Допустим, бакет лежал на четырех шардах, mover размазывает его по восьми шардам.
Таким образом, нагрузка автоматически размазывается на в два раза большее количество шардов, а на каждом отдельном шарде становится в два раза меньше.
Так ханки стали для нас решением всех проблем с балансировкой. Они дают нам автоматическое равномерное размазывание нагрузки, и мы всё ещё сами управляем занятостью и загруженностью шардов: можем свободно продолжать делать решардинг, то есть накидывать новых шардов в инсталляцию без всякого даунтайма.
Я катаю гусей уже много лет. Если у вас есть вопросы, буду рад на них ответить.
