Внедрение Git в корпоративную систему разработки

Разработчиков, которые знают и умеют работать с git, за последнее время выросло на порядок. Привыкаешь к скорости выполнения команд. Привыкаешь к удобству веток и легкого отката изменений. Разрешение конфликтов настолько обыденно, что программисты привыкли к героическому разрешению конфликтов там, где их быть не должно.
Наша команда в Directum разрабатывает инструмент разработки для платформенных решений. Если вы видели 1С, то примерно сможете представить рабочее окружение наших «клиентов» — прикладных разработчиков. С помощью этого самого инструмента разработки прикладной разработчик создает прикладное решение для заказчиков.
Перед нашей командой встала задача упростить жизнь нашим прикладникам. Мы разбалованы современными фишками из Visual Studio, ReSharper и IDEA. Прикладники требовали от нас внедрить в инструмент работу с git «из коробки».
Сложность то вот в чем. В инструменте на каждый тип сущности (договор, отчет, справочник, модуль) могла присутствовать блокировка. Один разработчик начинал редактировать тип сущности и блокировал его до тех пор, пока не завершит изменения и не закомитит их на сервер. Остальные разработчики в это время просматривают тот же тип сущности только на чтение. Разработка чем-то напоминала работу в SVN или пересылку документа Word по почте между несколькими пользователями. Хочется сразу всем, а может только один.
У каждого типа сущности может быть много обработчиков (открытие документа, валидация перед сохранением, запись в БД), в которых требуется написать код, который работает с конкретным экземпляром сущности. Например, заблокировать кнопки, отобразить пользователю сообщение или создать новое задание исполнителям. Весь код в рамках API, предоставляемого платформой. Обработчики — классы, в которых лежит много методов. Когда двум людям было необходимо поправить один и тот же файл с кодом, сделать это не представлялось возможным, потому что платформа блокировала тип сущности целиком вместе с зависимым кодом.
Наши прикладники пошли во все тяжкие. Они тихонько форкнули себе «нелегальную» копию нашей среды разработки, закоментировали часть с блокировками и мержили к себе наши коммиты. Прикладной код держали под гитом, коммитили через сторонние инструменты (git bash, SourceTree и прочие). Мы сделали свои выводы:
- Наша команда недооценила готовность прикладных разработчиков влезть в платформу. Огромное уважение и почет!
- Решение, предложенное ими, на продакшен не годится. С git у человека развязаны руки и он способен сотворить всё, что угодно. Поддерживать всё многообразие будет глупо, не угонимся. К тому же придется обучить заказчиков платформы. Задокументировать все команды git применительно к платформе свело бы команду документирования с ума.

Значит отдавать на продакшен гитом наружу не годится. Решили как-то инкапсулировать логику основных операций и ограничить их количество. По крайней мере для первого релиза. Список команд сокращали как могли и остались:
- status
- commit
- pull
- push
- reset --hard к HEAD
- reset к последнему «серверному» коммиту
Для первого релиза от работы с ветками решили отказаться. Не то, чтобы это очень сложно, просто команда не уложилась в ресурс времени.
Периодически наши партнёры присылают свою прикладную разработку и спрашивают: «У нас что-то не работает. Что мы делаем не так?». В этом случае прикладник загружает себе чужую разработку и глядит в код. Раньше это работало так:
- Разработчик забирал себе архив с разработкой;
- Изменял в конфигах локальную БД;
- Заливал чужую разработку к себе в базу;
- Отлаживал, находил ошибки;
- Выдавал рекомендации;
- Возвращал свою разработку назад.
Новая методология не укладывалась в старый подход. Пришлось поломать голову. Команда предложила два подхода для решения этой проблемы:
- Хранить все разработки в одном git-репозитории. При необходимости работы с чужим решением создавать временную ветку.
- Хранить разработки разных команд в разных репозиториях. Вынести настройки загружаемых в среду папок в конфигурационный файл.
Решили идти по второму пути. Первый показался сложнее в реализации и к тому же, легче выстрелить себе в ногу с переключениями веток.
Но и со вторым тоже не сладко. Команды, которые описаны выше, должны работать не просто в пределах одного репозитория, а сразу с несколькими. Есть изменения в типах сущностей из разных репозиториев? Мы показываем их в одном окошечке. Так удобнее и прозрачно для прикладного разработчика. Нажимая кнопку commit, инструмент фиксирует изменения в каждом из репозиториев. Соответственно команды pull/push/reset «под капотом» работают с физически разными репозиториями.

Для работы с git выбирали из двух вариантов:
- Работать с git, установленным в системе, дёргая его через Process.Start и разбирая вывод.
- Использовать libgit2sharp, который через pinvoke дёргает библиотеку libgit2.
Нам показалось, что использовать готовую библиотеку — разумное решение. Зря. Чуть позже расскажу почему. На первых порах библиотека дала нам возможность быстро выкатить рабочий прототип.
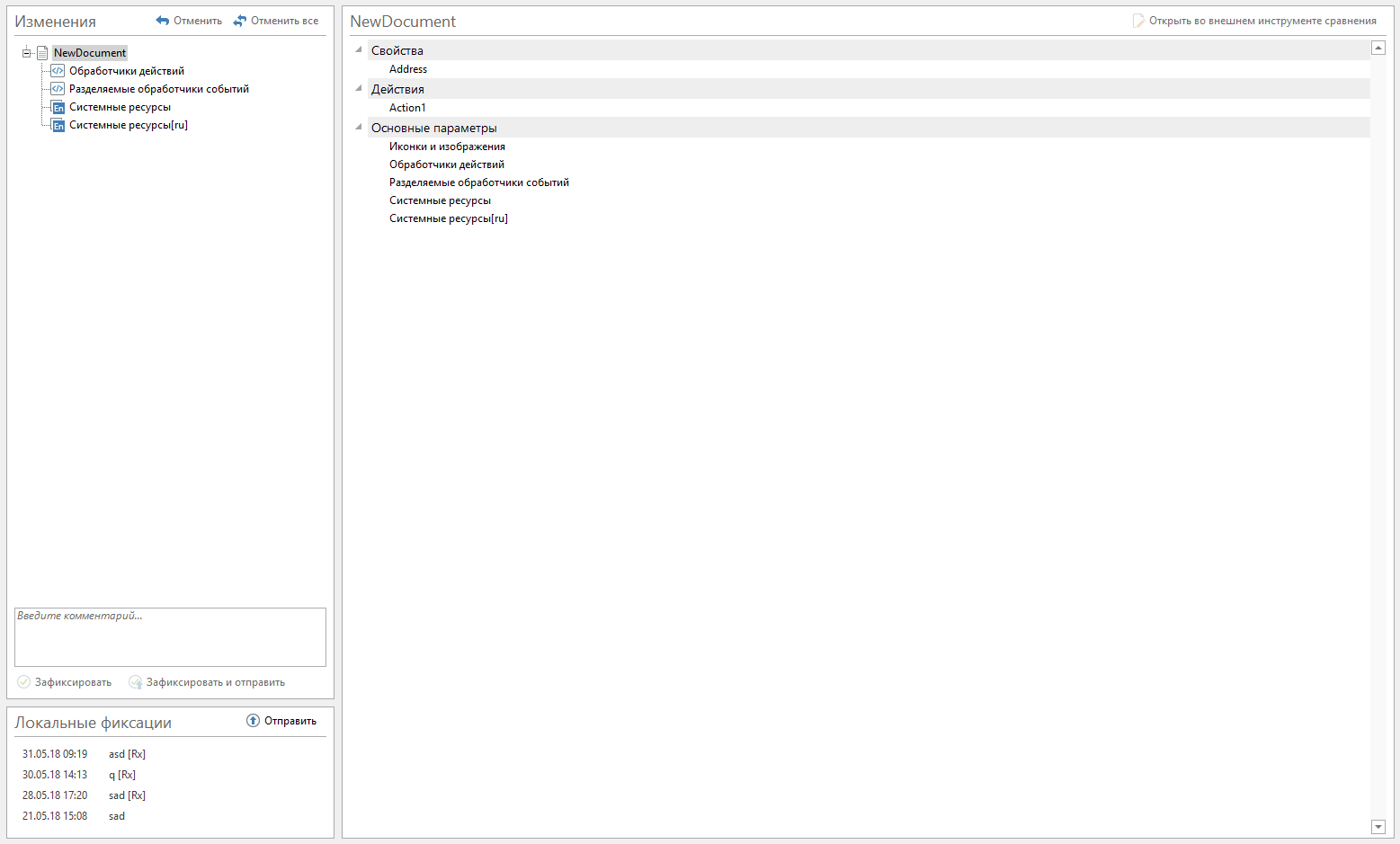
Удалось реализовать примерно за месяц. На самом деле прикручивание гита было быстрым, а большую часть времени мы пытались вылечить вскрытые раны из-за того, что выпилили старый механизм хранения исходных файлов. В интерфейс просто отдавали всё, что возвращал git status. При клике на каждый файл отображается diff. Выглядело как интерфейс git gui.
Первый вариант оказался чрезмерно информативен. С каждым типом сущности связано сразу много файлов. Эти файлы создавали шум, и становилось неясно, какие же типы сущности изменились и что конкретно.
Сгруппировали файлы по типам сущности. Каждому файлу дали человекочитаемое имя, такое же как и в GUI. Метаданные типа сущности описаны в JSON. Их тоже нужно было представить в человекочитаемом формате. Анализ изменения в версиях json «до» и «после» начали с помощью библиотеки jsondiffpatch, а затем написали собственную реализацию сравнения JSON (далее буду называть jsondiff). Результаты сравнения прогоняем через анализаторы, которые выдают человекочитаемые записи. Много файлов скрыли с глаз, оставляя простую запись в дереве изменений.
Конечный результат получился таким:
Libgit2 выдал большое количество неожиданных сюрпризов. Разобраться с некоторыми оказалось не под силу в разумное время. Расскажу, что вспомню.
Неожиданные и трудновоспроизводимые падения на некоторых стандартных операциях. «No error provided by native library» говорит нам обёртка. Прекрасно. Чертыхаешься, пересобираешь нативную библиотеку в debug, повторяешь упавший ранее кейс, а оно в debug режиме не падает. Пересобираешь в release и снова падает.
Если с libgit2sharp параллельно запущен сторонний инструмент, скажем SourceTree, то commit может не закоммитить некоторые файлы. Или зависает при отображении диффов на некоторых файлах. Как только пытаешься отладить, не получается воспроизвести.
У одного из наших прикладников выполнение аналога git status занимало 40 секунд. Сорок, Карл! При этом запущенный из консоли гит отрабатывал как положено в течение секунды. Я потратил пару дней, чтобы разобраться. Libgit2 при поиске изменений глядит на файловые атрибуты папок и сравнивает их с записью в индексе. Если время модификации отличается, значит внутри папки что-то изменилось и нужно заглянуть внутрь и/или поискать в файлах. А если ничего не менялось, то и внутрь лезть не стоит. Эта оптимизация видимо есть и в консольном git. Не знаю по какой причине, но именно у одного человека в индекс git изменялся mtime. Из-за этого git каждый раз проверял на наличие изменений содержимое ВСЕХ файлов в репозитории.
Ближе к релизу наша команда прогнулась под пожелания прикладников и заменили git pull на fetch + rebase + autostash. И тут к нам приехало ещё куча багов, в том числе и с «No error provided by native library».
status, pull и rebase работают заметно дольше вызова консольных команд.
Файлы в разработке делятся на два типа:
- Файлы, которые прикладник видит в инструменте разработки. Например, код, изображения, ресурсы. Такие файлы нужно мержить так, как это делает git.
- Файлы JSON, которые создаются средой разработки, но прикладной разработчик их видит только в виде GUI. В них требуется автоматически разрешить конфликты.
- Генерируемые файлы, которые автоматически пересоздаются при работе с инструментом разработки. В репозитории эти файлы не попадают, инструмент сразу заботливо кладёт .gitignore.
С новым укладом два разных прикладника смогли изменить один и тот же тип сущности.
Например, Саша изменит информацию о том, как хранить тип сущности в базе данных и напишет обработчик события сохранения, а Сергей стилизует представление сущности. С точки зрения git это конфликтом не будет и оба изменения сольются без сложностей.
А потом Саша изменил свойство Property1 и задал ему обработчик. Сергей создал свойство Property2 и задал обработчик. Если посмотреть на ситуацию сверху, их изменения не конфликтуют, хотя с точки зрения git затронуты одни и те же файлы.
Захотелось, чтобы инструмент смог самостоятельно разрулить подобную ситуацию.
Примерный алгоритм слияния двух JSON при возникновении конфликта:
-
Загружаем из гита JSON base.
-
Загружаем из гита JSON ours.
-
Загружаем из гита JSON theirs.
-
Используя jsondiff, формируем программные патчи base→ours и применяем к theirs. Получившийся JSON назовём P1.
-
Используя jsondiff, формируем программные патчи base→theirs и применяем к ours. Получившийся JSON назовём P2.
-
В идеале после применения патчей P1 === P2. Если это так, то записываем P1 на диск.
- В неидеальном случае (когда действительно нашелся конфликт) предлагаем пользователю выбрать между P1 и P2 с возможностью допилить руками. Записываем выбор на диск.
После слияния проверяем, пришли ли к состоянию без ошибок валидации. Если не пришли, то отменяем такое слияние и просим пользователя повторить. Это не лучшее решение, но оно хотя бы гарантирует, что со второй или третьей попытки слияние произойдет без неприятных последствий.
- Прикладники довольны, что могут легально пользоваться.
- Внедрение git ускорило разработку.
- Автоматические слияния вообще выглядят как магия.
- Заложим на будущее отказ от libgit2 в пользу вызова процесса git.
