Визуальный граф вызовов: VTune Amplifier и не только
Многим нравится представление структуры программы в виде call graph, «графа вызовов функций». Особенно интересно, если этот граф отражает профиль производительности, наиболее «горячие» ветки кода.Граф вызовов можно получить с помощью Intel® VTune™ Amplifier XE, но для этого нам понадобится ещё пара утилит.
 Сначала о базовом функционале. Представление данных профиля производительности — одна из самых мощных вещей в арсенале VTune Amplifier. Изучить дерево вызовов можно на вкладке Caller/Callee:
Сначала о базовом функционале. Представление данных профиля производительности — одна из самых мощных вещей в арсенале VTune Amplifier. Изучить дерево вызовов можно на вкладке Caller/Callee:
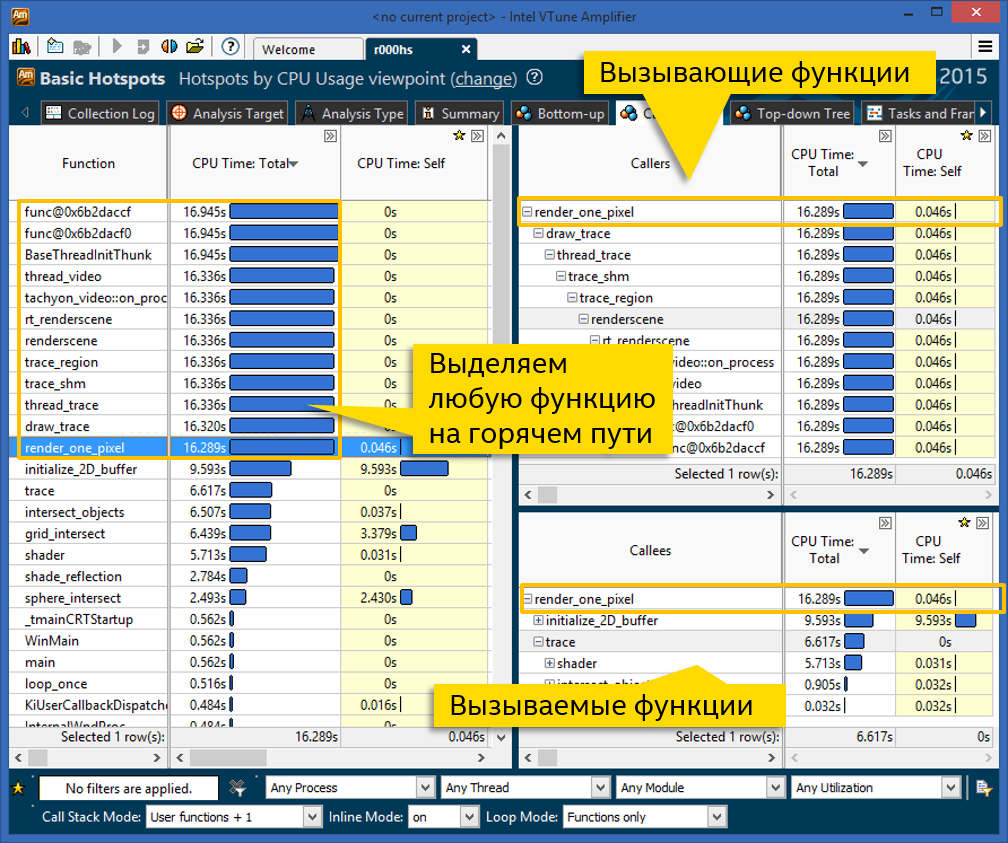
Слева находится список функций программы, отсортированный по потребляемому процессорному времени. Время это делится на общее и собственное. Общее время включает все вызываемые функции. Из этого списка видно, какие функции сами выполняют тяжёлые вычисления (большое self time), а какие стоят на «горячем пути» (большое total time). При этом на панели слева каждая функция встречается один раз, т.е. если она вызывается в разных ветках кода, то общее и собственное время с них суммируется. Так можно определить общий вклад каждой функции.
В нашем примере 12 функций имеют самый большой total time, примерно одинаковый, и нулевой self time. Это значит, что все они находятся на «горячем пути», возможно вызывая друг друга. Если мы хотим этот самый «горячий путь» изучить, кликаем на любой понравившейся функции и смотрим на панели справа.
Правая верхняя панель отображает последовательность вызовов «вверх» — т.е. все вызывающие функции. Для каждой функции из дерева также есть собственное и общее время. Корнем дерева (вверху) является функция, выбранная на левой панели. Если слева кликнуть на другую, дерево перестроится. Мы выбрали функцию render_one_pixel, и видим, что почти все остальные 11 функций с большим общим временем стоят в одной общей цепочке вызовов. На этой панели дерево может ветвиться — если веток кода несколько, показаны будут все, с распределением времени ЦПУ по всем веткам.
Правая нижняя панель, как вы уже догадались, рисует дерево вызываемых функций. Т.е. если заинтересовавший нас узел имеет много total time и мало self time, стоит посмотреть, что он вызывает. На скриншоте сверху значительная часть, 9.5 из 16 секунд, тратится в функции initialize_2D_buffer, остальное идёт из ветки функции trace.
Возможностей VTune Amplifier и представления вида Caller/Callee вполне достаточно для навигации по дереву вызовов и определения критических для производительности функций. Однако, некоторым нравится видеть всё дерево сразу, на одной картинке. Так представляют данные некоторые профилировщики, так делал и VTune много лет назад.Для любителей развесистого дерева вызовов горячих функций, есть способ его построить.1. Получаем профиль VTune Amplifier
Здесь всё просто — собираем любой результат. Одно условие — в нём должны быть стеки. Т.е. Advanced hotspots с уровнем детализации «Hotspots» не подойдёт, там стеков нет. Вполне подойдёт простой анализ Basic hotspots — можно собрать в GUI или командной строке:
amplxe-cl -collect hotspots -result-dir r000hs — find_hotspots balls.dat
2. Распечатываем результат в стиле gprof
VTune Amplifier умеет представлять данные в формате профилировщика gprof, это будет нужно для дальнейших преобразований. Здесь уже обязательно потребуется командная строка (на Windows и Linux одинаковая):
amplxe-cl -report gprof-cc -result-dir r000hs -format text -report-output r000hs_gprof_cc.txt
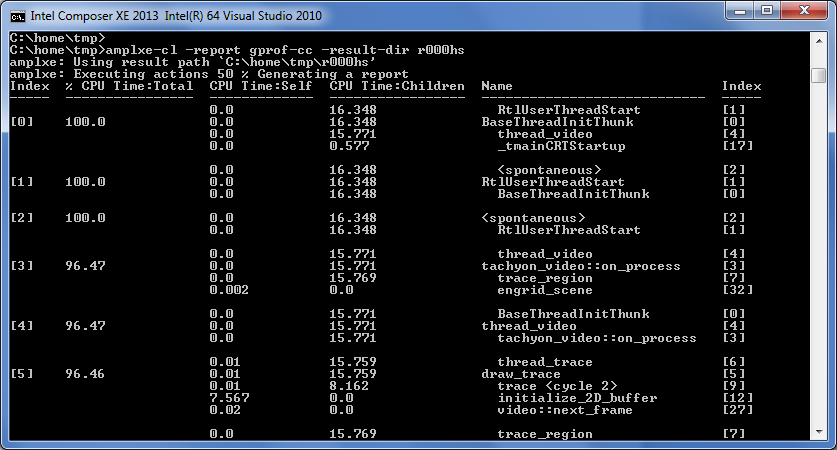 3. Конвертируем результат в граф с Gprof2dot
Теперь нам потребуется утилита Gprof2dot. Это python скрипт, который умеет строить граф в формате DOT из результатов разных профилировщиков. Спасибо господину Jose Fonseca за его создание и поддержку.Скрипт не просто умеет строить DOT граф из результатов gprof, но и поддерживает VTune Amplifier — спасибо контрибьюторам сообщества. Форматы VTune и gprof хоть и похожи, но не идеально совпадают, пришлось делать патчи. Но главное, что сейчас всё работает. Указываем «axe» в качестве формата и распечатку с шага 2 на вход:
python gprof2dot.py -f axe r000hs_gprof_cc.txt
4. Конвертируем DOT граф в картинку
Здесь пригодится ещё один инструмент — Graphviz. Он строит визуальное изображение графа по его описанию текстовом виде:
python gprof2dot.py -f axe r000hs_gprof_cc.txt | «c:\Program Files (x86)\Graphviz2.38\bin\dot» -Tpng -or000hs_call_graph.png
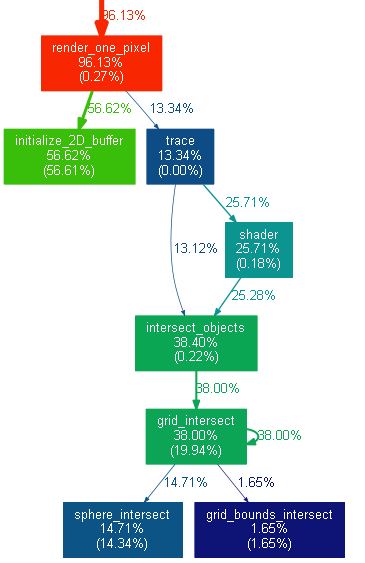
Собственно, шаг 4 включает в себя шаг 3, просто расписал подробнее кто что делает.Вуаля, теперь можно наблюдать дерево вызовов визуально (приведён фрагмент картинки): Такой граф отражает структуру вызовов функций (не всех, самых вычислительно нагруженных), и распределение процессорного времени, собственного и суммарного. Чем краснее цвет, тем сильнее была нагрузка на функцию. Так можно наблюдать «горячий путь». Недостатками являются возможно большой размер дерева целиком и его статичность — в PNG изображении уже нельзя группироваться, фильтроваться, смотреть исходники и метрики производительности, как можно в VTune Amplifier. Но, кому что нравится.
3. Конвертируем результат в граф с Gprof2dot
Теперь нам потребуется утилита Gprof2dot. Это python скрипт, который умеет строить граф в формате DOT из результатов разных профилировщиков. Спасибо господину Jose Fonseca за его создание и поддержку.Скрипт не просто умеет строить DOT граф из результатов gprof, но и поддерживает VTune Amplifier — спасибо контрибьюторам сообщества. Форматы VTune и gprof хоть и похожи, но не идеально совпадают, пришлось делать патчи. Но главное, что сейчас всё работает. Указываем «axe» в качестве формата и распечатку с шага 2 на вход:
python gprof2dot.py -f axe r000hs_gprof_cc.txt
4. Конвертируем DOT граф в картинку
Здесь пригодится ещё один инструмент — Graphviz. Он строит визуальное изображение графа по его описанию текстовом виде:
python gprof2dot.py -f axe r000hs_gprof_cc.txt | «c:\Program Files (x86)\Graphviz2.38\bin\dot» -Tpng -or000hs_call_graph.png
Собственно, шаг 4 включает в себя шаг 3, просто расписал подробнее кто что делает.Вуаля, теперь можно наблюдать дерево вызовов визуально (приведён фрагмент картинки): Такой граф отражает структуру вызовов функций (не всех, самых вычислительно нагруженных), и распределение процессорного времени, собственного и суммарного. Чем краснее цвет, тем сильнее была нагрузка на функцию. Так можно наблюдать «горячий путь». Недостатками являются возможно большой размер дерева целиком и его статичность — в PNG изображении уже нельзя группироваться, фильтроваться, смотреть исходники и метрики производительности, как можно в VTune Amplifier. Но, кому что нравится.
