Визуализация статистики ЕВРО-2016 с помощью Python и Inkscape

Привет, Хабр!
Прошло чуть больше недели с окончания Чемпионата Европы 2016 во Франции. Этот чемпионат запомнится нам неудачным выступлением сборной России, проявленной волей сборной Исландии, потрясающей игрой сборных Франции и Португалии. В этой статье мы поработаем с данными, построим несколько графиков и отредактируем их в векторном редакторе Inkscape. Кому интересно — прошу под кат.
Содержание
- Работа с данными API
- Визуализация данных с помощью Python
- Редактирование векторной графики в Inkscape
1. Работа с данными API
Чтобы визуализировать футбольные данные сначала их необходимо получить. Для этих целей мы будем использовать API football-data.org. Нам доступны следующие методы:
- Список соревнований — «api.football-data.org/v1/competitions/? season={year}»
- Список команд (по идентификатору соревнования) — «api.football-data.org/v1/competitions/{competition_id}/teams»
- Список матчей (по идентификатору соревнования) — «api.football-data.org/v1/competitions/{competition_id}/fixtures»
- Информация о команде — «api.football-data.org/v1/teams/{team_id}»
- Список футболистов (по идентификатору команды) — «api.football-data.org/v1/teams/{team_id}/players»
Подробная информация о всех методах находится в документации API.
Давайте теперь попробуем поработать с данными. Для начала попробуем изучить структуру возвращаемых данных для метода «competitions» (список соревнований):
[{'_links': {'fixtures': {'href': 'http://api.football-data.org/v1/competitions/424/fixtures'},
'leagueTable': {'href': 'http://api.football-data.org/v1/competitions/424/leagueTable'},
'self': {'href': 'http://api.football-data.org/v1/competitions/424'},
'teams': {'href': 'http://api.football-data.org/v1/competitions/424/teams'}},
'caption': 'European Championships France 2016',
'currentMatchday': 7,
'id': 424,
'lastUpdated': '2016-07-10T21:32:20Z',
'league': 'EC',
'numberOfGames': 51,
'numberOfMatchdays': 7,
'numberOfTeams': 24,
'year': '2016'},
{'_links': {'fixtures': {'href': 'http://api.football-data.org/v1/competitions/426/fixtures'},
'leagueTable': {'href': 'http://api.football-data.org/v1/competitions/426/leagueTable'},
'self': {'href': 'http://api.football-data.org/v1/competitions/426'},
'teams': {'href': 'http://api.football-data.org/v1/competitions/426/teams'}},
'caption': 'Premiere League 2016/17',
'currentMatchday': 1,
'id': 426,
'lastUpdated': '2016-06-23T10:42:02Z',
'league': 'PL',
'numberOfGames': 380,
'numberOfMatchdays': 38,
'numberOfTeams': 20,
'year': '2016'},
Прежде чем начать работать с Python, нам понадобится сделать необходимые импорты.
import datetime
import random
import re
import os
import requests
import json
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from matplotlib import rc
pd.set_option('display.width', 1100)
plt.style.use('bmh')
DIR = os.path.dirname('__File__')
font = {'family': 'Verdana', 'weight': 'normal'}
rc('font', **font)
Структура данных понятна, попробуем загрузить данные о соревнованиях за 2015–2016 год в pandas.DataFrame. Параллельно будем сохранять данные, с которыми будем работать в .csv файлы, поскольку бесплатно можно делать лишь 50 запросов к API в день. Ограничения также накладываются и на временной период данных — бесплатно нам доступны лишь 2015–2016 годы.
competitions_url = 'http://api.football-data.org/v1/competitions/?season={year}'
data = []
for y in [2015, 2016]:
response = requests.get(competitions_url.format(year=y))
competitions = json.loads(response.text)
competitions = [{'caption': c['caption'], 'id': c['id'], 'league': c['league'], 'year': c['year'],
'games_count': c['numberOfGames'], 'teams_count': c['numberOfTeams']} for c in competitions]
COMP = pd.DataFrame(competitions)
data.append(COMP)
COMP = pd.concat(data)
COMP.to_csv(os.path.join(DIR, 'input', 'competitions_2015_2016.csv'))
COMP.head(20)
Отлично! Мы видим чемпионат Европы 2016 в списке:
| caption | games_count | id | league | teams_count | year | |
|---|---|---|---|---|---|---|
| 12 | League One 2015/16 | 552 | 425 | EL1 | 24 | 2015 |
| 0 | European Championships France 2016 | 51 | 424 | EC | 24 | 2016 |
Теперь мы можем получить список команд по идентификатору (id) этих соревнований — используем метод teams для получения списка команд Евро-2016.
teams_url = 'http://api.football-data.org/v1/competitions/{competition_id}/teams'
response = requests.get(teams_url.format(competition_id=424))
teams = json.loads(response.text)['teams']
teams = [dict(code=team['code'], name=team['name'], flag_url=team['crestUrl'], players_url=team['_links']['players']['href'])
for team in teams]
TEAMS = pd.DataFrame(teams)
TEAMS.to_csv(os.path.join(DIR, 'input', 'teams_euro2016.cvs'))
TEAMS.head(24)
| code | flag_url | name | players_url | |
|---|---|---|---|---|
| 0 | FRA | upload.wikimedia.org/wikipedia/en/c/c3… | France | api.football-data.org/v1/teams/773/players |
| 1 | ROU | upload.wikimedia.org/wikipedia/commons… | Romania | api.football-data.org/v1/teams/811/players |
| 2 | ALB | upload.wikimedia.org/wikipedia/commons… | Albania | api.football-data.org/v1/teams/1065/pla… |
| 3 | SUI | upload.wikimedia.org/wikipedia/commons… | Switzerland | api.football-data.org/v1/teams/788/players |
| 4 | WAL | upload.wikimedia.org/wikipedia/commons… | Wales | api.football-data.org/v1/teams/833/players |
Структура нашей таблицы таблица (DataFrame) представлена со следующими столбцами:
- code (трехзначный код страны)
- flag_url (ссылка на .svg файл флага страны в нашем случае, а в оригинале crestUrl — .svg файл символа команды)
- name (наименование команды)
- players_url (ссылка на страницу API с данными об игроках — почему-то данных об игроках сборных нет, возможно, это еще одно ограничение API)
В нашей последующей работе нам также понадобятся .svg файлы флагов команд — просто скачаем их в отдельную директорию, я сделал это быстро и непринужденно с помощью расширения Chrono для Chrome.
Теперь попробуем получить данные непосредственно о матчах Евро-2016. Сначала вновь посмотрим структуру ответа сервера для выбранного метода «competitions». Для примера разберем структуру информации о матче, закончившемся серией пенальти (это максимально сложный состав данных из возможных для этого метода).
games_url = 'http://api.football-data.org/v1/competitions/{competition_id}/fixtures'
response = requests.get(games_url.format(competition_id=424))
games = json.loads(response.text)['fixtures']
# Для примера разберем структуру информации о матче, закончившемся серией пенальти.
games_selected = [game for game in games if 'extraTime' in game['result']]
games_selected[0]
В ответе получаем следующее:
{'_links': {'awayTeam': {'href': 'http://api.football-data.org/v1/teams/794'},
'competition': {'href': 'http://api.football-data.org/v1/competitions/424'},
'homeTeam': {'href': 'http://api.football-data.org/v1/teams/788'},
'self': {'href': 'http://api.football-data.org/v1/fixtures/150457'}},
'awayTeamName': 'Poland',
'date': '2016-06-25T13:00:00Z',
'homeTeamName': 'Switzerland',
'matchday': 4,
'result': {'extraTime': {'goalsAwayTeam': 1, 'goalsHomeTeam': 1},
'goalsAwayTeam': 1,
'goalsHomeTeam': 1,
'halfTime': {'goalsAwayTeam': 1, 'goalsHomeTeam': 0},
'penaltyShootout': {'goalsAwayTeam': 5, 'goalsHomeTeam': 4}},
'status': 'FINISHED'}
Для облегчения работы с данными и процесса загрузки их в DataFrame напишем небольшую функцию, которая в качестве атрибута принимает словарь с информацией о матче и возвращает словарь удобного для нас вида.
def handle_game(game):
date = game['date']
team_1 = game['homeTeamName']
team_2 = game['awayTeamName']
matchday = game['matchday']
team_1_goals_main = game['result']['goalsHomeTeam']
team_2_goals_main = game['result']['goalsAwayTeam']
status = game['status']
if 'extraTime' in game['result']:
team_1_goals_extra = game['result']['extraTime']['goalsHomeTeam']
team_2_goals_extra = game['result']['extraTime']['goalsAwayTeam']
if 'penaltyShootout' in game['result']:
team_1_goals_penalty = game['result']['penaltyShootout']['goalsHomeTeam']
team_2_goals_penalty = game['result']['penaltyShootout']['goalsAwayTeam']
else:
team_1_goals_penalty = team_2_goals_penalty = 0
else:
team_1_goals_extra = team_2_goals_extra = team_1_goals_penalty = team_2_goals_penalty = 0
team_1_goals = team_1_goals_main + team_1_goals_extra
team_2_goals = team_2_goals_main + team_2_goals_extra
if (team_1_goals + team_1_goals_penalty) > (team_2_goals + team_2_goals_penalty):
team_1_win = 1
team_2_win = 0
draw = 0
elif (team_1_goals + team_1_goals_penalty) < (team_2_goals + team_2_goals_penalty):
team_1_win = 0
team_2_win = 1
draw = 0
else:
team_1_win = team_2_win = 0
draw = 1
game = dict(date=date, team_1=team_1, team_2=team_2, matchday=matchday, status=status,
team_1_goals=team_1_goals, team_2_goals=team_2_goals,
team_1_goals_extra=team_1_goals_extra, team_2_goals_extra=team_2_goals_extra,
team_1_win=team_1_win, team_2_win=team_2_win, draw=draw,
team_1_goals_penalty=team_1_goals_penalty, team_2_goals_penalty=team_2_goals_penalty)
return game
# Сразу попробуем использовать функцию на примере нашей записи с пенальти
game = handle_game(games_selected[0])
print(game)
Вот как выглядит возвращаемый словарь:
{'date': '2016-06-25T13:00:00Z',
'draw': 0,
'matchday': 4,
'status': 'FINISHED',
'team_1': 'Switzerland',
'team_1_goals': 2,
'team_1_goals_extra': 1,
'team_1_goals_penalty': 4,
'team_1_win': 0,
'team_2': 'Poland',
'team_2_goals': 2,
'team_2_goals_extra': 1,
'team_2_goals_penalty': 5,
'team_2_win': 1}
Теперь у нас всё готово для загрузки данных обо всех матчах Евро-2016 в DataFrame.
games_url = 'http://api.football-data.org/v1/competitions/{competition_id}/fixtures'
response = requests.get(games_url.format(competition_id=424))
games = json.loads(response.text)['fixtures']
GAMES = pd.DataFrame([handle_game(g) for g in games])
GAMES.to_csv(os.path.join(DIR, 'input', 'games_euro2016.csv'))
GAMES.head()
| date | draw | matchday | status | team_1 | team_1_goals | team_1_goals_extra | team_1_goals_penalty | team_1_win | team_2 | team_2_goals | team_2_goals_extra | team_2_goals_penalty | team_2_win | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016–06–10T19:00:00Z | 0 | 1 | FINISHED | France | 2 | 0 | 0 | 1 | Romania | 1 | 0 | 0 | 0 |
| 1 | 2016–06–11T13:00:00Z | 0 | 1 | FINISHED | Albania | 0 | 0 | 0 | 0 | Switzerland | 1 | 0 | 0 | 1 |
Отлично, данные у нас загружены в DataFrame, но такая структура не подходит для анализа данных. Руководствуясь принципами документа «Tidy Data, Hadley Wickham (2014)», скорректируем структуру DataFrame таким образом, чтобы одна переменная (команда) была тождественна одной строке — фактически кол-во строк Dataframe мы увеличим вдвое. Также скорректируем названия столбцов, чтобы с ними было проще работать.
# Помимо всего прочего приведем столбец даты к формату даты.
GAMES['date'] = pd.to_datetime(GAMES.date)
# Для начала расположим столбцы в удобном порядке и скорректируем их названия (сократим)
GAMES = GAMES.reindex(columns=['date', 'matchday', 'status',
'team_1', 'team_1_win', 'team_1_goals', 'team_1_goals_extra', 'team_1_goals_penalty',
'team_2', 'team_2_win', 'team_2_goals', 'team_2_goals_extra', 'team_2_goals_penalty',
'draw'])
new_columns = ['date', 'mday', 'status', 't1', 't1w', 't1g', 't1ge', 't1gp', 't2', 't2w', 't2g', 't2ge', 't2gp', 'draw']
GAMES.columns = new_columns
GAMES.head()
# Теперь создадим итоговый DataFrame
# Создадим копию DataFrame с играми, перетасовав столбцы, и объединим его с оригинальным DataFrame.
GAMES_2 = GAMES.ix[:,[0, 1, 2, 8, 9, 10, 11, 12, 3, 4, 5, 6, 7, 13]]
GAMES_2.columns = new_columns
GAMES_F = pd.concat([GAMES, GAMES_2])
GAMES_F.sort(['date'], inplace=True)
GAMES_F.head()
| date | mday | status | t1 | t1w | t1g | t1ge | t1gp | t2 | t2w | t2g | t2ge | t2gp | draw | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016–06–10 19:00:00 | 1 | FINISHED | France | 1 | 2 | 0 | 0 | Romania | 0 | 1 | 0 | 0 | 0 |
| 0 | 2016–06–10 19:00:00 | 1 | FINISHED | Romania | 0 | 1 | 0 | 0 | France | 1 | 2 | 0 | 0 | 0 |
| 1 | 2016–06–11 13:00:00 | 1 | FINISHED | Albania | 0 | 0 | 0 | 0 | Switzerland | 1 | 1 | 0 | 0 | 0 |
Такая структура куда лучше, но для дальнейшей работы нам понадобится еще несколько небольших изменений.
# Для удобства отображения информации в таблице добавим еще один столбец - "g" - общее кол-во забитых за матч голов
GAMES_F['g'] = GAMES_F.t1g + GAMES_F.t2g
GAMES_F['idx'] = GAMES_F.index
# Для удобства отображения некоторых графиков добавим еще данные о стадии того или иного матча.
# Мы знаем, что всего матчей было 51, из них 15 матчей плей-офф, остальные - групповой этап.
# Давайте добавим эту информацию в DataFrame
TP = pd.DataFrame({'typ': ['Группы']*36 + ['1/8']*8 + ['1/4']*4 + ['1/2']*2 + ['Финал']*1,
'idx': range(0, 51)})
# Сформируем итоговый DataFrame
GAMES_F= pd.merge(GAMES_F, TP, how='left', left_on=GAMES_F.idx, right_on=TP.idx)
GAMES_F.head()
| date | mday | status | t1 | t1w | t1g | t1ge | t1gp | t2 | t2w | t2g | t2ge | t2gp | draw | g | idx_x | idx_y | typ | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2016–06–10 19:00:00 | 1 | FINISHED | France | 1 | 2 | 0 | 0 | Romania | 0 | 1 | 0 | 0 | 0 | 3 | 0 | 0 | Группы |
| 1 | 2016–06–10 19:00:00 | 1 | FINISHED | Romania | 0 | 1 | 0 | 0 | France | 1 | 2 | 0 | 0 | 0 | 3 | 0 | 0 | Группы |
| 2 | 2016–06–11 13:00:00 | 1 | FINISHED | Albania | 0 | 0 | 0 | 0 | Switzerland | 1 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | Группы |
2. Визуализация данных с помощью Python
Для визуализации данных мы будем использовать библиотеку matplotlib. На этом этапе мы фактически подготовим графики в формате .svg для их дальнейшей обработки в векторном редакторе.
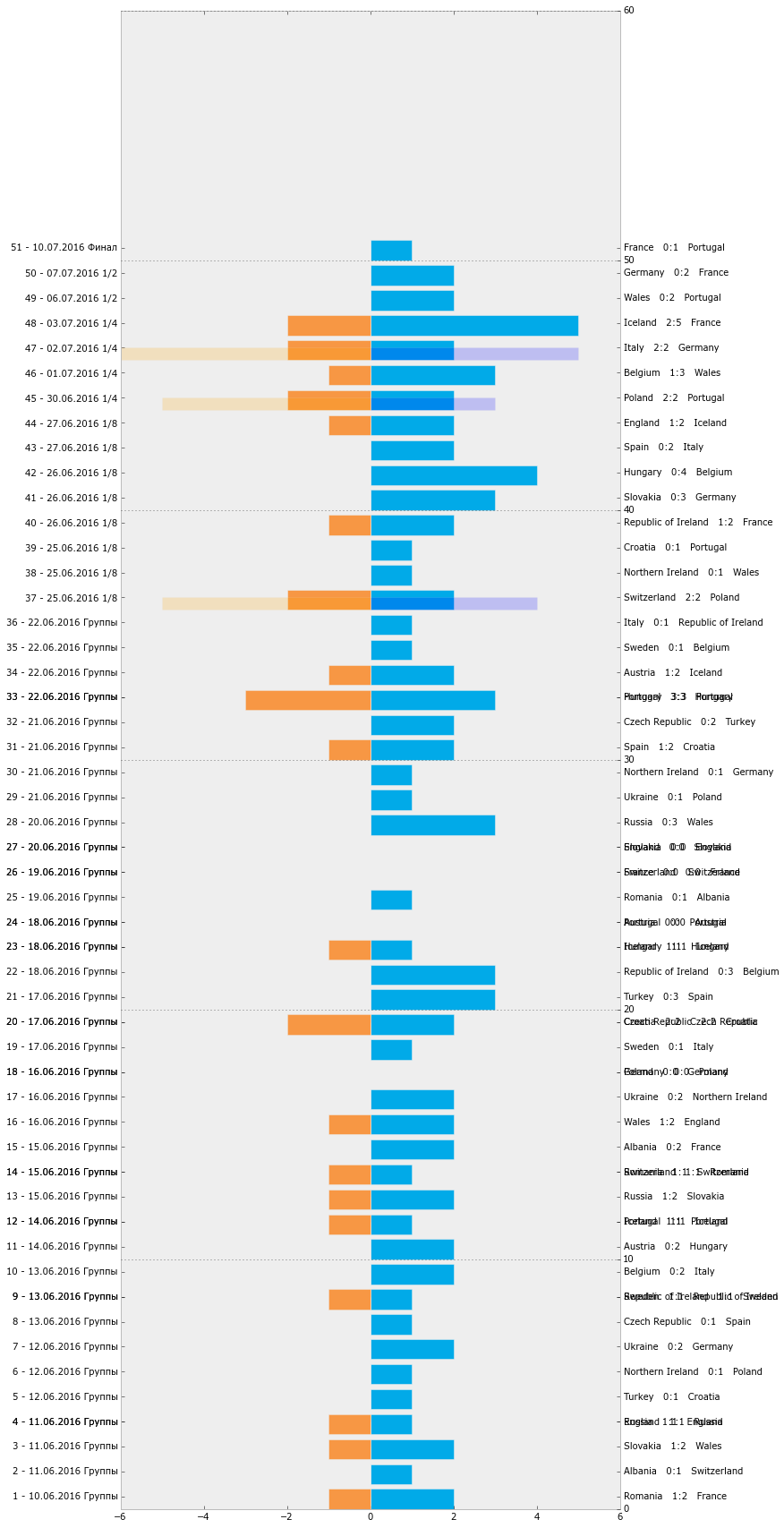
Для начала подготовим график-таймлайн всех матчей Евро-2016. Мне показалось, что он будет достойно и удобно смотреться в форме горизонтальных столбцов.
GAMES_W = GAMES_F[(GAMES_F.t1w==1) | (GAMES_F.draw==1)]
GAMES_W['dt'] =[d.strftime('%d.%m.%Y') for d in GAMES_W.date]
# Отформатируем подписи для осей
GAMES_W['l1'] = (GAMES_W.idx_x + 1).astype(str) + ' - ' + GAMES_W.dt + ' ' + (GAMES_W.typ)
GAMES_W['l2'] = GAMES_W.t2 + ' ' + GAMES_W.t2g.astype(str) + ':' + GAMES_W.t1g.astype(str) + ' ' + GAMES_W.t1
fig, ax1 = plt.subplots(figsize=[10, 30])
ax1.barh(GAMES_W.idx_x, GAMES_W.t1g, color='#01aae8')
ax1.set_yticks(GAMES_W.idx_x + 0.5)
ax1.set_yticklabels(GAMES_W.l1.values)
ax2 = ax1.twinx()
ax2.barh(GAMES_W.idx_x, -GAMES_W.t2g, color='#f79744')
ax2.set_yticks(GAMES_W.idx_x + 0.5)
ax2.set_yticklabels(GAMES_W.l2.values)
# Хорошо. Теперь мы нанесли почти достаточно информации для редактирования в редакторе - нам осталось лишь
# нанести информацию для матчей, закончившихся серией пенальти.
ax3 = ax1.twinx()
ax3.barh(GAMES_W.idx_x, GAMES_W.t2gp, 0.5, alpha=0.2, color='blue')
ax3.barh(GAMES_W.idx_x, -GAMES_W.t1gp, 0.5, alpha=0.2, color='orange')
ax1.grid(False)
ax2.grid(False)
ax1.set_xlim(-6, 6)
ax2.set_xlim(-6, 6)
# Теперь можно сохранить в файл для обработки
plt.show()
fig.savefig(os.path.join(DIR, 'output', 'barh_1.svg'))
На выходе мы получим вот такой неказистый график-таймлайн.
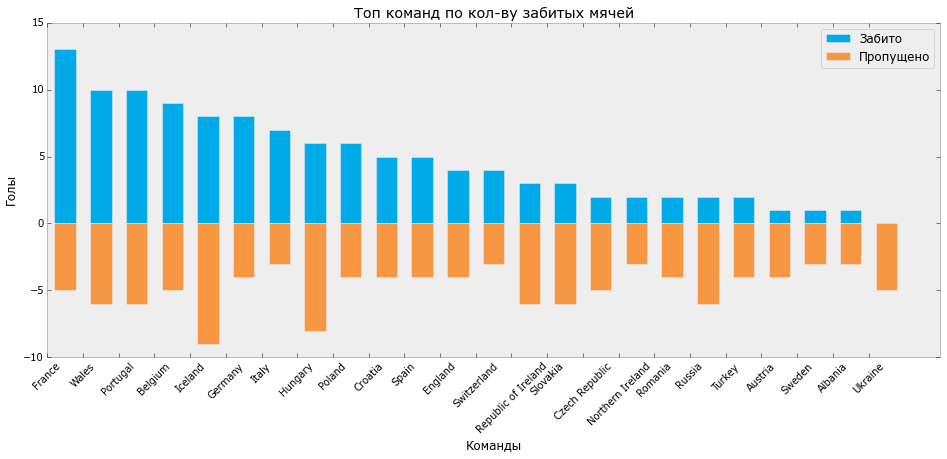
Давайте теперь узнаем, какая же сборная забила больше всего мячей. Для этого создадим группированный DataFrame из существующего и расcчитаем некоторые агрегированные показатели.
GAMES_GR = GAMES_F.groupby(['t1'])
GAMES_AGG = GAMES_GR.agg({'t1g': np.sum})
GAMES_AGG.sort(['t1g'], ascending=False).head()
teams goals
France 13
Wales 10
Portugal 10
Belgium 9
Iceland 8
Интересно, но давайте подсчитаем еще несколько показателей:
- Кол-во сыгранных матчей
- Кол-во побед/ничьих/поражений
- Кол-во забитых/пропущенных голов
- Кол-во матчей с дополнительным временем
- Кол-во матчей, закончившехся серией пенальти
GAMES_F['n'] = 1
GAMES_GR = GAMES_F.groupby(['t1'])
GAMES_AGG = GAMES_GR.agg({'n': np.sum, 'draw': np.sum, 't1w': np.sum, 't2w':np.sum,
't1g': np.sum, 't2g': np.sum})
GAMES_AGG['games_extra'] = GAMES_GR.apply(lambda x: x[x['t1ge']>0]['n'].count())
GAMES_AGG['games_penalty'] = GAMES_GR.apply(lambda x: x[x['t1gp']>0]['n'].count())
GAMES_AGG.reset_index(inplace=True)
GAMES_AGG.columns = ['team', 'draw', 'goals_lose', 'lose', 'win', 'goals',
'games', 'games_extra', 'games_penalty']
GAMES_AGG = GAMES_AGG.reindex(columns = ['team', 'games', 'games_extra', 'games_penalty',
'win', 'lose', 'draw', 'goals', 'goals_lose'])
Теперь визуализируем эти распределения:
GAMES_P = GAMES_AGG
GAMES_P.sort(['goals'], ascending=False, inplace=True)
GAMES_P.reset_index(inplace=True)
bar_width = 0.6
fig, ax = plt.subplots(figsize=[16, 6])
ax.bar(GAMES_P.index + 0.2, GAMES_P.goals, bar_width, color='#01aae8', label='Забито')
ax.bar(GAMES_P.index + 0.2, -GAMES_P.goals_lose, bar_width, color='#f79744', label='Пропущено')
ax.set_xticks(GAMES_P.index)
ax.set_xticklabels(GAMES_P.team, rotation=45)
ax.set_ylabel('Голы')
ax.set_xlabel('Команды')
ax.set_title('Топ команд по кол-ву забитых мячей')
ax.legend()
plt.grid(False)
plt.show()
fig.savefig(os.path.join(DIR, 'output', 'bar_1.svg'))
На выходе мы получаем такой график
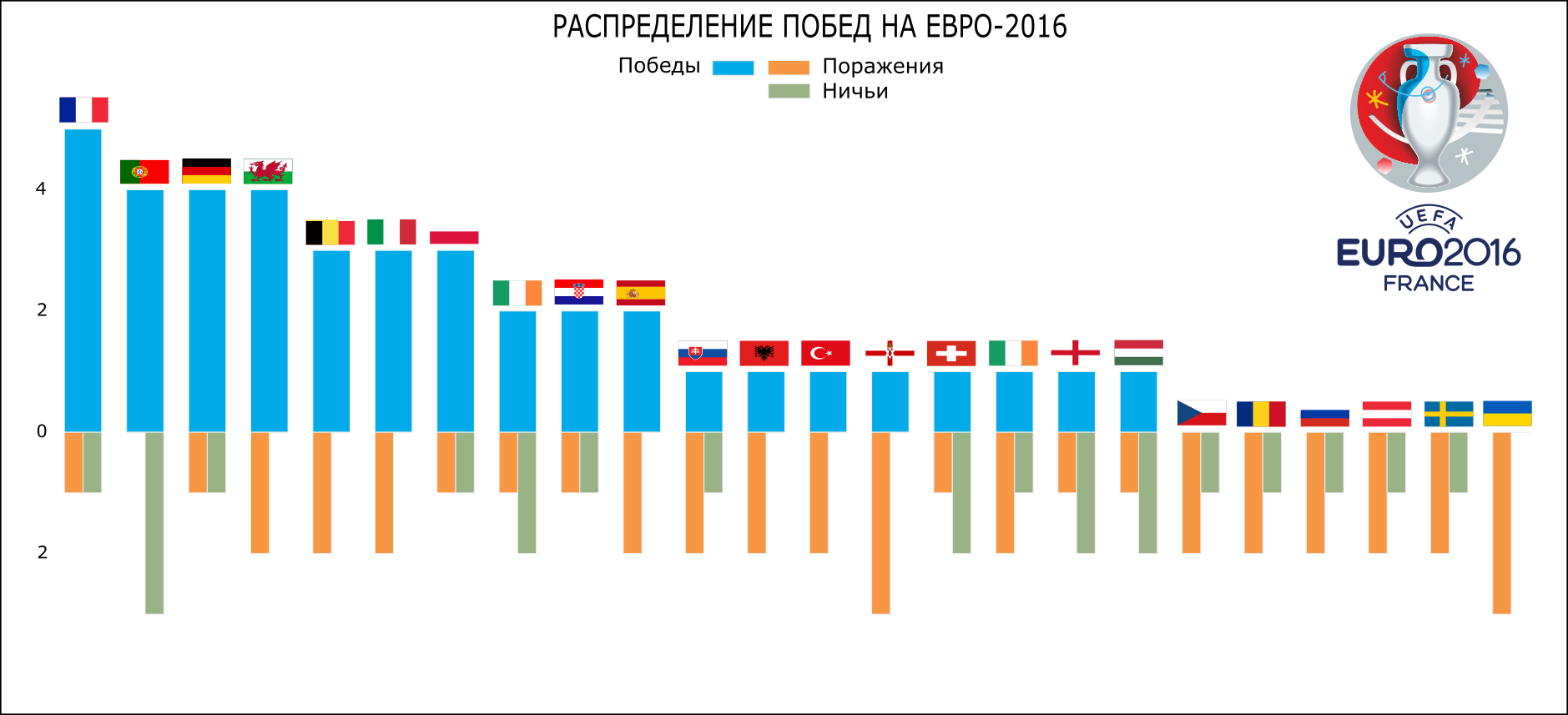
Нарисуем еще один график распределения побед, поражений и ничьих на Евро.
GAMES_P = GAMES_AGG
GAMES_P.sort(['win'], ascending=False, inplace=True)
GAMES_P.reset_index(inplace=True)
bar_width = 0.6
fig, ax = plt.subplots(figsize=[16, 6])
ax.bar(GAMES_P.index + 0.2, GAMES_P.win, bar_width, color='#01aae8', label='Победы')
ax.bar(GAMES_P.index + 0.2, -GAMES_P.lose, bar_width/2, color='#f79744', label='Поражения')
ax.bar(GAMES_P.index + 0.5, -GAMES_P.draw, bar_width/2, color='#99b286', label='Ничьи')
ax.set_xticks(GAMES_P.index)
ax.set_xticklabels(GAMES_P.team, rotation=45)
ax.set_ylabel('Матчи')
ax.set_xlabel('Команда')
ax.set_title('Топ команд по кол-ву побед')
ax.set_ylim(-GAMES_P.lose.max()*1.2, GAMES_P.win.max()*1.2)
ax.legend(ncol=3)
plt.grid(False)
plt.show()
fig.savefig(os.path.join(DIR, 'output', 'bar_2.svg'))
На выходе мы получаем такой график
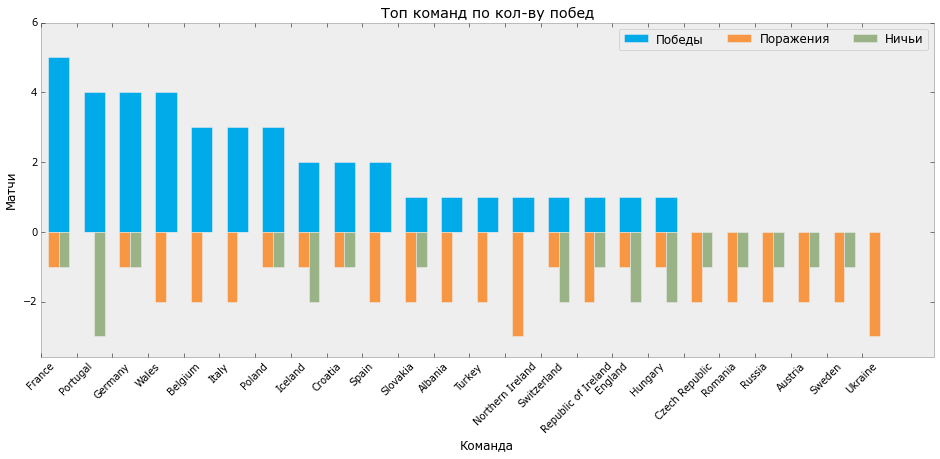
Пользуясь случаем, хочется отметить, что лидер по количеству забитых мячей и количеству побед Франция не стал победителем чемпионата, а Португалия, с 3 матчами в ничью, меньшим количеством забитых мячей и большим, чем у Франции количеством пропущенных, в итоге получила кубок.
3. Редактирование векторной графики в Inkscape
Теперь давайте отредактируем получившиеся у нас графики в векторном редакторе Inkscape. Выбор пал на этот редактор по одной причине — он бесплатный. Сразу хотелось бы отметить, что к ресурсам системы он также крайне требователен — опытным путём было определенно, что минимальное кол-во оперативной памяти для работы — 8 гб. У меня было 4 гб, так что к концу правки одной из иллюстраций я уже начинал нервничать от длительных ожиданий. Для комфортной работы в редакторе рекомендуется ознакомиться с вводными туториалами на сайте.
Основной задачей редактирования графиков в векторном редакторе является возможность сделать красивые визуализации с помощью встроенных функций редактора. При этом мы можем:
- Выбирать, изменять и перемещать любой элемент графика, созданный с помощью python
- Как угодно дополнять отрисованные данные из внешних источников, например — вставлять флаги стран
- Экспортировать данные в каком угодно разрешении в большинство графических форматов
Я не буду длительно описывать преобразования, которые я сделал в Inkscape, а просто перечислю их и представлю итоговые получившиеся графики. Изменения:
- Отредактированы подписи на осях
- Убраны лишние заливки
- Добавлены флаги стран для более понятной визуализации
- Произведены цветовые выделения
- Добавлена символика Евро-2016
- Добавлены футбольные атрибуты (например, мячи, отражающие количество забитых мячей на таймлайне)
Вот что получилось в итоге:
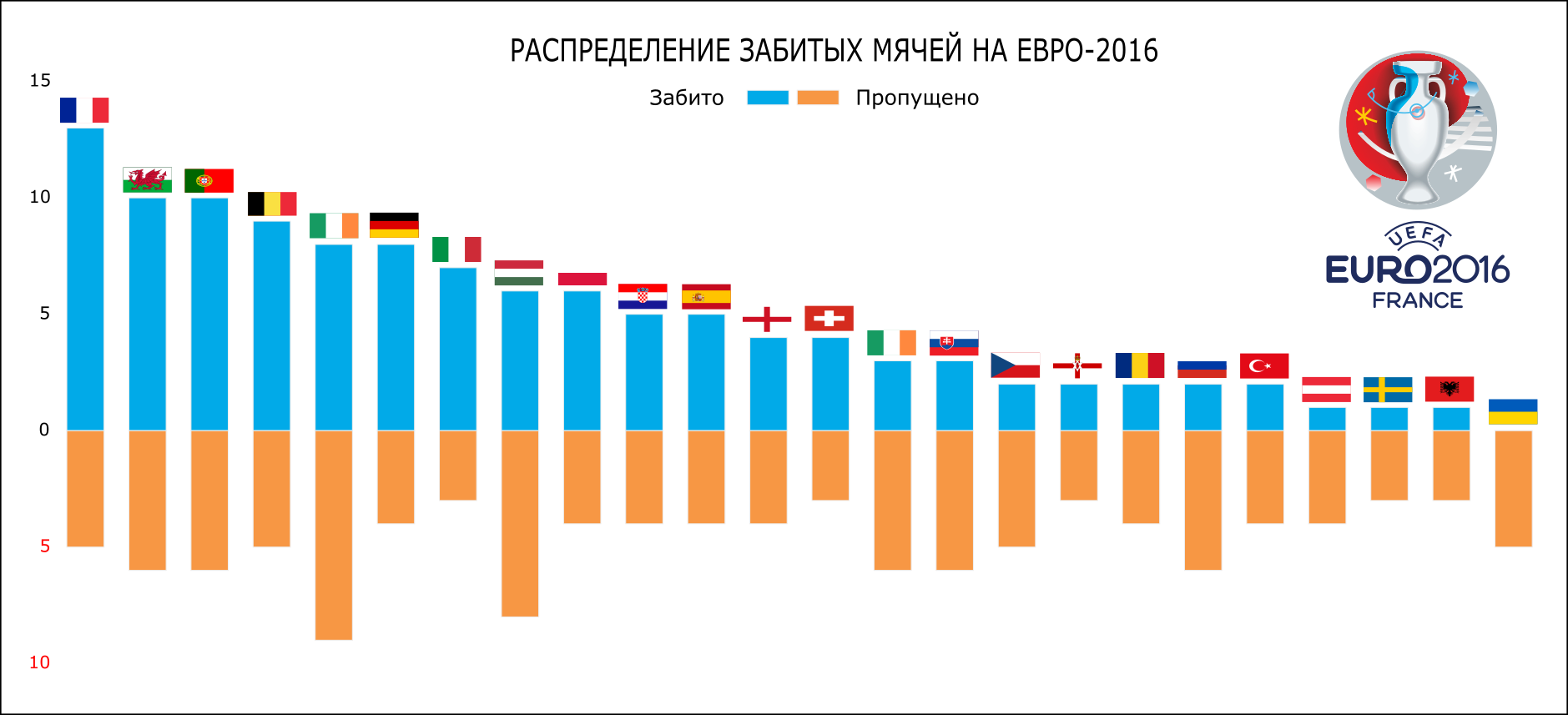

Спасибо за внимание.
