Vim: поиск по документации на Javascript
Обычно я работаю в Kate или Geany. Но иногда, как и всем людям, мне хочется освоить Vim. И каждый раз, примерно на второй минуте «освоения» возникает какой-нибудь совершенно дурацкий вопрос. Например, почему при нажатии стрелок (или клавиш jk) курсор скачет сразу через все строки абзаца?
Как бы я ни старался свои вопросы формулировать, поиск каждый раз выдаёт мне примерно одни и те же сто сайтов с заголовками вроде »100 самых полезных команд Vim». И какой бы сайт я ни выбрал, на нём всегда не будет хватать именно той «команды», которая мне нужна как раз сейчас.
Я подумал, как бы найти не сто, а вообще все команды Вим. И нашёл-таки страничку в сети, которая так и называлась: «Все команды Vim». И там действительно был очень большой список — штук шестьсот слов. Но не было указано, что эти команды делают, — просто список терминов. Меня так разозлила эта шутка, что я решил, наконец, почитать документацию и раз и навсегда составить свой собственный список «всех команд Vim». Результат на экране. Подробности ниже.
На официальном сайте меня отправили изучать документацию на страницу vimdoc.sourceforge.net. На этой странице больше ста ссылок на разные файлы; описание задач в них часто пересекается: например, для меня editing.html, motion.html, insert.html — всё это как бы одно сплошное «редактирование». Некоторые файлы вообще не нужны для поиска решения — например, сравнение версий вроде version5.html. Некоторые — что-то вроде учебника (usr_NN.html).
Я выбрал всё более-менее относящееся к «reference», скачал и решил как-то организовать поиск-фильтрацию по всему материалу сразу. После обработки sed’ом и склеивания получился файл размером 3.5 мегабайта. «Команд» там оказалось не 600, а шесть тысяч (со всеми псевдонимами и вариантами — которые уместились примерно в четырёх тысячах «статей» или «параграфов»). Их удалось все найти и выбрать, потому что автор документации, Bram Moolenaar, заботливо заключил их все в тэги »a name».
Именно по этому принципу я разделил весь текст документации: одно «ключевое слово» (или группа терминов-синонимов) — один сегмент текста. Я хотел организовать «сквозную» фильтрацию, чтобы при поиске произвольного слова видеть фрагменты из разных файлов документации. А ещё не потерять стандартную возможность документации — при щелчке по термину или «тегу» прыгать к тексту с определением (или описанием) этого термина.
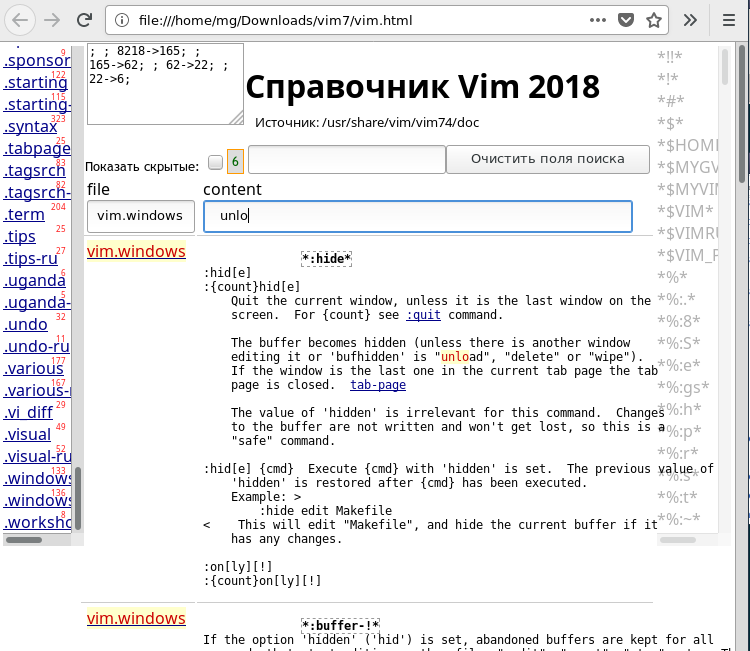
Для этого весь материал был помещён в одну большую html-таблицу, а потом в ней был организован поиск с помощью Javascript.
Все знают, что такая большая таблица — 4000 строк, 3.5 мегабайта — в браузере будет еле ворочаться. Но глаза боятся, руки делают. Javascript в современных браузерах — очень быстрый язык. Гораздо больше времени уходит на вывод текста на экран. Поэтому не надо показывать сразу всю таблицу.
Это первый простой приём, дающий самое большое ускорение загрузки для большой страницы — указать для таблицы правило display:none;. Невидимая таблица загружается на порядок быстрее, после чего можно не спеша создать все необходимые индексы. А позже, когда пользователь начнёт поиск, будем выводить на экран только небольшую часть таблицы. Иногда, конечно, и большую, если вы введёте в поле поиска всего одну букву.
Чтобы избавать пользователя (то есть, в первую очередь, себя) от долгого ожидания, мы завели в скрипте фильтрации два параметра: _Table.tx = 2 — искать начинаем, только если пользователь ввёл не меньше двух букв; _Table.vrows = 100 — показываем только первые 100 результатов поиска (не больше).
В Vim’е бывают, конечно, команды из двух букв, и даже из одной буквы. По ним практически невозможно отфильтровать нужный текст, потому что будет найдено много обычных слов. Чтобы при поиске буквы искомых терминов не смешивались с «обычными буквами», мы заключили все «термины» в звёздочки (точнее, оставили эти звёздочки, как в исходных файлах). Чтобы найти, например, описание команды «B» (заглавная латинская B), в поле поиска так и надо вводить букву прямо со звёздочками:

Предполагается, что при количестве результатов, например, 200, разумный пользователь продолжит фильтрацию, чтобы уменьшить количество найденных строк, — например, добавляя буквы в поле поиска другого столбца. Но если сильно захочется увидеть все 4000 найденных строк, можно нажать галочку «Показать скрытые».
Можно искать термины и горячие клавиши также с помощью обычного Ctrl+f — все ключевые слова полностью выведены на странице в отдельном списке справа, почти как на том сайте, где «все команды Вим». Только на нашей страничке по любому слову можно щёлкнуть и увидеть подробный текст из документации. По Ctrl+f в списке справа можно найти также и команды, состоящие из одной буквы — там они тоже окружены звёздочками.
Это второй приём ускорения — организация поиска по отдельным спискам, а не по всему сплошному тексту — для этого и нужна таблица с несколькими столбцами, а, возможно, ещё и пара столбцов снаружи таблицы.
Третий приём — не трогать DOM. Поиск на Javascript всегда лучше вести по специально подготовленным массивам, а не по реальным узлам DOM.
Четвёртый приём — «индексация». Мы связываем слово из списка прямо с конкретным элементом массива по его номеру. Это что-то вроде primary key. Тогда при щелчке по такому слову можно выводить нужную информацию практически мгновенно — так работает список терминов справа. Мы можем связать ссылку с несколькими элементами массива, тогда поиск тоже ускоряется, потому что никакого поиска нет — просто выводятся строки, связанные с набором элементов массива (что-то вроде связи один-ко-многим). Так работает список «категорий» слева — в нём имена исходных файлов документации: options, editing, motion… Правда, «ускорение» не очень заметно при щелчке, например, по ссылке vim.eval, потому что в этом разделе больше пятисот пунктов (строк таблицы), и выводятся на экран они уже достаточно долго (если вы, конечно, поставите галочку «Показать скрытые»).
Поиск текста на Javascript у нас производится с помощью функции indexOf() — перебираются все значения в массиве и сравниваются с введёнными для поиска буквами. Обычно для поиска этим методом надо приводить все значения в поисковых массивах к нижнему регистру. Но в нашем случае gg не то же самое, что GG, поэтому поиск сделан регистрозависимым.
***
В документации в каждом абзаце находится множество ссылок. Эти ссылки конечно создавались отнюдь не руками, и иногда в файлах можно встретить довольно странные вещи. Так, ссылки на команду «motion.as» мне пришлось полностью удалить — потому что таких ссылок в итоговом файле оказалось больше тысячи (в высказываниях вида »same as: map»). Я уж решил, миновала беда;, но вдруг случайно увидел следующий набор «шумовых» ссылок — со словом «do».
Тогда мне перестало казаться, что искать обязательно «самые свежие» html-файлы документации такая уж хорошая идея. Пусть у меня Vim не самый-самый последний, но документация-то всё равно ведь меняется не каждый день. Поэтому почему бы вместо «wget …» не написать в консоли cp -R /usr/share/vim/vim74/doc ~/Downloads/vim7/source. И ходить за исходными файлами далеко не надо.
В моей папке vim74/doc оказались ещё файлы .rux — переводы на русский. Файлов стало много, да ещё и с разными расширениями. И в целом выбор файлов для поиска стал определяться немного по-другому: не «выбрать всё похожее на reference», а удалить заведомо не-reference: rm -R usr_*; rm -R version*; rm -R todo*.
Число «команд vim» или тегов в правом списке увеличилось до 9000. Точнее, стало даже «over 9000». И часть тегов оказались связаны не с одним сегментом текста, а с двумя — английским и русским (если есть перевод). Хуже, по-моему, от этого не стало. Правда, число строк таблицы тоже выросло — до «over 8000». Но разницы в скорости работы поиска между таблицей в 4000 строк и таблицей с 8000 строк невооружённым глазом не заметно.
Vim tags
Разглядывая файлы документации, я обнаружил «список команд Вим» в файле tags, но не сумел его использовать в работе Javascript — не понял, что при этом можно выгадать. Его можно использовать раньше, при генерации html, как это делает лежащий в той же папке скрипт vim2html.pl, — чтобы выделять ключевые слова и размечать их html-тегами a name. Но для поиска на Javascript не нужны именно «a name», достаточно любых условных меток (мы выбрали ). И не нужен такой сложный инструмент, как vim2html.pl, — можно расставить метки с помощью обыкновенных регэкспов, sed’ом (код приведён в конце статьи).
Возвращаясь к Vim hjkl
Пока я неторопливо пилил в Kate Javascript-фильтрацию для Vim’овских доков, параллельно набирал этот текст в Vim. И ответ на свой первый вопрос о jk-навигации получил только в самом конце работы, дней через пять. В первом приближении ответ нашёлся быстро — в одной из статей прямо здесь, на Хабре: чтобы курсор двигался по экранным строчкам, а не по абзацам, надо изменить назначение клавиш с помощью инструкции map — в файле ~/.vimrc: map k gk, map j gj.
Но это была самая маленькая часть проблемы. Большая оказалась в идеологии. Клавиши hjkl, используемые вместо стрелок, призваны увеличивать удобство навигации: не надо уводить руку далеко от основных клавиш — к стрелкам. Ну, передвинулся я на нужное место в тексте, нажал i, напечатал букву. А потом-то что? Как дальше двигаться этими jk? Если я их нажму, они ведь просто напечатаются.
Надо как-то переходить опять в «нормальный» режим — то есть всё-таки уводить одну из рук от основных клавиш к клавише Esc. Её, конечно, щёлкнуть проще, чем к стрелкам перемещаться. Но раздражает сам факт частого переключения режимов для мелкой правки — теряется всякий профит.
Мудрая мысль насчёт «map k gk» подсказала следующий шаг: imap . И это прекрасно сработало почти для всех четырёх направлений. Кроме
imap l
map li
И вот в этом последнем я вдруг заметил, что клавиши работают как-то через раз. Понаблюдав ещё немного за поведением поциента, нашёл какое-то странное решение, необъяснимо оказавшееся рабочим:
imap lli
***
Можно ещё долго и много рассказывать о внутренней красоте Javascript и о тонкостях работы с таблицами вроде table-layout: fixed;, но я начинаю чувствовать за спиной укоризненный взгляд Линуса: «Покажите мне уже код!» Вот он, код обработки исходных файлов документации:
cd source
rm -R usr_*
rm -R version*
rm -R todo*
for f in *.txt;
do
n=$(echo "$f" | sed -r 's/\.\w+//');
perl -pe 's/"$n".html;
done;
for f in *.rux;
do
n=$(echo "$f" | sed -r 's/\.\w+//');
perl -pe 's/"$n"-ru.html;
done;
for f in *.html;
do
n=$(echo "$f" | sed -r 's/\.\w+//');
for ((i=0; i < 3; i++)); do
sed -i -r "s:\|([^\t ]+)\|:\1:g; s:(^|\t| )(\*[^\t ]+\*)(\t| |$):\1\2\3:g" "$n".html;
done;
sed -i "//i<\/pre><\/td><\/tr>vim.$n<\/u><\/td> " "$n".html;
done;
cat *.html > ../table.htm
cd ..
sed -i '/vim:tw=78:ts=8:ft=help:norl/d' table.htm
cat htm00.htm table.htm endhtm.htm >vim.html
Сначала кодируем в html все открывающие теги в тексте. И заодно копируем исходники в файлы с другим расширением. Потом ищем все слова со звёздочками и заключаем их в теги . Сложность в том, чтобы не зацепить вхождения вида »: autocmd BufRead */doc/*.txt set tw=78» — звёздочки без ключевых слов. Из-за сложного условия поиск приходится повторять несколько раз, потому что часть контекстов пересекается. Когда найдены и размечены все ключевые слова, опираясь на них, уже можно разделить будущую html-таблицу на строчки.
Потом файлы склеиваются в один, добавляется !DOCTYPE с мета-тэгами, 300 строк js и 40 строк css, которые можно посмотреть прямо внутри конечного файла. Результат: Vim docs
P.S. Пока дорабатывал описание, добавил кое-что в Javascript: 1) двойной щелчок мышкой запускает поиск по выделенному слову; 2) можно выделить мышкой несколько слов и нажать для поиска F2. 3) todo: Ctrl+Left должен возвращать к предыдущему результату поиска (и наоборот).
