VictoriaMetrics и мониторинг приватных облаков. Павел Колобаев

VictoriaMetrics — быстрой и масштабируемой СУБД для хранения и обработки данных в форме временного ряда (запись образует время и набор соответствующих этому времени значений, например, полученных через периодический опрос состояния датчиков или сбор метрик).

Меня зовут Колобаев Павел. DevOps, SRE, LeroyMerlin, все как код — это все про нас: про меня и про других сотрудников LeroyMerlin.

https://bit.ly/3jf1fIK
Есть облако на базе OpenStack. Там небольшая ссылка на техрадар.

Построено оно на базе железа Kubernetes, а также на всех сопутствующих сервисах к OpenStack и логирования.

Схема вот такая у нас была на разработке. Когда мы все это разрабатывали у нас был оператор Prometheus, который хранил данные внутри самого кластера K8s. Он автоматически находит то, что нужно отскрабить и складывает себе под ноги, грубо говоря.

Все данные нам нужно будет вынести за пределы кластера Kubernetes, потому что если что-то случится, то мы должны понимать, что и где.

Первое решение — мы используем federation, когда у нас есть сторонний Prometheus, когда мы ходим в кластер Kubernetes через механизм federation.

Но тут получаются небольшие проблемы. В нашем случае проблемы начались, когда у нас было 250 000 метрик, а когда стало 400 000 метрик, поняли, что так работать не можем. Мы увеличили scrape_timeout до 25 секунд.
Почему нам это пришлось сделать? Prometheus начинает отсчитывать время тайм-аута с начала момента забора. И не важно, что данные все еще льются. Если за этот указанный промежуток времени данные не слились и сессия не будет закрыта по http, то считается, что сессия провальная и данные не попадают в сам Prometheus.

Всем знакомые графики, которые мы получаем, когда часть данных отсутствуют. Графики рванные и нас это не устраивает.

Следующий вариант — это шардирование на основе двух разных Prometheus через тот же механизм federation.
Например, просто взять и по имени их отшардировать. Это можно тоже использовать, но мы решили двигаться дальше.

Нам придется теперь эти шарды как-то обрабатывать. Можно взять promxy, который сходит в область шарда, смультиплицирует данные. Он работает с двумя шардами как с единой точкой входа. Такое можно реализовать через promxy, но слишком пока сложно.
Первый вариант — мы хотим отказаться от механизма federation, потому что он очень медленный.
Разработчики Prometheus явно говорят: «Ребята, используйте другие TimescaleDB, потому что мы не будем поддерживать долгое хранение метрик». Это не их задача. 
Мы себе на бумашку записываем, что нам все-таки требуется выгрузка наружу, дабы не хранить все в одном месте.

Второй недостаток — это потребление памяти. Да, я понимаю, что многие скажут, что в 2020-ом году пару гигабайт памяти — это стоит копейки, но тем не менее.
Сейчас у нас есть dev и prod-среда. В dev — это порядка 9 гигабайтов на 350 000 метрик. В prod — это 14 гигабайтов с небольшим на 780 000 метрик. При этом retention time у нас всего 30 минут. Это плохо. И сейчас объясню почему.

Мы делаем расчет, т. е. при полутора миллионах метрик, а мы уже близки к ним, на этапе еще проектирования мы получаем 35–37 гигабайт памяти. Но уже к 4 миллионам метрик требуется уже порядка 90 гигабайтов памяти. Т. е. это было рассчитано по той формуле, которую предоставляют разработчики Prometheus. Мы посмотрели корреляцию и поняли, что мы не хотим платить пару миллионов за сервер просто под мониторинг.
У нас не просто увеличится количество машин, мы еще мониторим и сами виртуальные машины. Поэтому чем больше виртуальных машин, тем больше метрик разного рода и т. д. У нас будет специальный рост нашего кластера в плане метрик.

С дисковым пространством здесь не все так печально, но хотелось бы улучшить. Мы получили за 15 дней суммарно 120 гигабайтов, из которых 100 — это сжатые данные, 20 — это не сжатые данные, но всегда хочется меньше.

Соответственно, мы записываем еще один пункт — это большое потребление ресурсов, которые хочется все-таки экономить, потому что мы не хотим, чтобы наш кластер мониторинга съел ресурсов больше, чем наш кластер, который занимается управлением OpenStack.

Есть еще один недостаток у Prometheus, который мы для себя выявили, это хоть какое-то ограничение по памяти. С Prometheus здесь все гораздо хуже, потому что у него вообще таких крутилок нет. Использовать ограничение в докере тоже не вариант. Если вдруг у вас RAF упал и там 20–30 гигабайтов, то подниматься он будет очень долго.

Это еще одна причина, почему нам не подходит Prometheus, т. е. нельзя ограничить потребление памяти.

Можно было бы выйти на такую схему. Эта схема нам нужна для того, чтобы организовать HA кластер. Мы хотим, чтобы наши метрики были доступны всегда и везде, даже при падении сервера, который хранит эти метрики. И тем самым нам придется вот такую схему построить.
Эта схема говорит, что у нас будет дублирование шардов, а, соответственно, и дублирование расходов потребляемых ресурсов. Ее можно почти горизонтально масштабировать, но тем не менее потребление ресурсов будет адское.

Недостатки по порядку в том виде, в котором мы для себя их выписали:
- Требуется выгрузка метрик наружу.
- Большое потребление ресурсов.
- Нельзя ограничить потребление памяти.
- Сложная и ресурсоемка реализация HA.

Для себя мы решили, что мы уходим от Prometheus как от хранилища.
Мы для себя определили еще дополнительные требования, которые нам нужны. Это:
- Это поддержка promql, потому что уже много всего написано под Prometheus: запросы, алерты.
- И дальше у нас есть Grafana, которая уже точно так же написана под Prometheus как бэкенд. Не хочется переписывать дашборды.
- Мы хотим построить нормальную HA архитектуру.
- Мы хотим уменьшить потребление любых ресурсов.
- Есть еще маленький нюанс. Мы не можем использовать различного рода cloud системы сбора метрик. Мы не знаем, что у нас улетит в эти метрики пока. И так как туда может улететь все, что угодно, нам приходится ограничиваться локальным размещением.

Выбор был небольшой. Мы собрали все, по чему у нас был опыт. Посмотрели на страницу Prometheus в разделе integration, прочитали кучу статей, посмотрели, что вообще есть. И для себя мы выбрали VictoriaMetrics в качестве замены Prometheus.
Почему? Потому что:
- Умеет promql.
- Есть модульная архитектура.
- Не требует изменений в Grafana.
- И самое главное — мы, возможно, будем предоставлять хранилище метрик внутри своей компании как сервис, поэтому мы заранее смотрим в сторону ограничения различного рода, чтобы пользователи могли в каком-то ограниченном виде использовать все ресурсы кластера, потому что есть шанс, что он будет multitenancy.

Делаем первые сравнение. Мы берем тот же самый Prometheus внутри кластера, к нему ходит внешний Prometheus. Добавляем через remoteWrite VictoriaMetrics.

Сразу оговорюсь, что вот здесь мы поймали небольшое увеличение по потреблению CPU со стороны VictoriaMetrics. На VictoriaMetrics wiki написано, какие параметры лучше подходят. Мы их проверили. Они очень хорошо уменьшили потребление именно по CPU.
В нашем случае потребление памяти Prometheus, который находится в кластере Kubernetes, возросло не значительно.

Сравниваем два data source одних и тех же данных. В Prometheus мы видим все те же недостающие данные. В VictoriaMetrics все хорошо.

Результаты тестов с дисковым пространством. Мы в Prometheus получили 120 гигабайтов суммарно. В VictoriaMetrics мы получаем уже 4 гигабайта в день. Там немножко другой механизм, чем нежели привыкли видеть в Prometheus. Т. е. данные уже достаточно хорошо жмутся за день, за полчаса. Они уже хорошо пожаты за день, за полчаса, несмотря на то, что еще потом будет мержить данные. В итоге мы сэкономили на дисковом пространстве.

Еще мы экономим на потреблении ресурсов памяти. У нас Prometheus был на момент тестов развернут на виртуальной машине — 8 ядер, 24 гигабайта. Prometheus отъедает практически все. Он упал по OOM Killer. При этом в него лилось всего 900 000 активных метрик. Это порядка 25 000–27 000 метрик в секунду.
VictoriaMetrics у нас была запущена на двухъядерной виртуальной машине с 8 гигабайтами RAM. Нам удалось заставить VictoriaMetrics хорошо работать, покрутив некоторые вещи на 8-гигабайтной машине. В итоге мы уложились в 7 гигабайт. При этом получили скорость отдачи контента, т. е. метрик, даже выше, чем у Prometheus.

В CPU стало гораздо лучше относительно Prometheus. Здесь Prometheus потребляет 2,5 ядра, а VictoriaMetrics всего — 0,25 ядра. На старте — 0,5 ядра. По мере мержа она доходит до одного ядра, но это крайне-крайне редко.

В нашем случае выбор пал на VictoriaMetrics по понятным причинам, мы хотели сэкономить и сэкономили.

Вычеркиваем с ходу два пункта — это выгрузка метрик и большое потребление ресурсов. И нам остается решить два пункта, которые мы для себя еще оставили.

Здесь я оговорюсь сразу, мы VictoriaMetrics рассматриваем как хранилище метрик. Но так как мы будем предоставлять, скорее всего, VictoriaMetrics как хранилище для всего Leroy, нам нужно тех, кто будет использовать этот кластер, ограничить, чтобы они нам его не положили.
Есть замечательный параметр, который позволяет ограничивать по времени, по объему данных и по времени выполнению.
А также есть отличная опция, позволяющая ограничивать потребление памяти, тем самым мы можем найти тот самый баланс, который позволит нам получить нормальную скорость работы и адекватное потребление ресурсов.

Минус еще один пункт, т. е. зачеркиваем пункт — нельзя ограничить потребление памяти.

В первых итерациях мы тестировали VictoriaMetrics Single Node. Дальше мы переходим к VictoriaMetrics Cluster Version.
Здесь у нас развязываются руки на предмет разнесения разных сервисов в VictoriaMetrics в зависимости оттого, на чем они будут крутиться и какие ресурсы потреблять. Это очень гибкое и удобное решение. Мы на себе это использовали.

Основные компоненты VictoriaMetrics Cluster Version — это vmstsorage. Их может быть N количество. В нашем случае пока их 2.
И есть vminsert. Это прокси-сервер, который позволяет нам: устроить шардирование между всеми storages, о которых мы ему рассказали, и он позволяет еще реплику, т. е. у вас будет и шардирование, и реплика.
Vminsert поддерживает протоколы OpenTSDB, Graphite, InfluxDB и remoteWrite от Prometheus.

Есть еще vmselect. Его основная задача — это сходить в vmstorage, получить от них данные, дедуплицировать эти данные и отдать клиенту.

Есть замечательная штука как vmagent. Нам очень нравится она. Она позволяет конфигурировать точно так же как Prometheus и при этом делать все точно так же как Prometheus. Т. е. он собирает с разных сущностей, сервисов метрики и отправляет их в vminsert. Дальше все уже зависит от вас.

Еще один замечательный сервис — это vmalert, который позволяет в качестве бэкенда использовать VictoriaMetrics, получать от vminsert и отправлять в vmselect обработанные данные. Обрабатывает он сами алерты, а также rules. В случае алертов мы получаем алерт через alertmanager.
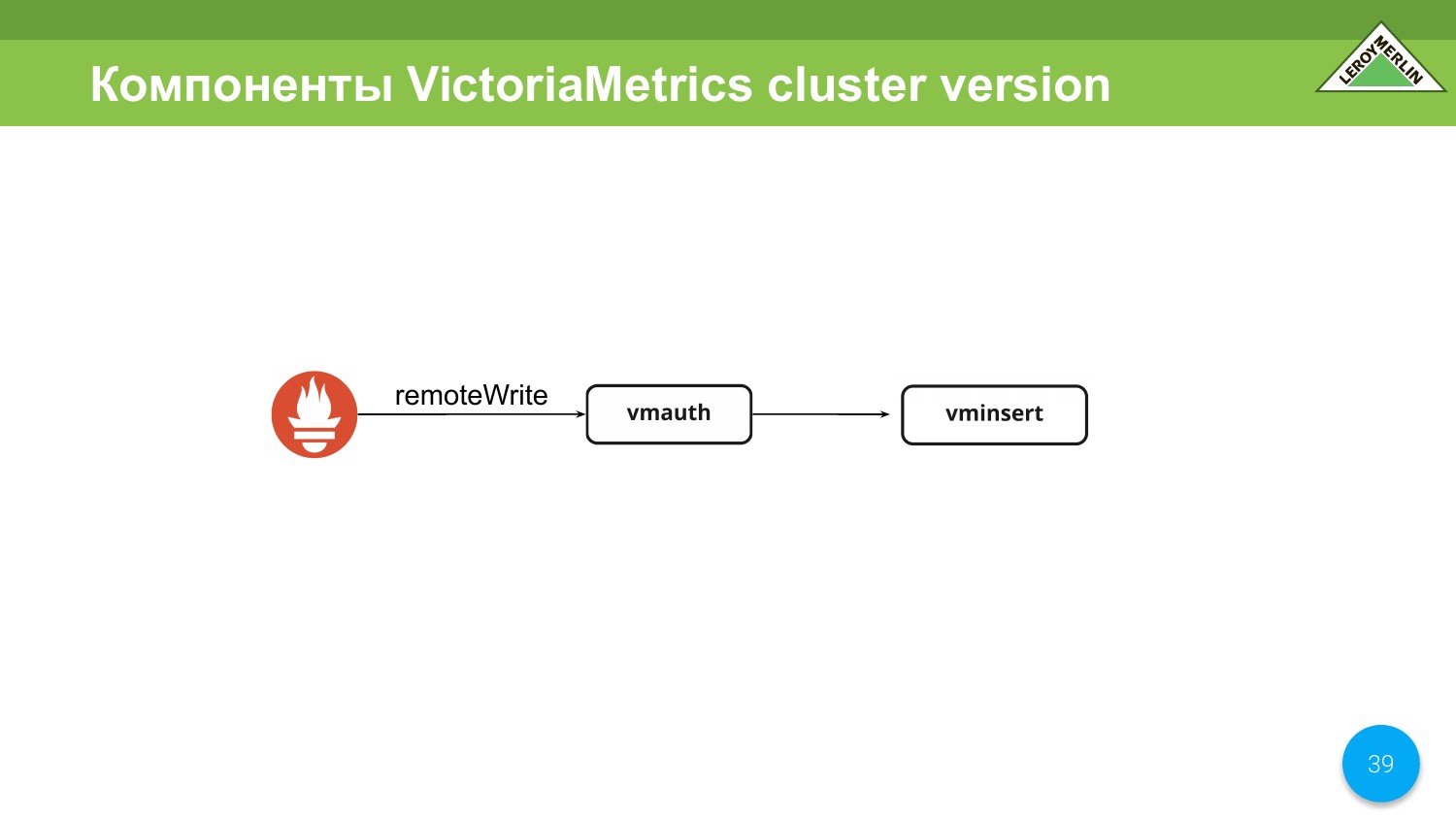
Есть компонент wmauth. Он у нас будет, возможно, использоваться, а, возможно, и нет (мы еще не определись с этим) в качестве системы авторизации при multitenancy версии кластеров. Он поддерживает remoteWrite для Prometheus и может авторизовать на основе url, а точнее второй его части, куда вам можно или нельзя писать.

Есть еще vmbackup, vmrestore. Это, по сути, восстановление и бэкап всех данных. Умеет S3, GCS, file.

Первая итерация нашего кластера была сделана во время карантина. На тот момент не было реплики, поэтому наша итерация представляла собой два разных и независимых кластера, в которые через remoteWrite мы получали данные.

Здесь оговорюсь, что, когда мы переходили с VictoriaMetrics Single Node на VictoriaMetrics Cluster Version, мы все так же остались в тех же потребляемых ресурсах, т. е. основная — это память. Примерно таким образом распределились наши данные, т. е. потребление ресурсов.

Здесь уже была добавлена реплика. Мы объединили все это в один относительно большой кластер. Все данные у нас как шардируются, так и реплицируются.
У всего кластера есть N точек входа, т. е. Prometheus может добавлять данные через HAPROXY. Вот у нас эта точка входа. И через эту точку входа можно заходить c Grafana.

В нашем случае HAPROXY — это единственный порт, который проксирует select, insert и остальные сервисы внутрь этого кластера. В нашем случае нельзя было сделать один адрес, нам пришлось сделать несколько точек входа, потому что сами виртуалки, на которых крутится VictoriaMetrics-кластер, находятся у нас в разных зонах одного облачного провайдера, т. е. не внутри нашего облака, а снаружи.

У нас есть алертинг. Мы его используем. Мы используем alertmanager от Prometheus. Мы в качестве канала доставки алертов используем Opsgenie и Telegram. В Telegram сыплются от dev, может быть, что-то от prod, но больше что-то такое статистическое, нужное инженерам. А Opsgenie — critical. Это звонки, управление инцидентами.

Извечный вопрос: «Кто же мониторит мониторинг?». В нашем случае мониторинг мониторит сам мониторинг, потому что мы используем vmagent на каждой ноде. А так как наши ноды разнесены по разным дата-центрам одного провайдера, у каждого дата-центра у нас свой канал, они независимые и даже если придет split brain, то мы все равно получит алерты. Да, их будет больше, но лучше получить больше алертов, чем ни одного.

Мы заканчиваем наш список с реализацией HA.

И дальше хотел бы отметить опыт общения с комьюнити VictoriaMetrics. Оно получилось очень позитивное. Ребята отзывчивые. Они пытаются вникнуть в каждый кейс, который предлагается.
Я заводил issues на GitHub. Они очень быстро были решены. Есть еще парочка issues, которые не до конца закрыты, но я уже по коду вижу, что работа в этом направлении идет.
Основная боль во время итераций для меня была в том, что если вырублю ноду, то первые 30 секунд у меня vminsert не мог понять, что бэкенда нет. Сейчас это уже решено. И буквально за секунду или две данные забираются уже со всех оставшихся нод, и запрос перестает ждать ту отсутствующую ноду.

Мы хотели в какой-то момент от VictoriaMetrics, чтобы это был VictoriaMetrics operator. Мы его дождались. Мы сейчас в активном построении обвязки над VictoriaMetrics operator, чтобы взять все pre-calculating rules и т. д. Prometheus, потому что мы достаточно активно используем rules, которые идут вместе с оператором Prometheus.
Есть предложения по улучшению кластерной реализации. Я их изложил выше.
И еще очень хочется downsampling. В нашем случае downsampling нужен исключительно для просмотров трендов. Грубо говоря, мне одной метрики в течение дня хватит. Эти тренды нужны на год, на три, на пять, на десять лет. И одного значения метрики вполне достаточно.
- Мы познали боль, как и некоторые наши коллеги, при использовании Prometheus.
- Мы выбрали для себя VictoriaMetrics.
- Она достаточно хорошо масштабируется как вертикально, так и горизонтально.
- Мы можем разносить разные компоненты на разное количество узлов в кластере, лимитировать их по объему памяти, накидывать память и т. д.
Мы будем у себя использовать VictoriaMetrics, потому что она нам очень понравилась. Вот что было и что стало.

https://t.me/VictoriaMetrics_ru1
Пара qr-кодов на чат VictoriaMetrics, мои контакты, техрадар LeroyMerlin.
