Подбор скважин-кандидатов для гидравлического разрыва пласта с использованием методов машинного обучения

Сегодня мы расскажем, как разрабатывали систему поиска скважин-кандидатов для гидравлического разрыва пласта (ГРП) с использованием машинного обучения (далее — ML) и что из этого вышло. Разберёмся, зачем делать гидравлический разрыв пласта, при чём здесь ML, и почему наш опыт может оказаться полезен не только нефтяникам.
Под катом подробная постановка задачи, описание наших IT решений, выбор метрик, создание ML конвейера, разработка архитектуры для выпуска модели в прод.
Зачем делать ГРП мы писали в наших предыдущих статьях тут и тут.
Зачем здесь машинное обучение? ГРП с одной стороны хоть и дешевле бурения, но всё равно мероприятие затратное, а с другой его не получится делать на каждой скважине — не будет эффекта. Поиском подходящих мест занимается эксперт-геолог. Поскольку количество действующих велико (десятки тысяч) нередко варианты упускаются из виду, и Компания недополучает возможную прибыль. Значительно ускорить анализ информации позволяет использование машинного обучения. Однако создать ML модель — это лишь полдела. Нужно заставить её работать в постоянном режиме, связать с сервисом данных, нарисовать красивый интерфейс и сделать так, чтобы пользователю было удобно зайти в приложение и решить свою проблему в два клика.
Абстрагируясь от нефтянки, можно заметить, что подобные задачи решаются во всех компаниях. Все хотят:
A. Автоматизировать обработку и анализ большого потока данных.
B. Уменьшить затраты и не упускать выгоду.
C. Сделать такую систему быстро и эффективно.
Из статьи вы узнаете, как мы реализовали подобную систему, какие инструменты использовали, а также какие шишки набили на тернистом пути внедрения ML в производство. Уверены, что наш опыт может быть интересен всем, кто хочет автоматизировать рутину — вне зависимости от сферы деятельности.
Как происходит подбор скважин на ГРП «традиционным» способом
При подборе скважин-кандидатов на ГРП нефтяник опирается на свой большой опыт и смотрит на разные графики и таблицы, после чего прогнозирует, где сделать ГРП. Достоверно, однако, никто не знает, что творится на глубине нескольких тысяч метров, ведь взглянуть под землю так просто не получается (подробнее можно почитать в предыдущей статье). Анализ данных «традиционными» методами требует значительных трудозатрат, но, к сожалению, не даёт гарантии точного прогноза результатов ГРП (спойлер — с ML тоже).
Если описать текущий процесс определения скважин-кандидатов на ГРП, то он будет состоять из следующих этапов: выгрузка данных по скважинам из корпоративных информационных систем, обработка полученных данных, проведение экспертного анализа, согласование решения, проведение ГРП, анализ результатов. Выглядит просто, но не совсем.
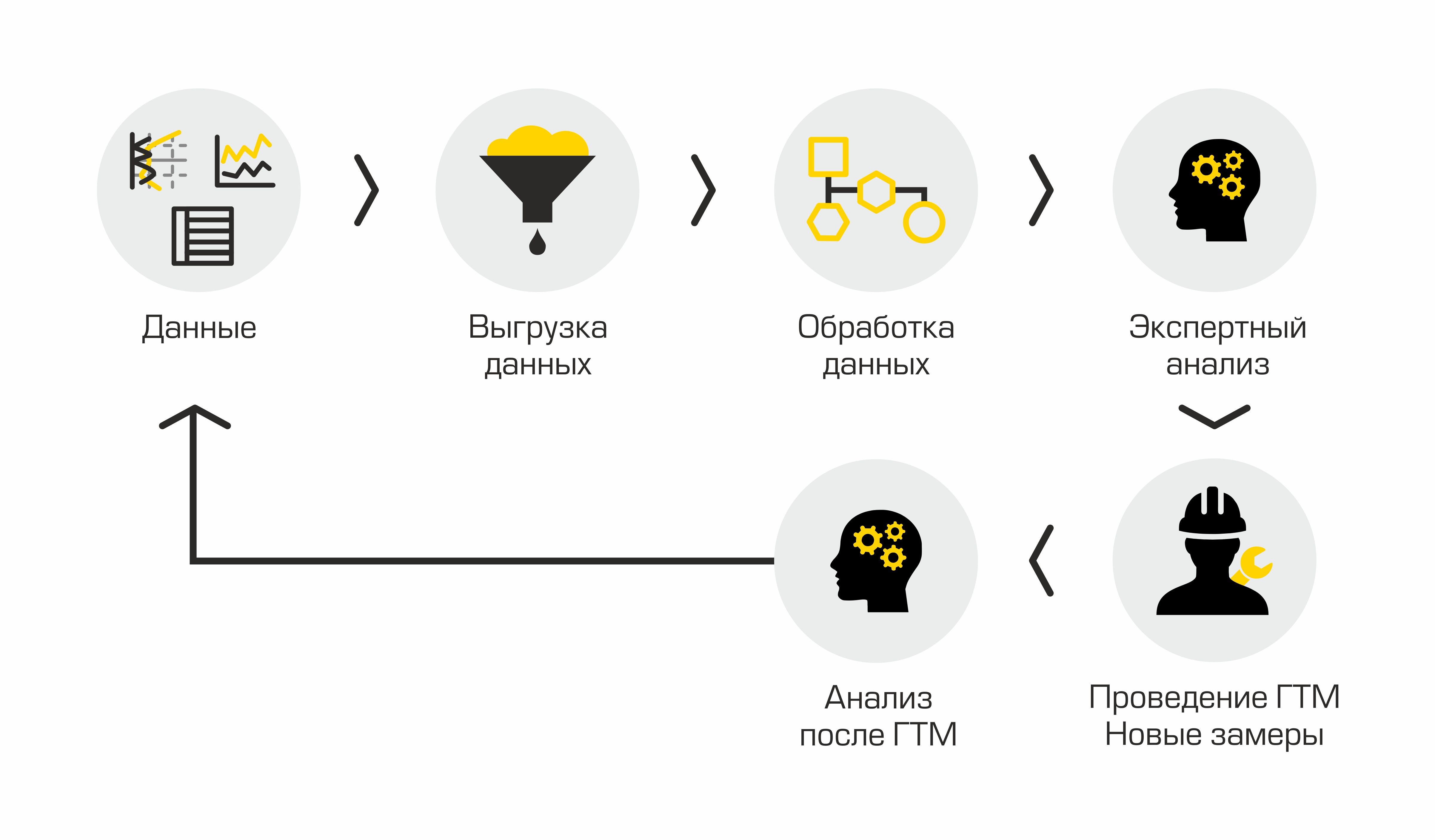
Текущий процесс подбора скважин-кандидатов
Основной минус подобного «ручного» подхода — много рутины, объёмы растут, люди начинают тонуть в работе, отсутствует прозрачность в процессе и методах.
Постановка задачи
В 2019 году перед нашей командой по анализу данных встала задача — создать автоматизированную систему по подбору скважин-кандидатов на ГРП. Для нас это звучало так — смоделировать состояние всех скважин, предположив, что прямо сейчас на них необходимо произвести операцию ГРП, после чего отранжировать скважины по наибольшему приросту добычи нефти и выбрать Топ-N скважин, на которые поедет флот и проведёт мероприятия по увеличению нефтеотдачи.
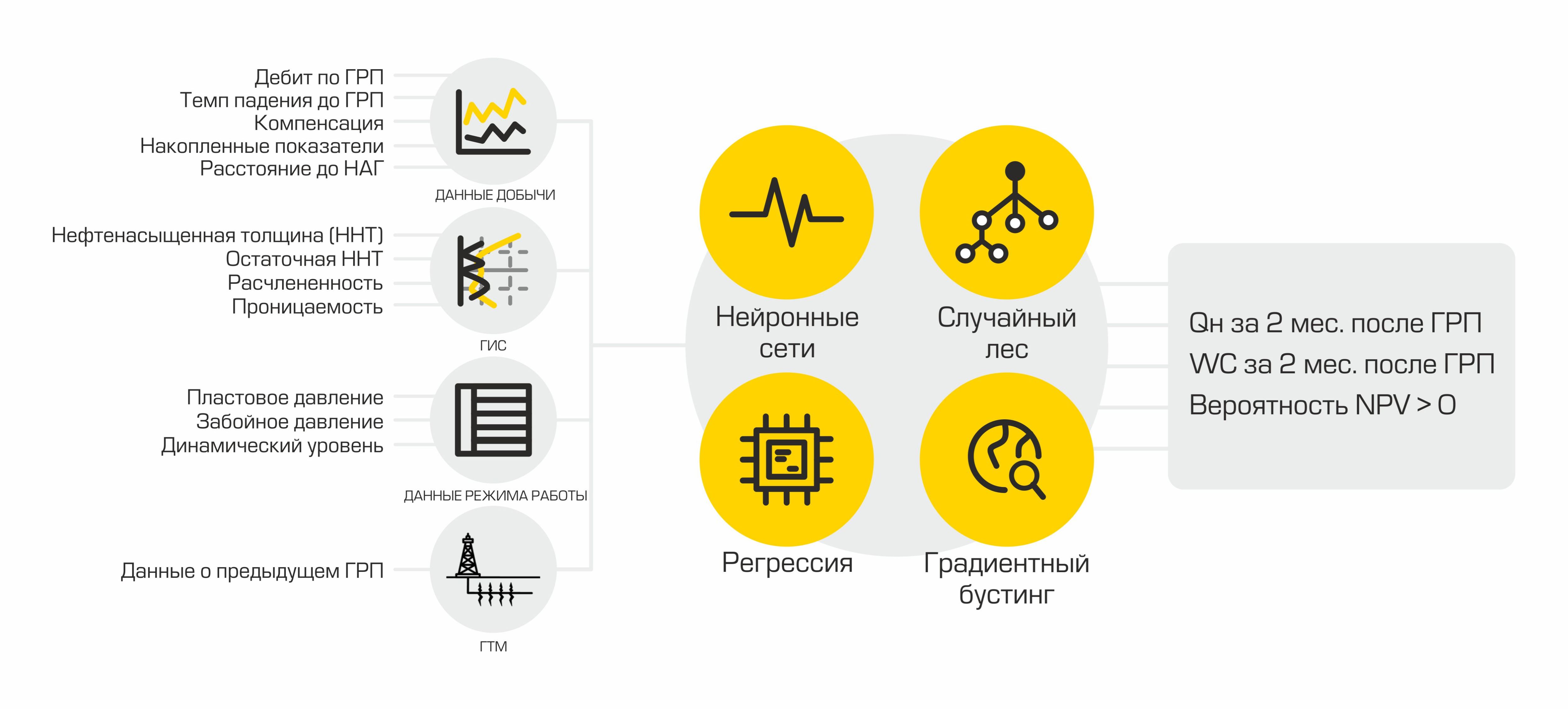
С помощью ML моделей формируются показатели, которые говорят о целесообразности проведения ГРП на конкретной скважине: дебит нефти после планируемого ГРП и успешность данного мероприятия.
В нашем случае дебит нефти представляет собой количество добытой нефти в метрах кубических за 1 месяц. Данный показатель рассчитывается на основе двух величин: дебита жидкости и обводнённости. Жидкостью нефтяники называют смесь нефти и воды — именно эта смесь является продукцией скважин. А обводнённость — это доля содержания воды в данной смеси. Для того чтобы рассчитать ожидаемый дебит нефти после ГРП, используются две модели регрессии: одна прогнозирует дебит жидкости после ГРП, другая прогнозирует обводнённость. С помощью значений, которые возвращают данные модели, рассчитываются прогнозы дебита нефти по формуле:

Успешность ГРП — это бинарная целевая переменная. Она определяется с помощью фактического значения прироста дебита нефти, который получили после ГРП. Если прирост больше некоего порога, определённого экспертом в доменной области, то значение признака успешности равно единице, в противном случае оно равно нулю. Таким образом мы формируем разметку для решения задачи классификации.
Что касается метрики… Метрика должна идти от бизнеса и отражать интересы заказчика, говорят нам любые курсы по машинному обучению. По нашему мнению — здесь кроется главный успех или неуспех проекта по машинному обучению. Группа датасайнтистов может сколь угодно долго улучшать качество модели, но если она никак не повышает бизнес-ценность для заказчика — такая модель обречена. Ведь заказчику было важно получить точно кандидата с «физичными» прогнозами параметров работы скважины после ГРП.
Для задачи регрессии были выбраны следующие метрики:

Почему метрика не одна, спросите вы — каждая отражает свою правду. Для месторождений, где средние дебиты высокие, МАЕ будет большим, а МАРЕ — маленьким. Если взять месторождение с низкими средними дебитами, картина будет противоположной.
Для задачи классификации выбраны следующие метрики:

(вики),
Площадь под кривой ROC–AUC (вики).
Ошибки, с которыми мы столкнулись
Ошибка №1 — построить одну универсальную модель для всех месторождений.
После анализа датасетов стало понятно, что данные меняются от одного месторождения к другому. Оно и неудивительно, так как месторождения, как правило, имеют разное геологическое строение.
Наше предположение, что если взять и загнать все имеющиеся данные для обучения в модель, то она сама выявит закономерности геологического строения, провалилось. Модель, обученная на данных конкретного месторождения, показывала более высокое качество прогнозов, нежели модель, для создания которой использовалась информация обо всех имеющихся месторождениях.
Для каждого месторождения тестировались разные алгоритмы машинного обучения и по результатам кросс-валидации выбирался один с наименьшей MAPE.
Ошибка №2 — отсутствие глубокого понимания данных.
Хочешь сделать хорошую модель машинного обучения для реального физического процесса — пойми, как этот процесс происходит.
Изначально в нашей команде не было доменного эксперта, и мы двигались хаотично. Не замечали, увы, ошибок модели при анализе прогнозов, делали неправильные выводы на основе результатов.
Ошибка №3 — отсутствие инфраструктуры.
Сперва мы выгружали много различных csv файлов для разных месторождений и разных показателей. В определённый момент файлов и моделей накопилось невыносимо много. Стало невозможно воспроизвести уже проведённые эксперименты, терялись файлы, возникала путаница.
1. ТЕХНИЧЕСКАЯ ЧАСТЬ
На сегодняшний день наша система автоподбора кандидатов выглядит следующим образом:
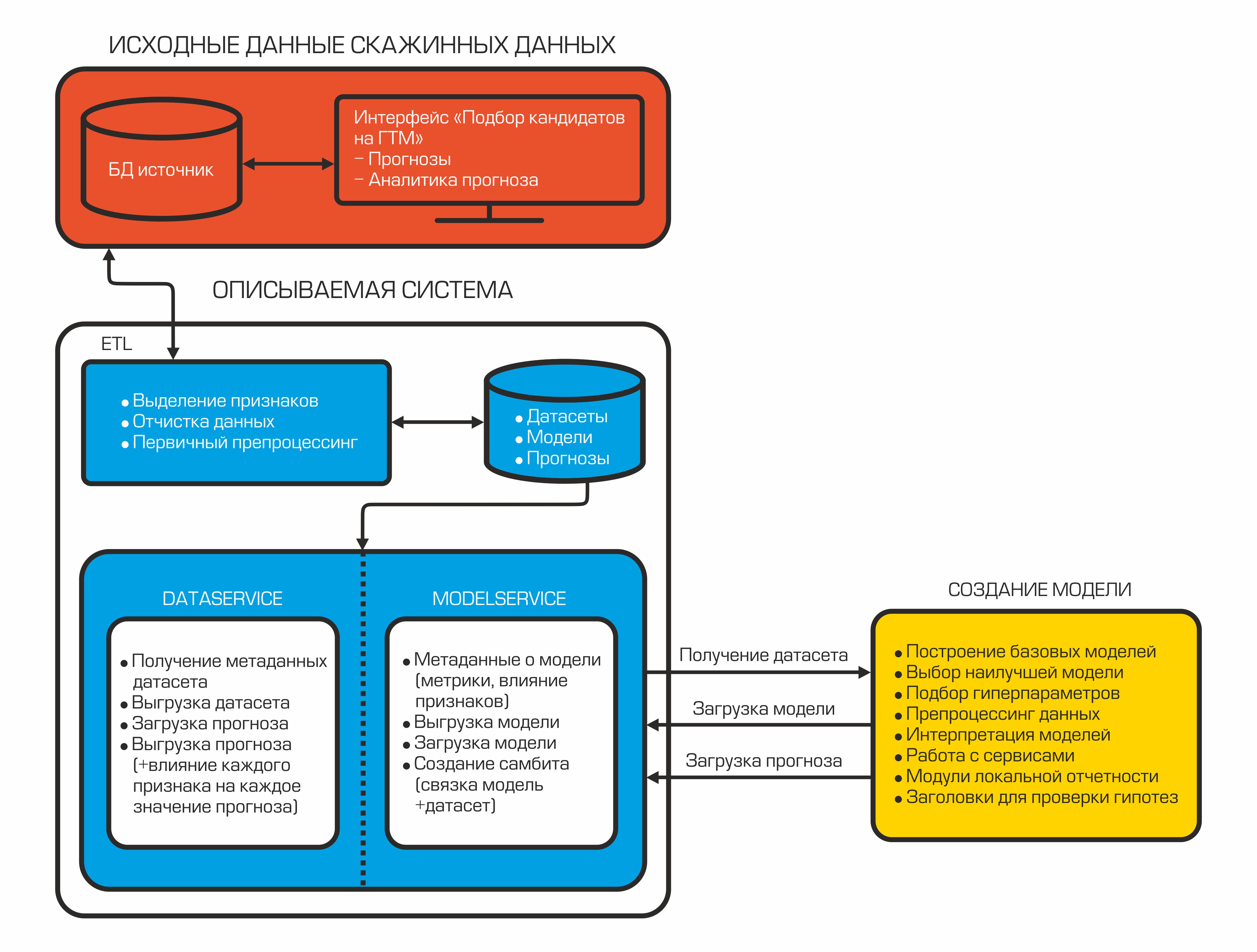
Каждый компонент представляет собой изолированный контейнер, который выполняет определённую функцию.
2.1 ETL = Загрузка данных
Всё начинается с данных. Особенно, если мы хотим построить модель машинного обучения. В качестве интеграционной системы мы выбрали Pentaho Data Integration.

Скриншот одной из трансформаций
Основные плюсы:
- бесплатная система;
- большой выбор компонент для подключения к различным источникам данных и трансформации потока данных;
- наличие веб-интерфейса;
- возможность управлять через REST API;
- логирование.
Плюс ко всему перечисленному у нас был большой опыт разработки интеграций на данном продукте. Почему нужна интеграция данных в проектах ML? В процессе подготовки датасетов постоянно требуется реализовать сложные расчёты, привести данные к единому виду, «по пути» рассчитать новые признаки — средние, изменения параметров во времени и т. д.
Для каждого факта ГРП выгружается более 400 параметров, описывающих работу скважины на момент проведения мероприятия, работу соседних скважин, а также информацию о проведённых ранее ГРП. Далее происходит преобразование и предобработка данных.
В качестве хранилища обработанных данных мы выбрали PostgreSQL. У него большой набор методов для работы с json. Так как мы храним итоговые датасеты в данном формате — это стало решающим фактором.
Проект машинного обучения связан с постоянным изменением входных данных в силу добавления новых признаков, поэтому в качестве схемы базы данных используется Data Vault (ссылка на вики). Эта схема построения хранилищ позволяет быстро добавлять новые данные об объекте и не нарушать целостность таблиц и запросов.
2.2 Сервисы данных и моделей
После причёсывания и расчёта нужных показателей данные заливаются в БД. Здесь они хранятся и ждут, когда датасайнтист возьмёт их для создания ML модели. Для этого существует DataService — сервис, написанный на Python и использующий gRPC протокол. Он позволяет получать датасеты и их метаданные (типы признаков, их описание, размер датасета и т. п.), загружать и выгружать прогнозы, управлять параметрами фильтрации и деления на train/test. Прогнозы в базе хранятся в формате json, что позволяет быстро получать данные и хранить не только значение прогноза, но и влияние каждого признака на этот конкретный прогноз.
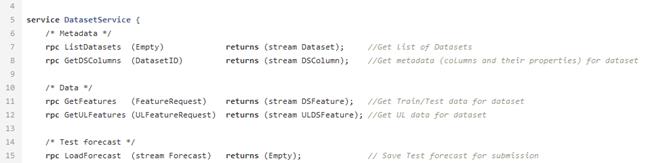
Пример proto файла для сервиса данных.
Когда модель создана, её следует сохранить — для этих целей используется ModelService, также написанный на Python с gRPC. Возможности этого сервиса не ограничиваются сохранением и загрузкой модели. Кроме того, он позволяет мониторить метрики, важность признаков, а также осуществляет связку модель + датасет, для последующего автоматического создания прогноза при появлении новых данных.

Примерно так выглядит структура нашего сервиса моделей.
2.3 ML модель
В определённый момент наша команда поняла, что автоматизация должна коснуться и создания ML моделей. Такая потребность была обусловлена необходимостью ускорения процесса создания прогнозов и проверки гипотез. И мы приняли решение разработать и внедрить в наш конвейер собственную библиотеку AutoML.
Изначально рассматривалась возможность использования готовых AutoML библиотек, однако существующие решения оказались недостаточно гибкими для нашей задачи и не обладали всем нужным функционалом сразу (по просьбам трудящихся можем написать отдельную статью о нашем AutoML). Отметим лишь, что разработанный нами фреймворк содержит классы, используемые для предобработки датасета, генерации и отбора признаков. В качестве моделей машинного обучения используется привычный набор алгоритмов, которые наиболее успешно применялись нами ранее: реализации градиентного бустинга из библиотек xgboost, catboost, случайный лес из Sklearn, полносвязная нейронная сеть на Pytorch и т. д. После обучения AutoML возвращает sklearn пайплайн, который включает в себя упомянутые классы, а также ML модель, которая показала наилучший результат на кросс-валидации по выбранной метрике.
Помимо модели формируется и отчёт о влиянии каких-либо признаков на конкретный прогноз. Такой отчёт позволяет геологам заглянуть под капот таинственного чёрного ящика. Таким образом, AutoML получает размеченный датасет с помощью DataService и после обучения формирует конечную модель. Далее мы можем получить окончательную оценку качества модели, загрузив тестовый датасет, сформировав прогнозы и рассчитав метрики качества. Завершающим этапом является выгрузка бинарного файла сформированной модели, её описания, метрик на ModelService, в то время как прогнозы и информация о влиянии признаков возвращаются на DataService.
Итак, наша модель помещена в пробирку и готова к запуску в прод. В любое время мы можем с её помощью сформировать прогнозы на новых, актуальных данных.
2.4 Интерфейс
Конечный пользователь нашего продукта — это геолог, и ему надо как-то взаимодействовать с ML моделью. Наиболее удобный для него способ — это модуль в специализированном ПО. Его-то мы и реализовали.
Фронтенд, доступный нашему пользователю, выглядит как интернет-магазин: можно выбрать нужное месторождение и получить список наиболее вероятных успешных скважин. В карточке скважины пользователь видит прогнозируемый прирост после ГРП и сам решает, хочет ли он добавить его в «корзину» и рассмотреть подробнее.

Интерфейс модуля в приложении.

Так выглядит карточка скважины в приложении.
Помимо прогнозируемых приростов по нефти и жидкости, пользователь также может узнать, какие признаки повлияли на предлагаемый результат. Важность признаков рассчитывается на этапе создания модели с помощью метода shap, а затем подгружается в интерфейс ПО с DataService.

В приложении наглядно показаны, какие признаки оказались наиболее важными для прогнозов модели.
Также пользователь может посмотреть на аналоги интересующей скважины. Поиск аналогов реализован на стороне клиента с помощью алгоритма K-d дерево.
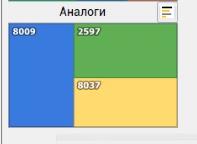
Модуль выводит скважины, схожие по геологическим параметрам.
2. КАК МЫ УЛУЧШАЛИ ML МОДЕЛЬ

Казалось бы, стоит запустить AutoML на имеющихся данных, и будет нам счастье. Но бывает так, что качество прогнозов, получаемых автоматическим способом, не идёт ни в какое сравнение с результатами датасайнтистов. Дело в том, что для улучшения моделей аналитики нередко выдвигают и проверяют различные гипотезы. Если идея позволяет улучшить точность прогнозирования на реальных данных, она реализуется и в AutoML. Таким образом, добавляя новые фичи, мы усовершенствовали автоматическое прогнозирование настолько, чтобы перейти к созданию моделей и прогнозов с минимальной включённостью аналитиков. Вот несколько гипотез, которые были проверены и внедрены в наш AutoML:
1. Изменение метода заполнения пропусков
В самых первых моделях мы заполняли почти все пропуски в признаках средним, кроме категориальных — для них использовалась самое часто встречающееся значение. В дальнейшем, при совместной работе аналитиков и эксперта, в доменной области удалось подобрать наиболее подходящие значения для заполнения пропусков в 80% признаков. Также мы испробовали ещё несколько методов заполнения пропусков с использованием библиотек sklearn и missingpy. Наилучшие результаты дали заполнение константой и KNNImputer — до 5% MAPE.

Результаты эксперимента по заполнению пропусков различными методами.
2. Генерация признаков
Добавление новых признаков для нас — итеративный процесс. Для улучшения моделей мы стараемся добавлять новые признаки на основе рекомендаций доменного эксперта, на основе опыта из научных статей и наших собственных выводов из данных.

Проверка гипотез, выдвигаемых командой, помогает вводить новые признаки.
Одними из первых стали признаки, выделенные на основе кластеризации. По сути, мы просто выделили в датасете кластеры на основе геологических параметров и сгенерировали основные статистики по другим признакам на основе кластеров — это дало небольшой прирост в качестве.
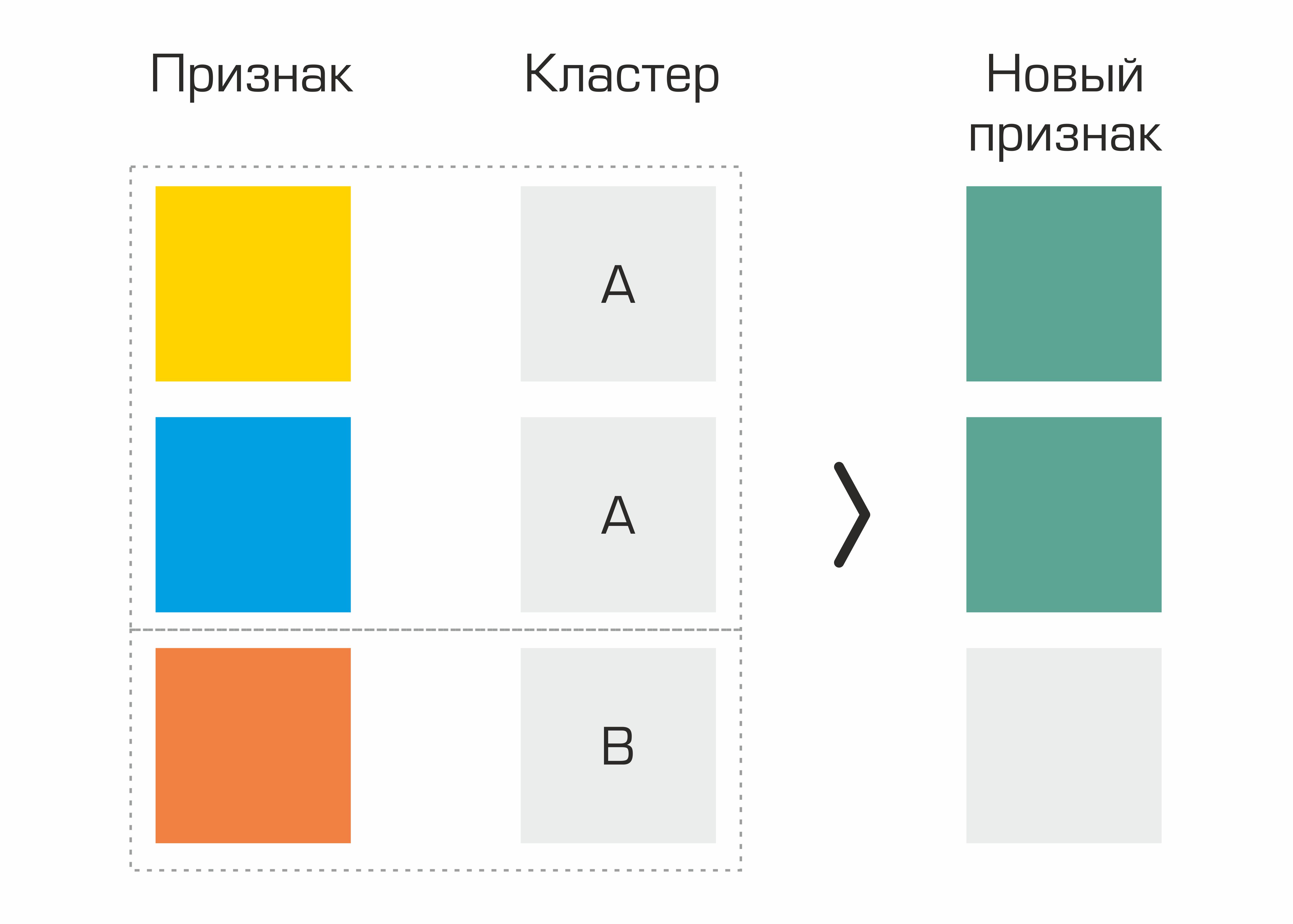
Процесс создания признака на основе выделения кластеров.
Также мы добавляли признаки, придуманные нами при погружении в доменную область: накопленная добыча нефти, нормированная на возраст скважины в месяцах, накопленная закачка, нормированная на возраст скважины в месяцах, параметры, входящие в формулу Дюпюи. А вот генерация стандартного набора из PolynomialFeatures из sklearn прироста в качестве нам не дала.
3. Отбор признаков
Отбор признаков мы производили многократно: как вручную вместе с доменным экспертом, так и используя стандартные методы feature selection. После нескольких итераций нами было принято решение убрать из данных некоторые признаки, не влияющие на таргет. Таким образом, нам удалось уменьшить размерность датасета, сохранив при этом прежнее качество, что позволило значительно ускорить создание моделей.
А теперь про полученные метрики…
На одном из месторождений мы получили следующие показатели качества моделей:

Стоит отметить, что результат выполнения ГРП также зависит от ряда внешних факторов, которые не прогнозируются. Поэтому о снижении МАРЕ до 0 говорить нельзя.
Заключение
Подбор скважин-кандидатов для ГРП с использованием ML — амбициозный проект, объединивший в команду 7 человек: дата инженеров, датасайнтистов, доменных экспертов и менеджеров. Сегодня проект фактически готов к запуску и уже проходит апробацию на нескольких дочерних обществах Компании.
Компания открыта для экспериментов, поэтому из списка были выбраны около 20 скважин, и на них провели операции гидроразрыва. Отклонение прогноза с фактическим значением запускного дебита нефти (МАРЕ) составило около 10%. И это очень неплохой результат!
Не будем лукавить: особенно на начальном этапе несколько предложенных нами скважин оказались неподходящими вариантами.
Пишите вопросы и комментарии — постараемся на них ответить.
Подписывайтесь на наш блог, у нас есть ещё много интересных идей и проектов, о которых мы обязательно напишем!
