В начале был “workflow”

Добрый день! Меня зовут Кирилл, и я DevOps-инженер. За свою карьеру мне не раз приходилось внедрять DevOps-практики как в существующие, так и в новые команды, поэтому хочу поделиться своим опытом и мыслями по поводу стратегий ветвления. Существует множество различных типов рабочих процессов, и чтобы разобраться что к чему, предлагаю рассмотреть пример создания нового программного продукта.
Часть 1: Рабочий процесс
Мы в начале пути. Создали репозиторий и начали писать код, неспешно, коммит за коммитом, публикуя изменения в мастер. Появляется первый прототип приложения, появляются тесты, проходит сборка, и вот настал момент развёртки приложения с целью предоставить свой продукт пользователям.
А далее как обычно бывает: всплывают первые запросы от пользователей на добавление новых фич/устранение багов и т.д., разработка кипит. Для того чтобы ускорить выход новых версий, принимается решение расширить команду DevOps«ом, и для решения насущных проблем DevOps предлагает построить CI/CD-конвейер (pipeline). И вот пришло время рассмотреть, как же CI/CD-конвейер ляжет на наш рабочий процесс, где у нас сейчас только мастер.

Для примера мы взяли простой конвейер с одним окружением. И вроде всё выглядит хорошо: разработчик запушил код в мастер, запустился конвейер, код прошёл ряд проверок, собрался и развернулся в окружении.
А теперь рассмотрим ситуацию, когда конвейер прервался на тестах.

То есть тесты показали, что в текущей версии мастера есть ошибки. Нам на руку, что в нашем примере конвейер прервался, и на окружении до сих пор работающее приложение, и пользователь остаётся довольным. А вот что начинается в команде разработки:

На данной картинке (которая может показаться слишком преувеличенным примером, однако такое бывает), мы видим, что в первом коммите, который ранее попал на окружение, каких-либо проблем нет. На втором коммите в мастер конвейер прервался. И вот тут начинается самое интересное. Понятно, что запушенный код нерабочий и надо его исправлять, чем и занялся разработчик. Но что, если у нас не один разработчик, а команда, где каждый усердно трудится над своей задачей? Второй разработчик ответственно начал добавлять новые улучшения в продукт, но в их основе лежит второй коммит. Что же будет дальше с этими изменениями? Сколько времени уйдёт у первого разработчика на исправление? Насколько сильными будут изменения в новом коммите? Что в это время делать второму разработчику? Что делать с уже написанными вторым разработчиком фичами? В общем, слишком много вопросов, а на выходе получаем:
уменьшение производительности,
впустую потраченное время,
много головной боли.
Для решения насущных проблем можно прибегнуть к изменению рабочего процесса.
Первым делом добавим небезызвестные feature-ветки.
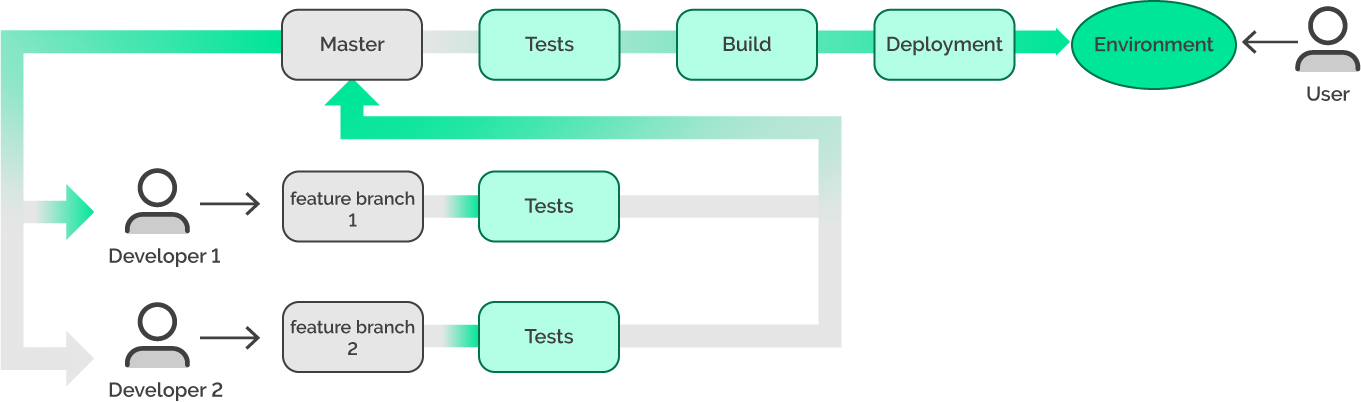
В отдельных feature-ветках каждый разработчик может без стресса заниматься своей задачей. При этом мы блокируем коммиты напрямую в мастер (или договариваемся так не делать), и впоследствии все новые фичи добавляются в мастер через «merge request».
И в очередной раз проиграем проблему: в feature-ветке обнаружен баг.

При таком рабочем процессе, если находится какая-либо неполадка, разработчик спокойно занимается исправлением, не влияя на работу остальной команды, и в мастере находится рабочий код, а следовательно, и окружение остаётся рабочим.
Но что, если на окружение попал новый мастер, и спустя какое-то время обнаружен баг (не углядели, всякое бывает).

Соответственно, это уже критическая ситуация: клиент не доволен, бизнес не доволен. Нужно срочно исправлять! Логичным решением будет откатиться. Но куда? За это время мастер продолжал пополняться новыми коммитами. Даже если быстро найти коммит, в котором допущена ошибка, и откатить состояние мастера, то что делать с новыми фичами, которые попали в мастер после злосчастного коммита? Опять появляется много вопросов.
Что ж, давайте не будем поддаваться панике, и попробуем ещё раз изменить наш рабочий процесс, добавив теги.

Теперь, когда мастер пополняется изменениями из feature-веток, мы будем помечать определённое состояние мастера тегом.
Но вот в очередной раз пропущен баг в теге v2.0.0, который уже на окружении.

Как решить проблему теперь?
Правильно, мы можем повторно развернуть версию v1.0.0, считая её заведомо рабочей.
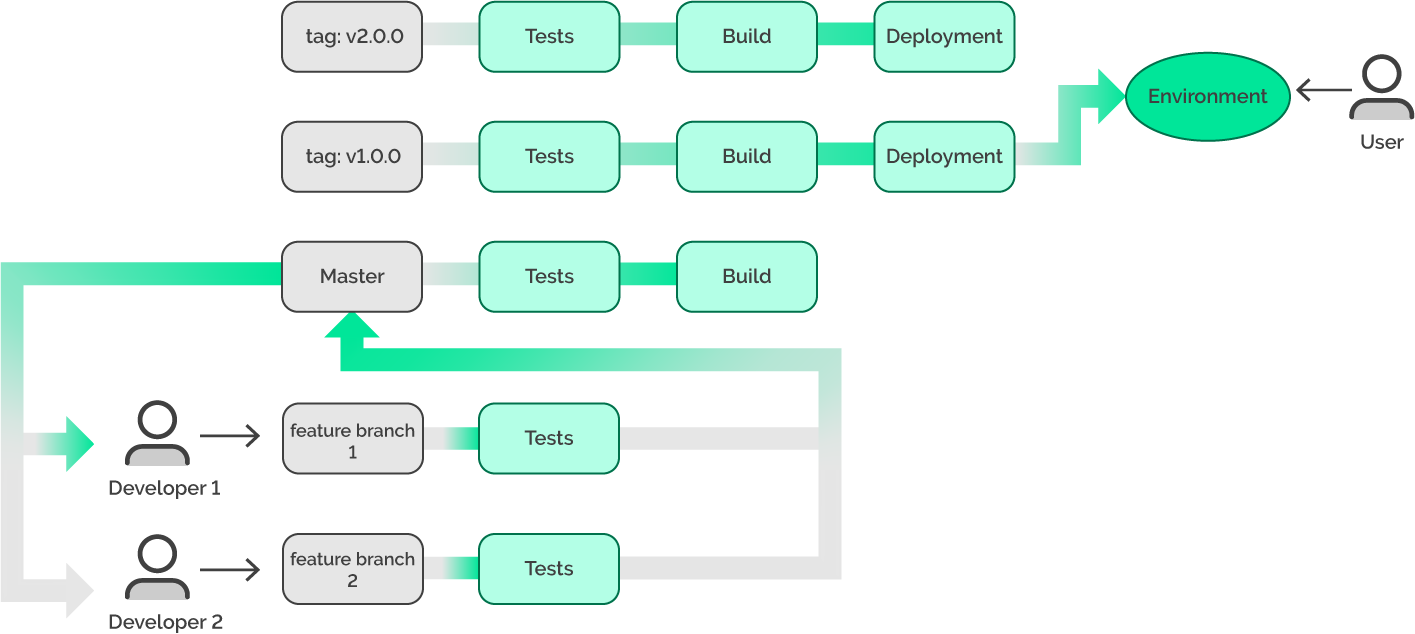
И таким образом, наше окружение снова рабочее. А мы, в свою очередь, ничего не делая, получили следующее:
сэкономили время и, как следствие, деньги,
восстановили работоспособность окружения,
предотвратили хаос,
локализовали проблему в версии v2.0.0.
Мы рассмотрели, как с помощью элементарного изменения рабочего процесса можно решить какие-то проблемы, и теперь хочется спросить, что это за рабочий процесс? Ну, однозначно здесь ответить нельзя.
Для примера возьмём и рассмотрим давно всем известный Git Flow:
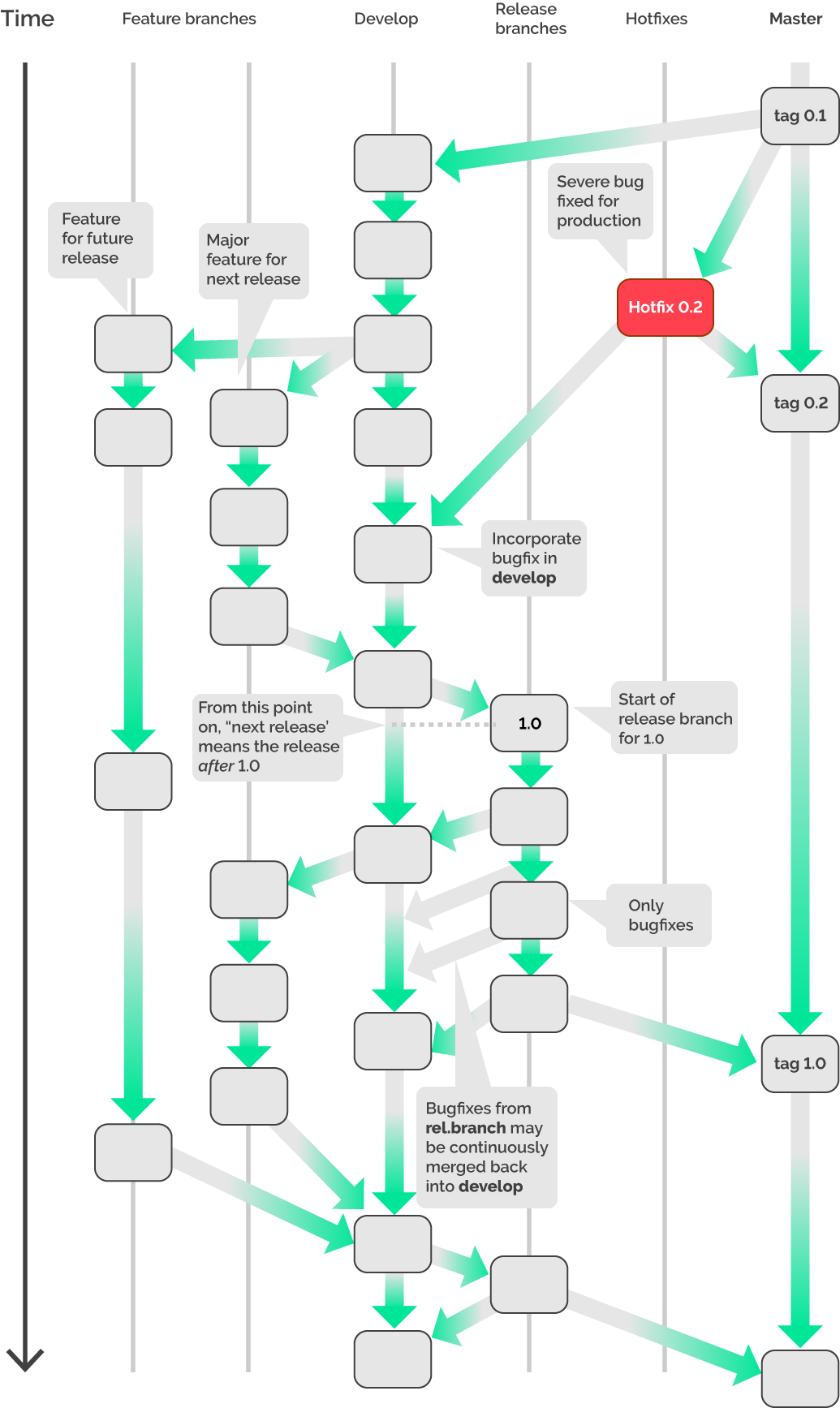
Сравним его с нашим последним примером и увидим, что у нас нет develop-ветки, а ещё мы не использовали hotfixes-ветки. Следовательно, мы не можем сказать, что использовали именно Git Flow. Однако мы немного изменим наш пример, добавив develop- и release-ветки.

И теперь в каком-то приближении наш пример стал похожим на Git Flow. Однако что мы получили в этом случае? Какие проблемы нам удалось решить и как нам удалось улучшить нашу жизнь? По моему мнению, добив наш рабочий процесс до Git Flow, который многие используют как эталонную модель, мы всего-навсего усложнили себе жизнь. И здесь я не хочу сказать, что Git Flow плохой, просто в наших простых примерах он определённо излишний.
Что ж, на Git Flow жизнь не заканчивается, ведь есть не менее известный GitHub Flow.

И первое, что мы можем заметить, так это то, что он выглядит в разы проще, чем Git Flow. И если сравнить с нашим примером, то мы можем заметить, что здесь не используются теги. Но, как мы можем вспомнить, мы ведь добавляли их не просто так, а с целью решить определённые проблемы, поэтому и здесь мы не можем сказать, что мы использовали конкретно GitHub Flow.
Собственно, сравнив наш рабочий процесс из примера с Git Flow и GitHub Flow, хотелось бы подчеркнуть следующее: безусловно, существование паттернов для построения рабочих процессов — это огромный плюс, так как мы можем взять существующий паттерн и начать работать по нему, и в определённых случаях какой-либо определённый паттерн идеально впишется в процесс разработки. Однако это работает и в другую сторону: какой-либо существующий паттерн может вставить нам палки в колеса и усложнить процесс разработки.

Поэтому не стоит забывать, что Git и его рабочие процессы — это лишь инструменты, а инструменты, в свою очередь, призваны облегчить жизнь человека, и иногда стоит посмотреть на проблему под другим углом для её решения.
Часть 2: Участь DevOps’а
В первой части мы рассмотрели, как выглядит рабочий процесс, а теперь посмотрим, почему для DevOps-инженера так важен корректно настроенный рабочий процесс. Для этого вернёмся к последнему примеру, а именно к построению того самого конвейера для реализации процесса CI/CD.
Так как конвейер может быть реализован различными инструментами, мы сфокусируемся конкретно на том, почему рабочий процесс важен для DevOps.
Собственно, построение конвейера можно изобразить вот такой простой картинкой:

Ну или одним вопросом: «как связать между собой код в репозитории и окружение?»
Следовательно, нужно понимать, какой именно код должен попасть в окружение, а какой нет. К примеру, если в ответ на вопрос: «Какой рабочий процесс используется?» мы услышим: «GitHub Flow», то автоматически мы будем искать нужный код в master-ветке. И ровно наоборот, если не построен никакой рабочий процесс и куски рабочего кода разбросаны по всему репозиторию, то сначала нужно разобраться с рабочим процессом, а лишь потом начинать строить конвейер. Иначе рано или поздно на окружение попадёт то, что возможно не должно там быть, и как следствие, пользователь останется без сервиса/услуги.
Сам конвейер может состоять из множества шагов, в том числе у нас может быть несколько окружений.

Но для наглядности далее рассмотрим два основных этапа в CI/CD- конвейерах: build и deployment/delivery. И начнем мы, пожалуй, с первого — build.
Build — процесс, конечным результатом которого является артефакт.
Для простоты введём следующее условие: артефакты должны версионироваться и храниться в каком-либо хранилище для последующего извлечения. Что ж, если у нас нет рабочего процесса, то первый (возможно, глупый, но важный) вопрос — как мы будем именовать артефакты при хранении. Опять же, вернёмся к нашему примеру с рабочим процессом, где мы использовали теги.
Так вот, у нас есть отличная возможность взять имя тега для артефакта и опубликовать его. Но что, если у нас нет никакого рабочего процесса? Что ж, тут уже сложнее. Конечно, мы можем взять хеш коммита, или дату, или придумать что-либо ещё для идентификации артефакта. Но очень скоро разобраться в этом будет практически невозможно.
И вот пример из реальной жизни.
Представьте ситуацию, когда вы хотите загрузить новую версию Ubuntu, и вместо такого списка версий:

… у вас будет список хешей коммитов. Следовательно, это может быть неудобно не только для команды, но и для пользователя.
Бывают случаи, когда мы можем пренебречь именованием. Поэтому рассмотрим ещё один небольшой пример: у нас нет конкретного рабочего процесса; как следствие, у нас нет понимания, что именно мы должны хранить в нашем хранилище. Что, в свою очередь, может быть чревато последствиями, так как хранилище так или иначе ограничено: либо деньгами, либо местом, либо и тем, и другим. Поэтому в ситуации, когда у нас нет конкретного рабочего процесса, мы можем начать публиковать артефакт из каждой feature-ветки (так как чёткой определённости у нас нет), но в таком случае рано или поздно возникнет ситуация, когда ресурсы закончатся, и придётся расширяться, что опять же несёт за собой трату как человеческих, так и денежных ресурсов.
Конечно, на этом примеры не заканчиваются, но думаю, что теперь мы можем перейти к delivery/deployment.
Delivery — процесс, в рамках которого развёртка приложения на окружении происходит вручную.
Deployment — процесс, в рамках которого развёртка приложения происходит автоматически.
В случае с Delivery мы можем автоматизировать процесс развёртки в окружение и запускать его вручную. Однако если не будет выстроен рабочий процесс, то тогда мы вернёмся к той ситуации, которая возникала в наших примерах с рабочим процессом ранее, когда в коммите обнаруживался баг.
Если же говорить о deployment, абсолютно неправильно реализовывать continuous deployment в случае, когда у нас не выстроен рабочий процесс. Потому что несложно представить, что будет, если изменения в коде каждый раз будут автоматически попадать на окружение.
Следовательно, и здесь нам крайне важно наличие рабочего процесса, по крайне мере в том случае, когда преследуется цель сделать хорошо.
Сейчас мы рассмотрели лишь две основных стадии при построении конвейера, но однозначно можно сказать, что беспорядок в рабочем процессе будет влиять на каждый этап реализации процессов CI/CD. И под беспорядком имеется в виду не только отсутствие рабочего процесса, но и его избыточность.
Заключение
В конце хотелось бы добавить, что основная мысль, которую мне хотелось донести этой статьёй, — это то, что есть книги, теория и так далее, а есть здравый смысл. Конечно, есть множество различных практик и примеров, которые успешно работают в том или ином продукте, но это не значит, что эти практики сработают в вашей команде. Поэтому если вас мучает вопрос: «Почему у нас это не работает?» или «Что нам нужно сделать, чтоб у нас это заработало?», то попробуйте задаться вопросом: «А надо ли оно нам?»
