Устройство поисковых систем: базовый поиск и инвертированный индекс
Под капотом почти каждой поисковой строки бьется одно и то же пламенное сердце — инвертированный индекс. Именно инвертированный индекс принимает текстовые запросы и возвращает пользователю список документов, а пользователь смотрит на всё это дело и радуется котиками, ответам с StackOverflow и страничкам на вики.
В статье описано устройство поиска, инвертированного индекса и его оптимизаций с отсылками к теории. В качестве подопытного кролика взят Tantivy — реализация архитектуры Lucene на Rust. Статья получилась концентрированной, математикосодержащей и несовместимой с расслабленным чтением хабра за чашкой кофе, осторожно!
Формальная постановка задачи: есть набор текстовых документов, хотим быстро находить в этом наборе наиболее подходящие документы по поисковому запросу и добавлять в набор новые документы для последующего поиска.
Первым шагом определим что такое релевантность документа запросу, причем сделаем это способом, понятным компьютеру. Вторым шагом дорисуем сову найдем K наиболее релевантных документов и покажем их пользователю. Ну, а дальше заставим всё это работать с приемлемой скоростью.
Определение релевантности
На человеческом языке «релевантность» — это смысловая близость документа к запросу. На языке математики близость может выражаться через близость векторов. Поэтому для математического выражения релевантности необходимо документам и запросам из мира людей сопоставить вектора в некотором пространстве из мира математики. Тогда документ будет считаться релевантным запросу, если документ-вектор и запрос-вектор в нашем пространстве находятся близко. Поисковая модель с таким определением близости зовётся векторной моделью поиска.
Основной проблемой в векторной модели поиска является построение векторного пространства  и преобразования документов и запросов в . Вообще говоря, векторные пространства и преобразования могут быть любыми, лишь бы близкие по смыслу документы или запросы отображались в близкие вектора.
и преобразования документов и запросов в . Вообще говоря, векторные пространства и преобразования могут быть любыми, лишь бы близкие по смыслу документы или запросы отображались в близкие вектора.
Современные библиотеки позволяют по щелчку пальцев конструировать сложные векторные пространства с небольшим количеством измерений и высокой информационной нагрузкой на каждое измерение. В таком пространстве все координаты вектора характеризуют тот или иной аспект документа или запроса: тему, настроение, длину, лексику или любую комбинацию этих аспектов. Зачастую то, что характеризует координата вектора, невыразимо на человеческом языке, зато понимается машинами. Нехитрый план построения такого поиска:
- Берем любимую библиотеку построения эмбеддингов для текстов, например fastText или BERT, преобразуем документы в вектора
- Складываем полученные вектора в любимую библиотеку для поиска K ближайших соседей (k-NN) к данному вектору, например в faiss
- Поисковый запрос преобразовываем в вектор тем же методом, что и документы
- Находим ближайшие вектора к запросу-вектору и извлекаем соответствующие найденным векторам документы
Поиск, основанный на k-NN, будет очень медленным, если вы попытаетесь засунуть в него весь Интернет. Поэтому мы сузим определение релевантности так, чтобы всё стало вычислительно проще.
Мы можем считать более релевантными те документы, в которых больше совпавших слов со словами из поискового запроса. Или в которых встречаются более «важные» слова из запроса. Именно вот такие выхолощенные определения релевантности использовались первыми людьми при создании первых масштабных поисковых систем.
NB.: Здесь и далее «слова» в контексте документов и запросов будут называться «термами» с целью избежания путаницы
Запишем релевантность в виде двух математических функций и далее будем наполнять их содержанием:
 — релевантность документа запросу
— релевантность документа запросу — релевантность документа одному терму
— релевантность документа одному терму
На
наложим ограничение аддитивности и выразим релевантность запроса через сумму релевантностей термов: 
Наиболее известные аддитивные функции релевантности — TF-IDF и BM25. Они используются в большинстве поисковых систем как основные метрики релевантности.
Откуда взялись TF-IDF и BM25
Если вы знаете как выводятся формулы из заголовка, то эту часть можно пропустить.
И TF-IDF, и BM25 показывают степень релевантности документа запросу одним числом. Чем выше значение метрик, тем более релевантен документ. Сами по себе значения не имеют какой-либо значимой интерпретации. Важно только сравнение значений функций для различных документов. Один документ более релевантен данному запросу, чем другой, если значение его функции релевантности выше.
Попробуем повторить рассуждения авторов формул и воспроизвести этапы построения TF-IDF и BM25. Обозначим размер корпуса проиндексированных документов как  . Самое простое, что можно сделать — это определить релевантность равной количеству вхождений терма (termFrequency или
. Самое простое, что можно сделать — это определить релевантность равной количеству вхождений терма (termFrequency или  ) в документ:
) в документ:

 , а запрос
, а запрос  , состоящий из нескольких термов, и мы хотим посчитать запроса для этого документа? Вспоминаем про ограничение аддитивности и просто суммируем все отдельные по термам из запроса:
, состоящий из нескольких термов, и мы хотим посчитать запроса для этого документа? Вспоминаем про ограничение аддитивности и просто суммируем все отдельные по термам из запроса:
Исправляем проблему, взвешивая каждый терм в соответствии с его важностью:

 — это количество документов в корпусе, содержащих терм . Получается, что чем чаще терм встречается, тем менее он важен и тем меньше будет . Термы вроде «and» будут иметь огромный и соответственно маленький .
— это количество документов в корпусе, содержащих терм . Получается, что чем чаще терм встречается, тем менее он важен и тем меньше будет . Термы вроде «and» будут иметь огромный и соответственно маленький . Вроде уже лучше, но теперь есть другая проблема — сам по себе мало о чём говорит. Если  , и размер корпуса проиндексированных текстов — 100 документов, то терм «жираф» в этом случае считается очень частым. А если размер корпуса 100 000, то уже редким.
, и размер корпуса проиндексированных текстов — 100 документов, то терм «жираф» в этом случае считается очень частым. А если размер корпуса 100 000, то уже редким.
Зависимость от может быть убрана превращением в относительную частоту путем деления на :

 в первом случае будет равно 100, а во-втором — 50. Терм «жираф» получит в два раза меньше очков, чем терм «слон» только лишь потому, что документов с жирафом на один больше, чем со слоном. Исправим эту ситуацию, сгладив функцию .
в первом случае будет равно 100, а во-втором — 50. Терм «жираф» получит в два раза меньше очков, чем терм «слон» только лишь потому, что документов с жирафом на один больше, чем со слоном. Исправим эту ситуацию, сгладив функцию . Сглаживание можно произвести различными способами, мы сделаем это логарифмированием:

Вряд ли документ, содержащий терм «жираф» 200 раз в два раза лучше, чем документ, содержащий терм «жираф» 100 раз. Поэтому и тут проедемся сглаживанием, только теперь сделаем это не логарифмированием, а чуть иначе. Заменим  на
на  С каждым увеличением числа вхождения терма на единицу, значение
С каждым увеличением числа вхождения терма на единицу, значение  прирастает все меньше и меньше — функция сглажена. А параметром
прирастает все меньше и меньше — функция сглажена. А параметром  мы можем контролировать кривизну этого сглаживания. Говоря по-умному, параметр контролирует степень сатурации функции.
мы можем контролировать кривизну этого сглаживания. Говоря по-умному, параметр контролирует степень сатурации функции.
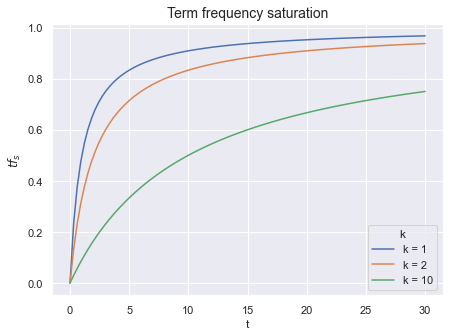
Рис. 0: Чем выше значение
, тем сильнее будут учитываться последующие вхождения одного и того же терма.У есть два замечательных побочных эффекта.
Во-первых, будет больше у документов, содержащих все слова из запроса, чем у документов, которые содержат одно слово из запроса несколько раз. Топ документов в этом случае будет больше радовать глаз и ум пользователя, ведь все термы запроса обычно печатаются не просто так.
Во-вторых, значение функции ограничено сверху. Остальная часть тоже ограничена сверху, поэтому и вся функций имеет ограничение сверху (далее  — upper bound). Более того, в нашем случае очень просто посчитать.
— upper bound). Более того, в нашем случае очень просто посчитать.
Почему важно для нас? является максимально возможным вкладом этого терма в значение функции релевантности. Если мы знаем , то можем срезать углы при обработке запроса.
Последний шаг — начнем учитывать длину документов в . В длинных документах терм «жираф» может встретится просто по-случайности и его наличие в тексте ничего не скажет о реальной теме документа. А вот если документ состоит из одного терма и это терм «жираф», то можно совершенно точно утверждать, что документ о жирафах.
Очевидный способ учесть длину документа — взять количество слов в документе  . Дополнительно поделим на среднее количество слов во всех документах
. Дополнительно поделим на среднее количество слов во всех документах  . Сделаем мы это исходя из тех же соображений, из каких нормировали выше — абсолютные значения портят качество метрики.
. Сделаем мы это исходя из тех же соображений, из каких нормировали выше — абсолютные значения портят качество метрики.
Найдем теперь место для длины документа в нашей формуле. Когда растет, то значение  падает. Если мы будем умножать на
падает. Если мы будем умножать на  , то получится, что более длинные документы будут получать меньший . То что нужно!
, то получится, что более длинные документы будут получать меньший . То что нужно!
Можно еще дополнительно параметризовать силу, с которой мы учитываем длину документа, для контроля поведения формулы в разных ситуациях. Заменим на  и получим:
и получим:

 формула вырождается в
формула вырождается в  , а при
, а при  формула принимает вид
формула принимает вид  .
. Ещё раз: — сила влияния повторяющихся термов на релевантность, а  — сила влияния длины документа на релевантность.
— сила влияния длины документа на релевантность.
Подставим в :

 (этот член называется
(этот член называется  ) заменен на
) заменен на  . Замена не имеет простых эвристик под собой и основана на подгонке под теоретически более чистую форму RSJ модели. Такая форма дает меньший вес слишком часто встречающимся термам: артиклям, союзам и прочим сочетаниям букв, несущим малое количество информации.
. Замена не имеет простых эвристик под собой и основана на подгонке под теоретически более чистую форму RSJ модели. Такая форма дает меньший вес слишком часто встречающимся термам: артиклям, союзам и прочим сочетаниям букв, несущим малое количество информации.Важное замечание: из формулы BM25 теперь видно, что в бОльшей мере зависит от значения , то есть от частоты терма в корпусе. Чем реже встречается терм, тем выше его максимально возможный вклад в .
Реализация инвертированного индекса
С учетом ограниченной памяти, медленных дисков и процессоров нам теперь нужно придумать структуру данных, способную выдавать top-K релевантных по BM25 документов.
Есть у нас набор документов, по которым необходимо вести поиск. Всем документам присваивается document ID или DID. Каждый документ разбивается на термы, термы при желании обрезаются или приводятся к каноничной форме. Для каждого обработанного терма составляется список DID документов, содержащих этот терм — постинг-лист.

Рис. 1: Постинг-листы
Различные реализации инвертированных индексов также могут сохранять точные места в документе, где встречается терм или общее количество вхождений терма в документ. Эта дополнительная информация используется при подсчете метрик релевантности или для выполнения специфичных запросов, в которых важно взаимное расположение термов в документе. Сам постинг-лист сортируется по возрастанию DID, хотя существуют и иные подходы к его организации.
Вторая часть инвертированного индекса — словарь всех термов. Под словарь используется KV-хранилище, где термы являются ключами, а значения — адреса постинг-листов в RAM или на диске. Обычно для KV-хранилища в оперативной памяти используются хеш-таблицы и деревья. Однако для словаря термов могут оказаться более подходящими другие структуры, например, префиксные деревья.

Рис. 2: Словарь термов (префиксное дерево)
В Tantivy для хранения термов вообще использованы finite-state transducers через crate fst. Если совсем упрощать, то можно считать, что префиксные деревья организуют словарь путем выделения общих префиксов у ключей, а трансдюсеры ещё могут и общие суффиксы выделять. Поэтому сжатие словаря происходит эффективнее, только в итоге получается уже не дерево, а ациклический орграф.
Библиотека fst в крайних случаях может сжимать даже лучше алгоритмов компрессии общего назначения при сохранении произвольного доступа. Крайние случаи случаются, когда большая часть ваших термов имеет длинные общие части. Например, когда вы складываете в инвертированный индекс URLы.
Ещё в fst есть методы сериализации и десериализации словаря, что сильно облегчает жизнь — складывать руками графы и деревья на диск то ещё развлечение. И в отличии от хеш-таблиц, fst позволяет использовать подстановку (wildcard) при поиске по ключам. Говорят, некоторые таинственные люди пользуются звездочкой в поисковых запросах, но я таких не видел.
Используя словарь термов и постинг-листы можно для запроса из одного одного терма определить список документов, в котором этот терм появляется. Затем останется посчитать для каждого документа из постинг-листа и взять top-K документов.
Для этого перенесем из области математики в реальный мир. В Tantivy используется BM25, как один из вариантов функции релевантности:

Кроме словаря термов, постинг-листов и длин документов Tantivy (и Lucene) сохраняет в файлах:
- Точные позиции слов в документах
- Скип-листы для ускорения итерирования по спискам (об этом дальше)
- Прямые индексы, позволяющие извлечь сам документ по его DID. Работают прямые индексы медленно, так как документы хранятся сжатыми тяжелыми кодеками типа brotli
- FastFields — встроенное в инвертированный индекс быстрое KV-хранилище. Его можно использовать для хранения внешних статистик документа а-ля PageRank и использовать их при расчете вашей модифицированной функции
Теперь, когда мы можем посчитать
для запроса из одного терма, найдем top-K документов. Первая идея — посчитать для всех документов их оценки, отсортировать по убыванию и взять К первых. Потребуется хранить всё в RAM и при большом количестве документов у нас кончится память. Поэтому при обходе постинг-листа от начала и до конца первые  документов кладутся в кучу (далее top-K heap) безусловно. А затем каждый последующий документ сначала оценивается и кладется в кучу только если его выше минимального из кучи. Текущий минимум в top-K heap далее будет обозначен как
документов кладутся в кучу (далее top-K heap) безусловно. А затем каждый последующий документ сначала оценивается и кладется в кучу только если его выше минимального из кучи. Текущий минимум в top-K heap далее будет обозначен как  .
.
Операции над постинг-листами для запросов из нескольких термов
Что сделает инвертированный индекс с запросом «скачать OR котики»? Он заведет два итератора по постинг-листам для термов «скачать» и «котики», начнет итерирование по обоим листам, попутно рассчитывая
и поддерживая top-K heap.Аналогичным образом реализуется AND-запрос, однако тут итерирование позволяет пропускать значительные части постинг-листов без расчета для них.
Более важными для поисковиков общего назначения являются OR-запросы. А всё потому, что они покрывают больше документов и потому, что ранжирование запросов метриками TF-IDF или BM25 всё равно поднимает в топ документы с бОльшим количеством совпавших слов. Это сделает top-K документов больше похожим на результат работы AND-запроса.
Наивный алгоритм реализации OR-запроса следующий:
- Создаем итераторы для постинг-листов каждого терма из запроса
- Заводим top-K heap
- Сортируем итераторы по DID, на которые они указывают
- Берем документ, на который указывает первый итератор и собираем среди оставшихся итераторов те, которые указывают на тот же документ. Так мы получим DID и термы, которые содержатся в этом документе
- Рассчитываем релевантность документа по термам, складываем их, получаем релевантность по всему запросу. Если документ хороший, то кладем его в top-K heap
- Продвигаем использованные итераторы и возвращаемся к п.3

Рис. 3: Итерации OR-алгоритма. Чуть ниже есть псевдокод алгоритма
В п.4 сбор итераторов осуществляется быстро, так как список итераторов отсортирован по DID. Пересортировку итераторов в п.3 тоже можно оптимизировать, если мы знаем какие итераторы были продвинуты в п.6.
Некоторые оптимизации инвертированного индекса
В обычной задаче поиска ищутся не вообще все релевантные документы, а только K наиболее релевантных. Это открывает путь для важных оптимизаций. Причина простая — большая часть документов станет ненужной и мы избежим накладных вычислений над ней. Такая постановка задачи ещё известна как Top-K queries.
Посмотрим внимательнее на псевдокод OR-алгоритма Bortnikov, 2017:
Input:
termsArray - Array of query terms
k - Number of results to retrieve
Init:
for t ∈ termsArray do t.init()
heap.init(k)
θ ← 0
Sort(termsArray)
Loop:
while (termsArray[0].doc() < ∞) do
d ← termsArray[0].doc()
i ← 1
while (i < numTerms ∩ termArray[i].doc() = d) do
i ← i + 1
score ← Score(d, termsArray[0..i − 1]))
if (score ≥ θ) then
θ ← heap.insert(d, score)
advanceTerms(termsArray[0..i − 1])
Sort(termsArray)
Output: return heap.toSortedArray()
function advanceTerms(termsArray[0..pTerm])
for (t ∈ termsArray[0..pTerm]) do
if (t.doc() ≤ termsArray[pTerm].doc()) then
t.next()
Наивный алгоритм работает с асимптотикой
 , где L — суммарная длина используемых при обработке запроса постинг-листов, а Q — количество слов в запросе. Немного обнаглев, из оценки можно выкинуть
, где L — суммарная длина используемых при обработке запроса постинг-листов, а Q — количество слов в запросе. Немного обнаглев, из оценки можно выкинуть  — подавляющее большинство пользователей приносит запросы не длиннее какого-то максимума и можно считать константой.
— подавляющее большинство пользователей приносит запросы не длиннее какого-то максимума и можно считать константой.На практике, наибольший вклад в скорость работы инвертированного индекса вносит размер корпуса (т.е длины постинг-листов) и частота запросов. Включенное автодополнение запроса или внутренние аналитические запросы в поисковую систему способны кратно умножить нагрузку на систему. Даже  в такой ситуации оказывается слишком грустной оценкой.
в такой ситуации оказывается слишком грустной оценкой.
Сжатие постинг-листов
Размер постинг-листов может достать гигабайтных размеров. Хранить постинг-листы как есть и бегать вдоль них без выдоха — плохая идея. Во-первых, можно не влезть в диск. Во-вторых, чем больше надо читать с диска, тем всё медленнее работает. Поэтому постинг-листы являются первыми кандидатами на сжатие.
Вспомним, что постинг-лист — это возрастающий список DID, сами DID — обычно 64-битные беззнаковые числа. Числа в постинг-листе не сильно отличаются друг от друга и лежат в достаточно ограниченной области значений от 0 до некоторого числа, сопоставимого с количеством документов в корпусе.
VarLen Encoding
Странно тратить 8 байт на то, чтобы закодировать маленькое число. Поэтому люди придумали коды, представляющие маленькие числа при помощи малого числа байт. Такие схемы называются кодировками с переменной длиной. Нас будет интересовать конкретная схема, известная под названием varint.
Чтение числа в varint происходит байт за байтом. Каждый прочитанный байт хранит сигнальный бит и 7 бит полезной нагрузки. Сигнальный бит говорит о том, нужно ли нам продолжать чтение или текущий байт является для этого числа последним. Полезная нагрузка конкатенируется вплоть до последнего байта числа.
Постинг-листы хорошо сжимаются varint’ом в несколько раз, но теперь у нас связаны руки — прыгнуть вперед в постинг-листе через N чисел нельзя, ведь непонятно где границы каждого элемента постинг-листа. Получается, что читать постинг-лист мы можем только последовательно, ни о какой параллельности речи не идет.
SIMD
Для возможности параллельного чтения изобрели компромиссные схемы, похожие на varint, но не совсем. В таких схемах числа разбиваются на группы по N чисел и каждое число в группе кодируются одинаковым количеством бит, а вся группа предваряется дескриптором, описывающим что в группе находится и как это распаковать. Одинаковая длина запакованных чисел в группе позволяет использовать SIMD-инструкции (SSE3 в Intel) для распаковки групп, что кратно ускоряет время работы.
Delta-encoding
Varint хорошо сжимает малые числа и хуже сжимает большие числа. Так как в постинг-листе находятся возрастающие числа, то с добавлением новых документов качество сжатия будет становиться хуже. Простое изменение — в постинг-листе будем хранить не сами DID, а разницу между соседними DID. Например, вместо [2, 4, 6, 9, 13] мы будем сохранять [2, 2, 2, 3, 4].
Список всё постоянно возрастающих чисел превратится в список небольших неотрицательных чисел. Сжать такой список можно эффективнее, однако теперь для раскодирования i-го числа нам нужно посчитать сумму всех чисел до i-го. Впрочем, это не такая уж и большая проблема, ведь varint и так подразумевает, что чтение списка будет последовательным.
Скип-листы для итерирования по постинг-листам
После сжатия постинг-листов, массив чисел превращается в связанный список. Всё, что мы теперь можем сделать — это последовательно обходить список от начала к концу. Хотя до сих пор нам большего и не требовалось, описанные в следующих секциях схемы оптимизации нуждаются в возможности продвигать итераторы на произвольное число DID вперед.
Есть такая замечательная штука — скип-листы. Скип-лист живет рядом со связанным списком чисел и представляет из себя разреженный индекс по содержанию этого списка. Если вы хотите в списке чисел найти Х, то скип-лист за время  пояснит вам, куда именно надо прыгнуть, чтобы оказаться в вашем связанном списке примерно в нужном месте перед Х. После прыжка вы уже обычным линейным поиском идете до Х.
пояснит вам, куда именно надо прыгнуть, чтобы оказаться в вашем связанном списке примерно в нужном месте перед Х. После прыжка вы уже обычным линейным поиском идете до Х.
Точность прыжка зависит от объема памяти, который мы можем выделить под скип-лист — типичный компромисс в алгоритмах. В Tantivy перемещение вдоль постинг-листа реализовано именно скип-листами. Известна lock-free реализация скип-листа, но на момент написания статьи (март 2021) библиотека выглядит не слишком поддерживаемой.
В нашей реализации скип-листа нужно ещё хранить частичные суммы до того места, куда мы собираемся прыгнуть, иначе ничего не получится, потому что для постинг-листа мы использовали Delta-encoding.
Оптимизации OR-запросов
Все оптимизации обхода постинг-листов делятся на безопасные и небезопасные. В результате применения безопасных оптимизаций top-K документов остается без изменений по сравнению с наивным OR-алгоритмом. Небезопасные оптимизации могут дать большой выигрыш по скорости, но они меняют top-K и могут пропустить некоторые документы.
MaxScore
MaxScore одна из первых известных попыток ускорить выполнение OR-запросов. Оптимизация относится к безопасным, описана в Turtle, 1995.
Суть оптимизации в разбиении термов запроса на два непересекающихся множества: «обязательных» и «необязательных». Документы, содержащие термы только из «необязательного» множества, не могут войти в top-K и поэтому их постинг-листы могут быть промотаны вперед до первого документа, который содержит хотя бы один «обязательный» терм.
Помните терма, введеный в разделе про TF-IDF и BM25? Напоминаю, что это максимально возможный вклад терма в релевантность любого запроса. является функцией от и рассчитывается на лету.
Имея на руках , можно отсортировать все термы из запроса по убыванию их и посчитать частичные суммы от первого и до последнего терма. Все термы с частичной суммой меньше текущего можно отнести к «необязательному» множеству. Документ, содержащий термы только из «необязательного» множества не может быть оценен выше, чем сумма этих документов. Стало быть, такой документ не войдет в итоговое множество.
Имеет смысл рассматривать только те документы, которые содержат хотя бы один терм из «обязательного» множества термов. Поэтому мы можем промотать постинг-листы «необязательных» термов до наименьшего из DID'ов, на которые указывают итераторы «обязательных» термов. Тут-то нам и нужны скип-листы, без них пришлось бы бежать по постинг-листам последовательно и никакого выигрыша в скорости не получилось бы.

Рис. 4: Промотка итераторов в MaxScore
После каждого обновления top-K heap производится перестроение двух множеств и алгоритм завершает работу в момент, когда все термы оказываются в «необязательном» множестве.
Weak AND (WAND)
WAND также является безопасным методом оптимизации поиска, описанным в Broder, 2003. В чем-то он похож на MaxScore: также анализирует частичные суммы и .
- Все итераторы термов WAND сортирует в порядке DID, на который указывает каждый итератор
- Рассчитываются частичные суммы
- Выбирается pivotTerm — первый терм, чья частичная сумма превосходит
- Проверяются все предшествующие pivotTerm'у итераторы.
Если они указывают на один и тот же документ, то этот документ теоретически может входить в top-K документов и поэтому для него производится полноценный рассчет
. Если хотя бы один из итераторов указывает на DID, меньший чем pivotTerm.DID, то такой итератор продвигается вперед до DID, большего чемpivotTerm.DID.
После этого, мы возвращаемся на первый шаг алгоритма
Block-max WAND (BMW)
BMW является расширением алгоритма WAND из предыдущего пункта, предложенным в Ding, 2011. Вместо использования глобальных для каждого терма, мы теперь разбиваем постинг-листы на блоки и сохраняем  отдельно для каждого блока. Алгоритм повторяет WAND, но проверяет в дополнение еще и частичную сумму блоков, на которые сейчас указывают итераторы. В случае, если эта сумма ниже , то блоки пропускаются.
отдельно для каждого блока. Алгоритм повторяет WAND, но проверяет в дополнение еще и частичную сумму блоков, на которые сейчас указывают итераторы. В случае, если эта сумма ниже , то блоки пропускаются.
Блочные оценки термов в большинстве случаев гораздо ниже глобальных . Поэтому многие блоки будут скипнуты и это позволит сэкономить время на расчете документов.
Для понимания разрыва между продакшеном инвертированных индексов и академическими исследованиями можно занырнуть в широко известный в узких кругах тикет LUCENE-4100.
TLDR: Реализация важной Block-max WAND-оптимизации молчаливо дожидалась смены TF-IDF на BM25, заняла 7 лет и была выкачена только в Lucene 7.
Block Upper Scoring
Рядом с для блока можно хранить другие метрики, помогающие принять решение не трогать этот блок. Либо сам поправить нужным образом так, чтобы его значение отражало вашу задумку.
Автор статьи экспериментировал с поиском, в котором необходимы были только свежие документы-новости. BM25 была заменена на  где
где  — функция, накладывающая пенальти на устаревающие документы и принимающая значения от 0 до 1. Поменяв формулу для , удалось добиться пропуска 95% всех блоков с несвежими новостями, что сильно ускорило конкретно этот вид поиска. Сам подход с&nb
— функция, накладывающая пенальти на устаревающие документы и принимающая значения от 0 до 1. Поменяв формулу для , удалось добиться пропуска 95% всех блоков с несвежими новостями, что сильно ускорило конкретно этот вид поиска. Сам подход с&nb
