Управление высокодоступными PostgreSQL кластерами с помощью Patroni. А.Клюкин, А.Кукушкин
Расшифровка доклада/tutorial "Управление высокодоступными PostgreSQL кластерами с помощью Patroni". А.Клюкин, А.Кукушкин
Patroni — это Python-приложение для создания высокодоступных PostgreSQL кластеров на основе потоковой репликации. Оно используется такими компаниями как Red Hat, IBM Compose, Zalando и многими другими. С его помощью можно преобразовать систему из ведущего и ведомых узлов (primary — replica) в высокодоступный кластер с поддержкой автоматического контролируемого (switchover) и аварийного (failover) переключения. Patroni позволяет легко добавлять новые реплики в существующий кластер, поддерживает динамическое изменение конфигурации PostgreSQL одновременно на всех узлах кластера и множество других возможностей, таких как синхронная репликация, настраиваемые действия при переключении узлов, REST API, возможность запуска пользовательских команд для создания реплики вместо pg_basebackup, взаимодействие с Kubernetes и т.д.
Слушатели мастер-класса подробно узнают, как работает Patroni, получат практические навыки настройки высокодоступных кластеров на его основе, познакомятся с различными дополнительными возможностями и поучаствуют в диагностике проблем. Будут рассмотрены следующие темы:
- область применения: какие задачи HA успешно решаются Patroni
- обзор архитектуры
- создание тестового кластера
- утилита patronictl
- изменение конфигурации PostgreSQL для кластера, управляемого Patroni
- мониторинг с помощью API
- подходы к переключению клиентов
- дополнительные возможности: ручное переключение, перезагрузка по расписанию, режим паузы
- настройка синхронной репликации
- расширяемость и универсальность
- частые ошибки и их диагностика

В конце есть опрос: "На сколько постов разделить tutorial? Прошу проголосовать."
(Алексей Клюкин) Здравствуйте! Большое спасибо, что вы пришли на этот tutorial о Patroni. Меня зовут Алексей. Мой коллега – Александр. Мы работаем в Zalando разработчиками по базам данных. И мы является также разработчиками Patroni. И мы очень рады использовать эту возможность для того, чтобы поделиться с вами нашими знаниями. И, может быть, поспособствовать тому, чтобы больше людей спало спокойно, используя автоматический failover и используя при этом Patroni. И мы хотим также рассказать о каких-то дополнительных возможностях, которые, возможно, мы еще не освещали в наших докладах.
# Для полного участия в мастер-классе вам понадобится ноутбук с установленным git, vagrant и virtual box.
# Vagrant можно загрузить со страницы https://www.vagrantup.com или установить с помощью пакетов в вашем дистрибутиве. Virtualbox: https://www.vagrantup.com
# После установки Vagrant и Virtualbox нужно выполнить:
$ git clone https://github.com/alexeyklyukin/patroni-training
$ cd patroni-training
$ vagrant up
$ vagrant ssh
$ sudo -iu postgres
$ cd patroni
$ ls
postgres0.yml postgres1.yml postgres2.yml На экране слайд с инструкциями для vagrant’а. Если у вас есть ноутбук и вы хотите следовать за нами, и выполнять команды, которые мы говорить (мы будем останавливать и говорить, что эти команды можно выполнить на своем ноутбуке и получить требуемый результат), то вы можете скачать vagrant или вы можете по адресу на GitHub, который здесь указан, скачать vagrantfile. После чего сделать vagrant up и vagrant ssh. И вы получите виртуальную машину, в которую уже установлен etcd, в которую установлен Postgres и в которую установлен Patroni. И эту виртуальную машину мы использовали для того, чтобы сделать слайды.
Если у вас нет ноутбука или вы не хотите за нами следовать, это не проблема. У нас также есть слайды, на которых будет написан результат всех тех действий, которые нужно предпринять и, соответственно, сами действия тоже. Поэтому вы можете просто смотреть на слайды. Мы слайды эти сделаем доступными после презентации, поэтому вы можете всегда использовать их, как справочный материал, когда вы будете работать с Patroni.
Patroni не требует от вас, чтобы у вас было слишком много postgres-кластеров. Вы можете использовать его для одного кластера и снова спать спокойно, и делать failover. А в Zalando у нас сотни кластеров. Мы доверяем Patroni каждый день, чтобы он переключал роль мастера на нужный нам postgres-кластер. Но вы можете использовать его на значительном меньшем количестве кластеров.

(Алексей Клюкин) Давайте начнем. Начнем мы с того, что я расскажу, чем мы будем заниматься. В начале мы расскажем про автоматический failover. Мы расскажем, как неправильно его делать, потому что очень много возможностей сделать его неправильно. Мы покажем, как не надо делать.
Мы расскажем про архитектуру Patroni, потому что очень важно понимать, как работает то решение, которому вы решили доверить свою базу данных.
После этого мы покажем, как создать кластер с помощью Patroni. Мы углубимся в детали, как менять конфигурацию рабочего кластера без перезагрузок. Если требуются перезагрузки, то Patroni поможет понять, когда их делать.
Мы расскажем про мониторинг, про те возможности, которые встроены в Patroni для того, чтобы мониторить ваши кластера.
Мы расскажем про возможности расширить функциональность Patroni с помощью пользовательских скриптов, которые выполняются при определенных действиях. В таких, как failover, как callback скрипты.
Мы также не обойдем вниманием вопрос, как перенаправлять клиентов на мастер-узел.
Мы расскажем про дополнительные возможности Patroni. В таких, как перезагрузка или failover по расписанию. Мы затронем теги, которые используются для модификации в репликации в Patroni. Расскажем подробнее про синхронную репликацию.
И в конце концов мы остановимся на различных способах создания реплик, которые есть в Patroni. А также на том, как Patroni решает такие задачи, как, например, склонировать существующий кластер или сделать point in time recovery существующего кластера на другом кластере.
И в самом конце мы рассмотрим типичные ошибки, с которыми мы встречались, когда поддерживали Patroni на GitHub. Мы рассмотрим, какие возникают ошибки и какие есть способы для решения этих ошибок.
Я теперь передаю слово Александру. Он вам расскажет про архитектуру в Patroni и вообще про автоматический failover.

(Александр Кукушкин) Здравствуйте! Для начала мы не будем рассматривать архитектуру в Patroni, а сделаем широкий взгляд сверху на High Availability, на высокодоступные решения, чтобы делать Postgres высокодоступным.
Давным-давно уже существует решение какого-то разделяемого хранилища. Это может быть какое-то сетевое хранилище, когда вы выделяете раздел и монтируете его на сервер. И при падении мастера, это хранилище перемонтируется на другой сервер, и там запускается Postgres. Как правило, такие решения достаточно дорогие, поэтому люди предпочтительно используют DRDB и LVM.
Для того, чтобы в таком случае переключать мастер, как правило, используют Corosync, PaceMaker. Это тоже очень сложная система. И люди очень часто делают ошибки в настройках. Основная проблема PaceMaker в том, что большую часть времени он работает. И ты постепенно забываешь, как с ним управляться, как он настраивается. И в какой-то момент что-то идет не так. И в этот момент, вы понимаете, что все знания утеряны, забыты и непонятно, что делать.
Логическая репликация или репликация, основанная на триггерах – это примерно одно и то же. Конечно, логическая репликация появилась в Postgres в 10-ой версии. Но никакой большой разницы между trigger-based репликацией или логической репликацией, по сути, нет.
У них есть свои плюсы и минусы. Но главный минус в том, что, как правило, при использовании такой логической репликации, вы реплицируете только данные. У вас не реплицируются какие-то служебные объекты, такие, как роли, юзеры. Реплицируются только какие-то отдельные базы, таблицы, т. е. не реплицируется кластер(сервер) целиком.
К счастью, в 2009-ом году появился Postgres 9.0, в котором появилась потоковая физическая репликация. Она позволяет кластер реплицировать один в один. И, как правило, все решения по High Availability строятся на физической репликации.
Многие думают, что с появлением multi-master’а у них эта проблема отпадет, потому что у вас будет много нод. Каждая нода сможет принимать данные на запись. В данный момент это можно реализовать с помощью BDR или bucardo. Но это обычно не то, что люди хотят. Поскольку и BDR, и bucardo также реплицируют исключительно данные. Они не реплицируют никаких служебных объектов в базе. И вам при таких решениях необходимо каким-то образом настраивать разрешение конфликтов. Потому что две ноды могут затрагивать один и тот же объект. И не всегда понятно, каким образом и в каком порядке эти изменения должны быть применены. Конечно, там можно настраивать эту стратегию. Но никакой стратегии по умолчанию невозможно придумать, которая бы удовлетворила всех. Поэтому большинство решений по High Availability строятся на потоковой репликации.
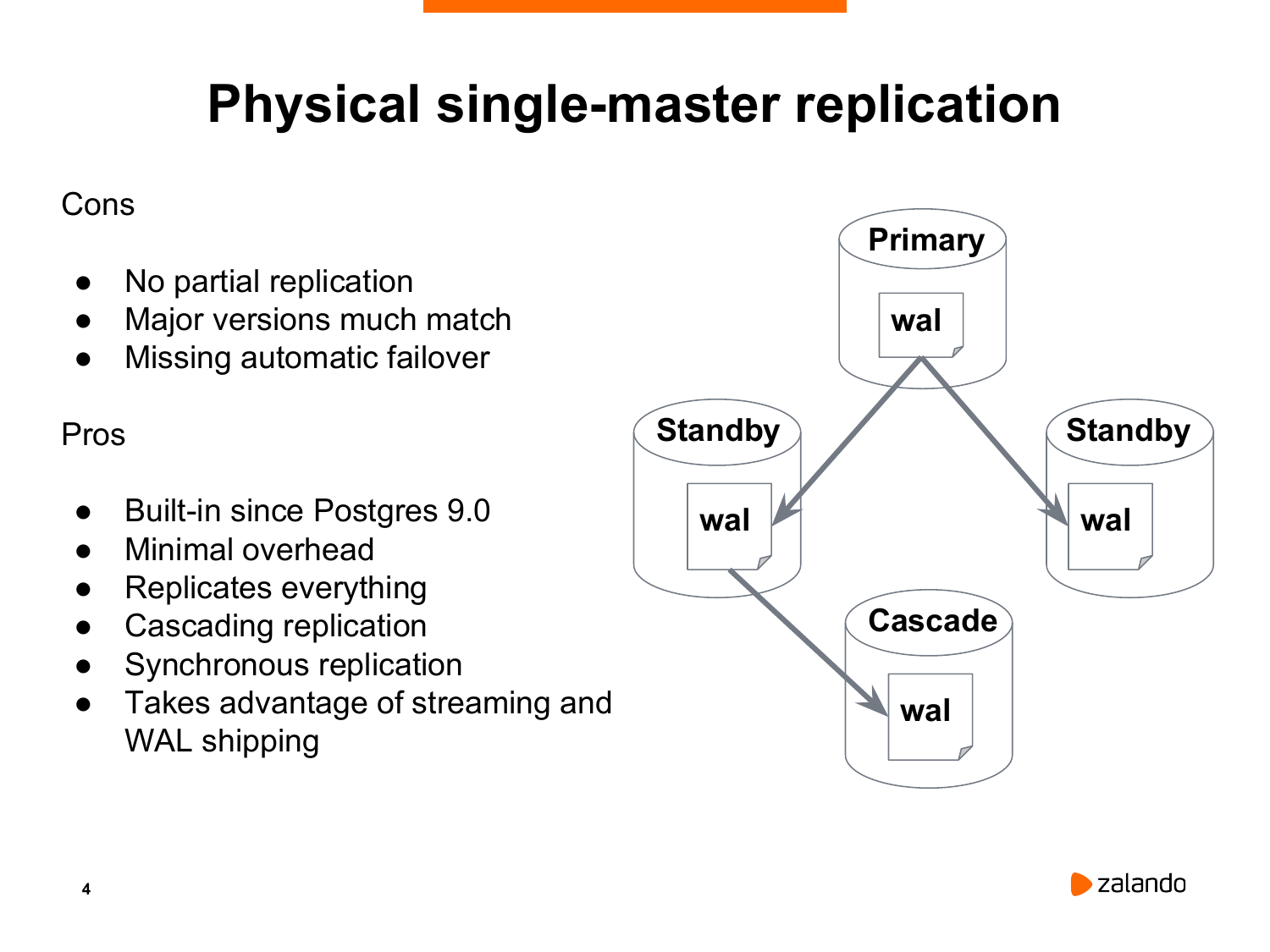
Какая в этом есть проблема? Сама по себе потоковая репликация не является полным решением высокой доступности. Потому что нет никакого встроенного решения, которое бы позволило перевести standby в режим нового мастера, если что-то произошло со старым мастером.
У этого решения есть очень глобальный недостаток в том, что потоковая репликация работает только на той же самой major versions.
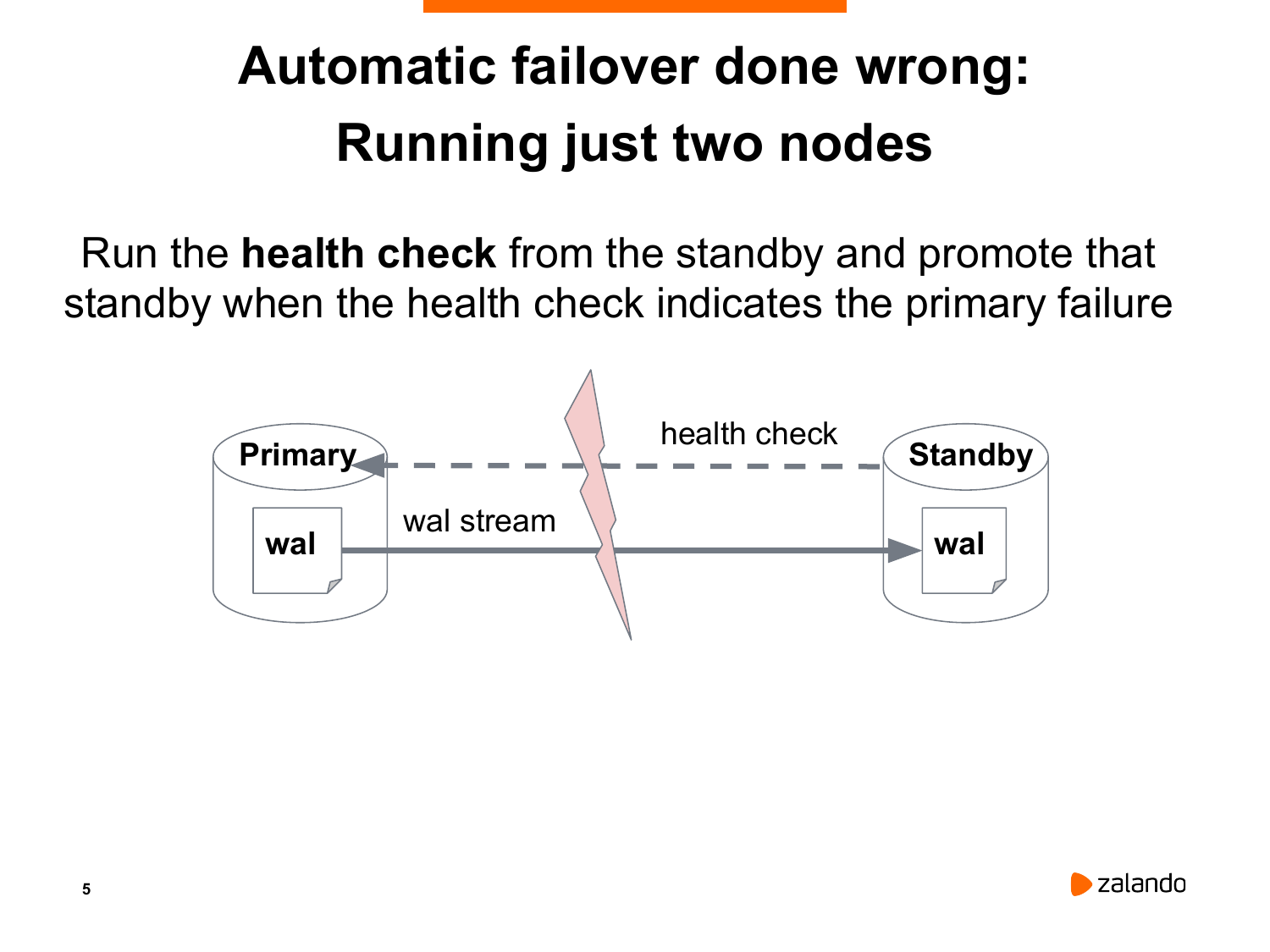
Что люди пытаются сделать: Мы построим базу, которая является мастером primary. Мы сделаем standby базу, которая будет через потоковую репликацию получать данные. Напишем какой-нибудь скрипт, который будет периодически запрашивать состояние мастера. И при условии, если мастер недоступен, мы будем превращать standby в новый мастер.
Мы живем в реальном мире. И поэтому сеть тоже неидеальная. Могут быть какие-то короткие всплески недоступности. Т. е. по факту с мастером ничего не случилось, он до сих пор работает. Он обслуживает соединения клиентские, все хорошо, но standby каким-то образом оказался, например, изолированным. И что происходит?

У нас получаются два мастера. Так называемая split-brain ситуация.
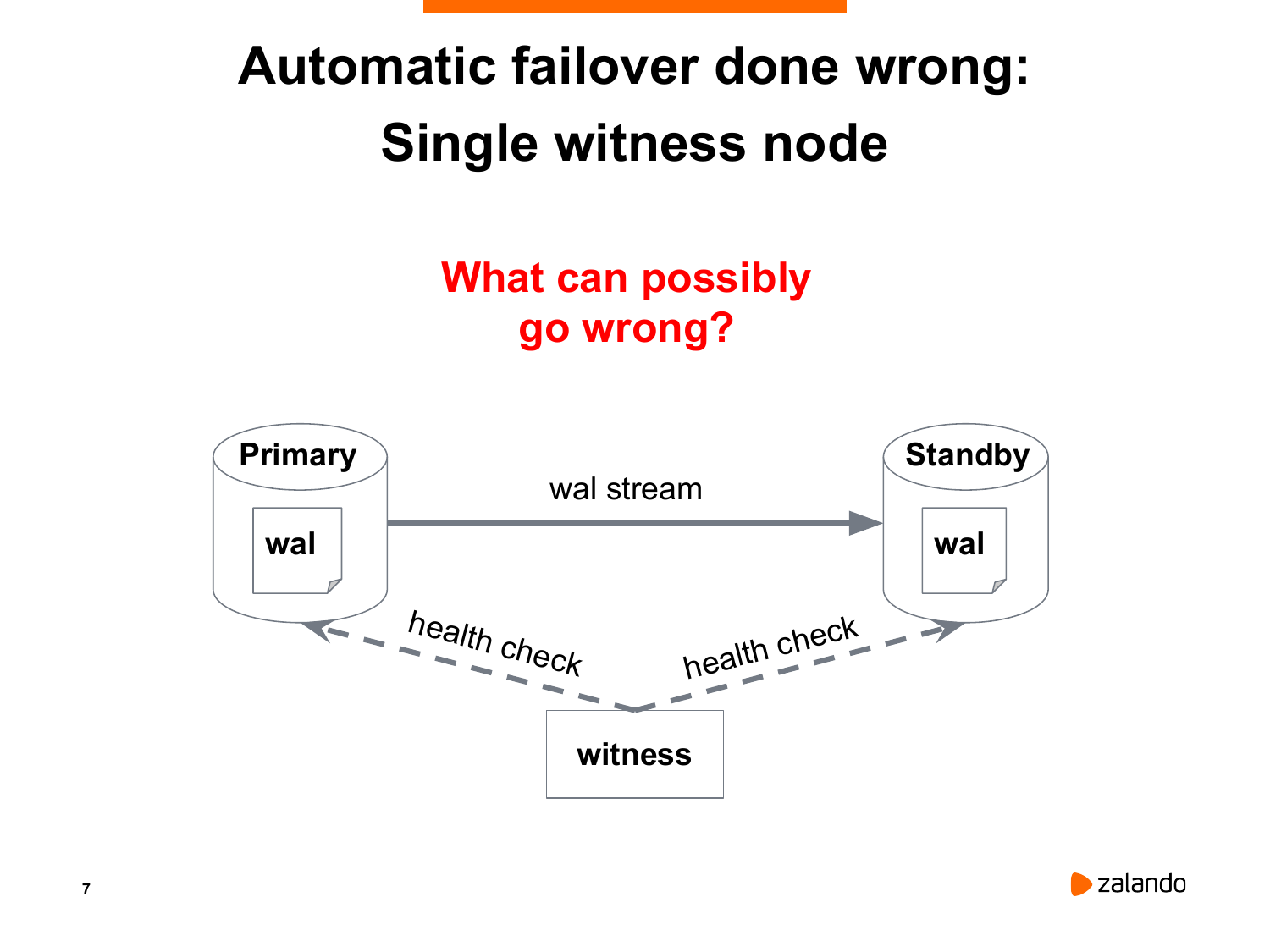
Поэтому есть другой подход к решению данной проблемы. Мы будем принимать решения о переводе standby в новый мастер с помощью какого-то третьего сервера.
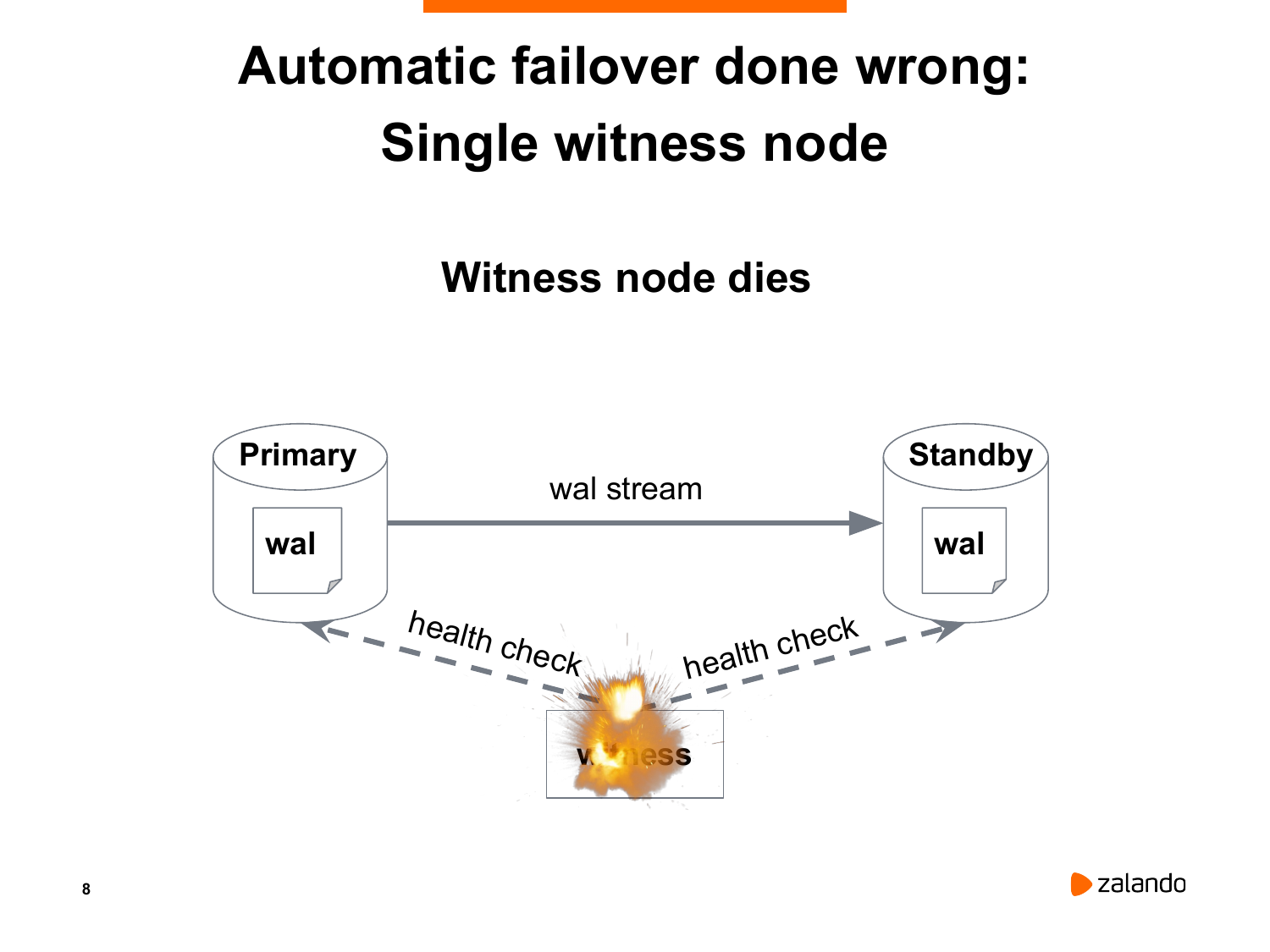
И, как вы думаете, что здесь может пойти не так? Во-первых, этот сервис тоже может сам по себе исчезнуть. Мы живем в реальном мире. И железки имеют обыкновение иногда сгорать, умирать, глючить. В этом случае мы теряем автоматический failover. С одной стороны, ничего критичного, мы можем поднять. Но с другой стороны, что может произойти в тот момент, когда нода, которая принимает решение, недоступна? У нас тоже может мастер отказать. И никто его не переключит. Никто не даст команду реплике переключиться.
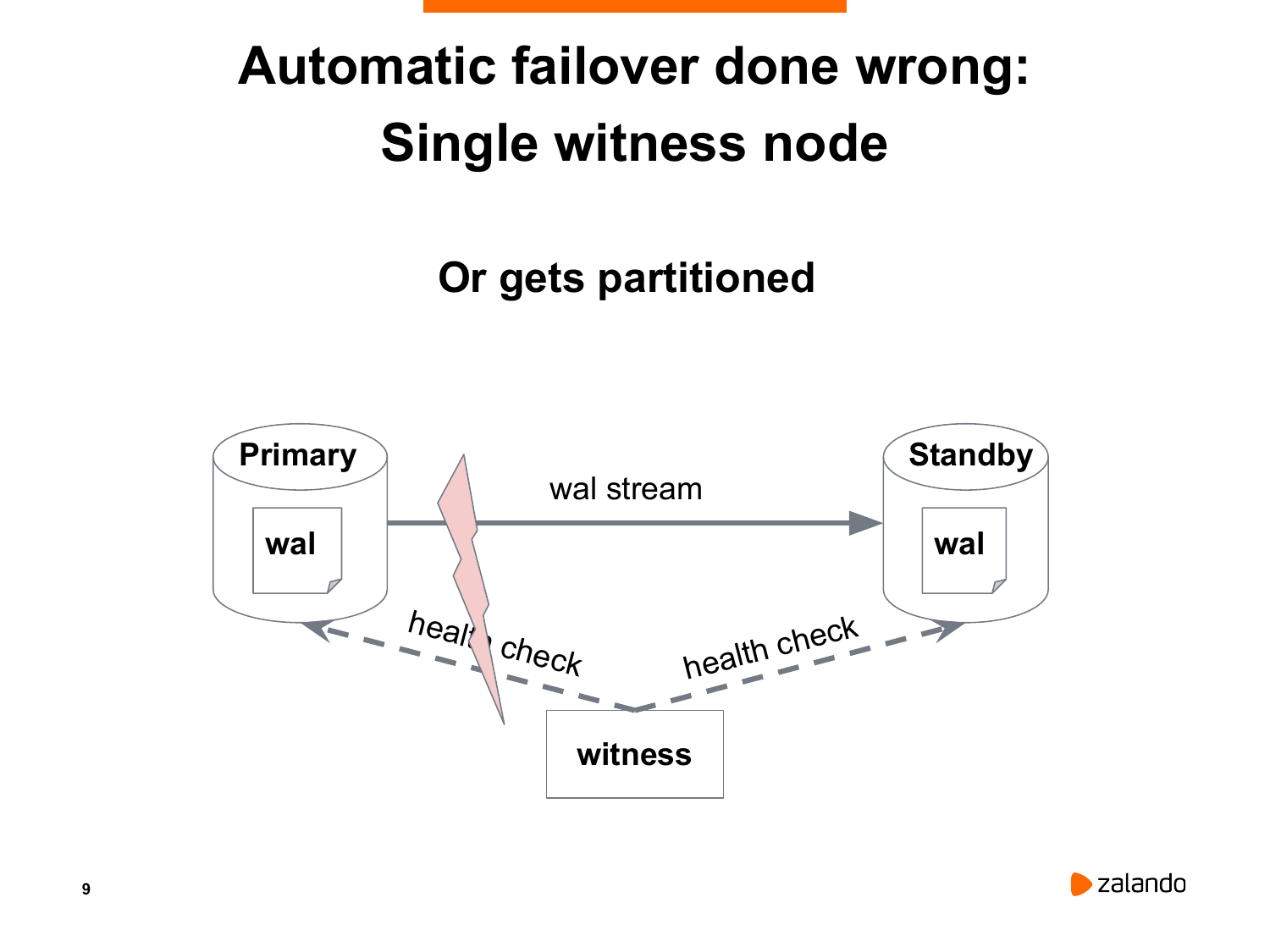
Есть еще одна ситуация. Может так оказаться, что мастер и standby оказались в разных сегментах сети. И нода, которая принимает решение, она может оказаться в том сегменте, где у нас находится standby. Нода понимает, что мастер недоступен, хотя мастер живой и обслуживает соединения. И нода принимает решение перевести standby в новый мастер. И мы снова получаем тот же самый split-brained.
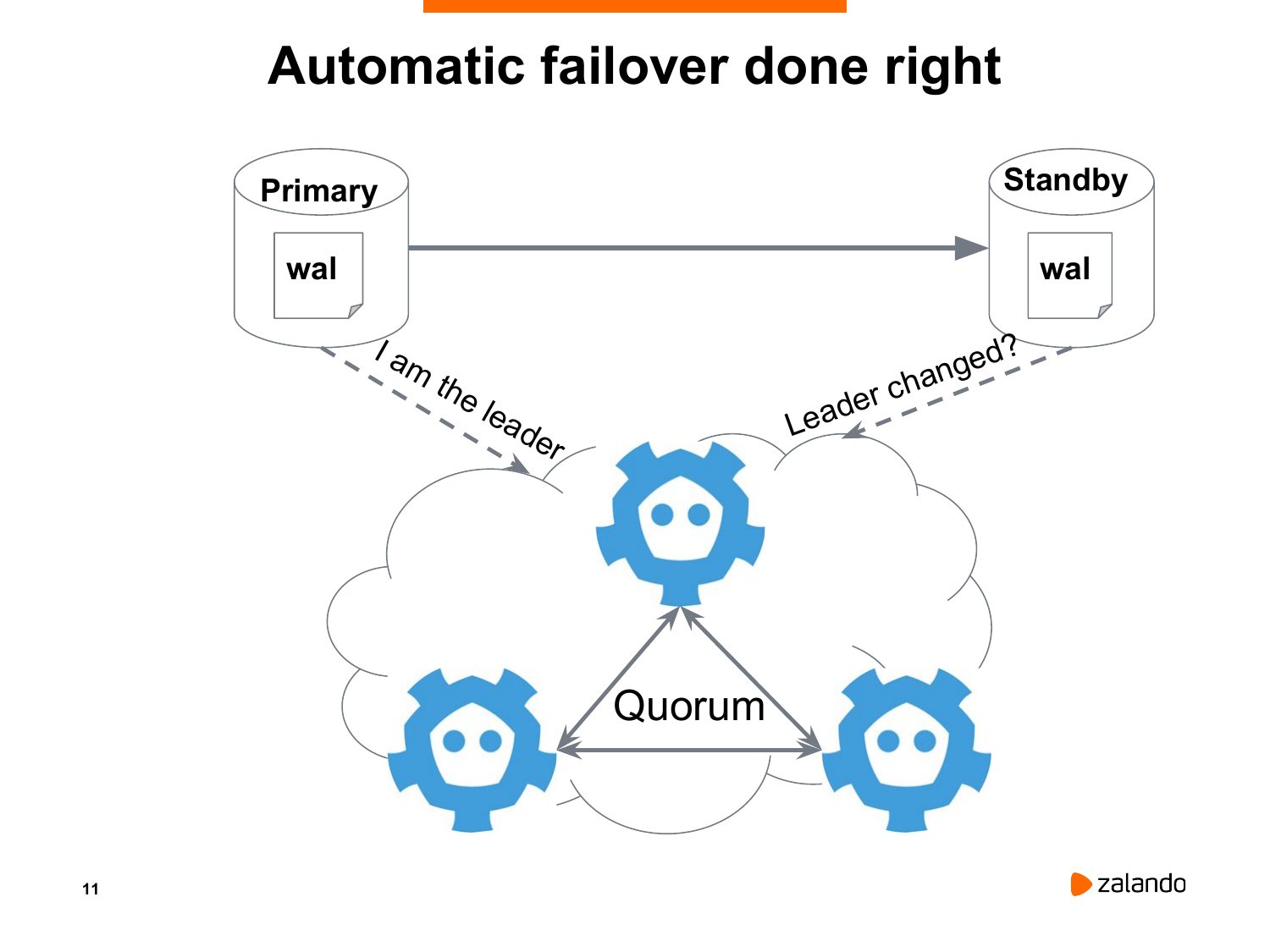
И потихоньку мы подходим к современному и правильному способу определения является ли мастер и реплика живыми. Это можно сделать только при условии, что у нас есть нечетное количество нод, которые проводят голосование.
В данном случае у нас есть три ноды. Если две ноды соглашаются о том, что у нас primary недоступен, то у этих двух нод есть большинство голосов. Два из трех – это большинство. Почему не рекомендуется использовать четное количество? В принципе, в этом нет ничего страшного, но для того, чтобы получить большинство голосов из четырех нод, должны три согласиться с результатами выборов.
(Уточнение: этого слайда я не нашел)
Конечно, очень важно убить старые соединения к мастеру. Для этого, как правило, выполняется STONITH. По-русски – это будет «пристрелить другую ноду в голову».
Quorum позволяет нам решать сложные задачи разрешения партицирования сети. Когда какой-то сегмент сети недоступен, то несколько других сегментов могут принимать решения. А изолированный сегмент в этом случае должен остановить старого мастера.
И очень хорошо иметь Watchdog. Это либо аппаратный, либо программный комплекс, который позволяет перезагрузить ноду при условии, что наш сервис не отвечает. Например, если что-то произошло в Patroni, то Watchdog не будет получать периодических сигналов и просто перезагрузит ноду. Это тоже способ закрытия сервера, потому что мы не должны оставлять Postgres работать самого по себе.
 И потихоньку мы приходим к подходу бота, который был придуман ребятами из компании «Compose». Compose был куплен IBM. Это достаточно большая компания. Идея в том, что мы рядом с каждым Postgres на каждой ноде запустим специального daemon`a, который будет управлять нашим instance Postgres. В случае если все хорошо и у нас есть доступ к какому-то распределенному хранилищу, где мы можем периодически обновлять lock, то данная нода может работать как мастер. Либо если у нас lock'а нет, то нода будет работать как реплика.
И потихоньку мы приходим к подходу бота, который был придуман ребятами из компании «Compose». Compose был куплен IBM. Это достаточно большая компания. Идея в том, что мы рядом с каждым Postgres на каждой ноде запустим специального daemon`a, который будет управлять нашим instance Postgres. В случае если все хорошо и у нас есть доступ к какому-то распределенному хранилищу, где мы можем периодически обновлять lock, то данная нода может работать как мастер. Либо если у нас lock'а нет, то нода будет работать как реплика.
И Bot занимается многими вещами. Но основная его задача следить за тем, что у нас Postgres работает либо в режиме мастера, когда он обязан быть один и только один, либо в режиме реплики.
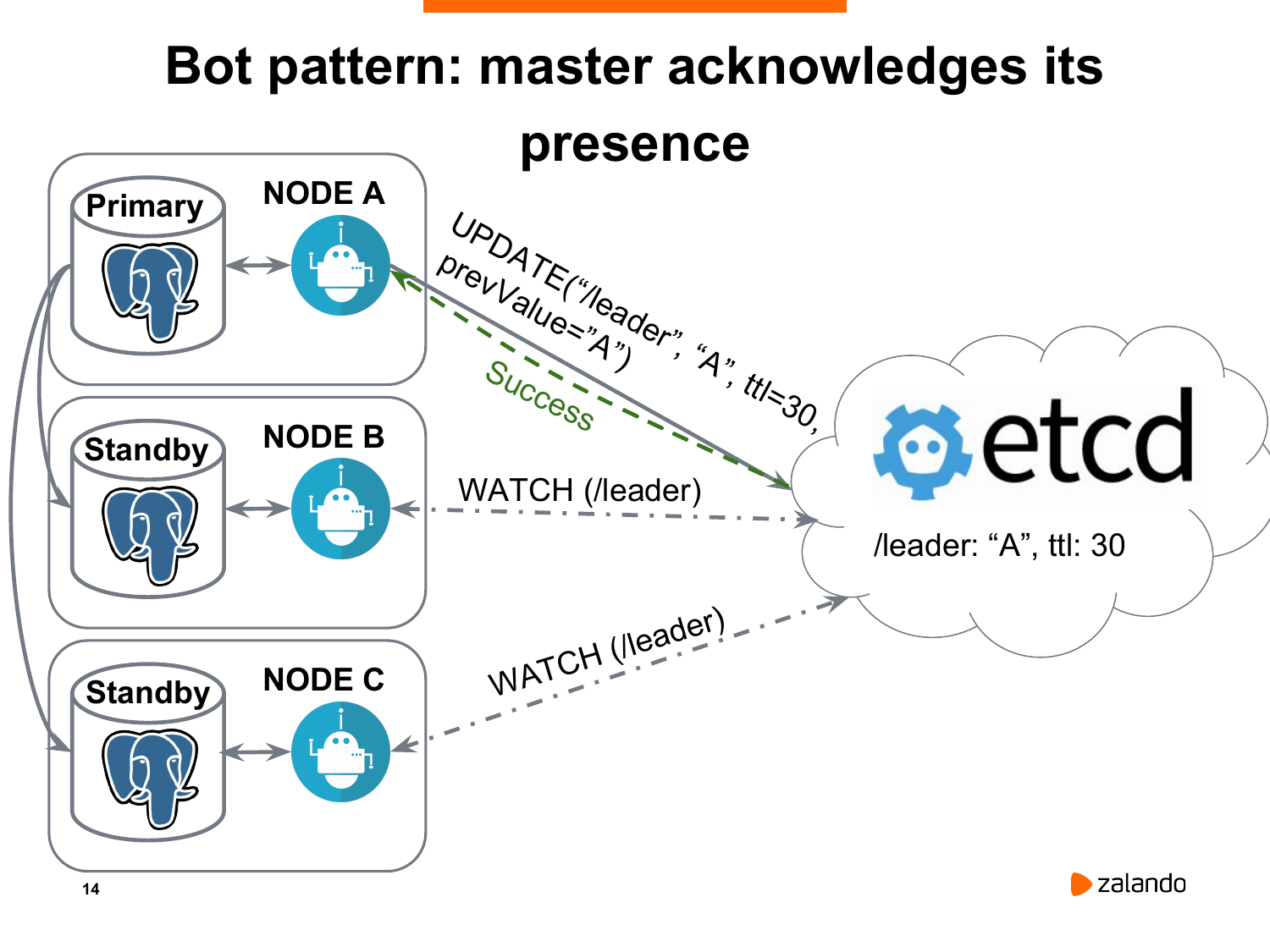
И вот, как все у нас происходит. На картинке у нас есть нода А, которая является текущим мастером. И она периодически отправляет в etcd запрос на обновление ключа лидера. Она это делает по умолчанию с периодичностью раз в 30 секунд. И важно, что у ключа лидера есть ttl. Это время в секундах, по истечению которого ключ пропадет.
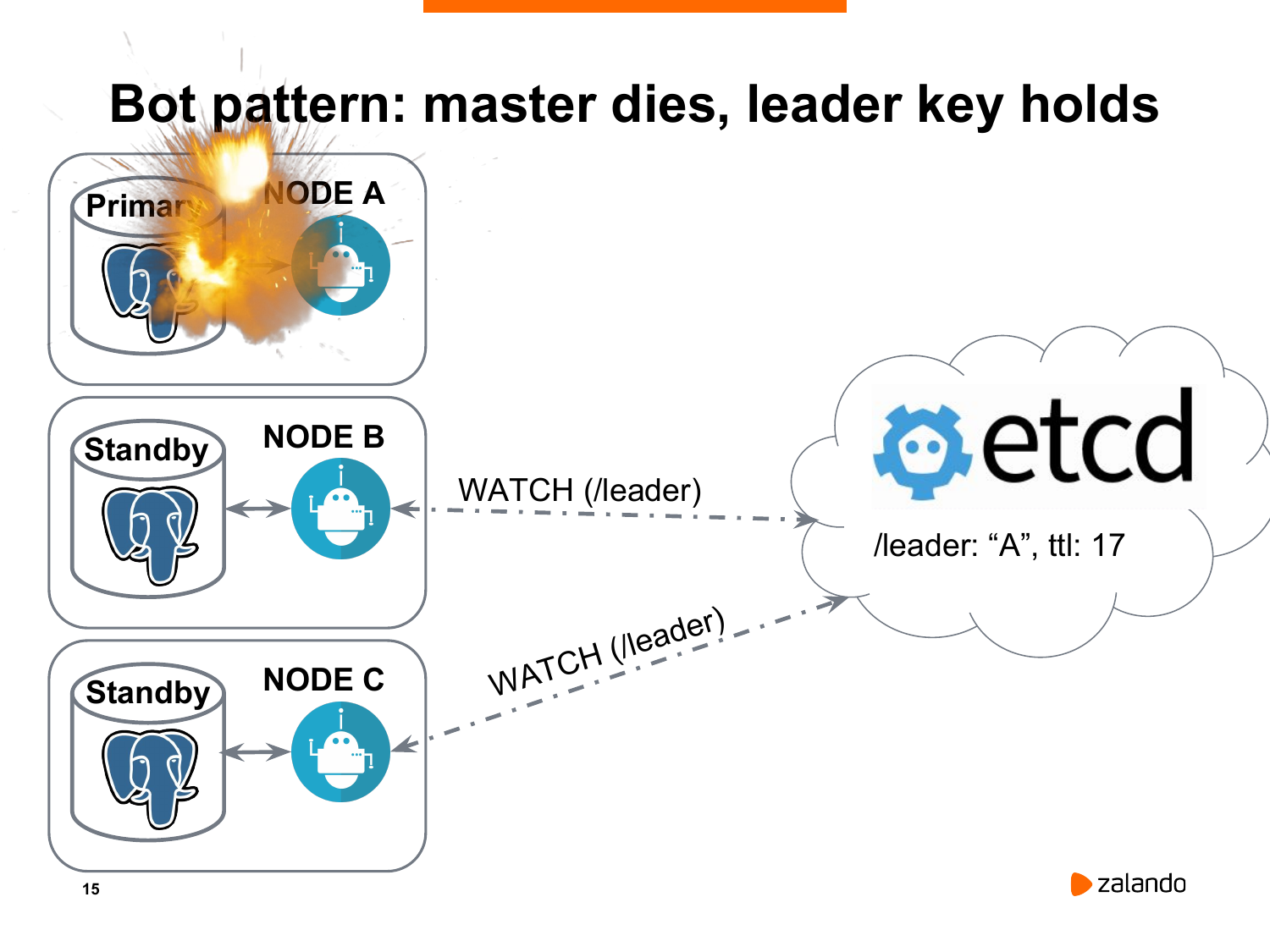
Если у нас что-то случилось с нашей нодой, она не будет обновлять ключ лидера. И потихоньку мы придем к ситуации, когда ключ лидера исчезнет.
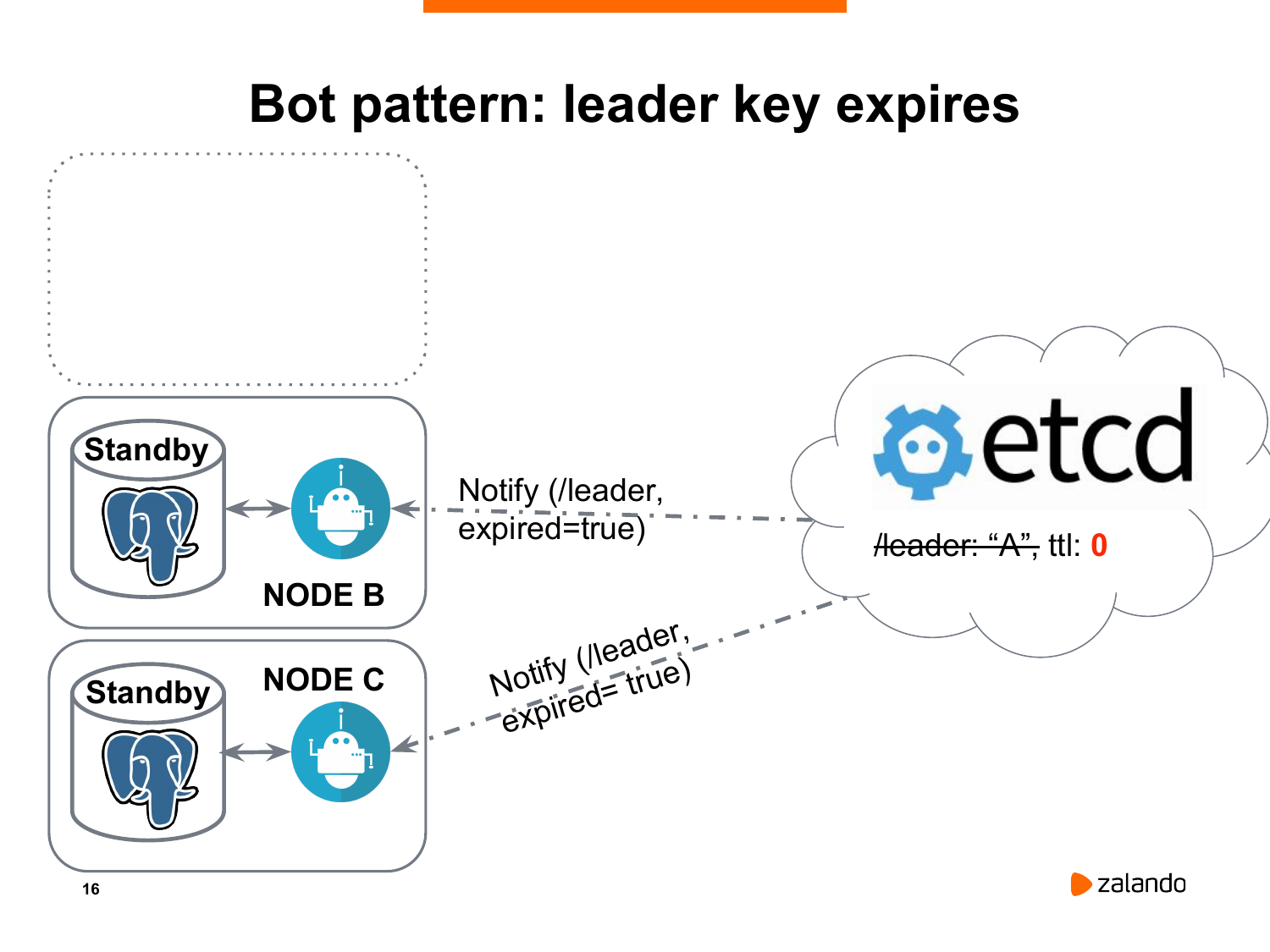
И оставшиеся ноды получат оповещение о том, что лидера нет, согласно etcd. И мы должны провести новые выборы.
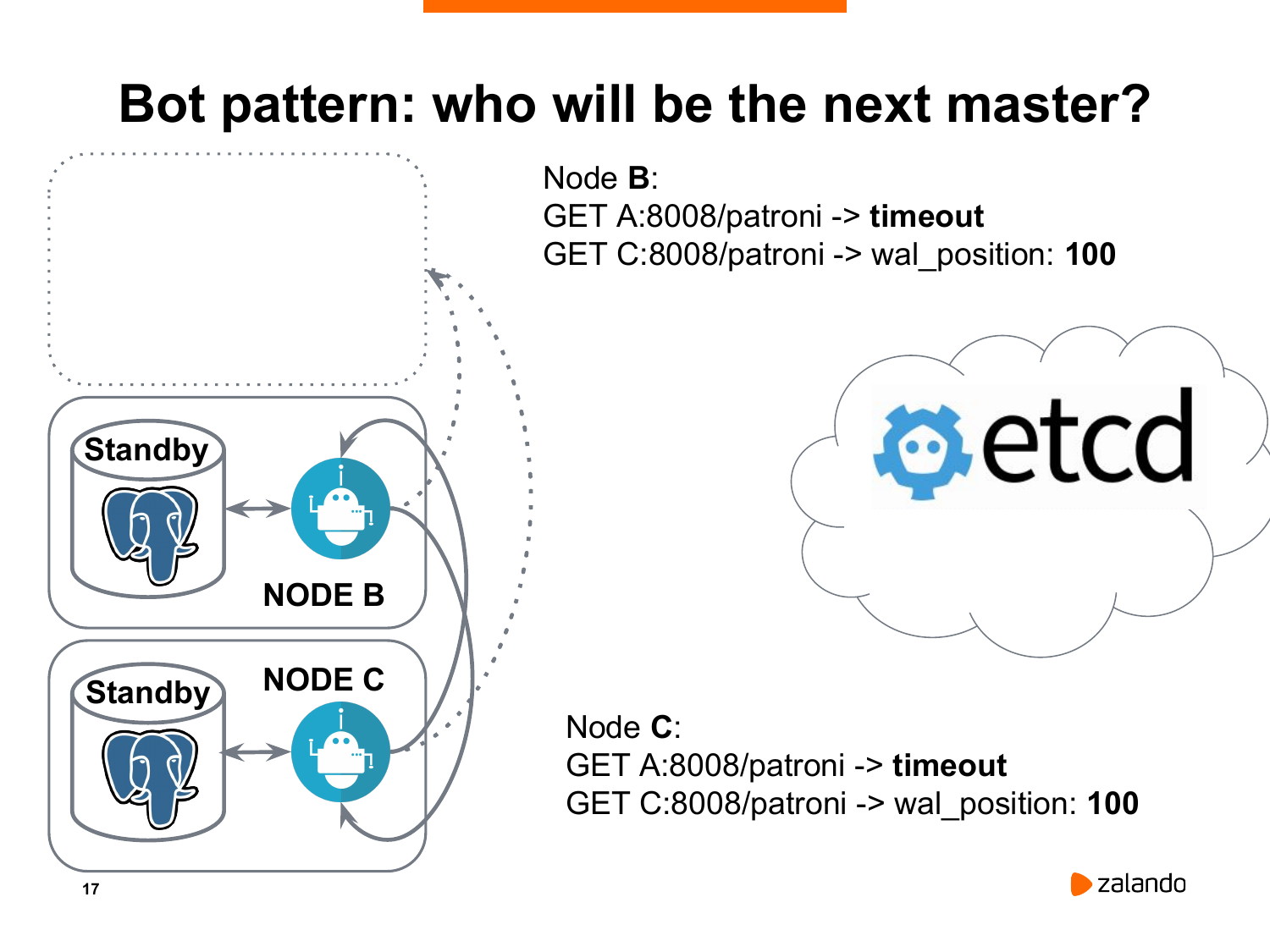
Как они это делают? Каждая нода обращается ко всем другим нодам, включая старый исчезнувший мастер. Потому что вдруг это были какие-то временные проблемы, и вдруг он до сих пор жив. Нам в этом надо убедиться. И каждая нода сравнивает позицию WAL со своей. При условии, если нода является впереди всех остальных или хотя бы не отстает, как в данном случае, когда у обоих реплик оказался wal_position равный 100, то они начинают гонку за лидером. Т. е. они отправляют запрос на создание нового ключа лидера в etcd.
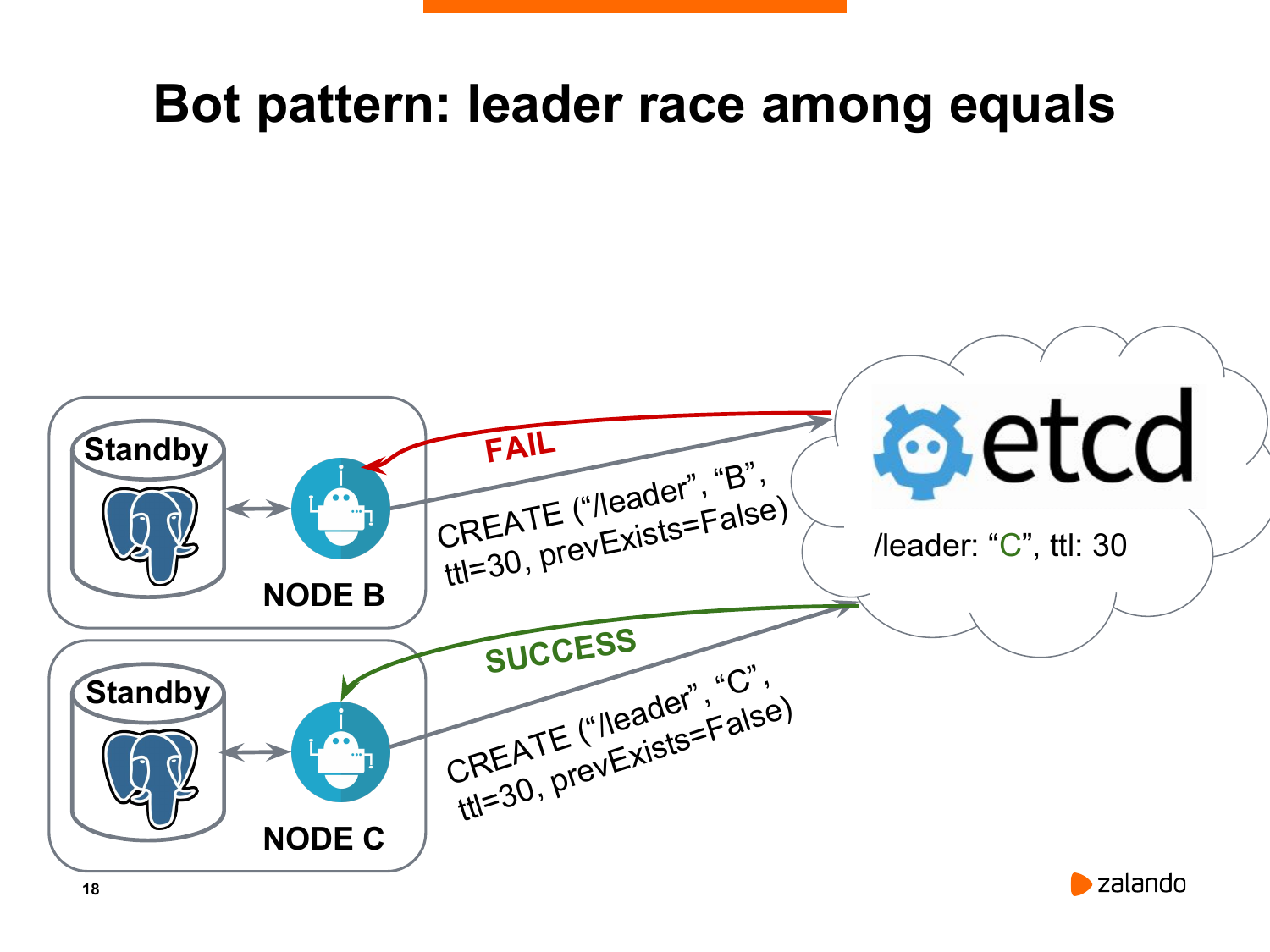
В чем прелесть etcd? В том, что он позволяет такие вещи делать атомарно. Т. е. когда одна нода создала ключ, то вторая нода, при условии, что мы запрещаем перезаписывать уже существующий ключ, его создать не сможет.
И на этом слайде мы видим, что нода C выиграла, она успела создать ключ лидера, а нода B не смогла.
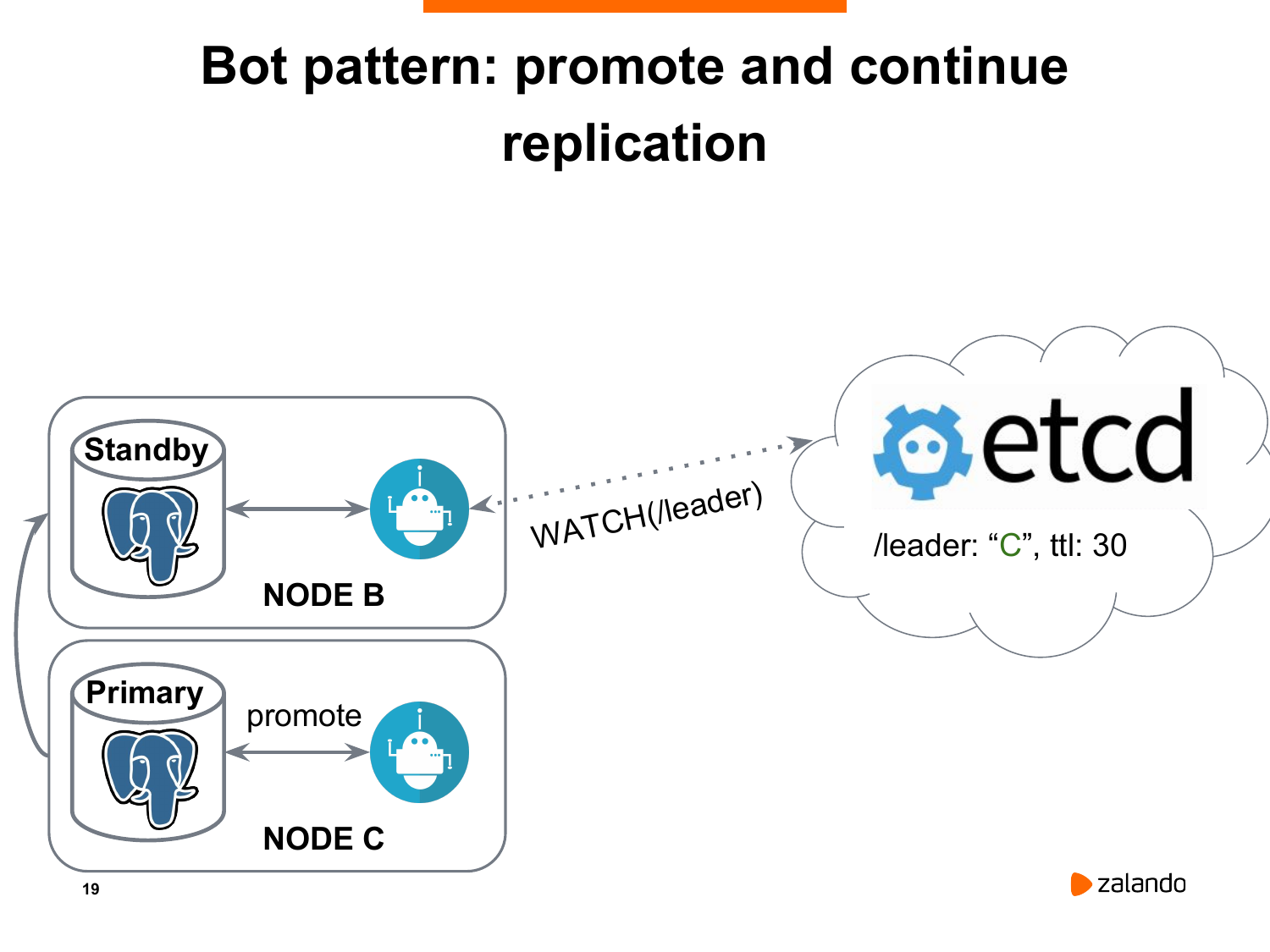
И в результате мы получаем, что нода C становится новым мастером, она выполняет promote для Postgres. А нода B становится новой репликой, которая будет уже реплицировать не с ноды A, которая недоступна, а с ноды C.
И немного про etcd. Это, конечно, не является главной темой нашего мастер-класса, но Patroni очень сильно зависит от таких distributed consistency store, от таких, как Etcd, Consul, Zookeeper. В том числе мы можем использовать Kybernetes API.
Etcd построен на алгоритме RAFT. И для его функционирования мы должны иметь больше двух нод, лучше три или пять.
И по этой замечательной ссылке вы можете поиграть с тем, как etcd внутри себя выполняет leader election, каким образом он определяет, какая из нод является ведущей, какие ноды являются репликой и позволяет разрешать в том числе любые проблемы сети, когда у нас одна сеть становится недоступна по отношению к другим.

Patroni имплементирует такой шаблон бота. Patroni написан на Python. И в основном разработкой занимаемся мы в Zalando, но в том числе у нас очень много других разработчиков. В основном это мелкие патчи, исправление проблем. Иногда документация. И помощь нам оказывает один из сотрудников Cybertec. Это очень известная компания, которая занимается консалтингом Postages. И они в том числе используют Patroni для своих клиентов.

(Алексей Клюкин) Мы сейчас перейдем к тому, что создадим наш первый Patroni кластер. Возможно, для некоторых людей он будет не первым, но в любом случае мы покажем, что достаточно просто создать High Availability кластер.

Для этого требуется выполнить всего несколько команд. И это тот слайд, который был изначально. И если вы хотите следовать за нами, то на вашем компьютере должен быть поставлен vagrant. У вас должна быть виртуальная машина. И вы можете сделать vagrant ssh туда, и выполнить команды sudo -iu postgres и там будет конфигурация Patroni.
И мы попробуем вместе получить наш первый High Availability Patroni кластер.
Запуск Patroni – это очень просто. В нашей машине vagrant’а уже запущен etcd. Поскольку это локальная виртуальная машина, то там запущен всего один instance etcd. На production кластерах, естественно, вы запускаете, три и больше instance etcd, потому что вся идея etcd в том, чтобы хранить информацию о состоянии кластера и ключ лидер. И это та система, которая должна быть постоянно доступной. Поэтому, пожалуйста, не запускайте один etcd на production. Если он упадет, никакого High Availability не будет, Patroni перейдет в режим только чтение.
И когда мы стали пользоваться Postgres, мы перешли в каталог Patroni. У нас там есть три yml-файла. Откуда мы взяли эти yml-файлы? Мы их взяли из GitHub, поскольку Patroni – это open source проект, то на GitHub выложены его исходные коды и в том числе тут есть эти yml-файлы. Мы их не придумывали из головы, мы просто взяли, как они есть здесь. Т. е. если вы сделаете git clone https://github.com/zalando/patroni.git, то вы можете это повторить на локальной машине, если у вас есть Python и все зависимости. Просто на виртуальной машине эти все зависимости уже установлены.

C 26:33 начинается demо.
Вот моя машина. Есть два Postgres. Я перехожу в каталог Patroni. Я уже здесь. И запускаю patroni postgres0.yml. Нам нужно перейти в каталог Patroni. Отлично, я запустил первый узел Patroni.
Первый узел Patroni увидел, что кластера у нас еще нет. И инициализировал мастер-узел, он запустил initdb. Initdb отработал. Вот есть вывод initdb. И он нам показал, что мы инициализировали новый кластер. У узла, на котором мы это запустили, есть lock, т. е. у него есть индикация, что он лидер. И он об этом говорит: «lock owner: postgresql0; I om postgresql0», т. е. говорит, что все хорошо, он работает как мастер.
Теперь давайте сделаем тоже самое со вторым узлом. Мы запустим patroni postgres1.yml. Что произошло со вторым узлом? Второй узел нашел etcd-сервер. Нашел, что кластер уже создан. У него уже есть лидер. И в etcd уже есть информация про то, что кластер создали. Поэтому вместо того, чтобы запускать initdb и стать мастером, он запустил pg_basebackup. Это утилита Postgres, которая позволяет вам создавать реплики. И создал себя в качестве реплики.
Вот он себя создал. И после этого попытался стартовать Postgres. Он ждет пока Postgres стартует. Это может занять некоторое время. После чего он сказал, что он не может получить WAL-файлы. Он сказал, что не может получить файлы с мастера.
Почему это происходит? Мы сделали реплику, все хорошо, Patroni ее настроил. Дело в том, что Patroni создает слот репликации для каждой реплики. В Postgres для потоковой репликации есть возможность сохранять те изменения, которые должны быть переданы на реплику. В нормальном случае, если вы не создадите слот и ваша реплика будет погашена по каким-то причинам, то через определенное время мастер возьмет все wal-файлы, которые у него накопились и отротирует их. Если реплика после этого подключится к кластеру, то она запросит wal-файлы, которых на мастере уже нет. И репликация будет невозможна. Вам для этого придется переинициализировать реплику.
Слоты репликации были созданы в Postgres как раз для того, чтобы решить эту проблему. Т. е. когда у вас есть слот репликации, то этот слот накапливает в себе изменения и не дает Postgres эти wal-файлы отротировать. И как только вы подключаете реплику, она подключается к этому слоту и все файлы передаются.
У этого способа также есть недостаток, потому что если ваша реплика потушена, а слот создан, то никто эти wal-файлы не проигрывает. Они накапливаются на мастере. И они будут накапливаться, пока у мастера не закончится место. Поэтому в Patroni есть возможность выключить слоты репликации. Но мы настоятельно рекомендуем ими пользоваться, потому что это избавляет вас от проблем, когда вам нужно будет на короткое время потушить реплику и после этого включить ее обратно.
Что здесь происходит? Он сказал, что не может включить репликацию, потому что Patroni еще не создал слот. На мастере Patroni смотрит на список реплик, которые подключились. И для каждой реплики создает слот через некоторое время.
Мы сейчас немного подождали. И вы видите, что эти ошибки прекратились. Эти ошибки выдаются не Patroni, эти ошибки выдаются Postgres. Он попытался подключиться к слоту под названием «postgres1», а postgres1 – это имя нашей реплики. И у него не получалось до определенного момента, пока Patroni все-таки не создал слот. И после этого репликация пошла нормально. Вот это сообщение показывается на реплике. Она говорит, что мастер lock завладел postgresql0, а я potstresql1, т. е. я – не мастер, я – реплика, у меня нет lock, я не предпринимаю никаких действий. А действием в данном случае может быть promote, потому что она следует за мастером, у которого есть lock. И дальше Patroni будет показывать это периодически. В данном случае достаточно часто и на мастере, и на реплике, т. е. он будет подтверждать, что здесь он показывает, что он мастер, а здесь Patroni показывает, что он реплика.
У кого получилось довести это до конца? У двоих. У остальных какие проблемы? Нет python-etcd. Я покажу эту команду. Для этого я создам новую консоль. Вам нужно зайти в patroni-training, зайти в ваш vagrant. И сказать pip install python-etcd. Вот эта команда установит etcd для Patroni. После чего те команды, которые я сделал для запуска Patroni, они увенчаются успехом. Patroni найдет etcd и сделает кластер.

Что мы сделаем дальше? Мы возьмем утилиту, которая называется Patronictl. Patronictl предназначена для контроля Patroni. В данном случае мы посмотрим на состояние нашего кластера.
Как мы это сделаем? Мы откроем еще одну консоль. Захожу в Patroni и говорю «patronictl», указываю конфигурацию одного из узлов. Из этой конфигурации он достанет имя кластера. Можно альтернативно указать ему имя кластера. И указываю команду, которую я хочу выполнить, т. е. «list».
И что я получаю? Я получаю вот такую табличку. В этой табличке указано название кластера, указано название узла «postgresql0» или «postgresql1», указан хост, на котором находятся. И очень важно, что указаны роли. Мы видим, что у нас кластер живой. Все хорошо, у нас один лидер. И указано также состояние Postgres, т. е. Postgres запущен на обоих узлах. Последняя колонка (Lag) – это если у нас есть реплика, то она может отставать от мастера по разным причинам. Потому что реплика медленная, потому что сеть, потому что на мастер большая нагрузка. Если у нас есть отставания, то Patroni эти отставания измеряет и показывает вам через утилиту Patronictl в отдельной колонке. Сейчас мы видим, что у нас никакого отставания нет, потому что на кластер никакой нагрузки нет.
То, что я вам показал, это ни разу не автоматический failover. Это просто как инициализировать кластер с точки зрения Patroni.

Что я вам хочу показать? Я хочу показать, как Patroni реализует автоматический failover. Есть терминалогия. Есть switchover, есть failover. Switchover – это переключение узлов, когда вы сами решаете переключить мастер на какой-нибудь другой узел. В то время, как failover (или на русском – аварийное переключение) – это когда от вас ничего не зависит, у вас сервер сгорел или с ним что-то случилось нехорошее. И вы хотите, чтобы Patroni переключился.
И мы покажем вам именно failover. Что мы для этого сделаем? Мы возьмем и оставим Patroni на мастере. Мы остановим Patroni специальным образом. Мы не сделаем «kill Patroni», потому что если я сделаю «kill Patroni», то он также остановит Postgres. Вместо я сделаю ctrl+Z, т. е. я переведу Patroni в background режим, и он остановится.
Давайте попробуем это сделать. Вот мой лидер. Я нажимаю «ctrl+Z» и я его остановил. Вот моя реплика.
Что происходит с репликой? Пока с ней ничего не происходит. Почему с ней ничего не происходит? Потому что пока еще у Patroni есть режим лидера. Пока еще в etcd находится ключ лидера. Должно пройти некоторое время. В данном случае при дефолтной конфигурации – это до 30 секунд. Это контролируется специальным параметром «ttl». Это все настраивается. Я об этом расскажу чуть позже. Там есть некое соотношение между разными параметрами Patroni. Вы можете поставить и 8 секунд, и 10 секунд, и меньше. Вам нужно соблюдать баланс между тем, как ваша сеть падает, поднимается и тем, насколько надежно вы хотите сделать failover. Но я бы не рекомендовал делать этот параметр сильно меньше, чем 30 секунд.
Что мы видим? Вот это последние сообщения. Что случилось дальше? Дальше случился вот такой warning в логах. Patroni сказал «request failed», т. е. не получилось сделать GET request. Что это такое? Patroni увидел, что lock’a в etcd больше нет. И попытался постучаться на мастер. Когда lock теряется, Patroni стучится на все известные узлы в кластере. И спрашивает у этого узла: «Ты – мастер?». А если он не мастер, то Patroni спрашивает позицию wal’а, т. е. насколько этот узел ближе к мастеру.

И вот то, что мы видим. У нас было два узла. И он попытался спросить у мастера: «Доступен ли ты?». И мастер ему ничего не ответил, потому что мы потушили Patroni на мастере. И после того, как это случилось, он принял решение сделать себе promotion, т. е. стать после этого лидером. Вот видите: promoted self to leader by acquiring session lock.
Вопрос: как долго Patroni опрашивает ноды?
Ответ: Он порядка две секунды тратит для каждой ноды, чтобы получить оттуда ответ. Все ноды он опрашивает параллельно.
Да, некоторое время он ждет, пока не ответит мастер. После этого делает себе promotion.
Вопрос: Можно ли держать etcd на тех же нодах что и Patroni?
Ответ: Как правило, лучше иметь отдельный кластер. У Etcd основное требование – ни большое количество памяти, ни большое количество процессоров, ему нужны только быстрые диски, чтобы он писал данные. В данной конфигурации – это демо. У нас здесь всего одна etcd нода, т. е. только для того, чтобы Patroni работал. В принципе, это вы сами можете решать. Вы можете иметь две ноды, на которых будет работать Postgres, плюс на каждой из них будет работать etcd. И иметь какой-нибудь третий сервер, на котором будет исключительно одна нода etcd.
Сейчас по факту в этой машине у нас работает и etcd, и два Patroni, и два Postgres, потому что это проще для демо.
Если один etcd упадет, то в некотором смысле – это является точкой отказа, если вы его не восстановите. Если у вас etcd будет работать независимо от Postgres, то два etcd сервера по-прежнему выполняют свою функцию. И если один из etcd серверов отказал, надо быстро его поднять.
Вопрос: Что произойдет с etcd, если network partition, т. е. если один из узлов оказывается изолированным?
Ответ: Произойдет network partition. У etcd тоже есть лидер, он сам выбирает лидера. Если в этой части сети, которая оказалась изолированной был лидер, то два оставшиеся сервера выбирают нового лидера. И, соответственно, новый лидер будет находиться в одной из двух оставшихся сетей. А старый лидер начнет перевыборы, потому что он поймет, что две другие ноды недоступны. Но при этом никакая запись через старого лидера не будет возможна.
И вот этот узел, который мы только что оставили, он сделает себе promotion. И дальше он работает как лидер. Он говорит, что он лидер, что у него есть lock, что он postgres1 и все хорошо.
Теперь мы сделаем одну очень интересную вещь. Вы помните, что на postgres0 узле, мы остановили Patroni? Мы остановили Patroni, но Postgres там еще работает. И Postgres там сейчас работает в режиме мастера.
Это мы сделали специально, потому что в реальной жизни, как правило, могут быть какие-то данные не реплицированы. Мы этот Postgres оставили только для того, чтобы сделать небольшой split-brain, т. е. только в целях демо.
Да. У нас есть бывшая реплика, которая сделала promotion и стала мастером. И у нас есть бывший мастер, который так и остался работать мастером, потому что мы потушили на нем Patroni.
Сейчас мы возьмем бывший мастер и запишем какие-то данные. Таким образом, сделав искусственный split-brain. А потом мы посмотрим, как Patroni будет бороться с этим split-brain.

Что мне для этого нужно? Мне нужно создать таблицу. Я создаю таблицу, которая называется «split-brain». И есть интересная возможность в Postgres. Можно создавать таблицу с нулем колонок. И этого достаточно.
Теперь я создал таблицу. И теперь самое интересное. Я возьму тот Patroni, который у меня сейчас остановлен. И скажу ему – продолжать свою работу. Мы поставили Patroni, чтобы он запускался, как основной процесс. И вот, что получилось.
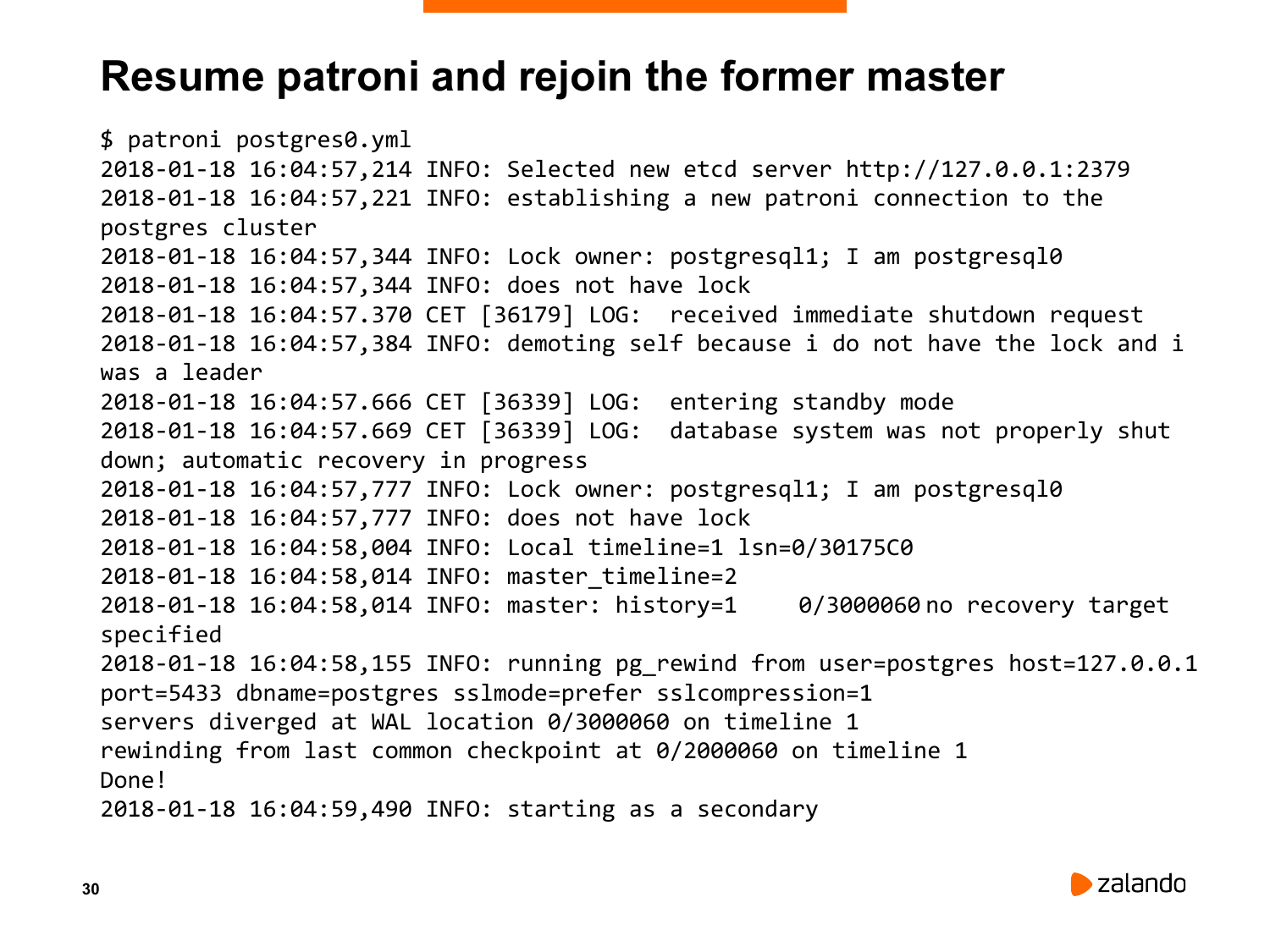
Внезапно он увидел, что он – мастер и то, что уже существует мастер. И что он сделал? Он сделал demoting Postgres настолько быстро, насколько возможно. Т. е. он сказал Postgres – сделай immediate shutdown прямо сейчас без всяких прелюдий. И Postgres сделал immediate shutdown. Это вот такой полупанический shutdown, т. е. он просто убивает все процессы, которые у вас есть. И мы это как раз сейчас видим. Он остановил базу данных и потом он сказал, что сделаю demoting, т. е. действие обратное promotion, потому что у меня нет lock’а. И после этого он стартовал Postgres.
Он делал crash recovery, потому что immediate shutdown – это не является чистой остановкой базы. И он препятствует pg_rewind. Pg_rewind откажется работать с кластером, у которого не было чистой остановки. Поэтому мы запускаем crash recovery mode в single user. Ничего не делаем, он просто запускает в single user и останавливает. После этого запускает pg_rewind, потому что Patroni знает, что там старый мастер был немного впереди нового мастера, когда произошел promotion.
Т. е. мы запустились в crash recovery. Когда он запустился, он проверил свою позицию в wal-сегменте. И он проверил wal-сегмент мастера. И он нашел, что произошел split-brain, потому что он – реплика, но он ушел вперед от мастера, потому что мы сделали create table split-brain. И он принял решение запустить pg_rewind.
Что такое pg_rewind? Это утилита в Postgres, которая позволяет предыдущему мастеру подключиться как реплика и перемотать обратно все те изменения, которые не попали на текущий мастер. Он перематывает до того момента, когда произошел разрыв между мастером и репликой, когда существующий мастер сделал promotion.
И мы это здесь увидим. Вот он написал «running pg_rewind from postgresql1». Pg_rewind написал, что был split-brain, что мастер и реплика разделились вот в такой позиции. Сказал, что мы сделали rewind, написал – done. И теперь мы можем увидеть, что старый мастер подключился как реплика. Он говорит, что мастер – postgresql1, а он – postgresql0. Т. е. в данном случае мы увидели, что, несмотря на то, что произошел split-brain (split-brain произошел, потому что мы остановили Patroni, если бы мы не останавливали Patroni, то никакого split-brain не было бы), мы все равно смогли разрешить эту ситуацию автоматически. Т. е. Patroni смог найти второго мастера, быстро его остановить. После этого он смог запустить его как реплику, сделать ему pg_rewind и включить его в кластер.
 Теперь мы можем посмотреть снова на результат работы утилиты Patronictl. И здесь мы теперь увидим картину, которая похожа на предыдущую, только лидер у нас переключился на postgreslq1. Раньше он был postgresql0, сейчас он postgresql1. И, соответственно, postgresql0 у нас тоже есть, он работает нормально, он является репликой. И он совершенно не отстает. Таким образом мы симулировали failover и показали, что Patroni может успешно разрешать такие ситуации.
Теперь мы можем посмотреть снова на результат работы утилиты Patronictl. И здесь мы теперь увидим картину, которая похожа на предыдущую, только лидер у нас переключился на postgreslq1. Раньше он был postgresql0, сейчас он postgresql1. И, соответственно, postgresql0 у нас тоже есть, он работает нормально, он является репликой. И он совершенно не отстает. Таким образом мы симулировали failover и показали, что Patroni может успешно разрешать такие ситуации.
Вопрос: Что случилось с таблицей, в которую я вставил?
Ответ: Этой таблицы уже нет. Т. е. если я сейчас пойду на мастер, то я не найду этой таблицы, потому что данные со старого мастера отмотались назад. И мы не сможем получить эти данные. Произошел split-brain, эти данные потерялись. И задача Patroni – не допускать split-brains, чтобы не терять данные.
Мир у нас реальный. И иногда репликации происходят с задержками. Т. е. какое-то количество транзакций при аварийных ситуациях могут быть потеряны. Чтобы избежать потерь, необходимо использовать синхронную репликацию. Синхронная репликация поддерживается в Patroni. Мы к этому подойдем немножко попозже. Но по большей части люди используют асинхронную репликацию, потому что синхронная репликация очень сильно бьет по производительности.
Что я хочу вам показать теперь? Это содержимое etcd. То содержимое, в котором хранится информация про наш кластер. Сделаем мы это с помощью утилиты etcdctl. И я могу показать, что мы храним внутри etcd. Это может быть также Consul, ZooKeeper или Kubernetes. Структура одинакова.
Etcd – это система ключ-значение. У нас есть какие-то ключи. И у этих ключей есть какое-то значение. Вы можете увидеть, что у нас есть ключ лидера, у нас есть ключ для каждого из участников кластера, т. е. для postgresql0 и для porsgresql1. У нас есть ключ initialize, который говорит о том, что кластер инициализирован и внутри хранится идентификатор кластера, который позволяет подключиться только тем узлам, которые являются частью этого кластера. Т. е. если вы подключите узел, который является частью какого-то другого кластера, он не сможет подключиться. Потому что в этом ключе initialize хранится как раз индификатор и ключ, связанный с конфигурацией кластера.

Давайте я покажу это на слайде, потому что там немножко лучше выделено. Вот тот же самый результат. После этого я смотрю на то, что хранится в узле members/postgresql1. Это json, в котором хранятся несколько важных параметров.
В частности, здесь хранится url, по которому можно подключиться к базе данных Postgres. Здесь хранится api_url, т. е. url, по которому Patroni, когда он делает promotion, может спросить у другого узла Patroni – мастер он или нет. Здесь хранится состояние базы данных. У нас может быть Patroni запущен на узле, но база данных еще не запущена. У нас хранится роль. И у нас хранится текущая позиция xlog’а или wal’а для данного узла, т. е. в какой позиции он восстанавливает или создает wal-сегменты. И также у нас здесь хранится timeline.
У нас есть несколько других ключей. Есть history. Если вы знаете, что такое timeline history, то вы знаете, что это история promotion данного кластера, история того, как кластер становился из реплики мастером. Здесь хранится эта история. И также хранится время, когда случился promotion. Т. е. по этому ключу вы можете узнать, когда произошел последний failover.

У нас есть кластер, он работает. Я хочу показать, как можно динамически менять конфигурацию вашего Postgres.

Почему это важно и почему это нужно? Потому что у вас есть кластер. Там есть несколько узлов. Вы можете, конечно, пойти на каждый из этих узлов и поменять там postgresql.conf или сделать autosystem для того, чтобы изменить параметры конфигурац
