Улучшаем возможности Nginx без затрат на коммерческую подписку (спойлер: с помощью Haproxy)
Очень часто Nginx используют для распределения трафика между несколькими экземплярами серверов приложений. Эти серверы иногда сбоят, а если их много, то сбоят постоянно. Ведь одни выключены для обслуживания, вторые перегружены запросами, третьи просто на минуточку перезапускаются для обновления и вот-вот вернутся. Ну, и сеть, конечно, не безупречна, наверняка дело в ней, всегда дело в ней. Одна из задач Nginx — скрыть за собой весь этот хаос и без ошибок показывать пользователю его любимых котиков и заодно страничку интернет-магазина.
Но ведь прокси-сервер не знает, что происходит вокруг. Как же быть? Частично помогают повторные запросы. Но они не всегда безопасны, довольно грубо конфигурируются и очень легко приводят к перегрузке всей системы. Если бэкенд сбоит в течение какого-то времени, его нужно как-то автоматически отключать, а не тратить время на безуспешные попытки.
В бесплатной версии Nginx наблюдает за ошибками при работе с бэкенд-серверами и при их появлении отстреливает сервер на несколько секунд от нагрузки. Такая схема неплохо работает, если на другой стороне сервис просто не слушает порт, и прокси-сервер быстро получает отказ в подключении. Но вот если удалённый сервер выключен, или ужасная сеть теряет ваши пакеты — всё становится не так радужно.
Коммерческая версия Nginx предлагает решение в виде проверок работоспособности из модуля ngx_http_upstream_hc_module: периодически запрашивается какой-то URL (или просто пытается открыть порт), и, если тот или иной бэкенд не отвечает, его временно исключают из рабочего списка.
Другая проблема, которая также решается в коммерческой версии, — ограничение на количество одновременных запросов к бэкенду, а точнее — помещение запросов, превышающих лимиты, в очередь для последующей обработки.
Представьте, что у вас есть приложение, которое легко может устроить out-of-memory event, если к нему подключится много клиентов. Вы знаете его пределы и, например, не хотите пускать больше ста пользователей за раз. Если нет возможности организовать очередь запросов, то даже при небольших всплесках активности пользователей не избежать 502-х ошибок в сторону клиента или даже OOM на серверах с приложением.
Третье существенное ограничение бесплатной версии Nginx — отсутствие встроенного способа получения вменяемой статистики по распределению трафика по бэкендам.
Что же делать, если коммерческая подписка по каким-то причинам не подходит, а в остальном вас Nginx полностью устраивает?
Несколько лет назад я работал на одну крупную российскую компанию и стоял перед этим вопросом. Дополнительно меня тяготило, что под Nginx у нас были существующие и довольно сложные конфигурации сайтов, бездумно трогать которые было совершенно небезопасно. Тогда в мою голову пришло решение, о котором хочу сегодня рассказать, — разделить задачи конфигурации бизнесовой логики сайта с его десятками locations, headers и прочих радостей и задачу управления распределением нагрузки между серверами. С первой задачей Nginx справляется на отлично, а вот второе прекрасно умеет решать очень известный на рынке продукт — Haproxy.
Здравствуй, старый друг
Что же умеет Haproxy в бесплатной своей версии из того, что нам пригодится:
Низкое потребление памяти и CPU, что нам очень даже нужно, ведь Nginx мы договорились оставить.
Tcp-streams, HTTP, HTTP/2 (в том числе и в сторону бэкендов) и скоро будет HTTP/3 (QUIC).
Распределение трафика между сотнями серверов с десятком алгоритмов балансировки и гибкой логикой выбора набора используемых бэкендов.
Замечательные health-check«и из коробки, в том числе с понижением нагрузки на сервера при их перегрузке.
Лимиты на частоту и количество соединений, а также очередь входящих запросов.
Возможность динамически формировать список серверов, управлять ими через unix domain socket, собирать оттуда счётчики, если нужно.
Умилительная, но очень-очень полезная html-страничка статистики, которая вызывает ностальгические воспоминания своим почти неизменным за последние 20 лет дизайном, но скрывает могучие возможности по управлению балансировкой.
Почему не Envoy?
Очень субъективный ответ: Envoy прекрасен, но чуть более требователен к ресурсам, а они при объединении двух компонентов становятся очень важны. Как мне кажется, идеальное место применения Envoy — динамически настраиваемый sidecar proxy в облачном контейнере, что тоже интересно, но всё-таки вне темы этой статьи. Повторюсь: не претендую на истину в последней инстанции и буду рад узнать что-нибудь новое в комментариях.
Собираем пазл
При наличии незагруженных ядер и достаточного количества памяти Nginx и Haproxy отлично уживаются на одном хосте, общаясь друг с другом через unix domain или tcp-сокеты. Что выбрать — зависит от вашего профиля нагрузки. Подробный тест будет позже, а пока я сформулирую общие правила:
Если ваш сайт генерирует страницы большого объёма и одновременных клиентских сессий мало (например, десятки), то лучше будут работать unix-sockets. Но так как unix-сокеты — это фактически просто файлы, придётся подумать о том, как организовать структуру хранения, и о правах. Кроме того, в unix-сокеты относительно сложно быстро заглянуть без риска пролить клиентский трафик.
Если же у вас много клиентов, а ответы серверов обычно небольшие (например, десятки килобайт), то tcp покажет лучшие результаты по задержке. Он намного гибче в использовании. Вы можете запустить tcpdump на lo-интерфейсе и вживую увидеть всё, что там творится. А можете какой-нибудь умный фильтр между прокси-серверами поставить, который интересный для вас трафик куда-нибудь перенаправит, отфильтрует или модифицирует. При необходимости Haproxy можно будет перенести на другую машину без особых проблем.
В tcp-режиме стоит поговорить про адресацию. Классическое решение: Haproxy слушает какие-то порты на 127.0.0.1, куда подключается Nginx. Но здесь есть несколько подводных камней.
Довольно скоро при большом пользовательском трафике и множестве haproxy-бэкендов вы столкнётесь с исчерпанием эфемерных портов. С этим можно бороться, увеличив их количество, но вы в любом случае будете ограничены теоретическим пределом около 65 000.
Если у вас на Haproxy множество конфигураций, которые слушают разные порты, то всё это очень быстро превратится в полнейший бардак, где живут 127.0.0.1:8000, 127.0.0.1:8080, 127.0.0.1:8888 и ещё десяток разных 8xxx, и кто из них за что отвечает, без чтения конфигурации понять будет невозможно. Если вы разбираете ретроспективные логи, то даже при наличии репозитория с конфигурацией всё будет совсем невесело.
Для себя я нашёл вот такое решение. Для начала вспомним про ipv6: во-первых, он у вас есть, во-вторых, сетевой стек в ядре сейчас под него очень хорошо оптимизирован. В ipv6, как и в ipv4, есть диапазон так называемых частных адресов, которые вы можете использовать по своему усмотрению — это fd00::/8. Вероятнее всего, вы сможете выбрать какую-то сеть из этого диапазона для ваших внутренних нужд, требования RFC на этот счёт описаны тут. Я предположу, что это будет fd00::/64. Также я предположу, что ваш сайт доступен снаружи под ipv4 адресом 192.0.2.1 и ещё каким-то ipv6. В таком случае мы можем добавить на lo-интерфейс адрес fd00::192.0.2.1/128 (есть такая нотация у ipv6-адресов, она будет интерпретироваться как fd00:: c000:201) и его же использовать в Haproxy.
Если сайт требует больше одного haproxy-бэкенда — не беда. Ipv4 адрес занимает лишь младшие 32 бита, а у нас есть ещё 2^32 вариантов: [fd00::1.192.0.2.1]:80, [fd00::2.192.0.2.1]:80, [fd00::1234:5678.192.0.2.1]:80. Никаких больше проблем с эфемерными портами, а по адресу сразу всем понятно (даже вашим парсерам логов), к какому сайту он относится. В примерах я буду придерживаться именно этого подхода.
Важное дополнение про tcp и Nginx: Nginx фактически не способен работать с бэкендами через HTTP/2 и выше (кроме gRPC-бэкендов). Также он по умолчанию общается через HTTP/1.0. У этого протокола есть две важные для нас особенности:
На каждый запрос обязательно открывается отдельное соединение, что очень дорого, если мы работаем поверх tcp даже на одном хосте.
Не предполагается использование заголовка Host, что может привести к исключительно интересным расследованиям «угадай, кто тебе ответил» в дальнейшем.
Поэтому мы сразу договоримся, что во все прокси-секции Nginx, даже при использовании unix-socket, мы будем добавлять:
location @upstream {
proxy_http_version 1.1;
proxy_set_header "Connection" "";
proxy_set_header Host $http_host;
...
}Для примера предположим, что у вас есть какая-то гипотетическая четырёхъядерная система, которая не бывает загружена более, чем на 200% (два ядра). Сервера приложений живут где-то ещё, а на системе крутится Nginx с примерно таким файлом конфигурации (пропускаю всё, что не относится к теме, в том числе SSL, HTTP/2 и прочее):
worker_processes auto;
http {
upstream servers {
server 10.0.0.1:80;
server 10.0.0.2:80;
server 10.0.0.3:80;
}
server {
listen 192.0.2.1:80;
location / {
proxy_pass http://servers/;
}
}
}Создаём конфигурацию Haproxy. Я убрал отсюда всё неважное для нас сейчас и уверен, что, установив Haproxy к себе в систему, вы найдёте там готовый /etc/haproxy/haproxy.cfg, в котором для начала нужно лишь добавить или заменить секции frontend и backend.
global
chroot /var/lib/haproxy
user haproxy
group haproxy
daemon
# Start two threads...
nbthread 2
# And bind them to the 2nd and the 3rd CPUs
cpu-map 1/all 2-3
defaults
# By default Haproxy works in TCP-mode
mode http
# Log only HTTP requests
option dontlognull
# It isup to you what timeouts to set
timeout connect 5s
timeout client 5s
timeout server 5s
frontend fe_default
# Fancy ipv6 loopback-address
bind [fd00::192.0.2.1]:8000
# By all means use servers from be_default backend
default_backend be_default
backend be_default
# Declaring the servers: names, addresses and ports
server server1 10.0.0.1:80
server server2 10.0.0.2:80
server server3 10.0.0.3:80Обязательно добавляем на lo-интерфейс нужный ipv6-адрес. Временно это можно сделать через sudo ip -6 address add fd00::192.0.2.1/128 dev lo, а как сохранить его навсегда — зависит от вашего дистрибутива. Перезагружаем конфигурацию Haproxy (обычно sudo systemctl reload haproxy) и возвращаемся к Nginx:
# We've bound Haproxy to the cores #2 and #3
# So, Nginx will use #0 and #1
worker_processes 2;
worker_cpu_affinity 0001 0010;
http {
upstream haproxy {
# We need a zone for the workers to share the upstream state
zone haproxy 64K;
# Haproxy's local address
server [fc00::192.0.2.1]:8000 max_fails=0;
# Always have hundred connections ready
keepalive 100;
}
server {
listen 192.0.2.1:80;
location / {
proxy_pass http://haproxy/;
# Proxy buffering is better be turned on,
# unless you have huge responses
proxy_buffering on;
# Turning on keepalive
proxy_http_version 1.1;
proxy_set_header "Connection" "";
# Always add the port if it differs from 80/443
proxy_set_header Host $http_host:$server_port;
# Not necessarily, but ease debugging a lot
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Real-IP $remote_addr;
}
}
}Обновляем конфигурацию Nginx: sudo systemctl reload nginx. При определённой доле везения на этом всё должно заработать.
Крутим ручки настройки
Итак, у нас есть рабочий бутерброд из двух обратных прокси. Но в таком виде он ничем не лучше, чем просто Nginx. Даже заметно хуже, так как обрабатывает трафик дважды. Давайте начнём с чего-то простого и полезного.
Мы хотим знать, живы ли сервера приложений на серверах. Для этого мы можем поправить бэкенд-секцию в Haproxy вот так:
backend be_default
default-server check
server server1 10.0.0.1:80
server server2 10.0.0.2:80
server server3 10.0.0.3:80 check-ssl port 443 verify requiredОпция default-server применяется по умолчанию для всех серверов секции. Сервер вправе переопределить что-то для себя. В данном случае мы просим Haproxy каждые две секунды пытаться открыть tcp-соединение на адрес и 80-й порт каждого из серверов. Кроме последнего (server3), там он пытается открыть TLS-соединение на порт 443 того же сервера, проверяя при этом корректность сертификата кроме поля subject. Если трижды подряд не получится это сделать, сервер будет временно отключён от нагрузки. Но попытки при этом не прекратятся, но когда две подряд увенчаются успехом, нагрузка будет возвращена. Все эти тайминги и количество попыток конфигурируется опциями inter, fall и rise. Порт и даже адрес хоста, куда отправляются проверки, можно задать опциями addr и port.
Если мы хотим убедиться, что сервер приложений гарантированно работает, можно использовать проверку HTTP-запросом. Я покажу пример с использованием GET-запроса, который должен вернуть определённую строку (healthy), но часто просто используется HEAD-запрос на URL »/». Проверок можно указать несколько, например, на разные порты, тогда все они должны быть успешны.
backend be_default
option httpchk
http-check send meth GET uri /health ver HTTP/1.1 hdr host localhost
http-check expect rstring healthy
default-server check
server server1 10.0.0.1:80
server server2 10.0.0.2:80
server server3 10.0.0.3:80А теперь самое интересное. Дополнительно к обычным проверкам доступности Haproxy предлагает Agent check. Подразумевается, что где-то есть приложение-агент: одно на всех или индивидуальное на каждом узле. Это приложение знает о состоянии бэкендов и может регулировать нагрузку на них. Оно должно слушать tcp-порт и при подключении отвечать одной строкой со статусом бэкенда. Haproxy подключается к приложению, может опционально передать туда какую-то строку, например, имя проверяемого сервера, вычитывает и разбирает ответ, меняет статус или вес бэкенда. Звучит сложнее, чем это есть на самом деле. Давайте разберём пример:
backend be_default
option httpchk
http-check send meth GET uri /health ver HTTP/1.1 hdr host localhost
http-check expect rstring healthy
default-server check weight 100 agent-check agent-addr 10.0.0.4 agent-port 10000 agent-inter 5s
server server1 10.0.0.1:80 agent-send "server1\n"
server server2 10.0.0.2:80 agent-send "server2\n"
server server3 10.0.0.3:80 agent-send "server3\n"В общем для всех указанных серверов параметре default-server появились две новые группы опций:
Вес
weight: запросы от клиентов распределяются среди серверов-бэкендов согласно запрошенному типу балансировки (параметрbalance). По умолчанию этоroundrobin, то есть честное распределение среди всех живых бэкендов пропорционально их весу. Иными словами, если у одного сервера вес 100, а у другого — 2, то второй будет получать в 50 раз меньше трафика, чем первый. По умолчанию вес равен 1, мы меняем его на 100.Настройки agent check: адрес, порт и интервал — как часто ходить по указанным реквизитам.
Каждые 5 секунд для каждого сервера Haproxy открывает порт 10.0.0.4:10000 и пишет туда заданную строку, например, server1 + перевод строки. Сервис с той стороны отвечает одной строчкой, которая заканчивается переводом строки. В этой строчке может быть несколько токенов, разделённых пробелом, табуляцией или запятыми. Подробнее, что там может быть, описано в документации. После этого tcp-сокет закрывается. Приведу несколько примеров ответов агента:
drain— убрать нагрузку сервера и перевести его в MAINT-статус;ready— вернуть сервер к READY-статусу и подать нагрузку;50% maxconn:30— вес сервера должен быть установлен в 50% от заданного при конфигурации, а максимальное количество одновременных клиентских запросов, которые он может обслужить, не может быть больше 30. Именно ради этих 50% мы и устанавливали вес, так как 50% от одного — это 0, а на сервера с нулевым весом нагрузка не подаётся (по сути, это DRAIN-статус). Будьте аккуратны, играя с процентами, и не делайте вес сервера меньше 100.
Пример программы на Go, которая меняет вес сервера в зависимости от загруженности его CPU, есть тут.
Надеюсь, что вы почувствовали всю мощь, которую открывает перед вами agent check.
Наблюдаем и управляем
Итак, у нас всё как-то работает, но пока не видно, как именно. У Haproxy накопилось множество различных инструментов интроспекции, но я хочу поговорить про следующие три:
Первые два варианта мы можем элегантно сконфигурировать вместе вот в такой бэкенд-секции:
frontend stats
bind 127.0.0.1:8080
mode http
http-request use-service prometheus-exporter if { path /metrics }
stats enable
stats uri /stats
stats refresh 30sУбедитесь, что поддержка Prometeus скомпилирована в вашей сборке Haproxy: haproxy -vv | grep USE_PROMEX=1.
Если всё в порядке, применяем новые настройки через sudo systemctl reload haproxy и идём браузером на адрес сервера http://ваш-сервер:8080/stats.
Можно ещё добавить SSL, ACL, аутентификацию и повесить на внешний интерфейс для удобства. Но это не самое интересное. Самое интересное — это режим администратора (stats admin if
С CLI тоже всё довольно просто. В секции global у вас должен быть сконфигурирован unix-socket для доступа к статистике и не только, а также указан таймаут — иначе он будет лишь 10 секунд. Обратите внимание на уровень доступа: если вы хотите управлять бэкендами, вам может понадобиться level admin. В других случаях достаточно level operator, который позволяет получать информацию о происходящем в системе и сбрасывать счётчики.
global
stats socket /run/haproxy/admin.sock mode 600 level admin
stats socket /run/haproxy/stats.sock mode 660 level operator
stats timeout 1mНесколько примеров того, как с этим сокетом работать:
Получить массу информации о статусе, счётчиках, состоянии секций и серверов:
echo "show info; show stat; show table" | socat /run/haproxy/stats.sock stdio.Сбросить счётчики всех секций и серверов:
echo "clear counters" | socat /run/haproxy/stats.sock stdio.Если вы сконфигурировали socket-файл с параметром level admin, вы сможете также управлять серверами и секциями. Например, вот так мы отключаем один из ранее сконфигурированных серверов и добавляем новый. Учтите только, что динамически добавленный сервер не переживёт перезагрузки конфигурации haproxy и исчезнет. В остальном — всё будет прекрасно работать:
echo "disable server be_default/server3; add server be_default/server4 10.0.0.5:80 enabled check; enable health be_default/server4" | socat /run/haproxy/admin.sock stdio.
Возможностей очень много, и я отошлю вас к документации, чтобы поискать там ещё что-нибудь полезное. Буду рад, если в комментариях вы расскажете, что удалось найти.
Измеряем производительность
Самая грустная глава — и не только потому, что последняя. Дело в том, что каждый слой прокси-серверов замедляет ответы бэкендов. Особенно это заметно на маленьких и быстрых ответах.
Также Haproxy будет кушать CPU и память: немного, но данные нужно где-то хранить, а HTTP-протокол придётся ещё раз декодировать и обратно закодировать. Ещё есть всеми любимые переходы из пространства пользователя в пространство ядра и обратно для передачи данных даже через loopback-интерфейс.
Именно поэтому в разделе о конфигурации я говорил о многоядерных системах, загруженных условно наполовину. Если вы возьмёте одноядерную машину и просто запустите там Haproxy в дополнение к Nginx, то тайминги вашего сервиса увеличатся почти в два раза (для быстрых страниц и под 100%-й нагрузкой). Иногда, как ни странно, это даже помогает, сглаживая пики пользовательских запросов.
Хорошая новость: если свободные CPU-ресурсы и память у вас есть, то большинство клиентов этих нескольких добавленных миллисекунд не заметят никогда, потому что:
Интернет огромный в плане расстояний, и редко кто-то будет жить вплотную к вашему дата-центру (ну разве что админы, которые там и живут).
Клиенты очень часто сидят на Wi-Fi или сотовой сети, а там такие задержки и такой джиттер, что… ну, вы понимаете.
Маленькая статика и котики у вас наверняка на CDN (на CDN же, правда?), а локальный NodeJS или Tomcat всё равно отвечает за сотни миллисекунд (иначе несерьёзно как-то).
Предлагаю перейти к графикам и посмотреть, где и сколько мы теряем, получив мощь и гибкость работы с двумя прокси-серверами одновременно.
Описание стенда
Три самых дешёвых виртуальных машины в одном из дата-центров облачного провайдера. На каждой из них один неторопливый Intel CPU и гигабайт оперативной памяти. Плюс одна чуть подороже с Intel Premium CPU (что бы это ни значило, но он реально быстрее раза в два) и тоже гигабайтом RAM под прокси-сервер. Диски заявлены, как SSD.
Какая-то виртуальная внутренняя сеть на 2,5 Гб, почему-то работающая только с ipv4.
Ubuntu 22.04, штатный Nginx=1.18.0–6ubuntu14.4 и нештатный, но свежий
Haproxy=2.8.3-1ppa1~jammy.Конфигурационные файлы Nginx — тут, а Haproxy — тут.
Для тестирования использовался
wrk=4.1.0-3build1.Трафик и нагрузку на память мы создавали вот этой программой с гордым названием Generator, которая довольно быстро работает, но легко доводит несчастную виртуалку до OOM при нескольких сотнях одновременных клиентов.
На виртуальной машине, которая будет играть роль прокси, к systemd-конфам Nginx, Haproxy и Generator был добавлен параметр CPUQuota=33%, чтобы минимизировать конкуренцию за CPU. Двух- и более ядерные виртуальные машины оказались как-то неприлично дороги.
Из sysctl-тюнинга ничего не делал, кроме увеличения
net.core.netdev_max_backlog, net.core.somaxconnиnet.ipv4.tcp_max_syn_backlogдо 1024.И ещё я не использовал TLS и HTTP/2, так как речь совсем не про них.
Всё! Сцена нарисована, артисты расставлены, давайте измерять.
Акт 1. Генератор трафика на прокси-сервере
Все три участника: Nginx, Haproxy и Generator — запущены на одном сервере. Ядро одно, но через cgroups каждому выделено лишь 33%. Тестирование проводится с соседнего сервера.
Цели тестирования:
Показать вносимые проксированием задержки, минимизируя влияние сети на трафик между прокси и сервером приложений.
Определить различия поведения unix sockets и tcp sockets для обмена данными между Nginx и Haproxy.
Для тестирования мы будем запрашивать Generator выдать нам ответы размером 1, 30 и 100 КБ (без учёта заголовков). Wrk будет последовательно загружать систему в течение 30 секунд сначала 1 подключением, затем 10, 100, 250, 500, 750 и, наконец, 1 000.
Пример командной строки запуска wrk:
wrk -t4 -c500 -d30s http://proxy/generate/102400 --latency --timeout 30s
Оценивать будем медиану времени ответа:

Рисунок 1. Сравнение таймингов на ответе в 1 КБ

Рисунок 2. Сравнение таймингов на ответе в 30 КБ
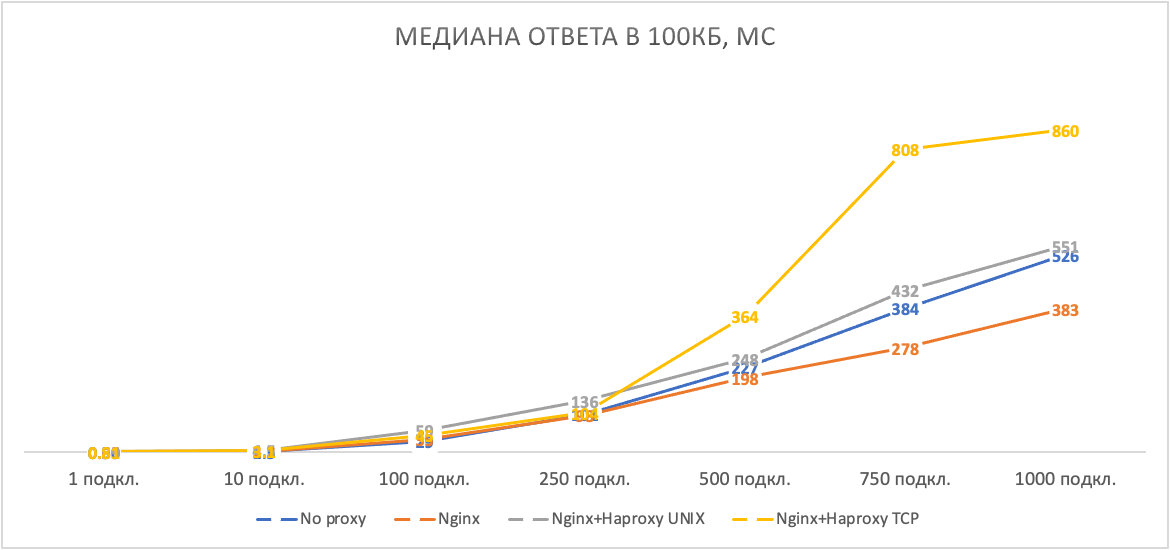
Рисунок 3. Сравнение таймингов на ответе в 100 КБ
Что мы видим на этих графиках:
Проксирование — это всегда некоторое ухудшение таймингов. Это очевидно, но сейчас вы видите насколько — сотни микросекунд на единичных запросах. При большом количестве пользователей паразитная задержка кратно растёт, так как ресурсы CPU остались всё те же, и каждый запрос разбивается на большее количество тайм-слайсов, растянутых во времени.
Unix-сокеты — штука очень интересная. На потоках малого размера они только всё портят, но если нужно передавать большие файлы, то отсутствие необходимости дополнительного перехода kernel/user space становится их убойным преимуществом. Посмотрите на стремительный рост таймингов в tcp-варианте подключения на рисунке 3.
Непонятно, каким образом, но на больших файлах и множестве клиентов Nginx показал лучшее время ответа, чем прямое подключение к приложению генератору трафика. Я повторял тест — всё так же. Если у кого-то есть какие-то мысли на этот счёт, то поделитесь, пожалуйста, в комментариях.
Акт 2. Отпавший бэкенд
Сейчас мы будем имитировать падение одного из двух серверов под балансерами. Просто останавливать сервис — неинтересно, так как прокси получают RST-ответ и быстро соображают, что нужно переотправить запрос на другой сервер. Мы сделаем хитрее: будем тихо отфильтровывать все приходящие от прокси-сервера на один из серверов-бэкендов пакеты: iptables -I INPUT -s proxy-server-ip -j DROP.
Но есть и ещё кое-что. Параметры запросов подобраны так, что один сервер-бэкенд при запросе ответов размера в 100 КБ и выше может выдержать примерно 100 одновременных клиентских сессий. После этого память на сервере заканчивается, процесс умирает и перезапускается. Когда живы оба бэкенда, запросы равномерно распределяются между ними, и всё работает относительно хорошо. Но если вся нагрузка ляжет на одного… Посмотрим, что будет.
Цель тестирования — определить, получаем ли мы какую-то пользу от наличия второго реверс-прокси в случае непредвиденного отключения сервера-бэкенда.
Замеряем производительность решения и наличие ошибок по методике из предыдущего акта. Здесь возможны следующие варианты:
Оба бэкенда живы.
Один бэкенд недоступен — решение, построенное только на Nginx с настройками по умолчанию.
Аналогичный вариант, но с ограничением max_conns=100 для бэкендов.
Один бэкенд недоступен, но вторым слоем дежурит Haproxy, где установлено ограничение в 100 одновременных клиентских сессий на один сервер. На Nginx ограничений нет.
На графиках я не показываю медиану ответа, если процент ошибок за сессию превышает 20%, так как wrk считает задержку для всех кодов ответа в одной куче.

Рисунок 4. Сравнение медианных таймингов при одном недоступном бэкенде и ответе в 1 КБ
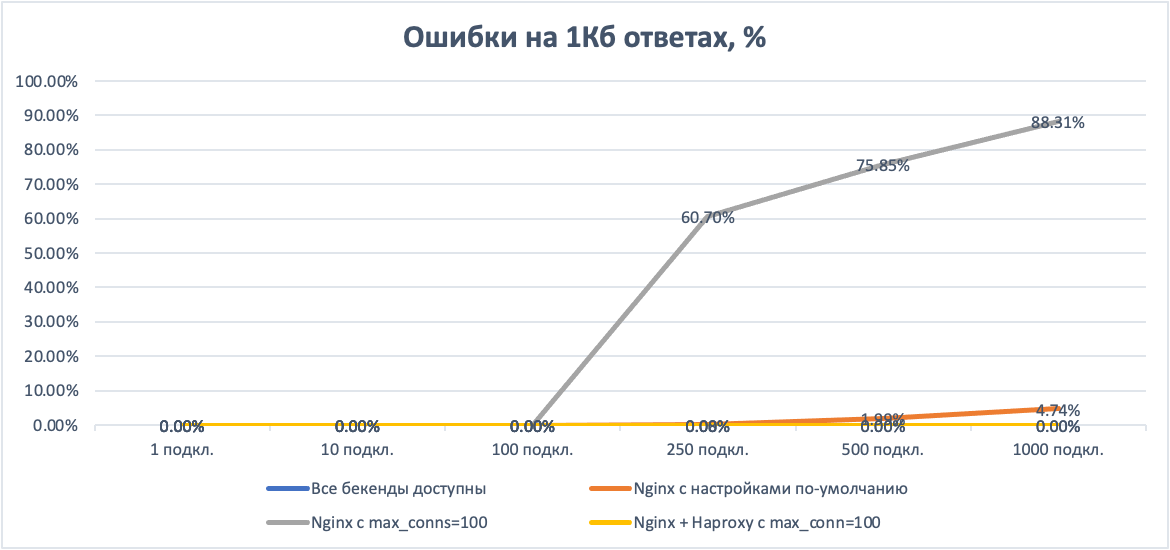
Рисунок 5. Ошибки при одном недоступном бэкенде и ответе в 1 КБ
На маленьких ответах наш бэкенд способен справиться и с тысячей одновременных запросов в одиночку. Nginx при этом показывает лишь небольшое проседание по таймингам, заметное на десятке одновременных клиентов. Ожидаемые 60% потерь для Nginx с лимитом в 100 соединений на бэкенд, начиная с 250 одновременных клиентов. Комбинация с Haproxy ведёт себя стабильно и без ошибок, показывая чуть большие тайминги.
30 КБ вариант я пропущу для экономии времени. Он показал что-то промежуточное между 1 КБ и 100 КБ. Увеличиваем размер ответа сразу до 100 КБ.
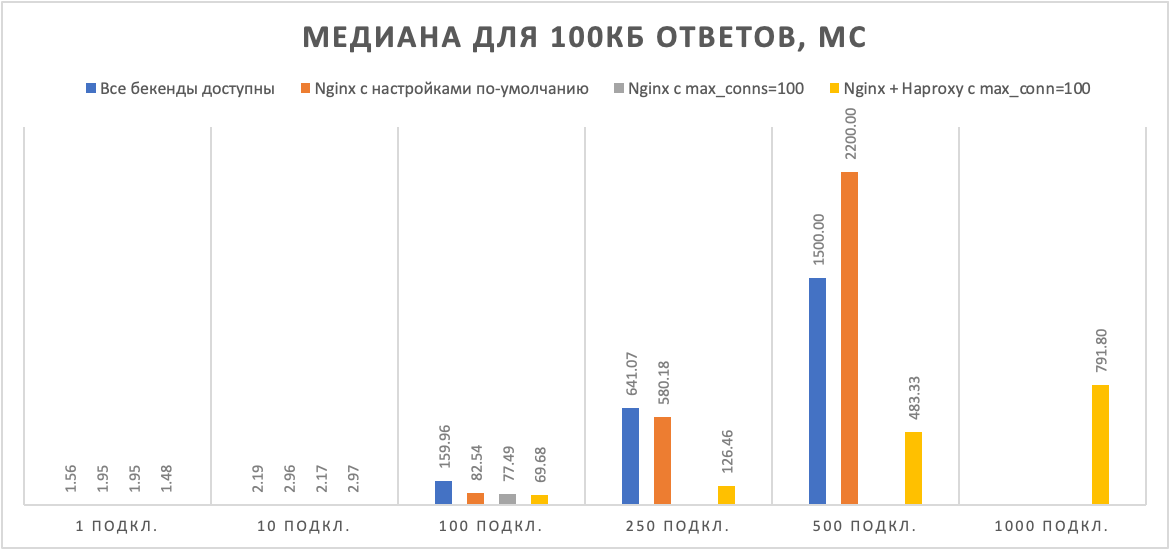
Рисунок 6. Сравнение медианных таймингов при одном недоступном бэкенде и ответе в 100Кб

Рисунок 7. Ошибки при одном недоступном бэкенде и ответе в 100 КБ
Становится интереснее. Бэкендам уже не хватает памяти, чтобы обслужить 500 одновременных соединений. Все варианты, кроме гибрида с Haproxy, показывают огромное количество ошибок на тысяче одновременных клиентов. Тайминги Nginx улетают вверх. Гибрид с Haproxy стабилен, и задержки его растут линейно с количеством пользователей.
Давайте ещё увеличим размер ответа до 1 МБ.

Рисунок 8. Сравнение медианных таймингов при одном недоступном бэкенде и ответе в 1Мб

Рисунок 9. Ошибки при одном недоступном бэкенде и ответе в 1Мб
Начиная с 250 одновременных клиентов, в живых остался только гибрид с Haproxy. Всё так же без ошибок, всё так же линейно растут задержки от числа клиентов.
Думаю, что победа парной работы двух реверс-прокси в данном примере очевидна.
Акт 3. Реальный пользователь
Напоследок посмотрим, видна ли разница в таймингах у пользователя, находящегося примерно в 12 миллисекундах от дата-центра, где размещён наш стенд.

Рисунок 10. Медианные тайминги ответов в 1 КБ на удалённом клиенте
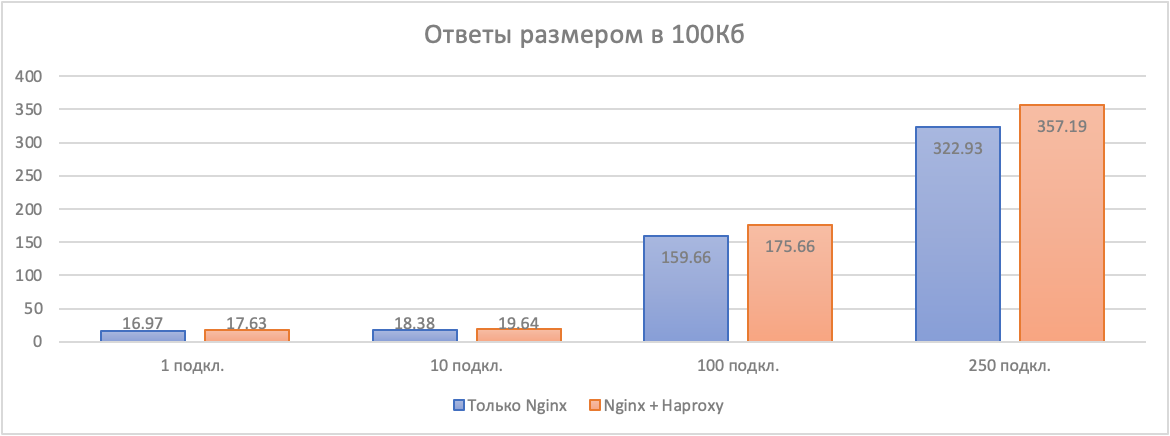
Рисунок 11. Медианные тайминги ответов в 100 КБ на удалённом клиенте
Как видите, время ответа действительно немного подрастает. Но насколько это критично для ваших клиентов — решать вам.
Заключение
Ну что же, мы попробовали преодолеть ограничения одного бесплатного инструмента с помощью другого бесплатного инструмента, и всё получилось. Решение не бесплатное, но цена известна, и она в CPU, памяти и таймингах. Взамен же вы получаете большую гибкость и надёжность всей вашей системы.
Если вам интересна эта тема и вы хотите больше узнать о применении Haproxy для распределения относительно больших объёмов трафика, пишите в комментариях. Буду рад поделиться ещё чем-нибудь интересным.
Спасибо, что осилили!
