У ELK’и иголки колки: минимизируем потерю сообщений в Logstash, следим за состоянием Elasticsearch

Стек от Elastic — одно из самых распространенных решений для сбора логов. А точнее — две его разновидности: ELK и EFK. В первом случае речь идет про Elasticsearch, Logstash, Kibana (а еще — Beats, который даже не участвует в аббревиатуре, о чем шутят сами создатели: «Do we call it BELK? BLEK? ELKB?»). Вторая связка — Elasticsearch, Fluentd и Kibana (уже без шуточек). У каждого элемента в этих стеках есть своя роль и выход из строя одного из них зачастую нарушает работу остальных. В этой статье поговорим об ELK-стеке, а в частности — о двух его элементах: Logstash и Elasticsearch.
Статья не является исчерпывающим руководством по тонкостям установки и настройки этих элементов. Это скорее обзор некоторых полезных фич и чек-лист по мониторингу не самых очевидных моментов, чтобы минимизировать потерю сообщений, проходящих через ELK. Также стоит упомянуть, что в статье мы не коснемся тем, связанных с программами-коллекторами (посредством чего сообщения попадают в Logstash) из-за их великого разнообразия: речь пойдет только о core-компонентах.
Logstash
Logstash, как правило, выступает для сообщений посредником, трансферной зоной. Он хранит эти сообщения в оперативной памяти, что является эффективным с точки зрения скорости их обработки, но чревато их потерей при перезапуске logstash. Также возможен сценарий, когда сообщений в очереди набирается настолько много (например, Elasticsearch перезапускается и недоступен), что Logstash начинает утекать по памяти, OOM-иться и перезапускается, поднимаясь уже «пустым».
Persistent Queue
Если через Logstash проходят важные сообщения, потеря которых критична (например, когда он выступает в роли consumer’а какого-либо брокера сообщений) или если нам необходимо переждать возможный большой даунтайм — например, во время тех. работ — со стороны получателя сообщений (обычно это Elasticsearch), можно прибегнуть к использованию persistent queue (документация). Это настройка Logstash, позволяющая хранить очереди на диске.
Из потенциальных проблем, с которыми мы можем столкнуться: небольшая потеря в производительности (однако это гибко настраивается) и вероятность дублирования сообщений после некорректной остановки Logstash (SIGKILL). Также не забываем, что за свободным местом на диске необходимо следить и создать для очередей отдельный PV (если Logstash запускается в Kubernetes-кластере). Путь до директории с очередью задается переменной path.queue и по умолчанию это path_to_data/data/queue.
При настройке persistent queue стоит обратить внимание на параметр queue.checkpoint.writes. Грубо говоря, он отвечает за то, как часто будет вызываться fsync и записывать очереди на диск. Значение по умолчанию — через каждые 1024 сообщения. Можно установить значение данного параметра в 1 для максимальной сохранности сообщений, но так мы потеряем в производительности.
Также обратим внимание на queue.max_bytes — общая емкость очереди. Значение по умолчанию — 1 Гб. При его достижении (т.е. если у нас скопилось файлов очереди на 1 Гб) новые сообщения Logstash не принимает, пока очередь не начнет разбираться и в ней не появятся свободные места. Если мы настроили PV для persistent queue размером, например, 4 Гб, следует не забыть изменить эту переменную.
Стоит обратить внимание, что еще есть параметр queue.max_events, который выполняет схожую функцию, но единица измерения уже не в байтах, а в количестве сообщений (по умолчанию 0, т.е. не ограничено). Если у нас задан и queue.max_bytes, и queue.max_events, Logstash примет за истину тот параметр, до ограничения которого первым доберется.
Еще из интересного: persistent queue хранит очереди в файлах, называемых страницами. Как только страница достигает определенного размера — queue.page_capacity (по умолчанию 64 Мб), — она становится неизменяемой, т.е. блокируется для записи (ждет, пока ее сообщения будут разобраны). После этого создается новая активная страница, которая аналогично ждет, пока не вырастет до размера queue.page_capacity… Каждая страница хранит какое-то количество сообщений и, если хотя бы одно сообщение из этой страницы не было отправлено, страница не будет удалена с диска (и будет занимать место, установленное в queue.max_bytes). По этой причине выставлять большое значение для queue.page_capacity не рекомендуется.
Подведем краткий итог. Persistent queue отлично подойдет, если вам важно минимизировать потерю сообщений, однако желательно протестировать его перед эксплуатацией в production-окружении, т.к. сохранение сообщений на диске (вместо оперативной памяти) может повлечь за собой небольшую потерю в производительности. Пример теста производительности можно найти в официальном блоге Elastic.
Dead Letter Queue
Раз уж мы заговорили о persistent queue, что позволяет добиться минимизации потери сообщений, стоит рассказать и про dead letter queue (документация). Эта функция позволяет сохранять сообщения с ошибкой маппинга. Часто их оказывается больше, чем ожидалось. Начнем с нескольких «но»:
DLQ работает только с сообщениями, которые изначально адресовались в Elasticsearch, т.е. DLQ будет собирать сообщения с неудачным маппингом только у тех пайплайнов, output которых был настроен на Elasticsearch.
Сообщения с ошибкой маппинга Logstash складывает локально на диск в файлы. Он умеет отправлять эти сообщения в Elasticsearch при помощи input-плагина DLQ, но файлы эти с диска после отправки он не удалит.
DLQ работает следующим образом. Если при отправке сообщения Logstash«ем в Elasticsearch его структура сильно отличается от той, что Elasticsearch ожидал увидеть, Elasticsearch откажется его принимать, а Logstash в свою очередь отбросит это «не принимаемое» сообщение и продолжит работать с новыми. Однако, если мы включили DLQ, Logstash начнет складывать отвергнутые сообщения в файлы по пути path_to_data/data/dead_letter_queue/имя_пайплайна.
Если мы включили DLQ, то при старте Logstash«а, зайдя в директорию с сообщениями, увидим, что там есть два файла: 1.log.tmp и .lock. Файл с tmp в конце — активный файл, в который будут писаться сообщения с ошибкой маппинга.
Настроек у DLQ не так много. Основных всего две: dead_letter_queue.flush_interval — число в миллисекундах, отвечающее за то, как скоро будет создан новый tmp файл, дефолтное значение — 5 секунд (5000 мс). При старте у нас создается пустой 1.log.tmp. Этот 1.log.tmp станет 1.log (избавится от приписки tmp и, как следствие, станет неизменным) и создастся 2.log.tmp, если в 1.log.tmp не было новых записей уже 5 секунд. Подразумевается, что какие-то сообщения в него успели прийти (пустые файлы не ротируются).
И вторая настройка — dead_letter_queue.max_bytes. Это максимальный размер сообщений, который может храниться на диске. Значение устанавливается для всех файлов (1.log, 2.log, …) вместе взятых, а не для каждого по отдельности.
Как уже упоминалось, у DQL есть плагин, который отправляет сообщения с диска в Elasticsearch. Предположим, что у нас уже есть некоторый пайплайн main, через который проходят сообщения в Elasticsearch, и нам необходимо настроить DLQ для него:
1. Мы создаем новый пайплайн dead-letter-queue-main.conf:
input {
dead_letter_queue {
path => "/usr/share/logstash/data/dead_letter_queue"
commit_offsets => true
pipeline_id => "main"
}
}
output {
elasticsearch {
hosts => [ "{{ .Values.elasticsearch.host }}:{{ .Values.elasticsearch.port }}" ]
index => "logstash-dlq-%{+YYYY.MM.dd}"
}
}В input указываем путь к директории, где DLQ хранит сообщения. При помощи pipeline_id указываем, что хотим собирать неудачные сообщения пайплайна main. Подробнее о конфигурации плагина можно почитать в документации.
2. Мы создали пайплайн, но DLQ еще не включили. Для этого в pipelines.yml для main-пайплайна включаем DLQ и добавляем в список пайплайнов наш dead-letter-queue-main.conf:
- pipeline.id: main
path.config: "/usr/share/logstash/pipeline/pipeline-main.conf"
dead_letter_queue.enable: true
dead_letter_queue.max_bytes: 1024mb
dead_letter_queue.flush_interval: 5000
- pipeline.id: main-dlq
path.config: "/usr/share/logstash/pipeline/dead-letter-queue-main.conf"В данном примере мы включили DLQ только для пайплайна main. Если бы мы внесли данные настройки непосредственно в logstash.yaml, а не pipelines.yml, то DLQ был бы активен для всех пайплайнов Logstash«а. Аналогичным образом можно включить и persistent queue для какого-то конкретного пайплайна, а не всех сразу.
В данном примере в настройках DLQ указаны дефолтные max_bytes и flush_interval. Важно уточнить, что сообщения из *.log.tmp-файла не будут обрабатываться пайплайном DLQ (и, как следствие, отправляться в Elasticsearch), пока этот файл не закроется (избавится от приписки tmp) и не создастся новый *.log.tmp. Поэтому устанавливать слишком высокие значения для параметра dead_letter_queue.flush_interval не стоит.
Однако стоит обратить внимание на то, что сами сообщения DLQ с диска не удаляются — это еще не реализовано. Есть разные способы того, как с этим справляются пользователи, однако официально решения пока нет.
DLQ будет полезен, если вы стали замечать, что какие-то сообщения не доходят до Elasticsearch или просто хотите обезопаситься от этого. Подобное возможно, если структура сообщений меняется и Elasticsearch не может их обработать. В этом случае DLQ пригодится, однако помните, что эта функция еще не доведена до совершенства и некоторые аспекты применения приходится додумывать самостоятельно (как для случая с удалением DLQ с диска).
Elasticsearch
Elasticsearch можно назвать центром системы — он хранит наши сообщения. В этой части хочется упомянуть несколько моментов, которые позволят следить за его здоровьем.
Мониторинг
Начнем с того, что у Elastic-стека есть расширение X-Pack, которое содержит в себе много дополнительного функционала, платного и бесплатного. Начиная с версии 6.3 бесплатный функционал поставляется в стандартных сборках стека (basic-версия включена по умолчанию).
Весь список функций, предоставляемых X-Pack, можно посмотреть на официальном сайте. В столбце «BASIC — FREE AND OPEN» перечислено то, что доступно бесплатно.
NB. Что касается платных подписок — какой-то конкретной цены нет, она индивидуальна для каждого проекта и строится относительно задействованных ресурсов. Если открыть страницу с ценами, то для кластеров self-hosted вместо цены мы увидим кнопку «Contact us».
Итак, вернемся к бесплатной версии: некоторые функции в ней включены по умолчанию, а некоторые необходимо включить самим.
Мониторинг по умолчанию включен, а сбор данных — нет. Если мы добавим xpack.monitoring.collection.enabled: true в elasticsearch.yml, нам откроется множество подробных графиков, посвященным узлам и индексам кластера. Чтобы их открыть, необходимо перейти по адресу http://адрес_кибаны/app/monitoring. Вот говорящие за себя примеры некоторых из них:
 Мониторинг состояния узла Elasticsearch
Мониторинг состояния узла Elasticsearch Подробная информация по конкретному индексу
Подробная информация по конкретному индексуПри включении сбора данных в Elasticsearch появляются соответствующие индексы — например, для самого Elasticsearch«а это .monitoring-es-7-%{+YYYY.MM.dd}. Все возможные крутилки мониторинга описаны здесь.
Аналогичным способом можно включить мониторинг для Logstash, добавив xpack.monitoring.enabled: true и xpack.monitoring.elasticsearch.hosts: "адрес_эластика:9200" (однако является legacy-решением начиная с релиза 7.9.0 от августа прошлого года).
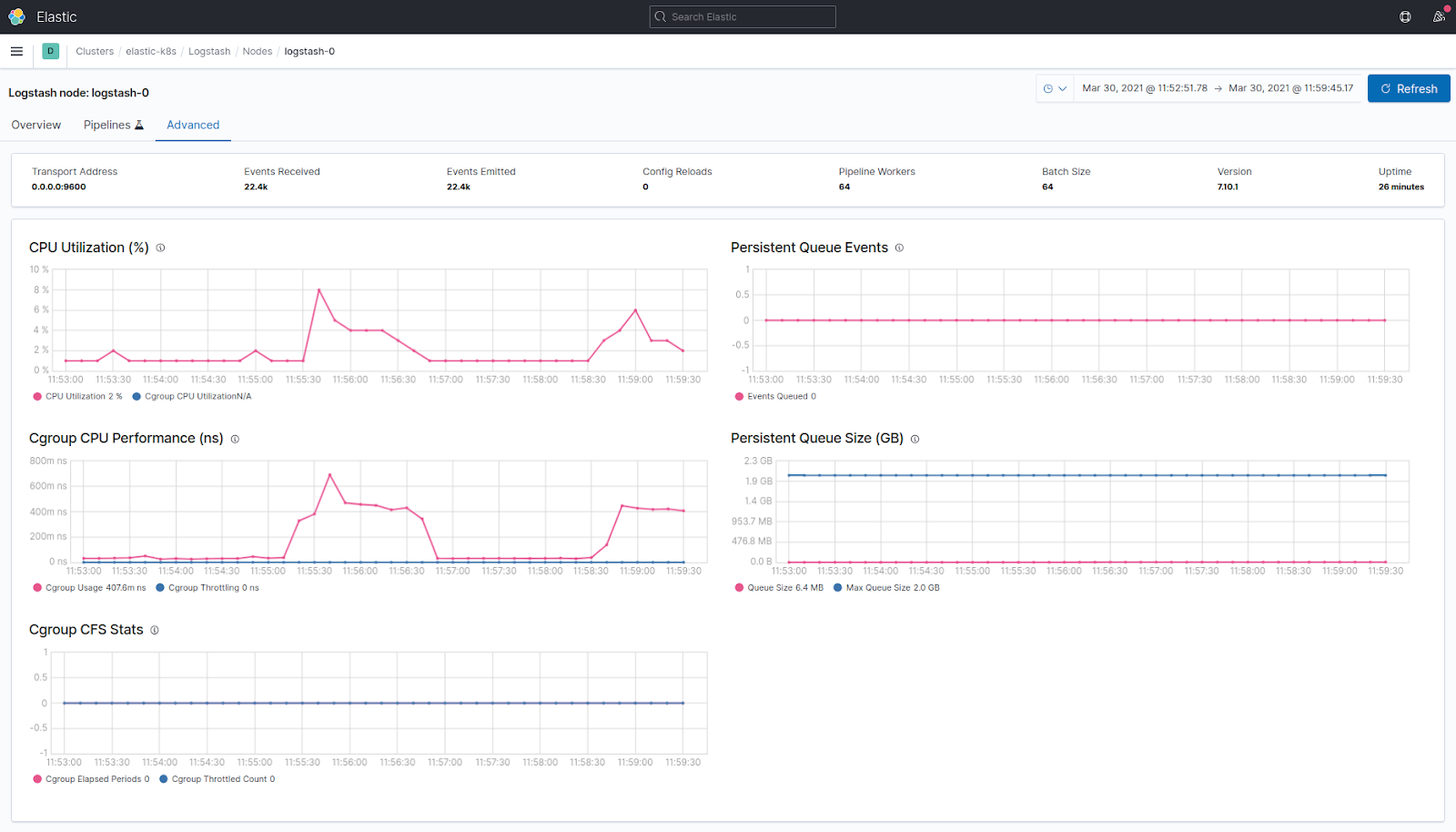 Мониторинг состояния узла logstash
Мониторинг состояния узла logstashТакже мы можем настроить авторизацию для своего кластера, включая окно авторизации для Kibana. Этому посвящен раздел Security. X-Pack содержит в себе много интересного функционала даже в бесплатной версии, однако часто случается так, что какие-то функции бесплатной фичи не работают с basic-лицензией.
Примером может служить мониторинг, о котором упоминалось выше, когда в Elasticsearch«е начинают появляться индексы .monitoring-es-7-%{+YYYY.MM.dd}. Для автоудаления этих индексов предусмотрен параметр xpack.monitoring.history.duration, однако при использовании basic-лицензии всегда будет использоваться значение по умолчанию.
Мониторинг, предоставляемый X-Pack«ом, — это просто красивая информативная панель, которая умеет показывать графики, что сможет нарисовать не каждый экспортер. Однако не стоит полностью на него полагаться, т.к. данные о мониторинге Elasticsearch хранятся в индексах, хранящихся в этом же Elasticsearch. Из-за этого система не кажется надежной (если у вас Elasticsearch из одного узла, то и вовсе таковой не является).
В связи с этим в официальной документации упоминается, что правильный подход — когда для production-контура у вас есть отдельный кластер для мониторинга. Для полноценного мониторинга узла необходимо настроить экспортер для самого Elasticsearch, чтобы следить за здоровьем кластера, unsigned-шардами, состоянием узлов… и еще экспортер для самой виртуальной машины для мониторинга нагрузки и свободного места на диске. Тут хочется обратить внимание на watermark.
Watermark
При настройке алертинга о заканчивающемся месте на диске стоит принимать во внимание watermark. Это настройка Elasticsearch, которая следит за свободным местом на диске, на который Elasticsearch складывает данные. В зависимости от объема оставшегося места разворачивается один из сценариев:
low — при достижении этого показателя на каком-либо из узлов Elasticsearch перестает отправлять новые шарды на этот узел. Настраивается параметром
cluster.routing.allocation.disk.watermark.low, по умолчанию равен 85%. Не распространяется на первичные шарды вновь создаваемых индексов — их будут размещать, а вот их копии — нет;high — при достижении этого показателя на каком-либо из узлов Elasticsearch начинает эвакуировать с нее шарды. Настраивается параметром
cluster.routing.allocation.disk.watermark.high, по умолчанию равен 90%;flood_stage — при достижении этого показателя на каком-либо из узлов Elasticsearch переводит индексы в
read_only_allow_delete. Настраивается параметромcluster.routing.allocation.disk.watermark.flood_stage, по умолчанию равен 95%.
Последний вариант (flood_stage) может быть болезненным, т.к. при read_only_allow_delete удалять индексы можно, но документы из них — нет.
Чаще индексы равномерно распределяются между узлами и ситуация редко доходит до read_only_allow_delete. Подобный сценарий возможен при использовании стандартного шаблона индекса, в котором указывается number_of_shards 1, а индекс выходит крайне большим (например, мы пишем какой-то Java-трейс). Получается, даже если этот большущий шард выгонят с одного узла (стадия high), он переедет на другой и, вероятнее всего, там он тоже не задержится.
Чтобы подобного не случалось, необходимо изначально настроить для подобных индексов шаблон с корректным number_of_shards, чтобы он равномерно распределялся между узлами. (Не стоит также забывать и про number_of_replicas. Если у вас кластер из одного узла, этот параметр необходимо выставить в 0, иначе Elasticsearch не будут зеленым из-за unassigned_shards.)
Менять настройки индекса, создавать шаблоны можно через запросы к Elasticsearch API прямо curl«ом (подробнее см. ниже) или через специальный UI — Cerebro.
При настройке мониторинга хоста, на котором установлен узел Elasticsearch, обязательно стоит учитывать параметры watermark. Также стоит обратить внимание, что значения у параметров watermark можно устанавливать не только в процентах свободного дискового объема, но и в единицах измерения этого самого объема. Это очень полезно, если используются большие диски: ведь не так критично, если у терабайтного диска занято 85% места, для таких случаев можно выставить и значения вроде 150 Гб.
Cheat sheet
Ниже приведен cheat sheet по Elasticsearch API — набор самых распространенных запросов.Подразумевается, что адрес Elasticsearch передается переменной окружения NODE_IP. Объявить ее можно командой:
NODE_IP=$(netstat -tulnp |grep 9200 |awk '{print $4}') && echo $NODE_IP… или просто прописать: NODE_IP="ip_узла_эластика:9200"
Общие запросы
1. Посмотреть версию Elasticsearch:
curl -s -X GET "$NODE_IP"2. Проверить здоровье кластера. Если статус green — все отлично. В противном случае, вероятнее всего, у нас есть unassigned shards:
curl -s -X GET "$NODE_IP/_cluster/health?pretty"3. Проверить здоровье узлов:
curl -s -X GET "$NODE_IP/_nodes/stats?pretty" | head -64. Список узлов, их роли и нагрузка на них:
curl -s -X GET "$NODE_IP/_cat/nodes?v=true"В поле node.role можно увидеть «Поле Чудес» из букв. Расшифровка:
Master eligible node (
m);Data node (
d);Ingest node (
i);Coordinating node only (
-).
5. Статистика по занимаемому месту на узлах и по количеству шардов на них:
curl -s -X GET "$NODE_IP/_cat/allocation?v"6. Посмотреть список плагинов:
curl -s -X GET "$NODE_IP/_cat/plugins?v=true&s=component&h=name,component,version,description"7. Посмотреть настройки кластера, включая дефолтные:
curl -s -X GET "$NODE_IP/_all/_settings?pretty&include_defaults=true"8. Проверить значения watermark:
curl -s -X GET "$NODE_IP/_cluster/settings?pretty&include_defaults=true" | grep watermark -A5или:
curl -s -X GET "$NODE_IP/_cluster/settings?pretty&include_defaults=true" | jq .defaults.cluster.routing.allocation.disk.watermarkИндексы, шарды
1. Посмотреть список индексов:
curl -s -X GET "$NODE_IP/_cat/indices"2. Список индексов, отсортированный по размеру:
curl -s -X GET "$NODE_IP/_cat/indices?pretty&s=store.size"3. Посмотреть настройки индекса:
curl -s -X GET "$NODE_IP/<имя_индекса>/_settings?pretty"4. Снять read-only с индекса:
curl -X PUT "$NODE_IP/<имя_индекса>/_settings?pretty" -H 'Content-Type: application/json' -d'
{
"index": {
"blocks": {
"read_only_allow_delete": "false"
}
}
}'5. Список шардов:
curl -X GET "$NODE_IP/_cat/shards?pretty"6. Посмотреть список unassigned shards:
curl -s -X GET $NODE_IP/_cat/shards?h=index,shard,prirep,state,unassigned.reason| grep UNASSIGNED7. Проверить, почему не размещаются шарды:
curl -s $NODE_IP/_cluster/allocation/explain | jq8. Удалить реплика-шард для индекса:
curl -X PUT "$NODE_IP/<имя_индекса>/_settings" -H 'Content-Type: application/json' -d'
{
"index" : {
"number_of_replicas" : 0
}
}'9. Удалить индекс/шард:
curl -X DELETE $NODE_IP/<имя>Шаблоны
1. Список шаблонов:
curl -s -X GET "$NODE_IP/_cat/templates?pretty"2. Смотреть настройки шаблона:
curl -X GET "$NODE_IP/_index_template/<имя_темплейта>?pretty"3. Пример создания шаблона:
curl -X PUT "$NODE_IP/_index_template/<имя_темплейта>" -H 'Content-Type: application/json' -d'
{
"index_patterns": ["<начало_имени_индекса>-*"],
"template": {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
}
}
}'
4. Удалить шаблон:
curl -X DELETE "$NODE_IP/_index_template/<имя_темплейта>?pretty"Заключение
Logstash выступает посредником в трансфере сообщений. Основная его задача — правильно обработать сообщение (filter) и отправить его дальше (output). Persistent и Dead Letter Queue помогут эффективно решать эти задачи, однако в первом случае мы заплатим за это производительностью, а во втором — столкнемся с сыростью решения.
Elasticsearch — центр нашей системы. Не важно, собирает он логи или задействован в поисковой системе, — в любом случае необходимо следить за его состоянием. Даже в базовой версии X-Pack можно настроить неплохой сбор статистики о индексах и состоянии узлов. Также обязательно стоит обратить внимание на watermark: часто о нем забывают при настройке алертинга.
P.S.
Читайте также в нашем блоге:
