Как мы строили работу с техническими инцидентами на уровне компании
Пока вы маленький старпап, команда легко справляется со всеми ошибками и сбоями сама. Если вы развиваетесь, и делаете это быстро, неизбежно приходит время, когда разработчиков становится больше, компания — крупнее, а проблемы перестают быть локальными и требуют участия смежных команд для их решения. Так и Skyeng прошел путь от маленького стартапа до известной онлайн-школы. Сейчас на платформе десятки тысяч учеников, 40 распределенных команд разработки и сотни сервисов, взаимодействующих друг с другом.
Конечно, в какой-то момент инциденты вышли за пределы наших команд, и мы задумались о едином подходе работы с ними. Ответственным за процесс организации оказался я — Дима Кузнецов, один из юнит-лидов в Skyeng. Так в декабре 2019 года мы создали MVP этого проекта, и к TechLead Conf 2020 получили первые результаты, о чем я и рассказал на конференции. Сегодня я опишу, каким был процесс и что мы получили в результате.

План был очень простым
Мы сформировали рабочую группу и на старте решили сфокусироваться только на серьезных инцидентах, чтобы получить больше эффекта в краткосрочной перспективе.
Сам MVP-процесс описали вот так:
Заводим канал #dev-disaster в Slack для быстрого реагирования на критические инфраструктурные сбои. Например, если сервис недоступен на проде, его разработчик пишет об этом — и дежурный сотрудник инфраструктуры подключается, чтобы помочь исправить проблему. Slack — наш основной инструмент коммуникации, поэтому выделенный канал для таких проблем должен стать отличной точкой старта. Плюс мы будем видеть, сколько обращений было на входе.
Инцидент фиксируется задачей в Jira, а заводить его будет QA. У него будет на это время, пока разработчик с сотрудником инфраструктуры решают проблему. Так мы увидим конверсию в инциденты на выходе: то есть сможем измерить, работает ли процесс и фиксируется ли сбой.
Когда инцидент устранен (и QA убедится в этом), пишем обязательный Postmortem (так как все рассматриваемые сбои у нас критичные). Постмортем пишет тот, у кого больше контекста: это может быть как разработчик, так и сотрудник инфраструктуры.
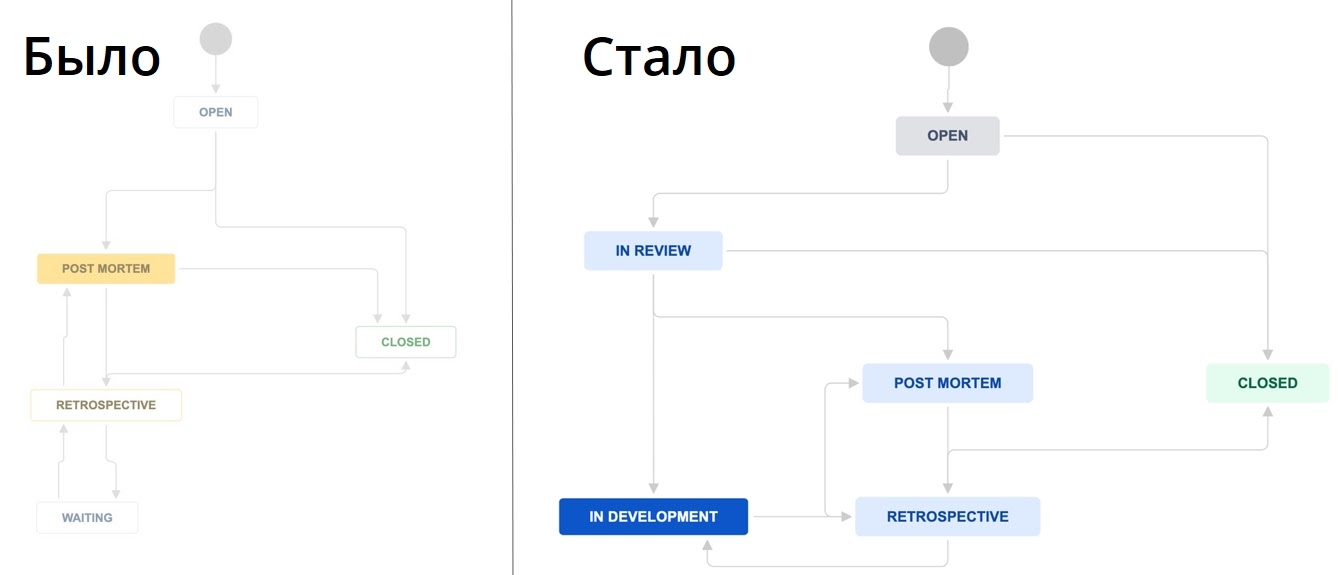
Инциденты за неделю разбирает рабочая группа: два руководителя разработки, руководитель эксплуатации инфраструктуры, руководители DevOps и QA. В первую очередь обращаем внимание на наличие системных проблем — тех, что могут возникать не только у одной команды. В процессе контролируем выполнение action-плана по устранению инцидента. А когда все задачи в составе инцидента выполнены, считаем инцидент проработанным и закрываем его.
Схема процесса получилась такой:
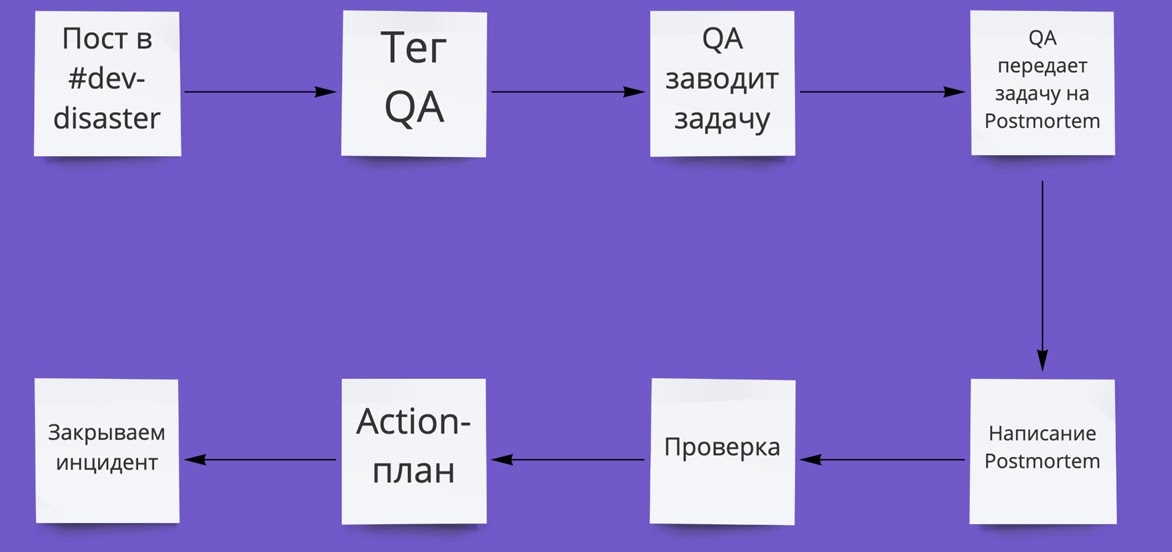
Я оформил этот регламент в Confluence, анонсировал в паре публичных каналов в Slack, и мы стали наблюдать, как все работает на практике.
Картина через месяц
Уже на первом еженедельном разборе мы увидели, что сам еженедельный разбор работает отлично, но фиксируется лишь часть инцидентов. Конверсия зафиксированных сбоев — количество постов из #dev-disaster, для которых были заведены задачи в Jira — была меньше 20%.
Когда я начал разбираться, вскрылось много интересного. У кого-то из команд не были настроены мониторинги и алертинги — из-за чего мы знать не знали про некоторые сбои. Кто-то пропустил анонс из-за информационного шума в мессенджере. У некоторых команд еще не было QA — и они решили, что к ним процесс не относится. Другие почему-то посчитали, что их будут наказывать за сбои, хотя никаких наказаний не подразумевалось. А кто-то не хотел писать постмортем — «заполнять бумажки ваши, ну такое…».
Но чаще всего ребята банально забывали, что нужно сделать. Разработчик забывал тегнуть QA. А тот — завести задачу и правильно ее оформить. Или не понимал, кому нужно передать написание постмортема. Назначенные SLA (3 дня) на написание постмортема не соблюдались, так как ответственные могли забыть про сроки или о том, чтобы перевести задачу в нужный статус.
Я мог бы с этим смириться и просто постоянно напоминать всем про процесс, смену статусов и так далее. Или мог бы делегировать эту задачу в отдел административных ассистентов, где коллеги по регламенту выполняли бы всю рутину: отправляли напоминалки и передвигали задачи. Но от перекладывания решения этой проблемы на других процесс лучше не станет. Поэтому я выбрал другой вариант.
Упрощаем
Наш MVP-процесс, как выяснилось, был непрозрачным, непонятным и неочевидным. Любые изменения внести в него было очень сложно — я и сам почти сразу столкнулся с этим. Недостаточно было просто изменить регламент — нужно было еще вручную отправить кучу уведомлений об этом. И надеяться, что их не только увидят, но запомнят и начнут учитывать.
Поэтому я решил всё это автоматизировать. И для этого нужно было собрать более полную картину происходящего.
Определяем маршруты инцидентов
Я собрал все источники, из которых мы могли узнавать об инцидентах: автотесты, аналитика, мониторинги команд разработки, инфраструктурные мониторинги и, конечно, техподдержка. Составил по каждому источнику схему обнаружения.
Вот, например, схема наших регулярных end-to-end тестов. Они отправляют отчеты о сбоях в отдельные Slack-каналы, где автоматизаторы анализируют отчет и находят места поломок. Если поломка критичная, то уведомление обязательно отправляется командам:

После составления схем стало очевидно, что все маршруты инцидентов упираются в команду разработки. Тогда мы договорились, что разработчик, узнавая о наличии инцидента, решал что лучше:
Если проблема инфраструктурная — писать в канал #dev-disaster и исправлять ее вместе с инфраструктурой;
Или, если это критичная бага на production, выполнить откат и решить проблему вместе с командой.

Определяем, что такое инцидент
По ходу процесса я также обратил внимание, что у ребят возникает непонимание того, что является инцидентом, а что — нет. И это даже без учета серьезности сбоев.
Поэтому мы выделили два типа сбоев:
Блокирующий инцидент — полная недоступность сервиса;
Критический инцидент — влияние на основной бизнес-процесс конкретного сервиса с учетом массовости его использования. Например, когда много пользователей не видят кнопки входа на урок в личном кабинете. Сюда же вошли сбои, которые хоть и не видны клиентам, но нарушают бизнес-процесс сервиса: например, если отвалились консьюмеры или не сработал cron.
В результате мы пришли к следующей схеме:

Тем не менее сами инциденты фиксировались все еще вручную, а я хотел упростить ребятам жизнь.
Упрощаем заведение инцидента
Можно было бы автоматически фиксировать любое сообщение в #dev-disaster как инцидент, но мне показалось, что если так сделать, то коллеги забудут через некоторое время о том, что мы просим фиксировать все виды инцидентов. Поэтому я сделал автоматизацию, которая при публикации поста в #dev-disaster спрашивала, является ли это инцидентом:
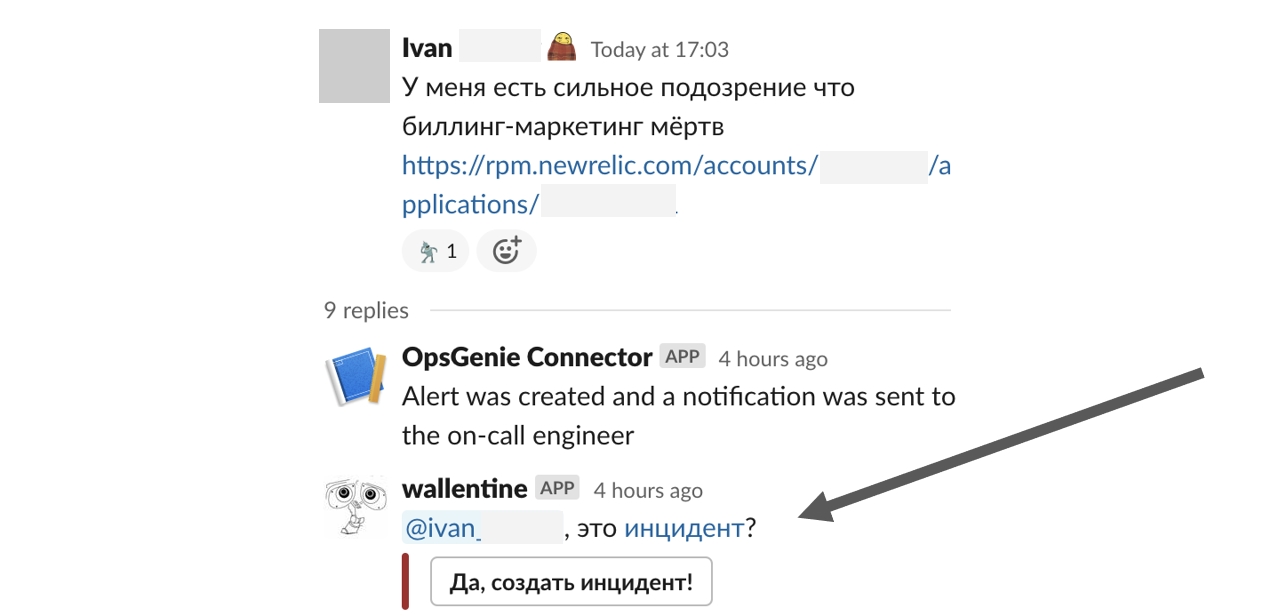
Одновременно это решило проблему того, что не все ребята помнили, где и как заводить задачу. Бот показывал модальное окно, в котором оставалось только дать название инциденту и выбрать его приоритет. Это же модальное окно можно было вызвать абсолютно из любого диалога в любом канале Slack, чтобы создать инцидент из треда:
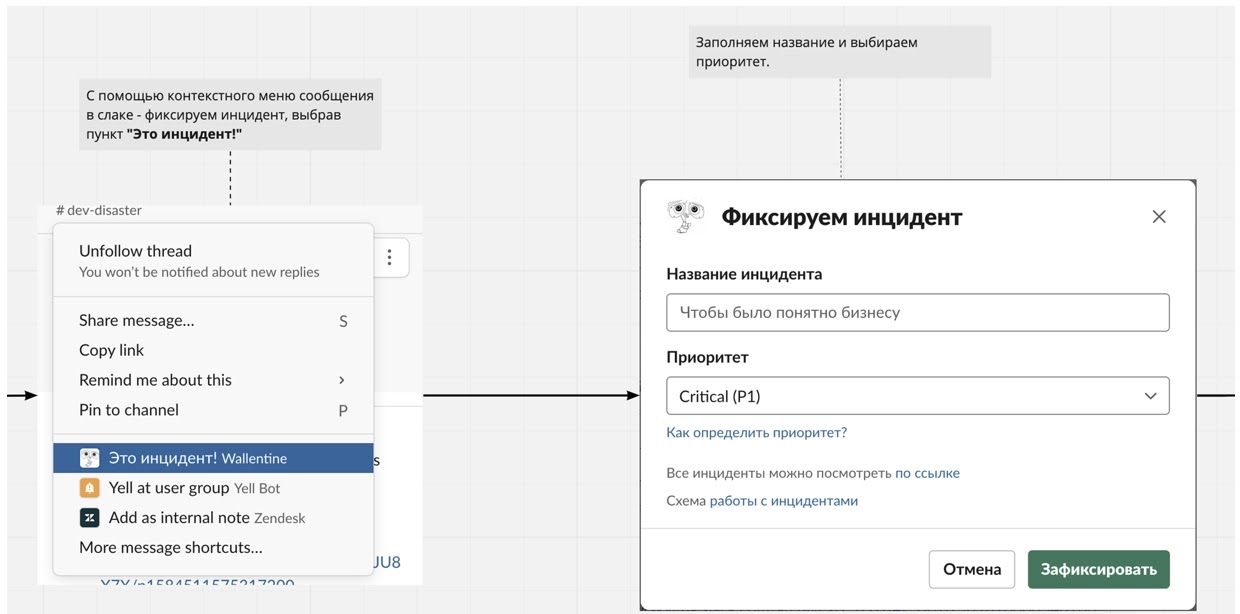 Вот так этот процесс показан теперь в Miro для новых сотрудников
Вот так этот процесс показан теперь в Miro для новых сотрудниковПри нажатии «Зафиксировать» бот автоматически создавал задачу в Jira по шаблону: описаниепроблемы брал из поста в Slack, а в задачу добавлял ссылку на тред, чтобы по нему можно было восстановить всю историю инцидента:
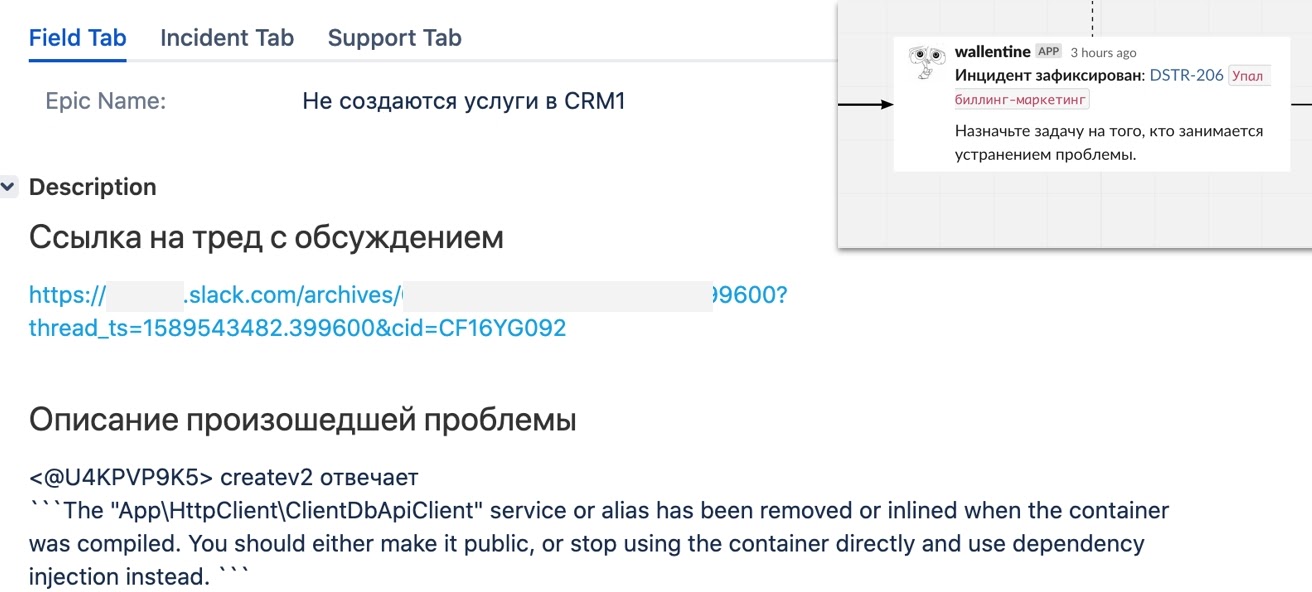
После этого бот сообщал об этом в треде и предлагал назначить ответственного. А сами инциденты мы сделали эпиками, чтобы в них можно было создавать задачи для любых команд на исправление. Если у команды уже был свой эпик, — например, у нашей инфры это эпики, направленные на повышение стабильности — то задача просто линковалась из другого проекта с типом blocked by.
В результате мы могли смотреть статистику и по задачам, созданным от эпиков, и по тем задачам, которые слинкованы с таким типом.
Упрощаем воркфлоу в Jira
Чтобы коллегам легче работалось с инцидентами в Jira, я стал прямо в задачу дописывать краткие инструкции того, что нужно сделать дальше. А наполнение задачи обязательными данными реализовал с помощью перехода и диалогового окна. Это оказалось супер-удобно. Мне теперь не нужно было исправлять регламенты, чтобы изменить процесс. А ребята понимали, что от них ожидается на каждом этапе. Я просто добавлял новое обязательное поле в модельное окно и писал подсказку:
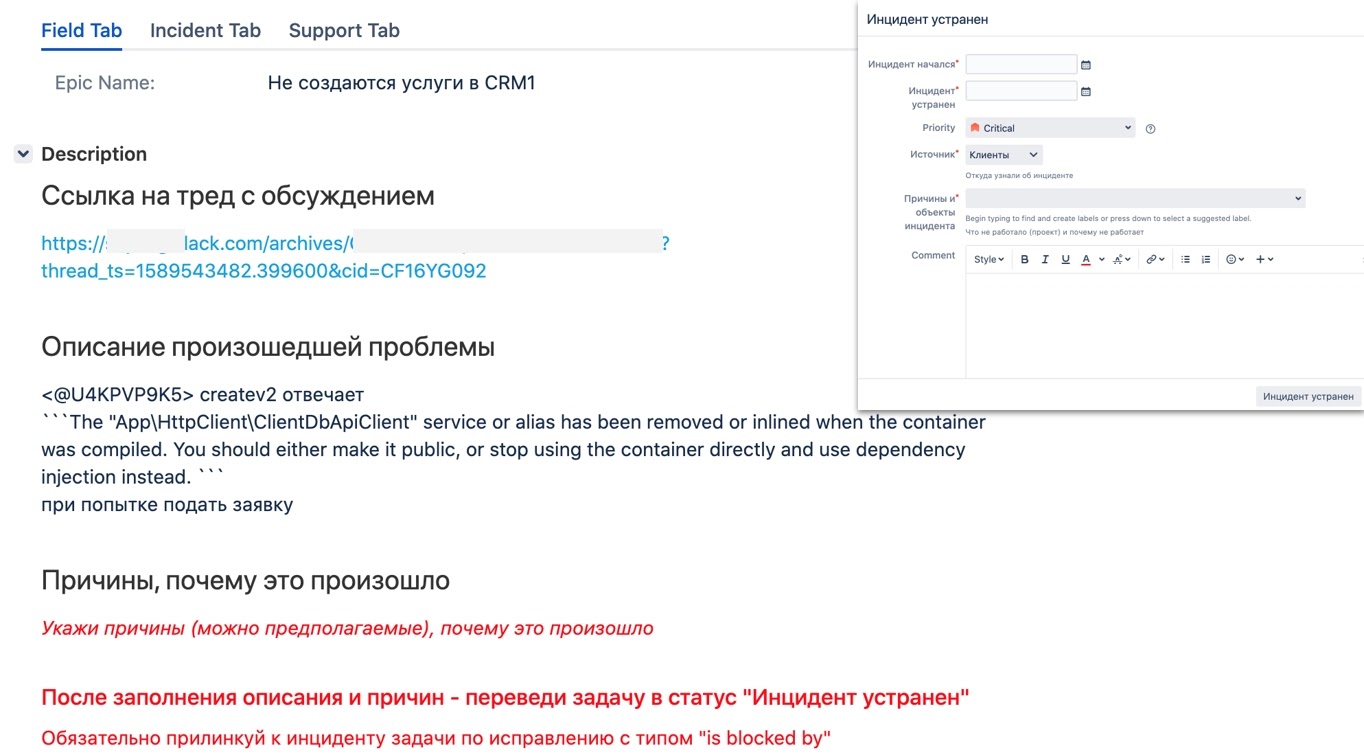
Убираем лишнюю бюрократию: делаем постмортем необязательным
Когда я проанализировал все инциденты, которые были зафиксированы за время работы MVP, то пришел к выводу, что Postmortem был нужен максимум в 30% случаев. Если до этого мы писали Postmortem после того, как инцидент был устранен, теперь, в результате работы бота, задача наполнялась минимально необходимой информацией в процессе создания.
Поэтому мы ввели статус ревью для задачи, где была указана причина сбоя, дата начала и устранения, а также источник. А дальше рабочая группа по инциденту принимала решение — нужно ли здесь писать постмортем (то есть, нужны ли нам подробности). Или по этой задаче и так все понятно — и ее можно переводить в ожидание выполнения action-плана. В результате команды стали делать меньше «бумажной» работы.
Запрашиваем постмортем только когда он нужен
Хотя постмортем и стал опциональным, я решил упростить и его создание. Теперь, чтобы запросить его, кто-то из рабочей группы:
перетаскивал задачу в соответствующий статус,
выбирал, кто будет писать постмортем,
и указывал дату, к которой хотел бы получить результат:

Сразу после этого человеку в личку уходило сообщение о том, что его просят составить постмортем к определенной дате. А в Confluence автоматически создавалась страница с шаблоном и той информацией, которая уже была в задаче:

А чтобы ребята не забывали про то, что от них требуется постмортем, незадолго до срока бот отправлял напоминание в личку. Внутри также была инструкция, что нужно сделать:
 Сейчас напоминание уже изменилось — потому что теперь мы можем менять процесс на ходу
Сейчас напоминание уже изменилось — потому что теперь мы можем менять процесс на ходуЕженедельный дайджест инцидентов
Благодаря автоматизации и упрощению процесса, у нас существенно возросло количество зафиксированных инцидентов и… мы перестали успевать разбирать все на еженедельном созвоне. Для решения этой проблемы мы внедрили новую идею — накануне встречи бот присылает нам емкую выжимку с самой важной информацией, на которую нужно обратить внимание:
 Дайджест содержит все инциденты за неделю и общую статистику, данные о конверсия постов из канала #dev-disaster и зависшие инциденты
Дайджест содержит все инциденты за неделю и общую статистику, данные о конверсия постов из канала #dev-disaster и зависшие инцидентыТакой дайджест упростил нашу подготовку ко встрече. Мы с коллегой созванивались и определяли, какие инциденты считаем важными. Обычно это что-то серьезное, системное, что может повторяться у других команд. Это и становилось повесткой общей встречи. А заодно мы отправляли напоминания, проталкивая зависшие инциденты, если бота кто-то проигнорировал.
Составляем наглядную документацию
Когда я внедрял наш обновленный процесс, то решил не повторять ошибок. Вместо публикации в общий канал я провел встречи с каждым юнитом. Я показывал схемы и рассказывал, для чего это нужно, объясняя, что и от кого требуется. По ходу встреч я ответил на кучу вопросов и получил прекрасную обратную связь.
В итоге собрал всю документацию на доске в Miro, и это помогло нам избавиться от больших текстов в Confluence. Каждый участок процесса я разбил на этапы и для наглядности прикрепил скриншоты:
 Такая подача отлично показывала работу процесса в целом, и закрывала основной блок вопросов
Такая подача отлично показывала работу процесса в целом, и закрывала основной блок вопросовВзаимодействие с техподдержкой
Одним из источников информации о сбоях была техподдержка. Я обратил внимание, что коллеги и так регистрируют массовые обращения, как инциденты, но — в своих внутренних системах, о которых разработка была не в курсе.

Поэтому в процессе нашего проекта мы наладили синхронизацию между разработкой и сотрудниками технической поддержки, заведя канал в слаке #incidents. При регистрации инцидента бот присылал туда уведомление, а сотрудники техподдержки брали ситуацию под контроль и, если требовалось, доносили информацию до пользователей по прогнозам устранения.Этот прямой канал коммуникации с техподдержкой открыл нам неочевидные, на первый взгляд, возможности:
ребята научились сами регистрировать инциденты в случае массовых обращений, тем самым повысив общее количество регистрируемых событий;
сотрудники инфраструктуры получили понятное место, где можно делать анонсы о плановой недоступности.
Результаты
Благодаря автоматизации и выстроенным процессам, каждый месяц мы отслеживаем метрики по количеству инцидентов, среднему времени и сумме потерь (если ее удается посчитать). Инциденты при этом приоритизируются по серьезности и количеству возможных повторений. А в зависимости от проблемы, мы выбираем что будет лучше: быстрое локальное решение или системное, которое требуется раскатить на всю компанию.
А самое главное — мы шаг за шагом исправляем ошибки и улучшаем стабильность нашей системы в целом, сокращая сумму убытков из-за сбоев для бизнеса.
Эти результаты я описывал на TechLead Conf 2020. Но на этом наш процесс не остановился и за год работы видоизменился еще несколько раз. Сейчас у нас появилась команда SRE, тимлид которой курирует весь этот процесс. А наша база основных проблем и сбоев разрослась и структурировалась.
Еще мы столкнулись с тем, что достаточно сложно раскатить необходимые изменения, чтобы предупреждать инциденты. Такие задачи всегда конкурируют с продуктовыми. Поэтому мы придумали прозрачный способ, который уже три квартала подряд показывает хорошие результаты. Мы назвали его фреймворк стабилизации, но это тема для отдельной статьи:
Если вы задумались над внедрением подобного в своей компании:
Определитесь сразу, для чего это вам. Чтобы собирать метрики? Чтобы улучшать вашу систему? Для каких-то других целей?
Выберите ответственного за процесс и будьте готовы к тому, что он потратит на это много времени. Первое время, особенно пока работал MVP-процесс, я тратил 100% своего времени на его поддержку. С внедрением автоматизации стало проще, но инциденты нужно анализировать и разбирать, поэтому сократить свое участие до нуля можно только выйдя из проекта;
Определите метрики: какие хотите снимать и на какие хотите влиять. Это может быть количество инцидентов, время простоя или сумма потерь. Метрики помогут быстро понять, работает процесс или нет;
Очень важно, чтобы у ответственного за процесс было достаточно административного ресурса для изменений. У меня он был. Не уверен, что процесс заработал бы, отвечай за него разработчик, QA или кто-то из тимлидов — у нас очень много команд;
Определите путь инцидентов — как вы о них узнаете, из каких источников. Это поможет собрать общую картину и вы обязательно увидите какие-то точки пересечения;
Упрощайте процесс. Сложный процесс не будет работать. Команды будут его избегать, а вы будете тратить много сил и ресурсов на его поддержание.
Внедряйте процесс в режиме диалога: так вы быстрее сможете получить обратную связь и провести работу над ошибками, а также сходу закрыть кучу возражений. Возражения точно будут — не все будут понимать, для чего это нужно, и что от них требуется;
Держите процесс под контролем. Я выстроил несколько уровней подстраховки, что помогает нам теперь фиксировать 90% инцидентов. Напоминания, контроль со стороны рабочей группы, помощь техподдержки — без этого фиксаций было бы намного меньше.
TechLead Conf 2021 пройдет с 30 июня по 1 июля 2021 в московском отеле Radisson Slavyanskaya. Расписание можно посмотреть здесь. А билеты — здесь.
До встречи на конференции, полностью посвященной инженерным процессам и практикам :)
