[Перевод] Масштабируем кластер Kubernetes до 7500 нод

Фото Carles Rabada, Unsplash.com
Мы заскейлили кластер Kubernetes до 7500 нод, создав масштабируемую архитектуру для крупных моделей, вроде GPT-3, CLIP и DALL·E, и для небольших итеративных исследований, например, законов масштабирования для нейронных моделей языка. Кластер Kubernetes такого размера — редкость, и действовать нужно осторожно, зато мы получили простую инфраструктуру, в которой специалисты по машинному обучению работают быстрее и могут масштабироваться без изменения кода.

С нашего последнего поста о масштабировании до 2500 нод мы продолжали расширять инфраструктуру под требования исследователей. В процессе мы узнали много нового. Возможно, эти знания пригодятся пользователям Kubernetes. В конце мы расскажем об оставшихся проблемах, за которые возьмемся дальше.
Наша рабочая нагрузка
Сначала расскажем о нашей рабочей нагрузке. Оборудование и приложения, с которыми мы используем Kubernetes, могут показаться необычными. Может быть, наши проблемы и их решения вообще вам не подойдут.
Большое задание машинного обучения выполняется на множестве нод. Эффективнее всего, когда у него есть доступ ко всем аппаратным ресурсам на каждой ноде. Таким образом GPU общаются напрямую друг с другом с помощью NVLink либо с сетевой картой при помощи GPUDirect. Так что для многих рабочих нагрузок один под занимает целую ноду. Состязание за ресурсы NUMA, CPU или PCIE не учитывается при планировании. Bin-packing или фрагментация — не частая проблема. В пределах кластера элементы могут общаться друг с другом на полной скорости (full bisection bandwidth), так что мы не учитываем такие факторы, как стойки и топология сети. В итоге, несмотря на большое количество нод, на планировщик ложится относительно небольшая нагрузка.
А вот нагрузка на kube-scheduler очень неравномерная, с резкими пиками. Новое задание может привести к созданию сотен подов одновременно, а потом все снова успокаивается.
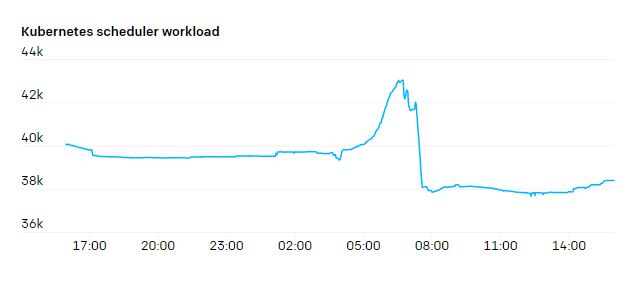
Наши самые большие задания используют MPI, и все поды в задании участвуют в одном MPI-коммуникаторе. Если один из подов умирает, останавливается все задание, и его приходится перезапускать. Задание регулярно создает чекпойнты и возобновляется с последнего из них. Так что поды у нас наполовину stateful — остановленные поды можно заменить, и работа продолжится, но это очень мешает и лучше не злоупотреблять.
Мы не особо полагаемся на балансировку нагрузки в Kubernetes. У нас очень мало HTTPS-трафика, нам не нужно A/B-тестирование, blue/green и canary деплои. Поды общаются друг с другом напрямую по IP-адресу с MPI через SSH, а не через эндпоинты сервиса. Service «discovery» ограничено — мы просто разово смотрим, какие поды участвуют в MPI при запуске задания.
Большинство заданий взаимодействуют с blob-хранилищем. Как правило, они стримят шарды набора данных или чекпойнты напрямую из blob-хранилища или кэшируют их на быстрый локальный эфемерный диск. У нас есть несколько PersistentVolume под семантику POSIX, но blob-хранилище куда проще масштабировать, и не нужно долго ждать присоединения и отсоединения.
Наконец, мы, в основном, занимаемся исследованиями, а значит рабочие нагрузки постоянно меняются. Хотя команда по супервычислениям старается предоставить уровень вычислительной инфраструктуры «продакшен-качества», приложения на кластере существуют недолго, а разработчики выполняют итерации быстро. В любое время могут возникнуть новые шаблоны использования, которые заставят нас пересмотреть наши предположения о трендах и допустимых компромиссах. Нам нужна стабильная система, с которой можно быстро реагировать на изменения.
Сети
Когда на кластерах у нас стало больше нод и подов, мы узнали, что у Flannel есть проблемы с увеличением пропускной способности до нужного уровня. Мы перешли на нативные сетевые технологии подов для конфигураций IP для Azure VMSS и соответствующие плагины CNI. Так нам удалось добиться пропускной способности на подах на уровне хоста.
Еще одна причина перехода на IP-адреса на базе алиасов в том, что на самых больших кластерах у нас могло быть по 200 000 IP-адресов одновременно. Мы тестили соединения на основе маршрутов, но нашли серьезные ограничения по числу маршрутов.
Без инкапсуляции нагрузка на базовый движок маршрутизации или SDN возросла, но зато у нас все очень просто. Добавлять VPN или туннелирование можно без дополнительных адаптеров. Мы не беспокоимся о фрагментации пакетов, потому что у части сети низкий MTU. С сетевыми политиками и мониторингом трафика все просто — источник и место назначения пакетов всегда очевидны.
Мы используем теги iptables на хосте, чтобы отслеживать использование сетевых ресурсов для каждого неймспейса и пода. Таким образом исследователи могут визуализировать паттерны использования сети. Во многих экспериментах мы используем четкие паттерны взаимодействия с интернетом и между подами, так что возможность изучать узкие места очень к месту.
Iptables-правила mangle позволяют произвольно отмечать пакеты, которые соответствуют определенным критериям. Вот какие правила мы используем, чтобы понять, какой трафик идет внутри, а какой — связан с интернетом. Правила FORWARD распространяются на трафик с подов, а INPUT и OUTPUT — на трафик с хоста:
iptables -t mangle -A INPUT ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in"
iptables -t mangle -A FORWARD ! -s 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-in"
iptables -t mangle -A OUTPUT ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out"
iptables -t mangle -A FORWARD ! -d 10.0.0.0/8 -m comment --comment "iptables-exporter openai traffic=internet-out"Когда мы ставим метку, iptables запускает счетчики для числа байтов и пакетов в соответствии с правилом. Эти счетчики можно просмотреть с помощью iptables:
% iptables -t mangle -L -v
Chain FORWARD (policy ACCEPT 50M packets, 334G bytes)
pkts bytes target prot opt in out source destination
....
1253K 555M all -- any any anywhere !10.0.0.0/8 /* iptables-exporter openai traffic=internet-out */
1161K 7937M all -- any any !10.0.0.0/8 anywhere /* iptables-exporter openai traffic=internet-in */Мы используем опенсорс-экспортер Prometheus iptables-exporter, чтобы отправлять данные отслеживания в систему мониторинга. Это простой способ отслеживать пакеты в соответствии с разными условиями.
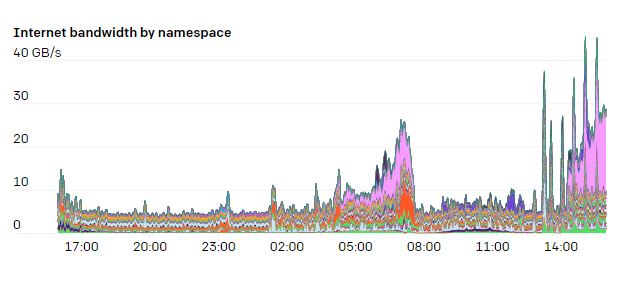
У нашей сетевой модели есть одна уникальная особенность — мы полностью раскрываем CIDR-диапазоны нод, подов и сервисной сети для наших исследователей. Мы используем топологию hub and spoke и нативные CIDR-диапазоны нод и подов для маршрутизации трафика. Исследователи подключаются к хабу, а оттуда получают доступ к отдельным кластерам (лучам звезды). При этом кластеры друг с другом общаться не могут — они изолированы и не имеют общих зависимостей, которые могут помешать локализации сбоя.
Мы используем NAT для преобразования CIDR-диапазона сервисной сети для трафика, поступающего из-за пределов кластера. Благодаря такой схеме исследователи вольны решать, как и какие сетевые конфигурации использовать для экспериментов.
Серверы API
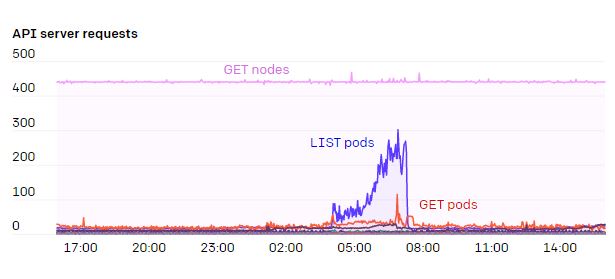
Серверы Kubernetes API и etcd — это критические компоненты здорового кластера, так что мы обращаем особое внимание на нагрузку на эти системы. Мы используем дашборды Grafana от kube-prometheus, а еще собственные дашборды. Нам показалось полезным настроить алерты о количестве ошибок HTTP 429 (слишком много запросов) и 5xx (ошибка сервера) для серверов API.
Некоторые предпочитают запускать серверы API в kube, нам больше нравится делать это за пределами самого кластера. У etcd и серверов API есть собственные ноды. У самых крупных кластеров по пять нод для серверов API и etcd, чтобы распределить нагрузку и свести к минимуму проблемы, если одна из них отвалится. У нас не было особых проблем с etcd с момента переноса событий Kubernetes в отдельный кластер etcd, как мы рассказывали здесь. Серверы API — stateless и обычно их легко запускать в самовостанавливающейся группе экземпляров или масштабируемом наборе. Мы еще не пробовали автоматизировать самовосстановление кластеров etcd, потому что инциденты возникают совсем редко.
Серверы API требуют немало памяти, причем потребление линейно зависит от количества нод в кластере. Для кластера на 7500 нод у нас получается куча до 70 ГБ на каждый сервер API. К счастью, возможностей нашего оборудования хватит еще надолго.

Серьезной проблемой для серверов API были операции WATCH на конечных точках. Есть несколько сервисов, например kubelet и node-exporter, в которые входит каждая нода на кластере. Когда нода добавлялась в кластер или удалялась из него, срабатывал WATCH. А поскольку обычно каждая нода сама следила за сервисом kubelet через kube-proxy, число и трафик в этих ответах составляли N² и целый 1 ГБ/с или даже больше. Благодаря EndpointSlices в Kubernetes 1.17 эту нагрузку удалось сократить в 1000 раз.
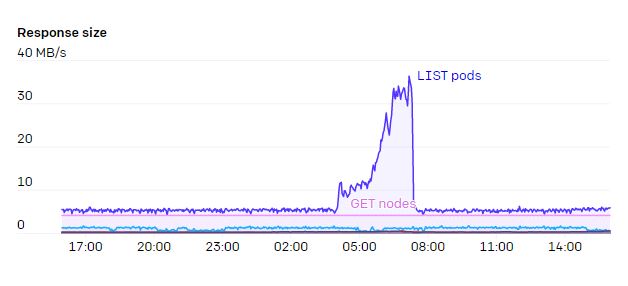
Обычно мы следим за запросами сервера API, которые растут вместе с кластером. Мы не хотим, чтобы DaemonSet взаимодействовал с сервером API. Если вам действительно нужно, чтобы каждая нода следила за изменениями, можно использовать промежуточный сервис кэширования, например Datadog Cluster Agent, чтобы избежать узких мест в кластере.
Чем больше становились кластеры, тем реже мы использовали автомасштабирование. Если автомасштабирования было слишком много, у нас иногда возникали проблемы — при добавлении новой ноды в кластер создавалось слишком много запросов, а если таких нод сразу несколько сотен, на сервер API ложилась непосильная нагрузка. Ускорив этот процесс, пусть даже на несколько секунд, мы смогли избежать перебоев.
Метрики временных рядов в Prometheus и Grafana
Мы используем Prometheus для сбора метрик временных рядов и Grafana для графов, дашбордов и алертов. Мы начали с установки kube-prometheus, который собирает самые разные метрики и создает хорошие дашборды для визуализации. Со временем мы добавили много собственных дашбордов, метрик и алертов.
Когда нод стало очень много, возникли проблемы с объемом метрик, которые собирал Prometheus. kube-prometheus дает много полезных данных, но некоторые из них мы даже никогда не смотрели, а другие были слишком подробными, чтобы можно было эффективно собирать, хранить и запрашивать их. Мы используем правила Prometheus, чтобы пропускать некоторые метрики.
Какое-то время мы пытались решить проблему, при которой Prometheus захватывал все больше и больше памяти, пока контейнер не падал с ошибкой Out-Of-Memory (OOM). Это происходило даже после того, как мы выделили приложению огромное количество памяти. Более того, когда возникал сбой, нам требовались часы, чтобы проиграть файлы write-ahead-log (WAL) и вернуть контейнер в строй.
В итоге мы отследили источник OOM. Им оказалось взаимодействие между Grafana и Prometheus, при котором Grafana использовала API /api/v1/series для Prometheus с запросом {le!=""} (т. е. «дай мне все метрики гистограммы»). У реализации /api/v1/series не было ограничений по времени и пространству — если у запроса было много результатов, требовалось все больше памяти и времени. Причем это продолжалось даже после того, как инициатор запроса закрывал соединение. Памяти никогда не хватало, и Prometheus вылетал. Мы пропатчили Prometheus, чтобы ограничить этот API контекстом и применить таймаут. После этого проблем не возникало.
Хотя Prometheus стал ломаться гораздо реже, когда нам все же приходилось его перезапускать, проигрывание WAL доставляло много проблем. Иногда только через много часов Prometheus снова начинал собирать метрики и обслуживать запросы. Благодаря Robust Perception мы узнали, что здесь спасает GOMAXPROCS=24. Prometheus пытается использовать все ядра при воспроизведении WAL, а если у серверов ядер много, из-за состязания производительность сильно падает.
Мы изучаем новые варианты расширения возможностей мониторинга (см. раздел Нерешенные проблемы).
Проверки работоспособности
Когда кластер настолько большой, выявлять и удалять неисправные ноды нужно автоматически. Со временем мы создали несколько систем проверки работоспособности.
Пассивные проверки работоспособности
Некоторые проверки работоспособности всегда пассивно выполняются на всех нодах. Они отслеживают базовые ресурсы системы, вроде доступности сети, неисправных или заполненных дисков и ошибок GPU. Проблемы с GPU проявляются по-разному, но одна из самых распространенных — неисправимая ошибка ECC. С инструментами Nvidia Data Center GPU Manager (DCGM) гораздо проще делать запросы по таким и другим ошибкам Xid. Для отслеживания таких ошибок мы используем в том числе dcgm-exporter, чтобы отправлять метрики в Prometheus, нашу систему мониторинга. Это метрика DCGM_FI_DEV_XID_ERRORS с самым частым кодом ошибки. Кроме того, NVML Device Query API дает более подробную информацию о работоспособности и работе GPU.
Обнаруженную ошибку часто можно исправить перезапуском GPU или системы, хотя иногда приходится физически заменять GPU.
Еще одна форма проверки работоспособности отслеживает события обслуживания от облачного провайдера. Все крупные облачные провайдеры сообщают о предстоящем обслуживании виртуальной машины, которое приведет к перерыву в работе. Например, нужно перезапустить виртуальную машину, чтобы установить патч для гипервизора или перенести физическую ноду на другое оборудование.
Пассивные проверки работоспособности непрерывно выполняются в фоновом режиме на всех нодах. Если проверка работоспособности сбоит, для ноды автоматически делается cordon, чтобы на ней нельзя было планировать новые поды. Если происходит более серьезный сбой проверки работоспособности, мы вытесняем поды, чтобы они сразу завершили работу. Под сам решает, разрешить это вытеснение или нет (настраивается через Pod Disruption Budget). В конце концов, после завершения всех подов или через 7 дней (как указано у нас в SLA) мы принудительно завершаем виртуальную машину.
Активные тесты GPU
К сожалению, не все проблемы с GPU отображаются как ошибки в DCGM. Мы создали собственную библиотеку тестов, чтобы отлавливать другие проблемы с GPU и гарантировать ожидаемое поведение оборудования и драйвера. Эти тесты нельзя выполнять в фоновом режиме — они занимают весь GPU на несколько секунд или минут.
Мы тестим ноды при загрузке по модели preflight. Все ноды присоединяются к кластеру с taint и меткой preflight, чтобы на них нельзя было планировать обычные поды. DaemonSet настроен на запуск тестовых preflight-подов на всех нодах с этой меткой. После успешного завершения тест сам удаляет taint, и нода доступна для обычного использования.
Время от времени мы выполняем эти тесты на протяжении жизненного цикла ноды, запуская CronJob для любой доступной ноды на кластере. Это, конечно, рандомный и неконтролируемый подход, но мы убедились, что он дает достаточное покрытие с минимальными перерывами и координацией.
Использование квот и ресурсов
По мере увеличения масштаба кластеров исследователи заметили, что им сложно пользоваться емкостью, которую мы им выделили. В традиционных системах планирования заданий есть много разных функций для справедливого разделения ресурсов между командами, но в Kubernetes таких функций нет. Вдохновляясь этими системами, мы разработали несколько аналогичных возможностей для Kubernetes.
Taint для команд
В каждом кластере у нас есть сервис team-resource-manager с несколькими функциями. Он берет данные из ConfigMap, где указан селектор нод, метка команды и объем выделенных ресурсов для всех команд, использующих этот кластер. Он сверяет эти значения с текущими нодами в кластере, помечая нужное число нод с помощью taint openai.com/team=teamname:NoSchedule.
team-resource-manager содержит сервис вебхука допуска (admission webhook service), так что при отправке каждого задания применяется toleration в зависимости от членства в команде. Использование taint позволяет гибко ограничивать планировщик подов Kubernetes, например toleration для подов с низким приоритетом разрешает командам одалживать друг у друга емкость без масштабной координации.
Baloon для CPU и GPU
Мы используем автомасштабирование кластера, чтобы не только динамически масштабировать кластеры на базе виртуальных машин, но и исправлять (удалять и снова добавлять) нездоровые члены кластера. Для этого мы задаем для минимального размера кластера 0, а для максимального — доступную емкость. Если сервис автомасштабирования видит простаивающие ноды, он пытается сократить масштаб до необходимой емкости. Это не идеальный вариант по многим причинам — задержка при запуске виртуальной машины, затраты на предварительное выделение ресурсов и влияние на сервер API, о котором мы говорили раньше.
В результате мы решили развернуть balloon-деплой для хостов только с CPU и с GPU, куда входит ReplicaSet с максимальным размером для подов с низким приоритетом. Эти поды занимают ресурсы на ноде, так что автомасштабирование не считает, что они простаивают. При этом они имеют низкий приоритет, так что планировщик может выселить их сразу, чтобы освободить место для настоящей работы. (Мы решили использовать Deployment вместо DaemonSet, чтобы DaemonSet не считался простаивающей рабочей нагрузкой на ноде.)
Кстати, мы используем для подов anti-affinity, чтобы они равномерно распределялись по нодам. В ранних версиях у планировщика Kubernetes возникала проблема производительности O (N²) из-за anti-affinity. Начиная с Kubernetes 1.18 проблема исправлена.
Gang scheduling — параллельное планирование
В экспериментах мы часто используем один или несколько StatefulSet, причем каждый работает в отдельной части проекта машинного обучения. Для оптимизаторов исследователям нужно, чтобы все члены StatefulSet были запланированы до начала обучения (потому что мы часто используем MPI для координации членов оптимизаторов, а MPI чувствителен к изменениям членства в группе).
По умолчанию Kubernetes не обязательно назначает приоритет для запросов от того или иного StatefulSet. Например, если два эксперимента запросили 100% емкости кластера, Kubernetes не планирует один из экспериментов полностью, а, допустим, берет по половине подов каждого эксперимента, что приводит к дедлоку и остановке обоих экспериментов.
Мы поэкспериментировали с кастомным планировщиком, но столкнулись с пограничными случаями, которые приводили к конфликтам с планированием обычных подов. В Kubernetes 1.18 появилась архитектура плагинов для основного планировщика Kubernetes, благодаря чему нативно добавлять такие фичи стало куда проще. Недавно мы остановились на плагине Coscheduling.
Нерешенные проблемы
Мы решили еще не все проблемы с увеличением масштаба кластеров Kubernetes. Например:
Метрики
При нашем масштабе у нас возникает немало трудностей со встроенной СУБД для хранения временных рядов в Prometheus — сжатие происходит очень медленно, а для воспроизведения WAL при каждом перезапуске требуется очень много времени. Запросы часто приводят к ошибкам «query processing would load too many samples» — при обработке запроса будет загружено слишком много сэмплов. Сейчас мы переходим на другое хранилище и движок запросов, совместимые с Prometheus.
Шейпинг трафика для подов
В наших растущих кластерах для каждого пода рассчитывается определенная пропускная способность интернет-соединения. В итоге совокупная пропускная способность на человека сильно выросла, и теперь наши исследователи могут случайно вызвать нехватку ресурсов в других местах, например для загрузки наборов данных и установки пакетов программного обеспечения.
Заключение
Мы считаем, что гибкая платформа Kubernetes отлично подходит для наших исследовательских задач. Ее масштаб можно увеличить для самых требовательных рабочих нагрузок. Пока, конечно, не все еще идеально, так что команда по супервычислениям в OpenAI продолжает изучать возможности масштабирования в Kubernetes.
