Типовое внедрение мониторинга. Николай Сивко
Расшифровка доклада «Типовое внедрение мониторинга» Николая Сивко.
Меня зовут Николай Сивко. Я тоже делаю мониторинг. Okmeter это 5 мониторинг, который я делаю. Я решил что я спасу всех людей от ада мониторинга и мы избавим кого-то от этих страданий. Я всегда в своих презентациях стараюсь не рекламировать окметер. Естественно картинки будут оттуда. Но идея того, что я хочу рассказать заключается в том что мы делаем мониторинг несколько другим подходом, чем все делают обычно. Мы очень много об этом рассказываем. Когда мы каждого конкретного человека пытаемся в этом убедить, в итоге он убеждается. Я хочу рассказать о нашем подходе именно для того чтобы, если вы будете делать мониторинг сами, чтобы вы избежали наших граблей.

Про окметер вкратце. Мы делаем то же самое что и вы, но есть всякие фишки. Фишки:
- детализация;
- большое количество преднастроенных триггеров, которые основаны на проблемах наших клиентов;
- автоконфигурация;

Типичный клиент приходит к нам. У него есть две задачи:
1) понимать что все сломалось из мониторинга, когда вообще ничего нет.
2) быстро чинить это.
Он приходит в мониторинг за ответами что у него происходит.
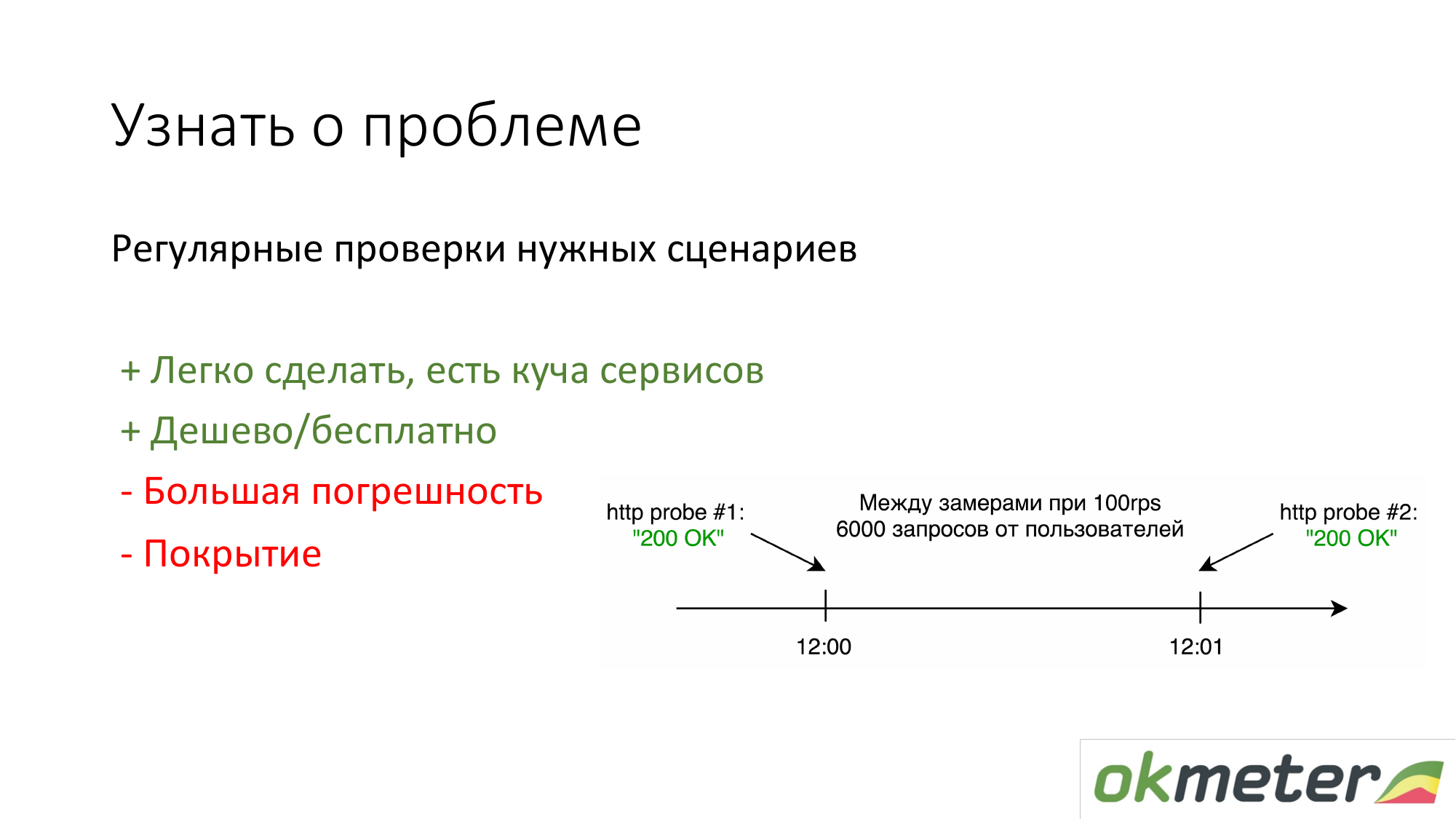
Первое что делают люди, у которых ничего нет — ставят https://www.pingdom.com/ и другие сервисы для проверки. Плюс этого решения в том, что это можно сделать за 5 минут. Вы уже не от звонков клиентов узнаете о проблеме. Там есть проблемы точностью, с тем что они пропускают проблемы. Но для простых сайтов это достаточно.

Второе что мы пропагандируем — считать по логам по статистику реальных пользователей. То есть сколько конкретный пользователь получает ошибок 5хх. Сколько время ответа по пользователям. Есть свои минусы, но в целом такая штука работает.

Про nginx: мы сделали так что любой клиент, который приходит, сразу ставит агент на фронтэнд и у него сразу все автоматом подхватывается, начинает парсится, начинают показываться ошибки и так далее. Ему почти ничего не надо настраивать.

Но у большинства клиентов нет в логах таймеров в стандартном nginx. Это 90 процентов клиентов не хотят знать время ответа их сайта. Мы с этим все время сталкиваемся. Надо лог nginx расширять. Тогда из коробки автоматом мы начинаем показывать еще и гистограммы. Это наверное важный аспект того что время надо мерить.

Что мы оттуда выдергиваем? На практике мы снимаем метрики в таких размерностях. Это не плоские метрики. Метрика называется index.request.rate — количество запросов в секунду. Она детализировано по:
- хосту, с которого вы сняли логи;
- логу, с которого эти данные снялись;
- http по методу;
- http статусу;
- cache статусу.
Это НЕ каждый конкретный URL со всеми аргументами. Мы не хотим снимать из лога 100000 метрик.

Мы хотим снять 1000 метрик. Поэтому мы пытаемся URL нормализовать, если это возможно. Берем топ URL. А для URL, которые значимы, мы показываем отдельную гистограмму, отдельно 5хх.

Вот пример того как эта простая метрика превращается в юзабельные графики. Это наш DSL сверху. Я пытался этим DSL объяснить примерную логику. Мы взяли все nginx request в секунду и разложили их по всем машинам, которые у нас есть. Получили знание о том как у нас это балансируется, сколько у нас суммарно RPS (request per second, запросов в секунду).

С другой стороны, мы можем эту метрику отфильтровать и показать только 4хх. На графике 4хх могут быть разложены по статусу, который настоящий. Напоминаю это та же самая метрика.

На графике можно показать 4хх с разбивкой по URL. Это одна и та же метрика.

Еще мы снимаем из логов гистограму. Гистограма это метрика response_time.histrogram, которая на самом деле RPS c дополнительным параметром level. Это как раз отсечка времени в какой bucket попадает запрос.
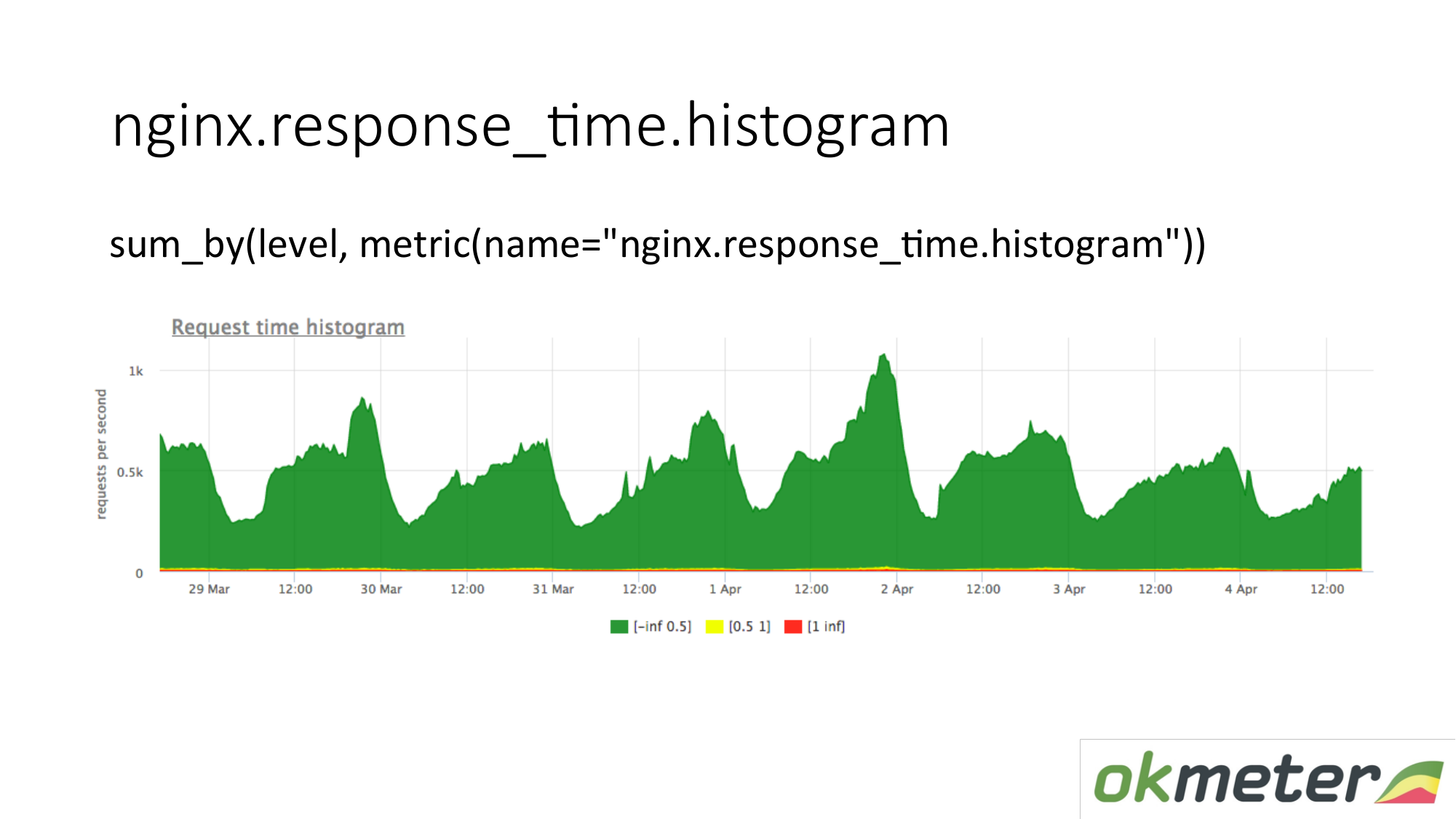
Мы рисуем запрос: просуммируем всю гистограмму и разложи по уровням:
- медленные запросы;
- быстрые запросы;
- средние запросы;
Мы имеем картинку, которая уже просуммирована по серверам. Метрика одна и та же. Ее физический смысл понятен. Но пользу извлекаем из нее совершенно по-разному.
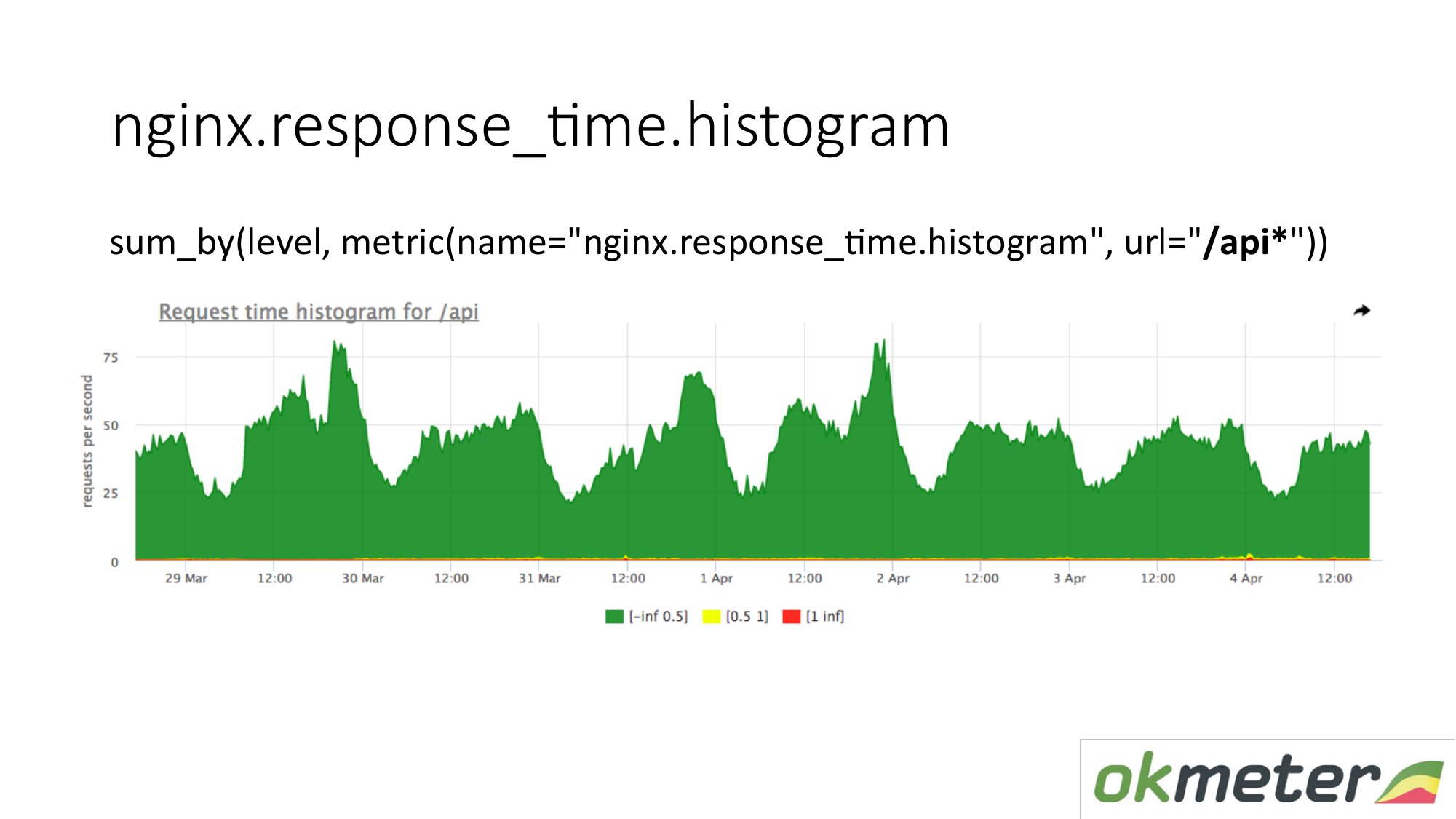
На графике можно показать гистограмму только по URL, начинающимся с »/api». Таким образом мы смотрим гистограмму отдельно. Мы смотрим сколько в этот момент. Мы видим сколько в URL »/api» было RPS. Та же метрика, но другое применение.

Пара слов про тайминги в nginx. Есть request_time, который включает себя время от начала запроса и до передачи последнего байта в сокет клиенту. А есть upstream_response_time. Их нужно мерить обе. Если просто снимаем request_time, то там вы увидите задержки из-за проблем связанности клиента с вашим сервером, вы увидите там задержки, если у нас у вас настроен limit request c burst и клиент в бане. Вы не будете понимать нужно сервер чинить или хостеру звонить. Соответственно снимаем обе и примерно понятно чего происходит.

С задачей понимать работает сайт или нет, я считаю что мы более менее разобрались. Там есть погрешности. Там есть неточности. Общие принципы такие.
Теперь про мониторинг многозвенной архитектуры. Потому что даже самый простой интернет магазин имеет как минимум frontend, за ним битрикс и базу. Это уже много звеньев. Общий смысл в том, что нужно снимать какие-то показатели с каждого уровня. То есть пользователь думает про frontend. Frontend думает про backend. Backend думает про соседние backend. И все они думают про базу. Вот так по слоям, по зависимостям и пробегаемся. Покрываем все какими-то метриками. Получаем что-то на выходе.

Почему нельзя ограничиться одним слоем? Как правило между слоями находится сеть. Большая сеть под нагрузкой крайне нестабильная субстанция. Поэтому там бывает всякое. Плюс могут врать те замеры, которые вы делаете на каком слое. Если вы делаете замеры на слое «А» и слое «Б», и если они между собой взаимодействуют через сеть, то вы можете сравнивать их показания, находить какие-то аномалии и нестыковки.

Про backend. Мы хотим понимать как backend мониторить. Что с ним делать чтоб понимать быстро что происходит. Напоминаю что мы уже перешли к задаче минимизации downtime. А про backend мы стандартно предлагаем понимать:
- Сколько это поедает ресурсов?
- Не уперлись ли мы в какой-нибудь лимит?
- Что у нас происходит с runtime? Например, платформа JVM runtime, Golang runtime и другие runtime.
- Когда мы уже все это покрыли нам интересно уже ближе к своему коду. Мы можем либо воспользоваться автоматическими интруметрарием (statsd, *-metric), которые нам все это покажут. Либо заинструментировать сами, расставив таймеры, счетчики и т.д.
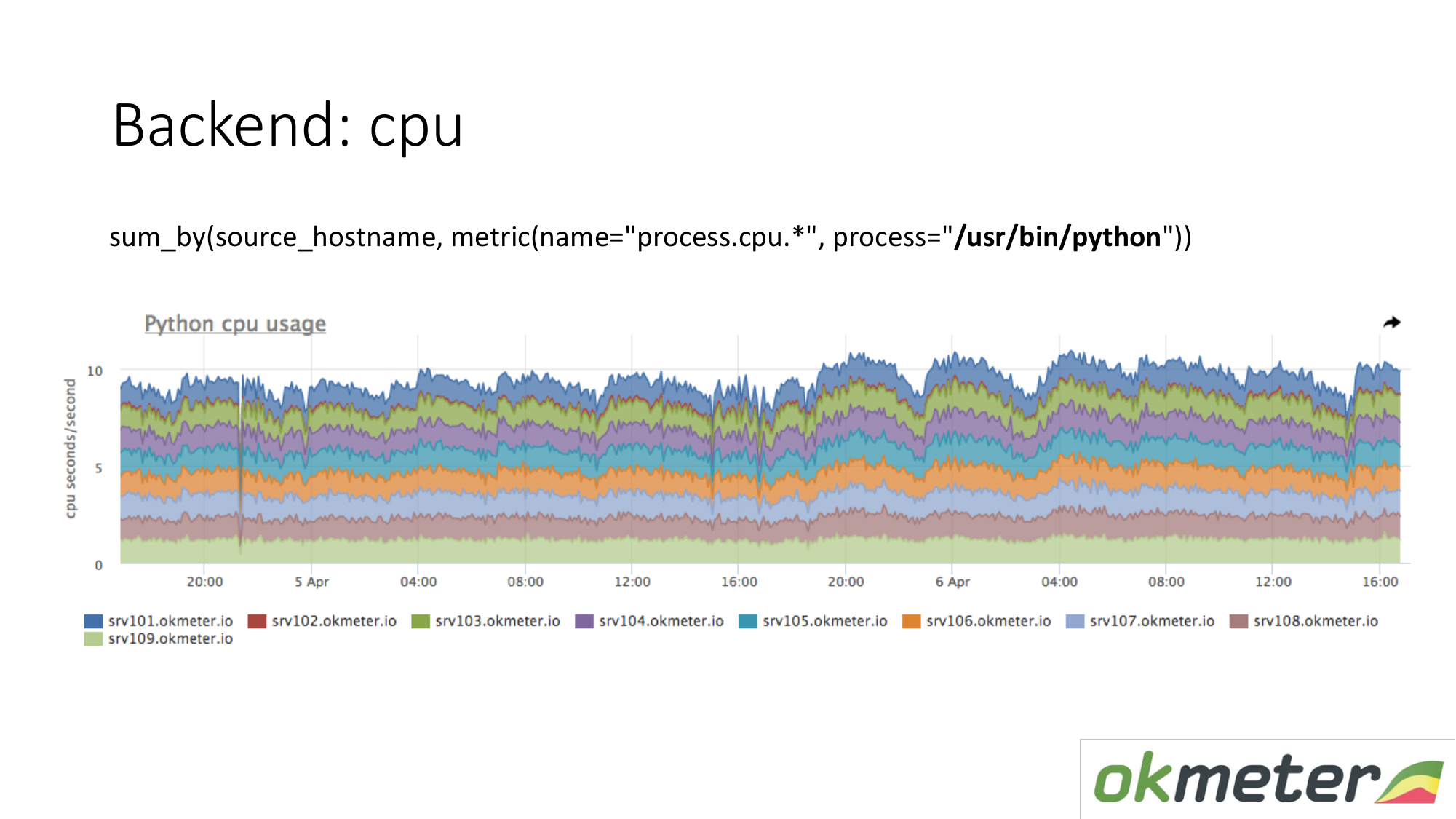
Про ресурсы. У нас стандартный агент снимает потребление ресурсов всеми процессами. Поэтому для backend нам не надо отдельно снимать данные. Мы берем и смотрим сколько потребляет CPU процесс, например Python на серверах по маске. Мы показываем на одном графике все сервера в кластере, потому что мы хотим понять нет ли у нас разбалансировки и не взорвалось ли что-то на одной машине. Мы видим суммарное потребление от вчера к сегодня.
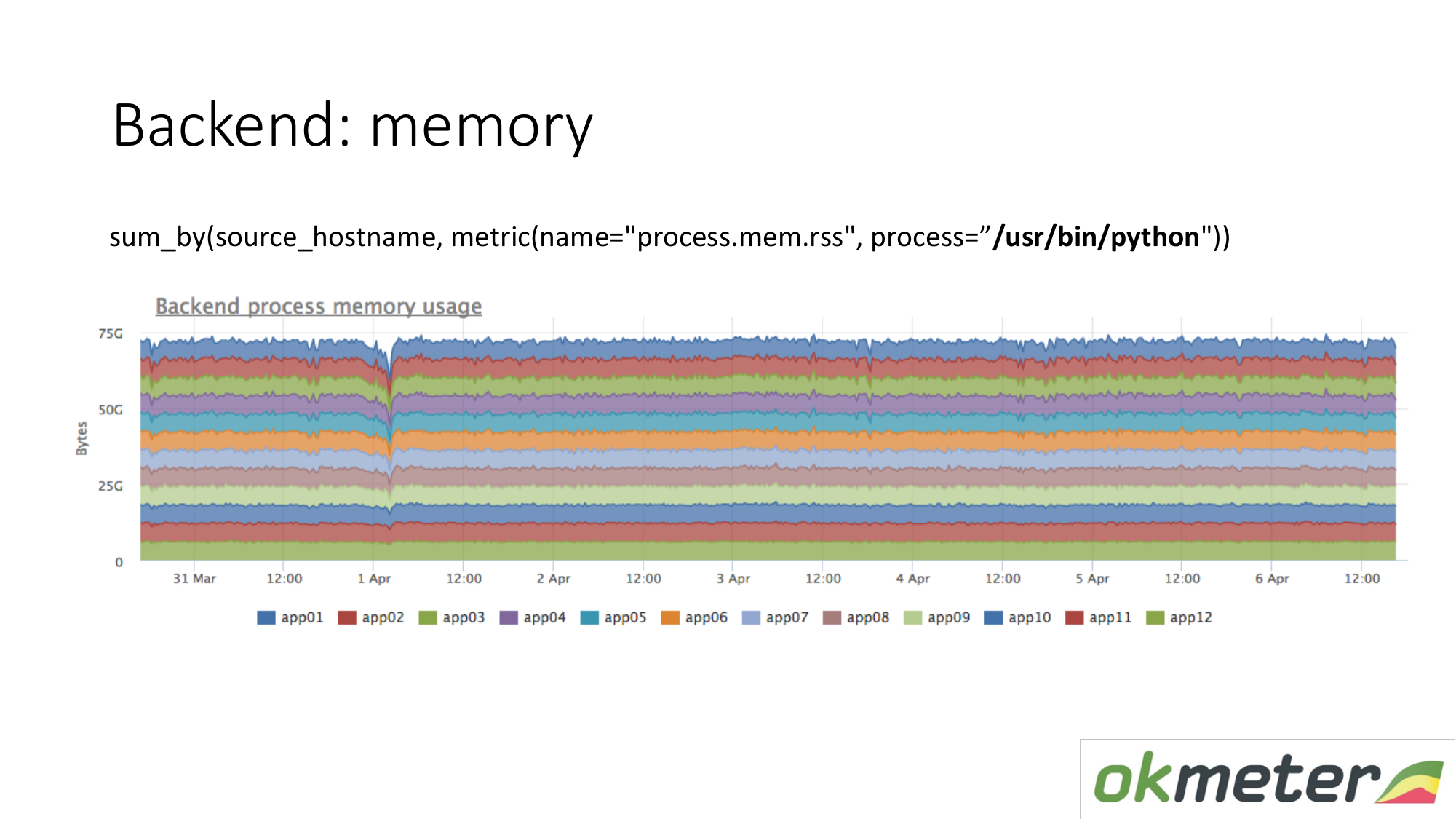
То же самое про память. Когда мы рисуем это в таком виде. Мы выбираем Python RSS (RSS — размер страниц памяти, выделенных процессу операционной системой и в настоящее время находящихся в ОЗУ). Cуммируем по хостам. Cмотрим нигде не течет память. Везде память распределена равномерно. В принципе на свои вопросы мы ответ получили.
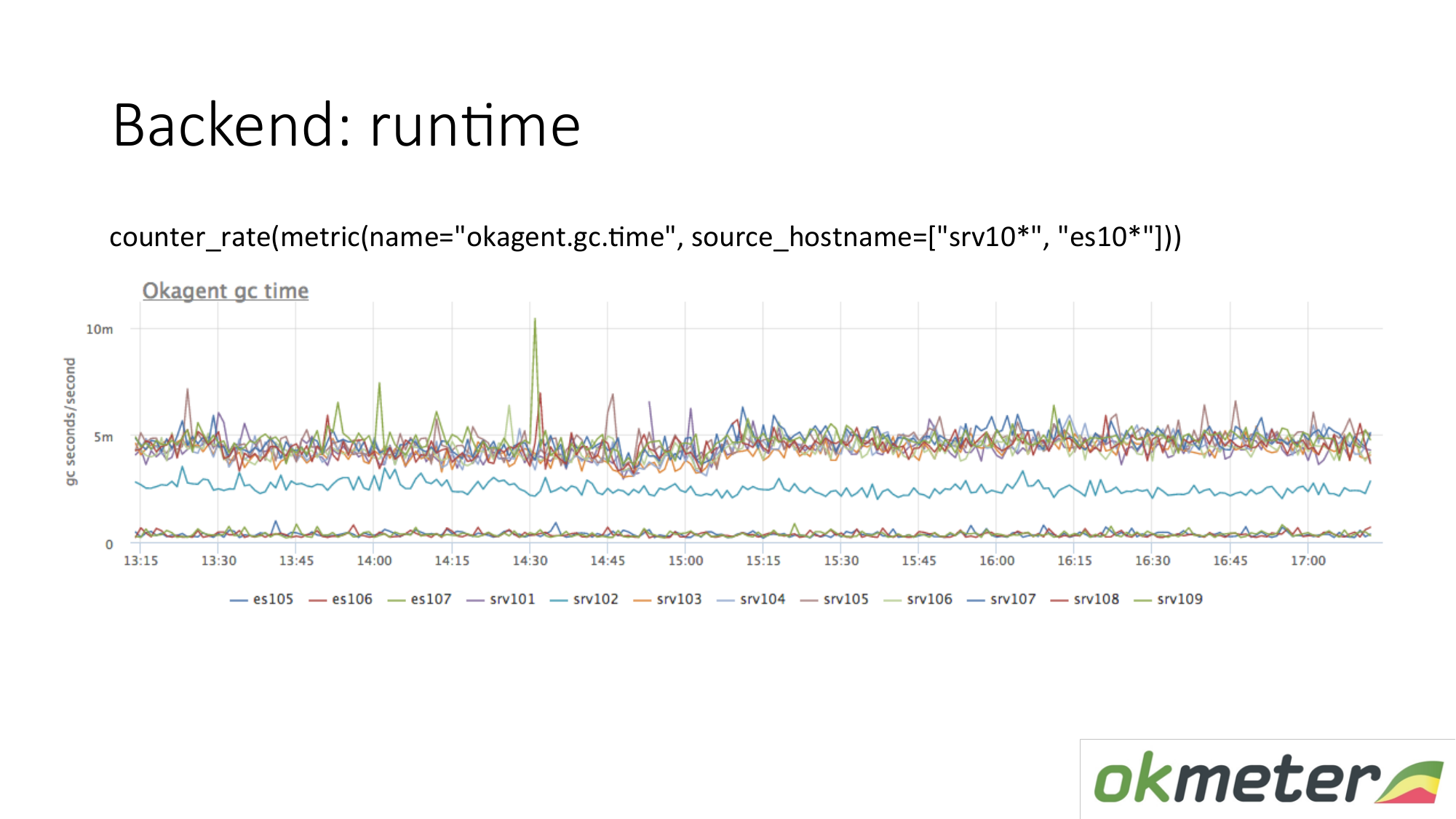
Пример runtime. Наш агент написан на Golang. Golang агент присылает про себя метрики своего runtime. Это в частности количество секунд потраченных Golang garbage коллектором на сборку мусора в секунду. Мы здесь видим что у одних серверов метрики отличаются от других серверов. Увидели аномалию. Пытаемся это объяснить.
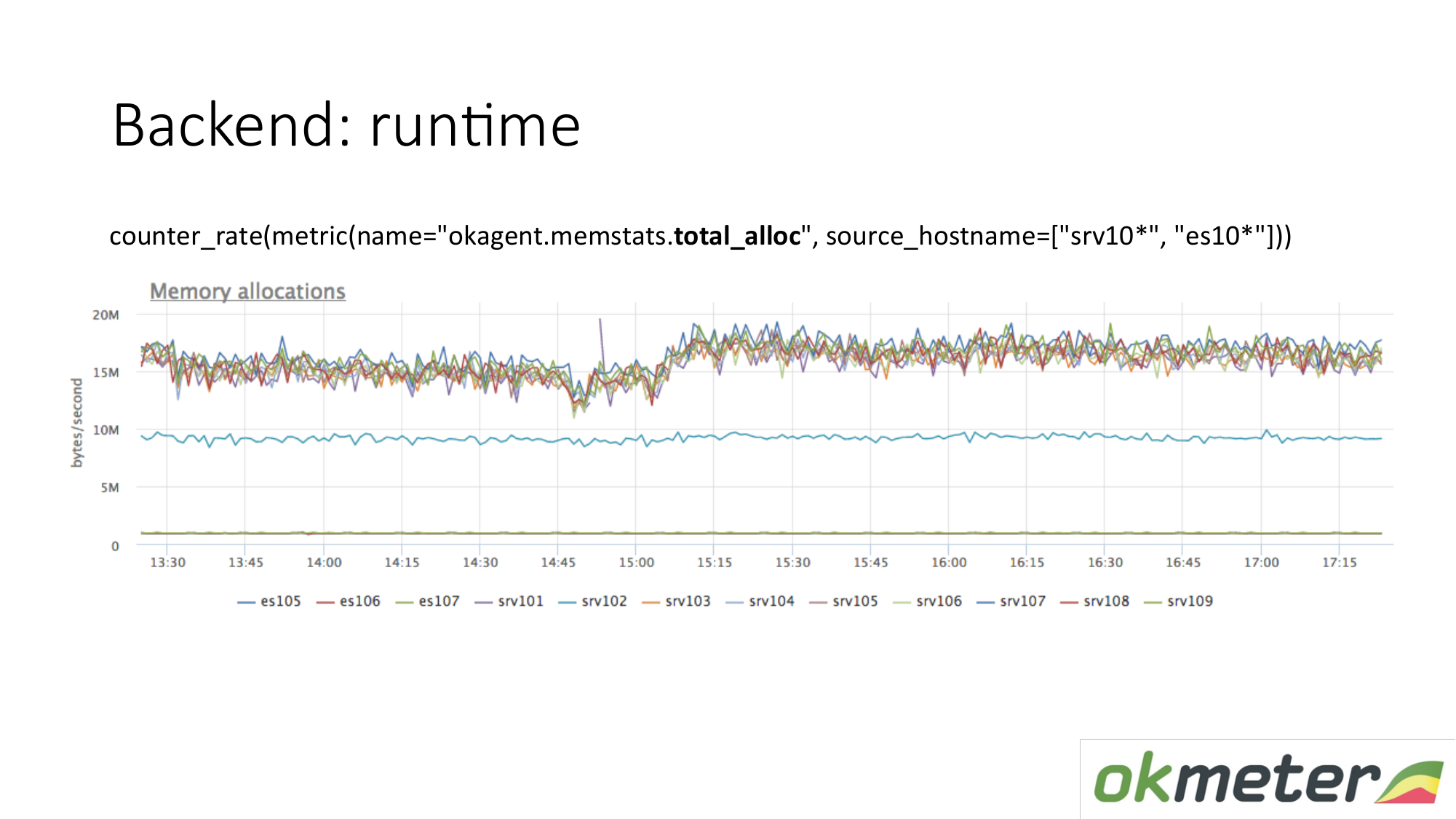
Есть другая метрика runtime. Сколько памяти аллоцируется в единицу времени. Видим что агенты с типом, которые верху, аллоцируют больше памяти, чем агенты которые внижу. Внизу агенты с менее агрессивным Garbage Collector. Это логично. Чем больше памяти через вас проходит, аллоцируется, освобождается, тем больше нагрузка на Garbage Collector. Дальше мы по своим внутренним метрикам понимаем почему мы столько памяти хотим на тех машинах и меньше на этих машинах.
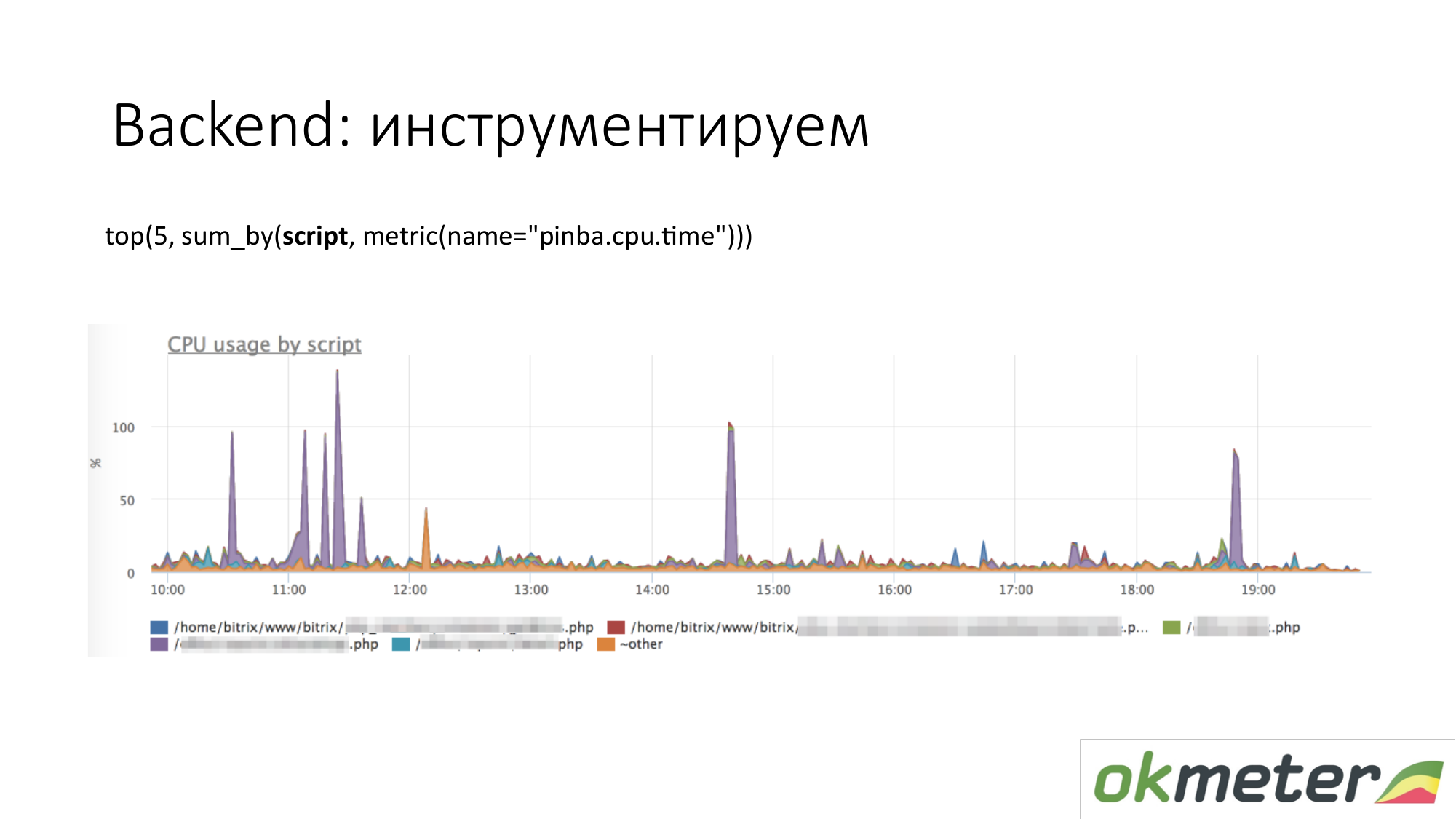
Когда мы говорим про инструментирование, то приходят всякие инструменты вроде http://pinba.org/ для php. Pinba это extension для php от компании Badoo, который вы ставите и подключаете к php. Он вам позволяет сразу снимать и отправлять по протоколу UDP protobuf. У них есть Pinba-сервер. Но мы сделали встроенный Pinba-сервер в агенте. PHP про себя отправляет сколько она потратила CPU и памяти на такие-то скрипты, сколько трафика отдано такими скриптами и так далее. Здесь пример с Pinba. Мы показываем топ-5 скриптов по потреблению CPU. Мы видим фиолетовый выброс это замазанная точка PHP. Идем чинить замазанную точку PHP или разбираться почему она съедает CPU. Мы уже сузили область проблемы настолько, что мы понимаем следующие шаги. Мы идем смотреть код и чиним.

То же самое про трафик. Мы смотрим топ-5 скриптов по трафику. Если для нас это важно, то мы идем и разбираемся.

Это график про наши внутренние инструменты. Когда мы через statsd ставили таймер и измеряли метрики. Мы сделали так что количество суммарно проведенного времени в CPU или в ожидании какого-то ресурса раскладывается по хендлеру, который мы сейчас обрабатываем, и по важным стадиям вашего кода: ждали кассандру, ждали elasticsearch. На графике можно показать топ-5 стадий по хендлеру /metric/query. На графике можно показать топ-5 хендлеров по потреблению CPU, так и что там внутри происходит. Понятно что чинить.
Про backend можно дальше углубляться. Есть штуки, которые делают tracing. То есть вы можете видеть вот этот конкретный запрос пользователя с cookie такой-то и IP таким-то породил столько-то запросов в базу, они ждали столько то времени. Мы tracing не умеем. Мы tracing не делаем. Мы умеем по-прежнему считаем что applications and performance monitoring мы не делаем.

Про базу данных. То же самое. Базы данных то же процесс. Он потребляет ресурсы. Если база очень чувствительна к latency, то там немножко другие особенности. Мы предлагаем проверять что ресурсов не стало меньше, деградации по ресурсам нет. Идеально понимать, что если база стала потреблять больше чем потребляла, то понять что конкретно в вашем коде изменилось.
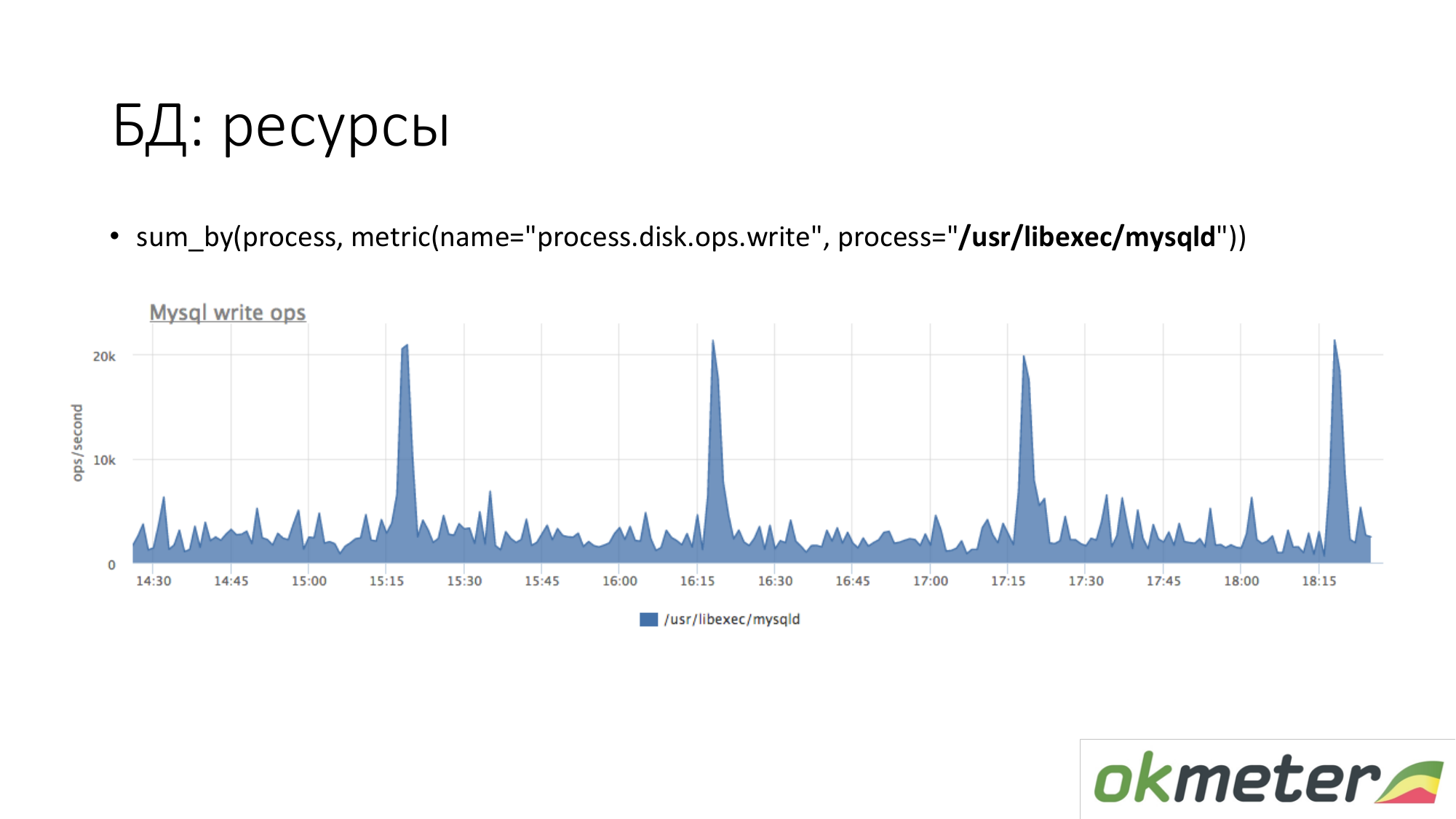
Про ресурсы. Точно так же смотрим сколько процесс MySQL порождает у нас операции записи на диск. Видим что в среднем столько то, но случается какие-то пики. Например, приходит туда много insert и он начинает писать на диск в 15.15, 16.15, 17.15.
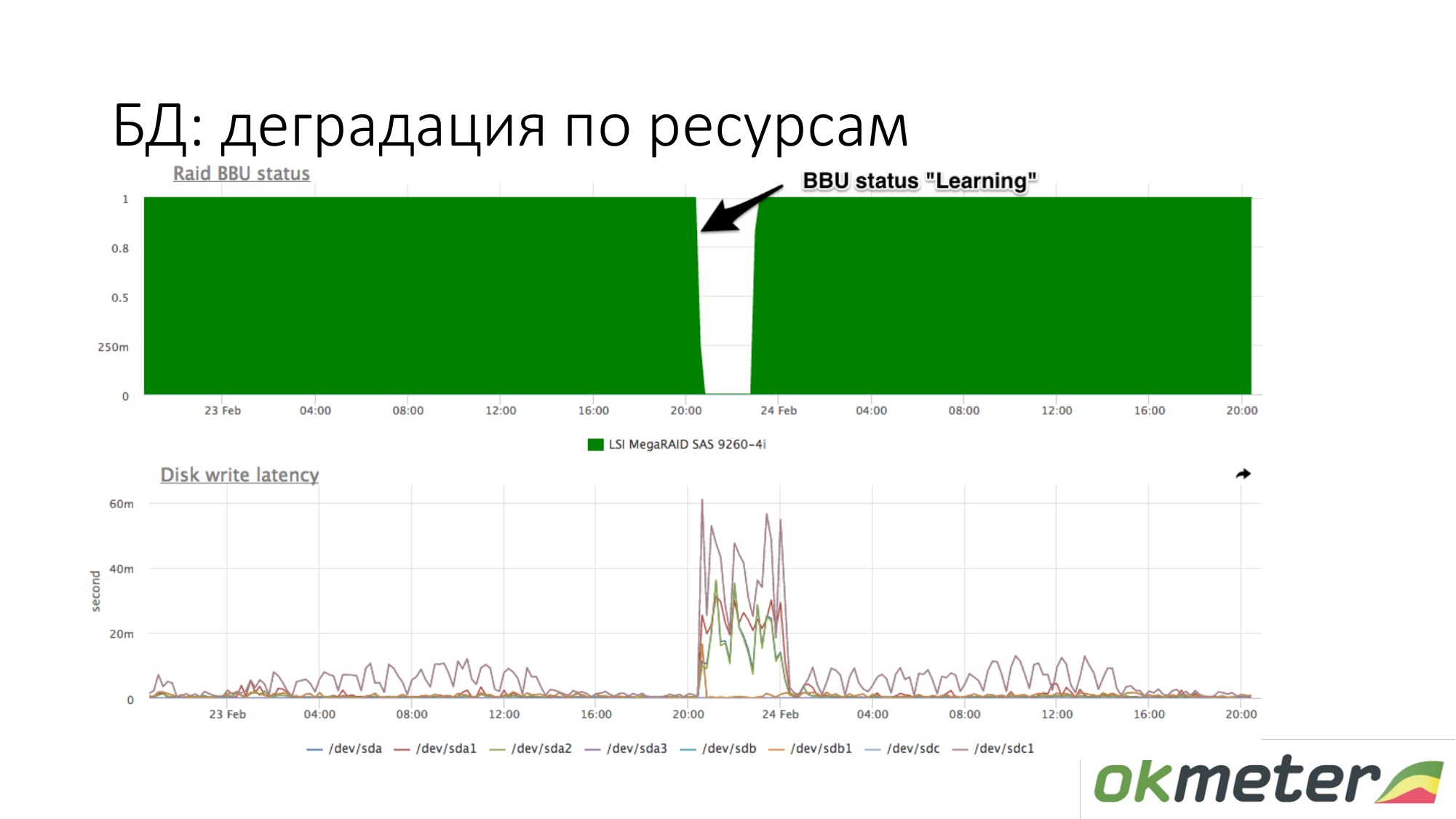
Про деградацию ресурсов. Например, у RAID батарейка ушла в maintenance режим. Она перестала контроллеру быть как живая батарейка. В этот момент отключается write cache, lateny дисков на запись возрастает. В этот момент, если база начала тупить при ожидании диска, и вы примерно знаете что у вас при такой же нагрузки на запись на диск latency было другое, то проверьте батарейку в RAID.

Ресурсы по запросам. Тут все не так просто. Зависит от базы. База должна сама про себя уметь рассказывать: на какие запросы она тратит ресурсы и т.д. Самый лидер в этом это PostgreSQL. У него есть pg_stat_statements. Вы можете понимать какой запрос у вас использует много CPU, диска на чтение и на запись, трафика.
В MySQL, если честно, все гораздо хуже. В нем есть performance_schema. Она с версии в 5.7 как-то работает. В отличие от одной view в PostgreSQL, performance_schema это 27 или 23 таблицы системных view в MySQL. Иногда если вы будете делать запросы к неправильным таблицам (к неправильным view), вы можете просадить MySQL.
В Redis есть статистика по командам. Вы видите что определенная команда использует много CPU и т.д.
В Cassandra есть времена по запросам к конкретным таблицам. Но так как кассандра проектируется так чтобы к таблице делался один тип запроса, то этого достаточно для мониторинга.
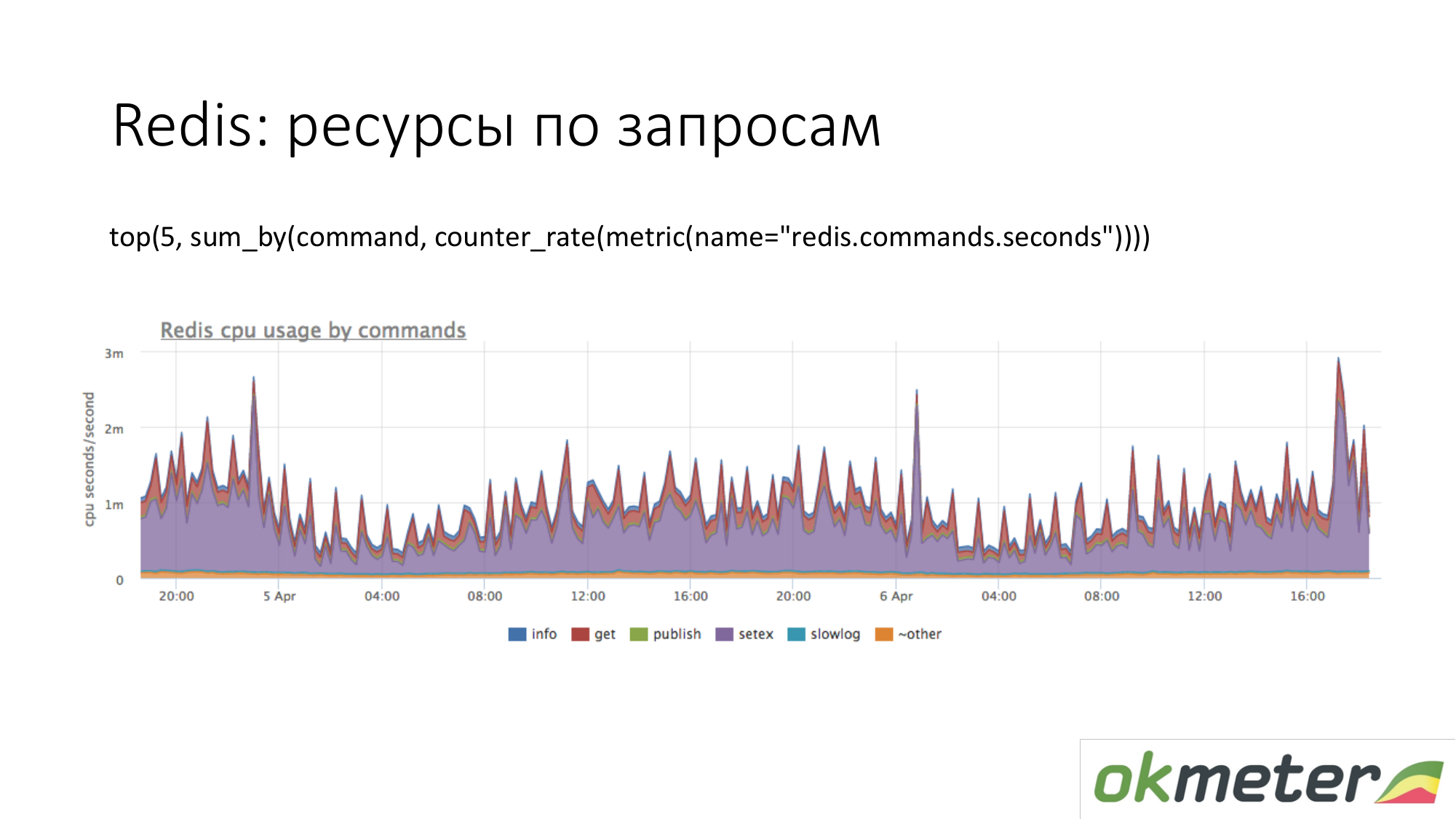
Это Redis. Видим что фиолетового использует много CPU. Фиолетовое это setex. Setex — запись ключа с установкой TTL. Если для нас это важно, идем с этим разбираться. Если для нас это не важно, просто знаем куда все ресурсы уходят.
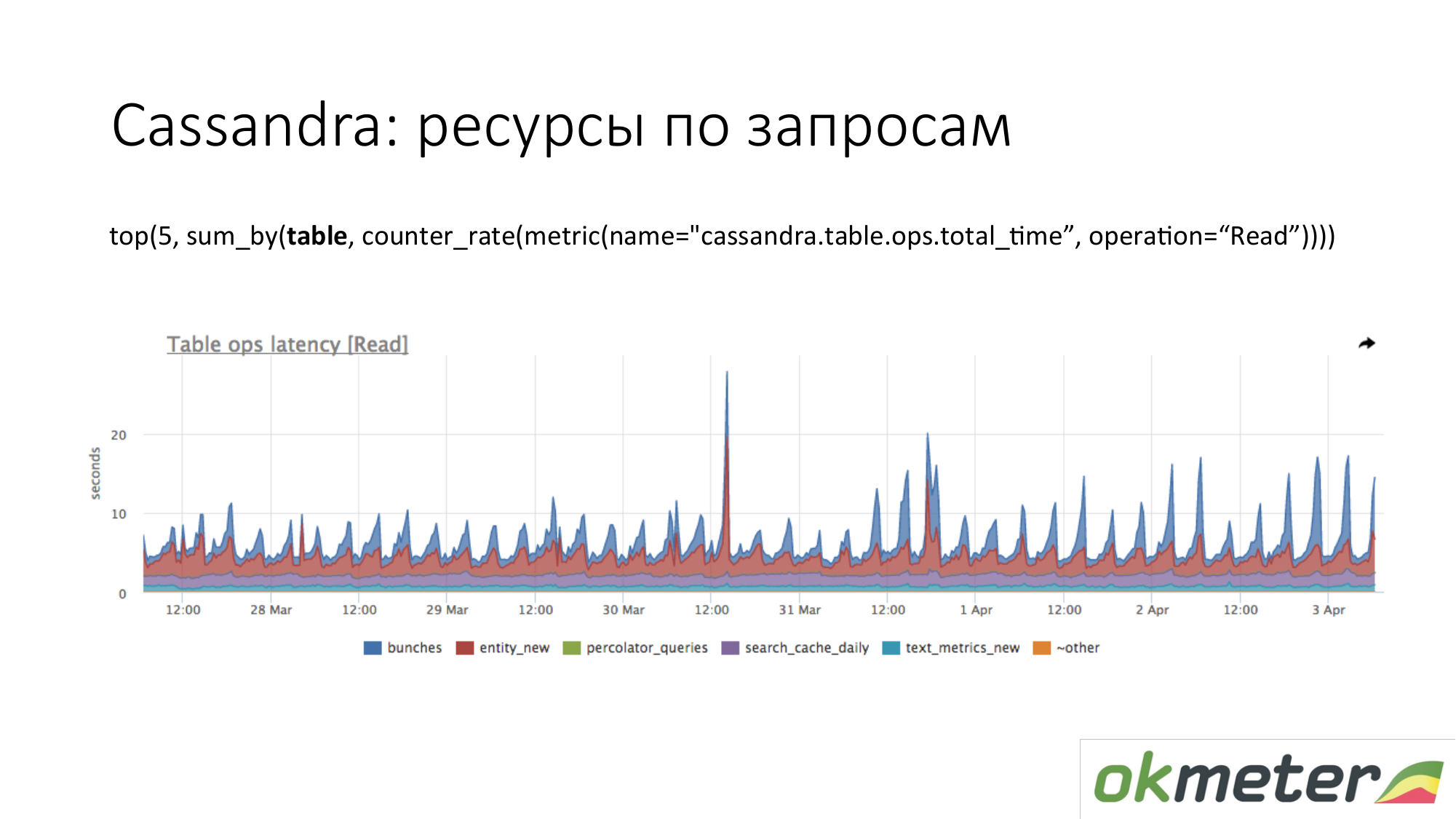
Cassandra. Видим топ-5 таблиц по запросам на чтение по суммарному времени ответа. Видим этот выброс. Это запросы к таблице и мы примерно понимаем что к этой таблице запрос у нас делает один кусок кода. Cassandra это не SQL база, в который мы можем делать разные запросы к таблицам. В Cassandra все более убого.

Еще пару слов про workflow работ с инцидентами. Как я это вижу.
Про alert. Наше видение workflow работ с инцидентами отличается от общепринятого.

Severy Critical. Мы уведомляем смсками и по всем real-time каналам связи.
Severy Info это лампочка которая может вам чем-то помочь при работе c инцидентами. Info никуда не уведомляется. Info просто висит и говорит вам о том, что что-то происходит.
Severy Warning это то что можно уведомить, может и нет.

Примеры Critical.
Сайт не работает вообще. Например, 5хх 100% или время ответа выросло и пользователи начали уходить.
Ошибки бизнес-логики. То что критично. Надо мерить деньги в секунду. Деньги в секунду хороший источник данных для Critical. Например, количество заказов, открутка рекламы и другие.

Workflow с Critical такой что этот инцидент нельзя отложить. Нельзя нажать OK и пойти домой. Если вам пришел Critical и вы едете в метро, то вы должны выйти из метро, подняться на наружу, сесть на лавочку и начать чинить. В противном случае это не Critical. Из этих соображений остаточному признаку мы конструируем остальные severity.

Warning. Примеры Warning.
- Место на диске заканчивается.
- Внутренней сервис работает долго, но при этом если у вас Critical нет, то значит вам на это условная все равно.
- Много ошибок на сетевой интерфейсе.
- Самая спорная это сервер не доступен. На самом деле, если у вас больше одного сервера и сервер недоступен это Warning. Если у вас недоступен 1 backend из 100, то глупо просыпаться от смски и вы получите нервных админов.
Все остальные Severy созданы для того чтобы помочь вам разобраться с Critical.

Warning. Мы пропагандируем такой подход к работе с Warning. Желательно Warning закрыть течение дня. Большинство наших клиентов отключили нотификацию на Warning. Тем самым у них нет так называемый мониторинговой слепоты. Имеется ввиду складывание писем в почте отдельную директорию не читая. Клиенты отключили уведомление на Warning.
(Как я понял чистый мониторинг это ненужные алерты и триггеры добавлены в исключения — примечание автора поста)
Если вы используете технику чистого мониторинга, если у вас появились 5 новых Warning, то вы в спокойном режиме их чините. Не успели сегодня починить, то отложили до завтра, если не критично. Если Warning загораются и погашаются сами, то это надо крутить в мониторинге чтобы опять же вас не беспокоить. Тогда вы будете более терпимы к ним относиться и соответственно жизнь наладится.

Примеры info. Тут спорно что высокое использование CPU у многих Critical. На самом деле, если при этом ничего не аффектится, то на это уведомление можно не обращать внимания.

Warning (возможно имеется ввижу Info — примечание автора поста) это лампочки, которые горят, когда вы приходите чинить Critical. Вы видите рядом два Warning (возможно имеется ввижу Info — примечание автора поста). Они вам могут помочь в решение инцедента с Critical. Зачем знать про высокое использование CPU отдельно в СМС или в письме непонятно.
Бессмысленный Info это тоже плохо. Если вы их настроить в исключение, то вы будете Info любить тоже сильно.

Общие принципы подхода к конструированию alert. Alert должны показывать причину. Это идеально. Но такого добиться сложно. Вот мы fulltime работаем над задачей и получается с какой-то части успеха.
Все говорят про то что нужны зависимости, автомагия. На самом деле, если у вас не приходят уведомления на то что вам не интересно, то лишнего много не будет. В моей практике статистика говорит о том что человек момент Critical инцидента отсмотрит глазами около сотни лампочек по диагонали. Он там найдет нужный и не будет думать о том что dependency скрыли какие-то лампочки, которые мне бы сейчас помогли. На практике это работает. Все что нужно делать это подчищать ненужные alert.

(Тут видео перескочило — примечание автора поста)

Хорошо бы эти downtime классифицировать чтобы с ними потом можно было работать. Например, делать организационные выводы. Вам нужно понимать из-за чего вы лежали. Мы предлагаем классифицировать/разбивать на такие классы:
- человек налажал
- хостер налажал
- пришли боты
Если вы их классифицируйте, то всем будет счастье.

Пришла СМС. Что делаем? Мы сначала бежим все чинить. Нам пока вообще ничего не важно, кроме того чтобы downtime закончился. Потому что мы мотивированны меньше лежать. Потом когда инцидент закрылся, он должен закрыться системе мониторинга. Мы считаем что инцидент должен проверить мониторингом. Если у вас мониторинг не настроен, достаточно чтобы удостовериться что проблема закончилась. Это надо крутить. После того как инцидент закрыт, он на самом деле не закрыт. Он ждет пока вы докопайтесь до причины. Любому руководителю на самом деле в первую очередь нужно чтобы проблемы не повторялись. Что проблемы не повторялись, нужно докопаться до причины. После того как до причины докопались, у нас есть данные чтобы их классифицировать. Делаем разбор причин. Потом как мы докопались до причины, нам нужно сделать в будущем чтобы инцидент не повторялся:
- нужно два человека в квартал для того чтобы вписать в backend такую-то логику.
- нужно поставить больше реплик.
Нужно сделать чтобы ровно такой же инцидент не произойдет. Когда вы работаете в таком workflow через N итераций вас ждет счастье, хороший аптайм.
Зачем мы их классифицировали? Мы можем взять статистику за квартал и понять что больше всего вам дало downtime. Потом в этом направлении работать. Можно работать по всем фронтам будет не очень эффективно, особенно если у вас там ресурсов в немного.

Мы там посчитали мы лежали столько-то времени, например 90% из-за хостера. Мы берем мы меняем этого хостера. Если у нас лажают люди, мы их отправляем на курсы. На самом деле, самый самый эффективный способ победить человеко-лажу — это автоматизация. Машина лажает реже. Если у релизов плохое качество, то командам разработки устраиваем выговор. Когда вы знаете причину, вам легче искать решения.

Выводы капитанские. Мониторинг мы раскладываем на две задачи:
- обнаружения проблем.
- поиск причины.
Если вас не устраивает время, которое вы ищете причину, то настраивайте точность мониторинга. Если точность вас не устраивает обнаружения, там тоже можно покрутить, настроить мониторинг.

Вопрос: мы добавляем новый сервис, новый сервер. Обычно как мы это делаем: подключили, добавили шаблоны, затем начинается творческий процесс. Мы убираем False Positive (ложные срабатывания), пытаемся убрать то, что мы не проверяем. Об этом подходе можете пару слов сказать?
Ответ: Мы с сервера снимаем все метрики. Когда вы добавили 10-й frontend сервер, то с него снимется все метрики. Если на соседних 9 frontend есть тайминги в логах nginx, а на 10-м таймингов нет, то мы вам зажжем warning alert без уведомлений. Вы в течение дня добавляете тайминги и у вас появляются все метрики. Если вы делаете новый сервис, то мы снимаем все метрики. Этот подход очень хорошо работает чтобы не забыть добавить метрики. Заинструметировать все наперед нельзя.
Вопрос: Я имел ввиду про пороги и уведомления. Например, у нас там сервер с БД, на нем load avarage 4 это нормально, веб-сервер у него load avarage 20 это нормально.
Ответ: Ответ на ваш вопрос не надо уведомлять load avarage. В среднестатистическом проекте на несколько 100 машин как правило пороге одинаковы для всех. Естествеенно мониторинг CPU usage на серверах Hadoop отвключен всегда. А порог дискового простанства на базах нужно делать немного поменьше. Как правило это вообще у всех работает. Все остальные триггеры одинаковые. Мы когда делаем автоматически триггеры, которые на всех пользователей выкатывается по умолчанию, мы их делаем примерно общими. В любом проекте плохо работает PostgreSQL и плохо настроен autovacuum, если worker autovacuum в работает два часа и более. Значит что он никогда не сделает свою работу для 99 процентов случаев. Warning как правило показывают исчерпывающую информацию. А Critical клиент настраивает для своего проекта. Для моего проекта Critical это10 5хх в секунду, а меньше это не Critical.
Вопрос: В какой момент и каким образом определяется порог? Кто это делает?
Ответ: Вы приходите к нам и говорите: мы хотим задать какой-нибудь Critical своего проекта. Если бы сейчас поставили 10 5хх в секунду, то сколько уведомлений получили бы неделю назад.
Вопрос: Какая нагрузка всего этого доброго мониторинга?
Ответ: В среднем она вообще незаметна. Но если парсите 50000 RPS это будет от 1% до 10% одного CPU. Так как мы занимаемся только мониторингом, мы оптимизировали наш агент. Мы меряем производительность агента. Если у вас нет ресурсов для мониторинга на сервере, значит вы делаете что-то не так. Всегда должны быть ресурсы для мониторинга. Если вы этого не сделаете, то вы будете как слепой на ощупь администрировать ваш проект.
