Тактовый механизм управления DWH: как разгрести бесконечную очередь и не умереть

Привет, Хабр! Я хочу поделиться с тобой тем, как работает наш сервис по управлению загрузками данных — в общих чертах, не погружаясь супер глубоко. Основная задача сервиса — снизить трудозатраты разработчиков и сопровождения DWH на всякую рутину, связанную с управлением загрузками, в идеале — как в старой доброй кнопочке «Сделать всё хорошо».

Как работает управляющий механизм
Итак, речь пойдет об автоматизированной системе под названием «Модуль управления» или просто УМ.
Модуль управляет бОльшей частью процессов в Централизованном хранилище данных (ЦХД). Большей — потому что есть обходные пути для особенных источников и витрин. Всегда же должен быть план Б =).
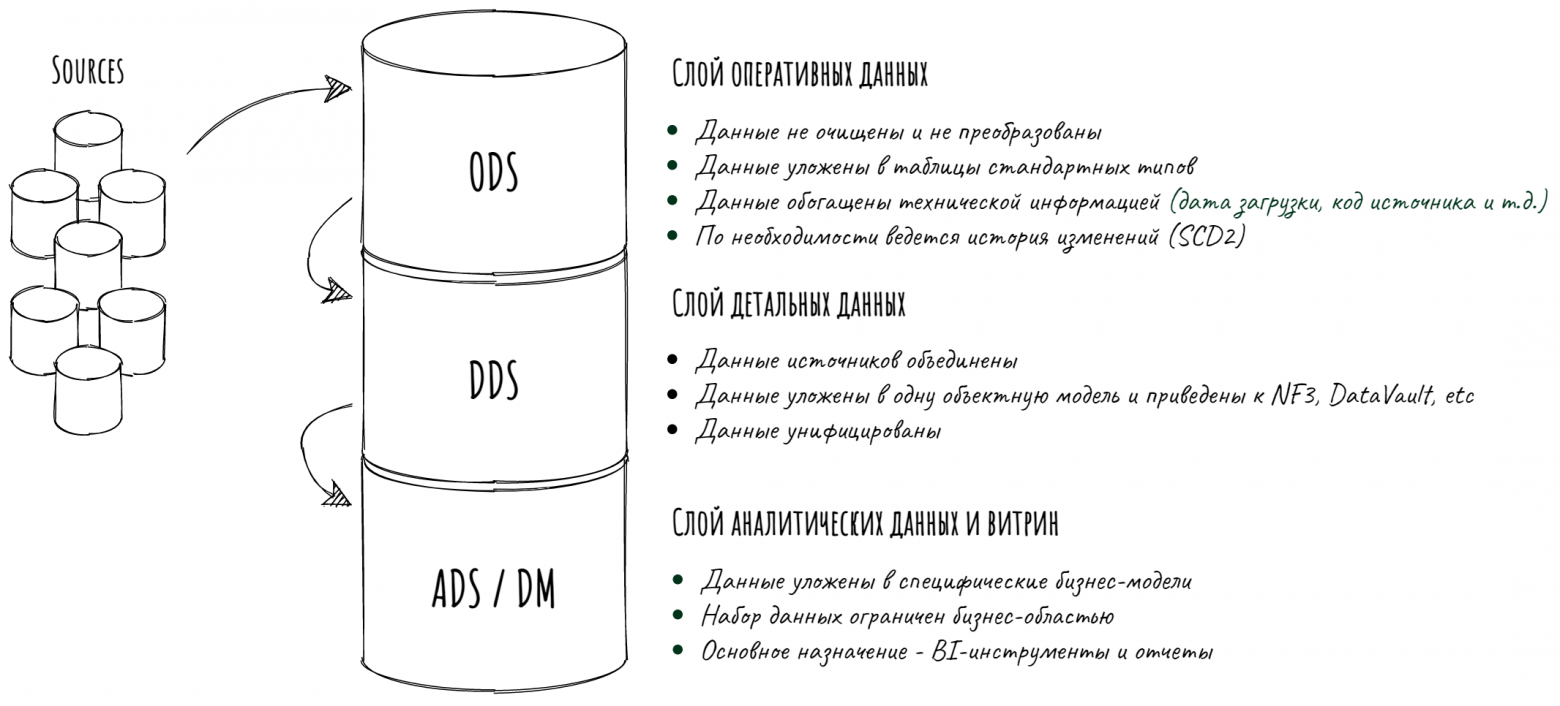
В ЦХД стекаются данные из информационных систем, которые используются в компании по всей стране: в цифрах это 300+ систем-источников и примерно 20 тысяч таблиц-источников, занимающих 650 ТБ, распределенных между Greenplum и Hive, а также широкий слой детальных данных и множество витрин.
Процессы, которыми управляет УМ — это примерно то же, что и у всех: поэтапные загрузки данных в различные слои DWH, сбор статистики, онлайн-проверка качества данных, рассылка оповещений и прочая стандартная дребедень.
Базовые принципы
1. Максимальная автоматизация всех процессов
Первый и главный принцип, который заложен в саму суть системы — «автоматизируй всё, что можно автоматизировать». Мы оставляем людям минимальную ручную настройку и разбор ошибок. Все процессы завязаны на метаданные: когда есть полное описание таблицы, можно и DDL сгенерировать, и DML автоматически во время загрузки сформировать, и алгоритм обновления выбрать без участия человека. Про всякие попутные логирования и говорить нечего.
Специально обученный человек один раз разрабатывает несколько унифицированных шаблонов загрузки данных и прописывает в системе логику выбора шаблона на основе метаданных (например, один шаблон для таблиц, которые должны храниться в Greenplum, другой — для тех, кто хранится в Hive). И всё — новые сущности могут грузиться по этому шаблону без дополнительных приседаний.
2. Все процессы разбиты на атомарные шаги
Загрузки данных, проверки КД, синхронизация метаданных, сбор статистики и т.д. — все процессы, которые умеет контролировать УМ, зарегистрированы в репозитории и описаны как набор параметризированных операций-шагов, между которыми есть направленные связи (как в ориентированном графе). Каждая операция должна быть неделимой (атомарной) и перенакатываемой (идемпотентной).
3. Процесс — это направленный ациклический граф
Процессы собираются из атомарных шагов, как из кубиков, и между кубиками создаются направленные связи. Ограничений на состав и сложность процессов нет (кроме требования на отсутствие циклов), и процессы бывают о-о-очень разными по наполненности и ветвистости.
Например, процесс загрузки данных в слой оперативных данных состоит из четырех этапов:
Загрузка в промежуточную таблицу (aka staging), очищаемую перед каждой загрузкой;
Проверка качества загруженных в staging данных (на дубли, на допустимые значения и пр);
Актуализация целевой таблицы постоянного хранения (aka target) одним из стандартных алгоритмов;
Проверка качества загруженных в target данных (бизнесовые проверки).
Этот процесс универсальный, не привязанный к конкретной таблице источника или таргету — наоборот, target задается параметром при старте процесса, а все остальное вычисляется из метаданных.

В отличие от загрузок ODS, расчеты таблиц детального слоя и витрин часто объединены в группы по предметным областям, и каждому «кубику» заранее задана конкретная таблица ХД. Представление таких процессов выглядит чуть более сложно, например, так:
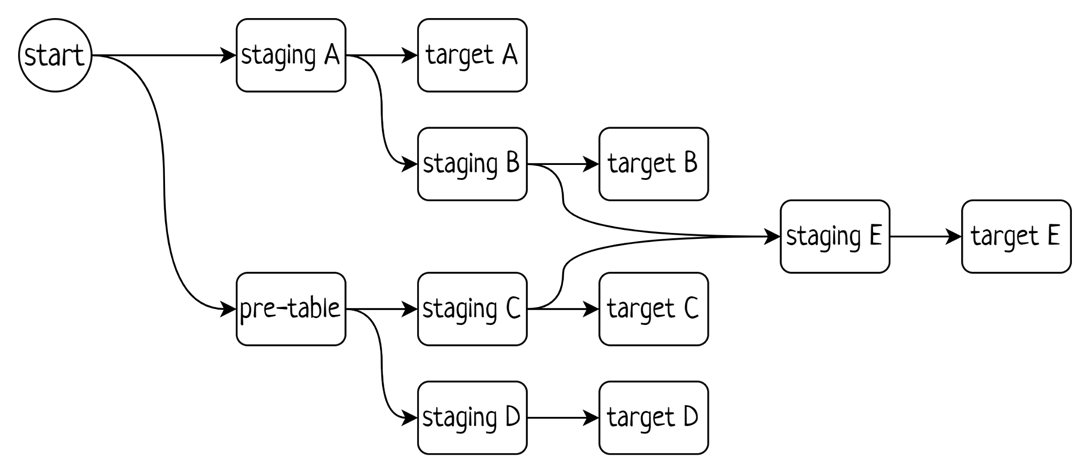
Но при сборке такого процесса все равно используются универсальные кубики, для каждого из которых надо только конкретную таблицу задать.
Хранится описание процессов в трех настроечных таблицах: Таблица процессов, Таблица шагов процесса и Таблица связей между шагами.
4. Регистрация задачи вместо немедленного выполнения
Когда через API прилетает очередное задание на запуск процесса, УМ вычисляет все необходимые параметры операций-шагов процесса, формирует команды и добавляет операции в общую очередь операций. Непосредственные расчеты начнутся позже — когда все пререквизиты отработают и получат успешный статус. Пререквизитами операции являются как операции того же процесса, которые выше по графу, так и другие процессы из общей очереди, использующие тот же объект ХД.

В целом, порядок выполнения операций определяется принципом FIFO: новые загрузки встают в конец очереди, а оркестратор отбирает из очереди первые N операций, чтобы отправить на выполнение. Дополнительно реализовано множество способов управления очередью и процессами в ней:
отмена — операции и процесс удаляются из очереди, освобождая дорогу другим;
пауза — операции не отправляются на выполнение, но остаются в очереди (и блокируют зависимые процессы);
рестарт — процесс начинается заново, как будто до этого ничего не выполнялось;
рекавер — для процессов, упавших в ошибку: продолжить с места падения, повторить ошибочную операцию;
игнор ошибки операции — для продвинутых пользователей с расширенными правами: продолжить с места падения без повтора ошибочной операции;
подвинуть процесс вверх/вниз в очереди — на примере с картинки можно поменять местами процессы B и C, т.к. они еще не начали выполнение;
подвинуть операцию без пререквизитов вверх/вниз очереди — операций без пререквизитов может быть много (в пиковые нагрузки на сервис в работе может быть несколько тысяч процессов). Такие операции образуют подочередь (очередь свободных операций), и обычно сортируются по дате добавления, но на этот порядок также можно влиять.
Надо отметить, что на порядок выполнения операций внутри одного процесса влиять нельзя — т.к. это может привести к ошибкам и дефектам данных.
5. Дискретно-непрерывный подход к ведению загрузок
Модуль управления — это механизм, работающий по принципу «включился — поработал — выключился — повторил через N минут». Одну итерацию такого цикла мы называем тактом. Частота тактов настраивается в зависимости от контура (среды) — на продуктиве это раз в минуту.
В начале каждого такта механизм определяет перечень операций, которые можно выполнить немедленно, асинхронно запускает их и завершает такт. Момент с асинхронностью здесь очень важен — система должна уметь запускать операции без ожидания завершения, т.к. самые тяжелые работают по несколько часов. Операция выполняется в обертке — стандартном джобе, который логирует и журналирует ход выполнения.
«Перечень операций, которые можно выполнить немедленно» — это как раз те операции из очереди, у которых не осталось пререквизитов и которые попадают в число «первых N».
Также в начале такта УМ выполняет управляющие действия над процессами — полностью выполненные закрывает, другие инициализирует.
6. Остановка ветки в случае ошибки
Когда всё идет гладко — загрузки грузятся, шестеренки крутятся, пользователи занимаются своими делами. Но как только происходит ошибка выполнения — блокируется всё, что по пайплайну зависит от упавшего этапа.

Игнорировать ошибку и продолжить процесс загрузки обычно нельзя, т.к. невыполнение одного этапа отрицательно скажется на результате остальных. Отменить весь процесс, в котором произошла ошибка, тоже нельзя — можно упустить массовую проблему или получить дырку в данных.
Из этого вытекает следующий факт — упавший процесс остается висеть в очереди. Когда зарегистрировано несколько загрузок по одному и тому же объекту, то ошибка одной загрузки блокирует не только pipeline-ветку процесса (например, какая-то витрина не стартанет, пока не рассчитается таблица DDS), но и остальные загрузки в тот же объект (т.е. ошибка при расчете таблицы за 1 января блокирует загрузки той же таблицы за другие даты). При этом на несвязанные загрузки влияния вообще нет и не должно быть — работают себе независимо и в ус не дуют.
В результате получается два момента, которые стоит отметить:
с любой проблемой, даже просто обрывом коннекта, должен разбираться ответственный сотрудник;
если ошибкой никто не занимается, то по объекту может накопиться приличный хвост, который начнет рассасываться только после решения проблемы.
Второй момент кажется минусом –, но это только на первый взгляд. На самом деле это своеобразная защита от проблем в данных, которая позволяет разбираться с ошибками в порядке критичности, не бросаясь сразу на все и не переживая, что от задержки что-то испортится или сломается.
Кстати, в бэклоге находится задача по разделению ошибок коннекта и остальных проблем. Предлагается при ошибке коннекта к БД повторять попытку выполнения операции через некоторое (настраиваемое) время. Ну и ограничить число попыток, конечно, чтобы в бесконечный цикл не уйти.
7. Защита открытых транзакций и логическая блокировка объектов
Статусы операций живут в специальном «журнале операций» — таблице, в которую попадают записи о задействованных в загрузках объектах ХД и операциях над ними. Перед началом каждой операции в журнал вставляется строка с указанием на объект, типом операции и статусом Running. После выполнения операции статус записи в журнале меняется на Success или Error в зависимости от результата. Записи в журнале живут, пока не завершится вся загрузка (все операции процесса).
В результате журнал не только отражает ход работы процесса, но и создает логическую блокировку объекта на весь период загрузки — даже после успешного завершения атомарной операции аналогичную новую операцию начать нельзя, т.к. следующие операции того же процесса могут использовать данные заблокированного объекта. Например, данные staging-таблицы нельзя перетирать, пока они успешно не зальются в target.
Логическая блокировка объекта в журнале реализована просто как уникальный индекс над таблицей-журналом.
Это невероятно полезная штука, супер-резерв, который несколько раз спасал нас от проблем потери данных. Не часто, но было такое, что что-то где-то задублилось, сломалось, неверно настроилось — и УМ пытался запустить одну и ту же операцию дважды. А т.к. вставка записи в журнал происходит перед выполнением операции, то такой номер не проходит — кто первый запись в журнал вставил, тот таблицу и танцует загружает. Уникальный индекс в этом плане надежен как скала =).
Технологический стек
Далее в статье упоминаются продукты таких вендоров как IBM и Oracle. Я понимаю, что в свете событий 2022 года использование их в проекте может быть, мягко говоря, затруднено или неразумно. Но пока так исторически сложилось. Принципы и подходы, описанные в статье, универсальны — ровно ту же историю можно реализовать на опенсорсных продуктах (и нам тоже придется постепенно перейти).

Система реализована как связка Oracle БД + ПО-оркестратор + рутины.
 Упрощенная схема взаимодействия компонентов
Упрощенная схема взаимодействия компонентов
Рутины (именованный исполняемый код) реализуют логику обработки данных — бизнесовую или техническую. Они могут быть реализованы как угодно: exe-файл, python-скрипт, bash-скрипт, процедура/функция БД, объект ETL-инструмента и пр. Всякие исполняемые файлы могут запускаться в контейнере, иметь собственные настройки/конфиги/окружение и пр. Все это неважно для УМ — главное, чтобы рутина была описана в настройках УМ как исполняемая параметризованная команда.
Пример: рутина актуализации ODS (т.е. обновления target-таблицы данными staging) у нас реализована как python-скрипт. Параметризованная команда вызова этого скрипта выглядит примерно так:
$python_path $py_act_folder/act_ods.py -t $P_OBJECT_NAME -src $P_OBJECT_SRC_CODE
-st $P_START_DTTM -end $P_END_DTTM -upload $P_UPLOAD_DTTM
-env $P_ENV -pkg_id $P_PKG_ID -init $P_INITВсе, что начинается с $, является либо параметром системы, либо параметром рутины. Параметры рассчитываются в момент регистрации загрузки, и в очередь попадает уже полностью готовая команда.
Добавить в УМ новую рутину легко — в настроечных таблицах описывается специальный объект: сама команда, способ выполнения (т.е. как выполнять — как команду ОС или, например, в БД отправлять) и формулы для расчета параметров. Далее указанный объект можно встраивать в любой процесс.
Oracle БД используется не только как хранилище метаданных, логов, журналов и настроек, но и как основной мозг системы (backend). Вся логика управления процессами зашита в хранимые объекты БД — представления и PL/SQL-пакеты.
Oracle как основа бэкенда был выбран сознательно — дополнительная прослойка между БД и оркестратором усложнила бы систему, но при этом не принесла бы особого профита. Реализовывать внутреннюю логику в оркестраторе мы пробовали, и нам не понравилось — очень тяжело поддерживать по сравнению с текущим вариантом. Код, написанный на SQL и PL/SQL, гораздо проще версионировать, накатывать изменения, оптимизировать и отлаживать, можно включить в CI/CD и пр. Также дополнительный плюс — нет особой привязки к оркестратору — переехать на другое ПО в случае чего не такая уж и проблема. Сменить СУБД, конечно, будет несколько сложнее.
Основные объекты в БД:
Журнал операций;
Очередь операций;
Таблица-пул, в которую кладется перечень операций, отобранных из очереди для выполнения в текущем такте. Каждой операции сопоставлено имя объекта оркестратора, который будет её выполнять;
Процедура управления, отвечающая за всю внутреннюю кухню обработки процессов и заполнение пула;
Кстати, таблица-пул появилась не сразу — поначалу оркестратор вычитывал список операций непосредственно из очереди. Но запрос к очереди довольно тяжелый, и оказалось, что такой подход иногда приводит к накладкам.
Оркестратор отвечает за «тактовость» работы механизма и «дергает за ручку» API остальных объектов системы. Он может быть реализован в любом инструменте, позволяющем обращаться к базам разных СУБД, запускаться по расписанию и отправлять команды в операционную систему. ETL-инструменты вроде Informatica, Airflow и даже NiFi вполне подходят. Мы выбрали IBM Datastage — на момент выбора у нас были лицензии, поддержка IBM и собственная экспертиза, плюс на стадии пилота Datastage оказался лучше, чем Airflow — в нем меньше багов и отказоустойчивость выше.
В оркестраторе реализовано несколько объектов, описывающих основные процессы — один головной, отвечающий за общее руководство, и дочерние, реализующие выполнение одной операции. Дочерних объектов столько, сколько реализовано способов выполнения операций — в нашем случае два: команды ОС и вызов процедуры БД. Когда появится новый способ выполнения, придется доработать оркестратор: создать новый объект и прописать его в настроечных таблицах БД, чтобы правильно заполнялась таблица-пул.
 Процессы оркестратора: основной и дочерний
Процессы оркестратора: основной и дочерний
Фишки и плюшки
1. Балансировка нагрузки на БД
Количество одновременно работающих в ХД процессов надо контролировать — если отправить на выполнение одновременно 100500 DML-операций, база может крякнуть и упасть. На продуктивном контуре под загрузки ХД выделены ресурсы, позволяющие работу 300 запросов одновременно (это на технические нужды, пользователи в другой группе тусят), но иногда и 300 слотов мало — в очереди может быть несколько тысяч незаблокированных операций. Такие аппетиты ограничиваются так: каждый такт УМ выбирает из очереди первые N операций, где N = Limit — Count_R.
Limit — максимально допустимое число одновременно выполняемых DML-операций, при котором гарантированно не падает БД.
Count_R — число операций, работающих в данный момент.
Limit пока задается пользователем вручную как глобальный параметр системы, но в бэклоге есть задача «Автоматическая адаптация лимита», в которой предлагается периодически проверять состояние Greenplum и повышать/понижать Limit.
2. Пока нет проблем масштабирования
Количество систем-источников постоянно растет, но это не сказывается на производительности. Фактически, мы упираемся в возможности БД ЦХД (Greenplum) в части числа одновременных запросов и свободное место. Также ПО, на котором работает оркестратор-запускалка, должно поддерживать одновременную работу как минимум Limit процессов/джобов. УМ можно развернуть на разных ПО — в данный момент у нас IBM Datastage, ресурсов и отказоустойчивости которого пока хватает. При этом у самого УМ, отдельно от ПО и от Greenplum, ограничений практически нет.
3. Все регламенты дружат и шарят ресурсы
Благодаря очереди и круглосуточной работе загрузки в ХД могут идти 24/7/365 — по разным объектам, за разные даты и периоды. Нет такого, что сейчас мы грузим все за 1 июня, а вчера грузили 31 мая. Одновременно могут идти процессы инициализирующих и регулярных загрузок с абсолютно разными периодами. Загрузка одного и того же объекта может быть включена в очередь несколько раз за разные периоды. Окончание загрузки одного объекта может стать триггером для старта загрузки другого.
Реальный пример: в последнюю версию скрипта, обеспечивающего обновление целевой таблицы ODS, закрался некий баг, который немного портил данные. Баг волшебным образом миновал все тесты и выкатился на прод, где прожил несколько дней, пока его не обнаружили и не исправили. В результате пришлось загружать данные источника в ODS заново за несколько дней. Сотрудник, разбиравший проблему, после исправления скрипта просто выполнил вручную запуск загрузки несколько раз за нужные периоды — без ожиданий, когда добежит одно, чтобы запустить другое. Загрузки зарегистрировались, встали в очередь и последовательно, в хронологическом порядке сами отработали без дополнительных танцев с бубном. Таблица детального слоя, при расчете которой используется описанная таблица ODS, стартовала сама* за эти же периоды, согласно своим настройкам запуска. От таблицы DDS веером разошлись загрузки витрин, опять же абсолютно самостоятельно, без дополнительных пинков.
*За автоматический запуск расчета по событию или группе событий отвечает другая система (сервис подписок), о которой я могу рассказать в отдельной статье, буде у сообщества возникнет такой интерес.
У внимательного читателя мог возникнуть вопрос –, а зачем запускать несколько загрузок за разные периоды, если можно запустить одну за один общий большой период?
В нашем случае у загрузок из источников в ODS есть промежуточный этап, когда пачка данных источника «приземляется» в сыром виде в Hadoop. Такая пачка данных называется пакетом и, во-первых, охарактеризована уникальным идентификатором, датой и периодом выгрузки, во-вторых, хранится довольно долго (места в Hadoop особо не жалко) и может быть переиспользована в подобных случаях. Такой промежуточный этап, хоть и удлиняет процесс, но позволяет отвязать заливку данных в ODS от процесса выгрузки из источника, а значит, разнести по времени «окно» доступности источника и процесс загрузки. При проблемах и/или регламентных работах в ХД, не позволяющих провести загрузку в ODS, пакеты копятся в Hadoop и могут быть загружены в любой момент. Плюс можно в любой момент загрузить данные заново и не потерять при этом историю изменений.
4. Все операции порождают событие
Каждая загрузка, проходя очередной этап (выполнив операцию), создает событие, регистрируемое в системе. Эти события используются как триггер для запуска следующих по пайплайну загрузок в слой детальных данных и витрины. Также события используются в различных метриках и мониторинге выполнения регламента — отслеживается выполнение плана.
Выхлоп
За месяц УМ обрабатывает суммарно более 300 тысяч разноплановых процессов и полтора миллиона операций. Их поддержкой занимается команда из 10–12 человек. Все тщательно залогировано, и логи хранятся 3 года. По любому процессу можно поднять историю и, например, провести анализ изменения скорости выполнения тяжелой операции.
Примерно 85% загрузок из источников в ODS реализуются без участия разработчика, на готовых процессах (если источник более-менее стандартный и не требует специальной реализации).
Разработка загрузок в DDS и витрины значительно ускорена — разработчики тратят на создание нового процесса и встройку его в общую систему считанные минуты, а основную часть времени — на реализацию и отладку бизнес-логики. Правда, на погружение в работу с УМ тратится больше времени, это да.
Команда сопровождения избавлена от многих проблем, типичных для хранилищ, реализованных в лоб — таких как управление количеством одновременных процессов, порядок выполнения равнозначимых процессов, необходимость ручного контроля выполнения и последовательного запуска зависимых процессов в случае накладок или сбоев и т.д.
Очень большой плюс — круглосуточная работа без дежурных. Наш кластер Greenplum не позволил бы провести, например, все дневные загрузки за одну ночь или за один рабочий день, а УМ выполняет большую часть работы по контролю и запуску сам, что позволяет не сильно страдать при отставании регламента и нагнать его в любой момент.
На логах и журналах УМ собирается самая разная статистика — выполнение регламента, число ошибок в час, среднее время выполнения и подозрительные зависания операций и прочее. Также на них натравлена Grafana — на графиках в режиме реального времени можно наблюдать за показателями системы и получать от Telegram-бота оповещения при появлении проблем.
