Symfony под капотом: механизм повторной обработки сообщений при ошибках в Symfony Messenger

Привет! Меня зовут Ваня, последние несколько лет я занимаюсь backend-разработкой в Сравни. Моя команда разрабатывает интеграции с сервисами наших партнёров, код пишем на PHP и Symfony Framework.
При работе с интеграциями мы часто имеем дело со сбоями в сторонних сервисах, и нам очень важна возможность восстановления после таких ошибок. Для решения этой задачи у Symfony есть прекрасный инструмент — нужно только правильно им воспользоваться!
В этой статье я расскажу о том, как в Messenger-компоненте Symfony устроен механизм повторной обработки сообщений при ошибках (или по-простому — механизм ретраев), а также поделюсь опытом его использования и некоторыми важными нюансами его работы.
Кто такой Symfony Messenger
Для начала, давайте вспомним, для чего нужен Messenger-компонент.
Symfony Messenger используется для обмена сообщениями между разными приложениями с помощью message brokers (RabbitMQ и т. п.), а также для обработки сообщений внутри одного приложения (как синхронной, так и асинхронной).
Концепция Messenger-компонента хорошо описана в официальной документации.
В рамках статьи мы сфокусируемся лишь на одной из функций этого компонента — механизме ретраев в контексте асинхронной обработки сообщений внутри приложения.
Какие проблемы решают ретраи
Для примера представим сервис, где необходимо обращение к внешним партнёрам по API (для оформления кредита — в банк, для страховки — в страховую и так далее).
Допустим, пользователь подобрал кредит и решает отправить заявку в банк. В момент создания заявки сформируем сообщение, которое с помощью Message Bus отправим в очередь для последующей асинхронной обработки (в примерах кода тут и далее — PHP 8.2 и Symfony 6.3):

У такого сообщения есть обработчик (handler), основная задача которого — отправить соответствующий запрос к партнёру.

При таком способе взаимодействия всегда есть риск, что внешний API может быть недоступен из-за сетевых проблем, сбоя в приложении, технических работ и прочих неполадок.
Если, получив от стороннего сервиса ошибку, к примеру, 502 Bad Gateway, мы завершаем обработку сообщения и просто показываем пользователю уведомление вроде «Не удалось отправить заявку из-за технической ошибки», в проигрыше остаются все стороны — и пользователь, недовольный уровнем сервиса, и партнёр, не получивший потенциального клиента, и мы, не оправдавшие ожиданий всех перечисленных выше.
Чтобы сгладить такие проблемы, логично попробовать отправить заявку ещё один раз (или более) через некоторый промежуток времени, что в итоге может привести к успеху.
Вот тут-то на помощь и приходит механизм ретраев из Symfony Messenger — давайте подробно его рассмотрим.
Магия ретраев
Основным связующим звеном механизма ретраев служит класс SendFailedMessageForRetryListener. Он слушает событие WorkerMessageFailedEvent и при выполнении ряда условий отправляет сообщение назад в транспорт, из которого оно было получено. Сообщение помечается специальным штампом DelayStamp, в котором указывается необходимое время ожидания до следующей попытки — так сообщение попадает назад в очередь.
На решение о необходимости повторной обработки влияет два фактора:
тип ошибки — класс исключения, брошенного в обработчике сообщения;
реализация Retry Strategy для транспорта текущего сообщения.
Пробрасывая определенные исключения внутри обработчика сообщения, мы можем явно влиять на то, произойдет ретрай или нет.
Так, если в обработчике бросить любое исключение, реализующее UnrecoverableExceptionInterface, то мы предотвращаем ретрай. Это имеет смысл, когда очевидно, что автоматически решить проблему с помощью ретраев не удастся.
К примеру, в обработчике отправляется запрос в API, на который сервер возвращает, допустим, ответ с кодом 400 или 401 — нет смысла отправлять такой же запрос ещё раз. Если тело запроса не валидно, или в запросе отсутствуют необходимые для авторизации заголовки, сначала следует исправить ошибки, а затем повторить отправку.
Если же бросить любое исключение, реализующее RecoverableExceptionInterface, то мы требуем, чтобы сообщение точно было отправлено на повторную обработку.
Это имеет смысл, когда очевидно, что ошибка носит временный характер. Например, на свой запрос в API партнёра вы получили ответ 429, который означает, что превышен лимит запросов к API. В таком случае можно, к примеру, бросить такое исключение:
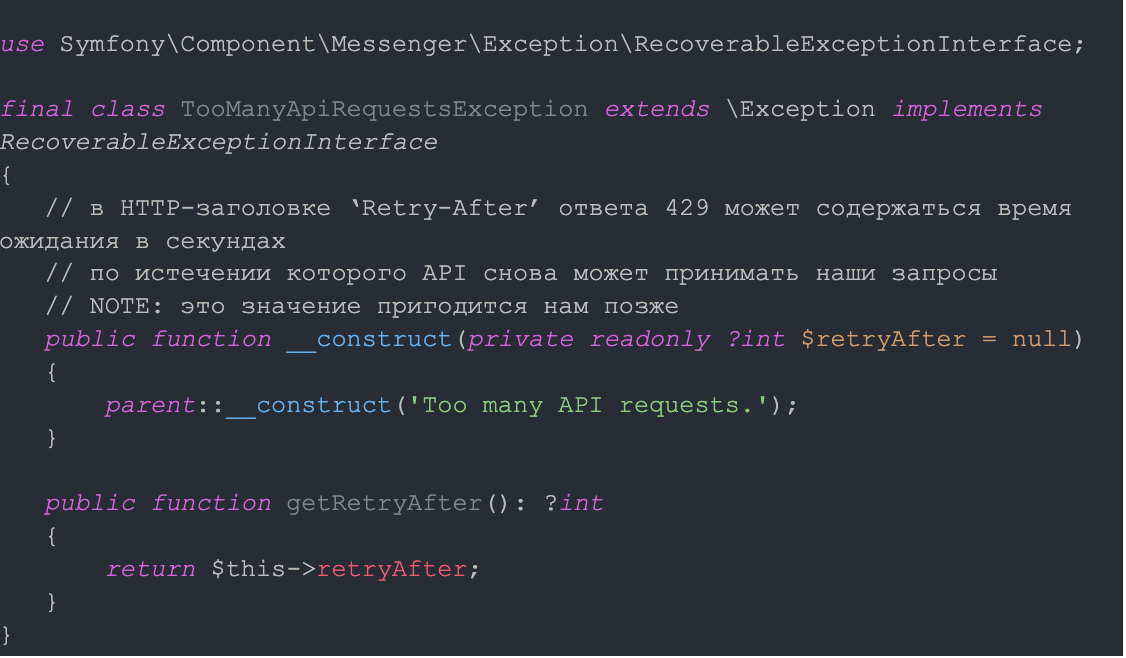
Далее в игру вступает Retry Strategy.
Если внимательно посмотреть на RetryStrategyInterface, становится ясно, что стратегия отвечает на два вопроса:
Нужно ли отправить сообщение на ретрай? Метод isRetryable — вызывается, только если ошибка не является Recoverable или Unrecoverable, то есть исключение не реализует ни один из упомянутых выше интерфейсов.
Через какое время нужно выполнить следующую попытку? Метод getWatingTime — вызывается в случае, если ретрай необходим.
От реализации этих двух методов зависит, через сколько будет выполнен следующий ретрай и будет ли он вообще.
Тут следует учитывать, что когда вы настраиваете транспорт для асинхронных сообщений, стратегия ретраев создается по умолчанию, хотите вы того или нет!
Настроив свой транспорт как в примере из документации, вы получите транспорт, в котором по умолчанию используется MultiplierRetryStrategy. Тогда в случае ошибки будет сделано еще три дополнительных попытки с интервалом 1, 2 и 4 секунды, соответственно:

Конфигурация позволяет настроить максимальное количество ретраев и регулировать их интервал, а при необходимости и вовсе указать свою собственную стратегию как service (далее мы рассмотрим и такой пример).
Два слова о том, откуда именно в транспортах берётся стратегия по умолчанию. Я не буду углубляться в детали, Symfony DI и Service Container — это отдельная большая тема, заслуживающая отдельной статьи (а лучше нескольких). Отмечу только, что это реализовано во FrameworkBundle, настройки по умолчанию объявлены в Configuration.php, а в файле FrameworkExtension.php стратегия ретраев с этими настройками автоматически регистрируется в сервис контейнере. Но давайте вернёмся к ретраям.
В случае, если все ретраи закончились неудачей (или их не было вовсе), сообщение просто удаляется из очереди, то есть попросту теряется! Чтобы этого избежать, можно (и чаще всего нужно) сконфигурировать Failure Transport (аналог Dead Letter Queue) — в него попадают сообщения, которые так и не удалось обработать.
Отправка сообщения в соответствующий failure transport (у каждого транспорта может быть настроен свой собственный failure transport) происходит в еще одном слушателе события WorkerMessageFailedEvent. Там как будто бы нет ничего сложного, но если вдруг после просмотра исходного кода у вас останутся вопросы о том, что там происходит — обязательно пишите в комментариях, буду рад помочь разобраться.
Порой могут возникать случаи, когда нужно полностью выключить ретраи, для чего достаточно изменить конфигурацию, указав max_retries: 0 в настройках стратегии:

К примеру, если API, в который отправляется запрос, не идемпотентен, в некоторых случаях даже неудачный запрос может вызвать какие-нибудь побочные эффекты, так что последующий повторный запрос к API может привести к другим результатам (другой ошибке, которая является следствием предыдущего неудачного запроса).
Разделяем логику ретраев
Еще один довольно важный нюанс, который стоит разобрать подробно: стратегия ретраев распространяется на все сообщения, полученные из данного транспорта!
Допустим, у вас в проекте один транспорт под названием async, который использует ретрай стратегию по умолчанию (прямо как в самом базовом варианте из документации Symfony, что мы уже рассмотрели выше). Через этот транспорт вы отправляете в очередь несколько разных сообщений:
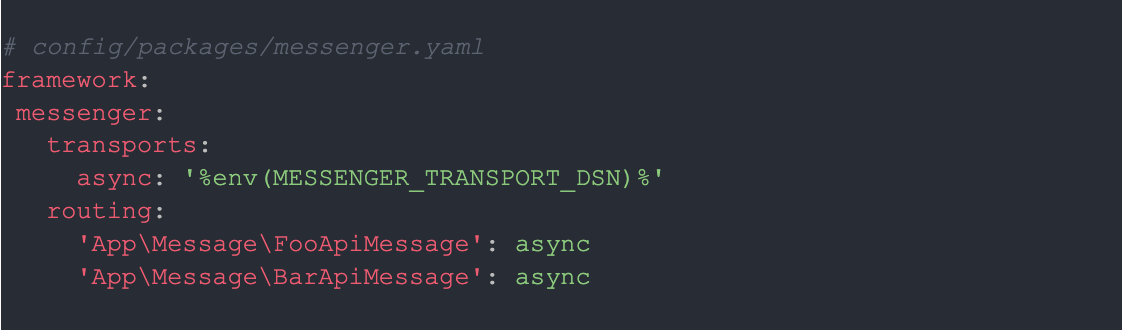
У каждого из этих сообщений есть свой обработчик, и они оба отправляют запросы в разные API.
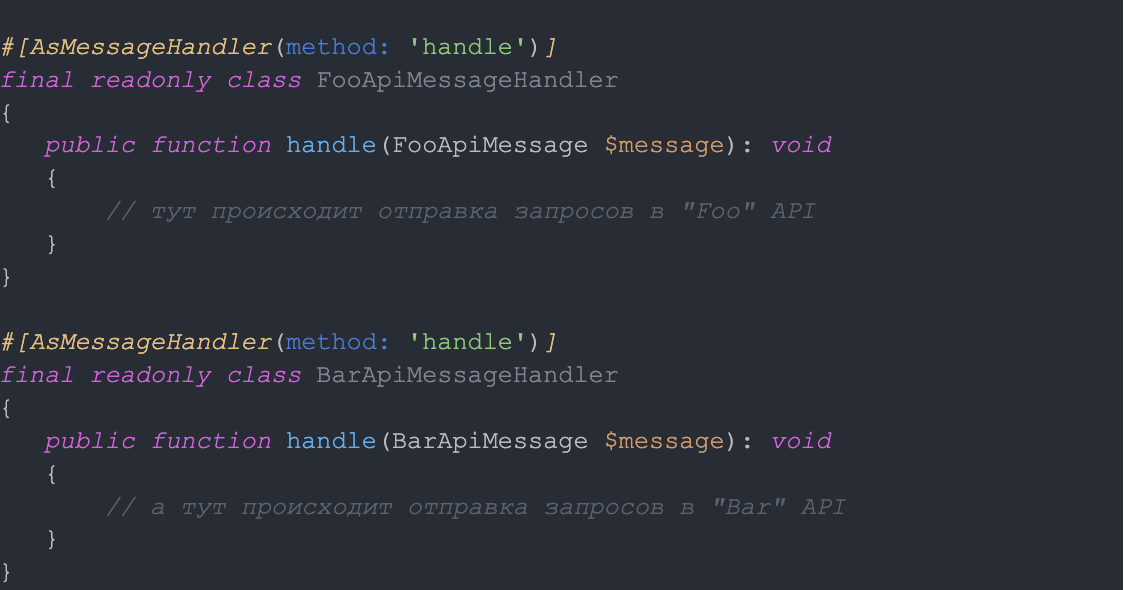
Разумно предположить, что логика работы с разными API скорее всего будет разной. Но и логика обработки ошибок разных API тоже может быть разной, как и требуемое количество и интервалы ретраев! А у нас одна общая стратегия ретраев на весь транспорт. И что же делать?
Наверное, самый простой вариант, который первым приходит в голову — использовать разные транспорты для сообщений, предназначенных разным API. В таком случае вы легко можете реализовать уникальную стратегию ретраев под каждый сценарий использования и назначить её на нужный транспорт. Здорово же, правда? Но не всё так просто.
Представьте, что у вас десятки или даже сотни сторонних сервисов с разными API, со своими транспортами и ретрай стратегиями.

Это уже не очень удобно, не правда ли? Сотни транспортов и стратегий! Должно же быть какое-то альтернативное решение? И оно есть!
Чтобы не создавать множество транспортов, было бы хорошо иметь какую-то динамическую стратегию ретраев, которая могла бы по-разному работать в разных условиях!
Например, для сообщений класса BarApiMessage — никогда ничего не ретраить, а в случае исключения TooManyApiRequestsException (о нём мы уже говорили выше) — ретраить всегда вне зависимости от типа (класса) сообщения, а в качестве времени ожидания использовать значение из HTTP-заголовка Retry-After.

К сожалению, из коробки такого функционала в Symfony Messenger нет, но хорошая новость в том, что его довольно просто реализовать самостоятельно! Ниже — один из возможных вариантов реализации.
Для начала нам понадобится ConditionalRetryStrategyInterface:
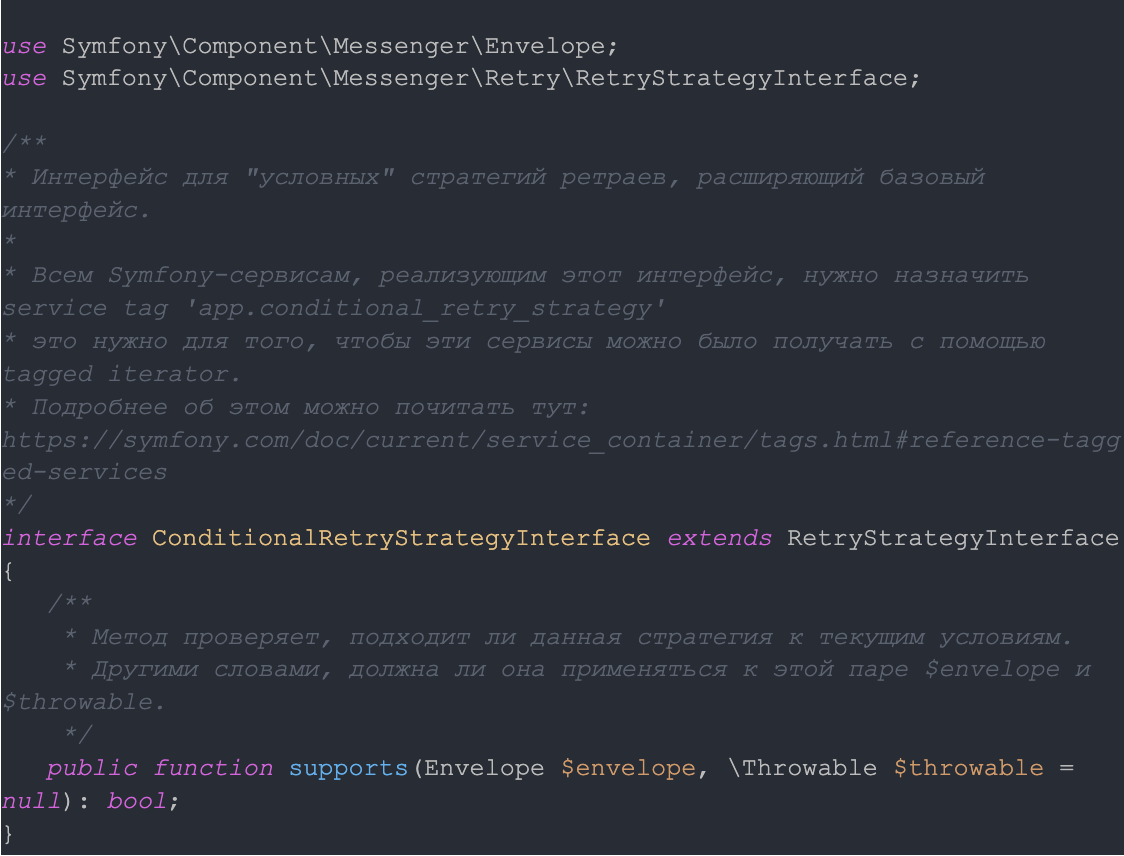
Затем реализуем DynamicRetryStrategy:
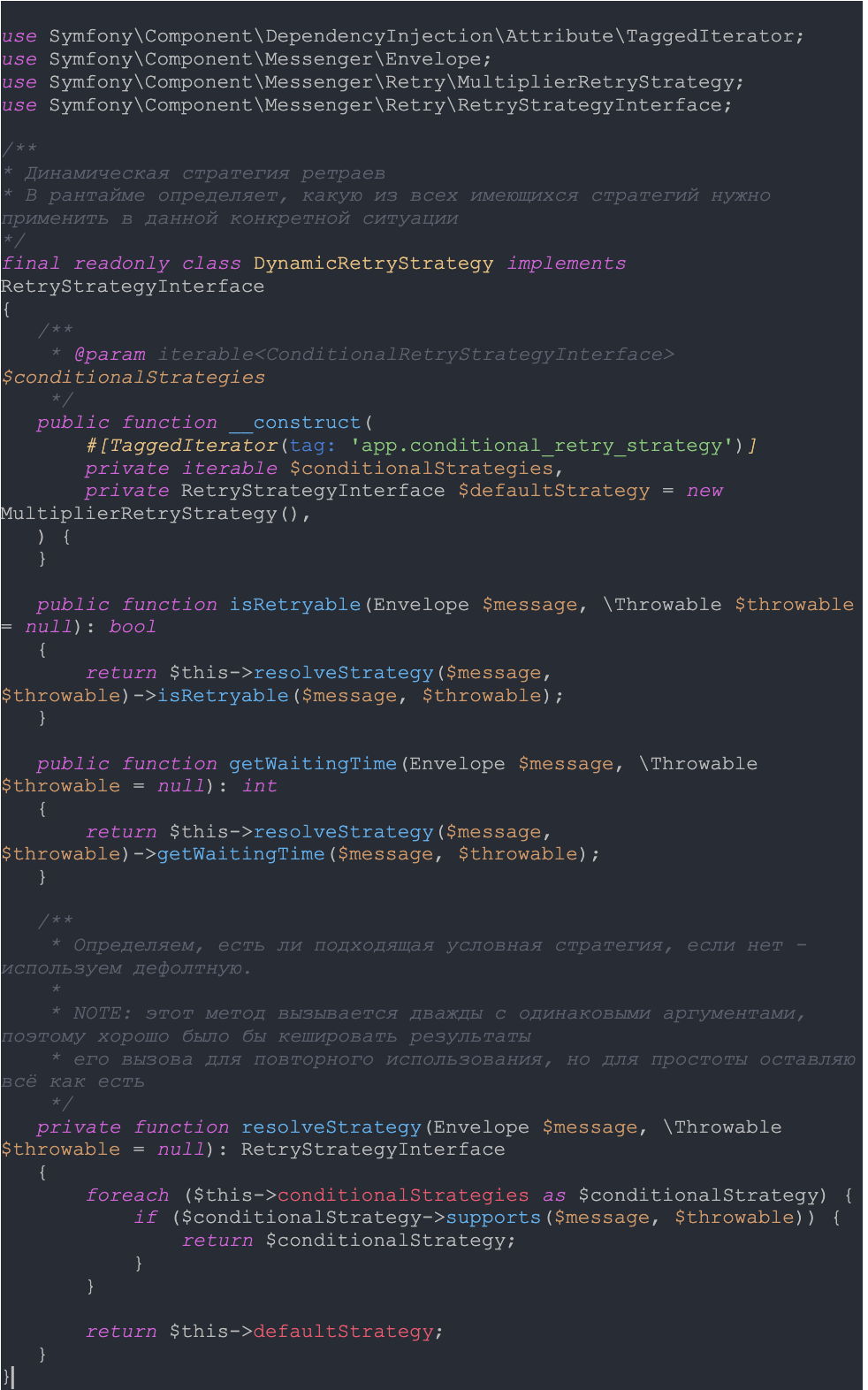
Теперь настроим эту стратегию для нашего async-транспорта:
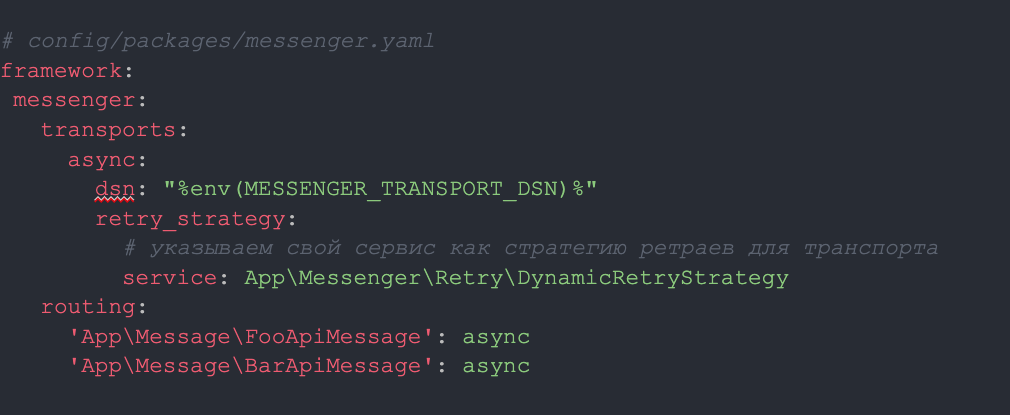
Почти всё! Последнее, что осталось, это непосредственно создать столько реализаций ConditionalRetryStrategyInterface, сколько потребуется под ваши конкретные сценарии.
Для примера реализую условную стратегию ретраев для обработки TooManyApiRequestsException:
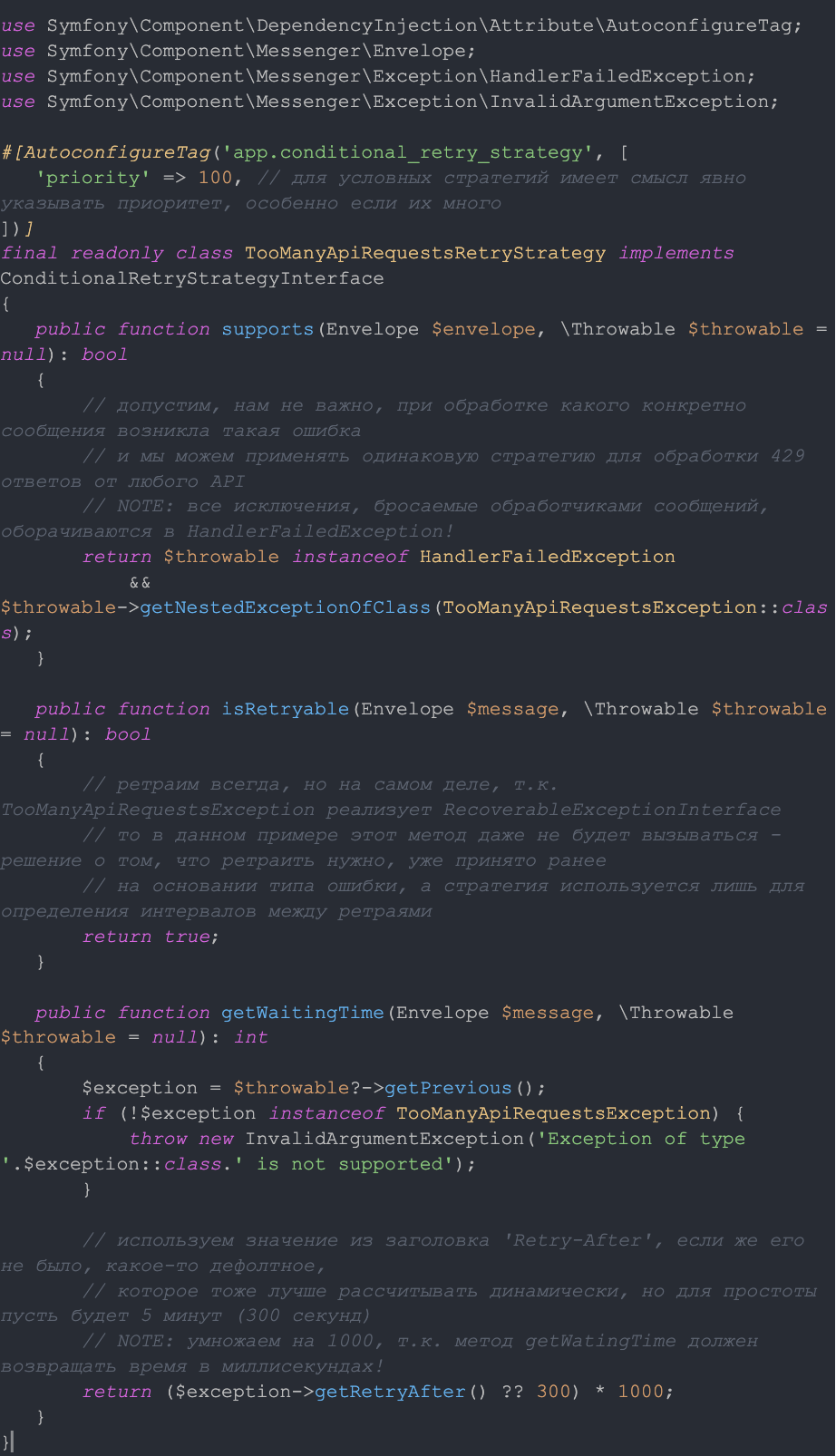
Вот теперь всё!
Возможности и ограничения
На примере с «динамической» стратегией ретраев хорошо видно, какую гибкость предоставляет механизм ретраев в Symfony Messenger!
Можно создать дефолтную стратегию, а специфичные кейсы реализовывать как «условные» стратегии, в которых для реализации логики ретрая можно использовать само сообщение, объект исключения и даже штампы из Envelope.
Дополнительным бонусом идёт возможность легко переиспользовать логику ретраев для определённых ошибок, требующих одинаковой обработки независимо от сообщения или деталей работы с конкретным API, чего заметно сложнее добиться используя множество отдельных транспортов и ретрай стратегий.
С другой стороны, следует учитывать, что для вызова метода ConditionalRetryStrategyInterface: supports в процессе обхода tagged-итератора $conditionalStrategies (а под капотом там \Generator) создаются инстансы всех условных стратегий, которые потом хранятся в памяти (в сервис-контейнере). Вряд ли это может стать реальной проблемой, но при очень большом количестве условных стратегий это может привести к высокому потреблению оперативной памяти — это, как минимум, нужно учитывать.
Наиболее востребованным условным стратегиям стоит назначать более высокий приоритет, чтобы реже создавать объекты редко применяемых стратегий.
В целом же хорошее понимание механизма ретраев неуспешных сообщений и правильное его использование имеет важное значение, когда обработчик сообщения (handler) отправляет запросы к другим сервисам (на самом деле и в других случаях тоже).
Так, слишком частое и продолжительное использование ретраев является анти-паттерном получившем название Retry Storm. В результате таких ретраев сервис, принимающий запросы, может попросту не восстановиться после падения из-за чрезмерной нагрузки, вызванной шквалом повторных запросов — таких ситуаций следует избегать. Могу порекомендовать отличную статью от Яндекса о том, какие для этого есть способы.
Выводы
В этой статье мы подробно рассмотрели, как устроен и как работает механизм ретраев в Symfony Messenger, разобрали базовые конфигурации, их ограничения и нюансы, а также некоторые специфические сценарии, реализовали свою стратегию ретраев.
Надеюсь, вам это поможет избежать неожиданностей в рабочих проектах, использующих Symfony Messenger для работы с очередями сообщений, а также поможет в реализации специфичных для ваших проектов стратегий.
P.S. Как думаете, хорошо было бы иметь похожую на DynamicRetryStrategy функциональность в Symfony Messenger из коробки? Может, стоит доработать эту идею и создать PR с такой фичей?
