Компонентный подход к Ansible или как навести порядок в инфраструктурном коде
Привет, Хабр! Меня зовут Игорь Гербылев, я технический директор в компании Just AI. В этой статье я расскажу о методологии структурирования ansible плейбуков, которую мы называем »Компонентный ансибл». Этот подход позволил нам упростить разработку и поддержку большого объёма ансибл-кода, который мы используем для настройки инфраструктуры и развёртывания наших SaaS продуктов.
Продукты состоят из множества микросервисов, имеют множество инфраструктурных зависимостей. Дополнительную сложность составляет необходимость установки системы на множестве окружений в дата-центрах заказчиков. Разумеется, в каждом окружении есть свои особенности конфигурации, иногда отличается состав устанавливаемых компонентов (микросервисов).
Для того, чтобы поменьше путаться в этом богатстве конфигураций, мы применяем несколько особенных решений. Одно из них — это введение понятия »компонента конфигурации» и методология для работы с этими компонентами. Подробнее об этом подходе, его правилах и преимуществах и пойдёт речь в статье. Также я расскажу о некоторых best-practices, которые можно использовать при любом подходе к IaC разработке.
Зоопарк поддерживаемых программ
Для начала хотелось бы рассказать о зоопарке программ, которые мы поддерживаем:
Приложение на микросервисной архитектуре и несколько десятков микросервисов — большая часть на Java, некоторые на Python и пара экзотических;
Несколько баз данных и брокеров сообщений: postgres, mongodb, clickhouse, redis, kafka;
Несколько облачных боевых окружений. Активно используются (и обновляются) 4, но общее количество превышает 10;
В боевых установках все компоненты резервируются по два инстанса, некоторые компоненты отмасштабированы и запускаются по 5–10 экземпляров;
Бессчетное количество девелоперских, тестовых, интеграционных окружений. Их количество уже подбирается к 100;
Несколько различных дата-центров в разных регионах со своей спецификой.
Проблемы автоматизации и способы решения
Обслуживая достаточно развесистую систему мы применяем множество автоматизаций: ansible, terraform, docker — из основных, а теперь, конечно, ещё и kubernetes. Но тем не менее регулярно возникают одни и те же проблемы.
Основная звучит так: в некоторых случаях подход IaC не уменьшает суммарные трудозатраты на управление инфраструктурой, а делает этот процесс даже более сложным, чем при работе «вручную». Конкретные проявления были таковы:
Установка некоторых компонентов вручную, например, БД всё ещё происходит быстрее, чем с помощью плейбуков (потому что не доделаны);
Плейбуки некоторых компонентов правятся при каждом использовании (потому что не отлажены);
Каждому инженеру не нравится код соседа (потому что он не работает с первого раза);
Инженеры тратят очень много времени на изучение скриптов своих коллег (потому что нельзя просто взять и запустить, приходится подправлять);
Конфигурация регулярно разъезжается, и не всегда та, что в коде соответствует той, что на серверах.
Думаю, каждый инженер может дополнить этот список. Давайте обозначим причины:
Отсутствие или размытость стандартов написания инфраструктурного кода. Их наличие должно улучшить читаемость кода, упростить коммуникации между инженерами, и определить способы решения задач;
Качество инфраструктурного кода;
Cоответствие конфигурации реальной и закодированной.
Собственно, борьбой с этими первопричинами и обосновывается появление методики, в составе которой мы:
Разработали стандарт написания плейбуков;
Ввели чек-лист для »приёмки» новых плейбуков;
Ввели процедуры регулярной проверки.
Ключевым элементом подхода является понятие компонента. Компонент — это отдельный, атомарный элемент системы, который может быть установлен самостоятельно, отдельно от других компонентов.
Его введение является основополагающим, потому что деление по компонентам задаёт способы структурирования кода, его тестирования и описания конфигурации системы. Далее приводится набор правил и рекомендаций, цель которых — придать конфигурационным компонентам более строгие очертания и рассказать о том, как с ними работать эффективно.
Базовые принципы компонентного подхода
Компонентный подход мы создали для приведения ансибл-кода в полное соответствие перечисленным ниже правилам. Стоит отметить, что эти правила будут иметь смысл в любой методологии, но для нашего подхода они строго обязательны.
1. Никакой ручной конфигурации — всё через гит и через ансибл
Очевидный пункт, но не указать его нельзя. В нашем подходе мы добавляем ещё одно ограничение: любая модификация в инфраструктуре должна применяться командой вида:
ansible-playbook -i
То есть применением какого-то плейбука к конкретному инвентарю, возможно, с ограничениями по требуемым действиям для ускорения процесса. Но без каких-либо других дополнительных хитростей, вроде определения переменных в командной строке.
2. Система конфигурируется через инвентарь
Операционный инженер при совершении рутинных действий должен править только инвентарь, но никак не плейбуки/роли. Инвентарь — это декларативное описание конфигурации системы, а плейбук — инструмент для её применения. Плейбук, как инструмент, может быть написан, отлажен, задокументирован, обкатан и переиспользован на множестве окружений (инвентарей). Инвентарь сам является документацией к той системе, которую описывает.
3. Инвентарь должен иметь типовую структуру
Нам приходится оперировать множеством окружений, часть из которых примерно одинаковые (например, тестовые стенды), а некоторые отличаются довольно сильно (в частности, on-prem установки). И чтобы в них не запутаться и легко переключаться между инвентарями, хочется иметь типовую структуру инвентарей и одинаковое наименование хост-групп. Следуя нашей концепции, хост-группа становится отражением понятия типа компонента.
Имена хост-групп в инвентаре должны иметь строго заданный смысл, смысл этот приравнивается к понятию типа компонента. Для закрепления соответствия компонент-хостгруппа компоненты у нас представляются плейбуками, а не ролями, именно потому, что плейбук имеет привязку к хостгруппе, а роль — нет. Если нам требуется использовать стороннюю роль, то мы пишем плейбук-компонент, придумываем для него имя, это же имя указываем в hosts внутри этого плейбука, внутри пишем инклюд требуемой роли.
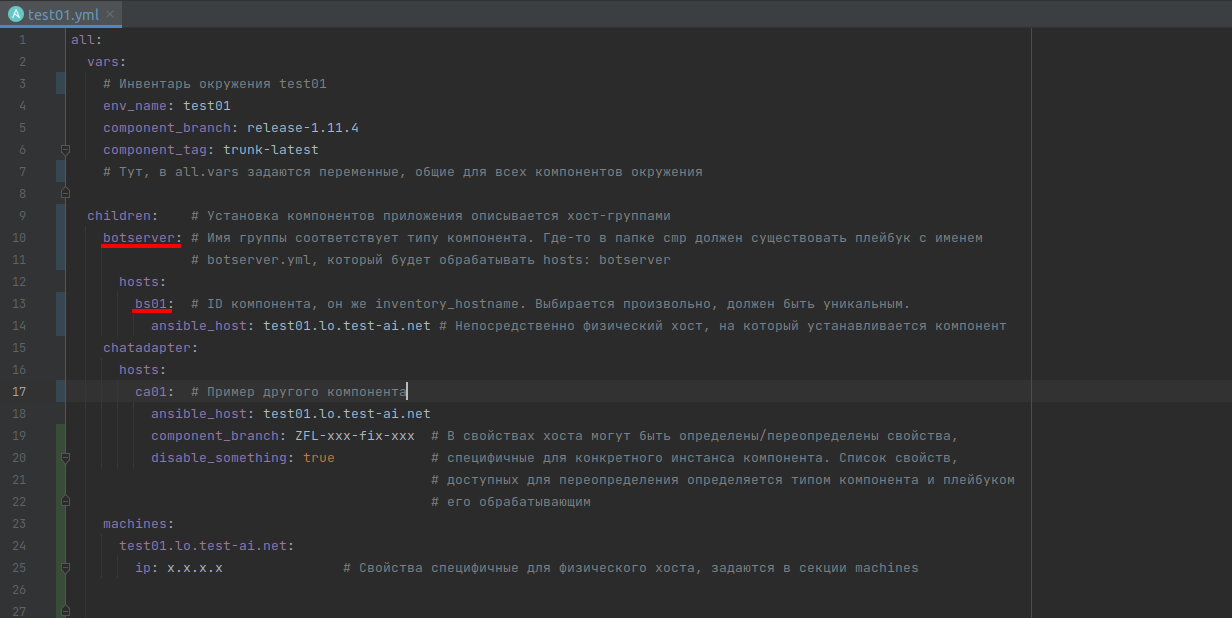
Пример инвентаря и плейбука с пояснениями

Пример инвентаря и плейбука с пояснениями
Про компоненты
В этом разделе описываются правила написания плейбуков, которые позволяют превратить плейбук в компонент. По сути, все эти правила относятся к структурированию кода, именованию и разделению ответственностей.
Принцип единственной ответственности
Один плейбук = один компонент = один элемент конфигурации.
Например: установка постгреса — один компонент, создание БД — другой, настройка бэкапов — третий.
Плейбук должен называться в соответствии с задачей, которую он выполняет
Каким бы удивительным ни был этот факт, но с файлами гораздо удобнее работать, когда они называются максимально точно и лежат в папках с говорящими названиями. Поэтому над системой именования нужно работать целенаправленно, согласовывать именования с командой, не оставлять файлов «назову_как_нибудь_другого_не_придумал». Если такие появляются, то хотя бы обсудите это с командой и донесите смысл этого названия до других. Отчасти этим требованием по именованию мотивируется предыдущий пункт про единственность ответственности — чем меньше людей делает компонент, тем проще для него подобрать название.
Один компонент = один хост
Один компонент = один хост. Или так: один компонент всегда должен иметь свой уникальный inventory_hostname, но при этом он может быть установлен на один физический хост вместе с другими компонентами. Достигается это путём указания параметра ansible_host при описании хоста-компонента.
Типовой фрагмент инвентаря, устанавливающий экземпляр какого-либо компонента куда-нибудь, выглядит так:
hosts:
ansible_host: <адрес физического хоста, на котором расположен компонент>
Другими словами: хостгруппа — это тип компонента, хост (inventory_hostname) — экземпляр компонента, id компонента. ID компонента должен быть уникальным в пределах инвентаря, при этом много компонентов может быть установлено на одном физическом сервере, это реализуется посредством указания ansible_host.
Про именование папок на диске и именование любых других ресурсов
Т.к. иногда нам приходится устанавливать на сервер по несколько компонентов одного типа, нам важно, чтобы папки нескольких инстансов одного и того же компонента не пересекались. Для именования папок рационально использовать component_id, он же inventory_hostname — т.к. это всегда уникальное имя в пределах одного окружения.
Стандартный шаблон имени папки из компонента deploy_compose выглядит так: {{component_name}}__{{component_id}}
Это предложение скорее рекомендация и относится, по большей части, к продуктовым микросервисам. Для инфраструктурных компонентов, например, postgres, mongo, prometheus и им подобных, нет прямой необходимости менять стандартные пути установки, особенно, если это требует существенных усилий.
О недопущении именования двух компонентов одинаковыми именами
Нужно внимательно относиться к уникальности компонент-хостнеймов, т.к. нарушение этого правила может вызвать трудно диагностируемые проблемы. Если в инвентаре появятся два хоста с одинаковым именем (в разных хост-группах), то их переменные смешаются и перетрут друг друга.
О раскладывании компонентов по папкам
Из принципа единственности ответственности вытекает то, что плейбуков у нас будет очень много. Чтобы не запутаться, надо структурировать, раскладывать их по папкам. У нас они такие: /cmp/app/
Получается, что обычные для ансибла соглашения о стандартных путях к плейбукам/файлам/темплейтам использовать не получится, поэтому мы сделаем свои соглашения и будем указывать пути всегда абсолютные, строя их от {{root_dir}}. root_dir — «магической переменной», указывающей на корень гит-репозитория того инвентаря, который мы сейчас обрабатываем. У нас она объявляется так:
root_dir:»{{ lookup ('pipe', 'git -C ' + (ansible_inventory_sources[0] | dirname) + ' rev-parse --show-toplevel') }}»
Про cmp-resources
Для удобства навигации по списку компонентов, файлы плейбуков и файлы ресурсов разделены. Разделены они примерно как java-исходники и файлы ресурсов в maven-проектах. Плейбуки у нас лежат в папке cmp, , а файлы ресурсов в папке cmp-resources. Если компонент использует какие-либо шаблоны или другие файлы-ресурсы, то они должны быть помещены в cmp-resources по пути, повторяющему путь к плейбуку в папке cmp. Т.е. в cmp-resources у нас появляется иерархия папок параллельная папкам в cmp.
Как выполнять действия, затрагивающие множество компонентов
Для этого у нас есть так называемые корневые плейбуки — обычно это длинный список инструкций import_playbook, в котором присутствуют все компоненты для конкретной задачи. Примером такого плейбука у нас является jaicp.yml. В сочетании с соответствующим инвентарём он выполнит полную установку нашего продукта JAICP, который состоит из нескольких баз данных и множества микросервисов.
Корневой плейбук отличается от компонентов тем, что он не инклюдится куда-либо еще, а также находится либо в корневой папке репозитория, либо в папке plays/.
Ограничение выполнения
Для лимитирования выполнения, т.е. для выполнения определённых действий и только на определенных компонентах делаем следующее:
Катим корневой плейбук;
Ограничение по хостам задает список компонентов, которые хотим затронуть. Не надо забывать о возможности использования звёздочек и запятых. Например: -l bs01 -l bs* -l ed*, ba*. В сочетании со строгими правилами именования хостов-компонентов получается очень удобным;
Ограничение по тэгам задает действие, которое мы собираемся выполнить. Например: только срендерить конфигурации, или только перезапустить компонент, или остановить\ удалить компонент. Например: -t render, -t push, -t restart.
Чек-лист разработки компонента
В этом разделе приводится список пунктов, которым должен удовлетворять качественно сделанный компонент-плейбук. При полноценном внедрении компонентного подхода (и наличии ресурсов для этого), этот список можно использовать как чек-лист для внутренней приемки вновь разрабатываемых плейбуков, например, на этапе код-ревью.
Чек-мод
Чекмод важен, а идемпотентность — обязательное свойства хорошего плейбука. Любой разрабатываемый компонент-плейбук обязан:
При повторной прокатке показывать changes=0;
При изменении конфигурации в инвентаре и последующей прокатке с -D показывать диф по конфигурационным файлам, которые он меняет;
В некоторых случаях, например, при установке кластера базы данных, чек-мод может быть реализован несколько иначе, чем непосредственно накатка сервиса. Например, мы можем подключиться к кластеру и проверить количество узлов в кластере, и основываясь на этом сделать вывод, что реальная конфигурация соответствует требуемой. Аналогично при создании баз данных: создание выполняется командой create_db, а в check mode мы пропускаем create_db, но пытаемся залогиниться в созданную БД с указанными кредами.
Документация
На каждый плейбук-компонент должна быть страничка документации (или секция комментариев), объясняющая, что этот компонент делает, зачем нужен, как работает, а также должны быть перечислены примеры применения.
Чек-лист документации:
Общее описание — что за компонент, зачем нужен;
Список конфигурационных переменных, которые может определять пользователь;
Приведённый фрагмент инвентаря, показывающий типовой вариант использования;
Перечисление тегов, если они есть и их назначение.
Все это нужно записывать документацию в шапке, в начале плейбука. Для корневых плейбуков должно быть указано, к каким инвентарям их можно применять и как лимитировать выполнение.
Дефолтные переменные
Список переменных, доступных для переопределения пользователем, определяется в начале плейбука в секции vars в следующем виде: _componentName_varName: componentName_varName | default (def), при том, что далее в тасках и темплейтах используются переменные с префиксом _. Переменная с префиксом _ трактуется как приватная, внутренняя переменная. Без префикса — глобальная, внешняя.
Дефолтные значения можно (но не рекомендуется) указывать в месте использования, но при условии, что:
а) Переменная используется только в одном месте;
б) Список переменных, доступных для переопределения пользователем, описан в документации.
Универсальность в плане конфигурации, адаптация при установке
Компоненты должны вставать на все поддерживаемые ОС, со всеми типами развертывания. Соответственно, чем меньше у вас ОС и способов развертывания, тем проще будет ваш IaC. По возможности, размер зоопарка надо уменьшать.
Регулярные проверки
Чтобы быть уверенными в том, что конфигурация на наших серверах, управляемых через ansible, действительно соответствует тому, что закодировано в плейбуках и инвентарях и залито в гитхаб, мы регулярно выполняем прокатку плейбуков с опциями -CD.
Делать это стоит не только при обновлении плейбуков или инвентарей, а по расписанию. И крайне желательно сделать так, чтобы отсутствие зелёного прогона check-mode являлось блокером для выполнения автоматических модификаций на серверах. Если это правило ничего не блокирует, то его легко проигнорировать.
Регулярные проверки 2
Для того, чтобы быть полностью уверенными в работоспособности своих инструментов, недостаточно выполнять только чек-мод. Крайне желательно построить CI-стенды, на которых на регулярной основе будет выполняется прокатка основных конфигураций, начинающаяся с полного форматирования или пересоздания хоста. Такие проверки также стоит проводить по расписанию, потому что иногда они ломаются. Не от изменений в вашем коде, а из-за того, например, что во внешнем мире вышла новая версия какого-нибудь пакета, а у вас версия не была зафиксирована. Или наоборот, какой-нибудь старый пакет удалился из публичных репозиториев.
Заключение
Со временем проблемы, обозначенные в начале статьи, уже перестали быть для нас проблемами, со сложностями мы успешно справились. Сейчас мы все более активно используем kubernetes, и некоторые проблемы решает сам kubernetes и helm. Тем не менее, статья не теряет актуальности, потому что и сервера и кубер-кластер мы сетапим все также через terraform+ansible.
Эта версия статьи сокращена примерно на треть в угоду краткости. В частности, здесь я исключил секцию про инфраструктурные компоненты используемые для начального сетапа серверов, они у нас имеют свои особенности. Если вам будет интересно, то опубликую и остальной материал отдельной статьей.
Прошу вас поделиться мыслями о том, какие из приведенных правил кажутся вам полезными, какие сомнительными. Также буду благодарен за ссылки на другие существующие методологии для построения большого объёма кода на ансибл.
