Страх и ненависть Threat Intelligence или 8 практических советов по работе с TI

У нас было две коммерческих APT-подписки, десять информационных обменов, около десяти бесплатных фидов и список exit-node Тора. А еще пяток сильных реверсеров, мастер powershell-скриптов, loki-scanner и платная подписка на virustotal. Не то чтобы без этого центр мониторинга не работает, но если уж привык ловить сложные атаки, то приходится идти в этом увлечении до конца. Больше всего нас волновала потенциальная автоматизация проверки на индикаторы компрометации. Нет ничего более безнравственного, чем искусственный интеллект, заменяющий человека в работе, где надо думать. Но мы понимали, что с ростом количества заказчиков мы рано или поздно в это окунемся.
Многие говорят, что Threat Intelligence — это вкусно, но не все до конца понимают, как его готовить. Еще меньше тех, кто разбирается, какие процессы нужно выстраивать, чтобы TI работал и приносил profit. И совсем мало кто знает, как выбрать поставщика фидов, где проверить индикатор на фолсы и нужно ли блокировать домен, который прислал коллега в WhatsApp.
За несколько лет постоянной работы с TI мы успели пройтись по разным граблям и сегодня хотим дать несколько практических советов, которые помогут новичкам избежать ошибок.
Совет №1. Не питайте больших надежд что-то поймать по хешу: большая часть вредоносного ПО уже давно полиморфна
В прошлой статье мы рассказывали о том, что такое TI, и привели несколько примеров организации процесса работы. Напомню, что информация об угрозах (threat intelligence) поступает в разных форматах и представлениях: это могут быть и IP-адреса центров управления ботнетами, и email-адреса отправителей фишинговых писем, и статьи, описывающие техники обхода средств защиты, которые APT-группировки вот-вот начнут использовать. В общем, много чего бывает.
Чтобы упорядочить все это безобразие, несколько лет назад Дэвид Бианко предложил так называемую «пирамиду боли». Она довольно неплохо описывает отношение между типами индикаторов, которые вы используете для детектирования атакующего, и тем, сколько боли вы доставите атакующему, если сможете детектировать конкретный тип индикатора.
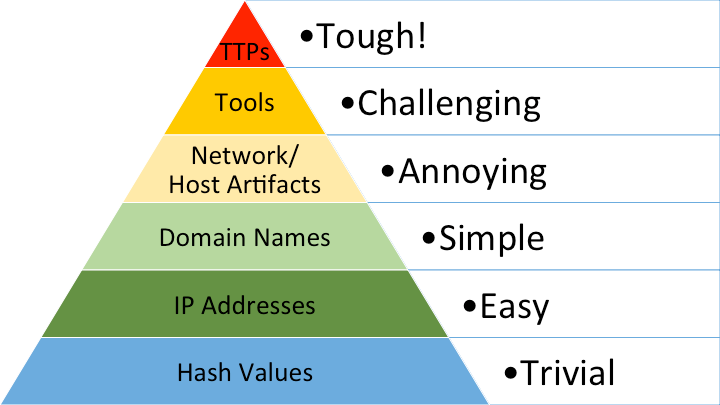
Например, если вы знаете MD5-хеш вредоносного файла, его можно довольно легко и при этом точно задетектировать. Однако это принесет очень мало боли атакующему — достаточно добавить 1 бит информации к файлу, и хеш уже другой.
Совет №2. Старайтесь использовать те индикаторы, смена которых будет сложна технически или невыгодна экономически для атакующего
Предвосхищая вопрос о том, как узнать, есть ли файл с данным хешом на АРМах нашего предприятия, отвечаю: существуют разные способы. Один из самых простых — это установка Kaspersky Security Center, который содержит базу MD5-хешей всех исполняемых файлов на предприятии, к которой можно сделать SELECT.
Вернемся к пирамиде боли. В отличие от детектирования по хешу, будет более продуктивно, если вы сможете задетектировать TTP (тактику, технику, процедуру) атакующего. Это сложнее и требует больше усилий, но зато и боли вы доставите больше.
Например, если вы знаете, что APT-группировка, нацеленная на ваш сектор экономики, распространяет фишинговые письма с *.HTA файлами, разработка правила детектирования, которое ищет файлы в почте с подобными вложениями, сильно ударит по атакующему. Ему придется изменить тактику рассылки, возможно, даже вложив кровные $ в покупку 0-day или 1-day эксплойтов, а это недешево…
Совет №3. Не питайте больших надежд относительно правил детектирования, которые разработали не вы, их придется проверять на ложные срабатывания и дорабатывать

При разработке правил детектирования всегда есть соблазн использовать готовые правила. Бесплатным примером может служить репозиторий Sigma — SIEM-независимый формат правил детектирования, который позволяет транслировать правила из языка Sigma в запросы ElasticSearch и правила Splunk или Arcsight. При этом репозиторий содержит около 200 правил, из которых ~130 описывают атаки на Windows. На первый взгляд, очень круто, но дьявол, как всегда, в деталях.
Давайте взглянем детально на одно из правил детектирования mimikatz:
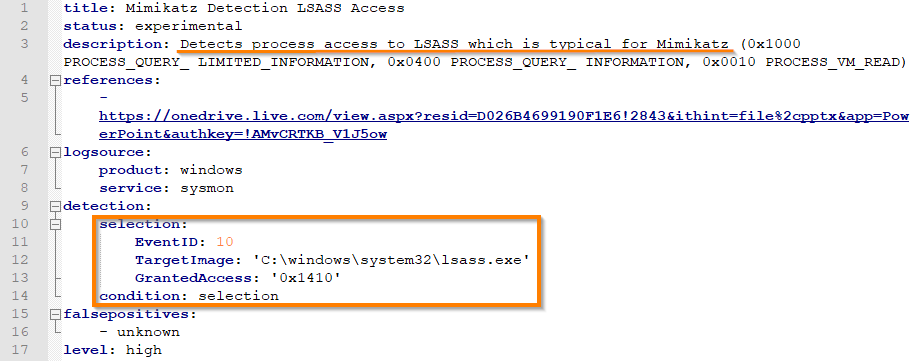
Правило детектирует процессы, которые попытались прочитать память процесса lsass.exe. Mimikatz делает это, когда пытается получить NTLM-хеши, и правило задетектирует вредонос.
Однако нам, как специалистам, которые занимаются не только детектированием, но и реагированием на инциденты, крайне важно, чтобы это был действительно mimikatz. К сожалению, на практике существует множество других легитимных процессов, которые читают память lsass.exe с этими же масками (некоторые антивирусы, например). Поэтому в реальной боевой среде подобное правило принесет больше ложных срабатываний, чем пользы.
Бывают и еще более интересные казусы, связанные с автоматической трансляцией правил из Sigma в правила SIEM:

На одном из вебинаров коллеги из SOC Prime, поставляющие платные правила детектирования, показали нерабочий пример подобной трансляции: поле deviceProduct в SIEM должно быть одновременно равно и Sysmon, и Microsoft Windows, что невозможно.
Не хочу никого винить и тыкать пальцем — все фолсят, это нормально. Однако потребителям Threat Intelligence нужно понимать, что перепроверка и доработка правил, получаемых как из открытых, так и закрытых источников, все-таки необходима.
Совет № 4. Проверяйте доменные имена и IP-адреса на вредоносность не только на прокси-сервере и межсетевом экране, но и в журналах DNS-серверов, уделяя внимание как удачным, так и неудачным попыткам резолва
Вредоносные домены и IP-адреса — это оптимальный индикатор с точки зрения простоты детектирования и количества боли, которую вы доставите атакующему. Но и с ними все просто только на первый взгляд. Как минимум, стоит задаться вопросом, откуда забирать журнал доменов.
Если ограничиться проверкой только журналов прокси-серверов, можно упустить вредоносное ПО, которое пытается обратиться напрямую в сеть или запрашивает несуществующее доменное имя, сгенерированное по DGA, не говоря уже про DNS-туннели — всего этого не будет в журналах корпоративного прокси-сервера.
Совет №5. «Мониторить нельзя блокировать» — ставьте запятую только после того, как вы узнали, что это за индикатор, и осознали возможные последствия блокировки

Перед каждым практикующим безопасником вставал сложный вопрос: блокировать угрозу или мониторить и при наличии сработок начинать расследование? В некоторых регламентах и инструкциях прямо пишут — блокировать, и иногда такое действие ошибочно.
Если индикатор — это доменное имя, используемое APT-группировкой, не ставьте его на блокировку, а начните мониторинг. Современные тактики целевых атак подразумевают наличие дополнительного скрытного резервного канала связи, выявить который можно только в ходе детального расследования. Автоматическая блокировка в данном случае будет препятствовать поиску этого канала, да и товарищи с другой стороны баррикад быстро поймут, что вы узнали о их деятельности.
С другой стороны, если индикатор — это домен шифровальщика, то его уже стоит поставить на блокировку. Но не забывайте производить мониторинг неуспешных попыток обращения к заблокированным доменам — в конфигурацию шифровальщика может быть встроено несколько адресов серверов управления. Часть из них может отсутствовать в фидах и соответственно не будет заблокирована. Рано или поздно зловред обратится к ним для получения ключа, которым моментально зашифрует хост. Гарантировать, что вы заблокировали все адреса сервера управления, может только реверс-анализ образца.
Совет №6. Проверяйте все поступающие индикаторы на релевантность перед постановкой их на мониторинг или блокировку
Помните, что информацию об угрозах создают люди, которым свойственно ошибаться, или алгоритмы machine learning, которые тем более от этого страдают. Мы уже были свидетелями того, как разные поставщики платных отчетов о деятельности APT-группировок случайно добавляют в списки вредоносных MD5 вполне легитимные образцы. Если даже платные отчеты об угрозах содержат некачественные индикаторы, что говорить об индикаторах, добытых с помощью разведки в открытых источниках. TI-аналитики далеко не всегда проверяют создаваемые ими индикаторы на ложные срабатывания, в результате подобная проверка ложится на плечи потребителя.
Например, если вам пришел IP-адрес очередной модификации Zeus или Dimnie, перед тем как использовать его в системах детектирования проверьте, не является ли он частью хостинга или сервисом, который говорит ваш IP. Иначе будет неприятно разбирать огромное количество ложных срабатываний, когда пользователи сайта, размещенного на этом хостинге будут заходить на совершенно невредоносные сайты. Подобную проверку можно легко выполнить с помощью:
- Сервисов категоризации, которые скажут вам о роде деятельности сайта. Например, ipinfo.io прямо напишет type: «hosting».
- Сервисов Reverse IP, которые подскажут, сколько доменов зарегистрировано на данном IP-адресе. Если их много, с высокой вероятностью перед вами хостинг сайтов.
Вот так, например, выглядит результат проверки индикатора, который является индикатором APT-группировки Cobalt (согласно отчету одного уважаемого TI-вендора):
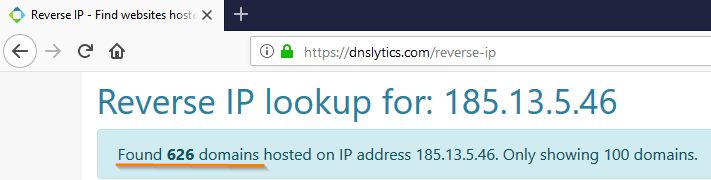
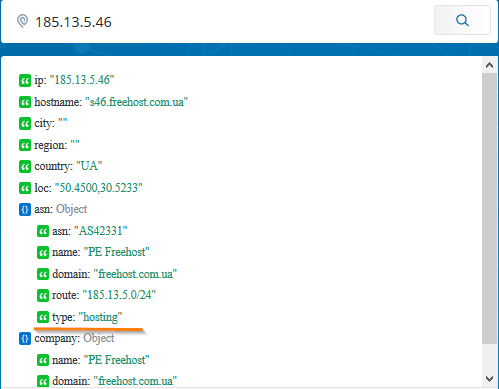
Мы, специалисты по реагированию, понимаем, что господа из Cobalt наверняка использовали этот IP-адрес. Однако пользы от данного индикатора нет — он нерелевантен, потому что дает слишком много ложных срабатываний.
Совет №7. Максимально автоматизируйте все процессы работы с информацией об угрозах. Начните с простого — полностью автоматизируйте проверку на ложные срабатывания через стоп-список с дальнейшей постановкой нефолсящих индикаторов на мониторинг в SIEM
Предотвратить большое количество ложных срабатываний, связанных с intelligence и полученных из открытых источников, может предварительный поиск этих индикаторов в стоп-списках (warning lists). Подобные списки можно сформировать на основе рейтинга Alexa (топ-1000), адресов внутренних подсетей, доменов крупных провайдеров сервисов вроде Google, Amazon AWS, MS Azure и других хостингов. Также крайне эффективным будет решение, которое динамически изменяет стоп-списки, состоящие из топа доменов/IP адресов, на которые ходили сотрудники компании в последнюю неделю или месяц.
Разработка подобных списков и системы проверки может быть затруднительна для среднего SOC, поэтому здесь имеет смысл задуматься о внедрении так называемых Threat Intelligence-платформ. Примерно полгода назад на Anti-malware.ru был хороший обзор платных и бесплатных решений подобного класса.
Совет №8. Сканируйте на хостовые индикаторы все предприятие, а не только хосты, которые подключены к SIEM
Ввиду того, что, как правило, не все хосты предприятия подключены к SIEM, проверить их на наличие вредоносного файла с определенным именем или путем, используя только стандартный функционал SIEM, не представляется возможным. Выкрутиться из этой ситуации можно следующими способами:
- Использовать IoC-сканеры наподобие Loki. Запустить его на всех хостах предприятия можно через тот же SCCM, а вывод перенаправить на общедоступную сетевую папку.
- Использовать сканнеры уязвимостей. Некоторые из них имеют compliance-режимы, в которых можно проверить наличие конкретного файла по конкретному пути.
- Написать powershell-скрипт и запустить его через WinRM. Если писать самим лень, можно использовать один из многочисленных скриптов, например, вот этот.
Как я уже сказал в начале, данная статья не подразумевает исчерпывающую информацию по тому, как правильно работать с Threat Intelligence. Однако, по нашему опыту, соблюдение даже этих простых правил позволит новичкам не наступать на грабли и начать сразу с эффективной работы с различными индикаторами компрометации.
