Развитие баз данных в Dropbox. Путь от одной глобальной базы MySQL к тысячам серверов
Когда только Dropbox запустился, один пользователь на Hacker News прокомментировал, что реализовать его можно несколькими bash-скриптами с помощью FTP и Git. Сейчас такого сказать никак нельзя, это крупное облачное файловое хранилище с миллиардами новых файлов каждый день, которые не просто как-то хранятся в базе данных, а так, что любую базу можно восстановить на любую точку в течение последних шесть дней.
Под катом расшифровка доклада Славы Бахмутова (m0sth8) на Highload++ 2017, о том, как развивались базы данных в Dropbox и как они устроены сейчас.
О спикере: Слава Бахмутов — site reliability engineer в команде Dropbox, очень любит Go и иногда появляется в подкасте golangshow.com.
Содержание
Архитектура Dropbox простым языком
Dropbox появился в 2008 году. По сути, это облачное файловое хранилище. Когда только Dropbox запустился, пользователь на Hacker News прокомментировал, что реализовать его можно несколькими баш-скриптами с помощью FTP и Git. Но, тем не менее, Dropbox развивается, и сейчас это достаточно крупный сервис c более чем 1,5 миллиардами пользователей, 200 тысячами бизнесов и огромным количеством (несколько миллиардов!) новых файлов каждый день.
Как выглядит Dropbox? 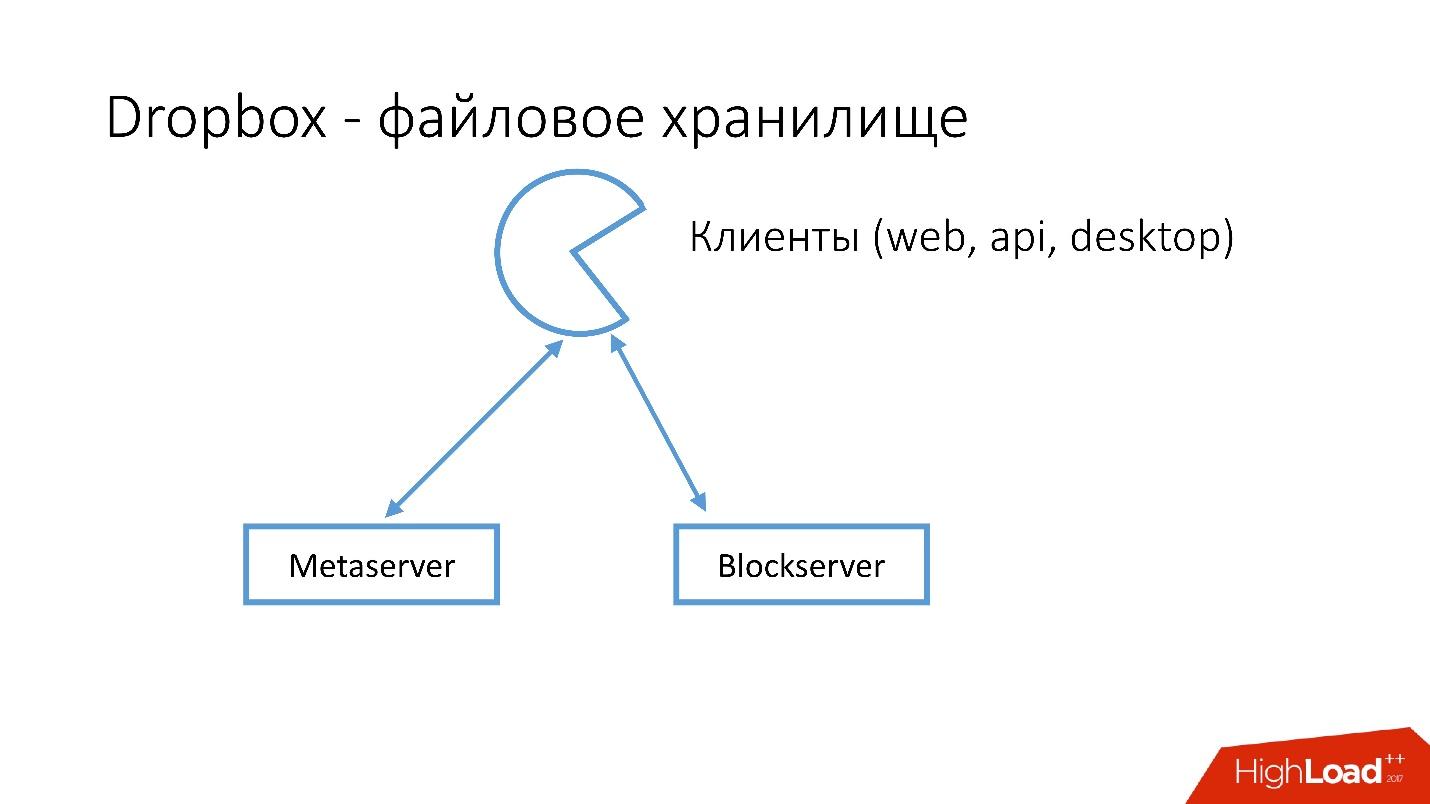
У нас есть несколько клиентов (web интерфейс, API для приложений, которые пользуются Dropbox, desktop-приложения). Все эти клиенты используют API и общаются с двумя большими сервисами, которые логически можно разделить на:
- Metaserver.
- Blockserver.
На Metaserver хранится метаинформация о файле: размер, комментарии к нему, ссылки на этот файл в Dropbox и т.п. В Blockserver хранится информация только о файлах: папки, пути и т.д.
Как это работает?
Например, у вас есть файл video.avi с каким-то видео. Ссылка со слайда
Ссылка со слайда
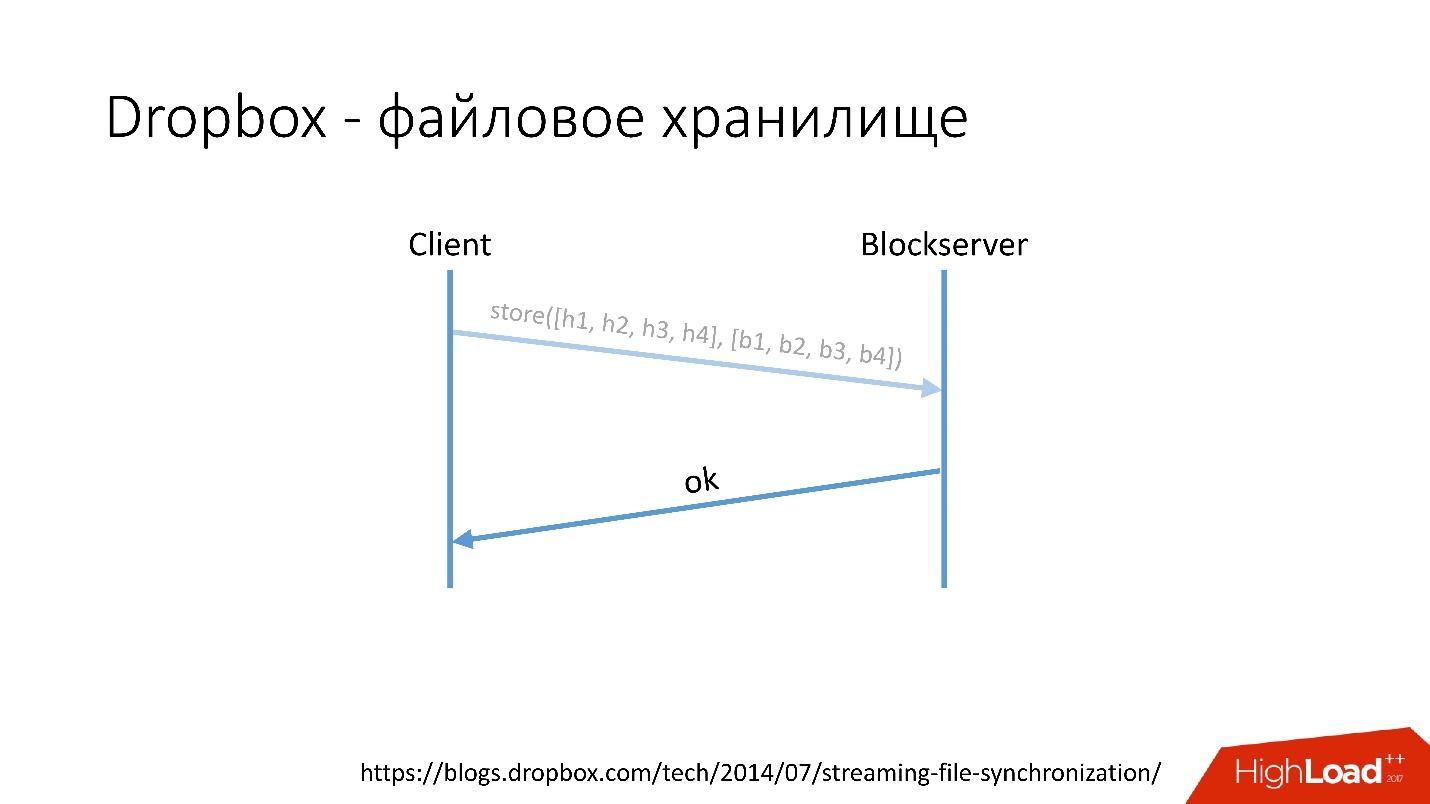
- Клиент дробит этот файл на несколько чанков (в данном случае по 4 МБ), подсчитывает контрольную сумму и отправляет к Metaserver запрос: «У меня есть файл *.avi, я хочу его загрузить, хэш-суммы такие-то».
- Metaserver возвращает ответ: «У меня нет этих блоков, давай загрузи!» Либо он может ответить, что у него есть все или некоторые блоки, и нужно загрузить только оставшиеся.
 Ссылка со слайда
Ссылка со слайда
- После этого клиент идет в Blockserver, отправляет хэш-сумму и сам блок данных, который сохраняется на Blockserver.
- Blockserver подтверждает операцию.
 Ссылка со слайда
Ссылка со слайда
Конечно, это очень упрощенная схема, протокол намного сложней: там есть синхронизация между клиентами внутри одной сети, есть драйверы ядра, возможность разрешать коллизии и т.д. Это достаточно сложный протокол, но схематически он работает примерно так.
Когда клиент сохраняет что-то на Metaserver, вся информация попадает в MySQL. Blockserver информацию о файлах, о том, как они структурированы, из каких блоков состоят, тоже хранит в MySQL. Также Blockserver хранит сами блоки в Block Storage, который в свою очередь информацию о том, где лежит какой блок, на каком сервере и как он обработан в данный момент, тоже сохраняет в MYSQL.
Для хранения экзабайтов пользовательских файлов мы параллельно сохраняем дополнительную информацию в базу данных на несколько десятков петабайт, раскиданных по 6 тысячам серверов.
История развития баз данных
Как развивались базы данных в Dropbox? 
В 2008 году все начиналось с одного Metaserver и одной глобальной базы данных. Всю информацию, которую Dropbox нужно было куда-то сохранять, он сохранял в единственный глобальный MySQL. Так продолжалось недолго, потому что количество пользователей росло, и отдельные базы и таблички внутри баз разбухали быстрее, чем другие.
Поэтому в 2011 году несколько таблиц были вынесены на отдельные сервера:
- User, с информацией о пользователях, например, логинами и oAuth токенами;
- Host, с информацией о файлах от Blockserver;
- Misc, которая не участвовала в обработке запросов с продакшена, но использовалась для служебных функций, вроде batch jobs.
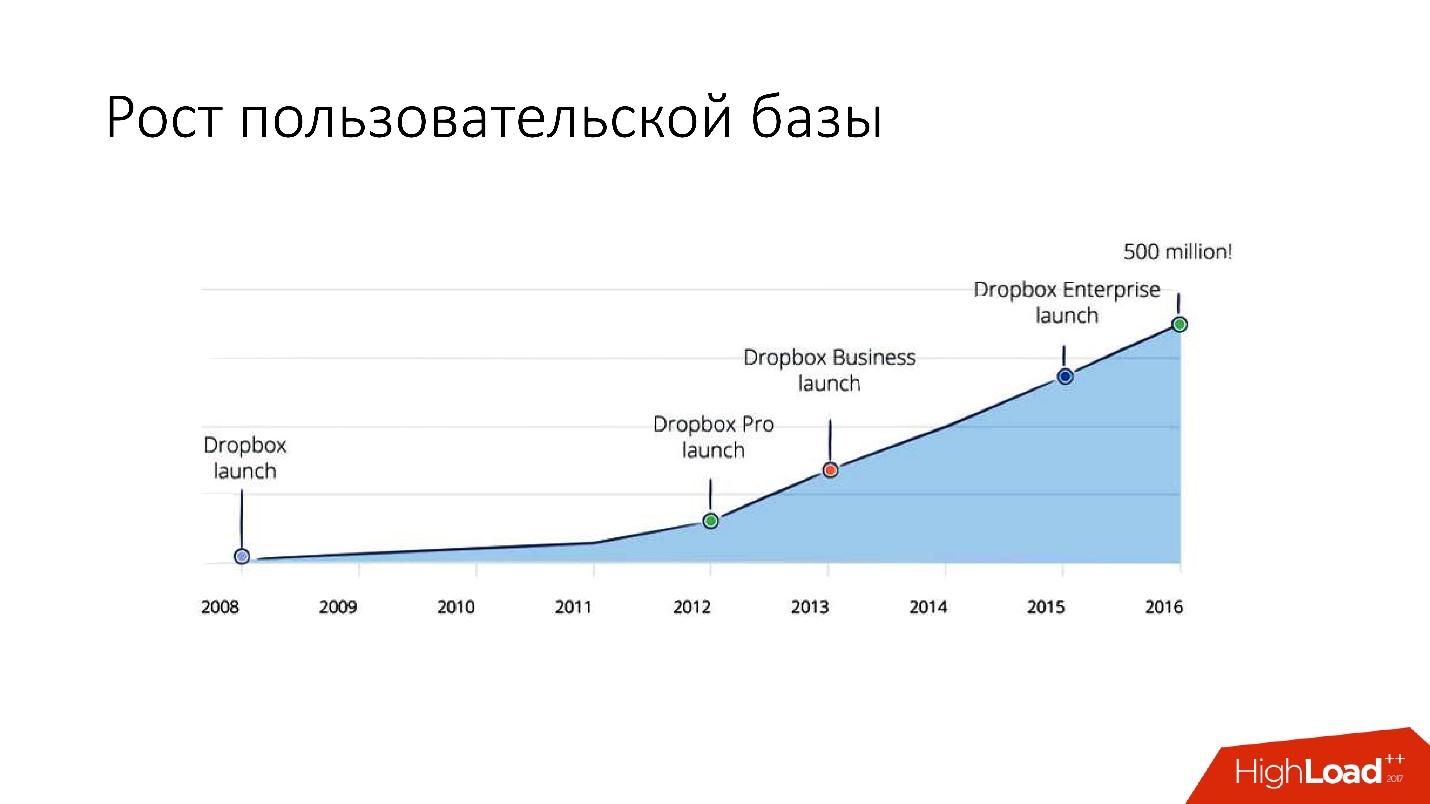
Но после 2012 года Dropbox начал очень сильно расти, с тех пор мы растем примерно на 100 млн пользователей в год.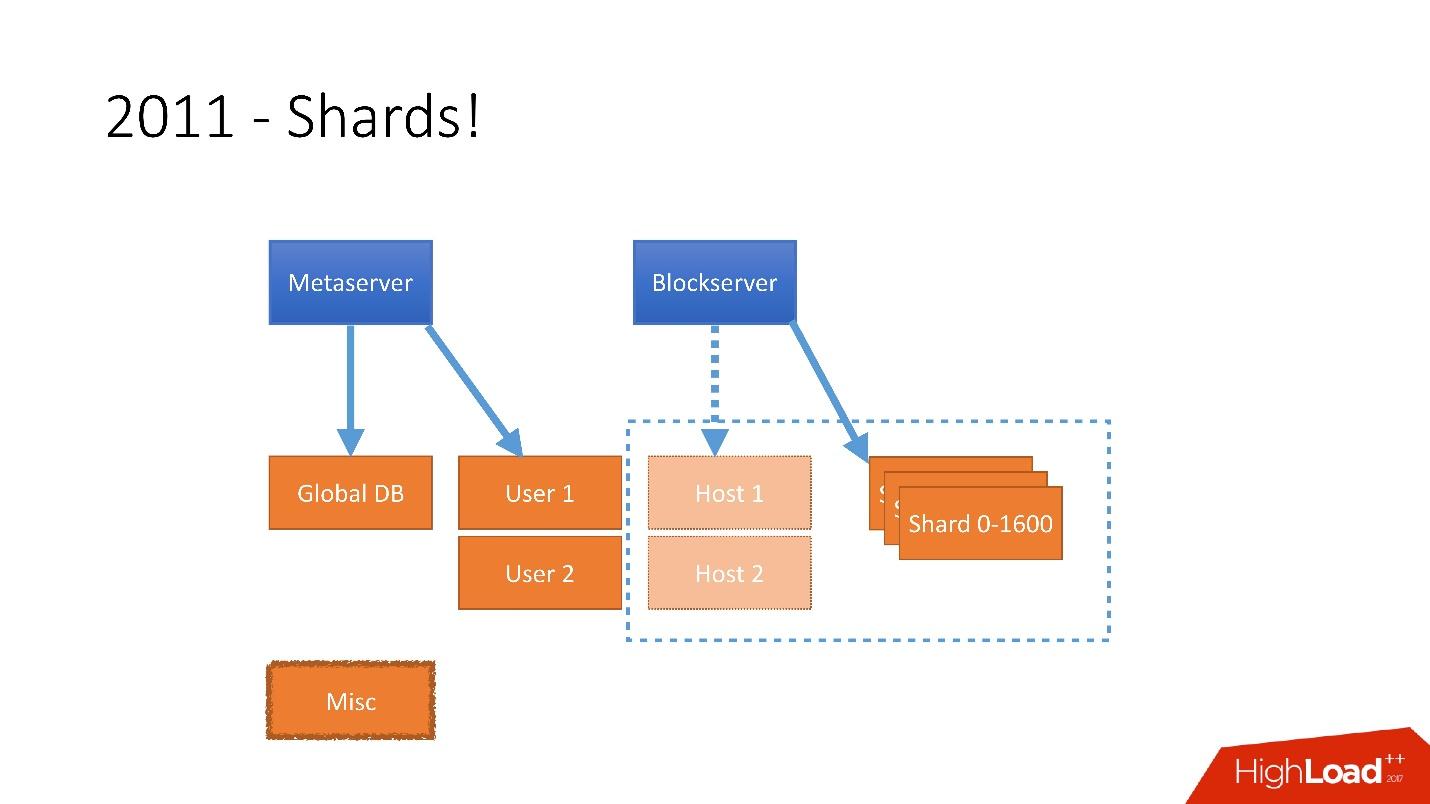
Нужно было учитывать такой огромный рост, и поэтому в конце 2011 года у нас появились шарды — база, состоящая из 1 600 шардов. Изначально всего 8 серверов по 200 шардов на каждом. Сейчас это 400 мастер-серверов по 4 шарда на каждом.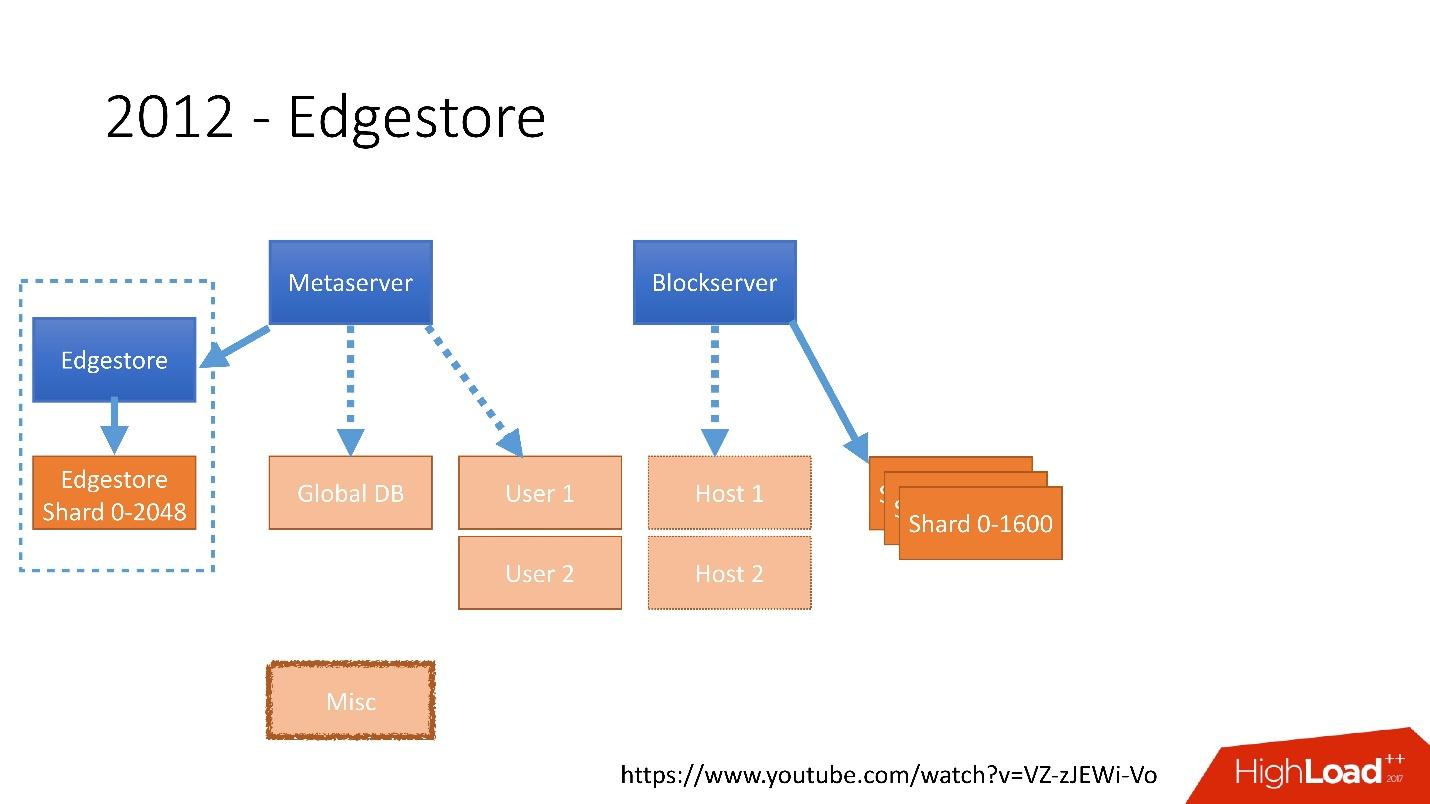 Ссылка со слайда
Ссылка со слайда
В 2012 году мы поняли, что создавать таблицы и обновлять их в БД на каждую добавляемую бизнес-логику очень сложно, муторно и проблематично. Поэтому в 2012 году мы изобрели свой собственный графовый storage, который назвали Edgestore, и с тех пор вся бизнес-логика и метаинформация, которую генерирует приложение сохраняется в Edgestore.
Edgestore, по сути, абстрагирует MySQL от клиентов. У клиентов есть некие сущности, которые соединены между собой ссылками из gRPC API к Edgestore Сore, который преобразует эти данные в MySQL и каким-то образом там хранит их (в основном он отдает все это из кэша).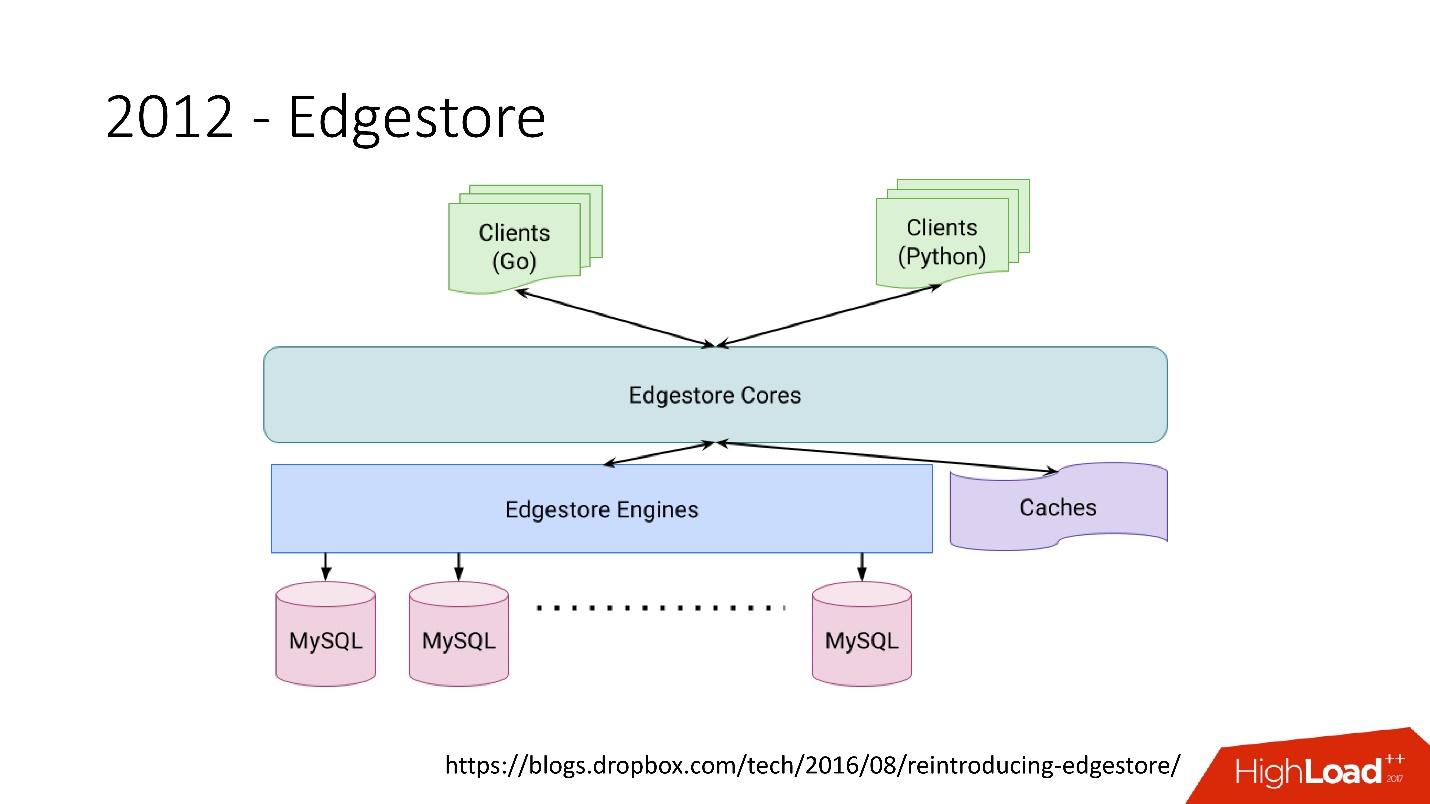 Ссылка со слайда
Ссылка со слайда
В 2015 году мы ушли с Amazon S3, разработали собственное облачное хранилище под названием Magic Pocket. В нем информация о том, где какой блок-файл находится, на каком сервере, о перемещениях этих блоков между серверами, хранится в MySQL. Ссылка со слайда
Ссылка со слайда
Но MySQL используется очень хитрым образом — по сути, как большая распределеннуя хэш-таблица. Это очень разная нагрузка, в основном, на чтение случайных записей. 90% утилизации это I/O.
Архитектура баз данных
Во-первых, мы сразу же определили некие принципы, по которым строим архитектуру нашей базы данных:
- Надежность и долговечность. Это самый главный принцип и то, чего от нас ждут клиенты — данные не должны теряться.
- Оптимальность решения — не менее важный принцип. Например, бэкапы должны делаться быстро и восстанавливаться тоже быстро.
- Простота решения — как архитектурно, так и с точки зрения обслуживания и дальнейшей поддержки разработки.
- Стоимость владения. Если что-то оптимизирует решение, но стоит очень дорого, это нам не подходит. Например, slave, который отстает от master на день, очень удобен для бэкапов, но тогда к 6 000 серверов нужно добавить еще 1 000 — стоимость владения таким slave очень высока.
Все принципы должны быть верифицируемыми и измеряемыми, то есть на них должны быть метрики. Если речь идет о стоимости владения, то мы должны посчитать, сколько у нас серверов, например, уходит под базы данных, сколько серверов уходит под бэкапы, и сколько это в итоге стоит для Dropbox. Когда мы выбираем новое решение, мы подсчитываем все метрики и ориентируемся на них. При выборе любого решения мы полностью руководствуемся этими принципами.
Базовая топология
База данных устроена примерно следующим образом:
- В основном дата-центре у нас есть master, в который происходят все записи.
- У master-сервера есть два slave-сервера, на которые происходит semisync репликация. Серверы часто умирают (порядка 10 в неделю), поэтому нам необходимо два slave-сервера.
- Slave-серверы находятся в отдельных кластерах. Кластеры — это совершенно отдельные комнаты в дата-центре, которые не связаны друг с другом. Если одна комната сгорает, вторая остается вполне себе рабочей.
- Также в другом дата-центре у нас есть так называемый pseudo master (intermediate master), который на самом деле просто slave, у которого есть другой slave.
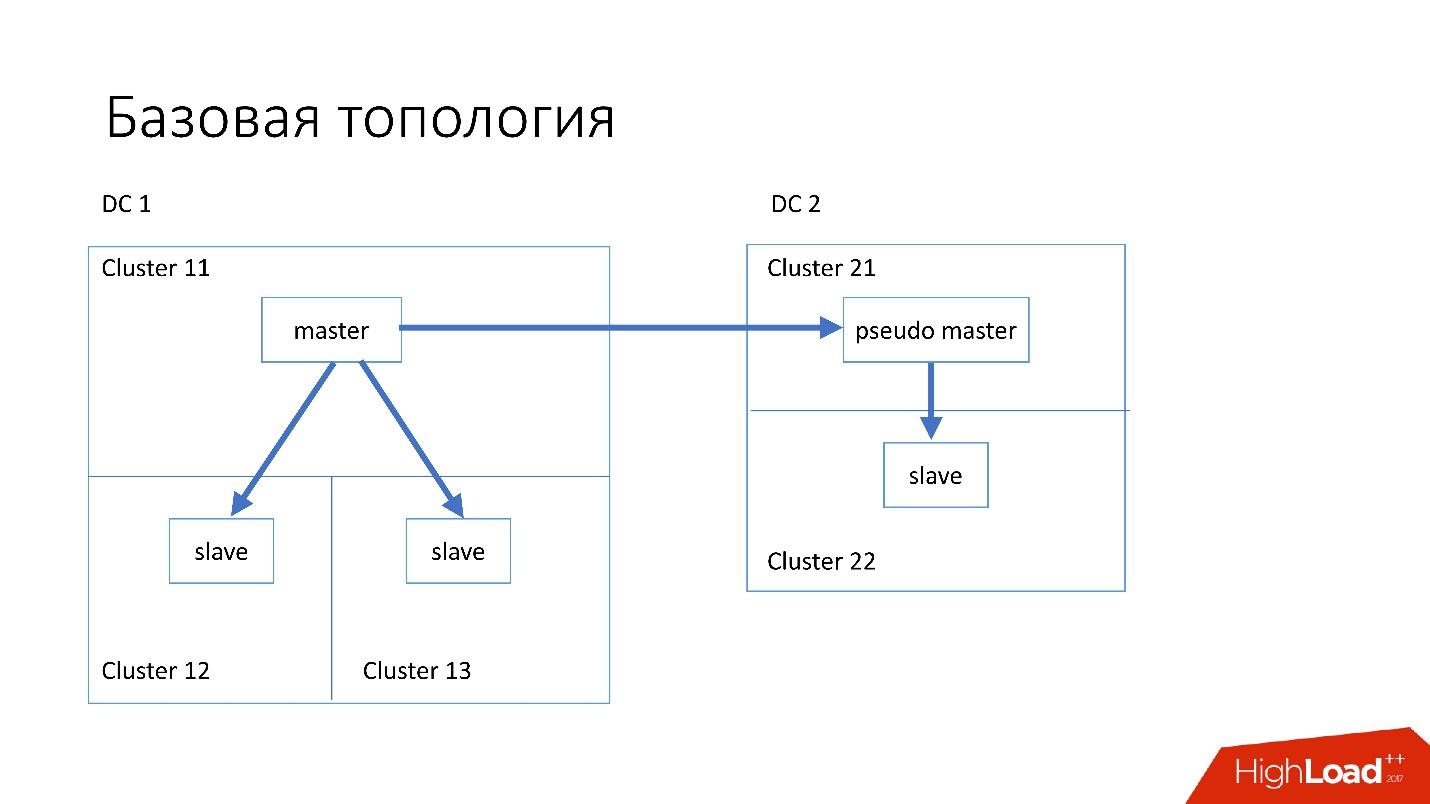
Такая топология выбрана потому, что если у нас вдруг умирает первый дата-центр, то во втором дата-центре у нас уже практически полная топология. Мы просто меняем в Discovery все адреса, и клиенты могут работать.
Специализированные топологии
Также у нас есть специализированные топологии.
Топология Magic Pocket состоит из одного master-сервера и двух slave-серверов. Так сделано, потому что сам Magic Pocket дублирует данные среди зон. Если он теряет одни кластер, то может восстановить через erasure code все данные с других зон.
Топология active-active — кастомная топология, которая используется в Edgestore. В ней есть по одному master и двум slave в каждом из двух дата-центров, и они являются slave друг для друга. Это очень опасная схема, но Edgestore на своем уровне точно знает, какие данные на какой master по какому range он может записать. Поэтому эта топология не ломается.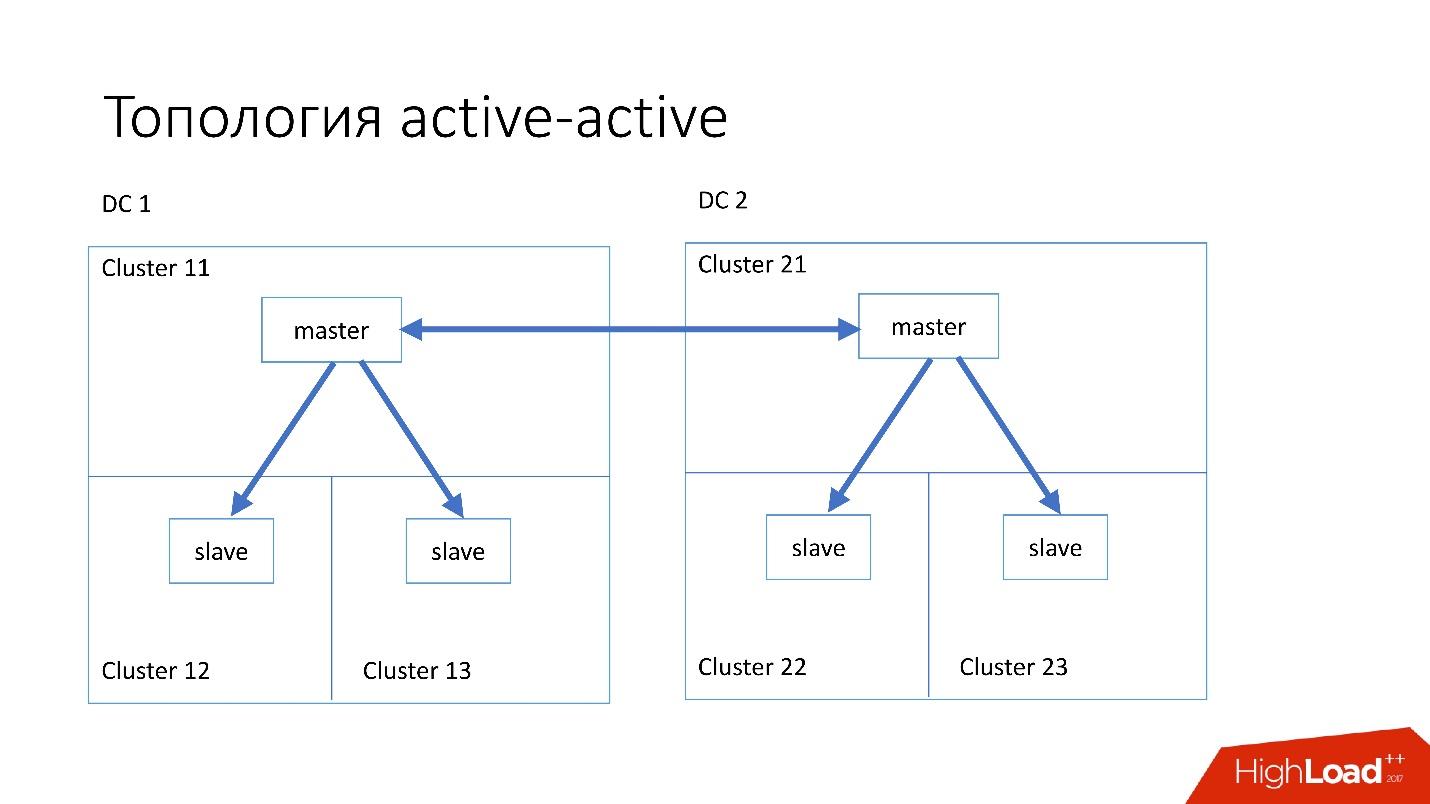
Instance
У нас установлены достаточно простые сервера с конфигурацией 4–5 летней давности:
- 2x Xeon 10 cores;
- 5TB (8 SSD Raid 0*);
- 384 GB memory.
* Raid 0 — потому что нам проще и намного быстрее заменить целый сервер, чем диски.
Single Instance
На этом сервере у нас есть один большой инстанс MySQL, на котором находятся несколько шардов. Этот MySQL инстанс сразу выделяет себе практически всю память. На сервере запущены и другие процессы: proxy, сбор статистики, логи и т.д.
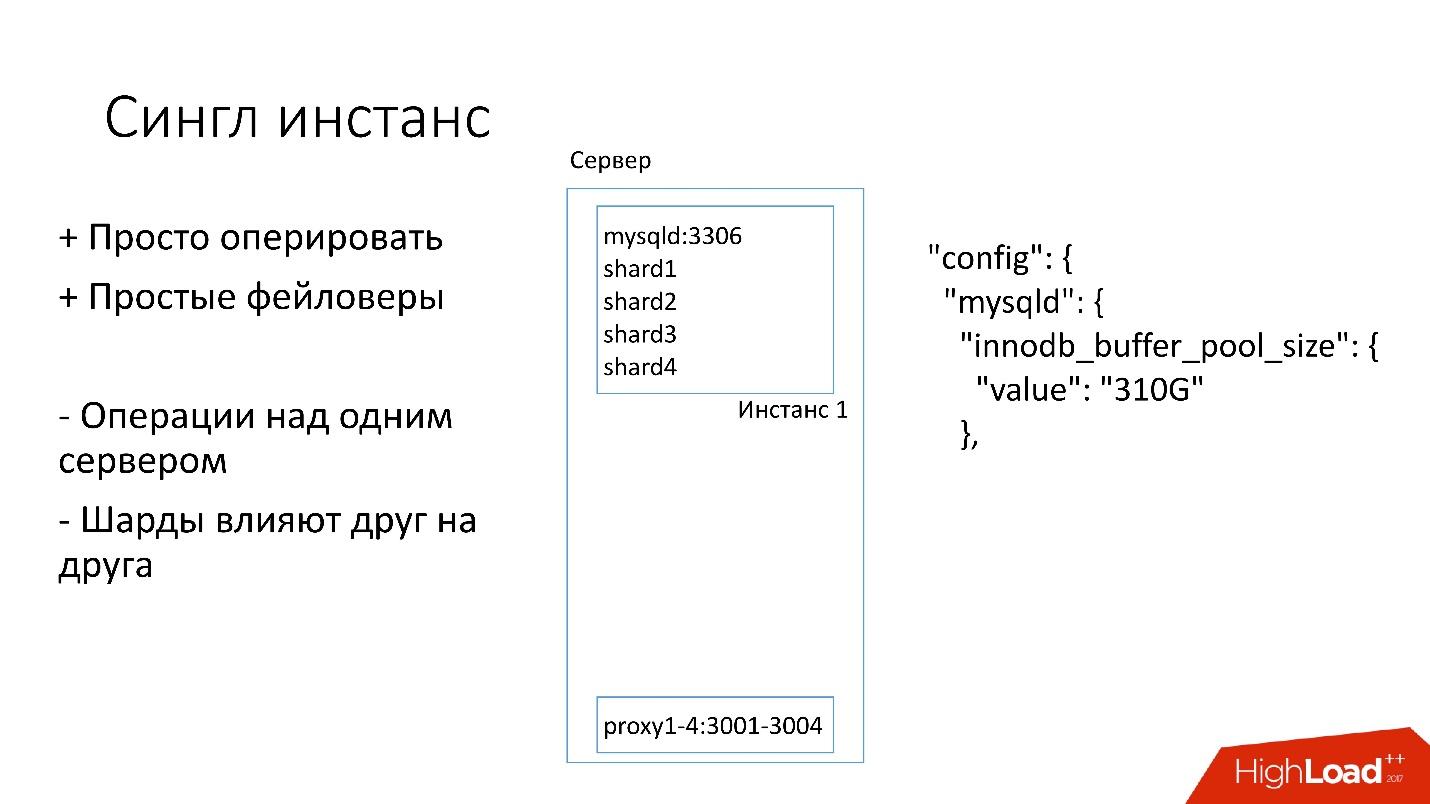
Это решение хорошо тем, что:
+ Им легко управлять. Если нужно заменить MySQL инстанс, просто заменяем сервер.
+ Просто делать фейловеры.
С другой стороны:
− Проблематично то, что любые операции происходят над целым инстансом MySQL и сразу над всеми шардами. Например, если нужно сделать бэкап, мы делаем бэкап сразу всех шардов. Если нужно сделать фейловер, мы делаем фейловер сразу всех четырех шардов. Соответственно, доступность страдает в 4 раза больше.
− Проблемы с репликацией одного шарда влияют на другие шарды. Репликация в MySQL не параллельная, и все шарды работают в один поток. Если с одним шардом что-то происходит, то остальные тоже становятся жертвами.
Поэтому сейчас мы переходим на другую топологию.
Multi Instance

В новом варианте на сервере запущено сразу несколько инстансов MySQL, в каждом есть по одному шарду. Чем это лучше?
+ Мы можем проводить операции только над одним конкретным шардом. То есть если нужен фейловер, переключаем только один шард, если нужен бэкап, делаем бэкап только одного шарда. Это значит, что операции очень сильно ускоряются — в 4 раза для четырех-шардового сервера.
+ Шарды почти не влияют друг на друга.
+ Улучшение в репликации. Мы можем миксовать разные категории и классы баз данных. Edgestore занимает очень много места, например, все 4 Тб, а Magic Pocket занимает всего 1 Тб, но у него утилизация 90%. То есть мы можем объединять различные категории, которые по-разному используют I/O и ресурсы машины, и запустить 4 потока репликаций.
Конечно, у этого решения есть и минусы:
− Самый большой минус — намного сложнее всем этим управлять. Нужен какой-то умный планировщик, который будет понимать, куда он может вынести этот инстанс, где будет оптимальная нагрузка.
− Сложнее фейловеры.
Поэтому мы только сейчас переходим на это решение.
Discovery
Клиенты должны как-то знать, как подключаться к нужной базе, поэтому у нас есть Discovery, который должен:
- Очень быстро нотифицировать клиента об изменениях топологии. Если мы поменяли master и slave, клиенты должны узнать об этом практически мгновенно.
- Топология не должна зависеть от топологии репликации MySQL, потому что при некоторых операциях мы меняем топологию MySQL. Например, когда мы делаем split, на подготовительном шаге на target master, куда будем выносить часть шардов, часть slave-серверов перенастраивается на этот target master. Клиентам нет необходимости знать об этом.
- Важно, чтобы была атомарность операций и верификация состояния. Нельзя, чтобы два разных сервера одной базы данных стали были master в один и тот же момент.
Как развивался Discovery
Сначала все было просто: адрес базы данных в исходном коде в конфиге. Когда нам нужно было обновить адрес, то просто все деплоилось очень быстро.
К сожалению, это не работает, если серверов становится очень много.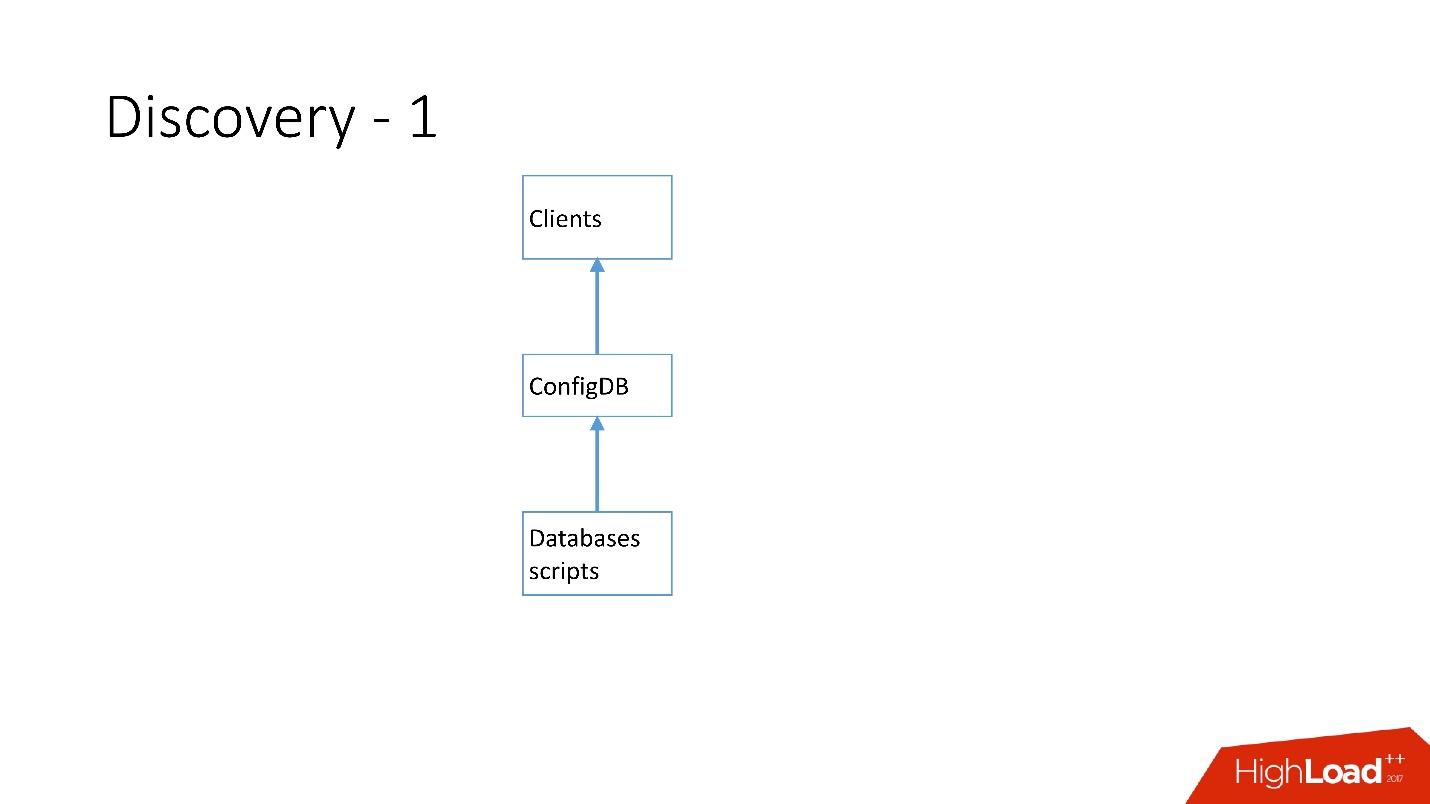
Выше самый первый Discovery, который у нас появился. Были скрипты базы данных, которые изменяли табличку в ConfigDB — это была отдельная табличка MySQL, а клиенты уже слушали эту БД и периодически забирали оттуда данные.
Таблица очень простая, есть категория базы данных, ключ шарда, класс БД master/slave, proxy и адрес БД. По сути, клиент запрашивал категорию, класс БД, ключ шарда, и ему возвращался MySQL-ный адрес, по которому он уже мог устанавливать соединение.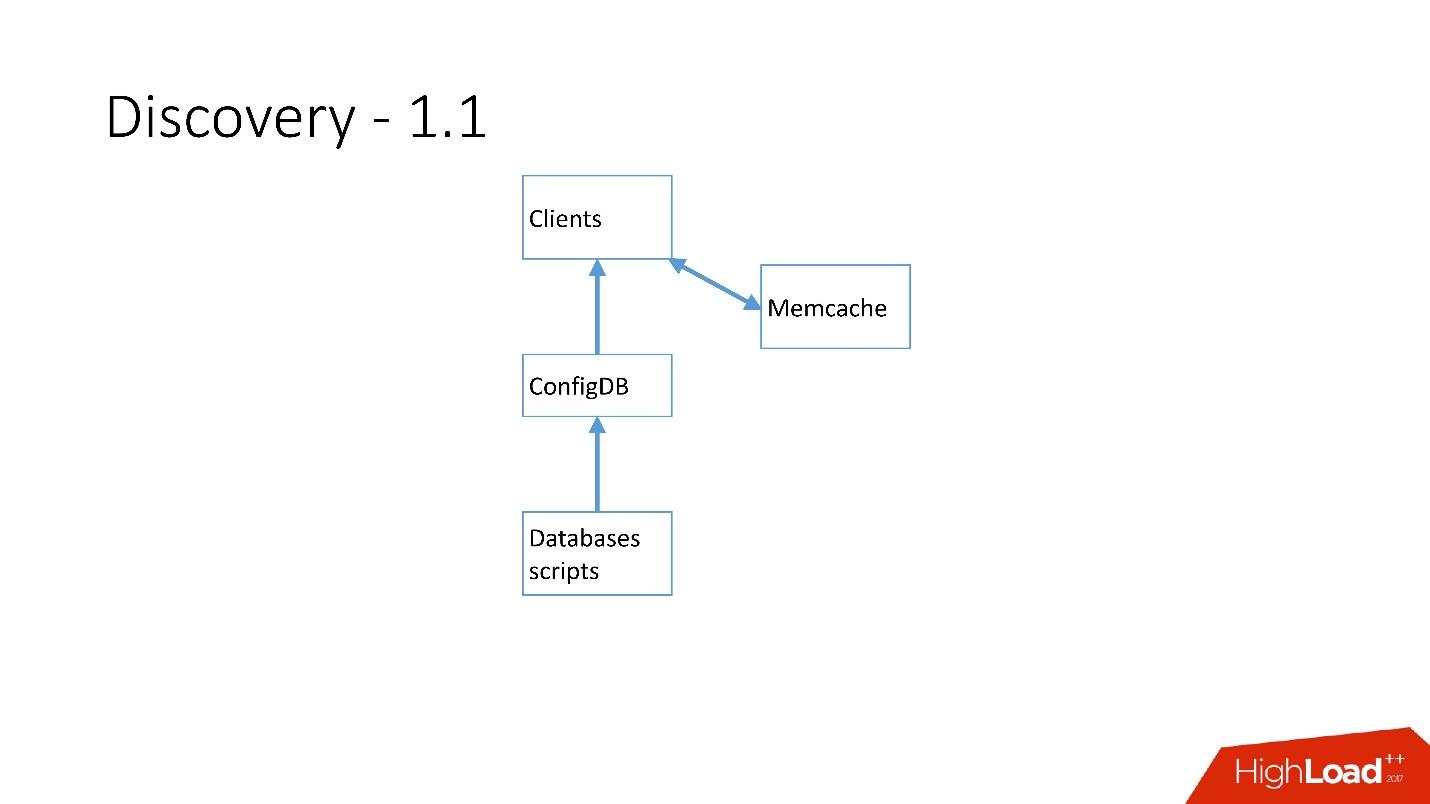
Как только серверов стало очень много, добавился Memcaсhе и клиенты стали общаться уже с ним.
Но потом мы это переработали. MySQL скрипты начали общаться через gRPC, через тонкий клиент с сервисом, который мы назвали RegisterService. Когда какие-то изменения происходили, у RegisterService была очередь, и он понимал, как применять эти изменения. RegisterService сохранял данные в AFS. AFS — это наша внутренняя система, построенная на базе ZooKeeper.
Второе решение, которое здесь не показано, напрямую использовало ZooKeeper, и это создавало проблемы, потому что у нас каждый шард был узлом в ZooKeeper. Например, 100 тысяч клиентов подключаются к ZooKeeper, если они вдруг умерли из-за какого-то бага все вместе, потом прийдет сразу 100 тысяч запросов к ZooKeeper, что просто его уронит, и он не сможет подняться.
Поэтому была разработана система AFS, которой пользуется весь Dropbox. По сути, она абстрагирует работу с ZooKeeper для всех клиентов. AFS демон локально крутится на каждом сервере и предоставляет очень простой файловый API вида: создать файл, удалить файл, запросить файл, получить нотификацию на изменение файла и compare and swap операции. То есть можно попробовать заменить файл с какой-то версии, а если эта версия поменялась в процессе смены, то операция отменяется.
По существу, такая абстракция над ZooKeeper, в которой есть локальный backoff и джиттер-алгоритмы. ZooKeeper уже не падает под нагрузкой. С AFS мы снимаем бэкапы в S3 и в GIT, потом сам локальный AFS уведомляет клиентов о том, что данные изменились.
В AFS данные хранятся в виде файлов, то есть это API файловой системы. Например, выше приведен файл shard.slave_proxy — самый большой, он занимает порядка 28 Кб, и когда мы изменяем категорию shard и slave_proxy класс, то все клиенты, которые подписаны на этот файл, получают нотификацию. Они перечитывают этот файл, в котором есть вся нужная информация. По shard key получают категорию и перенастраивают пул соединения к базе данных.
Операции
Мы используем очень простые операции: promotion, clone, backups/recovery.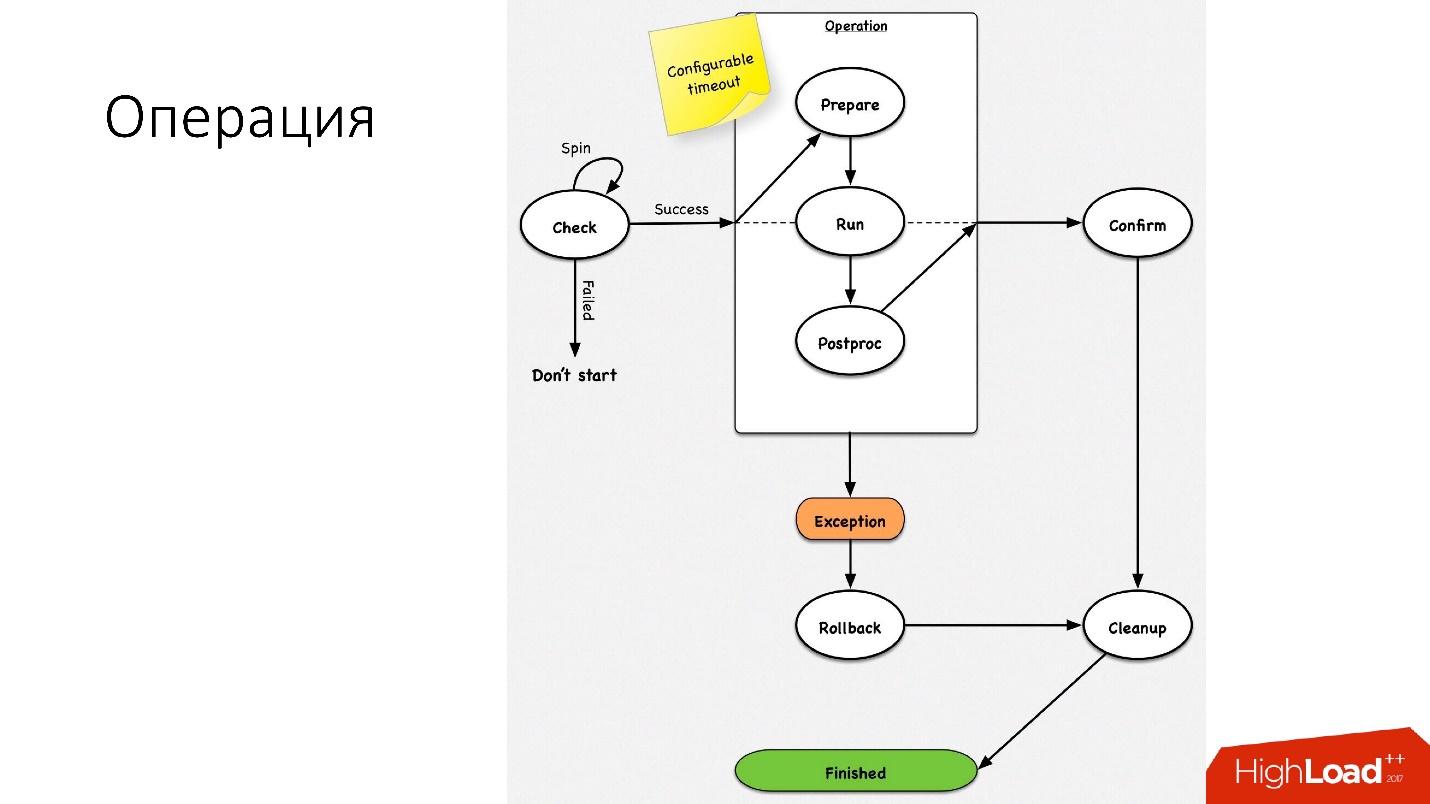
Операция — это простая стейт-машина. Когда мы заходим в операцию, мы производим какие-то проверки, например, spin-check, который несколько раз по таймауту проверяет, можно ли нам выполнить эту операцию. После этого мы делаем какое-то подготовительное действие, которое не влияет на внешние системы. Дальше собственно сама операция.
У всех шагов внутри операции есть rollback-step (отмена). Если с операцией возникла какая-то проблема, то операция пытается восстановить систему в исходное положение. Если все нормально, то происходит cleanup, и операция завершена.
Такая простая стейт-машина у нас на любой операции.
Promotion (смена мастера)
Это очень частая операция в БД. Были вопросы о том, как делать alter на горячем master-сервере, который работает — он же встанет колом. Просто все эти операции производятся на slave-серверах, и потом slave меняется с master местами. Поэтому операция promotion очень частая.
Нужно обновить kernel — делаем swap, нужно обновить версию MySQL — обновляем на slave, переключаем на master, обновляем там.
Мы добились очень быстрого promotion. Например, у нас для четырех шардов сейчас promotion порядка 10–15 с. На графике выше видно, что при promotion availability пострадало на 0,0003%.
Но нормальные promotion не так интересны, потому что это обычные операции, которые выполняются каждый день. Интересны фейловеры.
Фейловер (замена поломанного мастера)
Фейловер (failover) значит, что база данных умерла.
- Если сервер действительно умер, это просто идеальный случай.
- На самом деле бывает так, что серверы частично жив.
- Иногда сервер очень медленно умирает. У него отказывают raid-контроллеры, дисковая система, какие-то запросы возвращают ответы, но какие-то потоки блокируются и не возвращают ответы.
- Бывает такое, что master просто перегружен и не отвечает на наши health-check. Но если мы сделаем promotion, то новый master тоже будет перегружен, и станет только хуже.
Замена умерших master серверов у нас происходит примерно 2–3 раза в день, это полностью автоматизированный процесс, никакая интервенция человека не нужна. Критическая секция занимает примерно 30 с, и в ней есть куча дополнительных проверок того, жив ли сервер на самом деле, или, может быть, он уже умер.
Ниже примерная схема того, как работает фейловер.
В выделенной секции мы перезагружаем master-сервер. Это нужно, потому что у нас MySQL 5.6, а в нем semisync репликация не lossless. Поэтому возможны phantom reads, и нам нужно этот master, даже если он не умер, как можно быстрее убить, чтобы клиенты от него отключились. Поэтому мы делаем hard reset через Ipmi — это первая самая важная операция, которую мы должны сделать. В MySQL 5.7 версии это не так критично.
Синхронизация кластера. Зачем нам нужна синхронизация кластера? 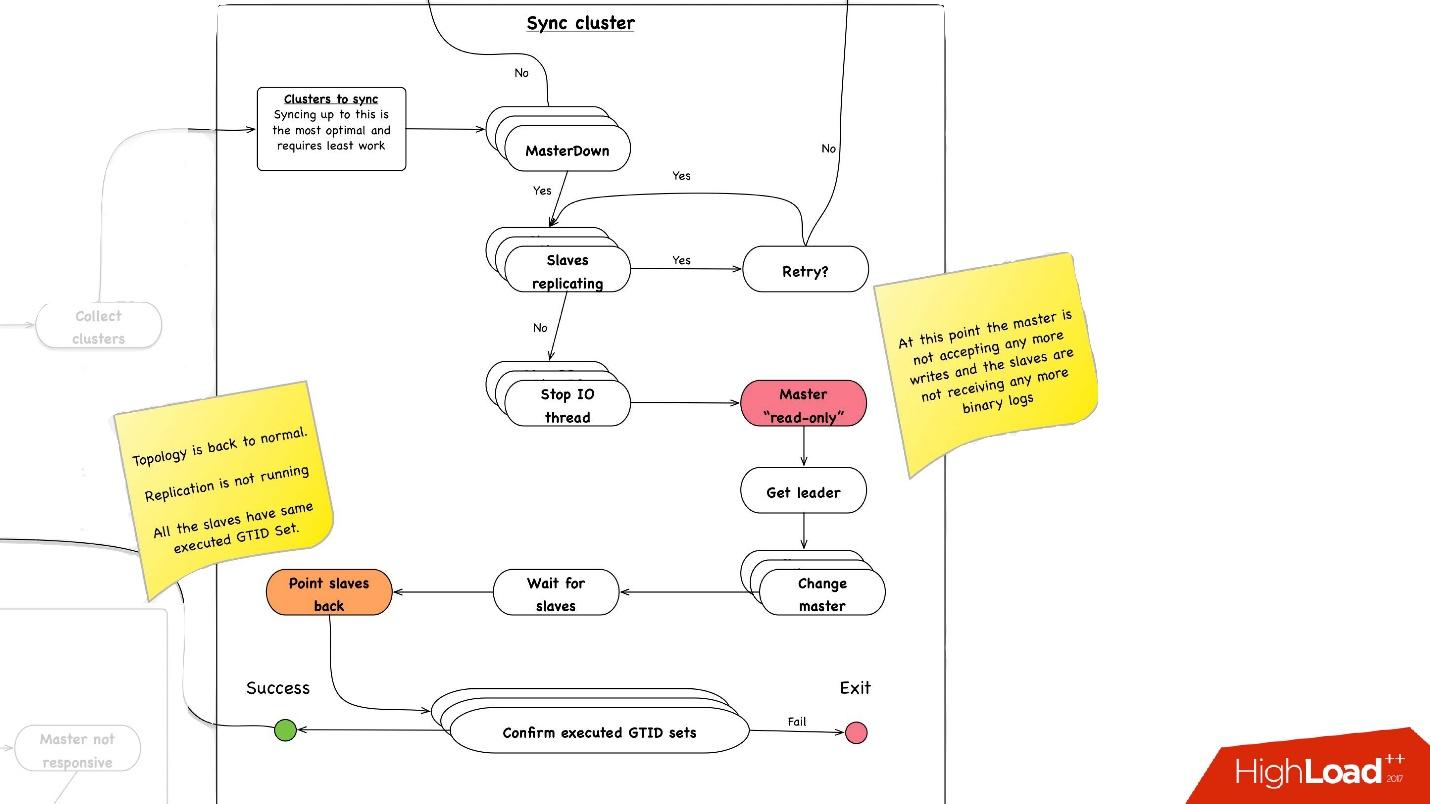
Если вспомнить предыдущую картинку с нашей топологией, у одного master-сервера есть три slave-сервера: два в одном дата-центре, один — в другом. При promotion нам нужно, чтобы master был в том же основном дата-центре. Но иногда, когда slave нагружены, при semisync бывает так, что semisync-slave«ом становится slave в другом дата-центре, потому что он-то не нагружен. Поэтому нам нужно сначала синхронизировать весь кластер, а потом уже сделать promotion на slave в нужном нам дата-центре. Это делается очень просто:
- Мы останавливаем все I/O thread на всех slave-серверах.
- После этого мы уже точно знаем, что master «read-only», так как отключился semisync и туда больше никто ничего записать не может.
- Дальше мы выбираем slave с наибольшим retrieved/executed GTID Set, то есть с наибольшей транзакцией, которую он либо скачал, либо уже применил.
- Перенастраиваем все slave-серверы на этот выбранный slave, запускаем I/O thread, и они синхронизируются.
- Ждем, пока они синхронизируются, после этого у нас весь кластер становится синхронизированным. В конце проверяем, что у нас везде executed GTID set установлен на одну и ту же позицию.
Вторая важная операция — синхронизация кластеров. Дальше начинается promotion, который происходит следующим образом: 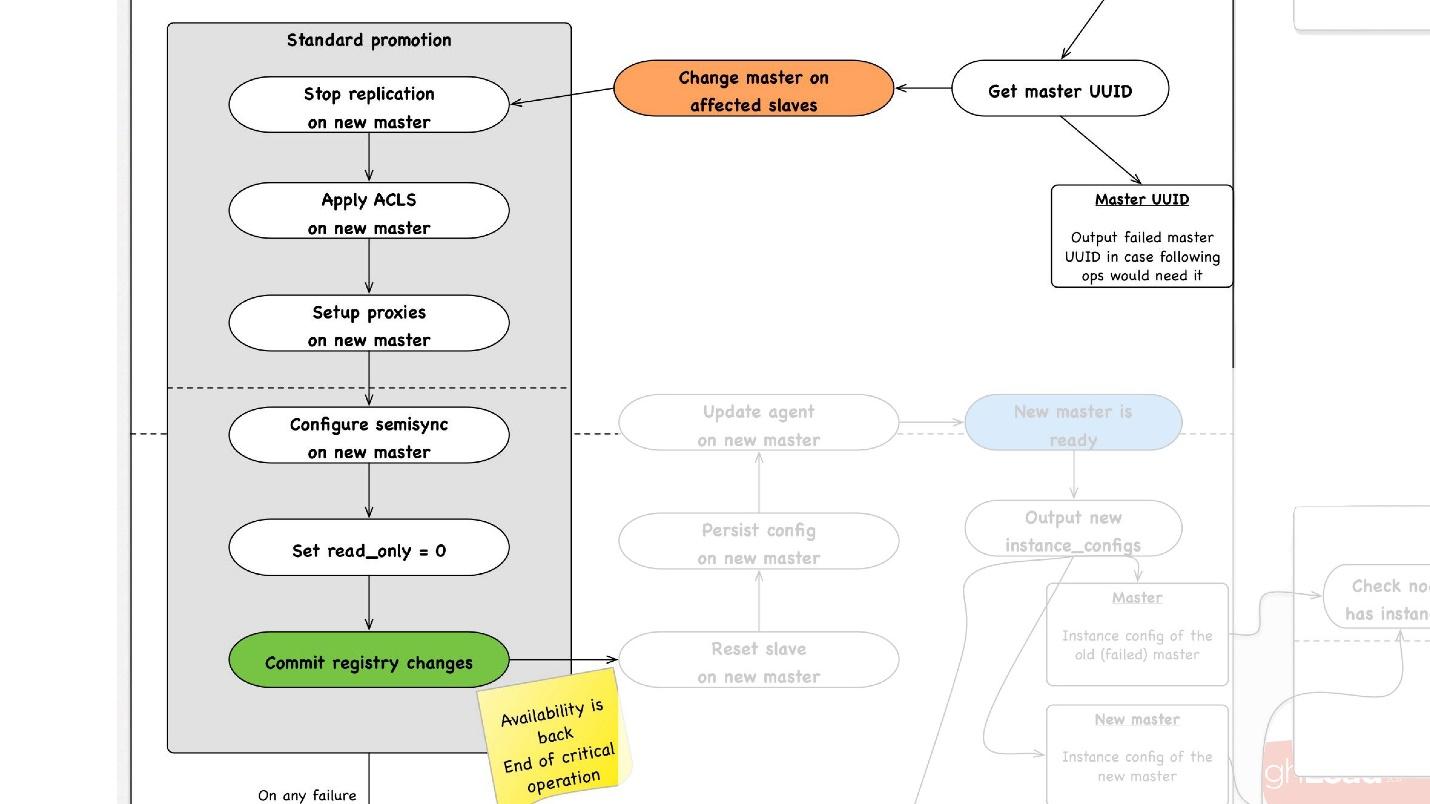
- Мы выбираем любой slave в нужном нам дата-центре, говорим ему, что он master, и запускаем операцию стандартного promotion.
- Мы перенастраиваем все slave-сервера на этот master, останавливаем там репликацию, применяем ACLs, вбиваем пользователей, останавливаем какие-то proxy, возможно, что-то перезагружаем.
- В конце концов мы делаем read_only = 0, то есть говорим, что теперь на master можно записывать, и обновляем топологию. С этого момента клиенты идут на этот master и у них все работает.
- Дальше у нас есть не критичные пост-шаги обработки. В них мы перезапускаем какие-то сервисы на этом хосте, перерисовываем конфигурации, делаем дополнительные проверки, что все точно работает, например, что proxy пропускает трафик.
- После этого вся операция завершена.
На любом шаге, в случае ошибки мы пытаемся сделать rollback до того момента, до которого можем. То есть мы не можем сделать rollback для reboot. Но для операций, для которых это возможно, например, переназначения — change master — мы можем вернуть master на предыдущий шаг.
Бэкапы
Бэкапы — очень важная тема в базах данных. Я не знаю, делаете ли вы бэкапы, но мне кажется, все должны их делать, это уже избитая шутка.
Паттерны использования
● Добавить новый slave
Самый главный паттерн, который мы используем при добавлении нового slave-сервера, мы просто его восстанавливаем из бэкапа. Это происходит постоянно.
● Восстановление данных на точку в прошлом
Достаточно часто пользователи удаляют данные, а потом просят их восстановить, в том числе из базы данных. Эта достаточно частая операция восстановления данных на точку в прошлом у нас автоматизирована.
● Восстановить целиком весь кластер с нуля
Все думают, что бэкапы нужны для того, чтобы восстановить все данные с нуля. На самом деле эта операция практически никогда нам не требовалась. Последний раз мы использовали ее 3 года назад.
Мы смотрим на бэкапы, как на продукт, поэтому говорим клиентам, что у нас есть гарантии:
- Мы можем восстановить любую базу данных. В нормальных условиях ожидаемая скорость восстановления 1Тб за 40 минут.
- Любую базу можно восстановить на любую точку в течение последних шесть дней.
Это наши основные гарантии, которые мы даем нашим клиентам. Скорость в 1 Тб за 40 минут, потому что есть ограничения по сети, мы не одни на этих стойках, на них еще продакшен трафик.
Цикл
Мы ввели такую абстракцию, как цикл. В одном цикле мы стараемся забэкапить практически все наши базы данных. У нас одновременно крутится 4 разных цикла.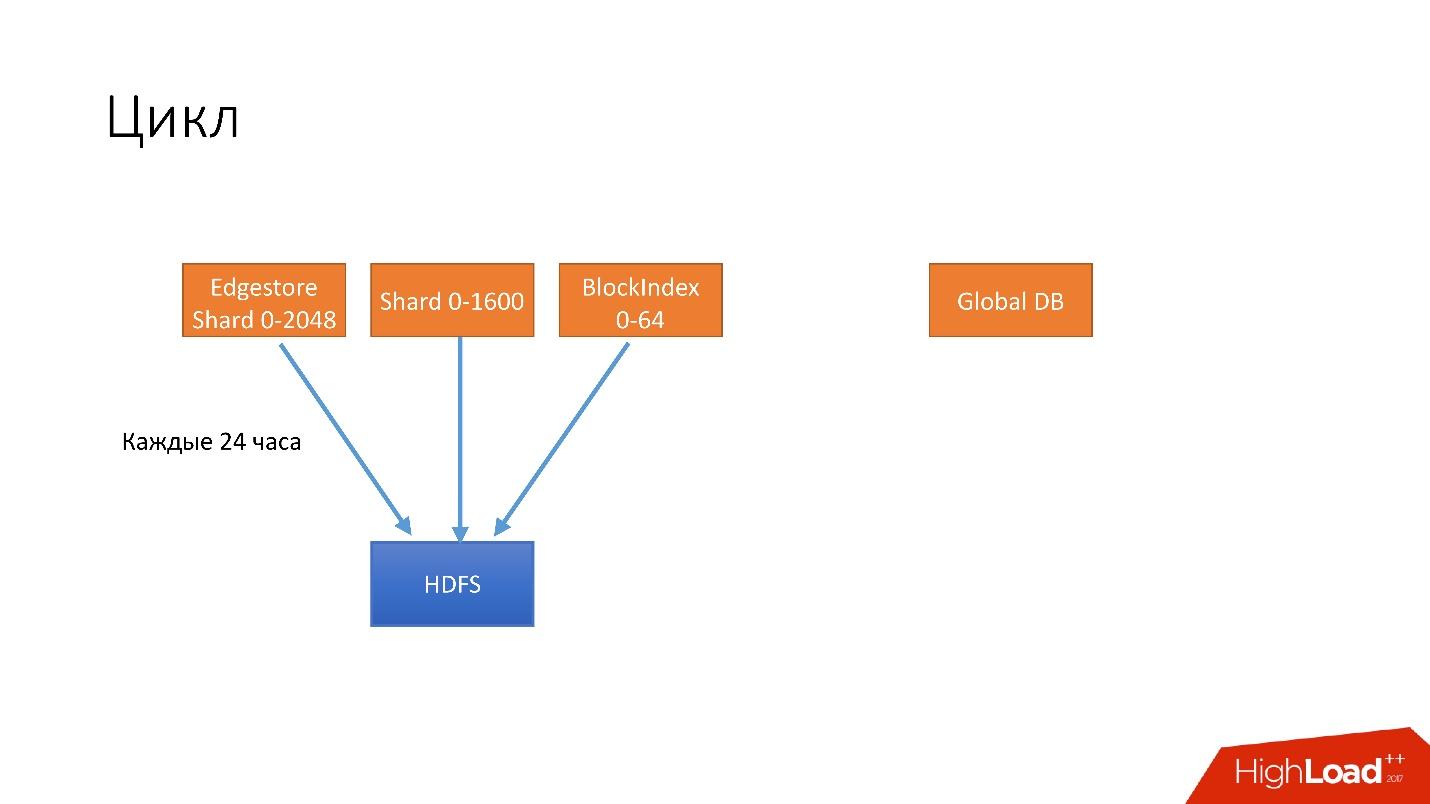
- Первый цикл выполняется каждые 24 часа. Мы бэкапим все наши шардированные базы данных на HDFS, это порядка тысячи с лишним хостов.
- Каждые 6 часов мы делаем бэкапы для unsharded databases, у нас еще есть некоторые данные на Global DB. Мы очень хотим от них избавиться, но, к сожалению, они до сих пор есть.
- Каждые 3 дня мы сохраняем полностью всю информацию шардированных баз данных на S3.
- Каждые 3 дня мы полностью сохраняем на S3 всю информацию нешардированных баз данных.

Все это хранится в течении нескольких циклов. Допустим, если мы храним 3 цикла, то в HDFS у нас есть последние 3 дня, и последние 6 дней в S3. Так мы поддерживаем наши гарантии.
Это пример, как они работают.
В данном случае у нас запущено два длинных цикла, которые делают бэкапы шардированных баз данных, и один короткий. При завершении каждого цикла мы обязательно верифицируем, что бэкапы работают, то есть делаем recovery на какой-то процент базы данных. К сожалению, мы не можем восстановить все данные, но какой-то процент данных для цикла мы обязательно проверяем. В итоге у нас будет 100 процентов бекапов, которые мы восстановили.
У нас есть определенные шарды, которые мы всегда восстанавливаем, чтобы смотреть скорость восстановления, чтобы мониторить возможные регрессии, и есть шарды, которые мы восстанавливаем просто рандомно, чтобы проверить, что они восстановились и работают. Плюс при клонировании мы тоже восстанавливаемся из бэкапов.
Горячие бэкапы

Сейчас у нас происходит hot-бэкап, для которого мы используем инструмент Percona xtrabackup. Запускаем его в режиме —stream=xbstream, и он нам возвращает на рабочей базе данных, поток бинарных данных. Дальше у нас есть script-splitter, который этот бинарный поток делит на четыре части, и потом мы сжимаем этот поток.
MySQL хранит данные на диске очень странным образом и у нас получилась компрессия больше 2x. Если база данных занимает 3 Тб, то, в результате сжатия, бэкап занимает примерно 1 500 Гб. Дальше мы шифруем эти данные, чтобы никто не мог их прочитать, и отправляем в HDFS и в S3.
В обратную сторону работает абсолютно точно так же.
Подготавливаем сервер, куда будем устанавливать бэкап, достаем бэкап из HDFS или из S3, декодируем и декомпрессируем его, splitter сжимает это все и отправляет в xtrabackup, который восстанавливает все данные на сервер. Потом происходит crash-recovery.
Некоторое время самой главной проблемой hot бэкапов было то, что crash-recovery занимает достаточно длительное время. В целом нужно проиграть все транзакции за то время, пока вы делаете бэкап. После этого мы проигрываем binlog, чтобы наш сервер догнал текущий master.
Как мы сохраняем binlogs?
Раньше мы сохраняли файлики binlog«ов. Мы собирали на master файлики, чередовали их каждые 4 минуты, либо по 100 Мб, и сохраняли в HDFS.
Сейчас у нас используется новая схема: есть некий Binlog Backuper, который подключен к репликациям и ко всем базам данных. Он, по сути, постоянно сливает binlog к себе и сохраняет их на HDFS.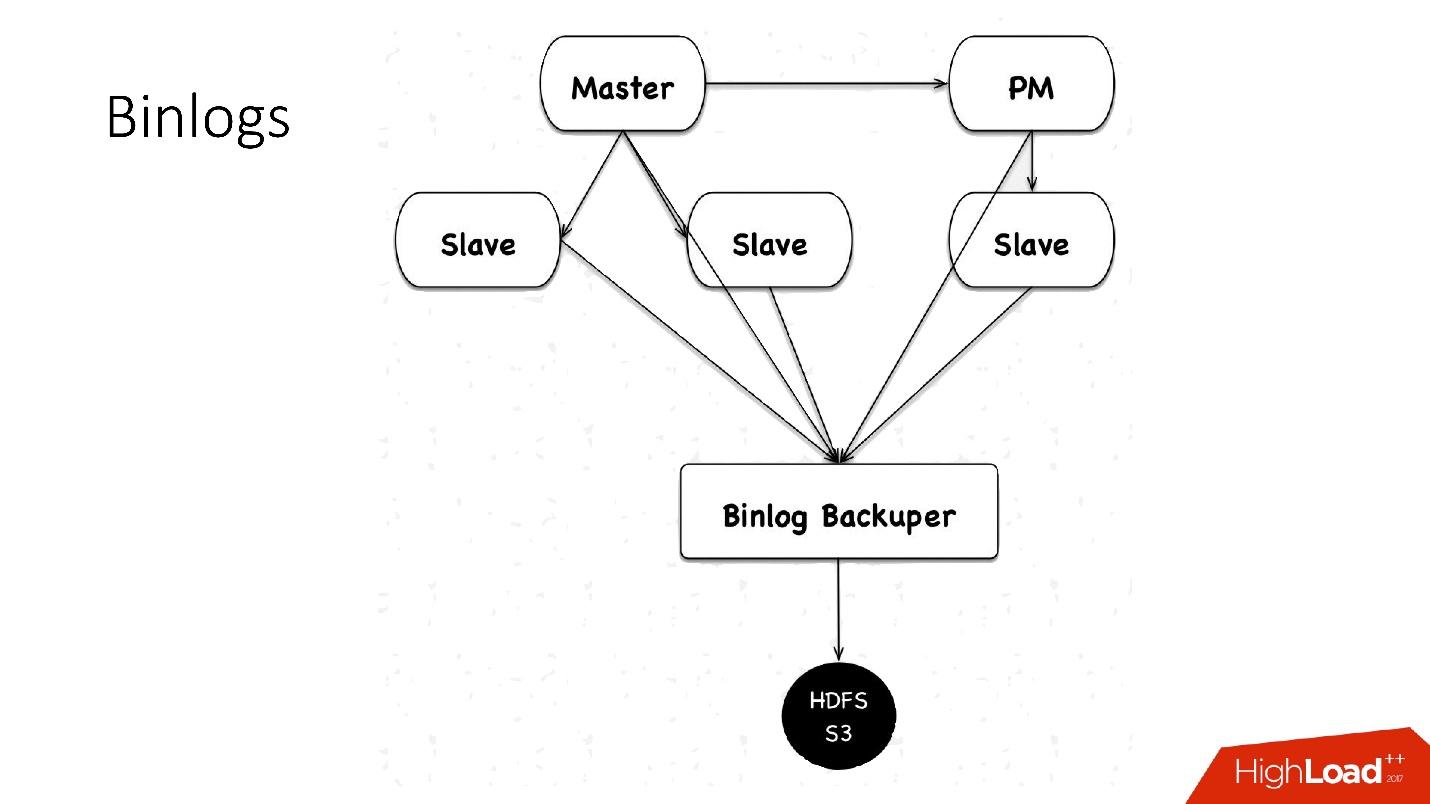
Соответственно, в предыдущей реализации мы могли потерять 4 минуты бинарных логов, если потеряли все 5 серверов, в этой же реализации, в зависимости от нагрузки, мы теряем буквально секунды. Все сохраненное в HDFS и в S3 хранится в течение месяца.
Холодные бэкапы
Мы подумываем перейти на холодные бэкапы.
Предпосылки для этого:
- Скорость каналов на наших серверах стала больше — было 10 Гб, стало 45 Гб — можно утилизировать больше.
- Хочется восстанавливать и создавать клоны быстрее, потому что нам нужен более умный scheduler для multi instance и хочется очень часто перекидывать slave и master с сервера на сервер.
- Самый важный момент — при холодном бэкапе мы можем гарантировать, что бэкап работает. Потому что, когда мы делаем холодный бэкап, мы просто копируем файл, потом запускаем базу данных, и как только она запустилась, мы знаем, что этот бэкап работает. После pt-table-checksum мы точно знаем, что данные на файловой системе консистентны.
Гарантии, которые получились при холодных бэкапах в наших экспериментах:
- В нормальных условиях ожидаемая скорость восстановления 1Тб за 10 минут, потому что это просто копирование файлов. Не нужно делать crash-recovery, а это самое проблемное место.
- Любую базу можно восстановить на любой период времени за последние шесть дней.

В нашей топологии есть slave в другом дата-центре, который практически ничего не делает. Мы периодически его останавливаем, делаем холодный бэкап и запускаем обратно. Все очень просто.
Планы ++
Это планы на дальнее будущее. Когда мы будем делать обновление нашего Hardware парка, мы хотим добавить на каждый сервер дополнительный шпиндельный диск (HDD) порядка 10 Тб, и делать на него горячие бэкапы + crash recovery xtrabackup, а после этого загружать уже бэкапы. Соответственно, у нас будут бэкапы на всех пяти серверах одновременно, в разные точки времени. Это, конечно, усложнит всю обработку и оперирование, но снизит стоимость, потому что HDD стоит копейки, а огромный кластер HDFS стоит дорого.
Клон
Как я уже говорил, клонирование — это простая операция:
- это либо восстановление из бэкапа и проигрывание бинарных логов;
- либо процесс бэкапа сразу на целевой сервер.
В диаграмме, где мы копируем на HDFS, также данные просто копируются на другой сервер, где есть ресивер, который принимает все данные и восстанавливает их.
Автоматизация
Конечно же, на 6 000 серверах никто ничего не делает вручную. Поэтому у нас есть различные скрипты и сервисы автоматизации, их очень много, но основные из них — это:
- Auto-replace;
- DBManager;
- Naoru, Wheelhouse
Auto-replace
Этот скрипт нужен, когда сервер умер, и нужно понять, правда ли он умер, и что за проблема — может, сеть поломалась или еще что-то. Это нужно решить, как можно быстрее.
Availability (доступность) — это функция от времени между возникновением ошибок и временем, за которое вы можете детектировать и починить эту ошибку. Починить мы можем очень быстро — у нас recovery очень быстрый, поэтому нам нужно как можно скорее определить существование проблемы.
На каждом сервере MySQL запущен сервис, которые пишет heartbeat. Heartbeat — это текущий timestamp.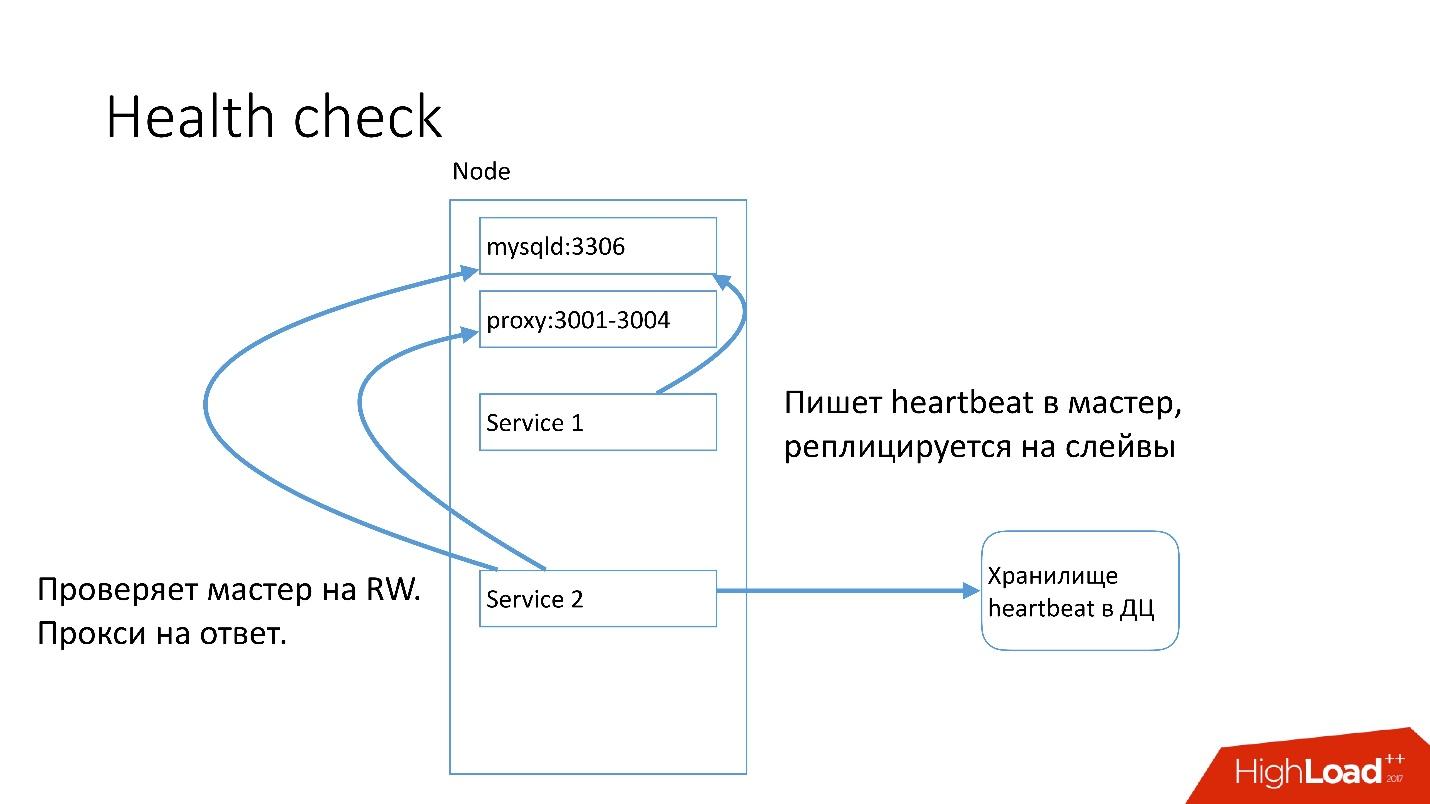
Есть также другой сервис, который пишет значение некоторых предикатов, например, что master в режиме read-write. После этого второй сервис отправляет в центральное хранилище этот heartbeat.
У нас есть auto-replace скрипт, работающий по такой схеме.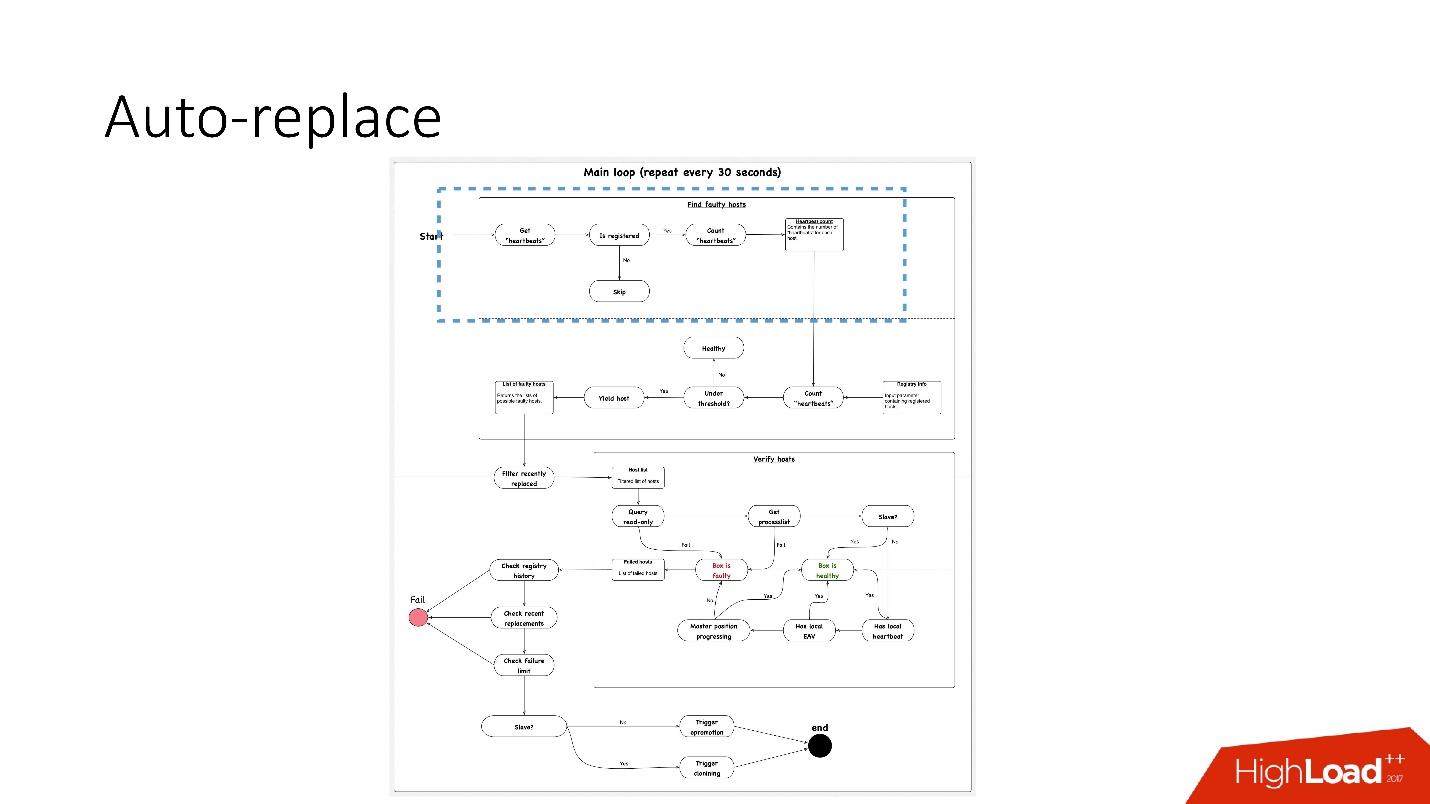 Схема в лучшем качестве и отдельно ее увеличенные фрагменты есть в презентации доклада, начиная с 91 слайда.
Схема в лучшем качестве и отдельно ее увеличенные фрагменты есть в презентации доклада, начиная с 91 слайда.
Что здесь происходит?
- Есть основной цикл, в котором мы проверяем heartbeat в глобальной базе данных. Смотрим, зарегистрирован этот сервис или нет. Подсчитываем heartbeat«ы, например, есть ли два heartbeat«а за 30 с.
- Далее, смотрим, удовлетворяет ли их количество пороговому значению. Если нет, то значит, что-то с сервером не так — раз он не послал heartbeat.
- После этого мы делаем reverse check на всякий случай — вдруг эти два сервиса умерли, что-то с сетью, или глобальная база данных не может почему-то записать heartbeat. В reverse check мы подсоединяемся к поломанной базе данных и проверяем ее состояние.
- Если уже ничего не помогло, мы смотрим, прогрессирует ли master position или нет, происходят ли на него записи. Если ничего не происходит, то этот сервер точно не работает.
- Последний этап — собственно auto-replace.
Auto-replace очень консервативен Он никогда не хочет делать много автоматических операций.
- Во-первых, мы проверяем, не было ли операций с топологией недавно? Может быть, этот сервер только что был добавлен и что-то на нем еще не запущено.
- Проверяем, не было ли каких-то замен в этом же кластере в какой-то промежуток времени.
- Проверяем, какой у нас failure limit. Если у нас много проблем одномоментно — 10, 20 — то мы не будем автоматически их все решать, потому что можем ненароком нарушить работу всех баз данных.
Поэтому решаем только одну проблему за раз.
Соответственно, для slave-сервера мы запускаем клонирование и просто удаляем его из топологии, а если это master, то запускаем фейловер, так называемый emergency promotion.
DBManager
DBManager — это сервис для управления нашими базами данных. В нем есть:
- умный планировщик задач, который точно знает, когда какой job запустить;
- логи и вся информация: кто, когда и что запускал — это источник правды;
- точка синхронизации.
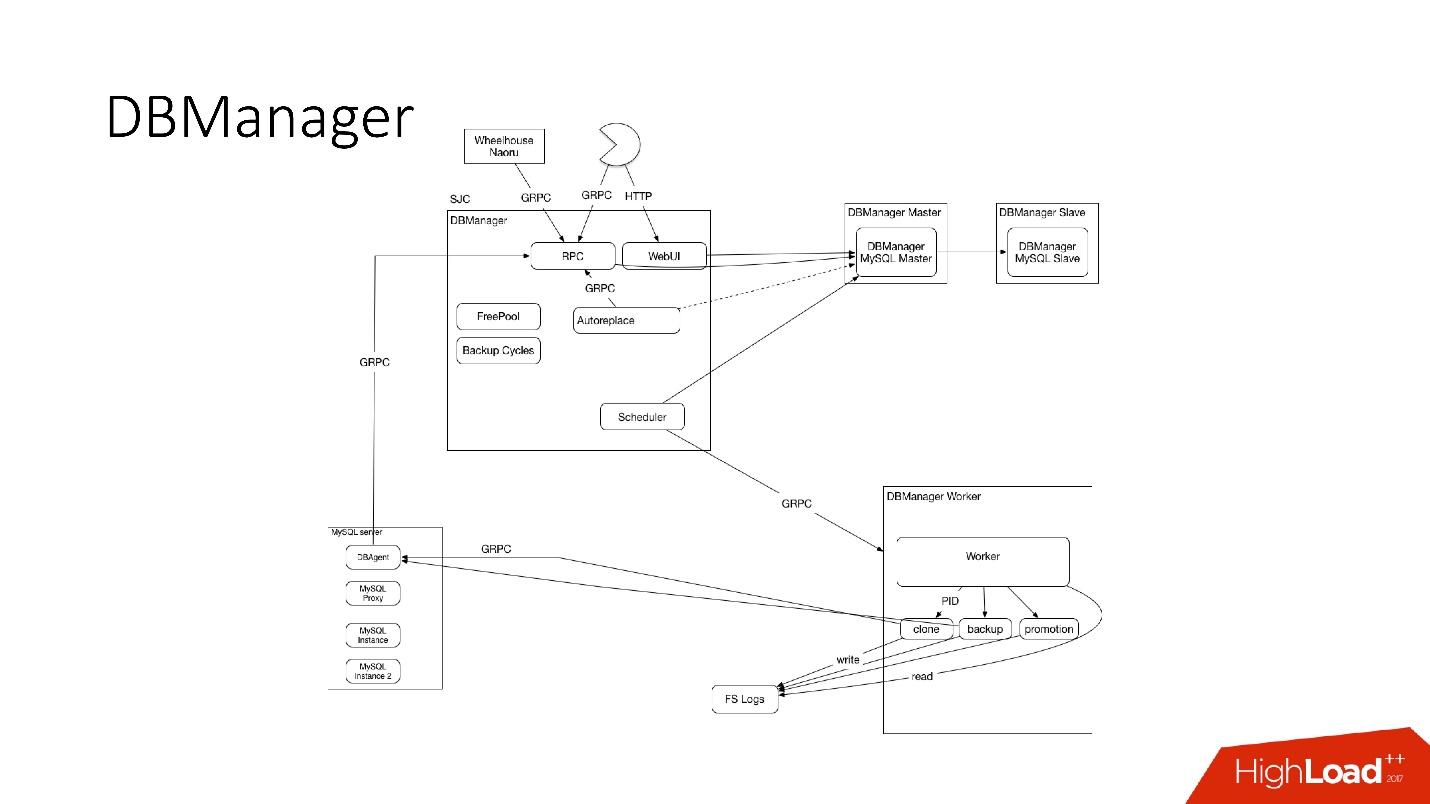
DBManager достаточно прост архитектурно.
- Есть клиенты, это либо DBA, которые что-то делают через web интерфейс, либо скрипты/сервисы, которые написали DBA, которые обращаются по gRPC.
- Есть внешние системы вроде Wheelhouse и Naoru, которая по gRPC ходит в DBManager.
- Есть планировщик, который понимает, какую операцию, когда и где он может запустить.
- Есть очень тупой worker, который, когда к нему приходит операция, запускает ее, проверяет по PID. Worker может перезагружаться, процессы не прерываются. Все worker«ы расположены как можно ближе к серверам, на которых происходят операции, чтобы, например, при обновлении ACLS нам не нужно было делать много раунд-трипов.
- На каждом SQL-хосте у нас есть некий DBAgent — это RPC сервер. Когда нужно провести какую-то операцию на сервере, мы отправляем RPC запрос.
У нас есть web интерфейс для DBManager, где можно посмотреть текущие запущенные задачи, логи к этим задачам, кто и когда что запустил, какие операции были проведены для сервера конкретной базы данных и т.д.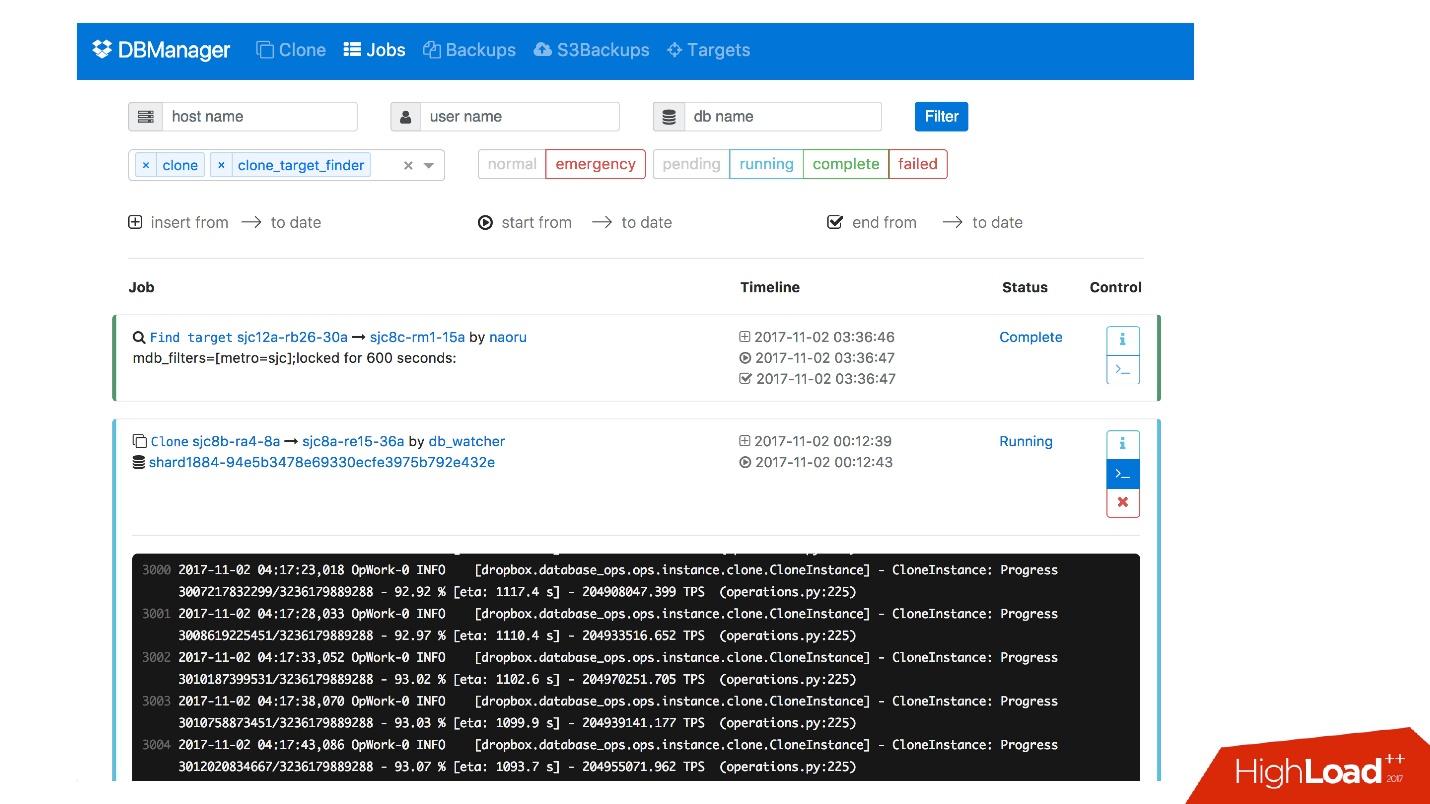
Есть достаточно простой CLI интерфейс, где можно запускать задачи и также просматривать их в удобных представлениях.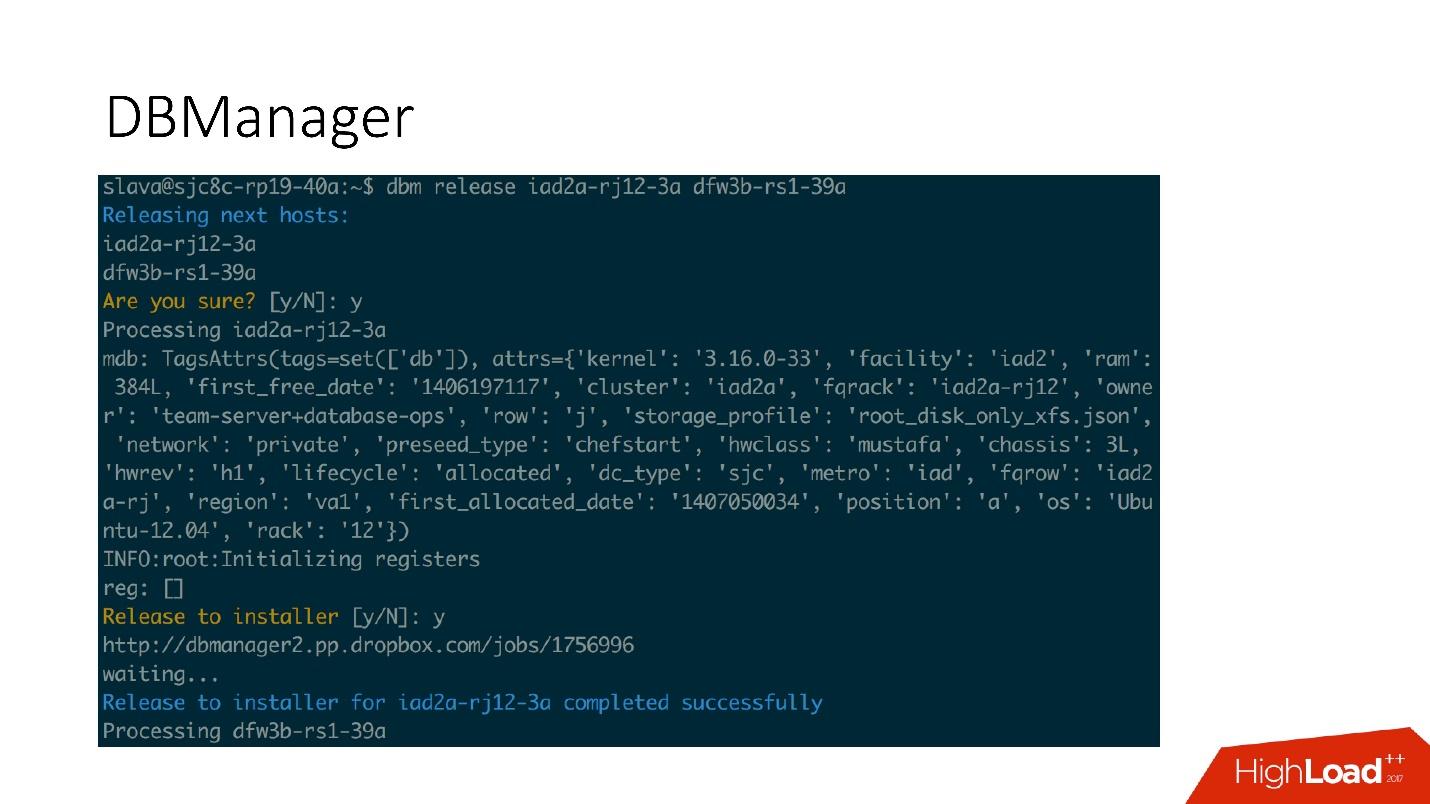
Remediations
Еще у нас есть система реагирования на проблемы. Когда у нас что-то поломалось, например, диск вышел из строя, либо какой-то сервис не работает, срабатывает Naoru. Это система, которая работае
