Стас Афанасьев. Juno. Pipelines на базе io.Reader/io.Writer. Часть 1
В докладе поговорим про концепцию io.Reader/io.Writer, для чего они нужны, как их правильно реализовывать и какие в связи с этим существуют подводные камни, а также про построение pipelines на базе стандартных и кастомных реализаций io.Reader/io.Writer.

Станислав Афанасьев (далее — СА): — Добрый день! Меня зовут Стас. Я приехал из Минска, из компании Juno. Спасибо, что в этот дождливый день пришли, нашли в себе силы выйти из дома.
Сегодня я с вами хочу поговорить на такую тему как построение пайплайнов (pipelines) Go на базе интерфейсов io.Reader/io.Writer. То, о чём я сегодня буду говорить, это, в общем-то, концепция интерфейсов io.Reader/io.Writer, для чего они нужны, как их правильно использовать и, самое главное, как их правильно реализовывать.
Мы также поговорим о построении пайплайнов на базе различных реализаций этих интерфейсов. Мы поговорим о существующих способах, обсудим их плюсы и минусы. Различные подводные камни я тоже упомяну (этого будет в достатке).
Прежде чем мы начнём, следует ответить на вопрос, зачем эти интерфейсы вообще нужны? Поднимите руки, кто с Go работает плотно (каждый день, через день)…

Отлично! У нас всё-таки Go-комьюнити. Думаю, многие из вас работали с этими интерфейсами, слышали о них, по крайней мере. Может, вы даже о них не знаете, но вы точно что-то должны были о них слышать.
В первую очередь, данные интерфейсы — это абстракция операции ввода-вывода во всех его проявлениях. Во-вторых, это очень удобный API, который позволяет выстраивать пайплайны, как конструктор из кубиков, не особо задумываясь о внутренних деталях реализации. По крайней мере, так задумывалось изначально.
io.Reader
Это очень простой интерфейс. Он состоит всего из одного метода — метода Read. Концептуально реализацией интерфейса io.Reader может быть сетевое соединение — например, там, где данных ещё нет, но они могут там появиться:

Это может быть буфер в памяти, где данные уже есть и их можно вычитать целиком. Также это может быть файл-дескриптор — мы можем вычитывать этот файл кусочками, если он очень большой.
Концептуальная реализация интерфейса io.Reader — это доступ к каким-то данным. Все кейсы, которые я писал, поддерживаются методом Read. Он имеет всего один аргумент — это slice byte.
Здесь надо сделать одно замечание. Тех, кто пришёл в Go недавно или пришёл из каких-то других технологий, где не было похожего API (я один из таких), эта сигнатура немного путает. Кажется, что метод Read каким-то образом вычитывает этот slice. На самом деле всё наоборот: реализация интерфейса Reader вычитывает данные внутри себя и заполняет этот слайс (slice) теми данными, которые у этой реализации есть.
Максимальное количество данных, которое может быть вычитано по запросу методу Read, равно длине этого слайса. Обычная реализация возвращает столько данных, сколько она может вернуть на момент запроса, либо максимальное количество, влезающее в этот slice. Это говорит о то, что Reader можно вычитывать кусочками: хоть по байту, хоть по десять — как угодно. А клиент, который вызывает Reader, по возвращаемым значениям из метода Read, думает, как ему дальше жить.
Метод Read возвращает два значения:
- количество вычитанных байт;
- ошибку, если она произошла.
Эти значения влияют на дальнейшее поведение клиента. На слайде есть гифка, которая показывает, отображает этот процесс, который я только что описал:

Io.Reader — How to?
Есть ровно два способа, чтобы ваши данные удовлетворяли интерфейсу Reader.
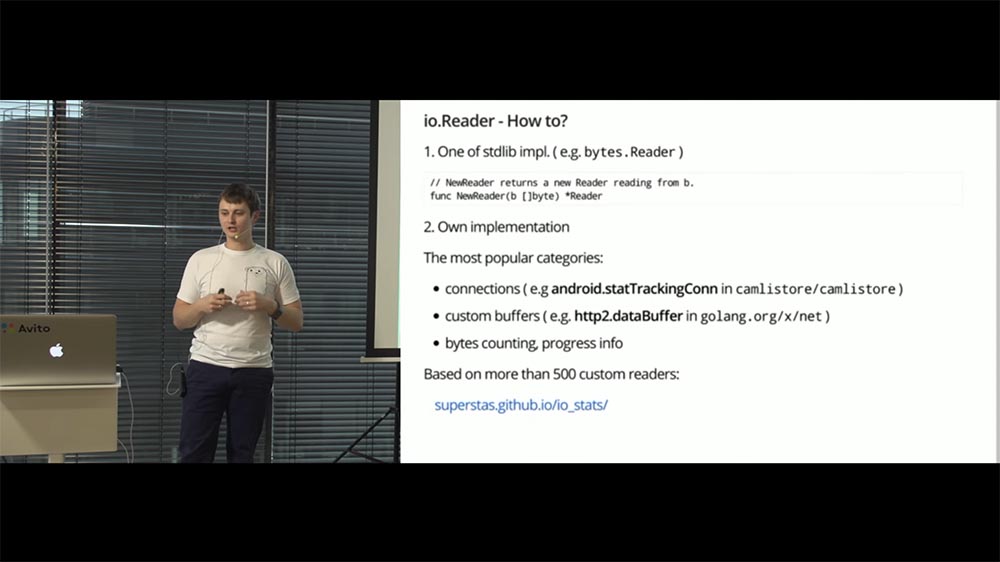
Первый — самый простой. Если у вас есть какой-то slice byte, и вы хотите сделать так, чтобы он удовлетворял интерфейсу Reader, можно взять реализацию какой-то стандартной библиотеки, которая уже удовлетворяет этому интерфейсу. Например, Reader из пакета bytes. На слайде выше видна сигнатура, как создаётся этот Reader.
Есть способ посложнее — реализовать самостоятельно интерфейс Reader. В документации есть примерно 30 строк с хитрыми правилами, ограничениями, которые необходимо соблюдать. Прежде чем мы обо всех поговорить, мне стало интересно: «А в каких случаях недостаточно стандартных реализаций (стандартной библиотеки)? Когда наступает тот момент, когда нам необходимо реализовывать интерфейс Reader самостоятельно»?
Для того чтобы ответить на этот вопрос, я взял тысячу самых популярных репозиториев на Github (по количеству звёзд), сполил их и нашёл там все реализации интерфейса Reader. На слайде у меня представлена некоторая статистика (разбитая по категориям) того, в каких случаях люди реализуют этот интерфейс.
- Самая популярная категория — connections. Это реализация как собственных протоколов, так и обёртки для уже существующих типов. Так, у Брэда Фитцпатрика есть проект Camlistore — там есть пример в виде statTrackingConn, который, в общем-то, является обычным Wrapper над типом con из пакета net (добавляет метрик к этому типу).
- Вторая категория по популярности — это кастомные буферы. Здесь мне понравился один-единственный пример: dataBuffer из пакета x/net. Его особенность в том, что он хранит данные, порезанные на чанки (chunks), и при вычитывании проходится по этим чанкам. Если в чанке данные закончились — он переходит к следующему чанку. При этом он учитывает ту длину, то место, которое он может заполнить в переданном слайсе.
- Ещё одна категория — это всевозможные progress-bars, подсчёты количества вычитанных байт с отправкой в метрики…
Исходя из этих данных, можно сказать, что необходимость реализовывать интерфейс io.Reader возникает довольно часто. Давайте тогда начнём говорить о правилах, которые есть в документации.
Правила документации
Как я уже сказал, список правил, и вообще документация — довольно большие, массивные. 30 строк — это достаточно много для интерфейса, который всего из трёх строк состоит.
Первое, самое важное правило касается количества возвращаемых байт. Оно должно строго больше или равно нулю и меньше или равно длине присланного slice. Почему это важно?

Так как это довольно строгий контракт, клиент может довериться тому количеству, которое приходит из реализации. В стандартной библиотеке существуют Wrapper«ы (например, bytes.Buffer и bufio). В стандартной библиотеке есть такой момент: некоторые реализации доверяют обёрнутым Reader«ам, некоторые не доверяют (об это мы ещё поговорим).
Bufio вообще ничему не доверяет — проверяет абсолютно всё. Bytes.Buffer доверяет абсолютно всему, что ему прилёт. Сейчас я продемонстрирую, что происходит в связи с этим…
Мы сейчас рассмотрим три возможных кейса — это три реализованных Reader«а. Они достаточно синтетические, полезны для понимания. Все эти Reader«ы мы будем вычитывать при помощи хелпера ReadAll. Его сигнатура представлена наверху слайда:

io.Reader#1. Пример 1
ReadAll — это хелпер, который принимает какую-то реализацию интерфейса Reader, вычитывает её всю и возвращает те данные, которые он вычитал, а также ошибку.
Первый наш пример — это Reader, который всегда будет возвращать -1 и nil в качестве ошибки, то есть такой NegativeReader. Давайте его запустим и посмотрим, что же будет:

Как известно, паника без причины — признак дурачины. Но кто в этом случае дурачина — я или byte.Buffer — зависит от точки зрения. У тех, кто пишет этот пакет и кто за ним следит, имеют разные точки зрения.
Что здесь произошло? Bytes.Buffer принял отрицательное количество байт, не проверил, что оно отрицательное, и внутренний буфер попытался отрезать по верхней границе, которую он получил — и мы получили выходит за границы slice.
В этом примере есть две проблемы. Первая — это то, что сигнатурой не запрещено возвращать отрицательные числа, а документацией запрещено. Если бы в сигнатуре был Uint, то мы получали бы классическое переполнение (когда число со знаком интерпретируется как беззнаковое). А это очень хитрый баг, который обязательно произойдёт в пятницу вечером, когда вы уже домой собрались. Поэтому паника в этом случае — вариант предпочтительный.
Второй «пойнт» — в том, что по stack trace не понятно, что вообще произошло. Понятно, что мы вышли за границы слайса — ну и что? Когда у вас столь многослойный pipe и происходит такая ошибка, не с ходу понятно, что произошло. Так вот bufio стандартной библиотеки тоже «паникует» в этой ситуации, но делает более красиво. Он сразу пишет: «Я вычитал отрицательное количество байт. Делать больше ничего не буду — не знаю, что с этим делать».
А bytes.Buffer паникует как может. Я отправил issue в Golang с предложением добавить человеческую ошибку. Дня три мы обсуждали перспективы этого решения. Причина такова: исторически так сложилось, что разными людьми в разное время были приняты разные несогласованные решения. И сейчас мы имеем следующее: в одном случае мы не доверяем реализации вообще (проверяем всё), а в другом — доверяем полностью, нам по барабану, что оттуда придёт. Это не решённый вопрос, и мы об этом ещё поговорим.
io.Reader#1. Пример 2
Следующая ситуация: наш Reader будет возвращать всегда 0 и nil в качестве результатов. С точки зрения контрактов здесь всё законно — никаких проблем нет. Единственный нюанс: в документации написано, что реализации не рекомендуется возвращать значения 0 и nil, кроме того кейса, когда длина присланного slice равна нулю.
В реальной жизни такой Reader может доставить массу неприятностей. Так, мы возвращаемся к вопросу, должны ли мы доверять Reader«у? Например, в bufio встроена проверка: он последовательно читает Reader ровно 100 раз — если 100 раз возвращается такая пара значений, он просто возвращает NoProgress.
В bytes.Buffer ничего подобного нет. Если мы запустим этот пример, мы получим просто бесконечный цикл (ReadAll под капотом использует bytes.Buffer, а не сам вычитывает Reader):

io.Reader#1. Пример 2
Ещё один пример. Он тоже довольно синтетический, но полезен для понимания:

Здесь мы возвращаем всегда 1 и nil. Казалось бы, здесь тоже никаких проблем нет — всё законно с точки зрения контракта. Есть нюанс: если я запущу этот пример на своём компьютере, то он зависнет секунд через 30…
Связано это с тем, что клиент, который вычитывает этот Reader (т. е. bytes.Buffer), никогда не получает признака конца данных — вычитывает, вычитывает… Плюс к этому, он каждый раз получает один вычитанный байт. Для него это значит, что в какой-то момент заканчивается прелоцированный буфер, он элоцирует ещё — ситуация повторяет, и он элоцирует до бесконечности, пока не лопнет.
io.Reader#2. Возврат ошибки
Мы подходим ко второму важному правилу реализации интерфейса Reader — это возвращение ошибки. В документации оговорены три ошибки, которые реализация должна возвращать. Самая главная из них — это EOF.
EOF — это тот самый признак конца данных, который реализация должна возвращать всякий раз, когда данные у неё закончились. Концептуально это, в общем-то, не ошибка, а сделано в качестве ошибки.
Есть ещё одна ошибка, которая называется UnexpectedEOF. Если вдруг во время чтения Reader не может больше вычитывать данные, задумывалось, что он будет возвращать UnexpectedEOF. Но по факту эта ошибка используется только в одном месте стандартной библиотеки — в функции ReadAtLeast.

Ещё одна ошибка — NoProgress, о которой мы уже говорили. В документации так и написано: это — признак того, что интерфейс реализован фигово.
Io.Reader#3
В документации оговаривается набор кейсов, как ошибку нужно правильно возвращать. Внизу вы можете посмотреть три возможных кейса:

Мы можем вернуть ошибку как вместе с количеством вычитанных байт, так и отдельно. Но если вдруг в вашем Reader данные закончились, и вы не можете сейчас вернуть [признак окончания] EOF (многие реализации стандартной библиотеки именно так и работают), то допускается, что вы на следующий последовательный вызов вернёте EOF (т. е. вы должны отпустить клиента).
Для клиента это значит, что данных больше нет — больше ко мне не приходи. Если вы возвращаете nil, а клиенту нужны данные, то он должен прийти к вам ещё раз.
io.Reader. Mistakes
В общем-то, по Reader«у это были основные важные правила. Есть ещё набор мелких, но они не такие важные и не приводят к такой ситуации:

Прежде чем мы пройдём всё, что касается Reader«а, надо ответить на вопрос: важно ли это, часто ли случаются ошибки в кастомных реализациях? Чтобы ответить на этот вопрос, я обратился к своей шпуле (spool) на 1000 репозиториев (а там получилось порядка 550 кастомных реализаций). Я глазами первую сотню посмотрел. Конечно, это не суперанализ, но какой есть…
Определил две самые популярные ошибки:
- никогда не возвращается EOF;
- слишком большое доверие к обёрнутому Reader«у.
Опять-таки, это проблема с моей точки зрения. А со стороны тех, кто смотрит за пакетом io, это не проблема. Мы об это ещё поговорим.
К одному нюансу я хотел бы вернуться. Смотрите:

Клиент ни в коем случае не должен интерпретировать пару 0 и nil как EOF. Это ошибка! Для Reader«а это значение — всего лишь возможность отпустить клиента. Так вот две ошибки, о которых я сказал, кажутся несущественными, но достаточно представить, что у вас в проде многослойный pipeline и в середину закралась маленькая, хитрая «багуля», то «подземный стук» не заставит себя ждать долго — гарантированно!
По Reader«у в принципе всё. Это были основные правила реализации.
io.Writer
На другом конце пайплайнов у нас есть io.Writer — то, куда мы данные, как правило, пишем. Очень похожий интерфейс: он тоже состоит из одного метода (Write), сигнатура у них сходная. С точки зрения семантики интерфейс Writer является более понятным: я бы сказал, что как слышится, так и пишется.

Метод Write принимает slice byte и записывает его, в общем-то, целиком. У него тоже есть набор правил, которым необходимо следовать.
- Первое из них касается возвращаемого количества записываемых байт. Я бы сказал, что оно не такое строгое, потому что я не нашёл ни одного примера, когда это приводило бы к каким-то критическим последствиями — например, к panic«ам. Это не очень строго, потому что есть следующее правило…
- Реализация Writer обязана возвращать ошибку всякий раз, когда количество записанных данных меньше, чем было прислано. То есть частичная запись не поддерживается. Это значит, что не очень-то и важно то, сколько байт было записано.
- Ещё одно правило: Writer ни в коем случае не должен модифицировать присланный slice, потому что клиент с этим слайсом ещё будет работать.
- Writer не должен удерживать этот slice (такое же правило есть и у Reader«а). Если вам нужны данные в своей реализации для каких-то операций, вы должны просто скопировать этот слай, и всё.

По Reader и Writer всё.
Дендрограмма
Специально для этого доклада я сгенерировал граф реализации и оформил его в виде дендрограммы. Те, кто хочет прямо сейчас, может перейти по этому QR-коду:

На этой дендрограмме есть все реализации всех интерфейсов пакета io. Эта дендрограмма нужна для того, чтобы просто понять: что и с чем можно склеиваться в пайплайнах, откуда и что можно вычитывать, куда можно записывать. Я на неё ещё буду ссылаться по ходу своего доклада, поэтому обращайтесь к QR-коду.
Пайплайны (pipelines)
Мы поговорили о том, что такое Reader, io.Writer. Теперь поговорим о том API, который существует в стандартной библиотеке для построения пайплайнов. Начнём с самых основ. Может, это кому-то даже будет неинтересно. Тем не менее это очень важно.
Мы будем вычитывать данные стандартного потока ввода (из Stdin«а):

Stdin представлен в Go глобальной переменной типа file из пакета os. Если вы бросите взгляд на дендрограмму, то заметите, что тип file реализует в том числе интерфейсы Reader и Writer.
Конкретно сейчас нас интересует Reader. Мы будем вычитывать Stdin при помощи того же самого хелпера ReadAll, который мы уже использовали.
Один нюанс относительно этого хелпера стоит заметить: ReadAll вычитывает Reader до конца, но окончание он определяет именно по EOF«у, по тому признаку окончания, о котором мы говорили.
Мы будем сейчас лимитировать количество данных, которые мы вычитываем из Stdin. Для этого в стандартной библиотеке существует реализация LimitedReader:

Я бы хотел, чтобы вы обратили внимание на то, как LimitedReader ограничивает вычитываемое количество байт. Можно было бы подумать, что эта реализация, этот Wrapper вычитает всё, что есть в Reader«е, который он оборачивает, а потом отдаст столько, сколько мы хотим. Но всё работает немного по-другому…
LimitedReader обрезает по верхней границе тот slice, который ему подают в качестве аргумента. И этот обрезанный слайс он передаёт в Reader, который оборачивает. Это наглядная демонстрация того, как регулируется длина вычитываемых данных в реализациях интерфейса io.Reader.
Возврат ошибки end of file
Ещё один интересный момент: обратите внимание, как эта реализация возвращает ошибку EOF! Здесь используются возвращаемые именованные значения, и они присваиваются теми значениями, которые мы получаем из обёрнутого Reader«а.
И если так происходит, что в обёрнутом Reader«е данных больше, чем нам нужно, мы присваиваем значения завёрнутого Reader«а — допустим, 10 байт и nil — потому что в обёрнутом Reader«е ещё есть данные. Но переменная n, которая уменьшается (в предпоследней строке), говорит, о том, что мы достигли «дна» — конца того, что нам нужно.
В следующей итерации клиент должен прийти ещё раз — на первом условии он получит EOF. Этот самый кейс, о котором я упоминал.
Продолжение будет совсем скоро…
Немного рекламы :)
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас, оформив заказ или порекомендовав знакомым, облачные VPS для разработчиков от $4.99, уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5–2697 v3 (6 Cores) 10GB DDR4 480GB SSD 1Gbps от $19 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле в дата-центре Equinix Tier IV в Амстердаме? Только у нас 2 х Intel TetraDeca-Core Xeon 2x E5–2697v3 2.6GHz 14C 64GB DDR4 4×960GB SSD 1Gbps 100 ТВ от $199 в Нидерландах! Dell R420 — 2x E5–2430 2.2Ghz 6C 128GB DDR3 2×960GB SSD 1Gbps 100TB — от $99! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5–2650 v4 стоимостью 9000 евро за копейки?
