Стандартное отклонение и стандартная ошибка: две статистики с похожими названиями, но разными смыслами
Я читаю курс статистического мышления магистрам, и одна тема вызывает у них явные затруднения — чем стандартное отклонение отличается от стандартной ошибки и в каких случаях применять ту или иную статистику. Думаю, будет интересно поговорить об этом в блоге ЛАНИТ.
Случайные величины
Пусть  — случайная нормально распределенная величина. Ее математическое ожидание в теории вероятностей обозначается
— случайная нормально распределенная величина. Ее математическое ожидание в теории вероятностей обозначается![M[X]](https://habrastorage.org/getpro/habr/upload_files/0b9/f73/da7/0b9f73da73f7f2b457c6b0225bc3530d.svg) или
или ![E[X]](https://habrastorage.org/getpro/habr/upload_files/8e5/820/90b/8e582090bf7964736f95c611f86966b9.svg) , а в статистике —
, а в статистике —  . Сформируем две выборки по 100 значений. Для генерации выборок в Excel воспользуемся формулой =НОРМ.ОБР (СЛЧИС (); ;
. Сформируем две выборки по 100 значений. Для генерации выборок в Excel воспользуемся формулой =НОРМ.ОБР (СЛЧИС (); ;  ). Зададим одинаковые матожидания
). Зададим одинаковые матожидания  и разные среднеквадратичные отклонения:
и разные среднеквадратичные отклонения:  и
и  .
.

Рис. 1. Нормально распределенные случайные величины. По оси абсцисс — номер элемента в выборке, по оси ординат — значение нормально распределенной случайной величины. Видно, что увеличение среднеквадратичного отклонения приводит к большему разбросу точек.
Среднее арифметическое выборки
Несмотря на то, что мы задали для генерирующего процесса матожидание  , среднее по выборке будет отличаться от этого значения. Среднее по выборке называют средним арифметическим
, среднее по выборке будет отличаться от этого значения. Среднее по выборке называют средним арифметическим  (или просто средним), и рассчитывают по формуле:
(или просто средним), и рассчитывают по формуле:

где  — отдельные значения случайной величины,
— отдельные значения случайной величины,  — число значений случайной величины в выборке.
— число значений случайной величины в выборке.
Для выборок на рис. 1 оказалось, что  ,
,  .
.
Дисперсия и среднеквадратичное отклонение генеральной совокупности
Для измерения рассеяния (изменчивости) случайной величины относительно ее матожидания наиболее часто используют дисперсию, обозначаемую ![D[X]](https://habrastorage.org/getpro/habr/upload_files/dc3/3b2/7ee/dc33b27eef4b937aabbd6d778eed2c6f.svg) ,
, ![Var[Х]](https://habrastorage.org/getpro/habr/upload_files/809/44c/7b8/80944c7b8b797ef54827c01c6804bf89.svg) или
или 

… и среднеквадратичное отклонение 

Стандартное отклонение выборки
Стандартное отклонение (Standard Deviation, SD)  вычисляется по формуле:
вычисляется по формуле:

Вообще термины используются разными авторами немного по-разному. Мне нравится следующий подход. Генеральную совокупность описывают параметрами, обозначаемыми греческими буквами: математическое ожидание  и среднеквадратичное отклонение
и среднеквадратичное отклонение  . Выборки описывают статистиками, обозначаемыми латинскими буквами: среднее арифметическое
. Выборки описывают статистиками, обозначаемыми латинскими буквами: среднее арифметическое  и стандартное отклонение .
и стандартное отклонение .
В реальной жизни ни матожидание, ни среднеквадратичное отклонение σ генеральной совокупности неизвестны. Но, извлекая выборку, мы кое-что узнаем о матожидании и среднеквадратичном отклонении. Говорят, что среднее является оценкой матожидания, а стандартное отклонение — оценкой среднеквадратичного отклонения σ.
При генерации случайной величины мы задали  и
и  . Для выборок на рис. 1 получили
. Для выборок на рис. 1 получили  ,
,  .
.
Чем меньше , тем кучнее значения располагаются вокруг среднего. Итак,
стандартное отклонение — мера разброса данных в выборке
Стандартное отклонение средних значений выборок
Сосредоточимся теперь на процессе генерации случайных чисел с  и
и  . Извлечем не одну выборку, а несколько. Хотя аргументы
. Извлечем не одну выборку, а несколько. Хотя аргументы  и
и  генератора случайных чисел постоянны, случайный процесс будет приводить к разным значениям для отдельных выборок:
генератора случайных чисел постоянны, случайный процесс будет приводить к разным значениям для отдельных выборок:


Если возьмем не 15, а 1000 выборок, то сможем построить довольно гладкое распределение средних значений :
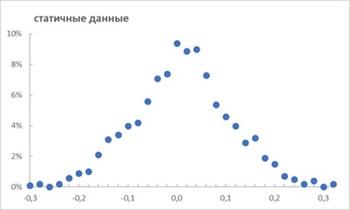
для 1000 выборок размером  . По оси абсцисс диапазоны средних значений выборок, по оси ординат доля таких выборок
. По оси абсцисс диапазоны средних значений выборок, по оси ординат доля таких выборокСовокупность средних  можно рассматривать как случайную величину
можно рассматривать как случайную величину  . Для ее распределения (рис. 3) также можно подсчитать стандартное отклонение по формуле (4):
. Для ее распределения (рис. 3) также можно подсчитать стандартное отклонение по формуле (4):  . Нижний индекс указывает, что стандартное отклонение относится к средним значениям . Обратите внимание, что стандартное отклонение одной выборки (рис. 1а) равнялось
. Нижний индекс указывает, что стандартное отклонение относится к средним значениям . Обратите внимание, что стандартное отклонение одной выборки (рис. 1а) равнялось . Стандартное отклонение каждой выборки задается генерирующим процессом, в котором среднеквадратичное отклонение генеральной совокупности
. Стандартное отклонение каждой выборки задается генерирующим процессом, в котором среднеквадратичное отклонение генеральной совокупности  . Для средних значений выборок размером
. Для средних значений выборок размером  стандартное отклонение
стандартное отклонение  приблизительно в 10 раз меньше, чем для отдельных значений в выборке
приблизительно в 10 раз меньше, чем для отдельных значений в выборке  .
.
Подсчитаем стандартное отклонение для 100 выборок других размеров  . Оказывается, что стандартное отклонение средних значений зависит от размера выборки:
. Оказывается, что стандартное отклонение средних значений зависит от размера выборки:
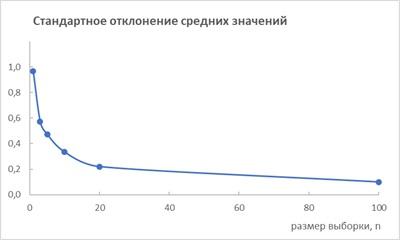
Рис. 4. Зависимость стандартного отклонения средних значений от размера выборок
Выведем формулу этой зависимости.
Формула стандартной ошибки
Для начала покажем, что постоянный множитель можно вынести за знак дисперсии, возведя его в квадрат.
По определению дисперсия случайной величины
случайной величины  равна
равна
![(5)Var(X)=E[(X-E[X])^2]](https://habrastorage.org/getpro/habr/upload_files/7b2/b6d/1a6/7b2b6d1a6501f650e0f5fce7d01d3dc5.svg)
где ![E[X]](https://habrastorage.org/getpro/habr/upload_files/478/86e/936/47886e936ab5410810ae9146f8415665.svg) — математическое ожидание случайной величины
— математическое ожидание случайной величины ![X, E[(X-E[X])^2]](https://habrastorage.org/getpro/habr/upload_files/ba5/e02/7d3/ba5e027d3dd59762596fb8fc3ee8bb7b.svg) — математическое ожидание квадрата разности самой случайной величины и ее матожидания.
— математическое ожидание квадрата разности самой случайной величины и ее матожидания.
Рассмотрим теперь случайную величину  , где
, где  — константа. Найдем дисперсию
— константа. Найдем дисперсию 
![(6)Var(Y)=E[(Y-E[Y])^2]=E[(cX-E[cX])^2]=E[c^2(X-E[X])^2]=c^2E[(X-E[X])^2]=c^2Var(X)](https://habrastorage.org/getpro/habr/upload_files/822/436/b5d/822436b5da0ea6b072bd74605cd13c3d.svg)
С другой стороны, среднее арифметическое по выборке:

Дисперсия выборки:

Здесь мы воспользовались только что выведенным свойством (6), используя  .
.
Теперь учтем, что дисперсия суммы независимых случайных величин равняется сумме их дисперсий:

Примем во внимание, что все случайные величины  одинаково распределены:
одинаково распределены:

Извлекая корень и переходя от параметра генеральной совокупности к статистике выборки, можем записать стандартное отклонение случайной величины  :
:

Мы получили зависимость стандартного отклонения средних значений выборок  от стандартного отклонения единичных значений
от стандартного отклонения единичных значений  и размера выборки
и размера выборки  . Если в (11) подставить (4), получим:
. Если в (11) подставить (4), получим:

Величинуназывают стандартной ошибкой или стандартной ошибкой среднего. позволяет по одной выборке оценить в каком диапазоне от среднего по выборке находится матожидание генеральной совокупности  . Например, в диапазон
. Например, в диапазон  матожидание генеральной совокупности попадет с вероятностью 95%.
матожидание генеральной совокупности попадет с вероятностью 95%.
Если стандартное отклонение — это показатель изменчивости элементов в выборке, то стандартная ошибка — аналогичный показатель (вычисляемый по той же формуле) изменчивости средних значений выборок.
Итак,
стандартная ошибка — мера оценки математического ожидания генеральной совокупности μ на основании выборочного среднего .
Обратите внимание, что с увеличением размера выборки  стандартная ошибка будет уменьшаться. В пределе при
стандартная ошибка будет уменьшаться. В пределе при  ,
,  и
и  .
.
Смещенные и несмещенные оценки
Оценку параметра генеральной совокупности в общем случае можно представить уравнением:
(13) Оценка = Оцениваемый параметр генеральной совокупности + Смещение + Шум
Оказывается, что среднее арифметическое является несмещенной оценкой матожидания:

Чтобы проиллюстрировать этот вывод, я случайным образом задал 10 000 чисел в диапазоне от 0 до 100. А затем создал 100 выборок по 100 последовательных значений: от 1 до 100, от 101 до 200 и т.д. На график в виде пунктирной линии нанес среднее значение для всех 10 000 случайных чисел, а также в виде точек — скользящее среднее для последовательности выборок. Например, первая точка — среднее арифметическое для первой выборки: 1…100, вторая точка — среднее статистик двух выборок: 1…100 и 101…200 и т.д.
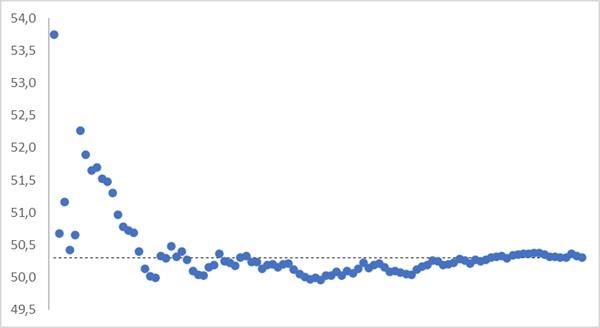
Рис. 5. Среднее арифметическое, как несмещенная оценка матожидания. Видно, что среднее выборок стремится к среднему по всей совокупности.
Представляется парадоксальным, но стандартное отклонение оказалось смещенной оценкой среднеквадратичного отклонения:

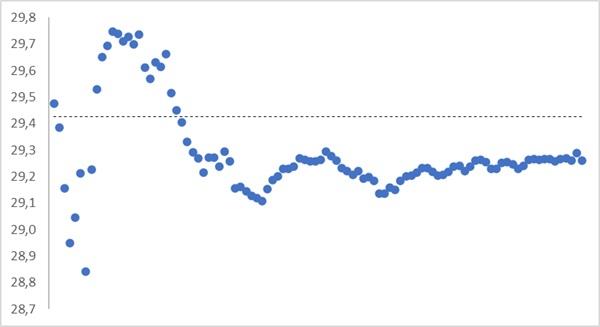
Рис. 6. Стандартное отклонение, как смещенная оценка среднеквадратичного отклонения
Выборочная оценка среднеквадратичного отклонения, названная нами стандартным отклонением, и введенная формулой (4) дает систематическую ошибку!
Поправка Бесселя
Чтобы разобраться с источником систематической ошибки, еще раз приведем формулы среднеквадратичного и стандартного отклонений.


… и вернемся к примеру на рис. 1а.
Мы знаем (сами задали в Excel), что матожидание генеральной совокупности  . Но среднее арифметическое выборки
. Но среднее арифметическое выборки  . И это наша лучшая оценка матожидания. Правильная (несмещенная) оценка среднеквадратичного отклонения генеральной совокупности σ должна была бы основываться на отклонениях от
. И это наша лучшая оценка матожидания. Правильная (несмещенная) оценка среднеквадратичного отклонения генеральной совокупности σ должна была бы основываться на отклонениях от  по формуле (3). Но если мы не знаем истинное значение
по формуле (3). Но если мы не знаем истинное значение  , то вычисляем стандартное отклонение
, то вычисляем стандартное отклонение  от по формуле (4).
от по формуле (4).
Заметим, что  в формуле (3) можно представить, как
в формуле (3) можно представить, как  , где
, где  – константа (смещение), показывающая насколько выборочное среднее отличается от матожидания генеральной совокупности. Тогда
– константа (смещение), показывающая насколько выборочное среднее отличается от матожидания генеральной совокупности. Тогда  можно заменить на
можно заменить на  . Обозначим разность
. Обозначим разность  одним символом
одним символом  . В формуле (4) мы ищем сумму
. В формуле (4) мы ищем сумму  , а в формуле (3) — сумму
, а в формуле (3) — сумму  . Но
. Но

По определению сумма вторых слагаемых по выборке  равна нулю — отклонения от среднего в разные стороны компенсируют друг друга. На то оно и среднее. Сумма
равна нулю — отклонения от среднего в разные стороны компенсируют друг друга. На то оно и среднее. Сумма  представляет собой сумму квадратов расстояния от значений выборки до среднего выборочного значения.
представляет собой сумму квадратов расстояния от значений выборки до среднего выборочного значения.  — сумма квадратов расстояний между средним арифметическим по выборке и матожиданием генеральной совокупности.
— сумма квадратов расстояний между средним арифметическим по выборке и матожиданием генеральной совокупности.
Поскольку положительна (за исключением случая, когда  ) сумма квадратов расстояния от значений выборки до матожидания генеральной совокупности всегда будет больше, чем сумма квадратов расстояния до выборочного среднего.
) сумма квадратов расстояния от значений выборки до матожидания генеральной совокупности всегда будет больше, чем сумма квадратов расстояния до выборочного среднего.
Вот почему  дает систематическую ошибку (в сторону уменьшения) по сравнению с
дает систематическую ошибку (в сторону уменьшения) по сравнению с  .
.
В смещенной оценке , используя выборочное среднее вместо матожидания, мы недооцениваем каждое  на
на  .
.
Чтобы найти расхождение между смещенной оценкой  и параметром генеральной совокупности σ, нужно найти матожидание
и параметром генеральной совокупности σ, нужно найти матожидание  . В разделе Формула стандартной ошибки мы показали, что это матожидание равно дисперсии выборочного среднего σ/n. Таким образом, смещенная оценка занижает на
. В разделе Формула стандартной ошибки мы показали, что это матожидание равно дисперсии выборочного среднего σ/n. Таким образом, смещенная оценка занижает на  :
:
 смещенная оценка
смещенная оценка  несмещенная оценка
несмещенная оценка  несмещенная оценка
несмещенная оценка
Поправкой Бесселя называют коэффициент  , на который следует умножить стандартное отклонение, чтобы смещенную оценку сделать несмещенной:
, на который следует умножить стандартное отклонение, чтобы смещенную оценку сделать несмещенной:

Проверим поведение  на модели:
на модели:

Рис. 7. Стандартное отклонение, как несмещенная оценка среднеквадратичного отклонения
Поправку Бесселя следует ввести и в формулу (12) для расчета стандартной ошибки среднего. Получим:

Допущения
При выводе формул стандартного отклонения и стандартной ошибки явно или неявно мы использовали следующие допущения:
данные в выборке подчиняются нормальному распределению;
выборка является репрезентативной для генеральной совокупности;
наблюдения в выборке независимы друг от друга; для временных рядов допущение о независимости как правило нарушено;
измерения проводятся на интервальной или относительной шкале; использование категориальных данных может быть некорректным;
оценки чувствительны к выбросам.
Посмотрим, что происходит, когда одно или несколько допущений нарушены.
Распределения с жирными хвостами
Нормальное распределение обладает тонким хвостом. Это означает, что поведение нормально распределенной случайной величины определяется центральной частью распределения. Хвостовые значения встречаются очень редко. Центральная предельная теорема дает быструю сходимость, и мы наблюдаем характерное поведение, как на рис. 5.
На мой запрос ChatGPT указал три области, где данные хорошо описываются нормальным распределением: рост людей, ошибки измерения (длины или массы среди однородной группы объектов), интеллектуальные способности (тесты IQ разработаны с учетом нормального распределения, и средний уровень интеллекта обычно приходится на центральную часть распределения).
Нормальное распределение настолько растиражировано, что мы используем его даже тогда, когда этого делать не следует — при работе с финансовыми инструментами, экономическими и социальными явлениями. Типичный пример — средний доход посетителей бара, который взлетит до миллиарда, если туда случайной зайдет Билл Гейтс.
Посмотрим, как сходится к среднему случайная величина, заданная стандартным распределением Коши:

Для моделирования в Excel я воспользовался тем фактом, что t-распределение Стьюдента с числом степеней свободы  эквивалентно стандартному распределению Коши. А для t-Стьюдента в Excel есть формулы прямого и обратного распределений.
эквивалентно стандартному распределению Коши. А для t-Стьюдента в Excel есть формулы прямого и обратного распределений.
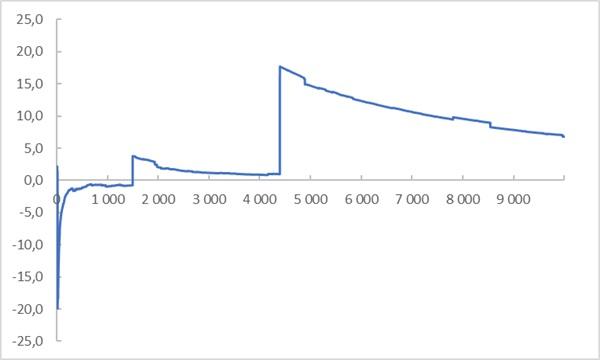
Рис. 8. Сходимость распределения Коши вроде бы есть…, но только до очередного выброса
Если мы посмотрим на допущения, сформулированные выше, то увидим, что данные, распределенные по Коши, нарушают почти все. (1) Никакая выборка не является репрезентативной. Хвостовые значения всё еще относительно редки (правда, не настолько, как при нормальном распределении), но именно они определяют среднее по выборке. (2) Наличие или отсутствие выброса в выборке сильнее влияет на среднее арифметическое, чем центральная тенденция.
Вслед за средним арифметическим, и стандартное отклонение, и стандартная ошибка, полученные на основе выборки, мало что говорят о генеральной совокупности.
В качестве примера я привел экстремально жирнохвостое распределение Коши, но и многие иные распределения, например, степенные, ведут себя лишь немногим более предсказуемо. Эта тема подробно раскрыта в новой книге Нассима Талеба (см. ссылку ниже).
Области использования
Вот несколько областей использования стандартного отклонения:
Оценка разброса данных (изменчивости) относительно среднего значения. Чем больше стандартное отклонение, тем больше разброс.
Оценка качества как индикатор изменчивости процесса производства или управления. Меньшее стандартное отклонение говорит о более стабильном процессе. Стандартное отклонение может использоваться для построения границ контрольных карт Шухарта.
Области использования стандартной ошибки среднего (Standard Error of the Mean, SEM):
Доверительные интервалы для среднего значения. Например, если вы провели опрос с небольшой выборкой и вычислили среднее и SEM, то можете построить доверительный интервал, указывающий, где находится истинное среднее в генеральной совокупности.
При сравнении средних значений из разных выборок SEM используется для определения статистической значимости различий между выборками. Если разница средних значений превышает несколько SEM, это может свидетельствовать о статистически значимом различии.
SEM указывает, насколько точно среднее выборки оценивает истинное среднее в генеральной совокупности. Большая SEM указывает на большую неопределенность в оценке.
С осторожностью и оговорками стандартное отклонение и стандартную ошибку следует применять для оценки рисков в финансовой сфере. Формулы SD и SEM основаны на нескольких статистических предположениях. Важно понимать эти допущения при использовании и интерпретации результатов.
Литература
Владимир Гмурман. Теория вероятностей и математическая статистика
Поправка Бесселя, Bessel’s correction
Нассим Николас Талеб. Статистические последствия жирных хвостов.
