SQL HowTo: 1000 и один способ агрегации
Наш СБИС, как и другие системы управления бизнесом, не обходится без формирования отчетов — каждый руководитель любит сводные цифры, особенно всякие суммы по разделам и красивые »Итого».
А чтобы эти итоги собрать, необходимо по исходным данным вычислить значение некоторой агрегатной функции: количество, сумма, среднее, минимум, максимум, … — и, как правило, не одной.
Сегодня мы рассмотрим некоторые способы, с помощью которых можно вычислить агрегаты в PostgreSQL или ускорить выполнение SQL-запроса.
Совместные агрегаты
Давайте сразу возьмем задачу чуть посложнее, чем тривиальное вычисление единственного агрегата. Попробуем вычислить по одной и той же выборке несколько агрегатов одновременно, и пусть это будут количество и сумма элементов в некотором входном наборе:
->
$1 = '{2,3,5,7,11,13,17,19}'
<-
count | sum
8 | 77
Это самый-самый простой случай — просто сразу одновременно в запросе пишем count и sum:
SELECT
count(*)
, sum(prime)
FROM
unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime;
И хоть агрегатных функций мы использовали две, в плане у нас все хорошо — узел Aggregate выполнялся всего лишь один раз: 
«Несовместимые» агрегаты
Проблемы начинаются, если мы хотим вычислить сразу несколько агрегатов, но вот у каждого из них — разные условия [не]включения одной и той же записи исходного набора. Например, попробуем вычислить для нашего набора количество чисел больше и меньше 10 — отдельными полями:
->
$1 = '{2,3,5,7,11,13,17,19}'
<-
countlt | countgt
4 | 4Вложенные запросы
Понятно, что это можно сделать самым примитивным способом — вложенными запросами к CTE, каждый из которых сначала «выфильтровывает» себе из общей выборки подходящий под условия «кусочек», а потом считает на нем отдельный агрегат:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
(SELECT count(*) FROM src WHERE prime < 10) countlt
, (SELECT count(*) FROM src WHERE prime > 10) countgt;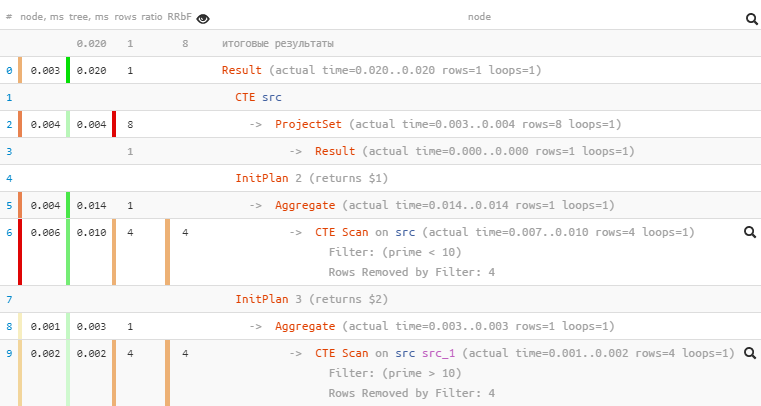
Какие из этого плана можно сделать выводы? Много бегаем и много фильтруем — дважды [CTE Scan + Rows Removed by Filter: 4].
А если выборка будет из 10K записей, а агрегатов захочется 3–4–5?… Совсем нехорошо.
FILTER-агрегаты
Этот вариант, наверное, самый простой и понятный:
SELECT
count(*) FILTER(WHERE prime < 10) countlt
, count(*) FILTER(WHERE prime > 10) countgt
FROM
unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime;
Он идеален во всех отношениях, быстро и эффективно решает все наши задачи, но имеет и ложку дегтя — доступен только с версии 9.4 (мало ли у кого что «на бою» стоит).
Агрегаты от условия
Допустим, 9.4 еще не подвезли, а запрос все-таки хочется написать «в один проход». В этом случае можно воспользоваться знанием, что count(*) FILTER(WHERE cond) эквивалентно sum(CASE cond):
SELECT
sum(CASE WHEN prime < 10 THEN 1 ELSE 0 END) countlt
, sum(CASE WHEN prime > 10 THEN 1 ELSE 0 END) countgt
FROM
unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime;
Или можно чуть короче, если вспомнить о возможности скастовать boolean в integer вместо CASE с результатами 1/0:
SELECT
sum((prime < 10)::integer) countlt
, sum((prime > 10)::integer) countgt
FROM
unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime;
Вообще, подход вычисления агрегата от некоторого условия достаточно универсален, но имеет и свои подводные камни.
Агрегация в массив
Допустим, мы хотим теперь получить не просто количество чисел, подходящих под то или иное условие, но массивы из них состоящие:
->
$1 = '{2,3,5,7,11,13,17,19}'
<-
primeslt | primesgt
{2,3,5,7} | {11,13,17,19}
И тут нам тоже поможет агрегат — ведь он возвращает одно значение, но тип его может быть не обязательно скаляром, но записью таблицы или даже массивом — с помощью array_agg.
Вариант с использованием FILTER очевиден:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
array_agg(prime) FILTER(WHERE prime < 10) primeslt
, array_agg(prime) FILTER(WHERE prime > 10) primesgt
FROM
src;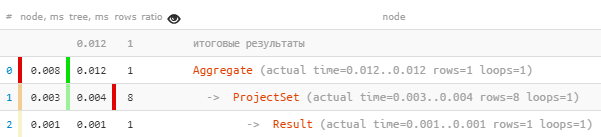
А вот если попытаться превратить его в агрегат от условия — придется разбираться с попаданием в набор NULL'ов, что уже совсем невесело:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
, tmp AS (
SELECT
array_agg(CASE WHEN prime < 10 THEN prime END) primeslt -- {2,3,5,7,NULL,NULL,NULL,NULL}
, array_agg(CASE WHEN prime > 10 THEN prime END) primesgt -- {NULL,NULL,NULL,NULL,11,13,17,19}
FROM
src
)
SELECT
ARRAY(SELECT * FROM unnest(primeslt) prime WHERE prime IS NOT NULL) primeslt
, ARRAY(SELECT * FROM unnest(primesgt) prime WHERE prime IS NOT NULL) primesgt
FROM
tmp;
Но если вам хоть немного повезло, и стоит хотя бы версия 9.3, то можно воспользоваться функцией array_remove для достижения того же эффекта:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
array_remove(array_agg(CASE WHEN prime < 10 THEN prime END), NULL) primeslt
, array_remove(array_agg(CASE WHEN prime > 10 THEN prime END), NULL) primesgt
FROM
src;Несколько агрегатов: Function Scan vs CTE
Мы тут внезапно вынесли наш исходный набор в CTE —, а почему? Потому что так банально быстрее. Давайте проверим на простом примере:
SELECT
array_agg(i) FILTER(WHERE i % 2 = 0) even
, array_agg(i) FILTER(WHERE i % 2 = 1) odd
FROM
generate_series(1, 1000000) i;
WITH src AS (
SELECT generate_series(1, 1000000) i
)
SELECT
array_agg(i) FILTER(WHERE i % 2 = 0) even
, array_agg(i) FILTER(WHERE i % 2 = 1) odd
FROM
src;
Почти на 40% быстрее! Пример, конечно, вырожденный, но эффект имеет место быть.
DISTINCT + OVER
Еще один способ агрегации «за единственный проход» заключается в использовании уникализации выборки с помощью DISTINCT и применения «окна» к агрегатной функции:
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT DISTINCT
array_agg(prime) FILTER(WHERE prime < 10) OVER() primeslt
, array_agg(prime) FILTER(WHERE prime > 10) OVER() primesgt
FROM
src;
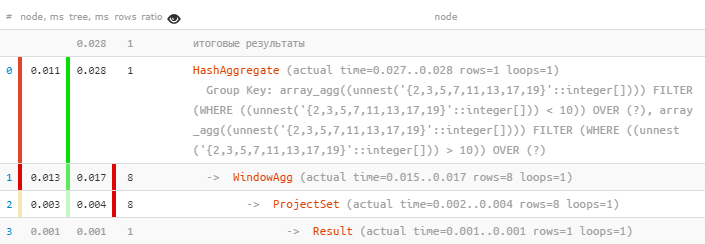
Единственная проблема — такая группировка «небесплатна»:
Сложный агрегат
Но предположим, что мы хотим что-то «этакое сложное», для чего нет подходящего агрегата:
->
$1 = '{2,3,5,7,11,13,17,19}'
<-
exp | val
2 * 3 * 5 * 7 * 11 * 13 * 17 * 19 = | 9699690
В этом примере мы хотим вычислить произведение всех участвующих чисел, но такой агрегатной функции — нету. Понятно, что ее можно создать, но как-то это неспортивно — создавать по функции, если потребность возникает редко.
Соберем запрос, который решит нашу задачу:
WITH RECURSIVE src AS (
SELECT
*
FROM
unnest('{2,3,5,7,11,13,17,19}'::integer[])
WITH ORDINALITY T(prime, rn)
)
, T(rn, exp, val) AS (
SELECT
0::bigint
-- база агрегации
, '{}'::integer[]
, 1
UNION ALL
SELECT
src.rn
-- итеративное вычисление сразу всех агрегатов
, exp || src.prime
, val * src.prime
FROM
T
JOIN
src
ON src.rn = T.rn + 1 -- переход к следующей записи
)
SELECT
array_to_string(exp, ' * ') || ' = ' exp
, val
FROM
T
ORDER BY -- отбор финального результата
rn DESC
LIMIT 1;
Кучеряво! Попробуем упростить и ускорить, опираясь на тот факт, что входной аргумент заведомо является массивом — то есть может быть перебран поэлементно:
WITH RECURSIVE src AS (
SELECT '{2,3,5,7,11,13,17,19}'::integer[] arr
)
, T(i, exp, val) AS (
SELECT
1::bigint
-- база агрегации
, '{}'::integer[]
, 1
UNION ALL
SELECT
i + 1
-- итеративное вычисление сразу всех агрегатов
, exp || arr[i]
, val * arr[i]
FROM
T
, src
WHERE
i <= array_length(arr, 1)
)
SELECT
array_to_string(exp, ' * ') || ' = ' exp
, val
FROM
T
ORDER BY -- отбор финального результата
i DESC
LIMIT 1;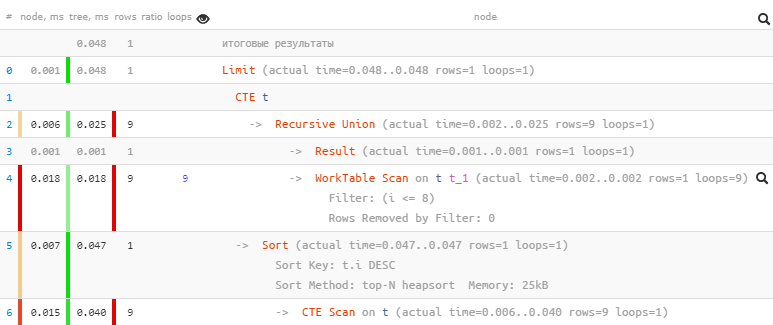
Намного лучше!
Math.bonus
Применим string_agg и немного математической магии: 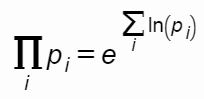
WITH src AS (
SELECT unnest('{2,3,5,7,11,13,17,19}'::integer[]) prime
)
SELECT
string_agg(prime::text, ' * ') || ' = ' exp
, exp(sum(ln(prime)))::integer val -- для любителей математики
FROM
src;
