Шпаргалка для подготовки к экзамену по машинному обучению
Небольшое предисловие
Многие студенты колледжей в России в этом году будут обязаны сдать демо-экзамен по дисциплине, посвящённой изучению темы машинного обучения, но качество обучения в учебном заведении может страдать в силу малого количества опыта в вопросе проведения подобного рода тестирования. В силу данного обстоятельства студенты в поисках материала для подготовки обращаются к помощи интернет ресурсов, но с ужасом обнаруживают, что информация не такая структуризированная, как было бы удобно экзаменуемым.
Меня тоже коснулась эта проблема, поэтому я решил написать статью, объясняющую принципы работы с необходимыми инструментами для сдачи демонстративного экзамена.
Чем эта статья отличается от любых других, посвящённых основам работы с pandas, seaborn и sklearn?
Именно данная работа обладает необходимой комплексностью повествования, описывающего специфику использования перечисленных ранее инструментов в контексте сдачи демонстративного экзамена. В данной статье собрано описание использования минимального набора инструментов, доступных к применению при выполнении поставленных комиссией задач.
Ход работы
Мы разбираем непосредственно один из демонстрационных вариантов прошлых лет, но в подробностях описывая каждый шаг, имея расчёт на то, что читатель сможет обратиться к шагам решения и описанным в них инструментам.
Скачать готовый ipynb файл и разбираемую таблицу можно по ссылке.
0 — Начало работы
В первую очередь нам необходима зайти в среду разработки, которая будет предоставлена на экзамене. Как правило это Anaconda Jupyter или Google Colab, однако экзаменационная комиссия вряд-ли будет против, если вы будете использовать что-то другое.
0.1 Заходим в Jupyter любым удобным способом:
0.2 Включаем подсказки. Для этого нам нужно перейти во вкладку Nbextensions, снять галочку с пункта » disable configuration …» и поставить галочку напротив пункта «Hinterland».

0.3 Создаём новый файл
1 — Выполнение примера первой части экзамена
1.1 — Импортируем необходимые для выполнения первой части библиотек
import pandas as pd
#Для манипуляции данными
import numpy as np
#Позволяет использовать новые математические инструменты, например читать NaN'ы
import matplotlib.pyplot as plt
#Для рисования графиков1.2 — Читаем необходимых нам файл
data = pd.read_csv('Адрес файла')
data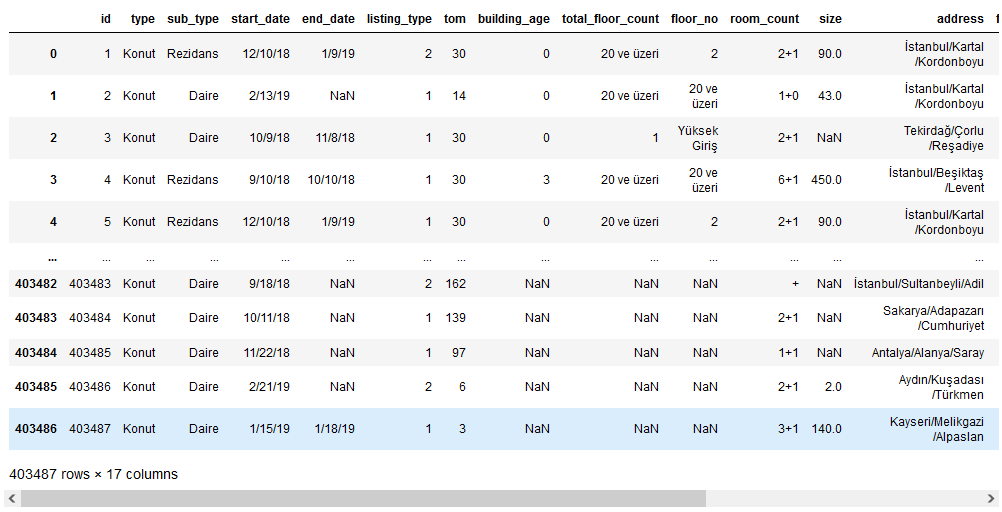
1.3 — Посмотрим информацию о созданном нами dataset’е
data.shape #Выводим размерность dataframe'a
data.info() #Вывадим информацие о df'e.
#Нам это нужно, что-бы узнать типы данных столбцов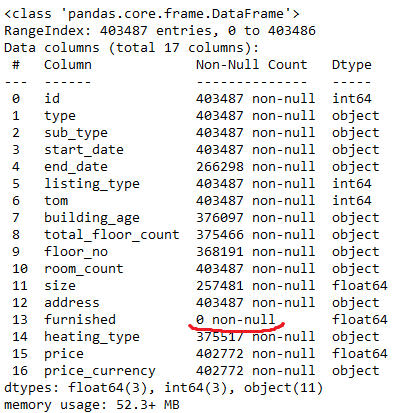
Благодаря этой команде мы узнали типы данных столбцов. Так-же можно заметить, что столбец furnished (мебельный) полностью заполнен пропусками данных (NaN) .
Давайте проверим количество пустых значений во всех столбцах.
data.isna().sum() #isna - ищет пустые значения(NaN'ы), а sum() выводить их сумму
1.4 — Удалим не информативные столбцы
data.drop("furnished", axis = 1, inplace = True) # Удаляем, т.к слишком много NaN
# axis = 1 обозначет то, что мы удаляем столбец, а не строку
# inplace = True обозначет то, что df изменён
data.drop(["end_date", "start_date"], axis = 1, inplace = True) #Удяляем даты из за их неинформативности 1.5 — Теперь нам для каждого столбца (признака) таблицы повторить этот процесс, если нужно. Заменяем строковые переменные на числовые и NaN’ы на средние значения
1.5.1 — Выполним действия над столбцом «total_floor_count»
Чтобы заменить найти строковые значения столбца нам нужно сначала их найти. Для этого воспользуемся методом value_counts ()
data["total_floor_count"].value_counts()
Строковые значения могут вызывать проблемы с обучение модели, так что заменим их на числовые.
data["total_floor_count"].replace("10-20 arası", 15, inplace = True)
#Заменяем элемнет "10-20 arası" на 15
data["total_floor_count"].replace("20 ve üzeri", 20, inplace = True)
#Заменяем элемент "20 ve üzeri" на 20Теперь нам нужно заменить пустые значения на медиану столбца
data["total_floor_count"].fillna(data["total_floor_count"].median(), inplace = True)
#При помощи fillna заменяем NaN'ы на медиану столбца
data["total_floor_count"] = data["total_floor_count"].astype("int64")
#Приобразуем столбец в тип данных int641.5.2 — Теперь выполним действия над столбцом «building_age»
data["building_age"].value_counts() 
Этот столбец содержит много строковых и много числовых значений, что делает обработку данных невозможной. Для того, что-бы обеспечить дальнейшую работоспособность программы нам необходимо декодировать этот столбец, т.е заменить все строковые значения на их уникальные номера.
Для этого импортируем LabelEncoder
from sklearn.preprocessing import LabelEncoder #Импортируем LabelEncoder
le = LabelEncoder() #Создаём экземпляр LabelEncoderЗаменяем столбец «building_age» на его декодированную версию
data["building_age"] = le.fit_transform(data["building_age"].astype(str))Проверим результат декодирования столбца
data["building_age"].value_counts()
»! Узнай что это или удали!»
le.classes_
1.5.3 — Теперь подготовим столбец «floor_no»
Посмотрим уникальные значения столбца
data["floor_no"].value_counts()
В столбце 'floor_no' мы считаем не информативным, так как он может зашумить нашу модель. Удалим его.
data.drop("floor_no", axis =1, inplace = True)1.5.4 — Перейдём к столбцу «size»
data["size"].value_counts()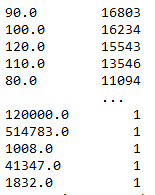
Столбец полностью состоит из числовых значений, следовательно его квантиль (Значение, которое заданная случайная величина не превышает с фиксированной вероятностью) может иметь выбросы (значения сильно больше или сильно меньше среднего). Это может негативно повлиять на качество модели. Чтобы этого избежать нам нужно посчитать максимальный и минимальный квантиль, чтобы затем удалить их выбросы.
quant = data["size"].quantile(0.9)# считаем квантиль 90 %
quant_low = data["size"].quantile(0.1)# считаем квантиль 10 %df_new = data[data["size"] < quant] # убираем выбросы по квантилю
df_new = df_new[df_new["size"] > quant_low] # убираем выбросы по квантилюВ демонстративных целях мы можем построить график, называемый 'ящиком с усами', чтобы проверить верность нашего решения.
df_new.boxplot("size") # строим ящик с усами и показываем, что выбросов практически нет Выбросов практически нет
Выбросов практически нет
Для дальнейшего преобразования столбца нам нужно посчитать его максимум
df_new[df_new["size"] < quant]["size"].max() # считаем максимум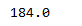
Теперь проверим есть ли в столбце пустые значения
df_new.isna().sum() # пустых значений нет Пустых значений нет
Пустых значений нет
1.5.5 — Разберём столбец «heating_type»
Посмотрим его уникальные значения
df_new["heating_type"].value_counts()
Заменим строки на самое популярное значение столбца и закодируем переменную
df_new["heating_type"].fillna("Kombi (Doğalgaz)", inplace = True) # заменяем пропуски на часто встречаемое
df_new["heating_type"] = le.fit_transform(df_new["heating_type"]) # кодируем переменнуюСтолбец 'price' содержит огромное количество выбросов, поэтому мы не сможем взять его для обучения нашей модели, однако удалять его мы не будем. И просто заменим пропуски медианой значения
df_new["price"].fillna(df_new["price"].median(), inplace = True)1.5.6 — Разберём столбец «price_currency»
Посмотрим на уникальные значения ячеек столбца
df_new["price_currency"].value_counts()
Заменим пустые значения самыми популярными значениями и закодируем весь столбец
df_new["price_currency"].fillna("TRY", inplace = True)
df_new["price_currency"] = le.fit_transform(df_new["price_currency"])1.5.7 — В столбце 'type' всего одно уникальное значение, так-что мы можем удалить его из базы данных.
df_new["type"].value_counts() # В столбце всего одно уникальное значение
df_new.drop("type", axis = 1, inplace = True)1.5.8 — Перейдём к столбцу 'sub_type'
df_new["sub_type"].value_counts()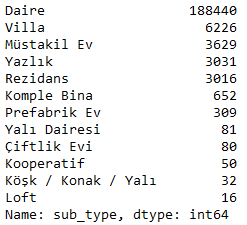
В данном столбце отсутствуют пустые элементы, так — что мы можем просто закодировать его.
df_new["sub_type"] = le.fit_transform(df_new["sub_type"]) # кодируем переменные1.5.9 — Проверим столбец 'listing_type'
df_new["listing_type"].value_counts()
Так как он имеет всего 3 уникальных числовых значения, то мы можем просто оставить этот столбец без изменений.
1.5.10 — В столбце 'tom' так-же есть определённое количество (181) уникальных значений и мы можем оставить и этот столбец без изменений.
df_new["tom"].value_counts()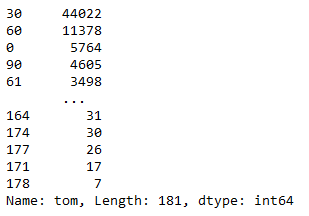
1.5.11 — Признак 'room_count' представляет собой столбец, состоящий из строковых значений. Из этого следует то, что нам нужно их декодировать.
df_new["room_count"] = le.fit_transform(df_new["room_count"])1.5.12 — Столбец id мы можем просто удалить, так как он не поможет нам обучить модель
df_new.drop("id", axis = 1, inplace = True)1.5.13 — Посмотрим на столбец 'address'
df_new["address"].value_counts()
В столбце слишком много уникальных значений, что без сомнений внесёт шум в нашу модель. Удалим этот столбец.
df_new.drop("address", axis = 1, inplace = True)1.6 — Оценим нашу очищенную и улучшенную модель
df_new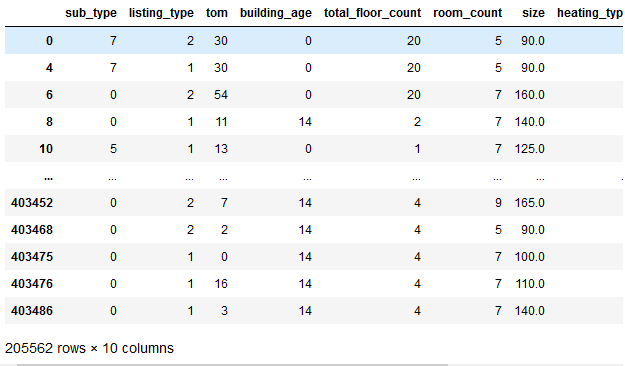
2 — Выполнение примера второй части экзамена
Задания в второй части состоит из нескольких пунктов.
2.1 — Отбора признаков. Нам необходимо определить, какие признаки имеют наибольшее влияние на классификацию объектов по возрасту недвижимости (building_age) и оставить только их для обучения. Могут остаться и все исходные признаки. Необходимо обосновать выбор признаков, оставленных для обучения.
Однако в нашем случае признаки были отобраны уже на предыдущем этапе, но в можете просто еще раз продублировать всю последовательность действий в отчёте. Также можно обучить алгоритм и построить график важности признаков и показать, что все отобранные признаки влияют на конечный результат классификации. К сожалению мы не можем выполнить задание полностью без использования обучающей и тестовой выборки, так что вернёмся к этому пункту после выполнения 2.2.
2.2 — Разбиения данных на обучающую и тестовую выборку. Необходимо определить принцип разделения данных на обучающую и тестовую выборки. Даже если вы выбираете случайное разделение данных, необходимо обосновать выбор данного принципа.
Чтобы разбить разбить данные на обучающую и тестовую выборку нам нужно сначала создать выборку ответов (матрицу ответов)
x = df_new.drop("building_age", axis = 1) #Выборка обучающая
y = df_new["building_age"] #Выборка ответенаяИмпортируем библиотеки для создания нужных нам выборок
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_reportСоздаём обучающую и тестовою выборку
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)2.1 — Продолжение отбора признаков
Инструменты для машинного обучения градиентным бустингом мы возьмём из библиотеки xgboost, но вы можете использовать любую другую, например 'sklearn'.
from xgboost import XGBClassifier, plot_importance, plot_tree
#Импортируем классификаторЕсли при попытки импорта библиотеки появляется ошибка, говорящая об отсутствии такой библиотеки, то нам нужно установить её при помощи pip install.
Создаём экземпляр классификатора, обучающего модель по модели случайного леса
xgb_cls = XGBClassifier(n_estimators = 100, learning_rate = 0.3, n_jobs = -1, random_state = 1)
xgb_cls.fit(x_train, y_train)
#Непосредственно тренеруем модель(метод для способов тренеровки моделей одинаков)
Сохраняем predict (предсказание) в переменную
y_pred = xgb_cls.predict(x_test)Смотрим текстовый отчёт по показателям классификации
print(classification_report(y_test, y_pred))
Так-же мы можем воспользоваться accuracy_score для отображения точности модели, но для начала нам нужно импортировать его из библиотеки metrix
from sklearn.metrics import accuracy_score
print(accuracy_score(y_pred, y_test))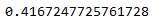
Отберём признаки с помощью алгоритма и нарисуем график важности, чтобы определить силу влияния признаков (столбцов) на классификацию
plot_importance(xgb_cls)
По графику важности признаков можно заметить, что признаки price_currency и listing_type не оказывают большого влияния на классификацию, значит, их можно удалить.
df_n = df_new.drop(["price_currency", "listing_type"], axis = 1)
X = df_n.drop("building_age", axis = 1)
y = df_n["building_age"]Разбиваем новые данные на тестовою и тренировочную выборку
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)2.3 — Классификации объектов. Необходимо выбрать модель классификации недвижимости по возрасту недвижимости (building_age), обосновать выбор модели. Необходимо обучить модель на обучающей выборке и протестировать. Необходимо предоставить показатели точности работы выбранной модели и всех рассматриваемых.
Импортируем необходимые для задачи классификации инструменты
from xgboost import XGBClassifier, plot_importance, plot_treeСоздаём экземпляр класса
xgb_cls = XGBClassifier(n_estimators = 100, learning_rate = 0.3, n_jobs = -1, random_state = 1)Тренируем данные градиентным бустингом
xgb_cls.fit(x_train, y_train)
Сохраняем предсказание в переменную
y_pred = xgb_cls.predict(x_test)Смотрим текстовый отчёт по задачам классификации
print(classification_report(y_test, y_pred))
Отбираем признаки с помощью алгоритма
plot_importance(xgb_cls)
3.1 — Отбор признаков
Необходимо определить, какие признаки имеют наибольшее влияние цены на недвижимость (price) и оставить только их для обучения. Могут остаться и все исходные признаки. Необходимо обосновать выбор признаков, оставленных для обучения.
3.2 Разбиение данных на обучающую и тестирующую выборки
Необходимо определить принцип разделения данных на обучающую и тестирующую выборки. Даже если вы выбираете случайное разделение данных, необходимо обосновать выбор данного принципа.
Нарисуем ящик с усами
sns.boxplot(df_new.price)
Посчитаем квантили и очистим datafram’ы от выбросов по квантилю
quant = df_new["price"].quantile(0.6)# считаем квантиль 90 %
quant_low = df_new["price"].quantile(0.01)# считаем квантиль 10 %
df2 = df_new[df_new["price"] < quant] # убираем выбросы по квантилю
df2 = df2[df2["price"] > quant_low] # убираем выбросы по квантилюНарисуем ещё один ящик с усами
sns.boxplot(df2.price)
Создадим выборку ответов
X = df2.drop("price", axis = 1) #Удаляем столбец с выборкой ответо из основного df
y = df2["price"] #Создаём выборку ответовСоздаём новые обучающие и тестовые выборки
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)3.3 — Прогнозирование
Импортируем из библиотеки xgboost метод градиентной регрессии
from xgboost import XGBRegressorСоздадим модель обучения градиентной регрессии
xgb_regr = XGBRegressor(n_estimators = 1000, learning_rate = 0.1, n_jobs = -1, random_state = 1)Тренируем модель градиентной регрессии
xgb_regr.fit(x_train, y_train)
Сохраняем финальную модель предсказания в переменную
y_pred = xgb_regr.predict(x_test)Вычисляем квадратных корень из оценки незаметного количества
np.sqrt(mean_squared_error(y_test, y_pred))Выводим коэффициент детерминации
r2_score(y_test, y_pred) Это ответ
Это ответ
