Апгрейд базы PostgreSQL через репликацию
Доброго времени суток. Решил поделиться опытом апгрейда через репликацию. Порыскав немного нашел написанного не мало на просторах Хабра, теории и практики, но в моем случае есть небольшое отличие ну и плюс актуальные версии, в общем думаю лишним не будет, а если кому-то даже частично будет полезно то вообще блеск. Итак приступим …
Задача у команды стояла такая — нужно разделить одну базу на 8 отдельных баз по внутреннему индикатору- ID проекта (в процессе работы проект разделился на признаку и все жило в пределах одной базы). Так же у меня была своя задача апгрейда с 13 на 14 версию PostgreSQL. Была просьба от команды сделать это с минимальный простоем и совсем хорошо если за один присест, а не разбивая частями по 2–3 базы за итерацию.
Недолго рассмотрев сложившуюся ситуацию предложил ребятам метод апгрейда через репликацию, для них никаких сложностей лишь один раз перезапустить приложение с изменением имени базы в коннекторе. Это позволит за раз сделать все что необходимо с учетом всех условий. Объяснил что разработчикам нужно наверно даже больше уделить внимание тестированию того что может выстрелить в новой версии самого 14 PosgreSQL — возможно изменение синтаксиса SQL, или свежий баг на лини сопряжения «база — ОС», или особенность драйвера, в общем нужно протестировать работу всего функционала и ухо держать востро, ну, а я сделаю все максимально гладко со своей стороны.
Соответственно на тесте постарался процедуру обкатать и проиграть в различных вариантах и ситуациях. Да и конечно было ограничение — на сервере не было дискового пространства на 8 баз суммарно, разве что на 3 хватило. Короче есть ограничение по месту. Да и сразу скажу, что в моей базе партиций не было, поэтому стоит это учесть и внести изменения в скрипты, если требуется !
Как выглядит кластер БД
Текущая прод система состоит из двух серверов (МАСТЕР + РЕПЛИКА) работающих под управлением PostgreSQL 13. Целевая система состоит из одного сервера — пустой инстанц под управлением PostgreSQL 14.
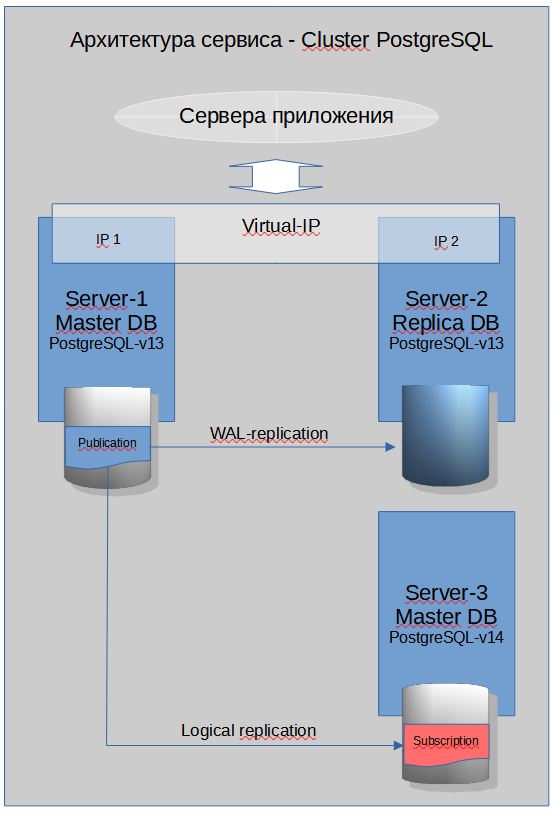 Архитектура кластера PostgreSQL
Архитектура кластера PostgreSQL
Начало работы
Подготовка к работам включала следующие моменты изменить конфигурацию текущего инстанца с учетом дополнительных нагрузок репликации и создания инстанца в 14 версии фактически с аналогичной конфигурацией плюс с поправкой на 8 баз.
Шаги:
Изменить настройки инстанца в 13-ой версии.
Выгрузить схему исходной БД в файл и скопировать его на сервер 14 версии.
Создать публикацию всех необходимых нам таблиц.
Установить признак уникальности для таблиц.
Создать базы в новой 14 версии и создать объекты базы.
Внести требуемые изменения в настройки инстанца 14 версии.
Запустить репликацию в базах 14 версии.
Вычистить и ужать целевые база в процессе репликации.
Процедура ясная и вполне понятная, так что можно приступать. Ну поехали …
На (Master DB)
Конфигурируем инстанц (обращаю внимание что так же по хорошему нужно их изменить на реплике.)
max_wal_size = »32GB» — тут требуется отслеживать представление pg_replication_slots колонку wal_status что должен быть в состоянии reserved, гарантирует вам наличие WAL-логов для накатки на приемник в случае временной остановки или отставания репликации в момент пиков. (Внимание: есть еще параметр max_slot_wal_keep_size — сохранение wal-ов нужных для слотов репликации. Параметр статический). Параметр динамический.
max_level = «logical» — формат сохраняемых данных в логах без которых не возможна логическая репликация. Параметр статический.
max_wal_senders = 14 — максимальное число подключений потоковой репликации (т.е. число процессов передачи WAL). Параметр статический
Создаем дамп базы (без данных, только схему с объектами)
В виду того что репликация буде происходить в таблицы которые уже должны находиться в базе приемнике, которые должны быть симметричны таблицам источника, то самый легкий способ это сделать дамп описания схемы или по табличный, который загрузим затем в базу приемника.
$ pg_dump -d db_name -s -f file_dump
далее по средством настроенных приватных -публичных ключей копирую дамп на новый мастер сервер.
$ scp ./file_dump postgres@10.91.0.212:/var/lib/postgresql/dump/
Создаем публикацию всех необходимых таблиц эталонной базы, для этого сгенерим команду
»create publication pub_ux for table »
добавляем — рекомендую воспользоваться скриптом в том случае если таблиц более чем 3 в psql запросом
ux=# SELECT relname||',' FROM pg_class WHERE relkind in ('r','p') AND relnamespace=2200 ORDER BY relkind;
добавляем — завершаем заменой последнего символа »,» заменить на »;» (так же обращаю внимание что у меня стандартная схема public, стандартна имеющая oid = 2200)
в итоге получаем что-то типа `create publication pub_ux for table table1_name, table2_name, … tableN_name;`
проверяем нашу публикацию

Далее требуется указать базе данных по какому признаку требуется вычислять уникальность строки при репликации таблицы, оптимальным является использование первичного ключа таблицы, если его нет то для надежности можно указать «вся строка является уникальным признаком». Таким образом для тех таблиц которые обладают уникальным признаком указываем его, как вариант есть еще вариант указать UNIQUE-индекс. Опять таки матушка лень которая нам подсказывает, воспользоваться запросом в psql для генерации скрипта
db_name=# SELECT DISTINCT indrelid::regclass, count(indexrelid) idx_cnt FROM pg_index i, pg_class c WHERE c.oid=i.indrelid AND c.relnamespace=2200 AND indisprimary GROUP BY indrelid;
для остальных таблиц cгенерим скрипт с опцией REPLICA IDENTITY FULL
На (NEW Master DB)
Конфигурируем инстанц. Выставляем параметры
max_logical_replication_workers = 14 — из расчета что у меня работает репликация для инстанца реплики и по три сессии будет кушать каждая активная база в момент ее первоначальной заливки и в режиме синхронизации по одной на базу, чтобы не создавать серьезных нагрузок на Master DB льем по одной базе и синхронизируются все уже залитые. В последнем моменте получается одна сессия это Replica DB, 7 сессий это 7 баз и еще 3 сессии это заливка последней 8-ой базы, итого 11 сессий. Параметр статический.
max_sync_workers_per_subscription = 2 — (2 значение по умолчанию) число параллельных процессов, которые выполняют первоначальную заливку данных таблиц, так называемый первичный снапшот. В данный момент один процесс это одна таблица, таблица не может заливаться несколькими процессами одновременно. Параметр статический (2 значение по умолчанию)
wal_level = «replica» — значение должно быть таким или выше иначе репликация работать не будет. Параметр статический
max_replication_slots = 14 – максимальное число слотов репликации, (Внимание: если этот число будет меньше чем текущее количество отслеживаемых источников репликации, то сервер не запустится). Параметр статический
max_wal_senders = 14 — максимальное число подключений потоковой репликации (т.е. число процессов передачи WAL). Параметр статический
Создаем пользователя владельца новой базы
db_name=# create role ux_user with login password ‘my_password’;
Так же не забываем дать права на подключение пользователю в базу в файле pg_hba.conf, ну и за одно всем остальным пользователям приложения.
Создаем новые базы с нужными именами
postgres=# create database ux1 owner ux_user;
Переносим (создаем) всех необходимых пользователей из 13-ой в 14-ую версию.
Заливаем дамп схемы базы в новую базу.
$ cat ./file_dump |psql -d ux1
(Процедуру по созданию базы и заливке дампа как вы понимаете я проделал 8 раз)
Далее может потребоваться внести какие-то изменения в настройках инстанца новой базы, тут поставлю три точки каждому на свой вкус и цвет, не забываем что у меня количество баз выросло и требования к ресурсам сервера по мощности изменились, так что репликация и авто-вакум могут потребовать больше процессов для оптимальной работы, если хорошо подумать то может еще что найдется. Перегружаем инстанц и он готов.
После того как нужные базы созданы необходимо запустить заливку данных — репликацию. Так же тут нужно не забыть дать права на подключение пользователя под каким будет осуществляться подключение из 14-ой в 13-ую версию. У пользователя должны быть расширенные права, возможно это делать легче под суперадмином «postgres».
Подключаемся в первую базу и в ней создаем подписку.
postgres=# \c ux1
ux1=# create subscription sub_ux1 CONNECTION 'dbname=ux host=10.91.0.211 user=postgres password=postgres_password' PUBLICATION pub_ux;
Теперь на сервер 13-ой версии в представлении pg_replication_slots можно увидеть три записи относящихся к созданной нами подписке, в поле slot_name одна запись будет с именем нашей подписки — это основной процесс репликации отвечающий за накатку изменений, два других будут отвечать за по табличную выгрузка первоначальных данных, которые по завершения первичной выгрузки таблиц будут завершены и отключены, происходит по табличное распределение на процессы. В случае не хватки сессий для логической репликации воркеров будет не хватать и может страдать в том числе и накат реплики, так что стоит точно рассчитать необходимое количество процессов для репликации в вашем случае, может и хватить дефолтных настроек, но не в моем.

Момент начала репликации можно запечатлеть в представлении pg_subscription_rel в таком состоянии (первый таблицы начали реплицироваться, остальные ожидают своей очереди поле srsubstate)

Соответственно в параллельной консоли подключения отслеживаем размер заливаемых баз в 14 версии.
ux1=# SEELCT datname, pg_size_pretty(pg_database_size(datname)) FROM pg_database ORDER BY pg_database_size(datname) DESC;
По окончанию заливки первичного снапшота — копирование таблиц одной базы (это можно увидеть по размеру заливаемой базы и пропаданием дополнительных процессов выгрузки таблиц в представлении pg_replication_slots, а так же из представления pg_subscription_rel)
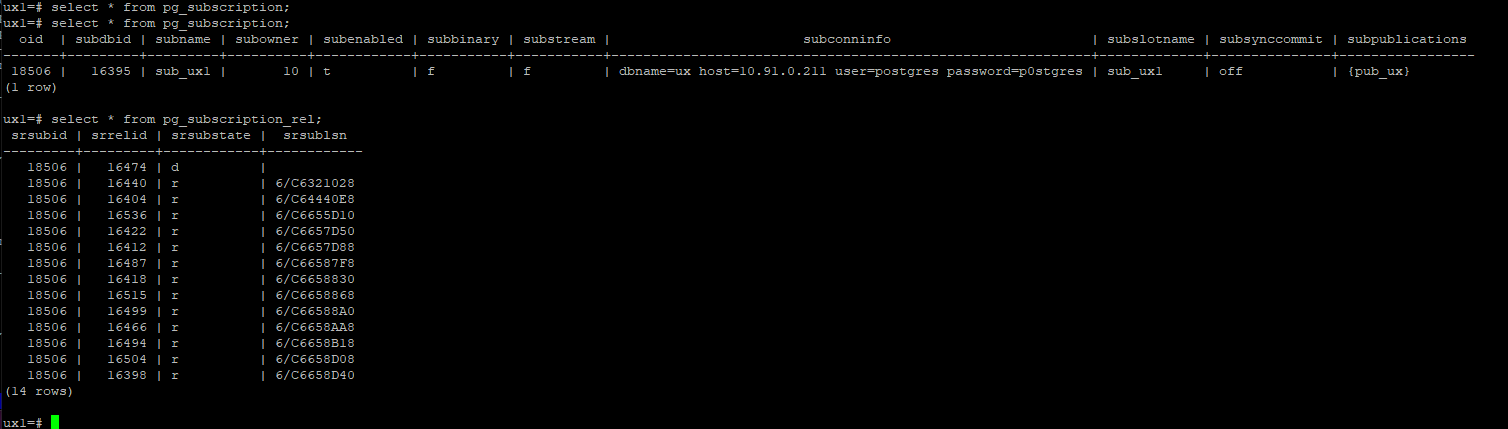 Пример состояния таблиц при завершении копирования первичного снапшота данных
Пример состояния таблиц при завершении копирования первичного снапшота данных
начинаем зачистку данных которые являются лишними для текущего проекта. Команда разработки мне любезно предоставила скрипты, которыми я и воспользовался.
Репликацию на момент зачистки останавливал, ведь мне требовался вакум самой бд (т.к. стояла задача сократить используемое пространство). Так что в 14-ой версии подключаемся к реплицируемой базе и выполняем
ux1=# ALTER SUBSCRIPTION sub_ux1 DISABLE;
Далее запуск скриптов зачистки, проверяем что отработал нормально ну и не удалили чего нужного.
ux1=# VACUUM FULL VERBOSE ANALYZE;
(Тут стоит сделать небольшое отступление и предупреждение, выполняя вакум фул на всю бд я наткнулся на баг в виду которого процедура вылетала на системной табличке с ошибкой, что не является проблемой в том смысле что не убивает базу, но в итоге отчистка продуктивных таблиц не проходит, так что я выполнял по табличный вакум фул, который похожим способом можно сгенерить запросом). (Внимание: нельзя забывать про сбор статистики по всем таблицам, т.к. для базы они все новые, поэтому стоит выполнять по табличный вакум с опцией ANALYZE!)
Теперь мы можем увидеть что размер базы стал меньше и на файловой системе место пустого стало больше.
Нам остается вернуть репликации базы в строй и перейти к следующей в очереди базе.
ux1=# ALTER SUBSCRIPTION sub_ux1 ENABLE;
Проверяем что репликация наша работает.
Как результат имеем следующее. У нас поднята 14-ая версия инстанца, в ней созданы 8 баз, которые составляют общим объемом примерно тот же размер что и исходная 13-ая версия базы, данные по всем проектам к сожаление продолжают попадать во все 8 баз, те же что ложатся в исходную, что приводит нас к мысли, что нам придется возможно еще раз их зачистить удалением и вакумом, ну это я предлагаю уже отнести к необходимому злу, что называется. Все зависит от ясности плана и сроков проведения процедуры, которое на прямую может влиять на оптимальность наших шагов. И так наши базы находятся в отставании примерно в 1 секунду от исходной базы.
Тут конечно я напомню про сетевые доступы и фаерволы и может еще что стоит вам учесть в вашем плане, мне делать ничего не пришлось. Главный вопрос который меня интересовал потянет ли мастер сервер 9 репликаций и свои пики нагрузки. Я сталкивался с тем, что не представлялось возможным реплицировать и одной, правда большой и нагруженной таблицы. Так что советую этому уделить внимание. Сама по себе репликация чревата сопутствующими повышенными нагрузками ввода/вывода в следствии работы своего алгоритма, которые могут очень ощущаться при пиковых нагрузках в базе данных.
Пойдем дальше… вторая часть задачи.
План работы в момент «Ч» уже представляет собой меньшую половину приключений для достижения нашей цели.
Что делаем:
В момент «Ч» останавливаем приложения взаимодействующие с базой.
Останавливаем репликации удаляем подписку.
Корректируем последовательности.
Тушим текущий МАСТЕР под 13 версией.
Переносим VIP-адрес на сервер 14 версии.
Команда разработки выполняет накат приложения и проверяет работоспособность и доступность приложения пользователям.
Пересоздаем тестовый стенд.
Ну поехали
После остановки приложения еще раз убеждаемся что репликация всех баз актуальна и ни кто по дороге не отстал, все потоки репликации показывают одинаковое значение в поле confirmed_flush_lsn представления pg_replication_slots.
ux1=# ALTER SUBSCRIPTION sub_ux1 DISABLE;
nux1=# DROP SUBSCRIPTION sub_ux1
Проверяем что репликационный процесс остановлен на сервере 13-ой версии
ux=# SELECT * from pg_replication_slots;
С дампом в базе создались последовательности, но все они имеют первый стартовый индекс (pg_dump пишет в дамп команды по созданию последовательностей, но не выгружает их статус) и требуется его актуализировать до следующего последовательного номера индекса и в виду того что он за частую служит порядковым номером для записей в таблицы и участвует в формированию первичного или уникального индекса, приложение просто не сможет вставлять новые данные. Сгенерим скрипт
ux1=# SELECT 'SELECT setval ('''||relname||''','||nextval(relname::regclass)||');' FROM pg_class WHERE relkind='S';
Выполняем это в каждой базе!
Будет список команда такого плана SELECT setaval («app_seq»,10543); — на каждую последовательность в вашей базе.
Далее я перенес виртаульный — рабочий адрес на новый мастер сервер и отдаю базу в работы команде разработки.
С этого момента считаем нашу работу выполненной. Конечно ничего не мешает нам тщательно наблюдать лога работы базы.
Пересоздание тестового стенда оставляю на вашей совести и на этом заканчиваю свое повествование. Спасибо.
