СОРМ: от приказа до релиза
Какое-то время назад меня занесло в команду, разрабатывающую СОРМ, поэтому эта статья будет о том, как происходит процесс разработки, и какие новшества и проблемы в них мне встретились по сравнению с классическими приложениями. Сразу хочу отметить, что статья носит ознакомительный обзор по процессам и основным проблемам, но не детализацию технологий, думаю, понятно почему.
Начнем с того, откуда же приходят требования, если заказчика по факту как такового нет, и какие типы СОРМ существуют?
Типы СОРМ и приказы Минцифры
Изначально, все начинается с официально принятого приказа Министерством цифрового развития России о хранении данных. Все документы можно найти на официальном сайте Минкома в открытом доступе.
Каждым приказ можно грубо разделить на несколько частей:
много фраз о том как все это важно и нужно и почему, которые не несут никаких требований
описание работы с клиентом, что важно для той части разработки, которая отвечает за внешний интерфейс коммуникации приложения и пульта управления, с которого приходят команды на выдачу информации и которым пользуются господа в униформе, когда им это требуется. И в отличии от большинства приложений, которые активно дергают REST, у СОРМа свой интерфейс, причем у каждого приказа он свой, как и пульт, с которым он работает
описание работы с системами хранения данных, а именно — какие данные, сколько по времени, в каких форматах и т.д. требуется хранить в случае, если это требуется
приложение к приказу, именуемое «Методика тестирования» — официальный документ, по которому приложение должно проверятся, имеет в себе ряд тест кейсов с ожидаемым результатом.
Однако, несмотря на то, что каждый приказ несет в себе что-то новое, а типы соединений и интерфейсы отличаются, все же можно разделить СОРМ на два вида:
СОРМ, который должен хранить результаты, и в случае надобности можно будет вытащить данные прошлых месяцев или лет.
СОРМ, работающий с данными «on a fly»- выдача результата в реальном времени сразу на пульт без сохранения результата в бд.
В первом случае с клиента, именуемым «пульт управления» или просто «ПУ» приходит определенный запрос — «команда + фильтры + отрезок времени», и СОРМ должен выдать всю информацию за указанный период по данному фильтру в определенном виде. Примером такого подхода может быть приказ 573 о хранении данных абонентов
Во-втором случае приходит сигнал о постановке на контроль абонента, и только после этого начинает отбор информации. Информация выдается на пульт сразу же, и идет она до того момента, пока с пульта не придет сигнал о снятии с контроля, но сами найденные данные на стороне СОРМ (сервера) не сохраняются.
Примерами таких приказов могут быть приказы №645 о контроле связи и №139 о контроле интернет данных.
Также, можно разбить СОРМ по типу съема: активный и пассивный.
Активный — выполняется непосредственно при помощи телекоммуникационного оборудования. Все современные и исторические телефонные станции обладают специальным API, по которому можно передать интересующие идентификаторы абонента (номер телефона, IMSI, IMEI), после чего, при совершении любого события указанным абонентом (звонок, смс, смена местоположения и тд.), телефонная станция сама передает эту информацию через указанный специализированный API.
Пассивный — основан на зеркалированни всего трафика с последующим анализом протокола, с целью извлечения данных по событиям между абонентами. Считается более надежным, поскольку метод не полагается на честность станции и ее ПО.
Любой приказ СОРМ может быть реализован при помощи пассивного съема, метод активного съёма используется в случаях сложности анализа всего трафика и протокола, либо для СОРМ приказа формата «on a fly» №645, №139.
Постановка задач и сбор требований
Как и везде, все начинается с постановок задач для команды разработки, и в дело вступает ProductOwner. Так как процесс создания сторей и так широко известен, остановимся на трех основных проблемах, что встречаются на этом этапе в рамках СОРМ.
Первая проблема — въехать, что написано в приказе
Звучит, возможно, на первый взгляд, странно или смешно — как официальный документ РФ может не быть продуманным. Но по факту, приказ — это особый вид документации, который ломает глаза с первых строк прочтения. Основная его проблема, если не считать орфографических шибок (да, они есть) — очень вычурные и длинные предложения, как и в большинстве государственных и юридических документах, которые наполовину несут одно и тоже разными словами, наполовину описывают все настолько абстрактно, что Продакту приходится задействовать не только логику, упорство и выдержку, но и магический шар и карты таро, чтобы понять, что имел ввиду автор, и что он видел на самом деле.
Почему же нельзя опустить описания и сразу перейти к интерфейсу, который как раз структурирован? Можно, и обычно так и делают, пока Оунер продолжает копаться с сочинениями в первой части. Проблема в том, что требования типа «должно храниться в течении трех месяцев с момента старта» или «должны выдаваться порциями по суткам в размере 1 ГБ» и т.д. находятся как раз в первой части. И именно по этой причине такие требования легко пропустить, подобные требования описаны мельком и не акцентированы, а проверять
Вторая проблема — взаимоисключающие требования или расплывчатые требования.
Требования написаны иногда настолько криво, что их можно трактовать даже не двумя, а тремя и более способами. Либо не написаны вообще, но сделать как удобно нельзя, ведь потом, если кому-то на проверке не понравится, придется все переделывать. Ситуация, на первый взгляд, стандартная, за исключением того, что нельзя позвонить заказчику и спросить. Единственный вариант — стучаться в органы через несколько промежуточных лиц и просить разъяснений у людей в погонах, а это долго, нудно, порой стремно и не всегда помогает.
Пример про исключающие требования: «приказ 573, который должен иметь возможность выдавать всю информацию по абоненту.»
Что это значит? Ключевое слово «всю». То есть, если есть только СОРМ 573, то это данные платежей. А если, например, у оператора еще стоит 86ой (а он должен быть), то это еще данные звонков, а если 139ый, то и трафик.
И фраза «Приказ 573 должен выдать все данные по абоненту» превращается в .«Приказ 573 должен выдать все данные по платежам абонентов, всем типам звонков и интернет трафику». А, если посмотреть информацию этажом выше о типах СОРМ, то можно вспомнить, что, к примеру, трафик не хранится. И объемы данных к хранению никак не приспособлены. Но при этом 573 должен выдавать данные на месяца назад и по данным трафика в том числе.
Здесь начинаются пляски Оунера с архитекторами, каким образом хранить те данные, которые хранить не надо и под которые ничего не приспособлено, и при этом не сжечь дата-центр и разработчиков. Это приводит к проблеме №3:
Хранение данных — и здесь, возможно, посыпятся комментарии про big data и «все хранят, и вы храните». Но нужно понимать, о каких данных идет речь. Данные платежей и пользователей — не так уж много , даже для большого оператора, даже за год, и в целом проблем нет. Проблема возникла, когда Минком посчитал, что 573 должен включить выдачу по остальным приказам, которые хранение не предусмотрели. Точнее, там есть что-то в духе «должно храниться все за период», и на этом все. Тип интерфейса выдачи 573 вообще ни разу не приспособлен к выдаче информации по звонкам и трафику. Поэтому, к примеру, если выдается информация по трафику, где данные — это не только заголовки заголовки, а абсолютно весь трафик, всех пользователей за период, то это все в режиме реального времени должно парситься, конвертироваться под 573 интерфейс и при этом ничего не вешать и куда-то складываться.
Посчитаем на небольшом операторе:
Как правило, небольшой интернет провайдер закупает пропускной канал у какого-то крупного межрегионального оператора для предоставления доступа в сеть своим абонентам, поэтому для расчета мы просто возьмем величину этого канала. Пусть наш провайдер арендует канал шириной 20Gb\s, понятно что нагрузка днем и ночью разная, усредним ее до 15Gb\s. Тогда, за один день наш небольшой оператор прокачивает: 156060×24/8 = 162 TB
А данные трафика необходимо хранить месяц: 162×30 = 4.8 PB
Если использовать диски по 14TB, в режиме RAID5 (5+1), получим 417 дисков.
Часть требований указана только в методике тестирования. То есть. как в приказе могут быть требования, а в методике не будут описаны сценарии их воспроизведения, так и в методике могут быть требования где-то мельком между кейсами, но при этом в самом приказе их не будет, и не всегда все сопоставляется между собой.
Разработка
Сам СОРМ можно разделить на 3 компонента:
работа с пультом управления
конвертация, парсинг и запись в БД
анализ трафика
Работа с пультом управления
За этот пункт отвечает интерфейс, описанный в приказе. Описано все очень четко, что какой байт должен нести. Это относится как к командам с пульта, так и к выдаче информации. Такое жесткое описание это и плюс и минус.
Плюс:
никаких изменений в интерфейсе — ты получаешь приказ с описанием и больше никаких правок от юзеров и вот это вот все.
Минус:
никаких изменений в интерфейсе — ты не можешь ничего менять, даже если написано через ж. Несмотря на то, что это официальный приказ, в нем реально есть ошибки и части, которые очень хочется оптимизировать, но нельзя. В основном ошибок в интерфейсе 3:
типы данных: например, на пульт ожидается Int, но по факту сами данные это String, и оператор туда вписывает вместе с номером телефона еще кучу всего.
логические косяки: например, ожидается 12 символов, но по факту в БД их 16, потому что номер карты банка всегда 16 символов. Или, например, поле фамилии только из букв, но при этом все мы знаем, что есть фамилии через дефис или с апострофом.
орфографические: например, везде поле называется «name», а в одном месте «Name», при этом это одно и тоже поле, создаваемое из одной таблицы в одну и туже структуру.
Во всех случаях приходится пилить костыли, порой они довольно болезненные.
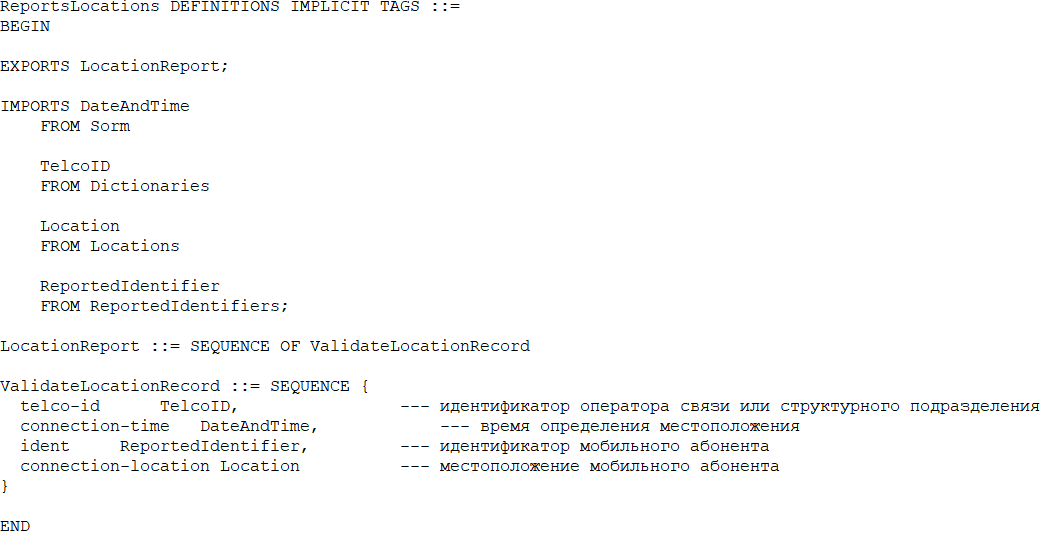
Примеры интерфейса asn для приказа 573:


Пример байтового интерфейса для приказа 86
Конвертация, парсинг и запись в БД
Помимо уже озвученных вопросов хранения, разработка также много тратит на решение проблемы состыковать данные оператора, что уже у них есть, с новой БД, заточенной под СОРМ.
На этапе стыковки с БД оператора, оператор присылает Excel документ с примерами данных, которые у них хранятся, заменяя реальную инфу на что-то еще похожее. Данные у каждого оператора выглядят по-разному. Совсем. То есть для каждого оператора своя синхронизация.
Для каждого оператора нужно написать тулу, что распарсит их данные и закинет в нужном виде в новую БД. Данные хранятся настолько криво, что даже, если ты гуру регулярок, ты не сможешь все распарсить за раз. И даже за 5 раз. И это несмотря на то, что оператору отправляется детализировано описанный интерфейс, как должны выглядеть поставляемые данные. Здесь может показаться, что я жалуюсь, но в свое время мой переход с Мегафона на Билайн проходил 3 месяца с 12ю заявками, потому что у них каждый раз что-то не стыковалось в данных, а их не то, чтобы было много. Теперь хотя бы стало ясно, почему.
Ко всему прочему, это просто очень долго. Одно согласование на изменение формата с оператором может идти 2+ недель, даже если это их косяк, а если косяк со стороны команды, то и месяц.
Анализ трафика
Основной компонент СОРМа, работающего в реальном времени — компонент, собирающий информацию с трафика или звонков. Данные собираются с вышек и имеют 2 вида — сам трафик и логи станции. С трафиком обычно все понятно, а с логами не очень.
Логи используются для детализации звуковых дорожек и насыщением их данными по абонентам, времени и т.д. Основные проблемы логов — логи всех станций различны, но это не так страшно, как то, что они часто не несут нужной информации вообще. Например, требуется выделить звонок и указать его начало и конец, а также абонентов. Есть лог и есть общие пакеты, среди которых где-то этот звонок. Чтобы вытащить звонок, нужно определить отрезок времени, но:
даты начала может не быть
даты конца может не быть
может не быть ничего, и продолжительность просто висит в воздухе
может даже продолжительности не быть
почти никогда нет опознавательных айдишников, названий, даты, номеров, бывает, что нет ничего от слова совсем, к чему можно зацепиться программно в принципе, и вычислительные формулы в коде напоминают учебники по квантовой физике. При этом, если нет данных по абонентам, по факту такая запись бесполезна и считается невалидной. Но она была, и потом на проверке это засчитают как серьезную багу.
данные иногда настолько дико выглядят по формату, что никто не понимает, что в них и как их читать, включая специалистов со станции, а документации часто не существует, или она не актуальна.
Тестирование
Отдельный вид боли — это тестирование СОРМ, и в отличии от разработки, здесь действительно не совсем обычный подход, особенно по части трафика.
Тест кейсы
За основу берется методика тестирования, что идет вместе с приказом, но есть очень много «но», и в первую очередь — методика кривая (как неожиданно).
Тест кейсы имеют в себе реальные ошибки, как в ожидаемом результате, так и в тестовых данных, и такого достаточно много. Поэтому, этот документ можно использовать как начальный, для понимания схемы взаимодействия компонент и последовательности действий, но в какой-то момент он начинает скорее путать, чем помогать.
Пример кейсов из методики:
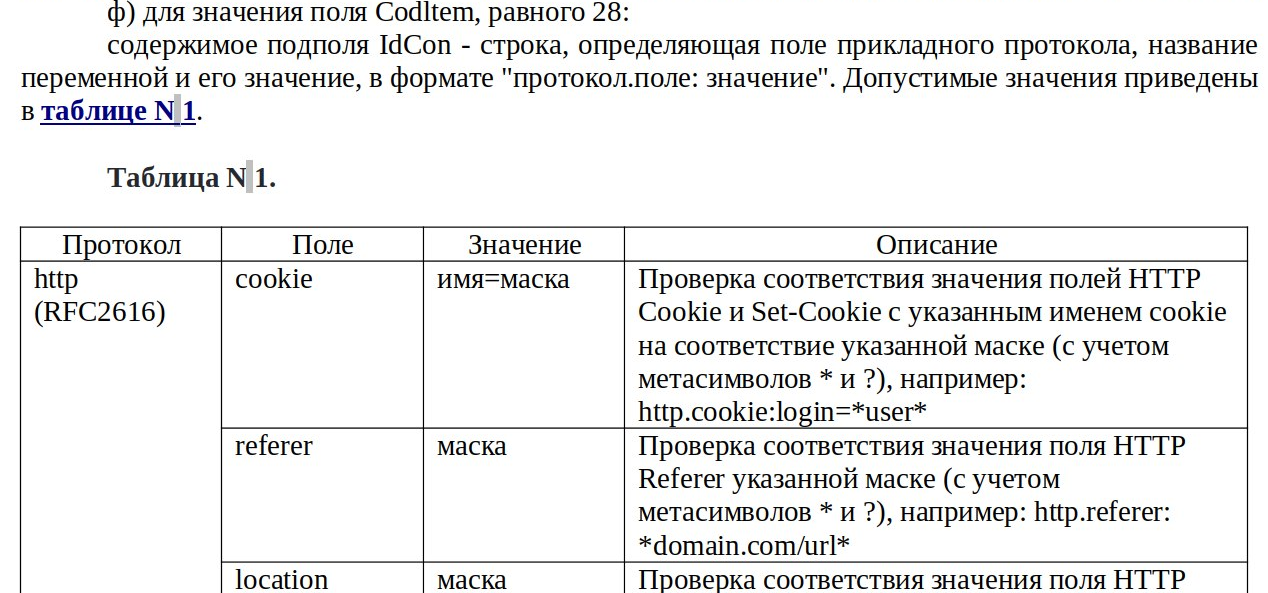
Часть методики приказа 139
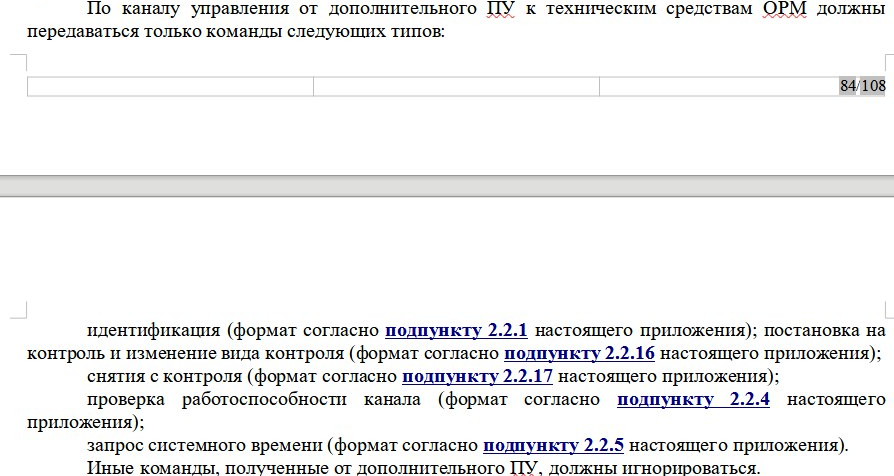
Часть методики приказа 139
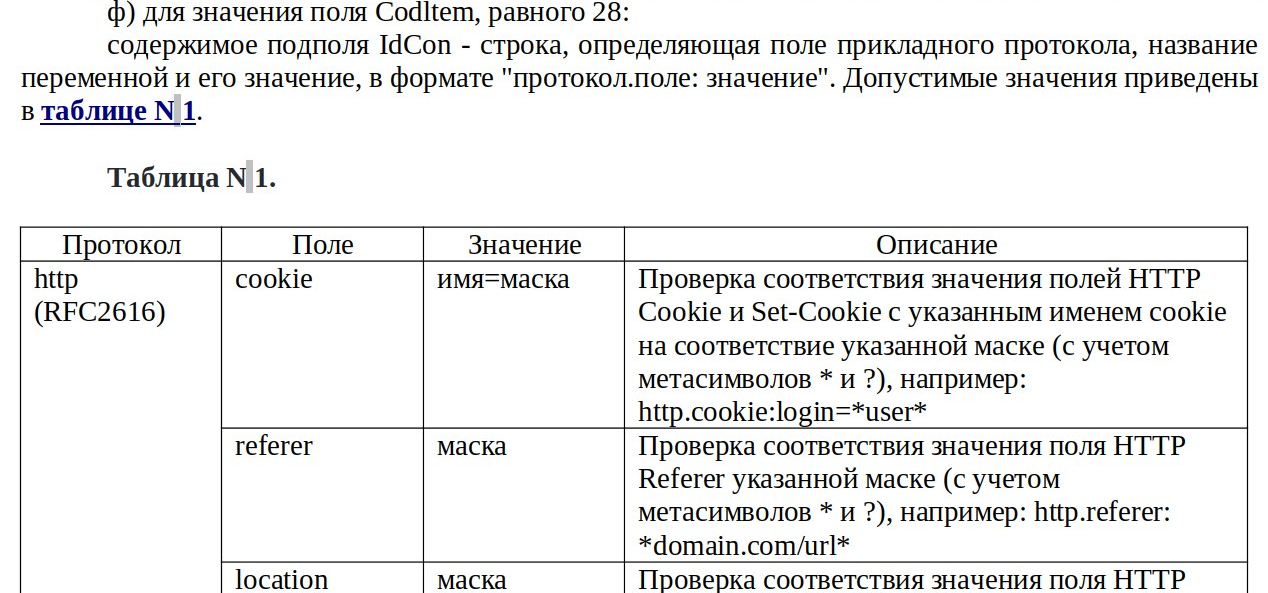
Часть методики приказа 139
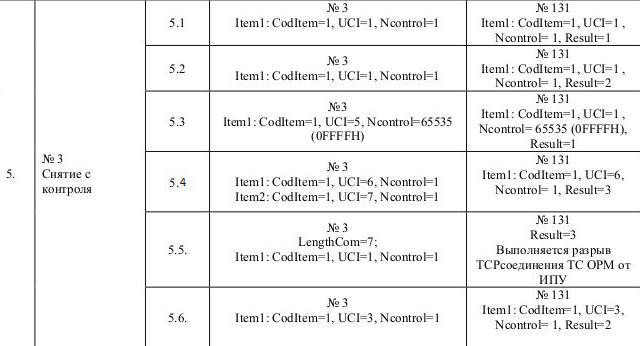
Часть методики приказа573:
Количество кейсов
Очень много кейсов, при этом действительно нужно пройти все. Также, нельзя показать прототип в конце пары спринтов, разработка идет от и до, по старинке, и часто нагрузка падает в конец на время перед сдачей по всем канонам.
Приказы очень большие, очень много нюансов в запросах с пульта, данные сильно пересекаются между собой, имеют противоположные требования или разные граничные значения, типы и т.д, особенно это видно при мердже двух приказов между собой.
По каждому фильтру своя структура выдачи, хотя таблица может быть та же. То есть нельзя раскидать по граничным значениям в одном фильтре и считать, что то же поле в другом фильтре сработает по ним верно, даже если таблица та же и поля те же.
Разумеется, никто не отменяет эквивалентности, автотесты и прочее, но остается много однообразных кейсов, которые при этом нельзя разбить адекватно на группы или сократить из-за особенностей интерфейса. Плюс, как сказано выше, все очень сильно усложняется кривостью данных с оператора и станций и даже, если все отработало хорошо, негативные кейсы прошли, все равно остаются случаи, когда это все накладывается друг на друга в таком диком сочетании, что даже извращенный мозг тестировщика не смог такое предположить на тестовых данных.
Доступ к ПУ
Если коротко — доступа к пульту нет и никогда не будет.
Пульт управления — это собственность правоохранительных органов, и доступа к нему нет. А значит, проверить интеграцию на реальном оборудовании нельзя. Тестировщики пользуются симуляторами, либо написанными все той же командой разработки, либо сторонней компанией. А любой симулятор — это ПО, а ПО имеет баги. Причем есть симуляторы пульта, которые также сертифицированы органами, то есть они официально подтверждены для тестирования. И даже они имеют баги, которые могут сильно путать. В связи с этим никогда нельзя провести интеграционные тесты и сказать, что приложение 100% работает с реальным пультом. Ко всему прочему, пульты также есть разные, и хоть они работают по четко описанному интерфейсу, все равно вылезают проблемы, которые можно оддебажить только на сертификации.
В качестве примера симулятора можно назвать «Импульс 374»

Импульс 374
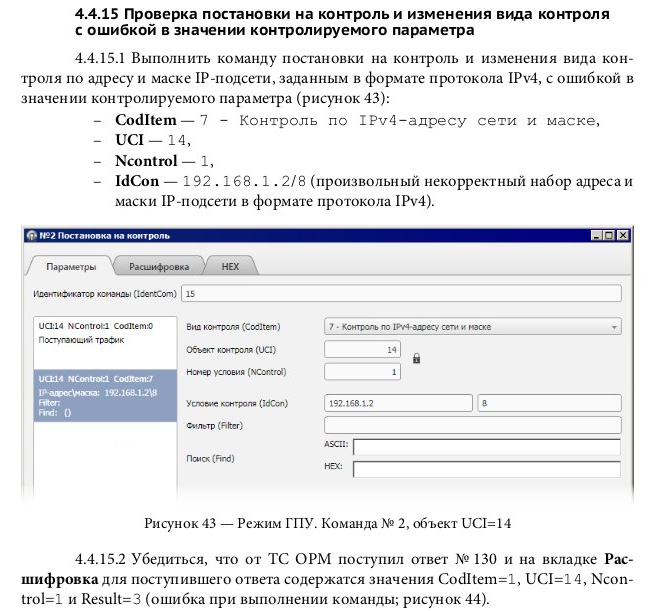
Пример описания постановки на контроль из приказа 139
Воспроизведение сценариев
Не все сценарии можно воспроизвести.
Для выдачи на пульт тестовые данные заносятся в БД, что просто и легко нагенерить, а для анализа трафика нужно пустить реальный трафик, чтобы приложение его считывало и парсило.
А потому есть 3 пути:
Нагенерить дампы трафика руками искусственно.
Нагенерить дампы трафика в офисе вживую.
Нагнуть оператора, чтобы он сгенерил дампы и прислал.
В первом случае искусственно создаются пакеты или слепляются уже имеющиеся дампы, чтобы получить нужный объем. Например, есть дампы по 10 секунд звонков, они складываются несколько раз — получаем нужную минуту и проигрываем новый дамп каким-нибудь tcpreplay. Проблема — данные одни и те же, структура таких гибридов не соответствует проду. Однако, этого более чем достаточно, чтобы провести типовые проверки по заполнению полей в БД.
Во втором случае можно приехать в офис, где тех.поддержка организовала тестовую площадку и подключения, но опять же — телефоны одни и те же, данные одни и те же.
Классический сценарий в таком случае: тестировщик едет в офис, где стоят две трубки. Он подключает приложение к нужным виртуальным интерфейсам, через которые пойдет трафик и вживую звонит по телефону, по WhatsUp и т.д и после проверяет, что все, что он наговорил записалось в БД.
В части проверок анализа трафика в целом не так много сценариев и их все можно воспроизвести, но разнообразие тестовых данных, доступных для тестировщика порой не очень.
В третьем случае можно договориться с оператором, который по написанным ему сценариям сделает вызовы на своей тестовой зоне. Здесь уже данные выглядят интересней и полезней, но нагрузку прода и реальный трафик все равно не всегда отображает, тут зависит от грамотности оператора — как он создал зону и сколько тестовых абонентов нагенерил. Ну и понятно, что это все весьма долго.
Но самой основной и болезненной проблемой является невозможность часть сценариев сгенерить в принципе нигде или почти негде, хоть таких случаев и не так много. И вот 2 примера для понимания.
Транкинговая связь в метро. Для такого сценария у тестировщика должны быть 2 рации, работающие через нужный тип вышки и станция метро. Сгенерить программно это можно, но достаточно сложно и немного бесполезно. В итоге, либо ты не проверяешь сценарий вообще, либо ищешь где-то нужные рации с конкретной, нужной станцией, просишь одолжить и едешь в метро.
Перехват трафика ICQ. Приказ 139 требует перехват всех типов мессенджеров, как новых версий так и старых. Можно поставить себе ICQ, но коннект будет через https, как и во всех мессенджерах сейчас. А по приказу надо уметь анализировать и старые до определенного года через http и снимать с них информацию. Скачать старый варианты физически почти негде, а даже, если повезет найти, начинаются проблемы с установкой, OS и т.д. Так что, в большинстве таких случаев, ты просто надеешься, что оно работает, а работает ли узнаешь только во время приема работ на сертификации, потому что у проверяющих есть такие дампы. Но дать они их разработке, понятное дело, не могут.
Проверки и сертификация
Когда приложение готово, его нельзя сразу продать оператору, сначала нужно пройти ряд проверок и получить гос.сертификат. Пожалуй, из всего процесса для меня это было самое непривычное после других компаний.
Сертификацию проводят сертифицированные испытательные лаборатории, можно почитать подробнее, например, на оф.сайте лаборатории СОТСБИ или лаборатории ЦНИИС
В определенный день приезжает комиссия с реальными клиентскими пультами. Их на протяжении всей проверки сопровождает Продакт, иногда дополнительно в комнате может быть кто-то из разработки или архитектор. Проверки занимают 2–3 дня, и в эти дни команды по возможности сидят в офисе, чтобы оперативно реагировать на найденные баги и фиксить их по мере поступления. В целом, помимо багов по кейсам и каких-то косяков с данными БД, можно дополнительно получить ошибки из-за проблем, описанных выше:
подключение к пультам. К пульту, который принесли на сертификацию, доступ только во время сертификации во время настройки, так что, если попался не очень качественный симулятор, то допиливать придется прямо в 1ый день проверок в соседнем кабинете, коннект к симулятору не является гарантией успеха.
кейсы, что не смогли воспроизвести. Те случаи, когда у проверки есть нужные данные, а у тестировщиков нет и не свезло на них напороться на проверке.
живой трафик. Проверка происходит на реальном операторе, на живом трафике в часы пик, и часто реальная ситуация далека от сгенеренных тестовых данных. Осложняется все это тем, что если во время проверки найден баг, то даже записанный в момент проверки трафик не особо поможет с воспроизведением, ряд багов просто не воспроизводится на дампах. И даже, если бы был доступ вечером для исправления, это тоже не поможет, потому что нагрузка уже не та. В итоге, разработка по факту исправляет вслепую, надеясь, что прокатит. Радует, что, опять же, таких ситуаций все же не шибко много.
неожиданные требования. Иногда бывает, что нужно допилить какое-то поведение, которого по факту нет в приказе. То есть требование пользователей во время бета-тестирования, если это можно так назвать. Хотя, надо отметить, что такие случаи редки, и сами допилы все же адекватные и не сильно большие, например, добавить доп. инфу в какое-то поле.
Комиссия ведет достаточно объемный протокол проверок и найденных ошибок, которые должны быть исправлены к следующему дню до нового прихода, а исправляются они после того, как комиссия уходит по домам или пока сидит в соседнем кабинете. Проверки обычно начинаются с методики, но проверяющие могут делать какие угодно проверки на каких угодно данных. В конечном итоге, комиссия может отказать в приемке продукта, если посчитает, что багов много или они серьезные (например, какой-то протокол не считывается) или принять с оговорками на ограничение тестовой зоны. Подписываются нужные бамаги и выдается сертификат, информация заносится в реестр. И только после этого можно выходить на рынок и ставить на оператора.
