Книга «SQL Server. Наладка и оптимизация для профессионалов»
 Привет, Хаброжители!
Привет, Хаброжители!
Исчерпывающий обзор лучших практик по устранению неисправностей и оптимизации производительности Microsoft SQL Server. Специалисты по базам данных, в том числе разработчики и администраторы, научатся выявлять проблемы с производительностью, системно устранять неполадки и расставлять приоритеты при тонкой настройке, чтобы достичь максимальной эффективности.
Автор книги Дмитрий Короткевич — Microsoft Data Platform MVP и Microsoft Certified Master (MCM) — расскажет о взаимозависимостях между компонентами баз данных SQL Server. Вы узнаете, как быстро провести диагностику системы и найти причину любой проблемы. Методы, описанные в книге, совместимы со всеми версиями SQL Server и подходят как для локальных, так и для облачных конфигураций SQL Server.
Владеть широким спектром технологий особенно важно в культуре DevOps, где команды разрабатывают и поддерживают решения сами для себя. Для разработчиков становится обычным делом устранять проблемы с производительностью, которые могут быть связаны с инфраструктурой или неэффективным кодом базы данных.
В общем, в какой бы роли вы ни работали с SQL Server, эта книга для вас. Я надеюсь, что вы найдете для себя полезную информацию независимо от того, как называется ваша должность.
Еще раз спасибо за ваше доверие, и я надеюсь, что вы прочтете эту книгу с таким же удовольствием, с каким я ее писал!
Глава 1 «Установка и настройка SQL Server» содержит принципы и лучшие методики того, как выбирать оборудование и настраивать экземпляры SQL Server.
Глава 2 «Модель выполнения SQL Server и статистика ожидания» описывает SQLOS — очень важный компонент SQL Server. Здесь же вы познакомитесь с таким распространенным методом устранения неполадок, как статистика ожидания. На эту главу опирается весь остальной материал книги.
Глава 3 «Производительность дисковой подсистемы» дает представление о том, как SQL Server взаимодействует с подсистемой ввода/вывода и как анализировать и оптимизировать ее производительность.
Глава 4 «Неэффективные запросы» демонстрирует несколько методов того, как выявлять неэффективные запросы и выбирать целевые объекты для оптимизации запросов.
Глава 5 «Хранение данных и настройка запросов» объясняет, как SQL Server работает с данными в базе данных, и дает рекомендации по настройке запросов.
Глава 6 «Загрузка процессора» рассматривает распространенные причины высокой загрузки ЦП и учит бороться с узкими местами на уровне процессора.
Глава 7 «Проблемы с оперативной памятью» посвящена настройкам SQL Server, относящимся к памяти, и описывает, как анализировать использование памяти и решать связанные с ней проблемы.
Глава 8 «Блокировки и конкурентный доступ» рассказывает о модели конкурентного доступа, используемой в SQL Server, и о том, как обращаться с блокировками в системе.
Глава 9 «Работа с базой данных tempdb и ее производительность» описывает использование системной базы данных tempdb и лучшие методики ее конфигурации. Кроме того, здесь содержатся рекомендации о том, как оптимально использовать временные объекты и устранять распространенные узкие места в tempdb.
Глава 10 «Кратковременные блокировки» посвящена кратковременным блокировкам в SQL Server. Рассматриваются случаи, когда они вызывают проблемы, и способы решения этих проблем.
Глава 11 «Журнал транзакций» рассказывает о том, как устроен журнал транзакций в SQL Server и как избавиться от распространенных узких мест и ошибок в нем.
Глава 12 «Группы доступности AlwaysOn» рассматривает самую популярную технологию высокой доступности SQL Server и частые проблемы, с которыми можно столкнуться при ее использовании.
Глава 13 «Другие примечательные типы ожиданий» описывает несколько распространенных типов ожиданий, которые не рассматривались в прочих главах.
Глава 14 «Анализ схемы базы данных и индексов» дает ряд советов о том, как обнаруживать неэффективные участки структуры базы данных, а также оценивать использование индексов и их работоспособность.
Глава 15 «SQL Server в виртуализированных средах» рассказывает о передовых методах настройки виртуальных экземпляров SQL Server и устранении сопутствующих неполадок.
Глава 16 «SQL Server в облаке» описывает, как настраивать и использовать SQL Server в облачных виртуальных машинах. В ней также представлен обзор управляемых служб SQL Server, доступных в Microsoft Azure, Amazon Web Services (AWS) и Google Cloud Platform (GCP).
В конце каждой главы приведен контрольный список наиболее важных шагов по устранению неполадок, связанных с темой главы.
Наконец, приложение «Типы ожиданий» можно использовать как справочник по распространенным типам ожиданий и методам устранения основных неполадок для каждого типа.
Неэффективные запросы
Неэффективные запросы существуют в любой системе. Их воздействие на производительность проявляется по-разному: в первую очередь это увеличение нагрузки ввода/вывода, использования ЦП и блокировок. Такие запросы важно обнаружить и оптимизировать.
В этой главе обсуждается, как неэффективные запросы влияют на систему, а также даны рекомендации, как их обнаружить. В первую очередь рассмотрим, как для этого использовать статистику выполнения на основе кэша планов. Затем мы изучим расширенные события (Extended Events), трассировку SQL (SQL Traces) и хранилище запросов (Query Store), а закончим главу замечаниями о сторонних инструментах мониторинга. В следующих главах мы разберем стратегии оптимизации неэффективных запросов.
Чем плохи неэффективные запросы
За время своей карьеры в области баз данных я еще не видел системы, где оптимизация запросов не пошла бы на пользу. Я уверен, что такие совершенные примеры существуют, но меня не зовут анализировать системы, где все в порядке. В любом случае, идеальных систем очень мало, а во всех остальных есть что улучшать и оптимизировать.
Не каждую компанию вообще заботит оптимизация запросов. Это трудоемкий и утомительный процесс. Чтобы быстрее разработать и вывести продукт на рынок, во многих случаях проще добавить аппаратных мощностей, чем тратить долгие часы, копаясь в запросах.
Но с определенного момента такой подход приводит к проблемам с масштабируемостью. Плохо оптимизированные запросы влияют на систему со многих сторон, но самый очевидный пример — это производительность диска. Если подсистема ввода/вывода не справляется с нагрузкой объемных операций просмотра, то ухудшается производительность всей системы.
До некоторой степени эту проблему можно замаскировать, добавив на сервер больше памяти. Это увеличит размер буферного пула и позволит SQL Server кэшировать больше данных, сокращая физический ввод/вывод. Но по мере того, как объем данных в системе растет, такой подход может стать непрактичным или даже невозможным, особенно в отличных от Enterprise выпусках SQL Server, где максимальный размер буферного пула ограничен.
Еще один эффект заключается в том, что неоптимизированные запросы сильно нагружают ЦП на серверах. Чем больше данных обрабатывается, тем больше ресурсов ЦП потребляется. На одну операцию логического чтения страницы данных или ее просмотра в памяти у сервера может уходить всего несколько микросекунд, но суммарные затраты времени на все операции быстро растут, когда количество операций увеличивается.
Опять же, можно замаскировать проблему, добавив на сервер больше процессоров. (Хотя при этом придется платить за дополнительные лицензии, причем в версиях, отличных от Enterprise, максимальное количество ЦП ограничено.) Более того, дополнительные ЦП не всегда помогают, потому что неоптимизированные запросы все равно будут вызывать блокировку. Существуют способы уменьшить блокировку без тонкой настройки запросов, но такие меры могут повлиять на работу системы в целом и ее производительность.
Суть такова: когда вы устраняете неполадки, всегда анализируйте систему на предмет неоптимизированных запросов. После этого оцените, насколько сильно такие запросы влияют на систему.
Хотя оптимизация запросов всегда идет на пользу, это сложное занятие и усилия не обязательно окупаются. Но в большинстве случаев имеет смысл привести в порядок хотя бы некоторые запросы.
К примеру, я перерабатываю запросы, когда вижу большую загруженность диска, блокировки или высокую нагрузку ЦП. Но если данные кэшируются в буферном пуле, а нагрузка ЦП приемлема, то я предпочитаю сперва сосредоточиться на других очагах проблем. Тем не менее я не теряю бдительности и учитываю, что может произойти по мере роста объема данных. Не исключено, что в один прекрасный момент активные данные перестанут помещаться в буферный пул, что приведет к внезапному и серьезному падению производительности.
К счастью, оптимизация запросов не требует подхода «все или ничего». Производительность можно значительно повысить, если оптимизировать всего несколько часто выполняемых запросов. Рассмотрим ряд способов, как их обнаружить.
Статистика выполнения на основе кэша планов
Как правило, SQL Server кэширует и повторно использует планы выполнения запросов. Для каждого кэшированного плана доступна статистика выполнения, в том числе количество запусков запроса, совокупное время ЦП и нагрузка ввода/вывода. Эти данные можно использовать, чтобы быстро выявить самые ресурсоемкие запросы, требующие оптимизации. (О кэшировании мы подробнее поговорим в главе 6.)
Анализировать статистику выполнения на основе кэша планов — не самый исчерпывающий метод обнаружения неоптимизированных запросов, и у него немало ограничений. Тем не менее он очень прост в использовании, и им часто удается обойтись. Этот метод работает во всех версиях SQL Server и всегда доступен в системе. Для него не надо настраивать дополнительный мониторинг и специально собирать данные.
Получить статистику выполнения можно с помощью представления sys.dm_exec_query_stats1, как показано в листинге 4.1. Этот запрос немного упрощен, зато он демонстрирует, как работает представление, и позволяет изучить несколько метрик из него. Далее в этой главе я приведу более сложную версию кода, основанную на этом запросе. В зависимости от версии SQL Server и установленных обновлений у вас могут не поддерживаться некоторые столбцы, которые я использую здесь и далее. Если так, то удалите их.
Этот код предоставляет планы выполнения запросов. Есть две функции, которые позволяют их получить:
sys.dm_exec_query_plan
Эта функция возвращает план выполнения всего пакета выполнения в формате XML. Из-за внутренних ограничений функции размер результирующего XML не может превышать 2 Мбайт, а для сложных планов функция может возвращать NULL.
sys.dm_exec_text_query_plan
Эта функция, которая используется в листинге 4.1, возвращает текстовое представление плана выполнения. Его можно получить для всего пакета или для определенной инструкции из пакета, передав смещение инструкции в качестве параметра функции.
В листинге 4.1 планы преобразуются в XML-представление с помощью функции TRY_CONVERT, которая возвращает NULL, если размер XML превышает 2 Мбайт. TRY_CONVERT можно удалить, если вы работаете с большими планами или запускаете код в SQL Server версий с 2005 по 2008R2.
Листинг 4.1. Использование представления sys.dm_exec_query_stats
;WITH Queries
AS
(
SELECT TOP 50
qs.creation_time AS [Cached Time]
,qs.last_execution_time AS [Last Exec Time]
,qs.execution_count AS [Exec Cnt]
,CONVERT(DECIMAL(10,5),
IIF
(
DATEDIFF(SECOND,qs.creation_time, qs.last_execution_time) = 0
,NULL
,1.0 * qs.execution_count /
DATEDIFF(SECOND,qs.creation_time, qs.last_execution_time)
)
) AS [Exec Per Second]
,(qs.total_logical_reads + qs.total_logical_writes) /
qs.execution_count AS [Avg IO]
,(qs.total_worker_time / qs.execution_count / 1000)
AS [Avg CPU(ms)]
,qs.total_logical_reads AS [Total Reads]
,qs.last_logical_reads AS [Last Reads]
,qs.total_logical_writes AS [Total Writes]
,qs.last_logical_writes AS [Last Writes]
,qs.total_worker_time / 1000 AS [Total Worker Time]
,qs.last_worker_time / 1000 AS [Last Worker Time]
,qs.total_elapsed_time / 1000 AS [Total Elapsed Time]
,qs.last_elapsed_time / 1000 AS [Last Elapsed Time]
,qs.total_rows AS [Total Rows]
,qs.last_rows AS [Last Rows]
,qs.total_rows / qs.execution_count AS [Avg Rows]
,qs.total_physical_reads AS [Total Physical Reads]
,qs.last_physical_reads AS [Last Physical Reads]
,qs.total_physical_reads / qs.execution_count
AS [Avg Physical Reads]
,qs.total_grant_kb AS [Total Grant KB]
,qs.last_grant_kb AS [Last Grant KB]
,(qs.total_grant_kb / qs.execution_count)
AS [Avg Grant KB]
,qs.total_used_grant_kb AS [Total Used Grant KB]
,qs.last_used_grant_kb AS [Last Used Grant KB]
,(qs.total_used_grant_kb / qs.execution_count)
AS [Avg Used Grant KB]
,qs.total_ideal_grant_kb AS [Total Ideal Grant KB]
,qs.last_ideal_grant_kb AS [Last Ideal Grant KB]
,(qs.total_ideal_grant_kb / qs.execution_count)
AS [Avg Ideal Grant KB]
,qs.total_columnstore_segment_reads
AS [Total CSI Segments Read]
,qs.last_columnstore_segment_reads
AS [Last CSI Segments Read]
,(qs.total_columnstore_segment_reads / qs.execution_count)
AS [AVG CSI Segments Read]
,qs.max_dop AS [Max DOP]
,qs.total_spills AS [Total Spills]
,qs.last_spills AS [Last Spills]
,(qs.total_spills / qs.execution_count) AS [Avg Spills]
,qs.statement_start_offset
,qs.statement_end_offset
,qs.plan_handle
,qs.sql_handle
FROM
sys.dm_exec_query_stats qs WITH (NOLOCK)
ORDER BY
[Avg IO] DESC
)
SELECT
SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END – qs.statement_start_offset)/2)+1) AS SQL
,TRY_CONVERT(xml,qp.query_plan) AS [Query Plan]
,qs.*
FROM
Queries qs
OUTER APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
OUTER APPLY
sys.dm_exec_text_query_plan
(
qs.plan_handle
,qs.statement_start_offset
,qs.statement_end_offset
) qp
OPTION (RECOMPILE, MAXDOP 1);
В зависимости от целей настройки можно сортировать данные по-разному: по устройствам ввода/вывода, когда задача — уменьшить нагрузку на диск, по ЦП в системах с привязкой к ЦП и т. д.
На рис. 4.1 частично показан вывод кода на одном из серверов. Как видите, запросы для оптимизации легко отбираются по частоте их выполнения и по данным о потреблении ресурсов.
Планы выполнения, которые отражены в выводе, не содержат фактических показателей выполнения. В этом отношении они аналогичны расчетным планам выполнения. Учитывайте это во время оптимизации (подробнее об этом я расскажу в главе 5).
Этой проблемы можно избежать в SQL Server 2019 и более поздних версиях, а также в базах данных Azure SQL, где можно включить сбор последнего фактического плана выполнения инструкций в базах данных с уровнем совместимости 150. Понадобится также включить параметр базы данных LAST_QUERY_PLAN_STATS. Как и в случае любого сбора данных, этот параметр увеличит нагрузку на систему, хотя обычно это увеличение несущественно.

Последний фактический план выполнения доступен через функцию sys.dm_exec_query_plan_stats. Во всех примерах кода в этой главе ее можно использовать вместо sys.dm_exec_text_query_plan, и код останется работоспособным.
Следует учитывать еще несколько важных ограничений. Прежде всего вы не увидите никаких данных о запросах, для которых не кэшированы планы выполнения. Могут оказаться пропущенными некоторые редко выполняемые запросы, чьих планов уже нет в кэше. Обычно это не проблема, потому что такие запросы чаще всего не нуждаются в оптимизации в начале настройки.
Есть и еще один нюанс. SQL Server не кэширует планы выполнения, если вы используете перекомпиляцию на уровне инструкций с нерегламентированными инструкциями или выполняете хранимые процедуры с предложением RECOMPILE. Эти запросы придется захватывать с помощью хранилища запросов или расширенных событий, о которых я расскажу позже в этой главе.
Если вы используете перекомпиляцию на уровне инструкций в хранимых процедурах или других модулях T-SQL, то SQL Server кэширует план выполнения инструкции. Правда, план не будет использоваться повторно, а в статистике выполнения отразится только одно последнее выполнение.
Вторая проблема связана с тем, как долго планы хранятся в кэше. Это зависит от плана, и результаты могут исказиться при сортировке данных по общим показателям. Например, запрос с меньшим средним временем потребления ЦП может показать большее общее количество выполнений и время ЦП, чем запрос с более высоким средним временем ЦП, — в зависимости от того, когда каждый из планов был закэширован.
Можно использовать любую из этих метрик, но у каждой свои недостатки. Если сортировать данные по средним значениям, то наверху списка могут оказаться редко выполняемые запросы. Например, так происходит с ресурсоемкими задачами по обслуживанию в ночное время. В то же время сортировка по общим значениям может пропустить запросы с недавно кэшированными планами.
Можно изучить столбцы creation_time и last_execution_time, в которых содержится время последнего кэширования и выполнения планов соответственно. Я обычно просматриваю данные, отсортированные как по общим, так и по средним показателям, учитывая частоту выполнения (общее и среднее количество выполнений в секунду). Я сопоставляю данные из обоих источников, прежде чем решить, что оптимизировать.
Бывает проблема сложнее: для одного и того же запроса или нескольких похожих запросов можно получить несколько результатов. Это может случиться с нерегламентированными рабочими нагрузками, а также когда клиенты используют разные настройки SET в своих сеансах, когда пользователи запускают одни и те же запросы с немного различающимся форматированием, и во многих других случаях. Проблема также встречается в базах данных с уровнем совместимости 160 (SQL Server 2022) из-за функции оптимизации плана с учетом параметров (подробнее об этом в главе 6).
К счастью, эту проблему можно преодолеть с помощью столбцов query_hash и query_plan_hash, которые отображаются в представлении sys.dm_exec_query_stats. Идентичные значения в этих столбцах сигнализируют о похожих запросах и планах выполнения. Эти столбцы можно использовать, чтобы группировать данные.
Рассмотрим простой пример. Код из листинга 4.2 выполняет три запроса, а затем изучает содержимое кэша планов. Первые два запроса одинаковы, просто отформатированы по-разному. Третий запрос от них отличается.
Листинг 4.2. Столбцы query_hash и query_plan_hash в действии
DBCC FREEPROCCACHE -- Не используйте в промышленной системе!
GO
SELECT /*V1*/ TOP 1 object_id FROM sys.objects WHERE object_id = 1;
GO
SELECT /*V2*/ TOP 1 object_id
FROM sys.objects
WHERE object_id = 1;
GO
SELECT COUNT(*) FROM sys.objects
GO
SELECT
qs.query_hash, qs.query_plan_hash, qs.sql_handle, qs.plan_handle,
SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END – qs.statement_start_offset)/2)+1
) as SQL
FROM
sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
ORDER BY query_hash
OPTION (MAXDOP 1, RECOMPILE);
Результаты показаны на рис. 4.2. В выводимых данных три плана выполнения. В последних двух строках содержатся одинаковые значения query_hash и query_plan_hash, но разные sql_handle и plan_handle.
В листинге 4.3 приведена более сложная версия сценария из листинга 4.1: теперь статистика по похожим запросам группируется. Инструкция и планы выполнения выбираются случайным образом из первого запроса в каждой группе; учитывайте это при анализе.
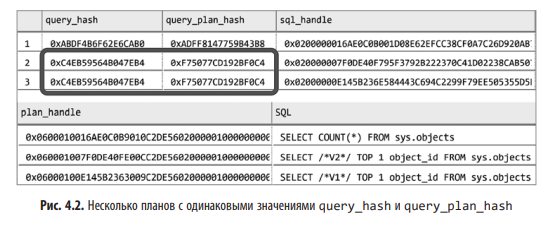
Листинг 4.3. Использование представления sys.dm_exec_query_stats с группировкой по query_hash
;WITH Data
AS
(
SELECT TOP 50
qs.query_hash
,COUNT(*) as [Plan Count]
,MIN(qs.creation_time) AS [Cached Time]
,MAX(qs.last_execution_time) AS [Last Exec Time]
,SUM(qs.execution_count) AS [Exec Cnt]
,SUM(qs.total_logical_reads) AS [Total Reads]
,SUM(qs.total_logical_writes) AS [Total Writes]
,SUM(qs.total_worker_time / 1000) AS [Total Worker Time]
,SUM(qs.total_elapsed_time / 1000) AS [Total Elapsed Time]
,SUM(qs.total_rows) AS [Total Rows]
,SUM(qs.total_physical_reads) AS [Total Physical Reads]
,SUM(qs.total_grant_kb) AS [Total Grant KB]
,SUM(qs.total_used_grant_kb) AS [Total Used Grant KB]
,SUM(qs.total_ideal_grant_kb) AS [Total Ideal Grant KB]
,SUM(qs.total_columnstore_segment_reads)
AS [Total CSI Segments Read]
,MAX(qs.max_dop) AS [Max DOP]
,SUM(qs.total_spills) AS [Total Spills]
FROM
sys.dm_exec_query_stats qs WITH (NOLOCK)
GROUP BY
qs.query_hash
ORDER BY
SUM((qs.total_logical_reads + qs.total_logical_writes) /
qs.execution_count) DESC
)
SELECT
d.[Cached Time]
,d.[Last Exec Time]
,d.[Plan Count]
,sql_plan.SQL
,sql_plan.[Query Plan]
,d.[Exec Cnt]
,CONVERT(DECIMAL(10,5),
IIF(datediff(second,d.[Cached Time], d.[Last Exec Time]) = 0,
NULL,
1.0 * d.[Exec Cnt] /
datediff(second,d.[Cached Time], d.[Last Exec Time])
)
) AS [Exec Per Second]
,(d.[Total Reads] + d.[Total Writes]) / d.[Exec Cnt] AS [Avg IO]
,(d.[Total Worker Time] / d.[Exec Cnt] / 1000) AS [Avg CPU(ms)]
,d.[Total Reads]
,d.[Total Writes]
,d.[Total Worker Time]
,d.[Total Elapsed Time]
,d.[Total Rows]
,d.[Total Rows] / d.[Exec Cnt] AS [Avg Rows]
,d.[Total Physical Reads]
,d.[Total Physical Reads] / d.[Exec Cnt] AS [Avg Physical Reads]
,d.[Total Grant KB]
,d.[Total Grant KB] / d.[Exec Cnt] AS [Avg Grant KB]
,d.[Total Used Grant KB]
,d.[Total Used Grant KB] / d.[Exec Cnt] AS [Avg Used Grant KB]
,d.[Total Ideal Grant KB]
,d.[Total Ideal Grant KB] / d.[Exec Cnt] AS [Avg Ideal Grant KB]
,d.[Total CSI Segments Read]
,d.[Total CSI Segments Read] / d.[Exec Cnt] AS [AVG CSI Segments Read]
,d.[Max DOP]
,d.[Total Spills]
,d.[Total Spills] / d.[Exec Cnt] AS [Avg Spills]
FROM
Data d
CROSS APPLY
(
SELECT TOP 1
SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END – qs.statement_start_offset)/2)+1
) AS SQL
,TRY_CONVERT(XML,qp.query_plan) AS [Query Plan]
FROM
sys.dm_exec_query_stats qs
OUTER APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
OUTER APPLY sys.dm_exec_text_query_plan
(
qs.plan_handle
,qs.statement_start_offset
,qs.statement_end_offset
) qp
WHERE
qs.query_hash = d.query_hash AND ISNULL(qt.text,'') <> ''
) sql_plan
ORDER BY
[Avg IO] DESC
OPTION (RECOMPILE, MAXDOP 1);
Начиная с SQL Server 2008, можно получать статистику выполнения хранимых процедур с помощью представления sys.dm_exec_procedure_stats1. Также можно использовать код из листинга 4.4. Как и в представлении sys.dm_exec_query_stats, данные можно сортировать по разным показателям выполнения в зависимости от вашей стратегии оптимизации. Учтите, что в статистику выполнения входят метрики из динамического SQL и других вложенных модулей (хранимых процедур, функций, триггеров), вызываемых из хранимых процедур.
Листинг 4.4. Использование представления sys.dm_exec_procedure_stats
SELECT TOP 50
IIF (ps.database_id = 32767,
'mssqlsystemresource',
DB_NAME(ps.database_id)
) AS [DB]
,OBJECT_NAME(
ps.object_id,
IIF(ps.database_id = 32767, 1, ps.database_id)
) AS [Proc Name]
,ps.type_desc AS [Type]
,ps.cached_time AS [Cached Time]
,ps.last_execution_time AS [Last Exec Time]
,qp.query_plan AS [Plan]
,ps.execution_count AS [Exec Count]
,CONVERT(DECIMAL(10,5),
IIF(datediff(second,ps.cached_time, ps.last_execution_time) = 0,
NULL,
1.0 * ps.execution_count /
datediff(second,ps.cached_time, ps.last_execution_time)
)
) AS [Exec Per Second]
,(ps.total_logical_reads + ps.total_logical_writes) /
ps.execution_count AS [Avg IO]
,(ps.total_worker_time / ps.execution_count / 1000)
AS [Avg CPU(ms)]
,ps.total_logical_reads AS [Total Reads]
,ps.last_logical_reads AS [Last Reads]
,ps.total_logical_writes AS [Total Writes]
,ps.last_logical_writes AS [Last Writes]
,ps.total_worker_time / 1000 AS [Total Worker Time]
,ps.last_worker_time / 1000 AS [Last Worker Time]
,ps.total_elapsed_time / 1000 AS [Total Elapsed Time]
,ps.last_elapsed_time / 1000 AS [Last Elapsed Time]
,ps.total_physical_reads AS [Total Physical Reads]
,ps.last_physical_reads AS [Last Physical Reads]
,ps.total_physical_reads / ps.execution_count AS [Avg Physical Reads]
,ps.total_spills AS [Total Spills]
,ps.last_spills AS [Last Spills]
,(ps.total_spills / ps.execution_count) AS [Avg Spills]
FROM
sys.dm_exec_procedure_stats ps WITH (NOLOCK)
CROSS APPLY sys.dm_exec_query_plan(ps.plan_handle) qp
ORDER BY
[Avg IO] DESC
OPTION (RECOMPILE, MAXDOP 1);
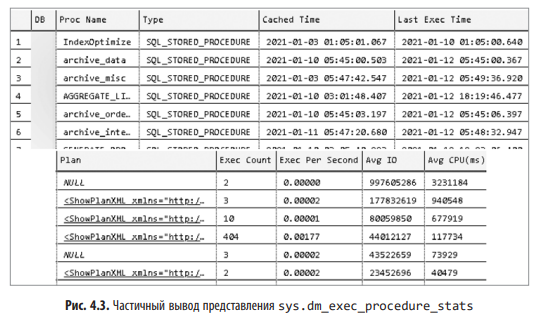
На рис. 4.3 частично показан вывод этого кода. Как видите, таким образом можно получить планы выполнения хранимых процедур. Во внутреннем представлении планы выполнения хранимых процедур и других модулей T-SQL представляют собой просто наборы отдельных планов каждой инструкции. В некоторых случаях — например, когда размер плана выполнения превышает 2 Мбайт — план не попадает в выходные данные.
Листинг 4.5 помогает решить эту проблему. С помощью этого кода можно получить кэшированные планы выполнения и их метрики для отдельных инструкций из модулей T-SQL. Имя модуля указывается в предложении WHERE при запуске скрипта.
SELECT
qs.creation_time AS [Cached Time]
,qs.last_execution_time AS [Last Exec Time]
,SUBSTRING(qt.text, (qs.statement_start_offset/2)+1,
((
CASE qs.statement_end_offset
WHEN -1 THEN DATALENGTH(qt.text)
ELSE qs.statement_end_offset
END – qs.statement_start_offset)/2)+1) AS SQL
,TRY_CONVERT(XML,qp.query_plan) AS [Query Plan]
,CONVERT(DECIMAL(10,5),
IIF(datediff(second,qs.creation_time, qs.last_execution_time) = 0,
NULL,
1.0 * qs.execution_count /
datediff(second,qs.creation_time, qs.last_execution_time)
)
) AS [Exec Per Second]
,(qs.total_logical_reads + qs.total_logical_writes) /
qs.execution_count AS [Avg IO]
,(qs.total_worker_time / qs.execution_count / 1000)
AS [Avg CPU(ms)]
,qs.total_logical_reads AS [Total Reads]
,qs.last_logical_reads AS [Last Reads]
,qs.total_logical_writes AS [Total Writes]
,qs.last_logical_writes AS [Last Writes]
,qs.total_worker_time / 1000 AS [Total Worker Time]
,qs.last_worker_time / 1000 AS [Last Worker Time]
,qs.total_elapsed_time / 1000 AS [Total Elapsed Time]
,qs.last_elapsed_time / 1000 AS [Last Elapsed Time]
,qs.total_rows AS [Total Rows]
,qs.last_rows AS [Last Rows]
,qs.total_rows / qs.execution_count AS [Avg Rows]
,qs.total_physical_reads AS [Total Physical Reads]
,qs.last_physical_reads AS [Last Physical Reads]
,qs.total_physical_reads / qs.execution_count
AS [Avg Physical Reads]
,qs.total_grant_kb AS [Total Grant KB]
,qs.last_grant_kb AS [Last Grant KB]
,(qs.total_grant_kb / qs.execution_count)
AS [Avg Grant KB]
,qs.total_used_grant_kb AS [Total Used Grant KB]
,qs.last_used_grant_kb AS [Last Used Grant KB]
,(qs.total_used_grant_kb / qs.execution_count)
AS [Avg Used Grant KB]
,qs.total_ideal_grant_kb AS [Total Ideal Grant KB]
,qs.last_ideal_grant_kb AS [Last Ideal Grant KB]
,(qs.total_ideal_grant_kb / qs.execution_count)
AS [Avg Ideal Grant KB]
,qs.total_columnstore_segment_reads
AS [Total CSI Segments Read]
,qs.last_columnstore_segment_reads
AS [Last CSI Segments Read]
,(qs.total_columnstore_segment_reads / qs.execution_count)
AS [AVG CSI Segments Read]
,qs.max_dop AS [Max DOP]
,qs.total_spills AS [Total Spills]
,qs.last_spills AS [Last Spills]
,(qs.total_spills / qs.execution_count) AS [Avg Spills]
FROM
sys.dm_exec_query_stats qs WITH (NOLOCK)
OUTER APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
OUTER APPLY sys.dm_exec_text_query_plan
(
qs.plan_handle
,qs.statement_start_offset
,qs.statement_end_offset
) qp
WHERE
OBJECT_NAME(qt.objectid, qt.dbid) =
-- Замените на имя хранимой процедуры
ORDER BY
qs.statement_start_offset, qs.statement_end_offset
OPTION (RECOMPILE, MAXDOP 1);
Начиная с SQL Server 2016, можно получать статистику выполнения для триггеров и скалярных пользовательских функций, используя представления sys.dm_exec_trigger_stats и sys.dm_exec_function_stats соответственно. Можно использовать тот же код, что и в листинге 4.4, просто заменив в нем имя динамического административного представления. Код также можно скачать из сопроводительных материалов этой книги.
Наконец, стоит отметить, что SQL Server может кэшировать тысячи планов выполнения. Кроме того, функции получения планов запросов и инструкций SQL весьма трудоемкие, поэтому я использую параметр запроса MAXDOP, чтобы уменьшить накладные расходы. В некоторых случаях стоит сохранять содержимое кэша планов в отдельную базу данных с помощью операторов SELECT INTO и анализировать данные на тестовых серверах.
У статистики выполнения на основе кэша планов есть определенные ограничения, и некоторые запросы могут быть пропущены. Но этот подход годится в качестве отправной точки. Важнее всего, что нужные данные собираются автоматически и доступны сразу без дополнительных инструментов мониторинга.
Дмитрий регулярно выступает на различных мероприятиях по SQL Server. Он ведет блог на aboutsqlserver.com, иногда пишет в Twitter @aboutsqlserver, и с ним можно связаться по адресу dk@aboutsqlserver.com.
Более подробно с книгой можно ознакомиться на сайте издательства:
» Оглавление
» Отрывок
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
Для Хаброжителей скидка 25% по купону — SQL
Для жителей других стран появилась возможность приобрести электронную версию книгу на Amazon.
