Смарт-реплай стикерами
 Привет, Хабр! Сегодня мы перезапустили ICQ. Ключевые функции нового мессенджера основаны на технологиях искусственного интеллекта: система быстрых подсказок стикеров и текста Smart Reply для ответа на пришедшее сообщение, предложение стикеров по введенным фразам, распознавание голосовых сообщений и другие.
Привет, Хабр! Сегодня мы перезапустили ICQ. Ключевые функции нового мессенджера основаны на технологиях искусственного интеллекта: система быстрых подсказок стикеров и текста Smart Reply для ответа на пришедшее сообщение, предложение стикеров по введенным фразам, распознавание голосовых сообщений и другие.
В этой статье я расскажу про одну из них — Smart Reply. Данная фича позволит экономить время пользователей, так как им надо будет всего лишь кликнуть по понравившемуся стикеру из предложенных. Заодно фича будет популяризировать использование разнообразных стикеров и повышать эмоциональность общения.
Подготовка данных
Задача из области NLP и решалась с помощью машинного обучения и нейросетей. Обучение проводилось на специально подготовленных данных из публичных чатов. Использовались пары: фрагмент диалога и стикер, который присылался одним из пользователей в ответ на последнее сообщение собеседника. Для лучшего учета контекста фрагмент диалога состоит из последних сообщений собеседника, которые склеиваются, и из сообщений пользователя до них. С числом сообщений можно экспериментировать, например, в Google ML Kit используется контекст из 10 сообщений [1].
Одна из проблем, с которой пришлось столкнуться, заключается в том, что частота использования стикеров, начиная от наиболее популярных, резко падает. При этом общее число стикеров более миллиона. Ниже на рисунке представлены по убыванию частоты использования 4000 наиболее популярных стикеров. Поэтому для обучения было выбрано 4000 популярных стикеров с удалением некоторых самых частотных, чтобы снизить неравномерность распределения обучающего сета.
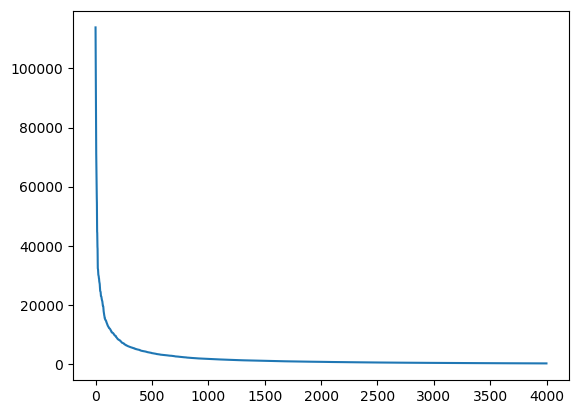
Частоты использования 4000 наиболее популярных стикеров по убыванию.
Для текстов выполнялась нормализация в плане удаления цифр, повторяющихся букв, одиночных символов, пунктуации (кроме знаков вопроса и восклицания, которые важны для смысла), приведения букв к нижнему регистру. Вообще, специфика такова, что в чатах пользователи слабо следят за грамматикой.
Выбор модели
Для предсказания используется сиамская модель DSSM, по аналогии с моделью для Smart Reply в Почте Mail.ru (близкая архитектура описывается в [2]), но с определенными отличиями. Преимущество сиамской модели в эффективности для инференса, так как часть, соответствующая стикерам, вычисляется заранее. Для ответа на письма в оригинальной модели используется мешок n-gram слов для представления текста, что для письма является оправданным: текст может быть большим, и нам надо уловить общую специфику и дать некоторый стандартный короткий ответ. В случае с чатами и стикерами текст короткий, и здесь важнее отдельные слова. Поэтому было решено использовать в качестве фич эмбединги отдельных слов и добавить для них LSTM-слой. Подобная идея использования LSTM-слоя в случае коротких текстов применялась, например, для текстовых ответов в мессенджере Google Allo [3] и в модели предсказания смайлов, соответствующих коротким сообщениям DeepMoji [4]. Ниже на рисунке схематически показана модель.
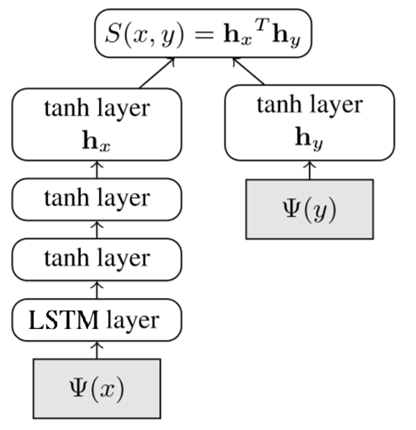
Архитектура модели.
На рисунке начальные слои — это эмбединги входящих токенизированных слов (слева) и стикеров (справа). Для токенизации слов использовался словарь, в который попали 100К наиболее популярных слов. Для разделения сообщений разных пользователей использовался специальный выделенный токен. Обучение идет end-to-end. После вычисления эмбедингов для последовательности слов идем LSTM-слой, состояние которого затем передается в полносвязные слои с тангенс-активацией. В итоге, в левом энкодере на выходе получаем вектор, который представляет текст, а в правом — вектор, соответствующий стикеру. Скалярное произведение векторов определяет, насколько подходят друг другу текст и стикер. Размерность эмбедингов, вектора внутреннего состояния LSTM и выходного вектора бралась равной 300.
Целевая функция для обучения выглядит так:
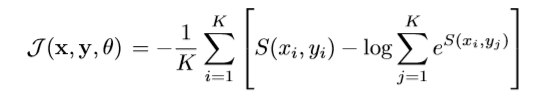
где K — это размер батча,
S (xi, yi) — скалярное произведение результирующих векторов для позитивных примеров пар текст-стикер,
S (xi, yj) — скалярное произведение векторов для негативных примеров пар текст-стикер. Негативные примеры пар текст-стикер генерировались за счет случайного перемешивания исходных корректных пар. Так как для популярных универсальных стикеров велика вероятность при перемешивании опять оказаться корректной парой, то на этапе дообучения применялся дополнительный контроль в рамках батча, чтобы не было похожих текстов для позитивных и негативных пар с одним стикером. В ходе экспериментов лучше работало, если негативных примеров использовать меньше, чем K. В виду шумности данных обучение большими батчами работало лучше. Усложнение модели и добавление attention-слоя заметного улучшения точности не дали, что, скорее, говорит об ограничениях, связанных с данными, и их качеством.
Из-за того что выбран подход со словарем из отдельных слов, а не character n-gram, теряется гибкость модели по отношению к опечаткам. Проводился с эксперимент с обучением fastText-эмбединга, который обучается непосредственно в сети, что позволило снизить влияние ошибок. В данном случае обучение шло хуже, и заметно помогло добавление attention-слоя. Взвесив показатели качества и другие факторы, решено было остановиться пока на более простой модели. В этом случае проблема опечаток решается применением спелчекера в ситуации, если слова нет в словаре. В обычном режиме спелчекер не применяется, так как некоторые слова с ошибками являются особенностью неформального общения в чатах.
Получение ответов
Как работает модель на стадии инференса?
Векторы для стикеров, вычисляемые правым энкодером, считаем заранее. На этапе обработки запроса используется только левый энкодер для получения вектора для входящего текста. Далее нужно получить список стикеров в порядке убывания скалярного произведения вектора текста и стикера. Это можно делать напрямую, перемножая все векторы стикеров, или использовать алгоритмы поиска ближайших соседей по данной метрике. Например, в [2] предлагается использовать Hierarchical Quantization для Maximum Inner Product Search (MIPS). Мы применили алгоритм поиска HNSW, и это дало существенное ускорение по сравнению с полным перебором.
Делаем ответы разнообразными
Следующий этап — это диверсификация предлагаемых стикеров, так как зачастую топовые стикеры могут быть все однообразны.

Три предлагаемых стикера на фразу «Привет»: без диверсификации и с диверсификацией.
Было проверено несколько вариантов для диверсификации. Самый простой — это выбрать топ N стикеров с учетом ограничения на score, далее выбрать топовый стикер, а остальные два выбрать с максимальным расстоянием между друг другом, при ограничении на допустимое различие расстояний до топового стикера. Данный подход можно комбинировать с использованием результатов ручной разметки стикеров по эмоциональной окраске (положительная, негативная, нейтральная), и выбирать из топ N стикеры с разной окраской, если такие присутствуют.
Другой вариант — кластеризация стикеров по их эмбедингам, и при выдаче результатов выбирать не более одного стикера из кластера. Для кластеризации использовалась связка UMAP + HDBSCAN. UMAP — это новый эффективный алгоритм снижения размерности, превосходящий уже зарекомендовавший себя t-SNE. Применялось снижение размерности до двух, а затем использовался алгоритм кластеризации HDBSCAN. Было выделено около 100 кластеров. Полностью автоматически данная задача не решается, при различных настройках удавалось добиваться кластеризации до 70% стикеров, но далее требуется ручная доработка, проверка. Поэтому остановились на описанных выше более простых вариантах, так как их результат оказался хорошим.
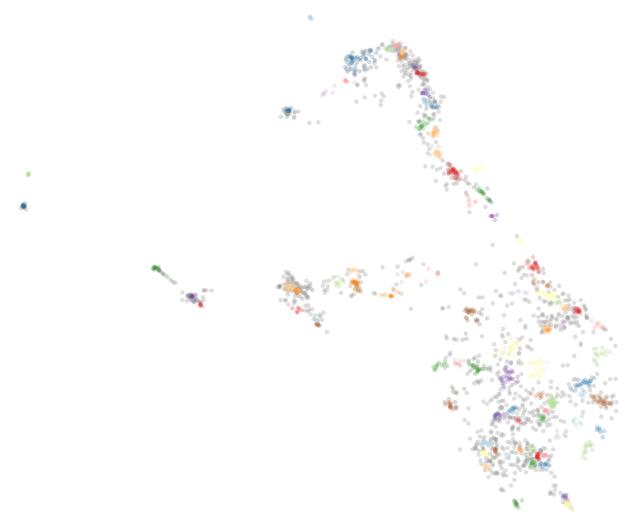
Кластеризация стикеров по эмбедингам.
Результаты
В итоге мы получили простой и эффективный смарт-реплай стикерами, который продемонстрировал очень хорошее качество ответов. По тестам на 1000 различных фраз, от простых до относительно сложных, по оценкам респондентов топовый стикер назвали полностью подходящим более чем в 75% случаев. На тесте по 100 более простым и популярным фразам результат еще более впечатляющий: топовый стикер назвали полностью подходящим в 93% случаев.

Примеры предлагаемых моделью ответов стикером.
Какие имеются недостатки?
Из-за имеющейся разбалансированности набора данных для обучения некоторые слова имеют излишне большое влияние. Например, слово «люблю» в каком-либо контексте часто ведет к предложению различных «романтических» стикеров, так как в обучающих данных имеется перекос в эту сторону. Введение дополнительных весов на частотные слова и стикеры, а также аугментация фраз не помогли полностью решить проблему, но частично улучшили ситуацию.
Мы не останавливаемся на достигнутом, и процесс улучшения качества наших моделей продолжается, проводятся эксперименты по модификации архитектуры и механизмов подготовки и использования данных.
Литература
- Google updates ML Kit with Smart Reply API for third-party Android and iOS apps. 9to5google.com/2019/04/05/ml-kit-smart-reply
- Matthew Henderson, Rami Al-Rfou, Brian Strope, Yun-Hsuan Sung, Laszlo Lukacs, Ruiqi Guo, Sanjiv Kumar, Balint Miklos, and Ray Kurzweil. Efficient Natural Language Response Suggestion for Smart Reply. arXiv:1705.00652v1, 2017.
- Pranav Khaitan. Chat Smarter with Allo. ai.googleblog.com/2016/05/chat-smarter-with-allo.html
- Bjarke Felbo, Alan Mislove, Anders Søgaard, Iyad Rahwan, Sune Lehmann. Using millions of emoji occurrences to learn any-domain representations for detecting sentiment, emotion and sarcasm. arXiv:1708.00524v2, 2017.
