(Не)очевидный OSINT в Twitter
Twitter — достаточно старый, но при этом все еще популярный у широкой аудитории сервис микроблогов, которым активно пользуются как рядовые пользователи, так и публичные личности. Лучший пример — официальные Twitter-аккаунты политиков, писателей, музыкантов, актеров. Конечно, зачастую такие учетные записи ведутся «специально обученными людьми», но если речь идет об OSINT в производственной сфере, то наблюдение за аккаунтами рядовых инженеров или менеджеров может дать великолепные результаты.
Немаловажно и то, что для эффективной работы с массивом данных из Twitter не обязательно обрабатывать каждый твит вручную, либо же бросаться в другую крайность — подключаться к API и самому писать софт. Хотя стандартный интерфейс сервиса не дает нам почти ничего в плане поисковых инструментов или инструментов фильтрации, при этом Twitter поддерживает огромное множество поисковых запросов и правил, о которых нигде толком в стандартном веб-интерфейсе или приложении не упоминается. Именно с использования этих запросов и стоит начать.
Twitter Dorks
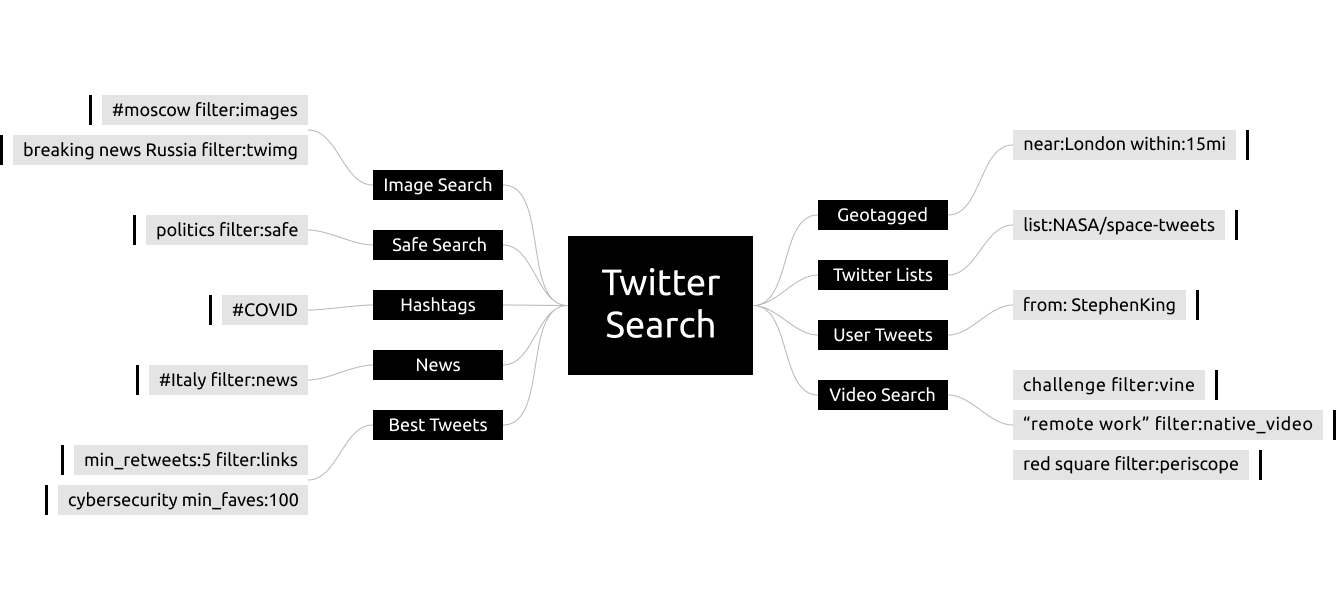
В Twitter информацию можно искать по четырем ключевым параметрам: по контенту, по полной информации твита, по типу медиа и по пользователю.
Под «контентом» подразумевается сам текст или ключевые слова твитов. К этой категории относятся следующие запросы:
Категория «информация» включает в себя как категорию «контент», так и такие данные как дата твита, геолокацию, ретвиты и даже такие сложные вещи, как фильтрацию по количеству ретвитов, ответов и лайков.
В категории «медиа» можно отфильтровать твиты по содержимому медиа-контенту, например, искать только твиты с видео или фото, либо просто найти все записи, которые содержат какой-либо внешний URL.
С фильтрацией по «пользователю» все более-менее понятно: этот набор поисковых функций позволяет отфильтровать записи по аккаунтам. При этом мы можем наблюдать не за конкретными твитами, а, например, только за ответами объекта наблюдения конкретным пользователям.
Важно отметить, что для всех приведенных выше запросов вида «filter: type» действует правило «исключающего» запроса через использование символа »-». Например, чтобы получить все медиа от NASA кроме изображений, нужно ввести запрос вида «from: NASA filter: media -filter: images».
Весь этот набор поисковых команд выглядит как Новый год посреди лета, потому что избавляет нас от необходимости парсинга сторонними инструментами, подключения к API и прочим техническим ухищрениям и сложностям, которые присущи поиску в публичных данных.
Фактически, сам Twitter позволяет нам забирать любую интересующую нас информацию, причем по достаточно широкому спектру параметров, которые мы сможем комбинировать между собой. Что удивительно, все описанные поисковые запросы нигде очевидно не документированы. То есть Twitter позволяет тонко парсить и искать по записям своих пользователей, но особо об это не распространяется. И это прекрасно — что у нас есть такая возможность — потому что очень часто специалисты страдают от эффекта «overqualification» и усложняют себе жизнь там, где можно было воспользоваться бритвой Оккама и найти самое очевидное и при этом самое правильное решение для своей задачи.
Tweetdeck
Известным приложением для фильтрации контента по заданным параметрам и категориям является Tweetdeck. Однако если рядовой пользователь рассматривает Tweetdeck просто как очередную инкарнацию RSS-ленты, то в случае целенаправленной фильтрации публичных данных он становится весьма сильным инструментом.
Один из наиболее очевидных сценариев использования Tweetdeck в разрезе OSINT — снижение уровня шума в рабочей выборке твитов. Из коробки сервис способен создать черный список ключевых слов и твиты, содержащие их, просто не появятся в вашей ленте. Если вы занимаетесь OSINT и собираете информацию из публичных источников, то у подобной функции есть вполне очевидное применение.
Давайте возьмем условный кейс: твиттер-аккаунт Стивена Кинга. Кто сталкивался с учетной записью писателя, тот знает, что на 30% она состоит из любви к его собаке, на 60% из ненависти к президенту Трампу, а на 10% твитов выпадает все остальное. Если нам нужны именно последние 10% записей, то Tweetdeck прекрасно позволит отфильтровать большую часть неинтересного для нас мусора и работать с более-менее релевантной выборкой. Посмотрим на кусок ленты Кинга:

Отфильтруем через настройки Tweetdeck записи по ключевым словам «Trump», «president», «white house», «Obama», чтобы вырезать большую часть «политоты» из нашей выборки.
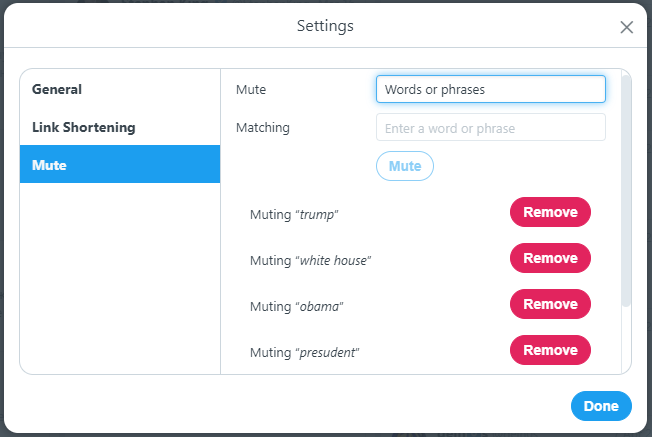
Собственно, делается это элементарно. После мута твитов с ключевыми словами, наблюдаемый нами аккаунт совершенно преобразился:

При этом Tweetdeck поддерживает все поисковые запросы, о которых шла речь в начале статьи, что делает его комфортным инструментом для поиска информации.
Сейчас многие из вас подумали, что с таким пулом поддерживаемых поисковых запросов осталось только написать софт, который будет вытягивать для вас твиты и собирать их в отчеты, например, в текстовые документы, которые потом можно будет лениво полистывать, потягивая свежий чаек. И вот тут опять работает принцип «самое простое решение — самое правильное». Ведь перед тем, как садиться писать софт, стоит открыть Google и он нам ответит: ничего писать не надо, такой софт уже есть и называется Twitter Archiver.
Twitter Archiver
Twitter (Tweet) Archiver — расширение для google-таблиц, которое собирает данные по нашим поисковым запросам из Twitter и выгружает все это в Google Docs. Само приложение цепляется к аддонам гугл-таблиц и позволяет выгружать результаты поиска сразу в документ.

В момент создания первого поискового правила Twitter Archiver запросит логин в существующий аккаунт, с которого будет вестись работа. Вот и все. Ищем, парсим, выгружаем в Excel-таблицу и анализируем.
Для примера пропарсим твиттер с максимально широкими параметрам поиска для того, чтобы показать, как будет выглядеть выгрузка:
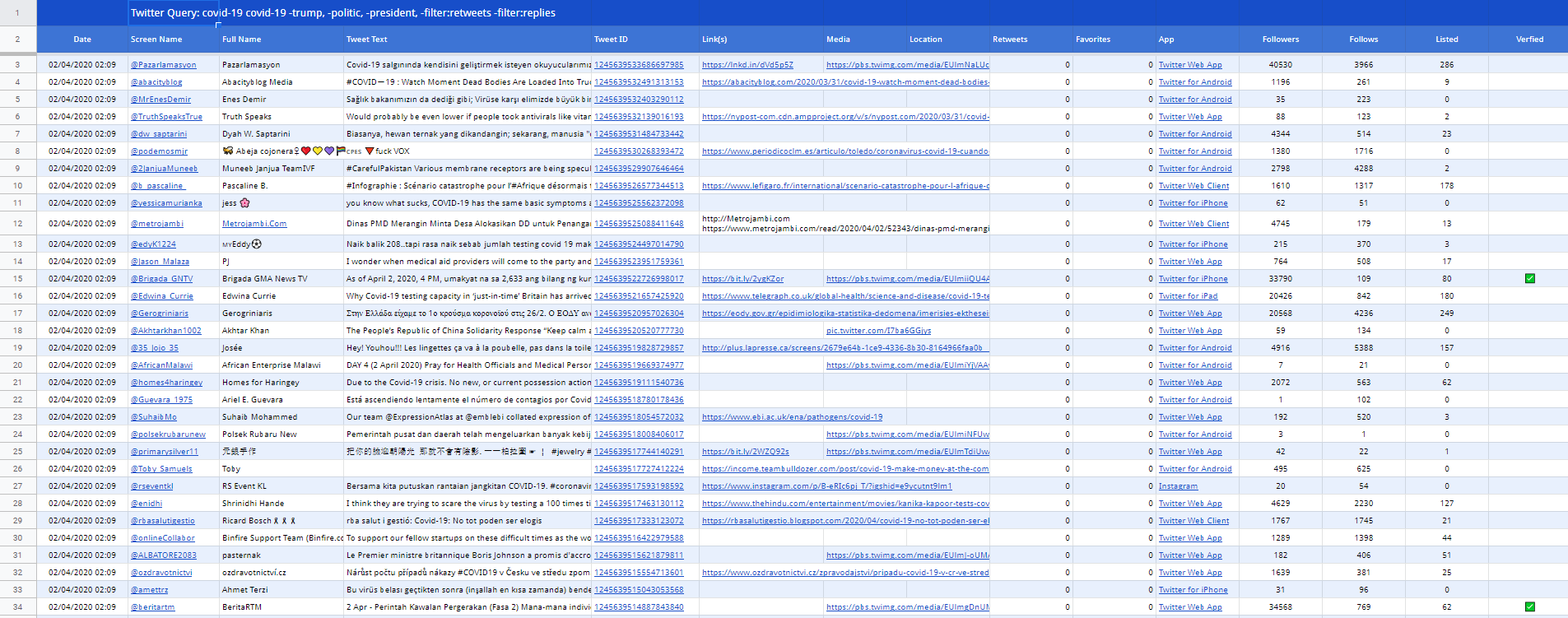
Кликабельно
На выходе мы получаем таблицу со следующими столбцами: Date, Screen Name, Full Name, Tweet Text, Tweet ID, Link (s), Media, Location, Retweets, Favorites, App, Followers, Follows, Listed, Verfied, User Since, Location, Bio, Website, Timezone, Profile Image. К сожалению, все это на скриншот выше не влезло, так как занимает два экрана.
В представленном инструменте есть только одно слабое место: бесплатная версия Twitter Archiver позволяет парсить только по одному правилу и только один раз в час. Платная версия работает без ограничений по количеству правил поиска и делает выгрузку раз в 15 минут. Стоит, правда, недешево: от 39$/год за одного пользователя и до 399$/год за неограниченное число учетных записей.
Итого
Собирать информацию в полуавтоматическом режиме можно без каких-либо навыков в программировании, достаточно поисковых запросов самого Twitter и приложение Tweetdeck. Бот для гугл-таблиц упрощает систематизацию, однако полноценная его версия стоит денег.
Есть и более сложный путь, который не относится к теме статьи в качестве простого решения, но упомянуть о котором необходимо. Это решение — получение доступа к API Twitter через официальный запрос и последующее создание собственных инструментов. Однако шансов на это у частного лица не слишком много: на профильных форумах говорят, что доступ к API дают далеко не всем и процент отказа очень велик.
Но что делать, если вы хотите защитить свои данные, а не собирать их? Как бороться с анализом данных в Twitter? Да, по сути, никак. Это публичная сеть микроблогов в которой есть только два инструмента защиты информации: черные списки аккаунтов и ограничение доступа.
Первое, очевидно, от ботов и парсинга не спасет. Второе более эффективно, но тогда твиты будут доступны для просмотра только подписчикам аккаунта. Если мы говорим о какой-то публичной учетной записи, то второй вариант не применим, плюс, наблюдатель всегда может прокрасться в перечень читателей, если владелец аккаунта добавляет новых фолловеров вручную.
Так что единственный гарантированный способ снизить вероятность OSINT-утечек через Twitter до приемлемого уровня — не пользоваться Twitter.
