«Скоро приедем?»: как оценить время в пути
За прошедший год мы много работали над качеством предсказания времени в пути (ETA) в навигаторе 2ГИС и на 30% увеличили количество маршрутов, у которых прогнозное время совпадает с реальным с точностью до минуты. Меня зовут Кирилл, я Data Scientist в 2ГИС, и я расскажу, как максимально точно рассчитывать время прибытия из точки А в точку Б в условиях постоянного изменения дорожной ситуации.
Поговорим про то, как мы постепенно меняли подходы к оценке времени в пути: от простой аддитивной модели до использования ML-моделей прогноза пробок и корректировки ETA. Ввели Traversal Time на смену GPS скоростей, а ещё проводили эксперименты и оценивали качество изменений алгоритма, чистили мусор из данных и закатывали модели в продакшн. Обо всём по порядку.

Почему нам важно правильно оценивать время в пути
Во-первых, оценка времени пути помогает выбрать подходящий маршрут из точки А в точку Б (сравнить время и решить, что подходит лучше).
Во-вторых, от времени в пути зависит стоимость поездки в такси или доставки товара, поэтому правильная оценка времени напрямую влияет на ценообразование для наших партнеров.
Важно определить, что мы понимаем под оценкой времени. Для этого используем два типа времени в пути (Time of Arrival):
ETA (Estimated Time of Arrival) — это ожидаемое время в пути (наша оценка времени);
RTA (Real Time of Arrival) — это реальное время в пути (время, которое прошло от начала и до завершения поездки пользователем).
Мы должны сделать так, чтобы наше ETA было как можно ближе к RTA.
 Для предложенного маршрута ETA равен 14 минутам, RTA в этот момент ещё неизвестно
Для предложенного маршрута ETA равен 14 минутам, RTA в этот момент ещё неизвестно
Какие метрики оцениваем
Оценка ETA — задача регрессионного анализа. Его классические метрики MAE (Mean Absolute Error) и RMSE (Root Mean Squared Error) отражают, на сколько минут в среднем отличается прогнозное время от реального (для некоторой случайной поездки):


Однако у такого подхода есть несколько проблем:
Длительность поездок может быть разной: 5 минут, 60 минут или даже несколько часов. Одна и та же ошибка прогноза — например, в 5 минут — будет восприниматься во всех трех случаях по-разному. Чем длиннее поездка, тем менее критичной будет казаться ошибка. Вспоминая, что ETA влияет на ценообразование, этот пример становится еще более актуальным.
Есть проблемы с интерпретацией результатов: если алгоритм в среднем ошибается на 10 минут — это хорошо или плохо? Ответить на этот вопрос невозможно, если мы не знаем среднюю длительность поездки. То есть в каждом новом эксперименте должна быть такая же средняя длительность поездки, как и в предыдущих. Если это требование нарушено, метрики экспериментов некорректно сравнивать между собой.
Нет сведений о том, в какую сторону алгоритм ошибается чаще. Постоянное занижение или завышение ETA — это очень плохо, даже если средняя ошибка низкая. Пользователи это заметят и попытаются скорректировать время в пути самостоятельно: например, прибавить 5 минут к прогнозному времени. Нашей оценке будут доверять меньше.
Поэтому для оценки качества ETA мы используем две другие метрики одновременно:
MAPE (Mean Absolute Percentage Error) показывает, на сколько процентов в среднем прогнозное время отличается от реального. Чем меньше ошибка, тем лучше.

Эта метрика решает трудности, связанные с интерпретацией результатов: теперь не нужно ничего знать о длительности поездки, чтобы понять, хорошо ли работает алгоритм и насколько большой будет ошибка для различных поездок.
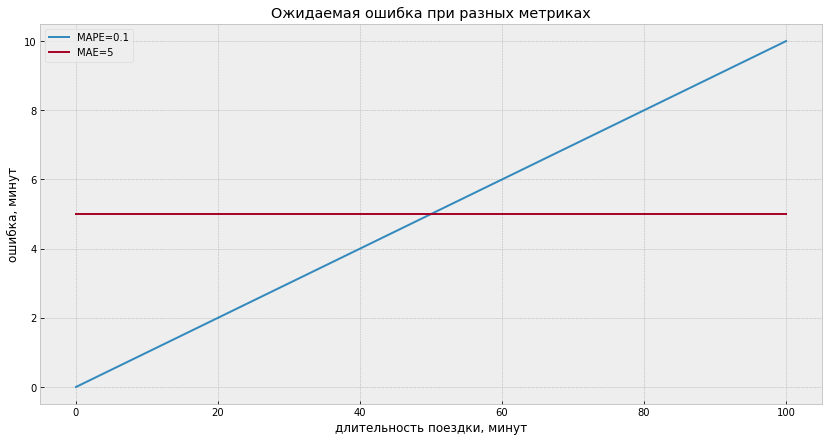 MAPE = 0.1 значит, что для десятиминутной поездки алгоритм в среднем ошибается на минуту, а для часовой — на 6 минут. MAE = 5 без дополнительных пояснений может значить, что для поездки в одну минуту можно ошибиться на целых 5 минут!
MAPE = 0.1 значит, что для десятиминутной поездки алгоритм в среднем ошибается на минуту, а для часовой — на 6 минут. MAE = 5 без дополнительных пояснений может значить, что для поездки в одну минуту можно ошибиться на целых 5 минут!
ETA/RTA (Estimated Time of Arrival / Real Time of Arrival) показывает среднее значение отношения прогнозного времени к реальному. В идеале оно должно быть около единицы, то есть в среднем алгоритм не должен стабильно завышать или занижать прогнозное время в пути.

ETA/RTA — вспомогательная метрика для проверки того, насколько (и в какую сторону) в среднем сдвинуто предсказанное время относительно реального. Для оценки качества предсказаний алгоритма в первую очередь нужно смотреть на MAPE.
Для анализа мы также используем и множество других метрик, однако эти две — наиболее значимые.
Вычисляем базовый алгоритм расчёта ETA
С метриками определились, а что дальше?
В нашем распоряжении есть дорожный граф, в котором ребра — это маленькие кусочки дорог, соединённые между собой. Каждое ребро такого графа может включать в себя несколько дорожных полос, но обязательно является однонаправленным. Помимо этого, есть также множество других постоянных характеристик ребра, например:
геометрия (длина и ширина);
ограничение на максимальную скорость;
тип покрытия;
наличие на ребре светофора.
Таким образом, считаем, что маршрут из А в Б — это путь в дорожном графе, начинающийся в вершине А и заканчивающийся в вершине Б.
 Пример маршрута: точки — это вершины графа, отрезки, их соединяющие — рёбра
Пример маршрута: точки — это вершины графа, отрезки, их соединяющие — рёбра
Также мы получаем GPS-данные с устройств пользователей-автомобилистов. Это текущее местоположение (широта и долгота) устройства, скорость, с которой устройство движется, азимут и прочее. Эти GPS-точки с каждого устройства приходят с интервалом в несколько секунд, что позволяет не просто собирать данные, но и анализировать целые траектории движения.
Более того, есть также алгоритм, который умеет притягивать GPS-точки к соответствующему ребру дорожного графа с довольно хорошей точностью. Поэтому для каждого ребра можно насчитать различные статистики:
текущая скорость;
текущая загруженность (например, число GPS-точек в единицу времени);
«обычная» скорость в это время (например, средняя за всю предыдущую неделю).
 Иллюстрация процесса притяжки к рёбрам графа: красные GPS точки проецируются на соответствующие рёбра графа, выделенные чёрным.
Иллюстрация процесса притяжки к рёбрам графа: красные GPS точки проецируются на соответствующие рёбра графа, выделенные чёрным.
Есть несколько вариантов расчёта статистик. Первый: пересчитывать их постоянно, с приходом новых точек — например, считать скорость на основе последних 100 точек. Второй: пересчитывать статистики каждые N минут на основе всех точек, полученных за это время.
Мы остановились на втором варианте и пересчитываем текущие статистики раз в пять минут, а «обычные» статистики — раз в неделю. Эти значения оказались оптимальными: если пересчитывать чаще, то данные не успевают накопиться (из-за чего статистики сильно «скачут»), а если реже, то не успеваем быстро адаптироваться к новой дорожной ситуации.
Всё готово к тому, чтобы рассказать про базовый алгоритм расчёта ETA:
Считаем время проезда по каждому ребру в маршруте на основе текущей скорости на ребре.
Добавляем к полученному времени «штрафы» — дополнительное время за совершение сложных манёвров, таких как повороты и развороты.
Алгоритм можно выразить простой формулой:

С преимуществами алгоритма всё понятно: он простой, быстрый и даже работает, предсказывая что-то близкое к правде! Но в таком виде у него есть существенные недостатки. Посмотрим на них.
Какие недостатки алгоритма нужно исправить
1. Алгоритм сильно зависит от текущих скоростей на ребрах
Эта скорость должна быть не какой-то абстрактной величиной, а точной оценкой средней скорости водителя на этом ребре. Поэтому нужно очень тщательно настроить алгоритм расчёта скоростей на ребрах, иначе предсказания будут далеки от истинных значений.
2. Не учитывается изменение скоростей по рёбрам во время движения
Некорректно брать текущую скорость на ребре, если мы приедем к нему, например, только через 40 минут. За это время на ребре может, например, начаться пробка, и скорость упадет в несколько раз, что повлияет на итоговое время в пути.
3. Нет персонализации предсказаний
Для любого пользователя на одном и том же маршруте будет предсказано одно и то же ETA, без учёта его манеры вождения.
4. Не учитывается общая дорожная ситуация и особенности построенного маршрута
Игнорируется много информации о состоянии дорог в маршруте, о текущих пробках в городе и конкретном районе, по которому предстоит ехать, количество участков с затрудненным движением и так далее.
5. Проблема с подбором корректных «штрафов»
В разных городах время на маневры может значительно отличаться. Более того, оно может быть уникальным для каждого перекрестка: нужно учитывать наличие светофоров, количество полос, качество и геометрию дороги и так далее. Эта задача ещё сложнее, чем расчет текущей скорости на ребре графа, поэтому в первых версиях алгоритма мы использовали постоянные штрафы на каждый вид манёвров.
Дальше расскажу про то, как мы поэтапно исправляли описанные недостатки.
Настраиваем схему экспериментов
Прежде чем модифицировать существующий алгоритм, нужно научиться оценивать эффект от изменений. Первая сложность — как оптимизировать две метрики? Что делать в ситуациях, когда одна метрика стала лучше, а другая — хуже?
Мало того, что две метрики в целом неудобно оптимизировать, так у них ещё есть особенности, которые мешают интерпретировать результат:
Во-первых, может быть ситуация, когда обе метрики стали лучше, а алгоритм — хуже.
Во-вторых, эти метрики взаимосвязаны: оптимальное значение MAPE достигается при ETA/RTA чуть меньшем, чем 1 (например, при ETA/RTA = 0.95). Из-за этого изменения (которые не делают ничего, кроме как немного двигают ETA всех маршрутов) могут влиять в том числе на MAPE.
Предположим, что мы как-то меняем существующий алгоритм и сравниваем его со старым по метрикам ETA/RTA и MAPE. По ним очевидный вывод: алгоритм стал лучше.

Теперь посмотрим на значения ETA/RTA поездок, полученные старым алгоритмом:
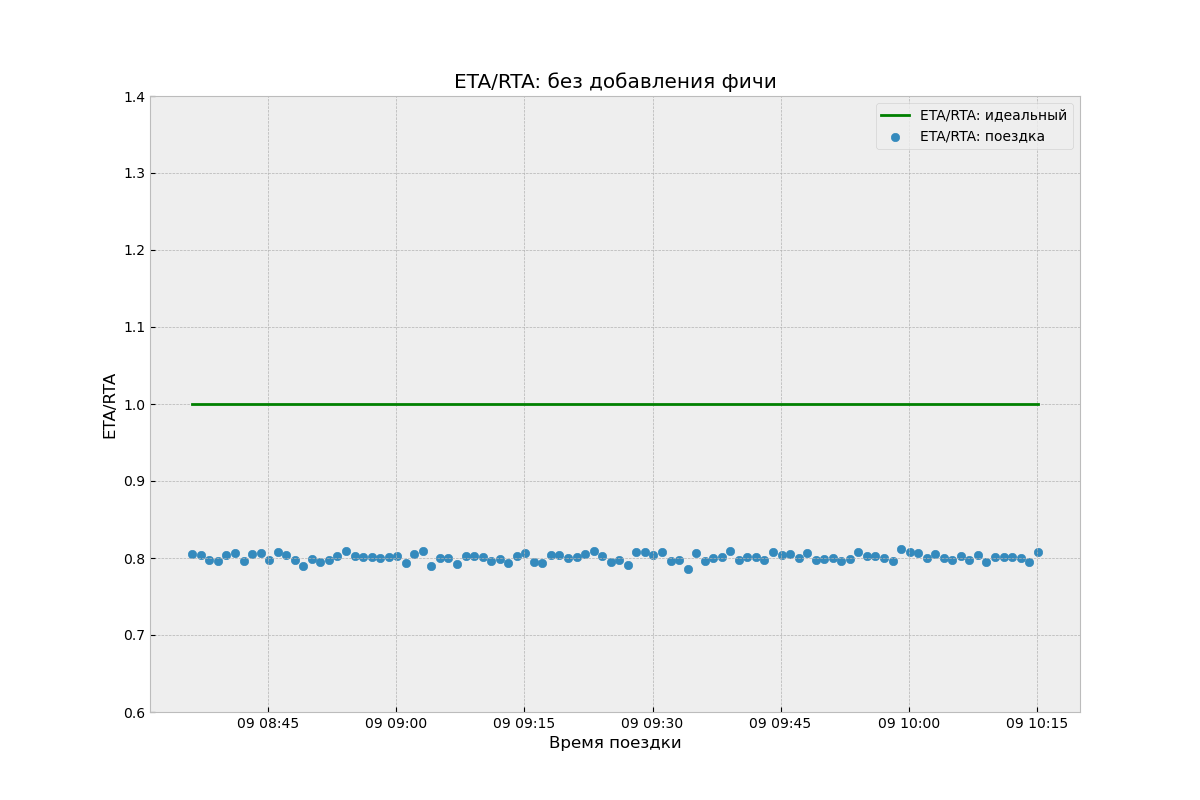
Видно, что в течение дня ETA/RTA смещён в среднем на 20% в сторону недопредсказания, но дисперсия значений очень низкая, что хорошо. Однако MAPE — это среднее отклонение относительно зелёной линии (то есть значения ETA/RTA=1), а не относительно среднего значения синих точек. Поэтому в данном случае MAPE высокий.
Если компенсировать этот сдвиг путем умножения ETA на 1.25, то получаем практически идеальный алгоритм с оптимальным ETA/RTA и низким MAPE:

А теперь посмотрим на график ETA/RTA поездок, полученных новым алгоритмом:
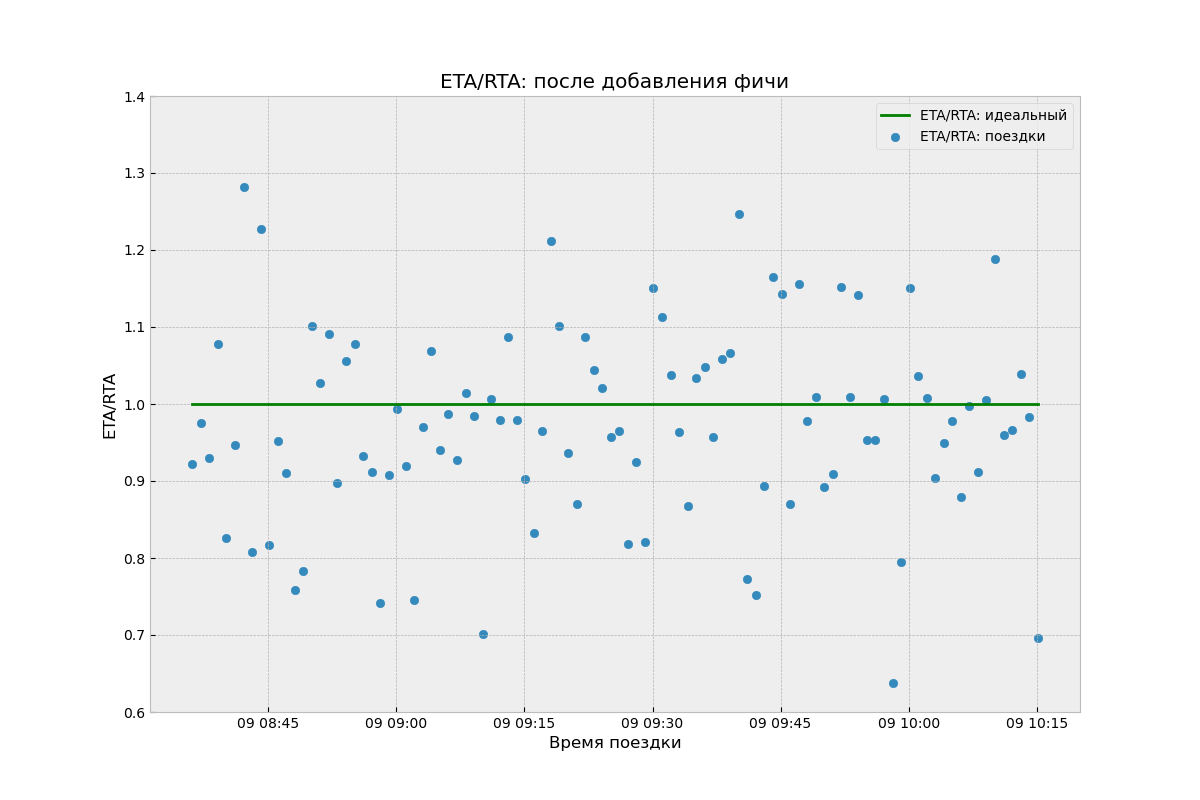
Он несмещённый, но имеет огромную дисперсию! Алгоритм однозначно стал хуже, но по метрикам этого не было видно. По графикам получаем один вывод, по метрикам — другой. Нужно что-то с этим сделать.
Чтобы выйти из этой ситуации, мы придумали свою метрику и назвали её NFCAM — Normalized First Central Absolute Momentum.

Фактически она показывает MAPE алгоритма при «идеальном» ETA/RTA, равном единице, и лишена двух вышеописанных недостатков. Заметим также, что любой смещённый алгоритм можно подвинуть к «идеальному» ETA/RTA путём умножения на величину, обратную ETA/RTA (которую можно насчитать из статистики).

По NFCAM видно, что алгоритм до добавления фичи был лучше, чем после, а простой сдвиг умножением не влияет на значение метрики. FCAM отличается от NFCAM отсутствием нормирующего члена в знаменателе, поэтому неустойчив к умножению.
После того, как определились с метрикой, появился следующий вопрос:, а как проводить эксперименты?
Все эксперименты мы проводим в два этапа:
Офлайн-тестирование: делаем датасет из поездок, для которых известна построенная геометрия маршрута и RTA. Заменяем скорости на ребрах/штрафы за манёвры на вычисленные новым алгоритмом и замеряем метрики.
Онлайн-тестирование: А/Б тестирование на реальных маршрутах.
Онлайн-тестирование нужно, чтобы проверить, не испортилось ли качество построения маршрутов (для этого у нас тоже есть специальная метрика). В офлайн-тестировании мы этого проверить не можем, так как RTA есть только для построенного маршрута, а значит, мы не можем перестраивать его в соответствии с новым алгоритмом — ведь тогда пользователь поехал бы иначе, а значит, RTA был бы другим.
Если обновленный алгоритм успешно проходит оба этапа, то есть для контрольной группы NFCAM становится лучше, то изменение выкатывается в продакшн.
Важно также отметить, что датасет мы формируем не из всех доступных поездок: среди поездок встречается очень много «мусора», который нужно отфильтровать. Чтобы попасть в датасет, «хорошая» поездка должна удовлетворять нескольким критериям:
Начинается и заканчивается недалеко от точек А и Б.
Реальная траектория движения не слишком отличается от предложенной (например, если предложенный маршрут был длиной 1 км, а пользователь проехал 8 км, такой маршрут отбросится).
Средняя скорость пользователя не аномальная (исключаем «телепортации» из-за некачественного GPS-устройства).
При этом мы не требуем, чтобы траектория движения полностью совпадала с предложенным маршрутом.
Улучшаем шаг за шагом
Traversal time
Решаем проблему 1. Улучшаем расчет текущих скоростей.
Мы уже упомянули о том, что сейчас алгоритм вычисления ETA по большей части зависит от текущих скоростей на рёбрах. Как правильно вычислять эти скорости?
Вспоминаем, что у нас есть GPS-точки, которые притягиваются к рёбрам. Первый и самый простой способ — усреднить все скорости GPS-точек на ребре и полученное число считать текущей скоростью. У такого подхода есть серьезные недостатки:
GPS-скорости очень ненадежны и часто значительно отличаются от настоящих.
Поскольку точки идут с интервалом в несколько секунд, неизвестно, какая скорость была между ними (фактически — игнорируем ускорение при расчетах).
Большое влияние на среднюю скорость оказывают выбросы: например, при каждой остановке будет присылаться нулевые скорости, которые нужно как-то фильтровать.
Более удачным способом вычислить текущую скорость оказался подход, использующий не GPS-скорости, а GPS-координаты. В нём мы пытаемся найти среднее время прохождения ребра пользователем (от начала и до конца ребра):

(суммирование происходит по всем пользователям, которые проезжали по ребру в выбранный период)
А уже на основе полученного времени — traversal time — мы считаем текущую скорость. Traversal time позволил значительно улучшить качество предсказания ETA по сравнению с подходом, в котором считали скорость только на основе GPS-скоростей.
Скорости из статистики
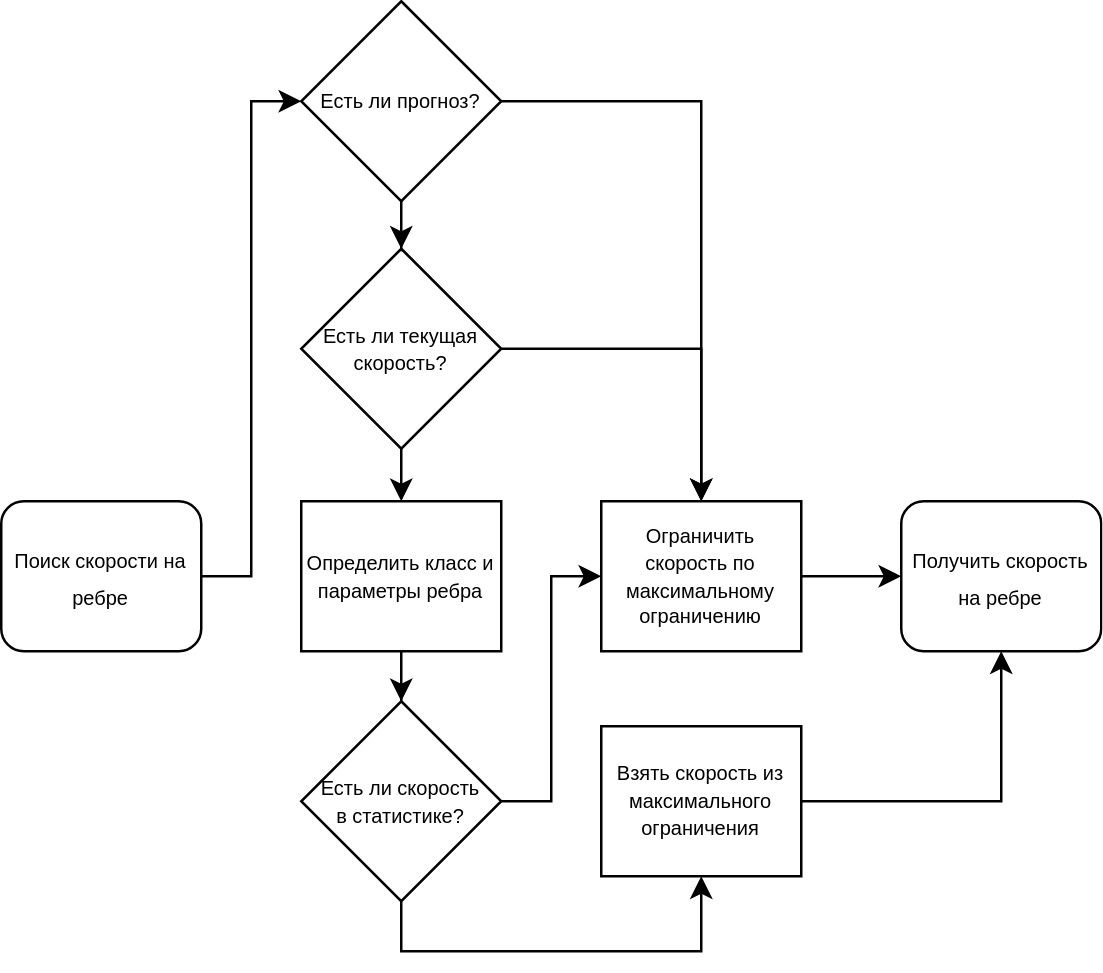
К сожалению, на ребре может быть недостаточно данных для расчёта скорости, которую можно было бы использовать для расчёта времени в пути по этому ребру. Но чтобы построить маршрут через это ребро, какая-то скорость всё же нужна. Для этого мы используем скорости из статистики следующим образом:
если недавно для этого ребра была рассчитана текущая скорость, берём её;
определяем «класс» ребра и берём скорость, типичную для этого класса;
если «класс» ребра не получается определить, берём ограничение скорости по знаку.
Раньше мы использовали скорости, которые «обычно» бывают в это время, но без них метрики оказались лучше.
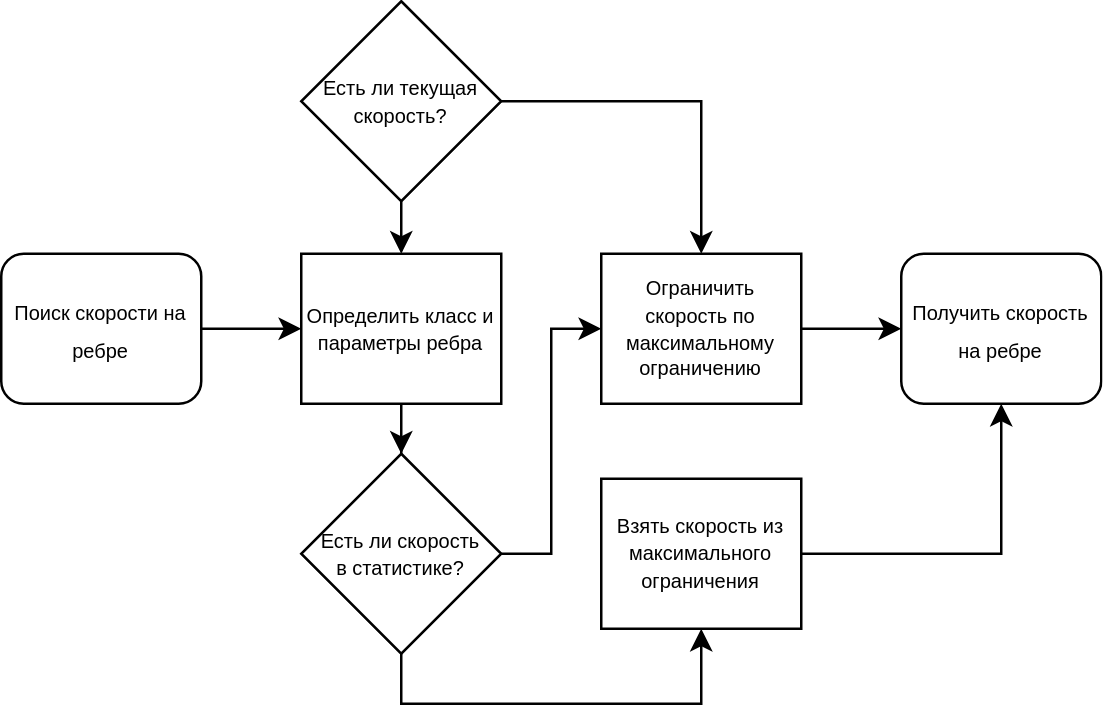
Модель прогноза скоростей
Решаем проблему 2. Прогнозируем изменение скоростей по мере движения пользователя по маршруту.
Дальше нужно было научиться предсказывать изменение скоростей (дорожной ситуации) по мере того, как пользователь двигается по маршруту. Для этого нужно заменить константные скорости на рёбрах на скорости, которые зависят от ETA кусочка маршрута, построенного из точки старта до выбранного ребра.
Для этого создали новую характеристику ребра — прогнозные скорости. Это скорости на час вперед от текущего момента с пятиминутным шагом, то есть 12 чисел для каждого ребра, которые, как и текущие скорости, пересчитываются раз в пять минут. Шаг в пять минут выбрали по аналогии с интервалом обновления текущих скоростей. Больший период прогноза, чем час, не оказывает никакого влияния на метрики ETA/RTA и MAPE.
Для формирования прогнозных скоростей сделали отдельный сервис с ML-моделями прогноза:
для каждого города свой набор моделей;
для каждого пятиминутного шага используется отдельная модель.
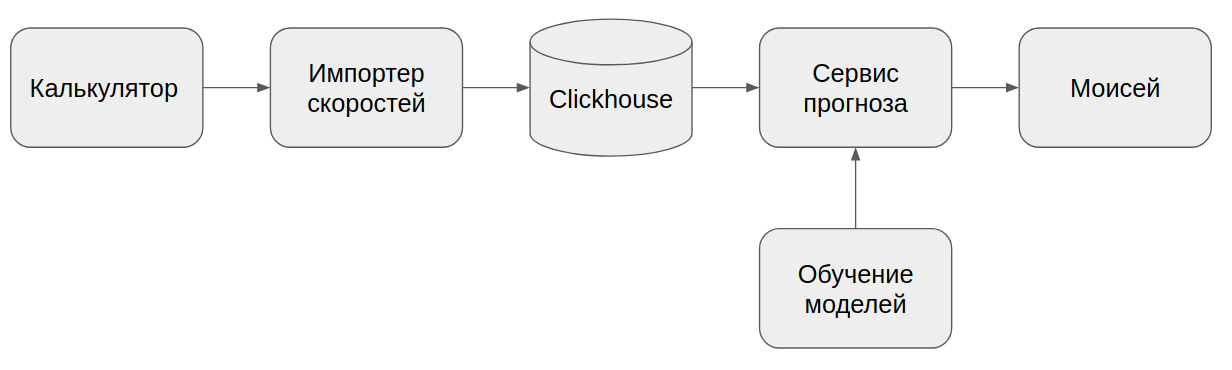 Да, вы правильно поняли: Моисей — это сервис построения маршрутов :)
Да, вы правильно поняли: Моисей — это сервис построения маршрутов :)
На вход сервис ждёт текущие скорости рёбер в дорожном графе. Затем они добавляются в БД Clickhouse, которая быстро считает признаки для нашего огромного объёма данных: среднюю и медианную скорости за последний час, неделю; количество полос на ребре; текущее время и прочее. Для тех рёбер, по которым недостаточно актуальной статистики, прогнозные скорости не вычисляются.
Сформированные признаки подаются на вход моделям, которые возвращают прогнозные скорости. Всё это упаковывается в файл и возвращается в сервис расчёта ETA.
Модели периодически автоматически переобучаются, чтобы учитывать изменение сезона и общей дорожной ситуации в городах. Качество каждой модели вычисляется так:
Выбираем некоторый момент в прошлом, предсказываем для него скорости через N минут (зависит от модели).
Считаем уже знакомую метрику RMSE между полученными скоростями и скоростями, которые будут текущими через N минут (то есть с «реальными» скоростями из будущего относительно момента предсказания).
Новые модели сравниваем со старыми на одинаковом наборе данных: если RMSE стал лучше, то модель меняется на новую. Также на стейджинге у нас развёрнут отдельный сервис прогноза для экспериментов.
Для ускорения работы сервиса мы убрали самые вычислительно тяжёлые признаки и конвертируем обученные модели в onnx-формат.
С добавлением прогнозных скоростей общая схема получения скорости на ребре выглядит так:
Модель корректировки ETA
Решаем проблемы 3 и 4. Добавляем персонализацию и учитываем дополнительные данные при предсказании ETA.
Затем нужно было как-то разобраться со сдвигом ETA/RTA: из-за того, что во всех городах используется один и тот же алгоритм, трудно отрегулировать все параметры так, чтобы ETA/RTA везде был около 1. В некоторых городах он был сильно занижен, а в других — завышен.
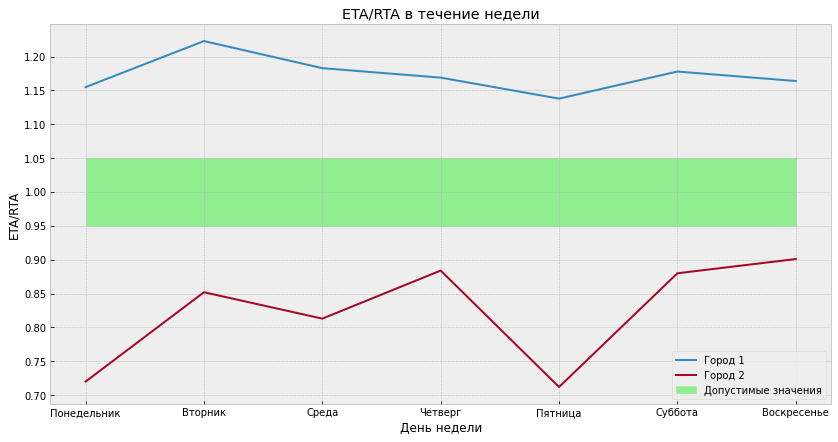 Пример распределения ETA/RTA по дням для двух разных городов: зелёной зоной обозначена та, в которой ETA/RTA считается допустимым
Пример распределения ETA/RTA по дням для двух разных городов: зелёной зоной обозначена та, в которой ETA/RTA считается допустимым
К тому же мы столкнулись с тем, что все пользователи навигатора делятся на две совершенно разные по стилю вождения группы: обычные пользователи и… таксисты :)
Последние ездят значительно быстрее, и для них ETA/RTA получается выше, чем для обычных пользователей. В итоге трудно сделать так, чтобы у обеих групп ETA/RTA не был сдвинут.
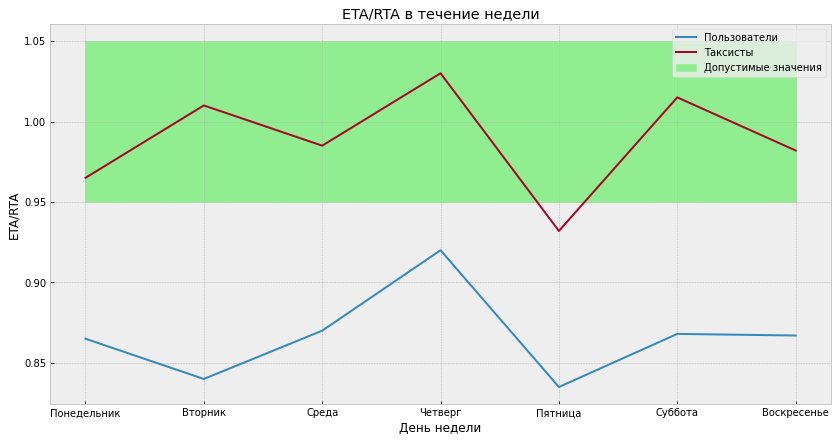 Пример распределений ETA/RTA обычных пользователей и таксистов в одном городе
Пример распределений ETA/RTA обычных пользователей и таксистов в одном городе
Первоначально мы с этим боролись так, как было описано выше: на основе статистических данных рассчитывали коэффициент коррекции…

… по каждому городу для обеих групп пользователей, а затем ETA поездок умножали на этот коэффициент. Таким образом решили проблему сдвига ETA/RTA и добавили персонализацию — для обычных пользователей и таксистов время в пути отличается.
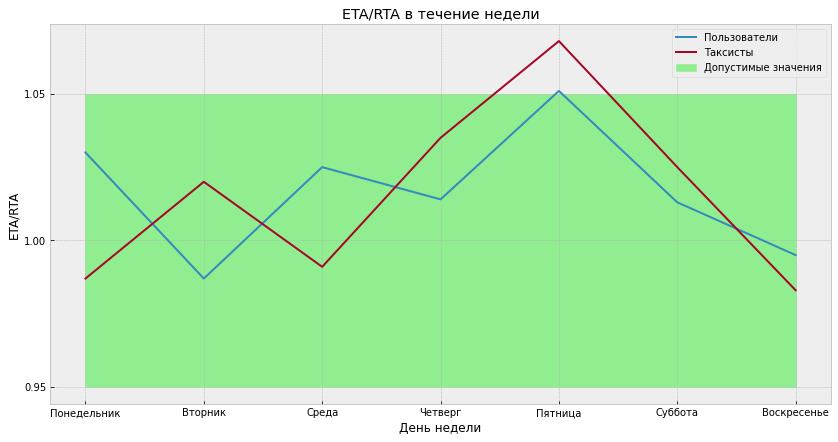 Графики распределения ETA/RTA после введения корректировки для того же города, что и на прошлом изображении. Видно, что константная корректировка работает не идеально, и иногда ETA/RTA всё равно выходит за границы
Графики распределения ETA/RTA после введения корректировки для того же города, что и на прошлом изображении. Видно, что константная корректировка работает не идеально, и иногда ETA/RTA всё равно выходит за границы
Затем мы улучшили этот механизм, и на смену константной корректировке пришла модельная корректировка, которая учитывает особенности каждого построенного маршрута.
 Модельная корректировка держит ETA/RTA в необходимом диапазоне, а сами значения стабильны ото дня ко дню
Модельная корректировка держит ETA/RTA в необходимом диапазоне, а сами значения стабильны ото дня ко дню
После построении маршрута и вычисления ETA считаются также его различные признаки, связанные со скоростями, геометрией, местоположением промежуточных точек и текущим временем. Затем эти признаки подаются на вход ML-модели, которая пытается скорректировать прежде посчитанный ETA. То есть модель не полностью заменяет базовый алгоритм, а только улучшает его результаты, используя дополнительную информацию.
В итоге вычисление ETA можно представить так:

Модели обучаются каждый день, потому что, во-первых, они получаются гораздо «легче» моделей прогноза, а во-вторых, они сильнее зависят от изменений дорожной ситуации.
Немного про штрафы
Решаем проблему 5. Уменьшаем влияние штрафов на итоговый результат.
В модели корректировки уже используется полная информация о манёврах в маршруте, поэтому определение штрафов за них мы переложили на модель. Формула расчета ETA немного упростилась, а качество — улучшилось:

Однако полностью от штрафов мы не отказались: они до сих пор используются при поиске оптимального маршрута (оптимальным мы считаем тот, у которого наилучший ETA), чтобы не строить геометрически слишком сложные маршруты. Поэтому в итоге у нас есть три разных времени в пути, каждое из которых очень важно:
ETA со штрафами: используется при построении маршрута.
ETA без штрафов: используется как признак в модели корректировки.
ETA скорректированный: используется как финальная оценка времени в пути по маршруту.
Результаты
Теперь, наконец, посмотрим, как повлияли все эти улучшения на метрики.
ETA/RTA
В результате ETA/RTA во всех городах теперь находится в пределах от 0.95 до 1.05, а в большинстве из них практически равен единице. Проблему сдвига ETA/RTA получилось полностью решить при помощи модели коррекции.
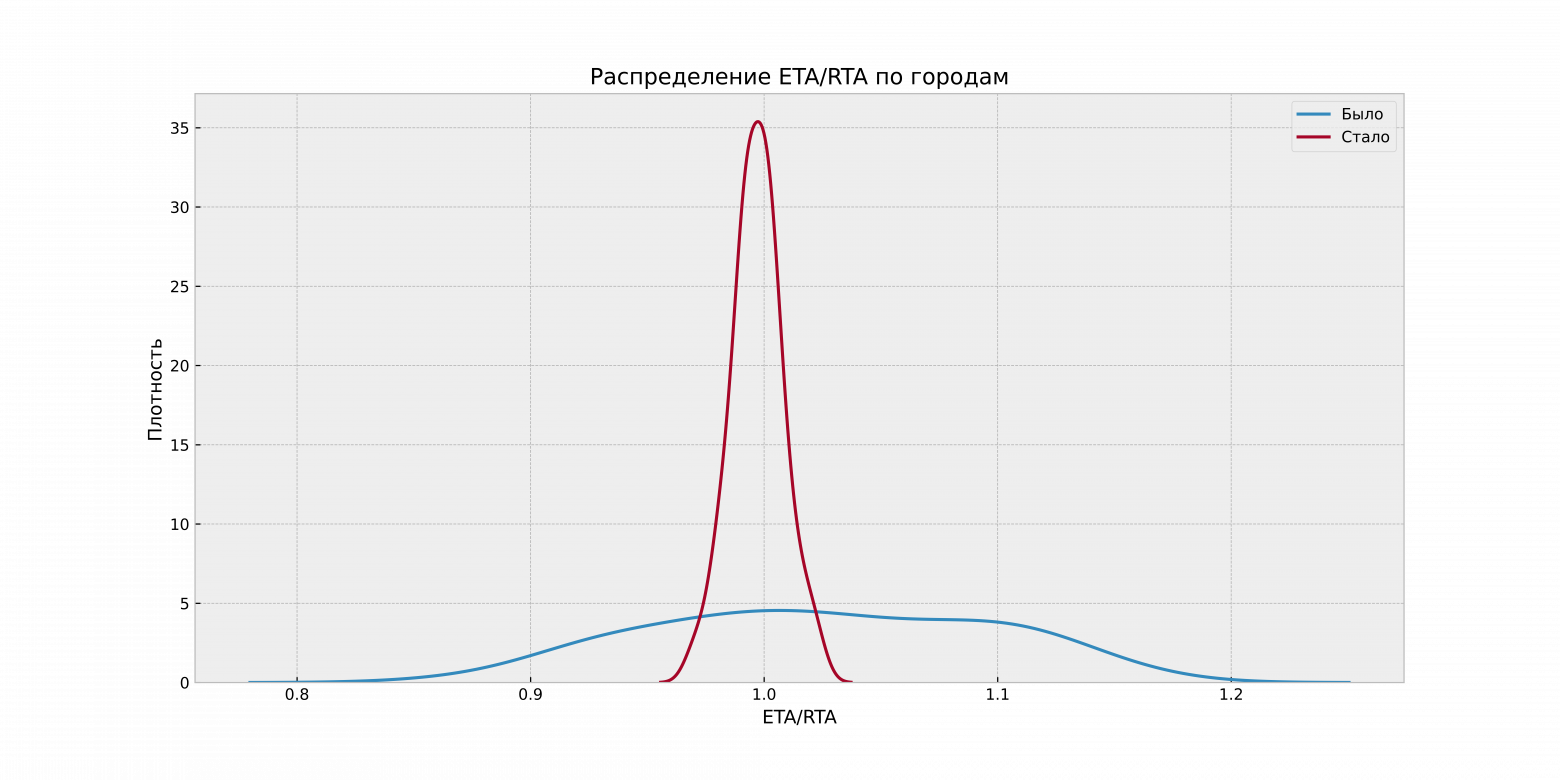
MAPE
MAPE улучшился в среднем на 0.08, а в отдельных городах улучшение достигло 0.13. Теперь в среднем мы ошибаемся менее чем на 20% при прогнозировании времени в пути.

Процент плохих маршрутов
Плохим маршрутом мы считаем тот, в котором ошибка прогнозирования оказалось больше 50%. Их количество удалось снизить на 4.5% от общего количества маршрутов, и теперь вероятность подобной ошибки — менее 10%.
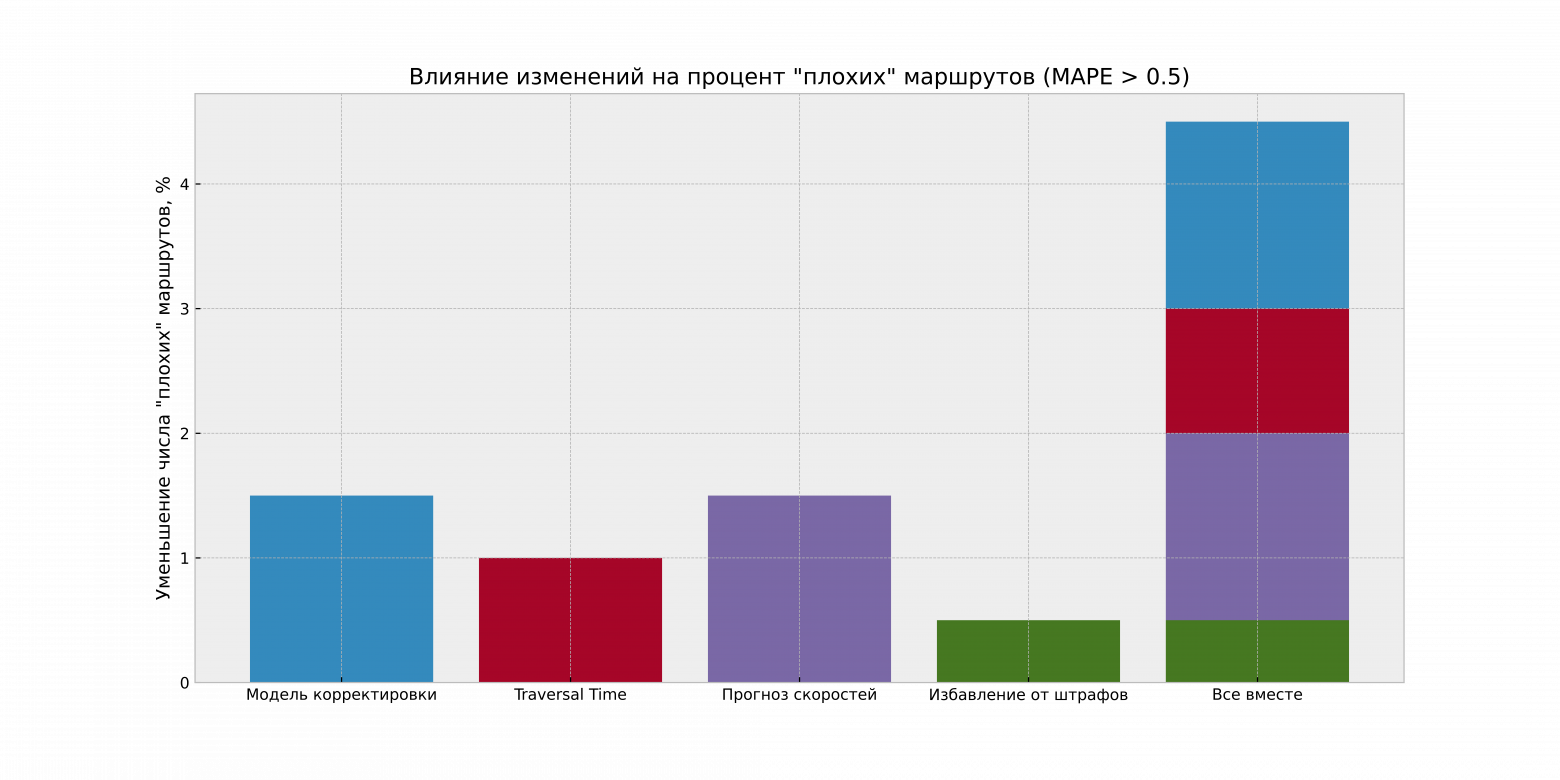
Можно с уверенностью сказать, что время в пути теперь определяется намного точнее, чем это было раньше, а значительных ошибок прогнозирования стало существенно меньше. Последнее особенно радует, потому что пользователи воспринимают эти ошибки крайне негативно.
Мы не останавливаемся на достигнутом и продолжаем улучшать алгоритмы вычисления времени в пути, в особенности, хотим учитывать личные предпочтения при построении геометрии маршрута.
