Сколько нужно нейронов, чтобы распознать сводку моста?
История началась, когда я переехал жить на остров Декабристов в Санкт-Петербурге. Ночью, когда мосты развели, этот остров вместе с Васильевским полностью изолирован от большой земли. Мосты при этом нередко сводят досрочно, иногда на час раньше опубликованного расписания, но оперативной информации об этом нигде нет.
После второго «опоздания» на мосты, я задумался об источниках информации о досрочной сводке мостов. Одним из пришедших в голову вариантов была информация с публичных веб-камер. Вооружившись этими данными и остаточными знаниями со специализации по ML от МФТИ и Яндекса, я решил попробовать решить задачу «в лоб».

Во-первых — камеры
С веб-камерами в Петербурге сейчас не густо, живых направленных на мосты камер у меня получилось найти только две: от vpiter.com и РГГМУ. Несколько лет назад были камеры от Skylink, но сейчас они не доступны. С другой стороны, даже информация по одному только Дворцовому мосту с vpiter.com может быть полезна. И она оказалась полезнее, чем я ожидал — товарищ-парамедик рассказал, что его экипаж «скорой» в том числе благодаря оперативной информации о мостах спас «плюс» двух петербуржцев и одного шведа за неделю. :-)
Ещё камеры имеют свойство отваливаться, отдавать видеопоток поток в мерзком формате flv, но всё это очень несложно обходится готовыми кубиками. Буквально в две строчки shell-скрипта из видеопотока получается набор кадров, поступающих на классификацию раз в 5 секунд:
while true; do
curl --connect-timeout $t --speed-limit $x --speed-time $y http://url/to | \
ffmpeg -loglevel warning -r 10 -i /dev/stdin -vsync 1 -r 0.2 -f image2 $(date +%s).%06d.jpeg
doneПравда, пока никакой классификации нет. Сначала в «сосисочную машинку» нужно положить размеченные данные, поэтому оставим скрипт работать по ночам на неделю, и опционально последуем мантре #ВПитереПить, проверив, что картинки грузятся.
x = io.imread(fname)
Во-вторых — обработка изображений
Так или иначе, раскидав руками и методом деления пополам фотографии по папкам UP, MOVING, DOWN я получил размеченную выборку. Эндрю Ын в своём курсе предлагал хорошую эвристику «если вы на картинке можете отличить объект A от объекта Б, то и у нейронной сети есть шанс». Назовём это эмпирическое правило наивным тестом Ына.
Первым делом кажется разумным обрезать картинку, чтоб на ней была только секция разводного моста. Телебашня — это красиво, но не выглядит практично. Напишем первую строчку кода, имеющую хоть какое-то отношение к обработке изображений:
lambda x: x[40:360, 110:630]
Я краем уха слышал, что настоящие специалисты берут OpenCV, извлекают фичи и получают пристойное качество. Но, начав читать документацию к OpenCV, мне стало печально — довольно быстро я понял, что в установленный лимит «сделать прототип за пару вечеров» я с OpenCV не уложусь. Но в используемой для чтения jpeg-ов библиотеке skimage по слову feature тоже кое-что находилось. Чем отличается разведённый мост от сведённого? Контуром на фоне неба. Ну так и возьмём skimage.feature.canny, записав себе в блокнот задачу почитать после прототипа о том, как устроен оператор Кэнни.
lambdax x: feature.canny(color.rgb2gray(x[40:360, 110:630]))
Едущий над заштрихованной водой троллейбус выглядит довольно красиво. Быть может, скучая и по этой красоте, mkot сожалеет, что переехал из Петербурга :-) Но данная картинка плохо проходит наивный тест Ына — она визуально выглядит шумной. Придётся прочитать документацию дальше первого аргумента функции. Кажется логичным, что если границ слишком много, то можно размазать картинку предлагаемым фильтром Гаусса. Значение по-умолчанию — 1, попробуем его увеличить.
lambdax x: feature.canny(color.rgb2gray(x[40:360, 110:630]), sigma=2)
Это уже больше походит на данные, чем на штрихи простым карандашом. Но есть другая проблема, у этой картинки 166400 пикселей, а кадров за ночь собирается пару-тройку тысяч, т.к. место на диске ноутбука не бесконечное. Наверняка, если взять эти бинарные пиксели как-есть, классификатор просто переобучится. Применим ещё раз метод «в лоб» — сожмём её в 20 раз.
lambda x: transform.downscale_local_mean(feature.canny(color.rgb2gray(x[40:360, 110:630]), sigma=2), (20, 20))
Это всё ещё похоже на мосты, но и изображение теперь всего 16×26, 416 пикселей. Имея несколько тысяч кадров на таком множестве недо-фич уже не очень страшно учиться и заниматься кросс-валидацией. Теперь неплохо бы выбрать топологию нейронной сети. Когда-то Сергей Михайлович Добровольский, читавший нам лекции по мат. анализу, шутил, что для предсказания исхода выборов президента США достаточно одного нейрона. Кажется, мост — не намного более сложная конструкция. Я попробовал обучить модель логистической регрессии. Как и ожидалось, мост устроен не намного сложнее выборов, и модель даёт вполне пристойное качество с двумя-тремя девятками на всяких разных метриках. Хотя такой результат и выглядит подозрительно (наверняка в данных всё плохо с мультиколлинеарностью). Приятным побочным эффектом является то, что модель предсказывает вероятность класса, а не сам класс. Это позволяет нарисовать забавный график, как процесс разводки Дворцового моста выглядит для «нейрона» робота в реальном времени.
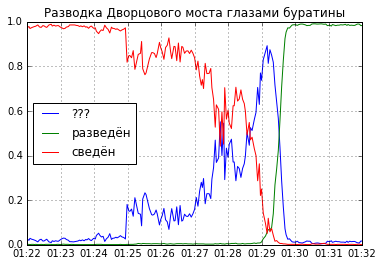
Остаётся прикрутить к этой конструкцию push-уведомления и какой-нибудь интерфейс, позволяющий посмотреть на мост глазами, если классификатор дал сбой. Первое оказалось сделать проще всего с помощью Telegram-бота, который отправляет уведомления в канал @SpbBridge. Второе — из костыликов, bootstrap и jquery сделать веб-мордочку с прямым эфиром.
Зачем я это всё написал?
Хотел напомнить, что у каждой проблемы есть простое, всем понятное неправильное решение, которое тем не менее может быть практичным.
И ещё, пока я писал этот текст, дождь, кажется, смысл в Неву камеру, которая смотрела на Дворцовый мост вместе с сервером vpiter.tv, о чём робот оперативно и сообщил.
Я буду рад, если вы во имя отказоустойчивости захотите поделиться своей веб-камерой, которая смотрит на какой-нибудь разводной мост. Вдруг, например, вы работаете в СПб ГКУ «ГМЦ» :-)
