Система сбора, анализа, уведомлений и визуализации логов на syslog-ng,elasticsearch,kibana,grafana,elasticalert
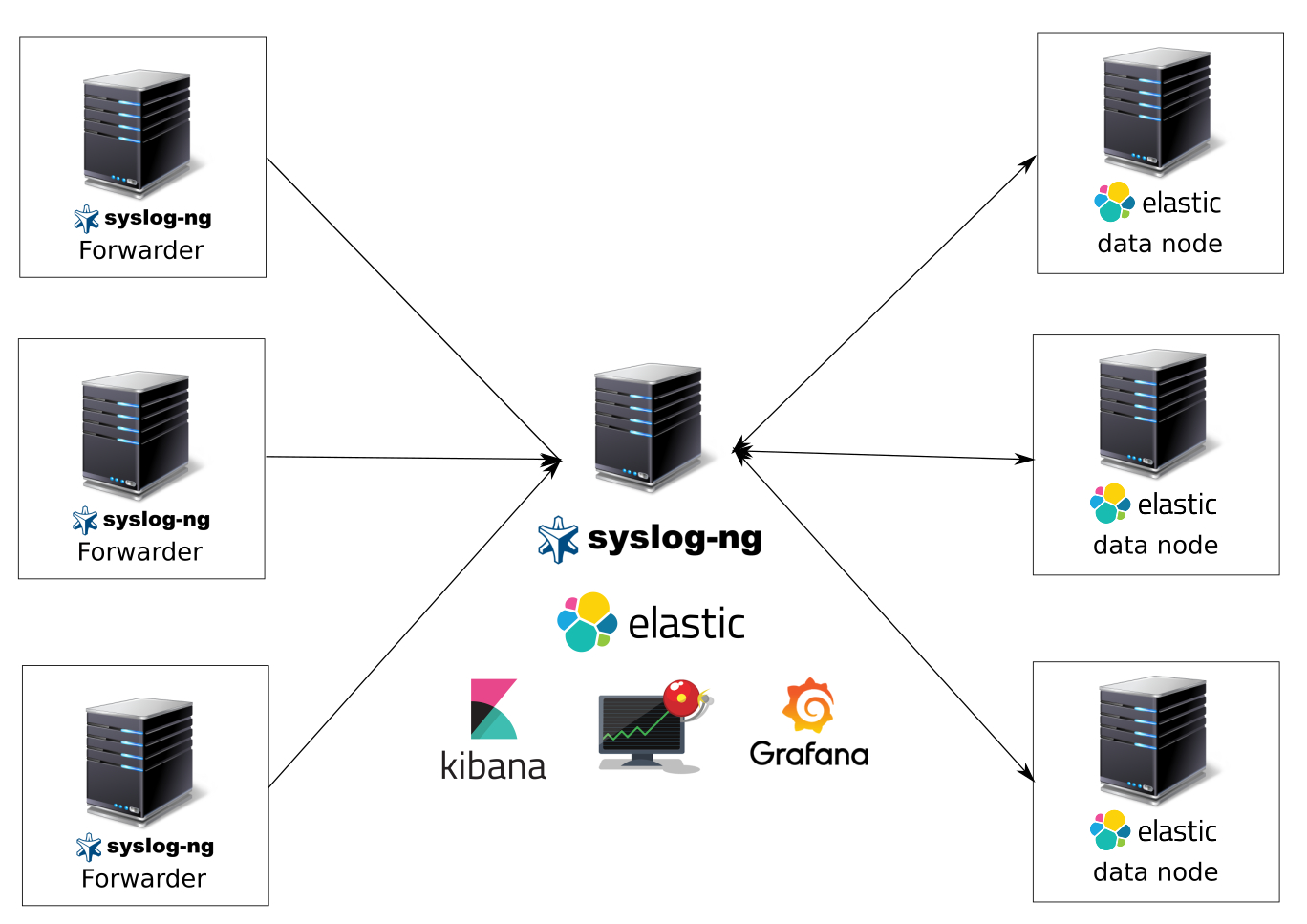
Что мы получим после этой статьи:
Систему сбора и анализа логов на syslog-ng, elasticsearch в качестве хранилища данных, kibana и grafana в качестве систем визуализации данных, kibana для удобного поиска по логам, elasticalert для отправки уведомлений по событиям. Приготовьтесь, туториал объемный.
Какие логи будем собирать:
- все системные логи разложенные по индексам в зависимости от их facility (auth, syslog, messages и т.д.);
- логи nginx — access и error;
- логи pm2;
- и др.
Обоснование выбора системы
Почему я выбрал связку с syslog-ng в качестве отправителя, парсера и приемщика логов? Да потому-что он очень быстрый, надежный, не требовательный к ресурсам (да да — logstash в качестве агентов на серверах и виртуальных машинах просто убожество в плане пожирания ресурсов и требованием java), с внятным синтаксисом конфигов (вы видели rsyslog? — это тихий ужас), с широкими возможностями — парсинг, фильтрация, большое количество хранилищ данных (postgresql, mysql, elasticsearch, files и т.д.), буферизация (upd не поддерживает буферизацию), сторонние модули и другие фишки.
Требования:
- Ubuntu 16.04 или debian 8–9;
- vm для развертывания;
- Прямые руки.
Приступим или добро пожаловать под кат
Небольшое пояснение.
Только кластер elasticsearch можно использовать в production, система из одной ноды просто загнется. В production используем кластер из master ноды и нескольких датанод. Отказоустойчивый кластер здесь рассматривать не будем. Кому интересно — вперед гуглить. Elastic рекуомендует исполльзовать одинаковую конфигурацию для нод кластера, так как кластер все равно будет работать со скоростью самой медленной ноды. Я использую ноды по 4 cpu и 12 gb озу и 700 gb ssd.
Наша система логов будет состоять из нескольких виртуальных машин — головного сервера (elasticnode1) и датанод elasticsearch (elasticnode2–9), на которых будут только храниться данные.
Сразу поправим файл /etc/hosts, если у вас нет настроенного dns сервера.
10.10.10.210 elasticsearch-node1 elasticnode1
10.10.10.211 elasticsearch-node2 elasticnode2
10.10.10.212 elasticsearch-node3 elasticnode3
10.10.10.213 elasticsearch-node4 elasticnode4
10.10.10.214 elasticsearch-node5 elasticnode5
10.10.10.215 elasticsearch-node6 elasticnode6
10.10.10.216 elasticsearch-node7 elasticnode7
10.10.10.217 elasticsearch-node8 elasticnode8
10.10.10.216 elasticsearch-node9 elasticnode9Компоненты головного сервера (elasticnode1):
- syslog-ng — наш главный приемщик, обработчик и отправитель логов;
- docker — в нем мы поднимем grafana, kibana, elasticalert;
- kibana — визуализация и поиск логов;
- grafana — визуализация и отправка уведомлений (на данный момент нельзя слать уведомления используя elasticsearch в качестве хранилища данных);
- elasticalert (через него и будем слать уведомления из elasticsearch в telegram — куда же без него);
- elasticsearch — собственно сюда и будем слать все наши данные с нод и отпарсенных файликов;
- ubuntu 16.04 в качетве ос.
Компоненты датанод (elasticнode2-elasticnode7):
- elasticsearch;
- ubuntu 16.04 в качестве ос.
Компоненты отправителей логов:
- ubuntu или debian;
- syslog-ng.
На данный момент появилась версия 6 продуктов elasticsearch, kibana и т.д., я же в production использую 5.6.3 — пока не было возможности мигрировать на последнюю версию.
Настраиваем отправители логов.
Устанавливаем syslog-ng последней версии. Ставить будем из репозитория. Здесь установка для Ubuntu 16.04.
systemct disable rsyslog; systemctl stop rsyslog; apt-get purge rsyslog -y
wget -P . http://download.opensuse.org/repositories/home:/laszlo_budai:/syslog-ng/xUbuntu_17.04/Release.key; apt-key add Release.key
echo "deb http://download.opensuse.org/repositories/home:/laszlo_budai:/syslog-ng/xUbuntu_16.10 ./" > /etc/apt/sources.list.d/syslog-ng-obs.list
wget http://no.archive.ubuntu.com/ubuntu/pool/main/j/json-c/libjson-c3_0.12.1-1.1_amd64.deb && dpkg -i libjson-c3_0.12.1-1.1_amd64.deb
apt-get update && apt-get install syslog-ng-core -yТюним sysctl.conf
Затираем
: > /etc/sysctl.conf
Вставляем
nano /etc/sysctl.confvm.swappiness=1
vm.max_map_count=262144
net.ipv4.tcp_wmem = 4096 65536 16777216
net.ipv4.tcp_wmem = 4096 262144 4194304
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_syncookies = 0
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_sack = 1
net.ipv4.tcp_rmem = 4096 262144 4194304
net.ipv4.tcp_rfc1337 = 1
net.ipv4.tcp_orphan_retries = 0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_mem = 50576 64768 98152
net.ipv4.tcp_max_syn_backlog = 65536
net.ipv4.tcp_max_orphans = 65536
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 20
net.ipv4.tcp_keepalive_intvl = 60
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_adv_win_scale = 2
net.ipv4.route.flush = 1
net.ipv4.ip_local_port_range = 10240 65535
net.ipv4.ip_forward = 1
net.ipv4.icmp_ignore_bogus_error_responses = 1
net.ipv4.icmp_echo_ignore_broadcasts = 1
net.ipv4.icmp_echo_ignore_all = 1
net.ipv4.conf.lo.rp_filter = 1
net.ipv4.conf.lo.accept_source_route = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.default.accept_source_route = 0
net.ipv4.conf.all.send_redirects = 0
net.ipv4.conf.all.secure_redirects = 0
net.ipv4.conf.all.rp_filter = 1
net.ipv4.conf.all.accept_source_route = 0
net.ipv4.conf.all.accept_redirects = 0
net.core.wmem_default = 65536
net.core.somaxconn = 65535
net.core.rmem_default = 65536
net.core.netdev_max_bacтlog = 100000
kernel.sem = 350 358400 64 1024
fs.inotify.max_user_watches = 67108864
fs.file-max = 518144
Применяем
sysctl -pНастраиваем syslog-ng для пирсинга и отправки логов с клиента на сервер.
Приводим /etc/syslog-ng/syslog-ng.conf к такому виду.
@version: 3.13
@include "scl.conf"
# Настраиваем глобальные параметры
options {
chain_hostnames(off);
log_fifo_size(1000);
use_dns(no);
use_fqdn(no);
owner("root");
group("adm");
perm(0640);
stats_freq(0);
bad_hostname("^gconfd$");
};
@include "/etc/syslog-ng/conf.d/*.conf"Создаем конфиг отправки логов на сервер.
mkdir -p /etc/syslog-ng/conf.d/
Вставляем сюда следующее содержимое
nano /etc/syslog-ng/conf.d/output.conf
source s_src {
system();
internal();
};
destination d_net {
udp("elasticnode1" port(514)
);
};
log { source(s_src); destination(d_net); };Таким образом мы все логи будет отправлять по udp на 514 порт сервера. Там он с ними разберется — разложит по индексам, отфильтрует и т.д.
Настройка отправки nginx access и error логов, через вывод содержимого лога и отправки по udp на обозначенные порты.
Почему я выбрал вывод содержимого из файла и отправку по udp, а не прямую отправку из nginx на порт? У меня возникали непонятные баги при отправке логов напрямую из nginx (сервер начинал возвращать много 500 и 502 ошибок).
Настройка логов для отправки в nginx. Отреадктируем конфиг nginx.conf.
#формат логов nginx, который будет принимать syslog-ng.
log_format full_format '"$time_iso8601"|"$http_host"|"$remote_addr"|"$http_x_forwarded_for"|"$request_method"|"$request"|"$status"|"$body_bytes_sent"|"$http_referer"|"$request_time"|"$upstream_http_x_cache"|"$uri"|"$upstream_addr"|"$host"|"$upstream_response_length"|"$upstream_status"|"$server_name"|"$http_host"|"$upstream_response_time"|"$upstream_cache_status"|"$http_user_agent"|"$scheme://$host$request_uri"|"$cookie_bar"';
access_log /var/log/nginx/access.log full_format;
error_log /var/log/nginx/error.log;Делаем рестарт nginx. Все логи будут падать (если у вам не переопределено в конфигах) в папку /var/log/nginx/ в 2 файла указанных выше.
Настраиваем syslog-ng на чтение файлов и отправку по udp.
nano /etc/syslog-ng/conf.d/output-nginx-logs.conf####Отправка логов на сервер nginx_access
destination udp_remote_log_host_nginx_main {
udp("elasticnode1" port(25230)
);
};
###### Источник с логами nginx access##################
source s_tail_log_host_nginx_main { file( "/var/log/nginx/access_main.log"
follow_freq(1)
flags(no-parse)
);
};
log {source(s_tail_log_host_nginx_main); destination(udp_remote_log_host_nginx_main);};
####Отправка логов на сервер nginx_error
destination d_server_nginx_error {
udp("elasticnode1" port(25231)
);
};
source s_tail_nginx_error { file( "/var/log/nginx/error.log"
follow_freq(1)
flags(no-parse)
);
};
log {source(s_tail_nginx_error ); destination(d_server_nginx_error);};Не забываем периодически обнулять файл логов, чтобы он не съел все место на сервере. Можете использовать данный скрипт по крону.
#!/bin/bash
find /var/log/elasticsearch/* -type f -ctime +2 | xargs rm -rf
for FILES in \
*.gz \
*.log.* \
*.log \
*.1 \
; do
/usr/bin/find /var/log/ -name "$FILES" -type f | xargs /bin/rm -rf
done
echo "Переинициализация логов nginx"
[ ! -f /var/run/nginx.pid ] || /bin/kill -USR1 `/bin/cat /var/run/nginx.pid`
/usr/sbin/logrotate /etc/logrotate.conf > /dev/null 2>&1Настраиваем головной сервер с syslog-ng, elasticsearch, kibana, grafana и elasticalert.
Для начала «тюним» систему.
Тюним limits.conf
Затираем
: > /etc/security/limits.confВставляем
nano /etc/security/limits.conf* - nofile 999999
* soft memlock unlimited
* soft memlock unlimited
* hard memlock unlimited
* soft nofile 999999
* hard nofile 999999
elasticsearch soft nofile 65535
elasticsearch hard nofile 65535
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimitedПроверяем
ulimit -aТюним sysctl.conf
Затираем
: > /etc/sysctl.confВставляем
nano /etc/sysctl.confvm.swappiness=1
vm.max_map_count=262144
net.ipv4.tcp_wmem = 4096 65536 16777216
net.ipv4.tcp_wmem = 4096 262144 4194304
net.ipv4.tcp_window_scaling = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_timestamps = 1
net.ipv4.tcp_syncookies = 0
net.ipv4.tcp_synack_retries = 1
net.ipv4.tcp_sack = 1
net.ipv4.tcp_rmem = 4096 262144 4194304
net.ipv4.tcp_rfc1337 = 1
net.ipv4.tcp_orphan_retries = 0
net.ipv4.tcp_no_metrics_save = 1
net.ipv4.tcp_moderate_rcvbuf = 1
net.ipv4.tcp_mem = 50576 64768 98152
net.ipv4.tcp_max_syn_backlog = 65536
net.ipv4.tcp_max_orphans = 65536
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_probes = 20
net.ipv4.tcp_keepalive_intvl = 60
net.ipv4.tcp_fin_timeout = 10
net.ipv4.tcp_congestion_control = htcp
net.ipv4.tcp_adv_win_scale = 2
net.ipv4.route.flush = 1
net.ipv4.ip_local_port_range = 10240 65535
net.ipv4.ip_forward = 1
net.ipv4.icmp_ignore_bogus_error_responses = 1
net.ipv4.icmp_echo_ignore_broadcasts = 1
net.ipv4.icmp_echo_ignore_all = 1
net.ipv4.conf.lo.rp_filter = 1
net.ipv4.conf.lo.accept_source_route = 0
net.ipv4.conf.default.rp_filter = 1
net.ipv4.conf.default.accept_source_route = 0
net.ipv4.conf.all.send_redirects = 0
net.ipv4.conf.all.secure_redirects = 0
net.ipv4.conf.all.rp_filter = 1
net.ipv4.conf.all.accept_source_route = 0
net.ipv4.conf.all.accept_redirects = 0
net.core.wmem_default = 65536
net.core.somaxconn = 65535
net.core.rmem_default = 65536
net.core.netdev_max_bacтlog = 100000
kernel.sem = 350 358400 64 1024
fs.inotify.max_user_watches = 67108864
fs.file-max = 518144
Применяем
systctl -pОтключаем swap.
swapoff -a Удаляем rsyslog
systemctl disable rsyslog
systemctl stop rsyslog
apt purge rsyslog -yСобираем syslog-ng из исходников со всеми модулями последней версии для нашего сервера.
Зависимости:
apt-get install bison gcc+ libglib2.0-0 libpcre3 glib-2.0 libglib2.0-dev flex python-dev libriemann-client-dev riemann-c-client libhiredis-dev libesmtp-dev libnet-dev libmaxminddb-dev libgeoip-dev libdbi-dev autoconf-archive libpixman-1-dev -y Устанавливаем granle
wget https://services.gradle.org/distributions/gradle-4.4-bin.zip
mkdir /opt/gradle
unzip -d /opt/gradle gradle-4.4-bin.zip
ls /opt/gradle/gradle-4.4
export PATH=$PATH:/opt/gradle/gradle-4.4/bin
configure && make && make installСтавим java8 и экспортируем пути
apt-get install openjdk-8-jdk -y
export LD_LIBRARY_PATH=/usr/lib/jvm/java-8-openjdk-amd64/jre/lib/amd64/server:$LD_LIBRARY_PATH
Клонируем репозиторий syslog-ng, собираем и устанавливаем
git clone https://github.com/balabit/syslog-ng/
cd syslog-ng
./autogen.sh
./configure --enable-all-modules --enable-systemd
make -j4 && make install
ldconfig -v Добавляем init.d скрипт — если вы ничего не меняли при сборке (пути) то все будет работать.
nano /etc/init.d/syslog-ng #! /bin/sh
### BEGIN INIT INFO
# Provides: syslog-ng
# Required-Start: $local_fs $network $time $remote_fs
# Required-Stop: $local_fs $network $time $remote_fs
# Default-Start: 2 3 4 5
# Default-Stop: 0 1 6
# Short-Description: Starting system logging daemon
# Description: Starting syslog-NG, the next generation
# syslog daemon.
### END INIT INFO#
set -e
SYSLOGNG_OPTS=""
#we source /etc/default/syslog-ng if exists
[ -r /etc/default/syslog-ng ] && . /etc/default/syslog-ng
# stop syslog-ng before changing its PID file!
PIDFILE="/var/run/syslog-ng.pid"
SYSLOGNG="/usr/sbin/syslog-ng"
NAME="syslog-ng"
PATH=/sbin:/bin:/usr/sbin:/usr/bin
test -f $SYSLOGNG || exit 0
# Define LSB log_* functions.
# Depend on lsb-base (>= 3.0-6) to ensure that this file is present.
. /lib/lsb/init-functions
case "x$CONSOLE_LOG_LEVEL" in
x[1-8])
dmesg -n $CONSOLE_LOG_LEVEL
;;
x)
;;
*)
log_warning_msg "CONSOLE_LOG_LEVEL is of unaccepted value."
;;
esac
create_xconsole() {
XCONSOLE=/dev/xconsole
if [ "$(uname -s)" = "GNU/kFreeBSD" ]; then
XCONSOLE=/var/run/xconsole
ln -sf $XCONSOLE /dev/xconsole
fi
if [ ! -e $XCONSOLE ]; then
mknod -m 640 $XCONSOLE p
chown root:adm $XCONSOLE
[ -x /sbin/restorecon ] && /sbin/restorecon $XCONSOLE
fi
}
create_pidfiledir() {
if [ ! -d /var/run/syslog-ng ]
then
mkdir -p /var/run/syslog-ng
fi
}
syslogng_wait() {
if [ "$2" -ne 0 ]; then
return 1
fi
if [ -n "$DPKG_MAINTSCRIPT_PACKAGE" ]; then
return 0
fi
RET=1
for i in $(seq 1 30); do
status=0
syslog-ng-ctl stats >/dev/null 2>&1 || status=$?
if [ "$status" != "$1" ]; then
RET=0
break
fi
sleep 1s
done
return $RET
}
syslogng_start() {
log_daemon_msg "Starting system logging" "$NAME"
create_pidfiledir
create_xconsole
start-stop-daemon --start --oknodo --quiet --exec "$SYSLOGNG" \
--pidfile "$PIDFILE" -- -p "$PIDFILE" $SYSLOGNG_OPTS
syslogng_wait 1 $?
RET="$?"
log_end_msg $RET
return $RET
}
syslogng_stop() {
log_daemon_msg "Stopping system logging" "$NAME"
start-stop-daemon --stop --oknodo --quiet --name "$NAME" --retry 3 \
--pidfile "$PIDFILE"
syslogng_wait 0 $?
RET="$?"
log_end_msg $RET
return $RET
}
syslogng_reload() {
log_daemon_msg "Reload system logging" "$NAME"
if $SYSLOGNG -s $SYSLOGNG_OPTS
then
start-stop-daemon --stop --signal 1 --quiet --exec "$SYSLOGNG" \
--pidfile "$PIDFILE"
syslogng_wait 1 $?
RET="$?"
log_end_msg $RET
return $RET
else
log_end_msg 1
return 1
fi
}
case "$1" in
start)
syslogng_start || exit 1
;;
stop)
syslogng_stop || exit 1
;;
reload|force-reload)
syslogng_reload || exit 1
;;
restart)
syslogng_stop
syslogng_start || exit 1
;;
status)
status_of_proc "$SYSLOGNG" "$NAME" && exit 0 || exit $?
;;
*)
echo "Usage: /etc/init.d/$NAME {start|stop|restart|reload|force-reload|status}" >&2
exit 1
;;
esac
exit 0Даем ему права и делаем unmask
chmod +x /etc/init.d/syslog-ng && systemctl unmask syslog-ng
Устанавливаем elasticsearch из пакета deb.
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.3.deb
dpkg -i elasticsearch-5.6.3.debЕще небольшие манипуляции. Создадим каталог для данных и сделаем автозапуска elasticsearch после рестарта системы.
mkdir /elasticsearchdata/ && chown -R elasticsearch:elasticsearch /elasticsearchdata/
update-rc.d elasticsearch defaults 95 10
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable elasticsearch.serviceНастроим elasticsearch на макимальное использование памяти. Для этого elasticsearch.service приводим к такому виду.
nano /usr/lib/systemd/system/elasticsearch.service[Unit]
Description=Elasticsearch
Documentation=http://www.elastic.co
Wants=network-online.target
After=network-online.target
[Service]
Environment=ES_HOME=/usr/share/elasticsearch
Environment=CONF_DIR=/etc/elasticsearch
Environment=DATA_DIR=/var/lib/elasticsearch
Environment=LOG_DIR=/var/log/elasticsearch
Environment=PID_DIR=/var/run/elasticsearch
EnvironmentFile=-/etc/default/elasticsearch
LimitMEMLOCK=infinity
WorkingDirectory=/usr/share/elasticsearch
User=elasticsearch
Group=elasticsearch
ExecStartPre=/usr/share/elasticsearch/bin/elasticsearch-systemd-pre-exec
ExecStart=/usr/share/elasticsearch/bin/elasticsearch \
-p ${PID_DIR}/elasticsearch.pid \
--quiet \
-Edefault.path.logs=${LOG_DIR} \
-Edefault.path.data=${DATA_DIR} \
-Edefault.path.conf=${CONF_DIR}
# StandardOutput is configured to redirect to journalctl since
# some error messages may be logged in standard output before
# elasticsearch logging system is initialized. Elasticsearch
# stores its logs in /var/log/elasticsearch and does not use
# journalctl by default. If you also want to enable journalctl
# logging, you can simply remove the "quiet" option from ExecStart.
StandardOutput=journal
StandardError=inherit
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65536
# Specifies the maximum number of processes
LimitNPROC=2048
# Specifies the maximum size of virtual memory
LimitAS=infinity
# Specifies the maximum file size
LimitFSIZE=infinity
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop the Java process
KillSignal=SIGTERM
# Send the signal only to the JVM rather than its control group
KillMode=process
# Java process is never killed
SendSIGKILL=no
# When a JVM receives a SIGTERM signal it exits with code 143
SuccessExitStatus=143
[Install]
WantedBy=multi-user.target
# Built for distribution-5.6.3 (distribution)Релоадим systemctl после изменения
systemctl daemon-reloadОтредактируем файл /etc/elasticsearch/jvm.options
nano /etc/elasticsearch/jvm.optionsДаем половину озу — у меня 12 гигабайт на VM — в heap space поставил 6g, по рекомендациям разработчиков elasticsearch.
# Xms represents the initial size of total heap space
# Xmx represents the maximum size of total heap space
-Xms6g
-Xmx6gРедактируем конфиг elasticsearch на нашем головном сервере. Приводим к виду
nano /etc/elasticsearch/elasticsearch.ymlnetwork.host: 0.0.0.0
cluster.name: "production"
node.name: elasticnode1
discovery.zen.ping.unicast.hosts: ["elasticnode1", "elasticnode2", "elasticnode3","elasticnode4","elasticnode5","elasticnode6","elasticnode7","elasticnode8","elasticnode9"]
# avoid swapping the Elasticsearch
bootstrap.memory_lock: true
###Make node master - non data
node.master: true
node.data: false
# minimum_master_nodes need to be explicitly set when bound on a public IP
discovery.zen.minimum_master_nodes: 1
path.data: /elasticsearchdata/Здесь мы поменяли путь для данных, задали имя кластера, указали что он у нас является мастер нодой (управляет распределением данных в кластере), не является дата нодой (не хранит данные), указали список всех нод кластера, отключили swap для elasticsearch (bootstrap.memory_lock: true), указали минимальное количество мастер нод для нашего кластера — 1 (мы здесь не делаем HA).
Запускаем кластер elasticsearch, предварительно почистив старую дата директорию.
rm -rf /var/lib/elasticsearch/* && /etc/init.d/elasticsearch restartСмотрим здоровье кластера из консоли
curl -XGET 'http://elastinode1:9200/_cluster/state?pretty'
curl http://elastinode1:9200/_nodes/process?pretty
Настраиваем датаноды elasticsearch — elasticnode2–9
Правим файл /etc/hosts как указано выше
Устанавливаем elasticsearch (не забываем про /usr/lib/systemd/system/elasticsearch.service и /etc/elasticsearch/jvm.options) и тюнингуем систем аналогично мастеру. Важно — обязательно должны быть одинаковые версии elasticsearch на всех нодах.
Конфиг elasticsearch на датаноде.
nano /etc/elasticsearch/elasticsearch.ymlnetwork.host: 0.0.0.0
cluster.name: "production"
node.name: elasticnode2
discovery.zen.ping.unicast.hosts: ["elasticnode1", "elasticnode2", "elasticnode3", "elasticnode4", "elasticnode5", "elasticnode6", "elasticnode7", "elasticnode8", "elasticnode9"]
# avoid swapping the Elasticsearch
bootstrap.memory_lock: true
###Make node master - non data
node.master: false
node.data: true
# minimum_master_nodes need to be explicitly set when bound on a public IP
discovery.zen.minimum_master_nodes: 1
path.data: /elasticsearchdata/ Здесь конфиг аналогично мастеру — мы поменяли путь для данных, задали имя кластера, указали что он у нас является датанодой (хранит данные), указали список всех нод кластера, отключили swap для elasticsearch (bootstrap.memory_lock: true), указали минимальное количество мастернод для нашего кластера — 1.
Стартуем ноды, предварительно стерев /var/lib/elasticsearch/ иначе будет выдавать ошибку, так как мы поменяли путь хранения данных.
rm -rf /var/lib/elasticsearch/* && /etc/init.d/elasticsearch restartСразу определимся, как добавить новую датаноду и сделать ребалансировку кластера.
Просто добавляем новую ноду в конфиги на все ноды кластера в строку discovery.zen.ping.unicast.hosts, при этом рестарт elasticsearch в текущем кластере делать не надо.
Запускаем процесс ребалансировки на головном сервере с помощь запроса через командную строку
curl -XPUT http://elasticnode1:9200/_cluster/settings -d '{
"transient" : {
"cluster.routing.allocation.enable" : "all"
}
}'Так же сразу потюним еще одну вещь cluster.routing.allocation.disk.watermark.
curl -XPUT http://elasticnode1:9200/_cluster/settings -d '{
"transient": {
"cluster.routing.allocation.disk.watermark.low": "90%",
"cluster.routing.allocation.disk.watermark.high": "10gb",
"cluster.info.update.interval": "1m"
}
}'Здесь мы определяем минимальное доступное место для работы кластера, преодолев данный порог он перестанет работать — принимать данные.
Установка kibana и grafana на головной сервер.
Kibana и grafana можно спокойно запускать через docker-compose, что мы и сделаем ниже. В принципе всю систему можно поднять через docker-compose. Ниже я выложу ссылку на репозиторий где все можно поднять одной командой, что в принципе для небольших систем и для тестирования вполне приемлимо. Докер это наше всё.
Ставим докер и docker-compose на ubuntu 16.04
apt-get install \
apt-transport-https \
ca-certificates \
curl \
software-properties-common -y
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add -
add-apt-repository \
"deb [arch=amd64] https://download.docker.com/linux/ubuntu \
$(lsb_release -cs) \
stable"
apt-get update && apt-get install docker-ce -y
curl -L https://github.com/docker/compose/releases/download/1.18.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
Создаем файл docker-compose.yml с таким содержанием. Обратите внимание в enviroment kibana.local прописал
"ELASTICSEARCH_URL=http://elasticnode1:9200" - адрес нашего elasticsearchСодержимое docker-compose.yml
version: '3.3'
services:
kibana.local:
image: kibana:5.6.3
container_name: kibana.local
hostname: kibana.local
ports:
- "5601:5601"
networks:
- local-network
tty: true
privileged: true
restart: always
extra_hosts:
- "elasticnode1:10.10.10.210"
environment:
- "TZ=Asia/Yekaterinburg"
- "ELASTICSEARCH_URL=http://elasticnode1:9200"
grafana.local:
image: grafana/grafana
container_name: grafana.local
hostname: grafana.local
volumes:
- ./configs/grafana/:/etc/grafana/
- ./data/grafana/:/var/lib/grafana/
- ./data/grafana/:/var/log/grafana/
ports:
- "13000:3000"
networks:
- local-network
tty: true
privileged: true
restart: always
environment:
- "TZ=Asia/Yekaterinburg"
- "GF_INSTALL_PLUGINS=grafana-clock-panel,grafana-simple-json-datasource,vonage-status-panel,grafana-piechart-panel,grafana-worldmap-panel"
networks:
local-network:
driver: bridge
Запускаем docker-compose
docker-compose up -dВ grafana по-умолчанию пользователь и пароль admin admin.
Заходим в kibana — видим что все ок.
Идем далее.
Настройка приема системных логов syslog-ng, их обработки и отправки в kibana.
Скачаем сразу базу данных geoip2 maxmind для построения в дальнейшем geoip карты. Анализатор (парсер) geoip2 syslog-ng 2 использует библиотеку maxminddb для поиска географической информации. По заверениям разработчиков он значительно быстрее, чем его предшественник, а также предоставляет более подробную информацию.
Скачаем и распакуем.
cd /usr/local/etc
wget http://geolite.maxmind.com/download/geoip/database/GeoLite2-City.mmdb.gz
gunzip GeoLite2-City.mmdb.gzСразу проверим на примере.
mmdblookup --file GeoLite2-City.mmdb --ip 1.2.3.4
Вывод
{
"city":
{
"geoname_id":
3054643
"names":
{
"de":
"Budapest"
"en":
"Budapest"
"es":
"Budapest"
"fr":
"Budapest"
"ja":
"ブダペスト"
"pt-BR":
"Budapeste"
"ru":
"Будапешт"
"zh-CN":
"布达佩斯"
}
}
[...]
"location":
{
"accuracy_radius":
100
"latitude":
47.500000
"longitude":
19.083300
"time_zone":
"Europe/Budapest"
}
[...] Окей. Идем далее.
Создадим симлинк каталога в который мы установили syslog-ng в /etc/syslog-ng — так удобнее, для тех кто привык к стандартному расположений syslog-ng.
ln -s /usr/local/etc /etc/syslog-ngОтредактируем главный конфиг — приведем к такому виду:
nano /usr/local/etc/syslog-ng.conf@version: 3.13
@include "scl.conf"
@module mod-java
# Настраиваем глобальные параметры
options {
chain_hostnames(off);
log_fifo_size(1000000);
use_dns(no);
use_fqdn(no);
owner("root");
group("adm");
perm(0640);
stats_freq(0);
bad_hostname("^gconfd$");
};
@include "/usr/local/etc/conf.d/*.conf"Создадим каталог в котором мы будем инклудить все конфиги для удобства.
mkdir -p /usr/local/etc/conf.dТеперь вставим конфиги по приему системных логов с других машин и отправку их в elasticsearch c разбиением по индексам.
nano /usr/local/etc/conf.d/input.conf###Принимаем логи на порт по udp 514
source udp-remote-system-logs {
udp(port(514)
log_iw_size(1000)
log_fetch_limit(1000000));};
########################
# Блок с фильтрами
########################
filter f_dbg { level(debug); };
filter f_info { level(info); };
filter f_notice { level(notice); };
filter f_warn { level(warn); };
filter f_err { level(err); };
filter f_crit { level(crit .. emerg); };
filter f_debug { level(debug) and not facility(auth, authpriv, news, mail); };
filter f_error { level(err .. emerg) ; };
filter f_messages { level(info,notice,warn) and
not facility(auth,authpriv,cron,daemon,mail,news); };
filter f_auth { facility(auth, authpriv) and not filter(f_debug); };
filter f_cron { facility(cron) and not filter(f_debug); };
filter f_daemon { facility(daemon) and not filter(f_debug); };
filter f_kern { facility(kern) and not filter(f_debug); };
filter f_lpr { facility(lpr) and not filter(f_debug); };
filter f_local { facility(local0, local1, local3, local4, local5,
local6, local7) and not filter(f_debug); };
filter f_mail { facility(mail) and not filter(f_debug); };
filter f_news { facility(news) and not filter(f_debug); };
filter f_syslog3 { not facility(auth, authpriv, mail) and not filter(f_debug); };
filter f_user { facility(user) and not filter(f_debug); };
filter f_uucp { facility(uucp) and not filter(f_debug); };
filter f_cnews { level(notice, err, crit) and facility(news); };
filter f_cother { level(debug, info, notice, warn) or facility(daemon, mail); };
filter f_ppp { facility(local2) and not filter(f_debug); };
filter f_console { level(warn .. emerg); };
###Куда будем писать логи - в данном случае в elasticsearch
###Каждому типу лога сделаем свой отдельный индекс с добавление года и месяца создания, чтобы потом можно было легко их найти
########################
# auth logs
########################
destination d_elastic_auth {
elasticsearch2(
index("auth-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs);filter(f_auth); destination(d_elastic_auth); };
########################
# crons logs
########################
destination d_elastic_crons {
elasticsearch2(
index("crons-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs); filter(f_cron); destination(d_elastic_crons); };
########################
# kern logs
########################
destination d_elastic_kern {
elasticsearch2(
index("kern-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs ); filter(f_kern); destination(d_elastic_kern); };
########################
# daemon logs
########################
destination d_elastic_daemon {
elasticsearch2(
index("daemon-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs); filter(f_daemon); destination(d_elastic_daemon); };
########################
# user logs
########################
destination d_elastic_user {
elasticsearch2(
index("user-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs); filter(f_user); destination(d_elastic_user); };
########################
# lpr logs
########################
destination d_elastic_lpr {
elasticsearch2(
index("lpr-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs); filter(f_lpr); destination(d_elastic_lpr); };
########################
# syslog logs
########################
destination d_elastic_syslog {
elasticsearch2(
index("syslog-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs); filter(f_syslog3);destination(d_elastic_syslog); };
########################
# uucp logs
########################
destination d_elastic_uucp {
elasticsearch2(
index("uucp-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs); filter(f_uucp); destination(d_elastic_uucp); };
########################
# mail logs
########################
destination d_elastic_mail {
elasticsearch2(
index("mail-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs); filter(f_mail);destination(d_elastic_mail); };
########################
# messages logs
########################
destination d_elastic_messages {
elasticsearch2(
index("messages-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs); filter(f_messages); destination(d_elastic_messages); };
########################
# debug logs
########################
destination d_elastic_debug {
elasticsearch2(
index("debug-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs); filter(f_debug); destination(d_elastic_debug); };
########################
# error logs
########################
destination d_elastic_error {
elasticsearch2(
index("error-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs); filter(f_error);destination(d_elastic_error); };
########################
# info logs
########################
destination d_elastic_info {
elasticsearch2(
index("info-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log { source(udp-remote-system-logs); filter(f_info); destination(d_elastic_info); };
Конфиги syslog-ng легко читаемы и понятны с первого раза. Не устану это повторять.
Теперь создадим конфиг для приема других логов — nginx access и error (php errors логи так же будем слать в error.log), nodejs.
nano /usr/local/etc/conf.d/input-web.conf#формат логов nginx, который будем принимать, здесь я его разместил для наглядности сопоставления с парсером этих логов, в качестве разделителей полей используем символ "|"
#log_format full_format '"$time_iso8601"|"$http_host"|"$remote_addr"|"$http_x_forwarded_for"|"$request_method"|"$request"|"$status"|"$body_bytes_sent"|"$http_referer"|"$request_time"|"$upstream_http_x_cache"|"$uri"|"$upstream_addr"|"$host"|"$upstream_response_length"|"$upstream_status"|"$server_name"|"$http_host"|"$upstream_response_time"|"$upstream_cache_status"|"$http_user_agent"|"$scheme://$host$request_uri"|"$cookie_bar"';
#access_log /var/log/nginx/access.log full_format;
#error_log /var/log/nginx/error.log;
#Докер со сборкой nginx + libressl + syslog-ng + nodejs можно найти здесь - https://github.com/galushkoav/nginx-php-nodejs
##Принмаем nginx access логи на порт 25230 по udp
source udp-nginx-acessfull {
udp(port(25230)
log_iw_size(1000)
log_fetch_limit(1000000)) ;
};
###Парсим принятые логи nginx, здесь мы указываем имена полей, куда будут попадать данные, укажем также разделитель полей символ "|"
parser p-nginx-acessfull-mapped {
csv-parser(columns("nginx.time", "nginx.http_host", "nginx.remote_addr", "nginx.http_x_forwarded_for", "nginx.request", "nginx.request_method","nginx.status", "nginx.body_bytes_sent", "nginx.http_referer", "nginx.request_time", "nginx.upstream_http_x_cache", "nginx.uri", "nginx.upstream_addr", "nginx.host", "nginx.upstream_response_length", "nginx.upstream_status", "nginx.server_name", "nginx.newurl", "nginx.upstream_response_time", "nginx.upstream_cache_status", "nginx.user_agent","nginx.request_uri","nginx.http_cookie" )
flags(escape-double-char,strip-whitespace)
delimiters("|")
quote-pairs('""[]')
);
};
###Здесь мы сверяем прилетающий ip из логов nginx - в поле "nginx.remote_addr" с нашей базой данных maxmidn geoip2
parser p_geoip2 { geoip2( "${nginx.remote_addr}", prefix( "geoip2." ) database( "/usr/local/etc/GEO/GeoLite2-City_20171205/GeoLite2-City.mmdb" ) ); };
##Rewrite необходим для того, чтобы информация о местоположении находилась в форме, ожидаемой Elasticsearch. Он выглядит несколько более сложным, чем для первой версии анализатора GeoIP, поскольку имеется больше информации и информация теперь структурирована.
rewrite r_geoip2 {
set(
"${geoip2.location.latitude},${geoip2.location.longitude}",
value( "geoip2.location2" ),
condition(not "${geoip2.location.latitude}" == "")
);
};
###Направляем nginx_access в elasticsearch - затем добавим индекс в кибана nginx-access-geo-*
destination d_elastic-nginx-acessfull {
elasticsearch2(
index("nginx-access-geo-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
type("netdata")
persist-name(elasticsearch-netdata)
);
};
log {source (udp-nginx-acessfull);
parser(p-nginx-acessfull-mapped);
rewrite(r_geoip2);
parser(p_geoip2);
destination(d_elastic-nginx-acessfull);};
##Принимаем nginx error логи на порт 25231 по udp
source udp-nginx-error {
udp(port(25231)
log_iw_size(1000)
log_fetch_limit(1000000));
};
destination d_elastic-nginxerror {
elasticsearch2(
index("nginxerror-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
###########фильтры - исключим unlink
filter f_tail_nginx_error_unlink {not match ("unlink") ;};
log {source(udp-nginx-error); filter(f_tail_nginx_error_unlink); destination(d_elastic-nginxerror); };Сохраняемся.
Поясню, какого вида имя index будет создаются в elasticsearch — формат имени будет иметь вид «базовоеимяиндекса-год.месяц», например nginx-access-geo-2018.01. В принципе здесь всё понятно, так как добавляется год и месяц после индекса — nginx-access-geo-${YEAR}.${MONTH}.
Подготовливаем индекс elasticsearch для примема логов nginx access — сделаем mapping для нашего первого индека nginx-access-geo-2018.01:
- поля nginx.upstream_response_time и nginx.request_time типом float вместо string, для возможности нахождения среднего значения по времени ответа сервера и ответа upstreams;
- создадим mapping в elasticsearch для geoip, чтобы можно было строить карту с помощью геолокации.
Важно. Всё это делает для индекса nginx-access-geo-2018.01(у нас так настроен формат в syslog-ng), т.е. после окончания месяца необходимо заново выполнить этот запрос, только вместо nginx-access-geo-2018.01 сделать nginx-access-geo-2018.02 и т.д.
Все эти манипуляции необходимо проделать до начала отправки логов в elasticsearch.
curl -X PUT 'http://elasticnode1:9200/nginx-access-geo-2018.01' -d \
'{
"mappings" : {
"_default_" : {
"properties" : {
"nginx" : {
"properties" : {
"request_time": {
"type": "float"
},
"upstream_response_time": {
"type": "float"
}
}
},
"geoip2" : {
"properties" : {
"location2" : {
"type" : "geo_point"
},
"geoip2.subdivisions.0.names.en" : {
"type": "text",
"fielddata": true
},
"geoip2.registered_country.names.en" : {
"type": "text",
"fielddata": true
}
}
}
}
}
}
}
}
}'Увидим в выводе что всё ок.
Смотрим наш индекс.
curl -X GET 'http://elasticnode1:9200/nginx-access-geo-2018.01'Увидели что все что нужно создано.
Проверяем syslog-ng, запускаем с выводом в консоль
syslog-ng -Fvde Если ошибок нет — стартуем как демон
/etc/init.d/syslog-ng startПосле определенного времени — когда к нам упадут логи заходим в elasticsearch и создаем наш индекс.
Сбор и отправка логов pm2 c помощью syslog-ng.
Pm2 должен быть запущен со следующими опциями.
--merge-logs --log-type=json --log-date-format="YYYY-MM-DD HH:mm Z"Создадим конфиг отправки на клиенте или допишем в существующий. Будем отсылать на отдельный порт.
####Источник с логами nodejs
destination d_server_pm2logs {
udp("elasticnode1" port(25216));
};
source s_tail_pm2 { file( "/root/.pm2/logs/server-error.log"
follow_freq(1)
flags(no-parse)
);
};
###Отправляем все источники на сервер - там их будем парсить и писать в нужные базы.
log {source(s_tail_pm2); destination(d_server_pm2logs);}На сервере создаем конфиг на принятие данного лога и его отправку в elasticsearch.
##Прием логов nodejs с удаленных машин на порт
source remote_log_host_nodejs {
udp(port(25216) log_iw_size(1000) log_fetch_limit(1000000) flags(no-parse));
};
###Направляем nodejs логи в elasticsearch
destination d_elastic_pm2logs {
elasticsearch2(
#client-lib-dir("/usr/share/elasticsearch/lib/")
index("pm2logs-${YEAR}.${MONTH}")
type("test")
time-zone("UTC")
client_mode("http")
flush-limit("10000")
cluster_url("http://elasticnode1:9200")
custom_id("${UNIQID}")
template("$(format_json --scope nv_pairs --key ISODATE @timestamp=${ISODATE})")
);
};
log {
source(remote_log_host_nodejs);
destination(d_elastic_pm2logs);
};
Перезапускаем syslog-ng на сервере и клиенте и добавляем индекс в kibana.
На этом настройка syslog-ng закончена.
Поиск логов в kibana и построение визуализаций.
Перейдем в наш индекс и сразу для проверки наших настроек попробуем найти все ответы сервера nginx, c временем ответа больше 2 секунд, для этого в поле делаем запрос nginx.request_time: [2 TO *].
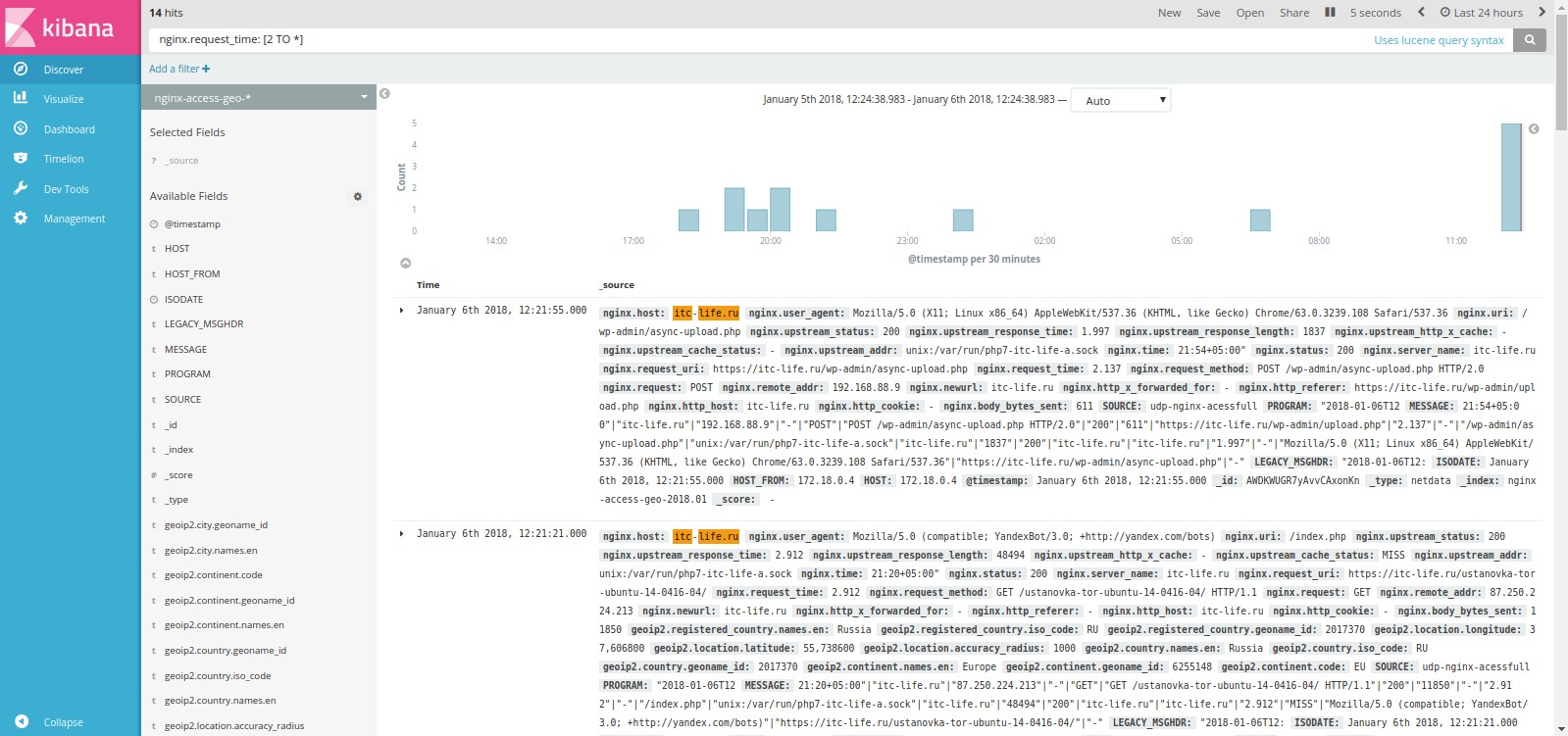
Сверху выбираем период за который мы хотим получить события и частоту обновления данных. В данном случаем мы выбраои период 24 часа с частотой обновления данных 30 секунд.
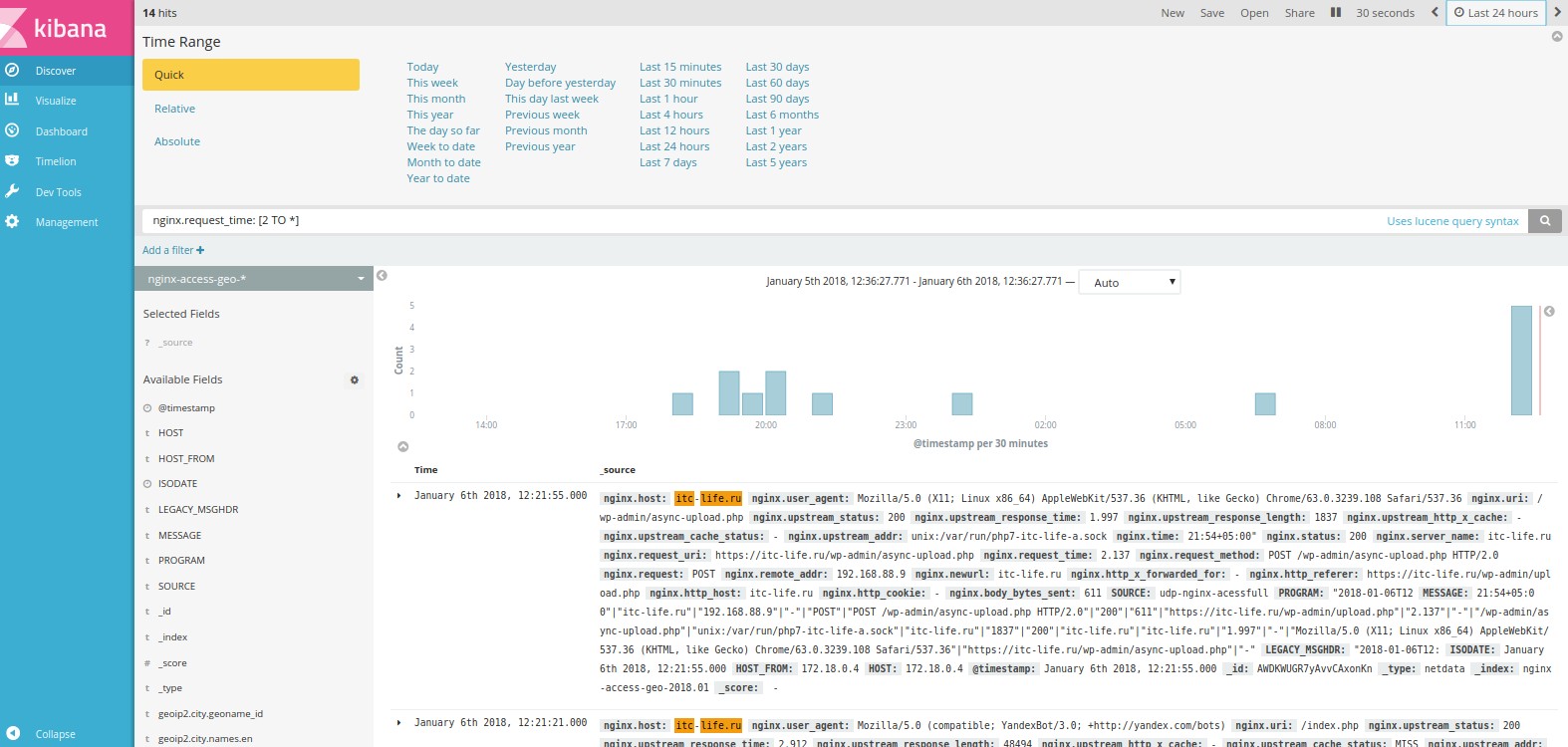
Как мы видим на выдало 14 событий (hits).
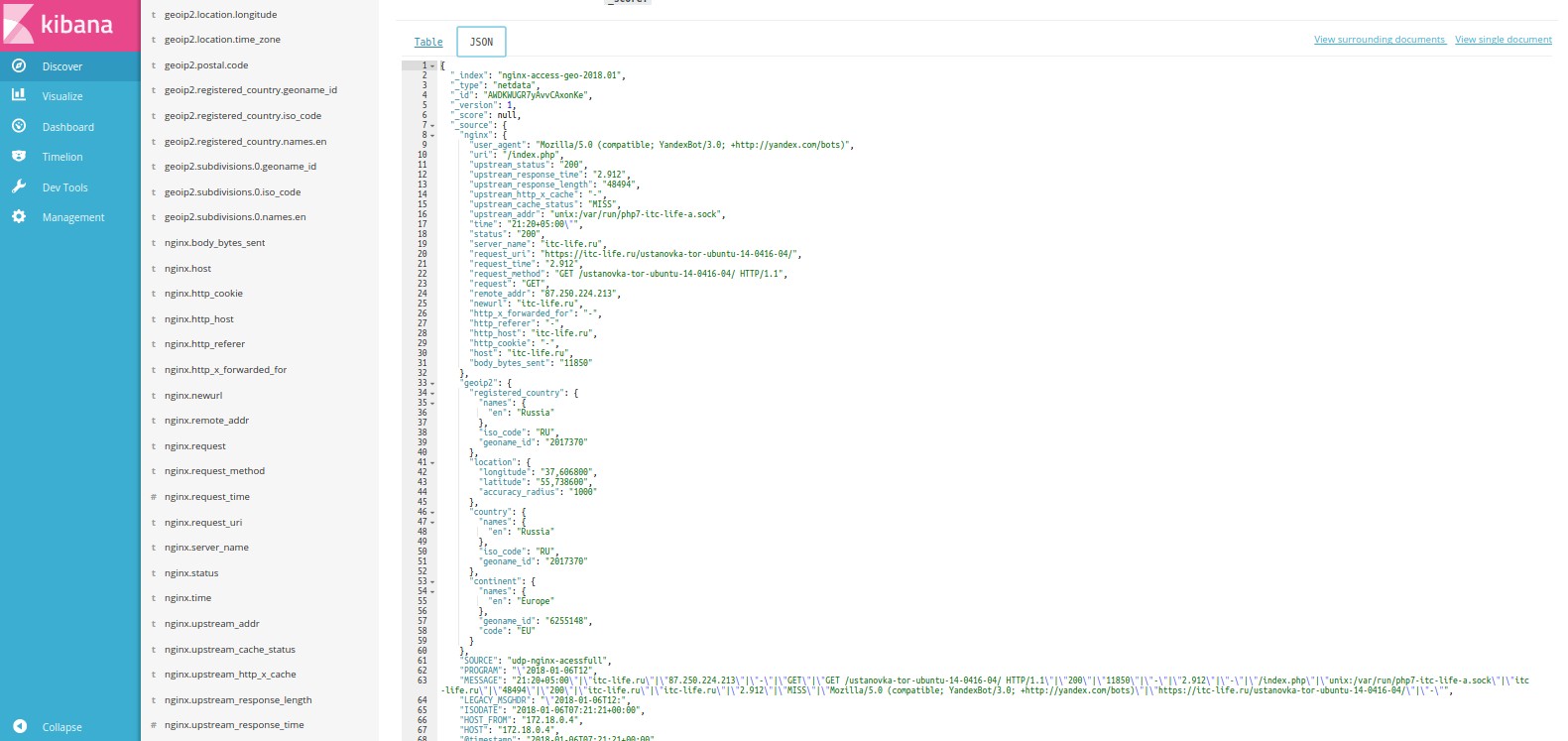
Рассмотрим какие поля у нас доступны в нашем индексе. Раскрываем событие и выбираем там json представление.
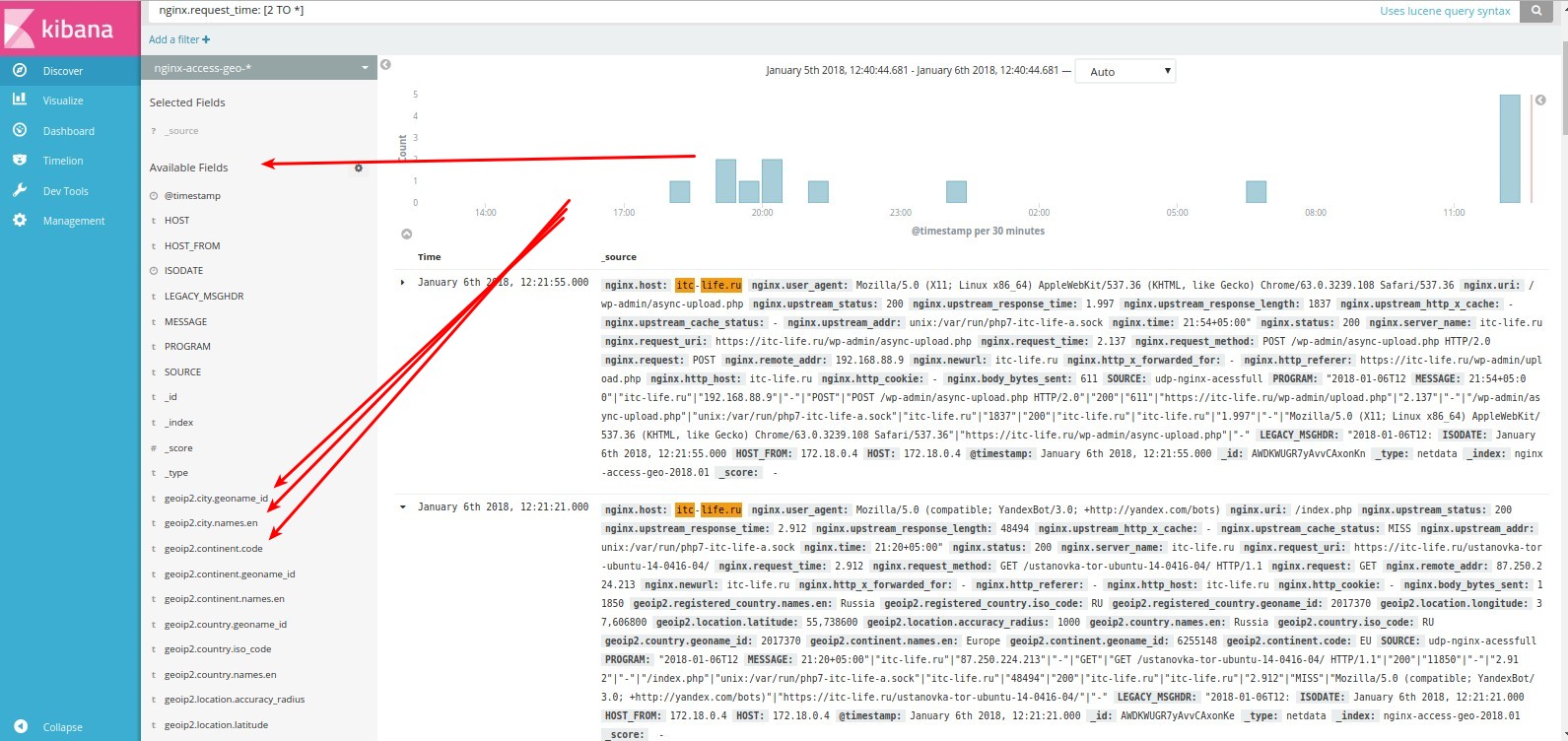
Так же поля доступны слева на панели
Теперь добавим другие наши индексы, которые мы указали в конфиге (если в них уже есть данные). Проверяем индексы командой:
curl 'http://elasticnode1:9200/_cat/indices?v'У меня получился примерно такой вывод:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open nginxerror-2018.01.03 jQVq1YWrSayxJ-zAeOeNKA 5 1 24 0 165.1kb 165.1kb
yellow open nginxerror-2018.01.05 dJ0D2ronQWiGcCjj_jVNHg 5 1 96 0 183.9kb 183.9kb
yellow open kern-2018.01 URAOk3_GRX6MMZfW8hLPbA 5 1 4196 0 1.5mb 1.5mb
yellow open messages-2018.01 DiU8IEV2RseZ2mQNx2CJxA 5 1 4332 0 1.5mb 1.5mb
yellow open syslog-2018.01 de2SOs8KRBGNkfd1ja4Mmg 5 1 38783 0 26.1mb 26.1mb
yellow open .kibana jLUuELr-TRGSVr5JzPX52w 1 1 5 0 44.6kb 44.6kb
yellow open error-2018.01 cnD8VeGkQa2n8HRTnC74SQ 5 1 671 0 438.6kb 438.6kb
yellow open nginxerror-2018.01.06 z1eT1JC1QLC0AqyIQoj9ng 5 1 47 0 214.6kb 214.6kb
yellow open nginx-access-geo 41WmT6BARUiQNjuahFhe1g 5 1 8583 0 14mb 14mb
yellow open syslog-ng hE37Hu2JRd-lyJaq7nDh-A 5 1 52 0 197.2kb 197.2kb
yellow open nginx-access-geo-2018.01 MfinD9z7SB-vIMRZcXJevw 5 1 2676 0 6mb 6mb
yellow open debug-2018.01 SwxEA6sSQjGSMBm6FcyAww 5 1 507 0 362.3kb 362.3kb
yellow open crons-2018.01 MOJetHGjQs-Gd3Vmg5kxHw 5 1 111 0 149.7kb 149.7kb
yellow open user-2018.01 zbRxNpGsShWwz43LXjPaAw 5 1 571 0 392kb 392kb
yellow open auth-2018.01 shHvBE8GSdCi2CIjTxNovg 5 1 468 0 370.8kb 370.8kb
yellow open daemon-2018.01 p97FQLBHTbyy-sM23oJpWQ 5 1 33754 0 25.1mb 25.1mb
yellow open nginxerror-2018.01.04 dJ-bnpNIQ328iudAVTg43A 5 1 109 0 170.5kb 170.5kb
yellow open info-2018.01 bQp1i6YwQoGOvv1aJCjudA 5 1 36267 0 26.7mb 26.7mbДобавляем индекс auth-*, в нем все события с авторизацией, sudo и др.
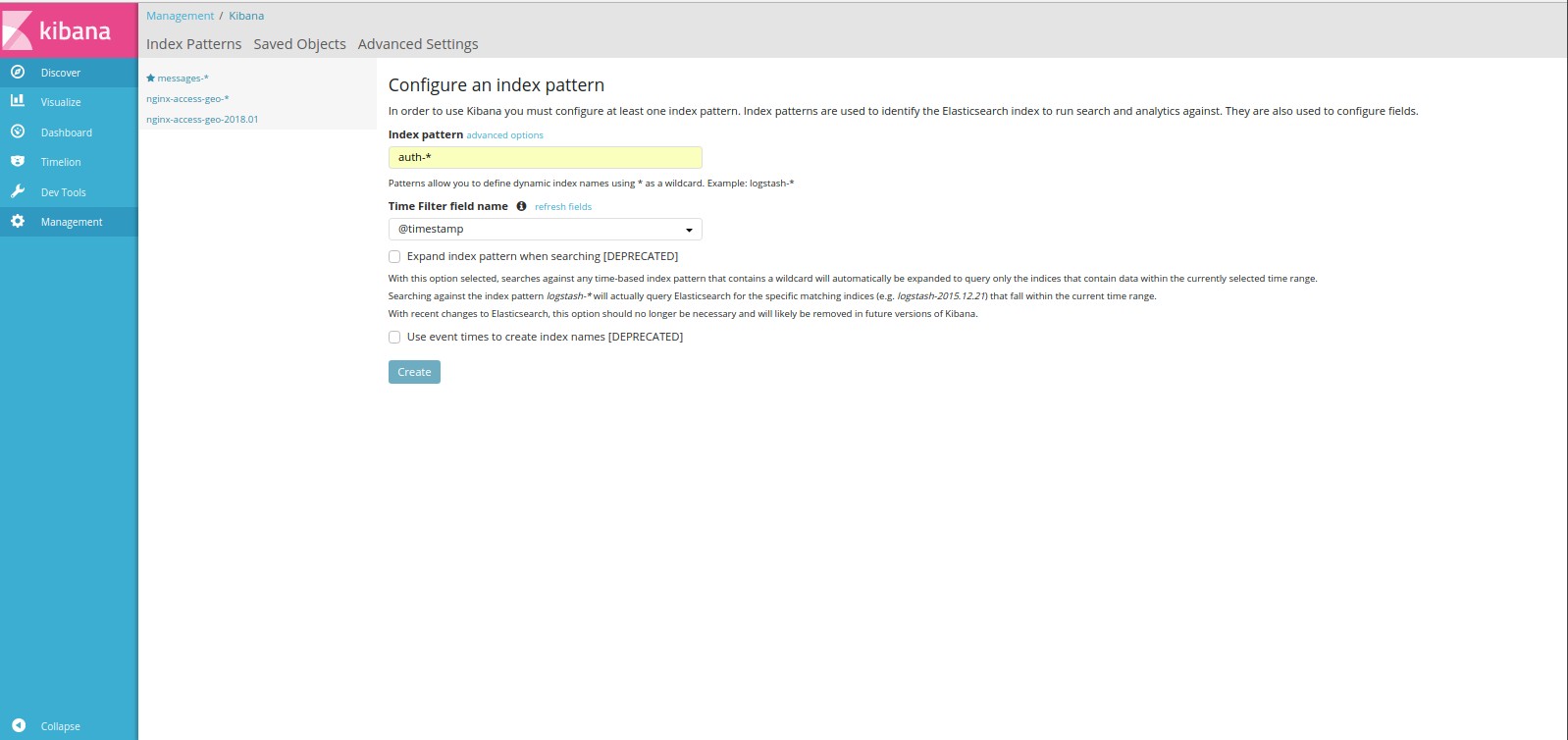
Перейдем к поиску и увидим события, связанные с авторизацией.
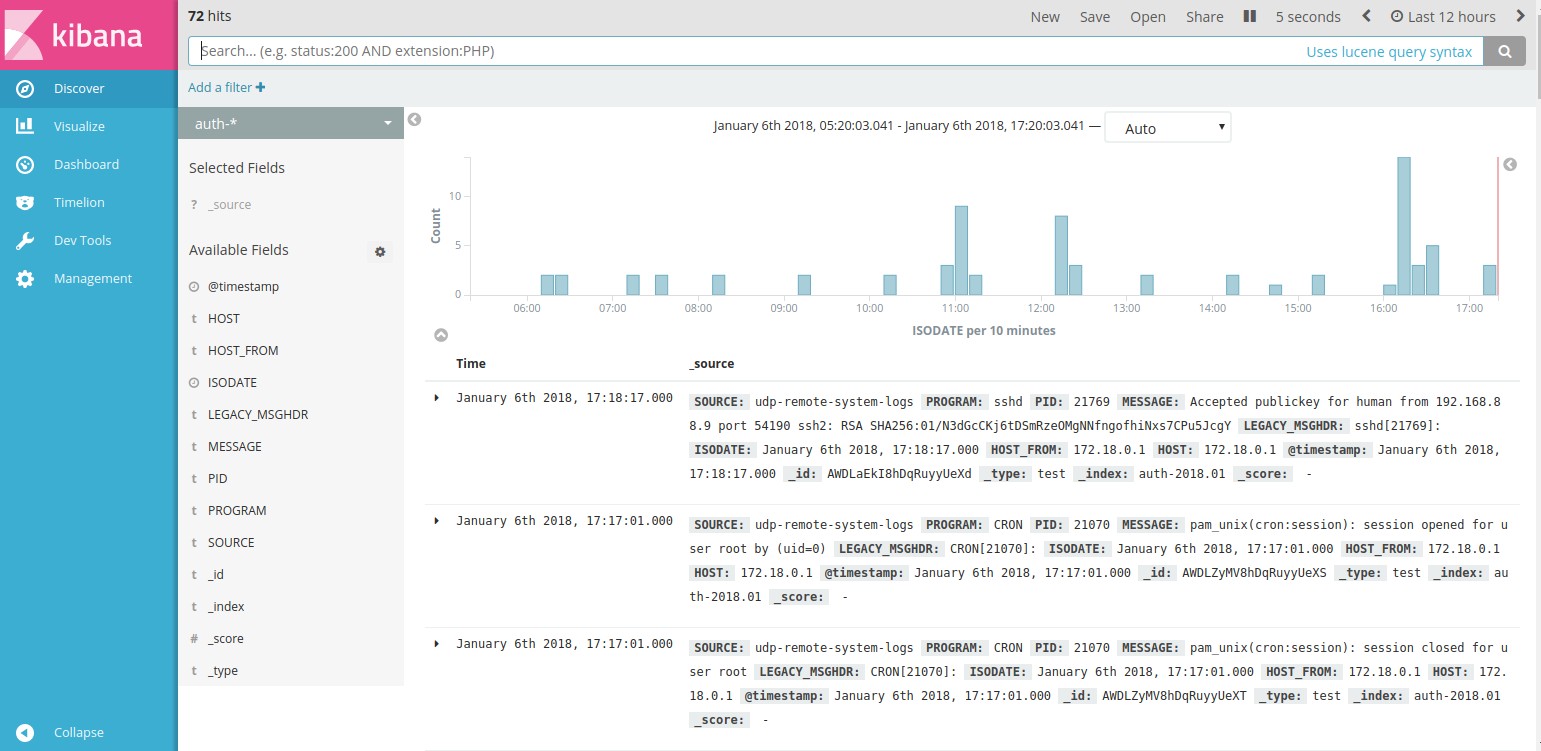
Таким же образом добавим другие индексы.
Настройки визуализации в ki
