Система отложенного исполнения на RabbitMQ

Всем привет!
Меня зовут Никита, и я курирую разработку нескольких проектов в ДомКлик. Сегодня я хочу продолжить тему «веселых картинок» в мире RabbitMQ. В своей статье Алексей Казаков рассматривал такой мощный инструмент, как отложенные очереди, и разные реализации стратегии Retry. А сегодня мы поговорим, как использовать RabbitMQ для планирования периодических задач.
Зачем нам понадобилось создавать свой велосипед и почему мы отказались от Сelery и других инструментов менеджмента задач? Дело в том, что они не подошли под наши задачи и требования к отказоустойчивости, которые у нас в компании достаточно жесткие.
При переходе на Docker и Kubernetes многие разработчики сталкиваются с проблемами организации периодических задач, кроны запускаются с бубном, да и контроль процесса оставляет желать лучшего. А еще есть проблемы с пиковой нагрузкой в дневное время.
Передо мной стояла задача реализовать в проекте надежную систему обработки периодических задач, при этом легко масштабируемую и отказоустойчивую. Наш проект на Python, поэтому логично было посмотреть, насколько нам подходит Celery. Это хороший инструмент, но с ним мы часто сталкивались с проблемами надежности, масштабирования и организации бесшовных релизов. Одна пода — одна группа процессов. При масштабировании Celery приходится увеличивать ресурсы одной поды, потому что нет синхронизации между подами, а это означает остановку обработки задач, хоть и временную. А если задачи еще и длительного выполнения, то вы уже догадались, насколько сложно этим управлять. Второй очевидный недостаток: из коробки нет поддержки асинхронности, а для нас это важно, потому что задачи в основном содержат операции ввода-вывода, а Celery работает на тредах.
На тот момент (2018 год) мы не нашли подходящего готового инструмента, и начали разрабатывать свой. Взяв за основу функциональность отложенного выполнения задач и Dead Letter Exchange, мы решили создать систему обработки периодических задач. Концепт выглядел как-то так:
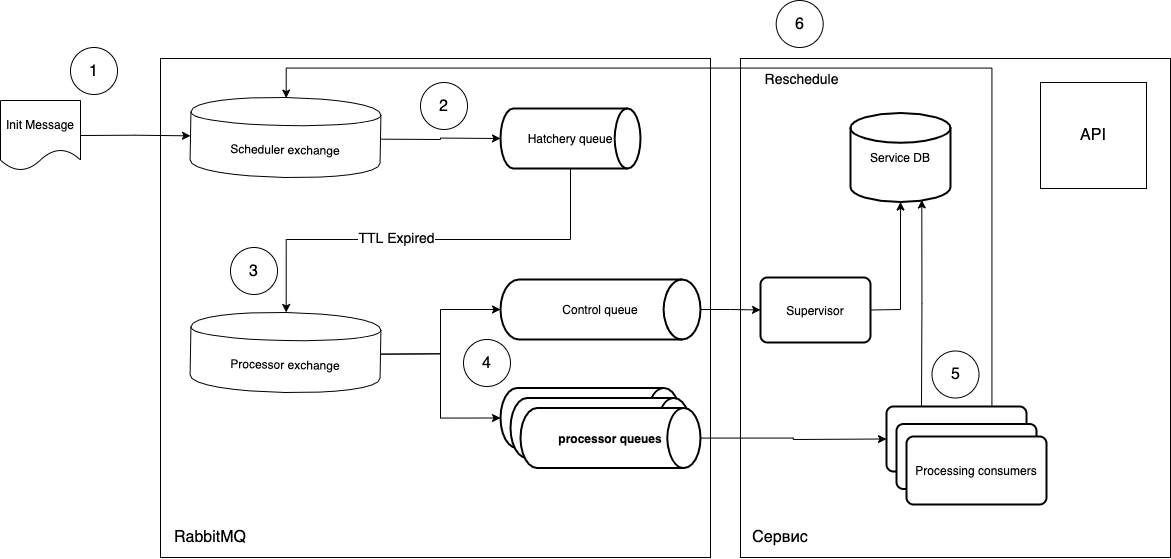
Попробую объяснить, что к чему.
- Задачи в виде сообщения попадают в коммутатор планировщика (Scheduler exchange).
- По
routing_keyпопадают в нужную очередь «вызревания» (Hatchery queue), которая имеет параметрmessage_ttl, а также связь с коммутатором исполнения (Processor exchange) в качестве deal letter exchange. Очередь «вызревания» не связана с типом задач, она только играет роль «таймера», то есть вы можете создать столько очередей, сколько периодов вам требуется, и управлять черезrouting_key. - Так как у очереди нет слушателей, сообщения после «вызревания» в очереди попадают в коммутатор исполнения (Processor exchange).
- Дальше свободный потребитель (Processing consumer) забирает сообщение и исполняет. После исполнения цикл при необходимости повторяется.
В чем же преимущество такой схемы?
- Поэтапность исполнения, то есть новая задача не поступит в обработку, если предыдущая не завершилась.
- Единый слушатель (consumer), то есть можно делать как универсальные воркеры, так специализированные. Масштабируется простым повышением количества нужных под.
- Деплой новых задач без нарушения работы текущих. Достаточно мягко обновить поды-слушатели и отправить в очередь соответствующее сообщение. То есть можно поднимать поды с новым кодом, которые займутся новыми сообщениями, а текущие процессы будут доживать в старых подах. Так мы получаем бесшовное обновление.
- Можно использовать асинхронный код и любую инфраструктуру, при этом независимы от стека.
- Можно контролировать исполнение задач на уровне нативного
ack/reject, а также получаем дополнительную опциональную очередь (control queue), которая может отслеживать жизненный цикл задач.
Схема получилась на деле достаточно простой, мы быстро создали рабочий прототип. И код получился красивым. Достаточно callback-функцию пометить простым декоратором, контролирующим жизненный цикл сообщения.
def rmq_scheduler(routing_key_for_delay_queue, routing_key_for_processing_queue):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
log_error(e)
redelivered_count = get_count_of_redelivery_attempts(properties)
if redelivered_count <= 3:
await resend_msg(
channel=channel,
body=body,
properties=properties,
routing_key=routing_key_for_processing_queue)
else:
async with app.natalya_db_engine.acquire() as conn:
async with conn.begin():
await channel.publish(
payload=body,
exchange_name='',
routing_key=routing_key_for_delay_queue,
)
await channel.basic_client_ack(envelope.delivery_tag)
return wrapper
return decorator
Сейчас мы используем эту схему для выполнения только периодических последовательных задач, но ее можно использовать и тогда, когда важно начать выполнять задачу в определенной время, без смещения времени на само исполнение. Для этого достаточно повторно запланировать задачу после попадания сообщения в supervisor.
Правда, у этого подхода есть дополнительные накладные расходы. Нужно понимать, что в случае ошибки сообщение вернется в очередь, его подхватит другой воркер и сразу начнет выполнять. Потому нужно разделять обработку ошибок по степени критичности и заранее продумывать, что делать с сообщением при той или иной ошибке.
Возможные варианты:
- Ошибка исправится сама (например, это системная ошибка): отправляем
noackи повторяем обработку ошибок. - Ошибка бизнес логики: нужно прервать цикл — отправляем
ack. - Ошибка из пункта 1 повторяется слишком часто: отравляем
rejectи сигнализируем разработчикам. Тут возможны варианты. Можно создать deal letter-очередь для отстоя сообщений, чтобы после разбора вернуть сообщение, или же применить технику ретраев (указатьmessage_ttl).
Пример декоратора:
def auto_ack_or_nack(log_message):
def decorator(func):
@wraps(func)
async def wrapper(channel, body, envelope, properties):
try:
res = await func(channel, body, envelope, properties)
await channel.basic_client_ack(envelope.delivery_tag)
return res
except Exception as e:
await channel.basic_client_nack(envelope.delivery_tag, requeue=False)
log_error(log_message, exception=e)
return wrapper
return decorator
Эта схема у нас работает уже полгода, она достаточно надёжна и практически не требует внимания. Падение приложения не нарушает работу планировщика и всего лишь немного задерживает выполнение задач.
Плюсов не бывает без минусов. У этой схемы есть и критическая уязвимость. Если с RabbitMQ что-то случилось и сообщения пропали, тогда нужно вручную смотреть, что потерялось, и запускать цикл снова. Но это исключительно маловероятная ситуация, при которой думать об этом сервисе придется в последнюю очередь :)
P.S. Если тема планирования периодических задач вам покажется интересной, то в следующей статье, я подробнее расскажу, как у нас устроена автоматизация создания очередей, а также про Supervisor.
Ссылки:
