Широкомасштабное эталонное тестирование OpenStack: Как мы тестировали Mirantis OpenStack в SoftLayer
Автор: Олег ГельбухПохоже, одним из главных вопросов, волнующих тех, кто вовлечен в индустрию облачных вычислений, стал вопрос о готовности OpenStack к эксплуатации на уровне предприятия при пиковой нагрузке. Среди распространенных тем разговоров — стабильность и производительность облачных сервисов на базе OpenStack в масштабе. Но что значит «масштаб»? Какой уровень масштаба применим в реальном мире?
Наш опыт работы с многочисленными корпоративными клиентами OpenStack показывает, что под «крупным частным облаком» обычно имеется в виду что-то, насчитывающее десятки тысяч виртуальных машин (VM). Сотни пользователей, участвующих в сотнях проектов, одновременно управляют этими VM. В таком масштабе, думаю, справедливо будет сказать, что «частное облако», по сути, становится «виртуальным центром обработки данных».
У виртуального центра обработки данных есть ряд значимых преимуществ по сравнению с традиционным физическим, не самое маловажное из которых — его гибкость. Период между получением заказа от клиента и готовностью запрашиваемой инфраструктуры уменьшается с нескольких дней/часов до нескольких минут/секунд. С другой стороны, здесь нужно быть уверенным в стабильности работы вашей IaaS-платформы под нагрузкой.
Масштабирование Mirantis OpenStack на базе Softlayer Мы решили оценить желаемое поведение платформы Mirantis OpenStack под нагрузкой, ожидаемой от нее в таком виртуальном центре обработки данных. Сотрудничая с нашими друзьями из IBM Softlayer, мы создали инфраструктуру из 350 физических машин, размещенных в двух местах. Для начала мы хотели установить некий базовый уровень по соглашению об уровне сервиса (SLA) для виртуальных центров обработки данных, работающих на Mirantis OpenStack.Очевидно, размер имеет значение. Но были и другие вопросы относительно виртуального центра обработки данных OpenStack в Softlayer, ответить на которые мы посчитали важным с самого начала. Например: •Может ли виртуальный дата-центр на базе облака обслуживать сотни запросов одновременно?
•Скажется ли на удобстве работы пользователя увеличение количества виртуальных серверов в виртуальном дата-центре?
Чтобы ответить на первый вопрос, нам потребовалось выполнить ряд тестов с увеличением количества одновременно посылаемых запросов. Целевой показатель параллельной обработки на данном этапе проведения эталонных тестов был задан равным 500. Ко второму вопросу мы подошли, уточнив его, чтобы оценить, сколько времени займет провижининг сервера в нашем виртуальном центре обработки данных, и, что более существенно, как продолжительность зависит от количества имеющихся серверов.
[embedded content]
Основываясь на вышеназванных ожиданиях, мы разработали первый набор эталонных тестов, целью которых является проверка инфраструктуры Mirantis OpenStack Compute, ключевого компонента платформы. Тестирование затрагивало не только Nova API и планировщик, но и агенты Compute, работающие на базе серверов гипервизора.
Поскольку мы осуществляем эталонное тестирование времени запуска, измерение масштабируемости сервиса OpenStack Compute не требует создания какой-либо нагрузки внутри VM, поэтому можно использовать разновидность (flavor) платформы OpenStack с небольшими требованиями к ресурсам, небольшим образом, который можно туда загрузить, и без каких-либо заданий, выполняемых на VM. При использовании типов экземпляра, определенных для OpenStack по умолчанию, размер экземпляра не оказывает существенного влияния на время провижининга. Однако нам нужно было выполнить тестирование на реальном аппаратном обеспечении, чтобы получить четкое представление о возможностях агента Nova Compute по обработке запросов под нагрузкой.
Базовые параметры SLA, которые мы хотели проверить, следующие: •Дисперсия времени загрузки экземпляров виртуального сервера, в том числе зависимость между временем и количеством виртуальных экземпляров в облачной БД;
•Процент успешности процесса загрузки для наших экземпляров, иными словами, сколько запросов из 100 окажутся по той или иной причине невыполненными.
В качестве целевого показателя для данного эталонного теста мы задали 100 тыс. виртуальных экземпляров, работающих в одном кластере OpenStack. С такой нетребовательной к ресурсам разновидностью наш эксперимент можно сравнить со специализированным сайтом для обслуживания мобильных приложений. Другим возможным вариантом использования с такой рабочей нагрузкой является тестовое окружение для сервера мобильных приложений с несколькими тысячами клиентов, работающих не независимых встраиваемых системах. Мы предполагали, что сможем понять это при помощи нескольких сотен серверов, щедро предоставленных нам компанией Softlayer на ограниченный период времени для использования в качестве тестового стенда.
Настройка тестового окружения для эталонного тестирования OpenStack Мы часто слышим вопрос: «Сколько аппаратных средств вам требуется?». И зачастую в шутку отвечаем клиентам: «Больше». Но ясно, что работа сотни тысяч VM требует достаточного потенциала аппаратных средств. Компания IBM Softlayer предлагает довольно большое разнообразие конфигураций, и ее сотрудникам было так же, как и нам, любопытно увидеть, что OpenStack может предоставить на этом уровне.Чтобы определить количество требуемых ресурсов, для начала мы задали тип экземпляра, или разновидность в терминах OpenStack: 1 виртуальный процессор, 64MB оперативной памяти и жесткий диск 2GB (что гораздо меньше, чем, например, у типа экземпляра m1.micro AWS). Этого вполне достаточно для загрузки тестового образа Cirros.
Использование типа экземпляра с весьма скромными требованиями к ресурсам не влияет на результат тестирования, поскольку для разновидностей/типов экземпляра, заданных в OpenStack по умолчанию, размер экземпляра не оказывает существенного влияния на время провижининга. Причиной тому является то, что данные разновидности определяют только количество процессоров, объем оперативной памяти и размер файлов на диске. Эти ресурсы, как правило, предоставляются фактически с нулевой дисперсией в зависимости от размера экземпляра, т.к., в отличие от экземпляра AWS, который также предоставляет такие дополнительные услуги, как эластичное блочное хранилище (EBS), экземпляры OpenStack являются изолированными; создание кратковременного хранилища, по сути, осуществляется путем создания, например, пустого файла. Поэтому мы можем использовать очень небольшой экземпляр, не опасаясь искажения результатов тестирования.
Общее количество ресурсов: •100 000 виртуальных процессоров (vCPU);
•6250 Gb оперативной памяти;
•200TB дискового пространства.
Поэтому мы решили, что репрезентативной конфигурацией сервера вычислений для проведения данного тестирования будет конфигурация с 4 физическими ядрами (+4 для HT), 16Gb оперативной памяти и 250GB дискового пространства. Поскольку мы не собираемся пускать какую-то реальную нагрузку на VM, мы можем спокойно перераспределить CPU в соотношении 1:32 (в два раза выше коэффициента перераспределения (overcommit rate), заданного для OpenStack по умолчанию), и перераспределить RAM в соотношении 1:1.5, что дает нам плотность, равную 250 виртуальных серверов на один физический узел. С такими нестандартными коэффициентами перераспределения нам потребовалось всего около 400 аппаратных серверов для достижения целевого показателя в 100 тыс. VM.
Зная о том, что максимальная нагрузка придется на наши контроллеры, мы задали для них расширенную серверную конфигурацию. Каждый контроллер имел 128GB оперативной памяти и твердотельный жесткий диск (SSD) для хранения данных, что позволяло ускорить работу базы данных состояний OpenStack на базе контроллера.Интересное примечание: из-за различий в конфигурации узлов Compute и Controller, их провижининг осуществлялся в различные дата-центры SoftLayer с запаздыванием между ними в 40 мс; не будет странным ожидать, что в реальном кластере у вас может быть точно такая же распределенная конфигурация. К счастью, из-за малой задержки между дата-центрами Softlayer какого-либо существенного влияния такой распределенной архитектуры при эталонном тестировании замечено не было.
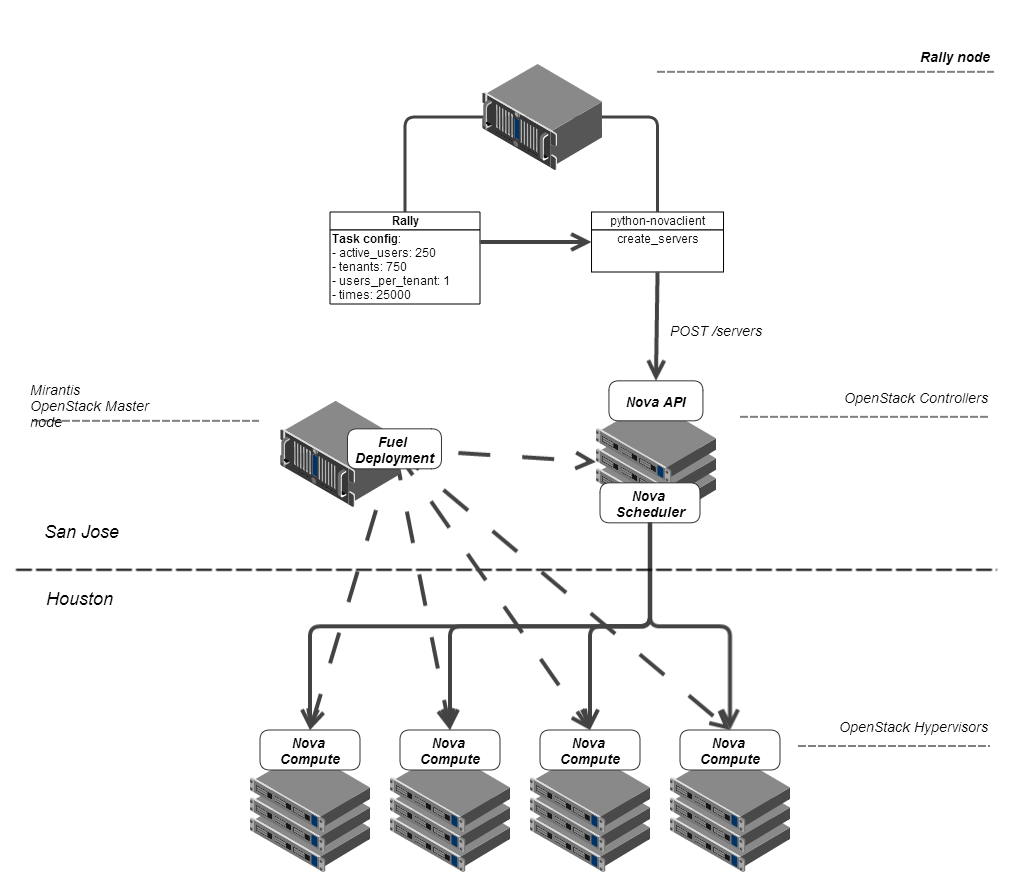
Подробная информация об OpenStack Мы использовали релиз 4.0 продукта Mirantis OpenStack, в который входит OpenStack 2013.2 (Havana), и развернули его на серверах, предоставленных компанией SoftLayer. Для этого нам пришлось незначительно изменить нашу инфраструктуру развертывания (Deployment Framework): поскольку мы не могли выгрузить Mirantis OpenStack ISO в SoftLayer, мы просто скопировали нужный код, используя rsync, через стандартный образ операционной системы. После развертывания кластер был готов для эталонного тестирования.В нашу конфигурацию входили только три сервиса OpenStack: Compute (Nova), Image (Glance) и Identity (Keystone). Это обеспечивало базовую функциональность сервиса Compute, достаточную для наших сценариев использования (тестирование мобильной платформы).
Для построения сети мы использовали сервис Nova Network в режиме FlatDHCP с включенной функцией Multi-host. В нашем простом варианте использования (одна частная сеть, сеть FlatDHCP и отсутствие плавающих IP) функции абсолютно такие же, как в Neutron (компонент Nova Network, который был недавно восстановлен из статуса «не рекомендуется к использованию» и возвращен в OpenStack upstream).
При проведении эталонного тестирования нам пришлось увеличить значения некоторых параметров заданной по умолчанию конфигурации OpenStack. Самое важное изменение — размер пула соединений для модуля SQLAlchemy (параметры max_pool_size и max_overflow в файле nova.conf). Во всех остальных аспектах мы использовали стандартную архитектуру Mirantis OpenStack высокой степени доступности, включая базу данных с возможностью синхронной репликации с несколькими хозяевами (MySQL+Galera), программный балансировщик нагрузки для API-сервисов (haproxy) и corosync/pacemaker для обеспечения высокой доступности на уровне IP.
Rally как инструмент эталонного тестирования Для фактического выполнения эталонного теста нам был необходим инструмент для тестирования; логичным выбором стал проект Rally в составе OpenStack. Rally автоматизирует тестовые сценарии в OpenStack, т.е. позволяет настроить шаги, которые необходимо выполнить при каждом проведении теста, указать количество запусков теста, а также записать время, которое потребовалось для выполнения каждого запроса. С такими функциями мы могли вычислить параметры, которые нужно было проверить: дисперсия времени загрузки и процент успешного выполнения.У нас уже был опыт использования Rally на базе SoftLayer, что очень помогло нам при проведении данного эталонного тестирования.Эталонная конфигурация выглядит примерно следующим образом:
{«execution»: «continuous», «config»: {«tenants»: 500, «users_per_tenant»: 1, «active_users»: 250, «times»: 25000}, «args»: {«image_id»:»0aca7aff-b7d8–4176-a0b1-f498d9396c9f», «flavor_id»: 1}}
Параметры в данной конфигурации следующие: •execution — режим работы инструмента эталонного тестирования. При значении «continuous» рабочий поток Rally будет выдавать следующий запрос по возвращении результата предыдущего (или истечении тайм-аута).
•tenants — количество временных арендаторов Identity (или проектов, как они сейчас называются в OpenStack), созданных в сервисе OpenStack Identity. Данный параметр отражает количество проектов, которые могут соответствовать, например, версиям тестируемой мобильной платформы.
•users_per_tenant — количество временных конечных пользователей, созданных в каждом вышеупомянутом временном проекте. Потоки Rally посылают реальные запросы от имени пользователей, случайно выбранных из этого списка.
•active_users — фактическое количество рабочих потоков Rally. Все эти потоки запускаются одновременно и начинают отправку запросов. Данный параметр отражает количество пользователей, работающих с кластером (в нашем случае создающих экземпляры) в какой-либо момент времени.
•times — общее количество запросов, отправленных во время проведения эталонного тестирования. На основе данного значения определяется процент успешного выполнения.
•image_id и flavor_id — параметры, специфичные для кластера и используемые для запуска виртуальных серверов. Rally использует одинаковые образ и разновидность для всех серверов в эталонной итерации.
•nics — количество сетей, к которым будет подключен каждый виртуальный сервер. По умолчанию такая сеть одна (это сеть, заданная для проекта по умолчанию).
Процесс эталонного тестирования
Для начала мы установили стабильную скорость одновременной отправки запросов. Для этого мы создали набор эталонных конфигураций, отличающихся только по двум параметрам — tenants и active_users — от 100 до 500. Количество VM, которые при этом нужно было запустить, равнялось 5000 или 25000. В целях экономного расходования ресурсов на начальных этапах мы начали с более мелкого кластера из 200 серверов Compute плюс 3 сервера Controller.Приведенные ниже диаграммы показывают зависимость времени запуска определенного виртуального сервера от количества одновременно выполняемых запросов.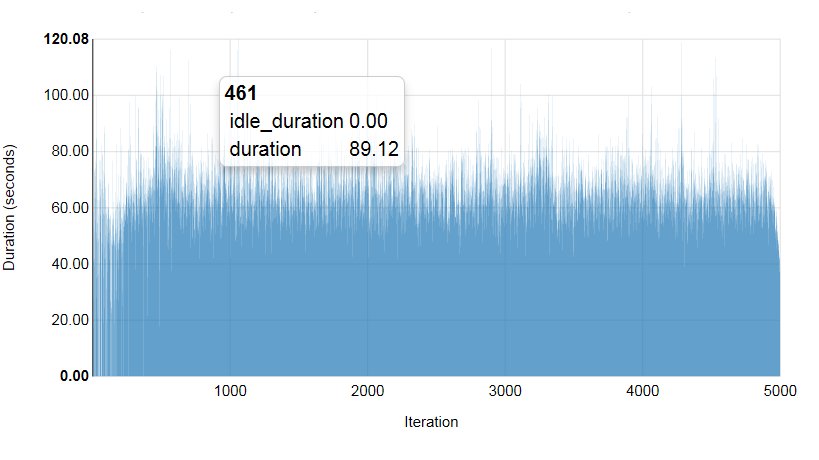
Прогон теста 1.1. 100 одновременных сессий, 5000 VM
Всего Успешн. (%) Мин. (сек) Макс. (сек) Средн.(сек) 90-й процентиль 95-й процентиль
5000×98.96×33.54×120.08×66.13×78.78×83.27
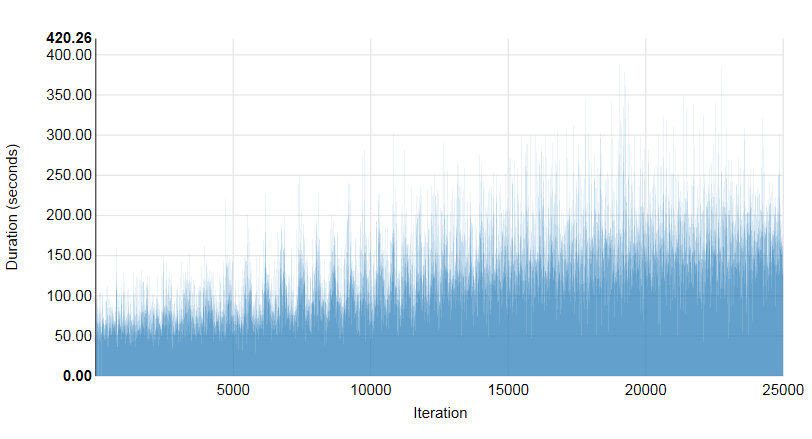
Прогон теста 1.2. 250 одновременных сессий, 25000 VM
Всего Успешн. (%) Мин. (сек) Макс. (сек) Средн. (sec) 90-й процентиль 95-й процентиль
25000×99.96×26.83×420.26×130.25×201.1×226.04
Пару раз при проведении эталонных тестов мы столкнулись с ограничениями, но все они устранялись путем увеличения размера пула соединений в sqlalchemy (с 5 до 100 соединений) и в haproxy (с 4000 до 16000 соединений). Кроме того, несколько раз Pacemaker ошибочно обнаруживал неисправность haproxy. Причиной тому был израсходованный пул соединений haproxy, что привело к тому, что Pacemaker переключил свой виртуальный IP на другой узел контроллера. В обоих случаях балансировщик нагрузки не отреагировал на переключение при отказе. Эти проблемы были решены путем увеличения предельного количества соединений в haproxy.
Следующим после этого шагом было увеличение количества VM в облаке до целевого показателя, равного 100 000. Мы задали другой набор конфигураций и запустили для него Rally под тестовой нагрузкой с целевыми совокупностями из 10 000, 25 000, 40 000, 50 000, 75 000 и 100 000 одновременно работающих виртуальных серверов. Мы обнаружили, что максимальным стабильным уровнем является 250 параллельных запросов. На данном этапе мы добавили к кластеру еще 150 физических хостов, общее количество серверов Compute стало равно 350 плюс 3 сервера Controller.
На основе полученных результатов мы внесли изменения в заданные цели и снизили целевой показатель со 100 000 до 75 000 VM. Это позволило нам продолжить эксперимент в конфигурации кластера 350+3.При установленном уровне параллельного выполнения потребовалось всего более 8ч для развертывания 75 000 виртуальных серверов с выбранной нами конфигурацией экземпляров. Приведенная ниже диаграмма показывает зависимость времени запуска VM от количества работающих VM при выполнении тестов.

Прогон теста 1.3. 500 одновременных сессий, 75000 VM
Всего Успешн. (%) Мин. (сек) Макс. (сек) Средн. (сек) 90-й процентиль 95-й процентиль
75000×98.57×23.63×614.29×197.6×283.93×318.96
Как видно из диаграммы, при 500 одновременных соединений среднее время на одну машину составило менее 200 сек, или в среднем 250 VM каждые 98.8 сек.
Результаты тестирования Mirantis OpenStack на базе Softlayer Первый этап проведения эталонного тестирования позволил нам установить базовый уровень ожиданий по SLA для виртуального центра обработки данных, настроенного для вычислительных ресурсов (в отличие, например, от чего-то, что является ресурсоемким с точки зрения хранения данных и операций ввода/вывода). Платформа Mirantis OpenStack способна одновременно обрабатывать 500 запросов и одновременно поддерживать 250 запросов для построения совокупности из 75000 экземпляров виртуальных серверов в одном кластере. В архитектуре Compute у экземпляров виртуальных серверов не предполагается постоянное наличие прикрепленных блоков для виртуального хранения данных, и они не образуют сложных сетевых конфигураций. Обратите внимание на то, что для того, чтобы быть консервативными, мы не наделяли кластер какими-либо функциями по масштабируемости OpenStack, такими как ячейки, модифицированный планировщик или выделенные кластеры для сервисов OpenStack или сервисов платформы (например, БД или очередь). Данное эталонное тестирование проведено на основе стандартной архитектуры Mirantis OpenStack; любые из вышеперечисленных модификаций подняли бы производительность на еще более высокий уровень.Важным фактором успеха, несомненно, являлось качество аппаратного обеспечения IBM SoftLayer и сетевой инфраструктуры для проведения эталонного тестирования. Полученные нами результаты показывают, что платформа Mirantis OpenStack может быть использована для управления работой большого виртуального центра обработки данных на стандартном оборудовании SoftLayer. Несмотря на то, что мы не измеряли сетевые параметры для оценки нагрузки на соединения, мы не наблюдали какого-либо воздействия. Кроме того, качество сетевых соединений между центрами обработки данных в SoftLayer позволило нам легко построить кластеры OpenStack с несколькими центрами обработки данных.Взгляд в будущее: расширение диапазона рабочей нагрузки OpenStack На следующем этапе проекта по проведению эталонного тестирования мы планируем применить аппаратные средства SoftLayer с эталонными заданиями, запущенными внутри экземпляров виртуальных серверов. Мы планируем установить пороги уровня сервиса для операций ввода/вывода на диске и в сети на основе общих профилей рабочей нагрузки (веб-хостинг, виртуальный рабочий стол, среда построения/разработки), а также оценить поведение Mirantis OpenStack при каждом из таких сценариев.Оригинал статьи на английском языке.
