Сeph — от «на коленке» до «production» часть 2
(первая часть тут: https://habr.com/ru/post/456446/)
Введение
Поскольку сеть является одним из ключевых элементов Ceph, а она в нашей компании немного специфична — расскажем сначала немного о ней.
Тут будет сильно меньше описаний самого Ceph, в основном сетевая инфраструктура. Описываться будут только сервера Ceph-а и некоторые особенности серверов виртуализации Proxmox.
Итак: Сама сетевая топология построена как Leaf-Spine. Классическая трехуровневая архитектура представляет из себя сеть, где есть Core (маршрутизаторы ядра), Aggregation (маршрутизаторы агрегации) и связанные напрямую с клиентами Access (маршрутизаторы доступа):
Трехуровневая схема
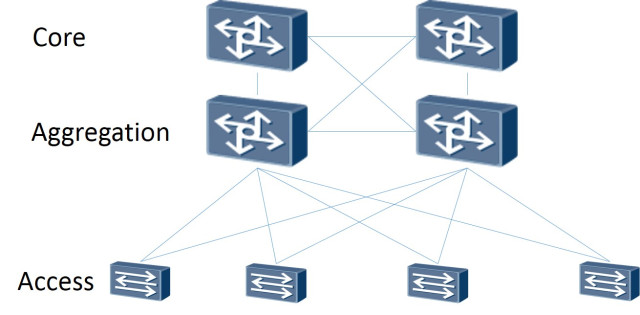
Топология Leaf-Spine состоит из двух уровней: Spine (грубо говоря основной маршрутизатор) и Leaf (ветви).
Двухуровневая схема

Вся внутренняя и внешняя маршрутизация построена на BGP. Основная система, которая занимается управлением доступами, анонсами и прочее — это XCloud.
Сервера, для резервирования канала (а так-же для его расширения) подключаются к двум L3 коммутаторам (большинство серверов включаются в Leaf коммутаторы, но часть серверов с повышенной сетевой нагрузкой включаются напрямую в Spine коммутатора), и через протокол BGP анонсируют свой unicast адрес, а так же anycast адрес для сервиса, если несколько серверов обслуживают трафик сервиса и им достаточно ECMP балансировки. Отдельной особенностью этой схемы, которая позволила нам сэкономить на адресах, но так же потребовала от инженеров познакомиться с миром IPv6, стало использование BGP unnumbered standard на основе RFC 5549. Какое-то время для обеспечения работы BGP в этой схеме для серверов применяли Quagga и периодически возникали проблемы с потерей пиров и связностью. Но после перехода на FRRouting (активными контрибьюторами которого являются наши поставщики ПО для сетевого оборудования: Cumulus и XCloudNetworks), больше таких проблем мы не наблюдали.
Всю эту общую схему для удобства называем «фабрика».
Поиск пути
Варианты настройки cluster network:
1) Вторая сеть на BGP
2) Вторая сеть на двух отдельных стекированных коммутаторах с LACP
3) Вторая сеть на двух отдельных изолированных коммутаторах с OSPF
Тесты
Тесты проводились двух типов:
а) сетевые, с помощью утилит iperf, qperf, nuttcp
b) внутренние тесты Ceph ceph-gobench, rados bench, создавали rbd и тестировали на них с помощью dd в один и несколько потоков, с помощью fio
Все тесты проводились на тестовых машинах с SAS дисками. На сами цифры в производительности rbd не сильно смотрели, использовали только для сравнения. Интересовали изменения в зависимости от типа подключения.
Первый вариант
Сетевые карты подключены к фабрике, настроены BGP.
Использовать эту схему для внутренней сети посчитали не самым лучшим выбором:
Во первых лишнее количество промежуточных элементов в виде коммутаторов, дающих дополнительные latency (это было основной причиной).
Во вторых первоначально для отдачи статики через s3 использовали anycast адрес, поднятый на нескольких машинах с radosgateway. Это выливалось в то, что трафик с фронтендовых машин до RGW распределялся не равномерно, а проходил по кратчайшему маршруту — то есть фронтовый Nginx всегда обращался к той ноде с RGW, которая была подключена к общему с ней leaf-у (это, конечно, был не основной аргумент — мы просто отказались в последствии от anycast адреса для отдачи статики). Но для чистоты эксперимента решили провести тесты и на такой схеме, чтоб иметь данные для сравнения.
Запускать тесты на всю полосу пропускания побоялись, поскольку фабрика используется prod серверами, и если бы мы завалили линки между leaf и spine — то это бы задело часть прода.
Собственно, это было еще одной из причин отказа от такой схемы.
Тесты iperf с ограничением BW в 3Gbps в 1, 10 и 100 потоков использовались для сравнения с другими схемами.
Тесты показали следующие результаты:
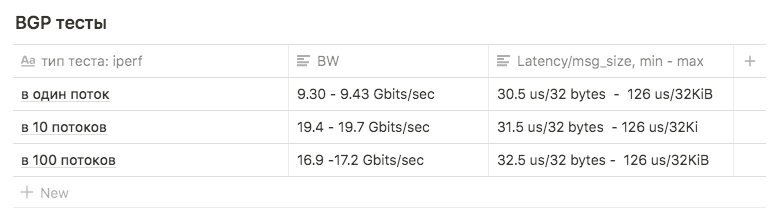
в 1 поток примерно 9.30 — 9.43 Gbits/sec (при этом сильно вырастает количество ретрансмитов, до 39148). Цифра оказалась приближенная к максимуму одного интерфейса говорит о том, что используется один интерфейс из двух. Количество ретрансмитов при этом примерно 500–600.
в 10 потоков 9.63 Gbits/sec на интерфейс, при этом количество ретрансмитов вырастало до среднего 17045.
в 100 потоков результат оказался хуже чем в 10, при этом количество ретрансмитов меньше: среднее значение 3354
Второй вариант
LACP
Нашлось два коммутатора Juniper EX4500. Собрали их в стек, подключили сервера первыми линками в один коммутатор, вторыми во второй.
Первоначальная настройка бондинга была такой:
root@ceph01-test:~# cat /etc/network/interfaces
auto ens3f0
iface ens3f0 inet manual
bond-master bond0
post-up /sbin/ethtool -G ens3f0 rx 4096
post-up /sbin/ethtool -G ens3f0 tx 4096
post-up /sbin/ethtool -L ens3f0 combined 64
post-up /sbin/ip link set ens3f0 txqueuelen 10000
mtu 9000
auto ens3f1
iface ens3f1 inet manual
bond-master bond0
post-up /sbin/ethtool -G ens3f1 rx 4096
post-up /sbin/ethtool -G ens3f1 tx 4096
post-up /sbin/ethtool -L ens3f1 combined 64
post-up /sbin/ip link set ens3f1 txqueuelen 10000
mtu 9000
auto bond0
iface bond0 inet static
address 10.10.10.1
netmask 255.255.255.0
slaves none
bond_mode 802.3ad
bond_miimon 100
bond_downdelay 200
bond_xmit_hash_policy 3 #(layer3+4 )
mtu 9000Тесты iperf и qperf показали Bw до 16Gbits/sec. Решили сравнить разные типа мода:
rr, balance-xor и 802.3ad. Так-же сравнивали разные типы хэширования layer2+3 и layer3+4 (рассчитывая выгадать преимущество на вычислениях хэшей).
Ещё сравнили результаты при различных значениях sysctl переменной net.ipv4.fib_multipath_hash_policy, (ну и поиграли немного с net.ipv4.tcp_congestion_control, хотя она к бондингу отношения не имеет. По этой переменной есть хорошая статья ValdikSS)).
Но на всех тестах так и не получилось преодолеть порог в 18Gbits/sec (этой цифры достигли используя balance-xor и 802.3ad, между ними в результатах тестов разницы особо не было) и то это значение достигалось «в прыжке» всплесками.
Третий вариант
OSPF
Для настройки этого варианта убрали LACP с коммутаторов (стекирование оставили, но оно использовалось лишь для менеджмента). На каждом коммутаторе собрали по отдельному vlan-у для группы портов (с прицелом на будущее, что в эти же коммутаторы будут воткнуты как QA так и PROD сервера).
Настроили две плоских приватных сети для каждого vlan (по одному интерфейсу в каждый коммутатор). Поверх этих адресов идет анонсирование еще одного адреса из третьей приватной сети, которая и является cluster network для CEPH.
Поскольку public network (по которой мы ходим по SSH) работает на BGP, то для настройки OSPF использовали frr, который уже стоит в системе.
10.10.10.0/24 и 20.20.20.0/24 — две плоских сети на коммутаторах
172.16.1.0/24 — сеть для анонсирования
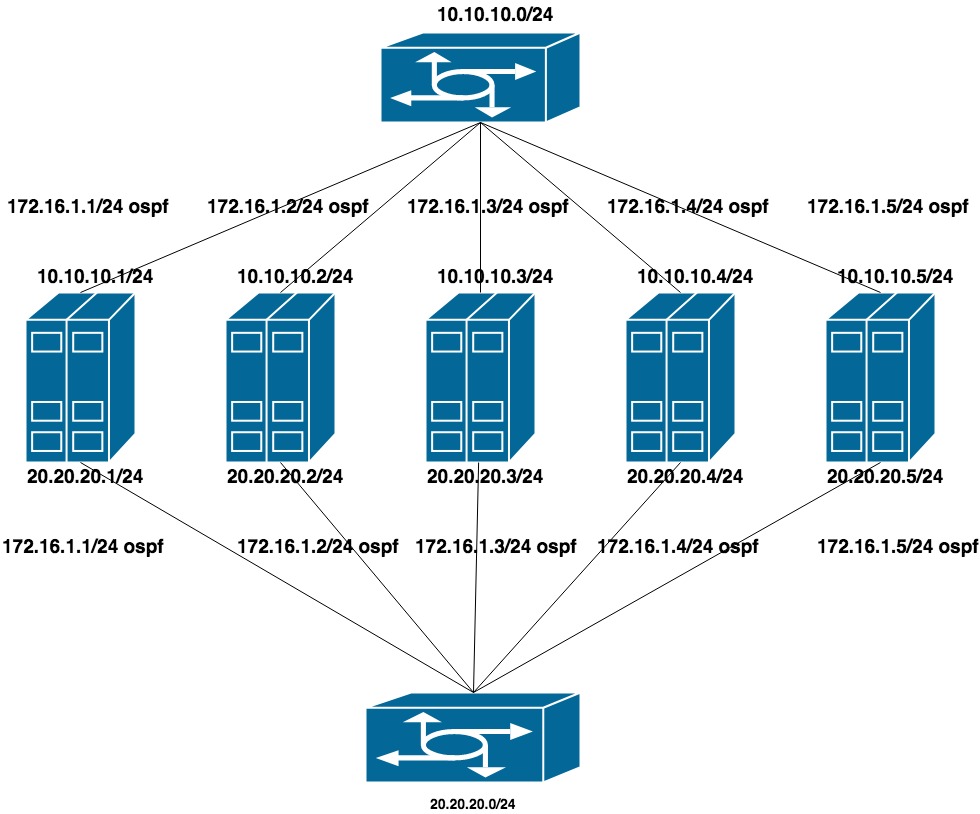
Настройка машины:
интерфейсы ens1f0 ens1f1 смотрят в приватную сеть
интерфейсы ens4f0 ens4f1 смотрят в публичную сеть
Конфиг сети на машине выглядит так:
oot@ceph01-test:~# cat /etc/network/interfaces
# This file describes the network interfaces available on your system
# and how to activate them. For more information, see interfaces(5).
source /etc/network/interfaces.d/*
# The loopback network interface
auto lo
iface lo inet loopback
auto ens1f0
iface ens1f0 inet static
post-up /sbin/ethtool -G ens1f0 rx 8192
post-up /sbin/ethtool -G ens1f0 tx 8192
post-up /sbin/ethtool -L ens1f0 combined 32
post-up /sbin/ip link set ens1f0 txqueuelen 10000
mtu 9000
address 10.10.10.1/24
auto ens1f1
iface ens1f1 inet static
post-up /sbin/ethtool -G ens1f1 rx 8192
post-up /sbin/ethtool -G ens1f1 tx 8192
post-up /sbin/ethtool -L ens1f1 combined 32
post-up /sbin/ip link set ens1f1 txqueuelen 10000
mtu 9000
address 20.20.20.1/24
auto ens4f0
iface ens4f0 inet manual
post-up /sbin/ethtool -G ens4f0 rx 8192
post-up /sbin/ethtool -G ens4f0 tx 8192
post-up /sbin/ethtool -L ens4f0 combined 32
post-up /sbin/ip link set ens4f0 txqueuelen 10000
mtu 9000
auto ens4f1
iface ens4f1 inet manual
post-up /sbin/ethtool -G ens4f1 rx 8192
post-up /sbin/ethtool -G ens4f1 tx 8192
post-up /sbin/ethtool -L ens4f1 combined 32
post-up /sbin/ip link set ens4f1 txqueuelen 10000
mtu 9000
# Анонсируемые адреса висят на loopback-ах:
auto lo:0
iface lo:0 inet static
address 55.66.77.88/32
dns-nameservers 55.66.77.88
auto lo:1
iface lo:1 inet static
address 172.16.1.1/32Конфиги frr выглядят так:
root@ceph01-test:~# cat /etc/frr/frr.conf
frr version 6.0
frr defaults traditional
hostname ceph01-prod
log file /var/log/frr/bgpd.log
log timestamp precision 6
no ipv6 forwarding
service integrated-vtysh-config
username cumulus nopassword
!
interface ens4f0
ipv6 nd ra-interval 10
!
interface ens4f1
ipv6 nd ra-interval 10
!
router bgp 65500
bgp router-id 55.66.77.88 #поле необязательное, чуть ниже расскажем зачем уго указали
timers bgp 10 30
neighbor ens4f0 interface remote-as 65001
neighbor ens4f0 bfd
neighbor ens4f1 interface remote-as 65001
neighbor ens4f1 bfd
!
address-family ipv4 unicast
redistribute connected route-map redis-default
exit-address-family
!
router ospf
ospf router-id 172.16.0.1
redistribute connected route-map ceph-loopbacks
network 10.10.10.0/24 area 0.0.0.0
network 20.20.20.0/24 area 0.0.0.0
!
ip prefix-list ceph-loopbacks seq 10 permit 172.16.1.0/24 ge 32
ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32
!
route-map ceph-loopbacks permit 10
match ip address prefix-list ceph-loopbacks
!
route-map redis-default permit 10
match ip address prefix-list default-out
!
line vty
!На этих настройках сетевые тесты iperf, qperf и т.д. показали максимальную утилизацию обоих каналов в 19.8 Gbit/sec, при этом latency упало до 20us
Поле bgp router-id: Используется для идентификации узла при обработке маршрутной информации и построении маршрутов. Если не указано в конфиге, то выбирается один из IP адресов узла. У разных производителей оборудования и ПО алгоритмы могут разниться, в нашем случае FRR использовал наибольший IP адрес на loopback. Это приводило к двум проблемам:
1) Если мы пытались повесить еще один адрес (например, приватный из сети 172.16.0.0) больше, чем текущий — то это приводило к смене router-id и, соответственно, к переустановке текущих сессий. А значит к кратковременному разрыву и потере сетевой связности.
2) Если мы пытались повесить anycast адрес, общий для нескольких машин и он выбирался в качестве router-id — в сети появлялись два узла с одинаковым router-id.
Часть 2
После тестов на QA приступили к модернизации боевого Ceph.
NETWORK
Переезд с одной сети на две
Параметр cluster network один из тех, которые нельзя поменять на лету, указав OSD его через ceph tell osd.* injectargs. Изменить его в конфиге и перезапустить весь кластер — терпимое решение, но очень не хотелось иметь даже небольшой даунтайм. Перезапускать по одной OSD с новым параметром сети тоже нельзя — в какой-то момент мы бы поимели два полкластера — старые OSD на старой сети, новые на новой. Благо, параметр cluster network (как, кстати, и public_network) это список, то есть можно указать несколько значений. Решили переезжать постепенно — сначала добавить в конфиги новую сеть, потом убрать старую. Ceph идет по списку сетей последовательно — OSD начинает работать сначала с той сетью, которая в списке указана первой.
Сложность заключалась в том, что первая сеть работала через bgp и была подключена к одним коммутаторам, а вторая — на ospf и подключена к другим, физически не связанным с первыми. На момент перехода необходимо было иметь временно сетевой доступ между двумя сетями. Особенность настройки нашей фабрики была в том, что ACLы невозможно настроить на сеть, если её нет в списке аннонсируемой (в этом случае она является «внешней» и ACL для нее может быть создан только вовне. Он создавался на spain-ах, но не приезжал на leaf-ы).
Решение было костыльным, сложным, но работало: анонсировать внутреннюю сеть через bgp, одновременно с ospf.
Последовательность перехода получилась такой:
1) Настраиваем cluster network для ceph на двух сетях: через bgp и через ospf
В конфигах frr менять ничего не пришлось, строка
ip prefix-list default-out seq 5 permit 0.0.0.0/0 ge 32не ограничивает нас в анонсируемых адресах, сам адрес для внутренней сети поднят на loopback интерфейсе, достаточно было на маршрутизаторах настроить приём анонса этого адреса.
2) Добавляем в конфиг ceph.conf новую сеть
cluster network = 172.16.1.0/24, 55.66.77.88/27и начинаем по одному перезапускать OSD, пока все не переходят на сеть 172.16.1.0/24.
root@ceph01-prod:~#ceph osd set noout
# Что-бы не вызвать резкого всплеска нагрузки при рестарте большого количества OSD
# перезапускаем их с некоторой задержкой. Практика показала, что на наших дисках
# после старта, OSD заканчивает сверку данных примерно за 30 секунд.
root@ceph01-prod:~#for i in $(ps ax | grep osd | grep -v grep| awk '{ print $10}'); \
root@ceph01-prod:~# do systemctl restart ceph-osd@$i; sleep 30; done3) После чего убираем из конфига лишнюю сеть
cluster network = 172.16.1.0/24и повторяем процедуру.
Все, мы плавно переехали на новую сеть.
Ссылки:
https://shalaginov.com/2016/03/26/сетевая-топология-leaf-spine/
https://www.xcloudnetworks.com/case-studies/innova-case-study/
https://github.com/rumanzo/ceph-gobench
