SAST для самых маленьких. Обзор open-source инструментов поиска уязвимостей для C/C++

Привет, Хабр!
Навыки статического анализа кода в арсенале исследователя безопасности приложений фактически являются must-have скиллом. Искать ручками уязвимости в коде, не прибегая к автоматизации, для небольших проектов вполне быть может и приемлемый сценарий. Но для больших задач с миллионами строк кода — это непозволительная роскошь с точки зрения временных затрат. Решения по автоматизации всего этого процесса не заставили себя долго ждать. Именно по этой причине мы имеем такой широкий выбор инструментов статического анализа, в разнообразии которого можно утонуть. Рассказать же подробно о всех не хватит и книги.
По этой причине главными героями сегодняшней статьи стали несколько известных и развивающихся инструментов статического анализа кода, которые могут пригодиться исследователям безопасности в процессе поиска уязвимостей. Мы постарались отобрать инструменты так, чтобы они обязательно имели открытый исходный код, возможность работы с языками C/C++ (так как они являются наиболее сложными в аспекте безопасного программирования) и без каких-либо ограничений для этого (например, как в SonarQube), а также имели возможность создавать собственные запросы/правила для кастомизации анализа под конкретный проект/тип уязвимости с минимальными усилиями.
Присутствие не самых известных инструментов в обзоре может немного удивить. Тем не менее они являются интересными образцами и достойны рассмотреня. Если вы хотите рассказать о своем фаворите, будем рады почитать о вашем опыте в комментариях!
Прежде чем начать обзор, сперва обратимся к истокам. Напомним, что такое SAST и за что его так все не любят.
Что такое SAST?
SAST (Static Application Security Testing) — это процесс тестирования, при котором применяется техники статического анализа для поиска ошибок и потенциальных проблем безопасности. Как уже отмечалось, на данный момент существует огромное количество SAST-инструментов для различных языков программирования. Пожалуй, наиболее полный перечень всевозможных инструментов расположен в github-репозитории Analysis Tools. Внушительный по объему список также был представлен OWASP Foundation — Source Code Analysis Tools.
К сожалению, о SAST далеко не все отзываются лестно. Так уж вышло, что общее отношение к SAST у ряда специалистов скорее скептично-негативное ввиду большого количества ложных срабатываний. Это отбивает желание пользоваться подобными инструментами, тратя на них свое драгоценное время.
Задача этой статьи вовсе не переубедить, а показать, что эти инструменты — не панацея, а лишь вспомогательный элемент в процессе поиска уязвимостей. Зная контекст исследуемого приложения/системы, можно создавать довольно эффективные правила, которые позволят найти отправные точки к возможным багам, ну и вообще облегчат поиск в огромной груде кода.
Наши подопытные
С учетом уже упомянутых критериев для обзора были выбраны следующие SAST-инструменты:
Чтобы оценить их, нам понадобится проект с исходным кодом, содержащий уязвимости. Было бы очень здорово охватить все слабости, перечисленные в Weaknesses in Software Written in C и Weaknesses in Software Written in C++, но мы решили взять одну из них и сделать акцент на различных способах ее реализации, чтобы проверить возможности исследуемых инструментов. И это… double-free, она же CWE-415! Данная уязвимость, несмотря на свою простоту и почтенный возраст, до сих пор обнаруживается в ряде известных проектов. Правила для анализа будем создавать под этот тип ошибки.
Помимо уязвимых сниппетов кода, наш проект будет содержать несколько простых ловушек для SAST-инструментов. Для людей эти «ловушки» могут показаться смешными, но для инструментов это целое испытание. Подобным образом можно будет выявить проблемные места инструментов, например, некоторые из них могут не уметь работать с Control Flow, не обладать межпроцедурным анализом и т.д. Так что постараемся внимательно изучать документацию, быть в курсе существующих примеров правил/запросов, и конечно же, подходить творчески и экспериментировать.
Игрушечный проект расположился в github-репозитории «double-free-samples».
Оформим для себя небольшой чек-лист по багам в коде игрушечного проекта, чтобы оценивать работу инструментов в будущем. В табличку запишем информацию об уязвимых участках кода и о «ловушках» для SAST-инструментов, т.е. ситуациях, при которых уязвимость не может существовать. Если они будут обнаружены в результатах, это будут ложноположительные кейсы.
Также стоит отметить, что код проекта полностью готов к сборке, если это будет необходимо инструменту статического анализа. Несомненно, на деле у исследователей безопасности не всегда имеется такая возможность. Однако это не повод не рассматривать те инструменты, которые нуждаются в кодовой базе. Как правило, в контексте их работы это является неплохим преимуществом, ведь кодовая база содержит много полезной информации для анализа, что влияет на качество результатов.
Начнем же наш обзор!
Semgrep

Semgrep — легковесный инструмент статического анализа для поиска ошибок в коде. Был разработан командой r2c, написан в большинстве своем на OCaml. Первый релиз состоялся в начале 2020 года. Пожалуй, это один из немногих инструментов, в котором трансформация «From Zero To Hero» для пользователя является самой скоростной. Всё это благодаря тому, что язык запросов, или в данном случае паттернов, максимально похож на язык программирования исследуемого проекта.
Когда Semgrep выполняет анализ кода, он создает абстрактное синтаксическое дерево (AST), которое затем транслируется в промежуточный язык, с которым уже и проводится анализ. Это крайне удобно и позволяет за короткое время научиться создавать эффективные правила. На этот счет инструмент имеет отличную документацию, а также большое количество хвалебных отзывов от AppSec-комьюнити, в том числе в виде отдельных статей. Мы тоже не обойдем стороной его достоинства — вот они:
- Не требует сборки проекта, а значит можно предоставлять несобираемые исходники, результат декомпиляции
- Поддерживаемые языки: C#, Go, Java, JavaScript, JSX, JSON, PHP, Python, Ruby, Scala, TypeScript, TSX. C/C++ имеют статус экспериментальных языков, как и многие другие
- Синтаксис паттернов совпадает с синтаксисом языка проекта
- Быстрая обработка запросов благодаря многопоточности
- Имеет крутую playground-площадку для обучения синтаксису
- В реестре semgrep-правил можно подсмотреть security rules для множества языков, создавать свои и делиться ими
- Есть собственный TrophyСase — найденные CVE с помощью Semgrep
И несколько недоработок:
- Не знает про межпроцедурное взаимодействие, анализирует все методы подряд без разбора что, где и когда вызывается
- Не так много публичных правил для C/C++
Как уже отмечалось, поддержка C/C++ пока что является экспериментальной, и публичных правил для этих языков не много. В сравнении с языками зрелой поддержки Java, Python, Go, Ruby, C#, имеющими впечатляющий ruleset.
Эту проблему поднимал исследователь Marco Ivaldi в статьe «Semgrep ruleset for C/C++ vulnerability research». Он написал несколько десятков собственных правил для поиска уязвимостей в C/C++, их можно найти в его github-репозитории. Официальный репозиторий semgrep-rules, к сожалению, не содержит правил для C++. Если вы опытный специалист и хотели бы внести вклад в развитие «сишного» комьюнити Semgrep, вы нужны, как никогда!
- Не поддерживает межфайловое взаимодействие, разрешение внешних ссылок, Global taint
Под внешней ссылкой в данном контексте понимаются файлы к включению, указанные в директиве #include <> или #include "". Semgrep не умеет работать с внешними ссылками и абсолютно не знает, что там может находиться внутри. Таковы особенности инструмента. Теперь пару слов о taint-анализе.
Анализ DataFlow как более обширное понятие используется для вычисления возможных значений, которые переменная может содержать в различных точках программы, определяя, как эти значения распространяются и где используются. Tainting tracking как более узкое понятие подразумевает контроль потока недоверенных данных (пользовательский ввод) по всему коду проекта с целью выявить их влияние на выполнение программы. Taint-анализ подразделяется на виды:
1) Local taint анализирует поток данных внутри одной функции. В данном случае рассматриваются только ребра между узлами графа, принадлежащие одной и той же функции.
2) Global taint исследует поток «порчи» между разными функциями по всей программе.
Стандартные правила Semgrep выполняются только в отношении одного файла, а новомодный «Taint mode» выполняется только в рамках одной функции, что для больших проектов и более сложных ошибок скорее бестолково, чем полезно. На этот счет r2c выпустила новый проприетарный инструмент под названием DeepSemgrep, который должен был добавить функционал global taint. Чтобы им воспользоваться, необходимо к запуску стандартной утилиты semgrep в командной строке добавить дополнительный аргумент, вот так:
semgrep --deepа в правиле указать дополнительные поля pattern-sources и pattern-sinks. К сожалению, поддерживаемыми языками на данный момент являются только Java и Ruby. На этом обсуждение достоинств и недостатков Semgrep заканчиваем и переходим к созданию правила.
Локальные правила в Semgrep бывают двух типов — эфемерные (единоразовые) и YAML-правила.
Эфемерный тип может быть полезен, если знаете, как кратко сформулировать ваше правило «вместо тысячи слов». Например, хотим примитивный double-free:
semgrep -e 'free($VAR); ... free($VAR);' --lang=c path/to/srcТакой запрос получит достаточно много ложноположительных результатов, так как мы совсем не уточнили, что высвобожденный чанк, на который указывает наш поинтер, не должен быть переназначен перед вторым освобождением. Для реализации более подробных и сложных правил необходимо создать YAML-файл и в нём описать все необходимые условия.
Для написания правила воспользуемся следующими конструкциями Semgrep:
id— строковый идентификатор правилаmetadata— данные о правиле, указывается по желанию, как здесь,referencesсодержит информацию о CWEmessage— поле сообщения, которое будет выводиться после каждого успешного поискаseverity— серьезность ошибки, известные вариации: INFO, WARNING, ERRORlanguages— язык, для которого определяется данное правилоpatterns— оператор, объединяющий шаблоны с использованием логического «AND»pattern-either— какpatterns, только с логическим «OR»pattern— шаблон, представляющий собой выражение, которое необходимо найти в коде проектаpattern-not— выражение, которое нужно игнорировать при поискеpattern-inside— ограничивает поиск требуемого паттерна внутри указанного выраженияpattern-not-inside— не включает в результат, если требуемый паттерн содержится в данном выражении
Semgrep богат на различные конструкции. С ними можно дополнительно ознакомиться в документации. Очень полезными являются, например, pattern-regex, позволяющий искать в коде по заданной PCRE-регулярке, metavariable-pattern и metavariable-regex, позволяющие гибко настроить метапеременные по заданным шаблонам/PCRE-регуляркам соответственно.
Итоговое правило будет выглядеть так:
rules:
- id: detect-double-free
metadata:
references:
- https://cwe.mitre.org/data/definitions/415.html
message: >-
Some vulnerable (and not) double-free cases. If malloc() returns
the same value twice and the program later gives the attacker control
over the data that is written into this doubly-allocated memory,
the program becomes vulnerable to a buffer overflow attack.
severity: ERROR
languages:
- cpp
pattern-either:
- patterns:
- pattern: |
free($PTR);
...
free($PTR);
- pattern-not: |
free($PTR);
...
$PTR = $EXPR;
...
free($PTR);
- pattern-not-inside: |
$FTYPE $FUNC(..., $TYPE $ARG, ...){
...
$ARG = $EXPR;
...
}
...
$FUNC($PTR);
...
- pattern-not-inside: |
if ($CONF){
...
goto $LAB;
}
...
free($PTR);
...
$LAB:
...
free(ptr);
- patterns:
- pattern: |
if ($COND){
...
free($PTR);
...
}
...
free($PTR);
- pattern-not: |
if ($COND){
...
free($PTR);
...
$PTR = $EXPR;
...
}
...
free($PTR);
- pattern-not: |
if ($COND){
...
free($PTR);
...
}
...
$PTR = $EXPR;
...
free($PTR);
- patterns:
- pattern-inside: |
$FTYPE $FUNC(..., $TYPE $ARG, ...){
...
free($ARG);
...
}
...
- pattern-not-inside: |
$FTYPE $FUNC(..., $TYPE $ARG, ...){
...
free($ARG);
...
$ARG = $EXPR;
...
}
...
- pattern: |
$FUNC(..., $PTR, ...);
...
$FUNC(..., $PTR, ...);
- pattern-not: |
$FUNC(..., $PTR, ...);
...
$PTR = $EXPR;
...
$FUNC(..., $PTR, ...);
- patterns:
- pattern: |
delete [] $PTR;
...
delete [] $PTR;
- pattern-not: |
delete [] $PTR;
...
$PTR = $EXPR;
...
delete [] $PTR;
- patterns:
- pattern: |
delete $PTR;
...
delete $PTR;
- pattern-not: |
delete $PTR;
...
$PTR = $EXPR;
...
delete $PTR;Запускаем:
semgrep --config config.yaml [PATH/TO/SRC]Findings:
13┆ free(buf1);
14┆ free(buf1);
⋮┆----------------------------------------
38┆ free(buf2);
39┆
40┆ buf3 = (char *) malloc(SIZE);
41┆ free(buf2);
⋮┆----------------------------------------
56┆ wrapper(buf1);
57┆ wrapper(buf1);
⋮┆----------------------------------------
66┆ if (condition){
67┆ free(ptr);
68┆ }
69┆ free(ptr);
⋮┆----------------------------------------
66┆ if (condition){
67┆ free(ptr);
68┆ }
69┆ free(ptr);
70┆ free(ptr);
⋮┆----------------------------------------
69┆ free(ptr);
70┆ free(ptr);
⋮┆----------------------------------------
88┆ delete [] x;
89┆ delete [] x;
⋮┆----------------------------------------
113┆ free(ptr);
114┆ goto free_me;
115┆
116┆ free_me:
117┆ free(ptr);
Ran 1 rule on 3 file: 8 findings.Что ж, в этом и есть сила Semgrep! Были найдены все кейсы двойного освобождения, ложноположительные результаты отсутствуют. Всё это потому, что мы создали соответствующие паттерны для тех ситуаций в коде проекта, где ошибка двойного освобождения могла бы существовать, и отфильтровали те случаи, когда ошибки нет. Это правило хорошо работает для игрушечного проекта и является достаточным. Запустите это правило на другом, более сложном проекте — результат вас не обрадует, поскольку правило охватывает далеко не все паттерны ситуаций, при которых в принципе может существовать ошибка double-free, а таких кейсов огромное количество. Пробуйте, дополняйте свои правила разнообразными паттернами, и их объемы будут соразмерно расти с качеством результатов.
Semgrep, несмотря на свои недостатки, оставляет о себе положительное впечатление. Инструмент продолжает развиваться благодаря отличной команде разработчиков и широкому заинтересованному AppSec комьюнити. Продолжим наш обзор и перейдем к рассмотрению следующего инструмента — CodeQL.
CodeQL

CodeQL впервые был представлен компанией Semmle в 2018 году. Бывалые ресечеры могут помнить его как SemmleQL. Он довольно быстро был выкуплен GitHub и с 2020 года принадлежит Microsoft. Одним из основных преимуществ CodeQL является, пожалуй, лучшая реализация DataFlow-анализа/Taint tracking в рамках кодовой базы по сравнению с другими инструментами. Последняя является иерархическим представлением кода, она включает в себя абстрактное синтаксическое дерево (AST) всего проекта, CFG (Control Flow Graph) и DataFlow данные, которые требуются для taint-анализа.
О CodeQL уже бывали выступления на международных площадках (например, ZeroNights 2021 — «Company wide SAST»), о нем не раз писали отличные статьи, в том числе и на Хабре (например, CodeQL: SAST своими руками (и головой), Сканирование кода C++ с помощью GitHub Actions), так что не будем повторяться и кратко обозначим некоторые особенности инструмента.
Преимущества:
- Поддерживаемые языки: C/C++, C#, Go, Java, JavaScript, Python, Ruby, TypeScript
- Удобная интеграция в Visual Studio Code — CodeQL extension
- Неплохая документация, а также полезные лекции от Semmle
- Качественный анализ DataFlow/TaintTracking
- Возможность реализации объектно-ориентированных запросов (object-oriented queries)
- В наличии воркшопы и полезные интро как от самих создателей, так и от комьюнити
- В онлайн-консоли LGTM (Looks Good To Me) можно создавать и тестировать СodeQL-запросы к доступным базам opensource-проектов или к собственным GitHub-репозиториям. Однако недавно появилась новость, что LGTM заявляет о своем закрытии к концу 2022 года и рекомендует использовать GitHub Code Scanning
- Список уязвимостей безопасности, найденных с помощью CodeQL, заметно пополняется
Недостатки:
- Необходимость создания кодовой базы
Это значит, что, если проект написан на компилируемом языке, он должен быть готов к сборке. Если проект по каким-либо причинам не может быть собран, CodeQL использовать не получится.
- Специфика языка запросов
К сожалению, как в случае с Semgrep, где можно с лету начинать писать собственные паттерны, с CodeQL придется потратить время на изучения языка запросов.
- Время исполнения запросов к базе
Это больше относится к taint-анализу. Если кодовая база велика, то некоторые запросы могут исполняться крайне долго, что, пожалуй, не удивительно. С базой в 4 миллиона строк кода запрос мог исполняться до полутора часов. Иногда taint-анализ окончательно замораживался и не возвращался из состояния поиска путей.
- Лицензионные ограничения
Учитывая формальную сторону, Github не разрешает использовать CodeQL для создания и анализа кодовых баз в ряде случаев. Более подробная информация располагается в GitHub CodeQL Terms and Conditions.
- Мистика результатов DataFlow анализа
Ошибки случаются, даже у taint-движка CodeQL. Порой в результатах встречаются некоторые ноды taint-путей, которые не внушают доверия, и часто такие пути вовсе не существуют. Например:
Теперь вернемся к нашему проекту. Для начала создадим СodeQL базу данных из директории с кодом, вот так:
codeql database create my_db --language=cppПрикрепляем ее в VSCode в качестве основной базы и приступаем к поиску баг. В официальном репозитории CodeQL есть ряд готовых запросов для поиска некоторых типов уязвимостей. Попробуем воспользоваться одним из таких как раз для поиска ошибок типа double-free. Вот, что мы получим:
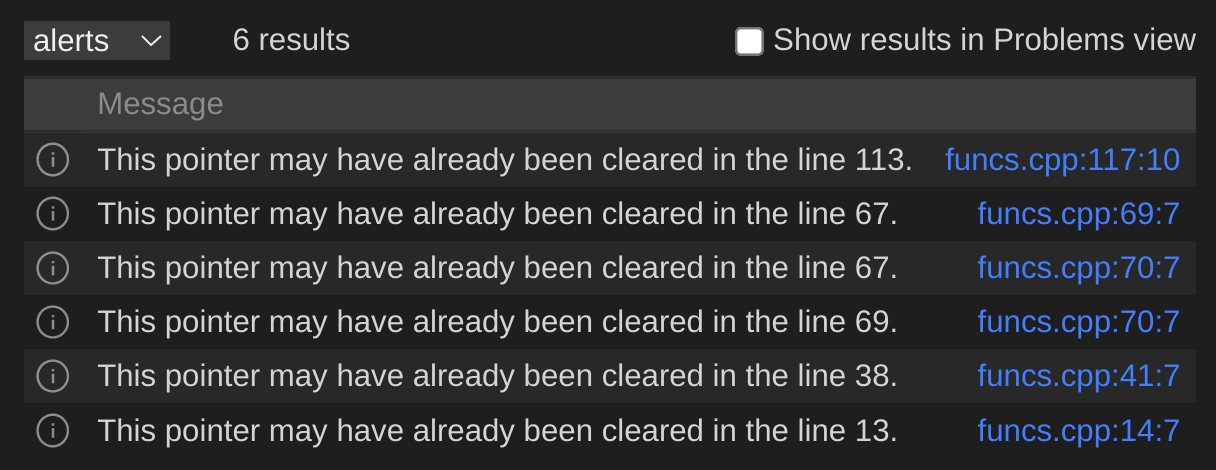
Как можно заметить, этот запрос не обнаружил double-delete, а также двойное освобождение через метод-обертку wrapper. Для новичков в CodeQL этот запрос может оказаться сложным и запутанным, поэтому попробуем создать наш собственный, поменьше и попроще, который будет обнаруживать конкретно double-delete в проекте.
Общий макет CodeQL-запросов обычно следующий:
import
import
from /* ... variable declarations ... */
where /* ... logical formulas ... */
select /* ... expressions ... */ Дополним его объектами FunctionCall и предикатами:
getTarget()— получает функцию этого вызова как отельный объект;getAPredecessor()— получает прямого предка данной ноды потока управления.
Теперь сформируем наш запрос:
import cpp
from FunctionCall fc, FunctionCall fc2
where
fc.getTarget().hasName("operator delete[]")
and fc2.getTarget().hasName("operator delete[]") and
fc != fc2 and fc.getAPredecessor*() = fc2
select fc, "Double-delete $@ and $@", fc2, "here", fc, "and here"Результат нас обрадует — CodeQL найдет примитивный double-delete, как мы и хотели:

Отлично, а теперь попробуем применить taint tracking и найти столько double-free, сколько сможем. Воспользуемся semmle.code.cpp.dataflow.TaintTracking для создания собственной taint-конфигурации, а также DataFlow::PathGraph для корректного отображения найденных путей.
/**
* @name Double free
* @kind path-problem
* @id double-free
*/
import cpp
import semmle.code.cpp.dataflow.TaintTracking
import DataFlow::PathGraph
class Config extends TaintTracking::Configuration {
Config() {this = "Double free"}
override predicate isSource(DataFlow::Node source) {
exists(FunctionCall call |
source.asDefiningArgument() = call.getArgument(0)
and
call.getTarget().hasGlobalOrStdName("free")
)
}
override predicate isSink(DataFlow::Node sink) {
exists(FunctionCall call |
call.getTarget().hasGlobalOrStdName("free")
and
sink.asExpr() = call.getArgument(0)
)
}
}
from Config config, DataFlow::PathNode source, DataFlow::PathNode sink
where config.hasFlowPath(source, sink)
select sink, source, sink, "Memory is $@ and $@, causing a potential vulnerability.", source, "freed here", sink, "here"Почти хорошо. Запрос успешно нашел вызов free в методе-обертке и обозначил путь требуемых данных (указателя на чанк) от источника к приемнику.
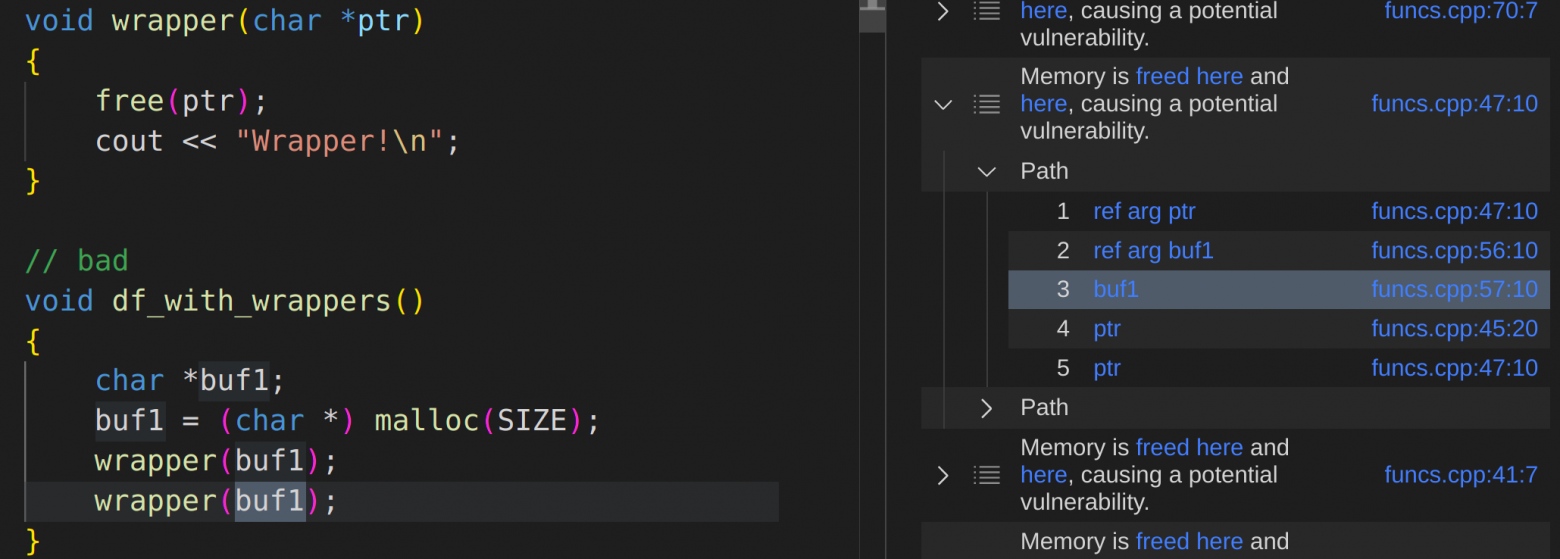
Однако CodeQL выдал один false-positive результат в кейсе с внутренним вызовом функции reassignment(char *ptr), где поинтер снова будет содержать адрес того самого чанка, который распределитель кучи достанет из корзины. К сожалению, переопределение предиката isSanitizer taint-конфигурации никак не смогло на это повлиять, так как taint path не включил в себя вызов этой функции, а значит и фильтрация будет безуспешной.
Таким образом, CodeQL — неплохой инструмент статического анализа, где результат сильно зависит от качества запросов, которые мы создаем к базе. CodeQL оставляет довольно противоречивое впечатление, так как несмотря на свой потенциал (особенно для объектно-ориентированных языков программирования) он имеет множество недостатков. В статье исследователя Valtteri Rahkonen «SAST Tool Comparison Using Secure C Coding Standard Examples», где сравнивались ряд open-source и коммерческих SAST-инструментов, CodeQL показал один из самых слабых результатов. Однако не будем останавливаться на плохой ноте. CodeQL может открыть большие возможности для исследования кода, что доказывает растущее число CVE, найденных с его помощью.
Weggli
Weggli — инструмент семантического поиска в кодовых базах на C/C++. Разработан исследователем Felix Wilhelm из Google Project Zero и опубликован осенью 2021 года с целью помочь ресечерам находить интересные места в больших кодовых базах. «Killer feature» данного инструмента — возможность исследовать C/C++ проекты без необходимости их сборки, в чем он очень похож на Semgrep.
На данный момент о Weggli не так много информации. Одна из немногих статей о Weggli от парочки бывалых пользователей CodeQL, «Playing with Weggli», рассказывает о попытках исследователей разобраться в синтаксисе запросов Weggli и получить желаемые результаты. В следующем github-репозитории содержится пример занятного Weggli-запроса для поиска double-free в ядре Linux. Мы тоже попробуем разобраться и создать свой запрос для поиска этой ошибки в нашем проекте. Но сперва отметим несколько особенностей инструмента.
Преимущества:
- Не требует сборки проекта
- Первоклассная поддержка C и C++
- Высокая скорость поиска
Недостатки:
- Отсутствие выделенной документации
- Мало примеров, статей от комьюнити и иных ресурсов, которые могли бы быть полезными для тех, кто пытается разобраться в работе инструмента
- Отсутствие межфайловой/межпроцедурной семантики
- Не умеет в Control Flow
Опишем конструкции Weggli, которыми воспользуемся для написания правила:
$func— переменная, в данном случае содержащая имя функции$ptr— переменная, обозначающая указатель, который хотим проследить в рамках double-freeNOT— отрицательный подзапрос, фильтрующий результаты по заданному условию_— любая AST-нода
Правило для поиска double-free в нашем проекте сделаем таким:
weggli --cpp -R '$func=free' '{ $func($ptr); NOT: $ptr = _; NOT: return; $func($ptr); }' ~/projectfuncs.cpp:9
void double_free()
{
char *buf1;
buf1 = (char *) malloc(SIZE);
**free(buf1);**
**free(buf1);**
}
funcs.cpp:29
void df_by_pointer()
{
..
char *buf3;
buf1 = (char *) malloc(SIZE);
buf2 = (char *) malloc(SIZE);
free(buf1);
**free(buf2);**
buf3 = (char *) malloc(SIZE);
**free(buf2);**
free(buf3);
}
funcs.cpp:61
void conditional_dfree()
{
int condition = 1;
char *ptr;
ptr = (char *) malloc(SIZE);
if (condition)
**free(ptr);**
**free(ptr);**
free(ptr);
}
funcs.cpp:61
void conditional_dfree()
{
int condition = 1;
char *ptr;
ptr = (char *) malloc(SIZE);
if (condition)
free(ptr);
**free(ptr);**
**free(ptr);**
}
funcs.cpp:61
void conditional_dfree()
{
..
char *ptr;
ptr = (char *) malloc(SIZE);
if (condition)
**free(ptr);**
free(ptr);
**free(ptr);** // Это прям нечто!
}
funcs.cpp:99
void intrnl_reassignment()
{
char *ptr;
ptr = (char *) malloc(SIZE);
**free(ptr);**
reassignment(ptr);
**free(ptr);**
}
funcs.cpp:109
void bad_goto()
{
char *ptr;
ptr = (char *) malloc(SIZE);
**free(ptr);**
goto free_me;
free_me:
**free(ptr);**
return;
}Weggli, как и ожидалось, не смог обработать внутренние вызовы, и поэтому пропустил double-free через вызов wrapper, выдал false-positive с переопределением указателя во внутреннем вызове reassignment и улыбнул на находке:
if (condition)
**free(ptr);** // first free
free(ptr);
**free(ptr);** // second free, это прям нечто!Составим аналогичный запрос для поиска double-delete — и Weggli хорошо справится с ним, успешно найдет этот простой кейс:
weggli --cpp 'delete $a; NOT: $a = _; delete $a' ~/projectWeggli — молодой инструмент и пока его функциональность не столь широка, как у Semgrep или CodeQL, но это отличное начинание. Ждем от Феликса новых идей и улучшений!
Joern

Joern — инструмент командной строки для статического анализа исходного кода и байт-кода от ShiftLeft. Реализован на языке Scala, а анализ кода выполняется с использованием языка запросов CPGQL, предметно-ориентированного языка (также основан на Scala), разработанного специально для работы с CPG (code property graph). CPG как понятие в контексте Joern является основообразующим, это описано в научной работе самих разработчиков — «Modeling and Discovering Vulnerabilities with Code Property Graphs». CPG представляет собой промежуточное представление кода, включает в себя AST проекта, Control Flow граф, информационные потоки и иные необходимые данные для дальнейшего анализа. Реализацию CPG можно найти в github-репозитории ShiftLeft.
Одноименный предок Joern со схожей концепцией анализа кода на основе CPG появился еще в далеком 2012 году и был представлен в рамках международной конференции ACSAC'12 (Annual Computer Security Applications Conference) исследователем Fabian Yamaguchi и командой компьютерной безопасности Геттингенского университета. CPG прежней реализации хранился в графовой СУБД Neo4J (в новом Joern заменен на OverflowDB), а в качестве языка запросов выступал Gremlin. На своем веку Joern-old успел обжиться собственной TrophyCase из нескольких десятков CVE. Однако ряд концептуальных недостатков с каждым годом становился все более явным, поэтому разработчики решили переосмыслить текущую реализацию и создать тот Joern, который есть сейчас.
Одной из главных особенностей Joern является возможность осуществления taint-анализа без необходимости сборки проекта. Эта мысль также поднимается в цикле статей о Joern, где исследователь сравнивает его работу с CodeQL на примере уже упомянутого CodeQL U-Boot challenge. Joern во многом не уступал в этом «версусе», и порой его запросы выглядели гораздо более компактными и эффективными. Посмотрим, насколько Joern хорош на деле. Но сперва отметим и другие положительные стороны Joern:
- Отличная документация как по работе с самим инструментом, так и к языку запросов CPGQL
- Не требует сборки проекта
- Имеет собственный Discord-чат для быстрой поддержки и обмена опытом
- Поддерживаемые языки: C/C++, Javascript, Kotlin, Python, Ghidra (x86/x64), JVM bytecode, LLVM bitcode
- Поддержка taint-анализа
- В наличии примеры запросов на CPGQL для разных языков, пусть и не в большом количестве
- На его основе сделан инструмент Joern Scan для сканирования кода и поиска некоторых категорий уязвимостей
- Расширяемость функционала плагинами, подробнее
Недостатки:
- Требуется знания не только CPGQL, но и основ Scala, чтобы создавать более-менее эффективные запросы
- Ruleset, к сожалению, совсем не велик
- Не для крупных проектов, т.к. создание CPG может быть крайне долгим или завершиться ошибкой в таких случаях
- Ошибки межпроцедурного анализа, приводящие к ложным срабатываниям. К ним мы еще вернемся.
Теперь попробуем создать собственные запросы для поиска double-free и double-delete. Первой командой, которую запустим в интерактивной оболочке, является importCode, которая создаст новый каталог проекта и сохранит в нем двоичное представление CPG:
██╗ ██████╗ ███████╗██████╗ ███╗ ██╗
██║██╔═══██╗██╔════╝██╔══██╗████╗ ██║
██║██║ ██║█████╗ ██████╔╝██╔██╗ ██║
██ ██║██║ ██║██╔══╝ ██╔══██╗██║╚██╗██║
╚█████╔╝╚██████╔╝███████╗██║ ██║██║ ╚████║
╚════╝ ╚═════╝ ╚══════╝╚═╝ ╚═╝╚═╝ ╚═══╝
Version: 1.1.1140
Type `help` or `browse(help)` to begin
joern> importCode(inputPath="путь_к_исходникам", projectName="имя_проекта")
res1: Cpg = Cpg (Graph [67082 nodes])Объект cpg является корневым всего языка запросов, так что чаще всего обращаться придется именно к нему и его предикатам. Например, хотим получить все вызовы free в проекте:
cpg.call("free").l.map(
call => (
call.id,
call.method.name,
call.code,
call.location.lineNumber match {
case Some(n) => n.toString
case None => "n/a"
}
)
) res3: List[(Long, String, String, String)] = List(
(24797L, "double_free", "free(buf1)", "13"),
(24799L, "double_free", "free(buf1)", "14"),
(24812L, "no_double_free", "free(ptr)", "22"),
(24820L, "no_double_free", "free(ptr)", "24"),
(24844L, "df_by_pointer", "free(buf1)", "37"),
(24846L, "df_by_pointer", "free(buf2)", "38"),
(24854L, "df_by_pointer", "free(buf2)", "41"),
(24856L, "df_by_pointer", "free(buf3)", "42"),
(24863L, "wrapper", "free(ptr)", "47"),
(24901L, "conditional_dfree", "free(ptr)", "67"),
(24903L, "conditional_dfree", "free(ptr)", "69"),
(24905L, "conditional_dfree", "free(ptr)", "70"),
(24918L, "free_null", "free(ptr)", "78"),
(24923L, "free_null", "free(ptr)", "80"),
(24966L, "intrnl_reassignment", "free(ptr)", "103"),
(24970L, "intrnl_reassignment", "free(ptr)", "105"),
(24983L, "bad_goto", "free(ptr)", "113"),
(24987L, "bad_goto", "free(ptr)", "117"),
(25005L, "good_goto", "free(ptr)", "127"),
(25011L, "good_goto", "free(ptr)", "131")
)Обратите внимание на первый атрибут id — значение типа Long, которое точно идентифицирует каждый узел графа потока управления (cfgNode в синтаксисе CPGQL). Опробуем же taint-анализ для поиска double-free!
Для этого создадим следующий запрос:
joern> run.ossdataflow // начиная с Joern v1.1.299 не обязателен к объявлению
joern> def source = cpg.call("free").argument
joern> def sink = cpg.call("free").argument
joern> sink.reachableByFlows(source).filter(f => f.elements.size > 1).pЗдесь мы объявили две переменные — source и sink, которые содержат единственный аргумент free — указатель, который мы хотим проследить по пути «порчи». Этим займется вызов reachableByFlows, который возвращает пути для потоков данных от источника к приемнику. filter (filter step) позволит продолжить обход для всех узлов графа, которые соответствуют его условию. В данном случае условие уберет так называемые «петли» (поток от вызова free к самому себе). Таковы особенности Joern.
Выхлоп будет следующий:
res10: List[String] = List(
"""____________________________________________________
| tracked | lineNumber| method | file |
|========================================================|
| free(ptr) | 113 | bad_goto | ~/sources/funcs.cpp |
| free(ptr) | 117 | bad_goto | ~/sources/funcs.cpp |
""",
"""_____________________________________________________________
| tracked | lineNumber| method | file |
|=================================================================|
| free(ptr) | 67 | conditional_dfree | ~/sources/funcs.cpp |
| free(ptr) | 69 | conditional_dfree | ~/sources/funcs.cpp |
| free(ptr) | 70 | conditional_dfree | ~/sources/funcs.cpp |
""",
"""_____________________________________________________________
| tracked | lineNumber| method | file |
|=================================================================|
| free(ptr) | 69 | conditional_dfree | ~/sources/funcs.cpp |
| free(ptr) | 70 | conditional_dfree | ~/sources/funcs.cpp |
""",
"""__________________________________________________________
| tracked | lineNumber| method | file |
|==============================================================|
| free(buf2) | 38 | df_by_pointer | ~/sources/funcs.cpp |
| free(buf2) | 41 | df_by_pointer | ~/sources/funcs.cpp |
""",
"""_____________________________________________________________________________
| tracked | lineNumber| method | file |
|=================================================================================|
| free(ptr) | 103 | intrnl_reassignment | ~/sources/funcs.cpp |
| reassignment(ptr) | 104 | intrnl_reassignment | ~/sources/funcs.cpp |
| reassignment(char *ptr) | 92 | reassignment | ~/sources/funcs.cpp |
| void | 92 | reassignment | ~/sources/funcs.cpp |
| reassignment(ptr) | 104 | intrnl_reassignment | ~/sources/funcs.cpp |
| free(ptr) | 105 | intrnl_reassignment | ~/sources/funcs.cpp |
""",
"""________________________________________________________
| tracked | lineNumber| method | file |
|============================================================|
| free(buf1) | 13 | double_free | ~/sources/funcs.cpp |
| free(buf1) | 14 | double_free | ~/sources/funcs.cpp |
""",
"""_____________________________________________________________
| tracked | lineNumber| method | file |
|=================================================================|
| free(ptr) | 67 | conditional_dfree | ~/sources/funcs.cpp |
| free(ptr) | 69 | conditional_dfree | ~/sources/funcs.cpp |
"""
)К сожалению, результат taint-анализа содержит ряд ошибок. Несомненно, он смог обнаружить примитивные кейсы двойного освобождения, кейсы с if-блоком и goto, но не нашел случай с оберткой над free (вызовы wrapper), выдал ложноположительный результат с внутренним переназначением указателя (вызов reassignment). Исследуя, почему произошли такие ошибки, мы выяснили:
1) У Joern нет какой-либо кастомизации taint-конфигурации, кроме назначения непосредственного источника/приемника данных. В секции «Data-Flow Steps» документации не обнаружилось каких-либо примитивов, которыми можно было бы воспользоваться и, к примеру, ограничить пути с учетом собственных требований. Да, это прямой намек на CodeQL и его предикаты isSanitizer и isBarrier, которые позволяют настраивать анализ с заданными условиями. Это могло бы помочь отфильтровать часть ложноположительных путей, не связанных с уязвимостью.
2) Ложноотрицательный результат:
Joern не выдал результат с вызовом free в обертке, и было принято решение сделать еще один маленький taint-анализ от аргумента первого вызова wrapper(buf1) (funcs.cpp:56) к аргументу free:
joern> def source = cpg.call.id(28247).argument
joern> def sink = cpg.call("free").argument
joern> sink.reachableByFlows(source).pРезультат оказался странным:
"""_______________________________________________________________________
| tracked | lineNumber| method | file |
|=========================================================================|
| wrapper(buf1) | 56 | df_with_wrappers | ~/sources/funcs.cpp |
| wrapper(buf1) | 57 | df_with_wrappers | ~/sources/funcs.cpp |
| wrapper(char *ptr) | 45 | wrapper | ~/sources/funcs.cpp |
| free(ptr) | 47 | wrapper | ~/sources/funcs.cpp |
"""То есть, Joern видит в контексте этой ситуации только один вызов free, а значит double-free здесь тоже не может существовать, что неверно.
3) Ложноположительный результат:
Внутреннее переназначение указателя (вызов reassignment) на пути между двумя вызовами free защищает от ошибки, но Joern так не посчитал. Исследуя проблему, оказалось, что мы не единственные, кто столкнулся с ней. Было обнаружено открытое issue «Dataflow inconsistency related to reassignment and subcalls» в github-репозитории Joern, где рассматривается крайне схожая ситуация с внутренними вызовами и переназ
