Разрабатываем софт через статистику
КДПВ не будет, извиняйте. Значение имеют только текст, тесты и статистика :)
Сам термин Statistics Driven Development (сокращенно SDD) я ввел в my.games году в 2017 м, но среди очень небольшого количества людей и до сих пор не встречал его в статьях. Самому мне было лень писать куда-то, кроме чатиков. Увы.
Возможно, этот подход давно существует и просто я не в курсе. Скажите, плиз, если это так.
Ну и еще один дисклеймер: возможно, при чтении может показаться, что это про мониторинг. В какой-то мере да, но есть важные нюансы, как мне кажется.
Давным давно в кругу разработчиков известен подход TDD, предполагающий написание тестов до написания работающего кода. Подход в теории интересный, но у меня не прижился и я не видел ни одного большого и/или успешного проекта, в котором этот подход бы применялся.
В любом случае среди программистов считается, что код, не покрытый тестами, скажем так, дурно пахнет. Для серверсайдного кода это, на мой взгляд, очень верное утверждение. А вот для клиентского оно разбивается о будни реальности: когда используешь огромное количество внешних библиотек и зависимостей, далеко не всегда являющихся надежными, апп может ломаться совершенно не там, где ожидаешь и где тестировал.
В общем, всё написанное далее касается лишь клиентсайдного кода, вне зависимости от платформы и справедливо и для десктопной, и для мобильной разработки.
Блочные тесты требуют огромного количества стабов и тестируют, в сущности, и так довольно надежную часть кода — ту, что написал сам программист, не затрагивая взаимодействия с другими библиотеками, на которых и случаются самые серьезные баги. Интеграционные тесты же сложны в исполнении и требуют поддержки большого количества изолированных конфигураций окружения. И те, и другие тесты сложны в написании и делают тестируемый код более запутанным и сложным. В общем, выглядит оно круто, но совершенно непонятно, какие бизнесовые KPI решает.
В моей практике хорошо зарекомендовал себя подход, когда ключевые места в коде отправляют в базу статистики деперсонализированные данные, а на сервере выполняются проверки, соответствуют ли пришедшие данные ожиданиям. Проверки выполняются как вручную, так и с помощью SQL запросов и отдельных скриптов. Разброс интервалов cron-проверок в проектах, где я участвовал, составлял от 5 минут до 4 часов — в зависимости от объемов данных. Чем больше данных приходит за минуту, тем меньше можно делать интервал проверки, чтобы минимизировать вероятность случайных выбросов.
В реализации, использующейся в Игровом центре my.games, запаздывание между отправкой данных клиентом и размещением их в БД в пригодном для анализа виде составляло около 90 секунд. Это время легко сократить в разы, но на практике оказалось, что и 90-секундное отставания комфортно для очень быстрых итераций «тестировщик увидел ошибку — разработчик сразу же посмотрел по базе детали того, что случилось».
Классной вещью в применении SDD является то, что при написании кода вместе с assert’ами пишется отправка данных в стату о недопустимых или подозрительных ситуациях. Таким образом, уже на этапе первых прогонов у тестировщиков по статистике видно, соответствует ли поведение программы ожидаемому.
Кроме ручных проверок по базе выполнялись, например, такие тесты (числовые показатели пишу условно — они в данном случае не принципиальны):
— количество исключений в проекте для последней зарелизенной версии за последние 10 минут не больше 2% от количества запусков;
— количество установок каждой из ключевых игр за последние 30 минут составляет не менее 50% от количества, которое было час назад и не менее 70% от того, что было сутки и неделю назад;
— push-уведомления дошли до пользователя не позднее 20 секунд с момента отправки серверным кодом не менее чем в 80% случаев и не позднее 1 минуты не менее чем в 90% случаев.
В случае, если на пути реализации функции стояло несколько участников (как, к примеру, с пушами, за которые отвечало сразу четыре команды), то можно было отправлять промежуточные состояние подсистем в общую стату, таким образом понимая, на каком именно этапе проблема.
Иллюстрацией могу привести отчет по одному из аппов, наглядно показывающий, в каком месте бага:
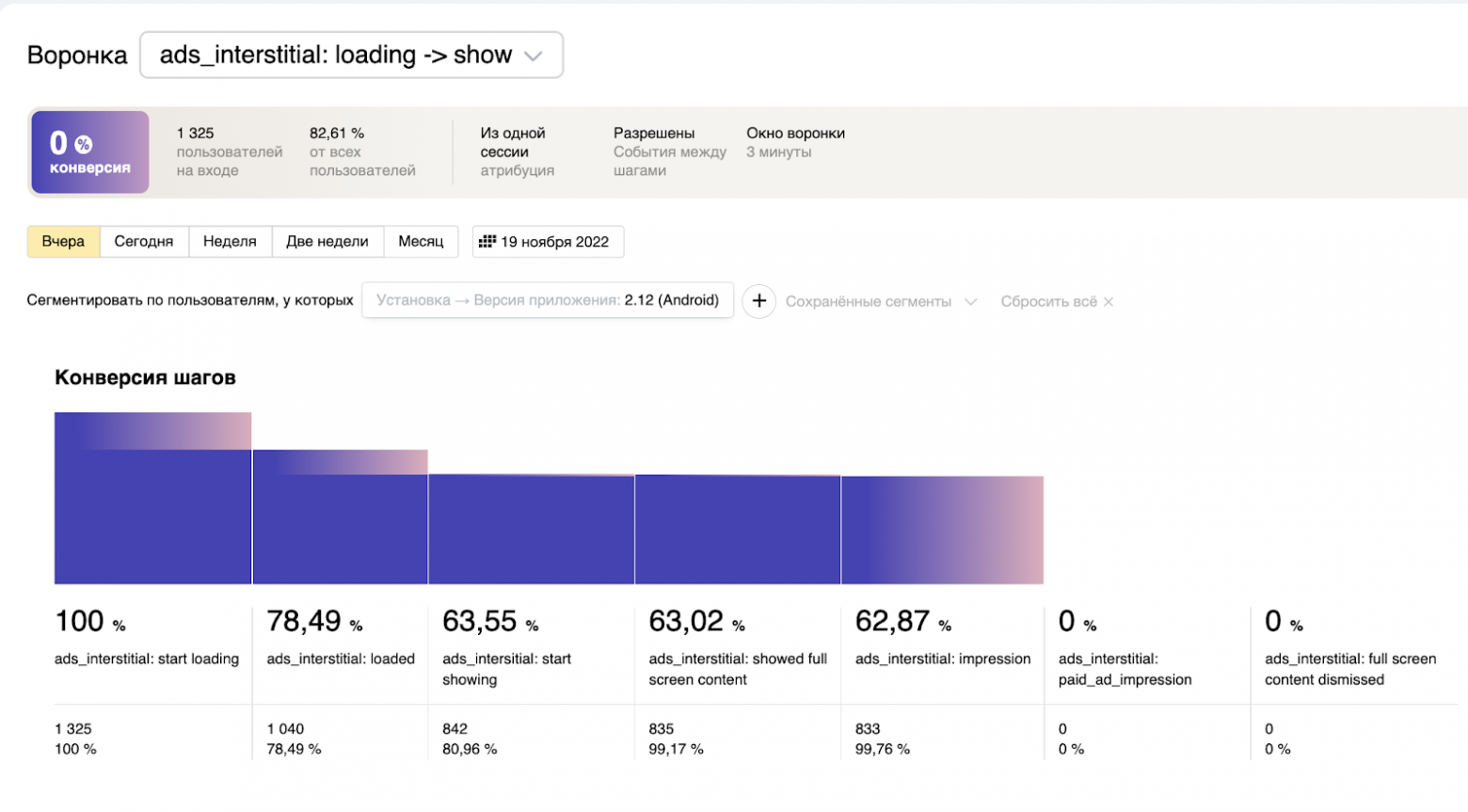
(в каком месте проценты упали до нуля — там и надо искать проблему)
Имеющаяся в my.games статистика удобным образом сочетает real-time мониторинг с ретроспективным анализом за много лет. Несколько раз были попытки от техдиров разделить эти две вещи, но каждый раз мне удавалось отстоять имеющийся подход.
В общем, в эту базу (с некоторыми ограничениями) одновременно лазали разрабы, маркетинг и менеджеры продуктов, т.к. только в ней были гарантии целостности данных (как раз из-за отсутствия разницы между real-time и аналитическими подсистемами).
Ключевые выигрыши от подхода SDD следующие:
1. Для внутреннего тестирования аппа будет достаточно «протыкать» основные кейсы на тестовых девайсах и, можно даже ничего не говорить разрабам — по стате будет видно, всё ли более-менее в порядке. Релизы будут качественнее.
2. При количестве устройств, использующих новую версию, в 200–300 штук, будут видны почти все баги — это означает, что после выкатки в течение нескольких минут можно принять решение, отзываем версию, или нет. Меньше потерь монетизации.
3. При проблемах в проде источник проблемы детектится за несколько минут. Автоматически или ручками, запросами к базе — в зависимости от того, насколько подходящими оказались автоматические тесты для возникшей проблемы. Меньше фрустрации.
4. Писать такие тесты на порядки проще, чем классические тесты в коде, т.к. этот подход требует, чтобы код в приложениях вообще никак не отличался от обычного, за исключением компактных и очень простых строк отправки событий. Поэтому тесты отражают реальную ситуацию и при этом не отвлекают разрабов от решения бизнесовых задач. Нет замедления процесса разработки.
Если интересно, могу написать продолжение о том, как всё это внедрялось.
