Самоучитель клингонского
Пару лет назад мы рассказали о том, как в системе Антиплагиат устроен поиск русского перевода английских статей. Естественно, без машинного переводчика в алгоритме не обойтись. В основе машинного переводчика, конечно, лежит машинное обучение, которое, в свою очередь, требует весьма значительного количества «параллельных предложений», т.е. одинаковых по смыслу предложений, написанных на двух языках. Значительное количество — это миллионы предложений, и чем больше, тем лучше. Понятно, что для русско-английской пары найти такую базу (в том числе и в открытом доступе) реально. А что делать с теми языковыми парами, для которых параллельных предложений принципиально не может быть слишком много?
Казалось бы, не имея в распоряжении большого объема обучающих примеров, обучить систему машинного перевода невозможно. Но на помощь приходит идеология Unsupervised Learning, или «обучение без учителя». Ну, а чтобы задача была действительно интересной (особенно порадует она фанатов вселенной Стартрека), мы будем обучать наш машинный переводчик для пары языков «английский — клингонский».
 Источник картинки: Собственное творчество от команды Антиплагиата
Источник картинки: Собственное творчество от команды Антиплагиата
А самым подходящим девизом к дальнейшему рассказу о применении Unsupervised Learning будет знаменитая выдержка из Инструкции клингонского почетного караула «Если не можешь контролировать себя, тебе не дано командовать другими».
Для тех, кто еще не стал фанатом Стартрека, клингонский язык — это искусственно созданный язык, на котором говорят клингоны в популярной американской киновселенной «Звездный путь». Для этого языка существует несколько систем письма, мы возьмем наиболее простую для нашей задачи систему на основе латиницы. Вообще, создавать свои языки для вымышленных миров — это довольно популярная тема. Вспомнить хотя бы Толкиена, который создал синдарин — язык эльфов в фантастическом мире «Властелин колец». Более свежие примеры — это дотракийский из «Игры престолов» или на«ви из «Аватара». Впрочем, для нашей задачи конкретный выбор языка не так уж важен, главное, чтобы в какой-нибудь библиотеке не лежало пару тысяч томов текста на этом языке — иначе станет неинтересно.
Концепция «Unsupervised Learning» подразумевает обучение моделей (математических, поручик, математических :)) без использования размеченных данных. В нашем случае это обучение системы машинного перевода без корпуса параллельных предложений (или с очень маленьким объемом). Применять обучение без учителя для задачи перевода стали не так давно. Здесь и здесь есть статьи, в которых впервые был описан одними один из самых популярных на сегодня методов решения нашей задачи. Этот метод мы и постараемся сегодня применить.
Сразу оговорим тот факт, что для построения переводчика мы все же будем использовать параллельный корпус, но только для побочных задач: построения словаря и дообучения модели. Дообучение модели опционально, его можно и не делать, а вместо построения словаря из параллельных предложений можно воспользоваться готовым (разумеется, если он есть). В любом случае, при подходе, описанном ниже, нам понадобится намного меньший корпус параллельных предложений, чем при обучении переводчика «в лоб», это будет видно в конце статьи.
Основной алгоритм построения модели переводчика без параллельных предложений можно описать следующим образом:
- построение векторных представлений для обоих языков;
- выравнивание векторных пространств;
- инициализация модели перевода пословным переводом (обучение переводчика);
- итеративное улучшение модели с помощью обратного перевода.
Далее поговорим о каждом пункте.
Векторизация слов
Элементарная смысловая составляющая языка — это слово. Если человек начинает учить незнакомый язык, то, как правило, он старается запомнить самые частые слова. Подобный принцип лежит в основе модели машинного перевода: на самом нижнем уровне оперируем словами (хотя это не всегда правда, но про BPE сегодня говорить не будем). С точки зрения компьютера слово — это только последовательность кодов символов. Никакого дополнительного смысла эта последовательность не несет. Поэтому слова надо каким-то образом «оцифровывать». Проще говоря, надо переводить слово в некоторый уникальный вектор или эмбеддинг. Построение такого преобразования само по себе очень большая и интересная задача, которая до сих пор актуальна. Причем решается эта задача чаще всего как раз с помощью Unsupervised Learning. Почитать о примерах реализации можно, например, здесь. Нам же важно, что такие модели существуют и обладают одним очень важным свойством: они подчиняются дистрибутивной гипотезе. Это значит, что слова, которые часто встречаются в одном контексте, в этом векторном пространстве будут располагаться ближе друг к другу. А слова, которые редко или вообще не встречаются в одном контексте, будут в этом векторном пространстве разнесены далеко. Таким образом, векторы слов образуют некоторую структуру в этом построенном пространстве.
Выравнивание векторных пространств
Можно предположить, что в идеальном случае такие структуры будут очень похожи для разных языков. На этом предположении и строится идея выравнивания эмбеддингов для разных языков. Имея два векторных пространства слов для разных языков, мы пытаемся максимально совместить их, чтобы сопоставить слова из разных языков друг с другом. Можно посмотреть наглядную иллюстрацию из статьи.
Самое логичное в данной задаче — использовать словари, которые, по сути, являются естественным отображением слов одного языка в слова другого языка. Если же словаря под рукой нет, можно получить его из небольшого набора параллельных предложений. В нашем эксперименте мы воспользуемся утилитой fast_align. Здесь надо сказать, что методы выравнивания векторных пространств на основе словарей работают неплохо, но порой с ними возникают проблемы. Во-первых, одному слову в словаре всегда соответствует несколько значений из другого языка — не всегда понятно, как работать с такой избыточной информацией. Во-вторых, пытаясь совместить векторные пространства по словарям, мы можем потерпеть неудачу, потому что словари составлены по совершенно другой структуре. Ну и наконец, бывают экзотические случаи, когда языковая пара, для которой мы хотим построить перевод настолько редка, что нет ни словаря, ни параллельного корпуса. Для таких случаев существуют методы выравнивания векторных пространства слов без использования информации из словарей. Про оба метода, как со словарем, так и без словаря, можно почитать, например, здесь.
Обучение переводчика
Итак, мы умеем переводить слово в вектор, а по вектору восстанавливать наиболее похожее слово из целевого языка. И уже теперь мы можем построить простейший переводчик. А именно: мы можем переводить предложения по отдельным словам. Конечно, это очень слабая модель перевода, но для начальной инициализации подойдет и такая. Теперь, имея простейшую модель перевода, мы можем сами порождать параллельные предложения. Конечно же, полученные параллельные предложения окажутся очень плохого качества — в них никак не будет учитываться грамматика языка. Самое время вспомнить о принципе обучения автокодировщиков для текстов.
Совсем недавно мы рассказывали, как модели автокодировщиков учатся восстанавливать зашумленный вход, чтобы настраивать свои параметры. В данном случае, полученный нами «плохой» параллельный корпус можно рассматривать как «зашумленную» версию перевода. И, пользуясь тем же способом, что и автокодировщики, мы можем учить модель восстанавливать истинный перевод. Для нашей пары «английский-клингонский» алгоритм выглядит следующим образом:
- переводим предложение с английского на клингонский «по словам»;
- переводим нашей моделью перевода с клингонского на английский;
- настраиваем параметры модели перевода, минимизируя разницу между исходным предложением и полученным после двойного перевода.
Стоит подчеркнуть, при данном подходе довольно логично обучать сразу две модели машинного перевода: с исходного языка на целевой и наоборот. Действительно, после некоторого числа итераций машинный переводчик достигнет качества пословного перевода (в теории) и больше не сможет улучшаться, так как корпус параллельных предложений так и остался «зашумленным». Поэтому в процессе обучения сгенерированный параллельный корпус надо периодически обновлять, переводя предложения более качественным обученным переводчиком. Казалось бы, пошагово улучшая переводчик на каждом шаге, мы в итоге должны получить идеальную модель. Если бы все было так просто! Мы не можем внести в модель больше информации, чем содержится в самом корпусе предложений изначально. К тому же, методы обучения машинного перевода, которые мы здесь рассматриваем, базируются на довольно сильных предположениях, которые на практике не совсем верны.
Модели перевода
То, какую модель перевода выбрать — отдельный вопрос. Глобально все модели можно разделить на два семейства: нейросетевые и статистические. Большим прорывом в области нейросетевого перевода стала архитектура трансформера, про который можно почитать в этой статье. У таких моделей есть большой недостаток: они требуют большого объема обучающей выборки. Причем данные в этой выборке должны быть достаточно хорошего качества. Статистические модели более просты и требуют гораздо меньшего объема данных для настройки параметров. Конечно, качество перевода у них, соответственно, будет ниже, но, как мы говорили в предыдущих статьях, нам не обязателен идеальный «читаемый» перевод. Достаточно, чтобы качества перевода хватало для дальнейших этапов работы.
Эксперименты
Продемонстрируем все теоретические выкладки на примере. Сразу оговоримся, что эксперименты несут чисто демонстративный характер и всего лишь иллюстрируют примерный ход экспериментов при построении модели.
Самое важное при построении новой модели машинного перевода — сбор данных. В случае с редкими языками вопрос сбора данных стоит особо остро, так как данных для таких языков не так много. Для клингонского языка мы подобрали несколько ресурсов, на которых можно было найти как параллельные данные (клингонский-английский), так и моноязыковые данные (предложения только на клингонском). В первую очередь, это сайт с открытыми параллельными корпусами, а также аналог Википедии на клингонском. С моноязыковыми данными для английского языка проблем, разумеется, нет, но мы ограничили размер выборки, чтобы сохранить баланс обучающих данных.
Что ж, у нас есть изложенный выше план, будем его придерживаться. Сначала надо обучить две модели векторизации слов для каждого языка по отдельности. Процедура эта довольно стандартная, и интересного в ней нет ничего.
Имея в распоряжении два векторных пространства слов, попробуем их выровнять друг относительно друга. Для этого будем использовать метод MUSE.
Попробуем перевести случайное слово с английского на клингонский с помощью полученной модели. Клингонцы — довольно воинственный народ, в языке которого много слов, связанных с оружием, битвами и пр. Поэтому логичнее всего посмотреть, как переводятся слова, связанные с ратным делом. Посмотрим на топ-5 ближайших слов из клингонского к словам «war» и «kill».
Носителей клингонского среди нас нет, поэтому оценить адекватность полученного перевода сложновато. Понадеемся на способности искусственного интеллекта и для проверки воспользуемся переводчиком Bing (разработчики которого, судя по плашке на странице переводчика, разработали перевод вместе с Институтом клингонского языка):

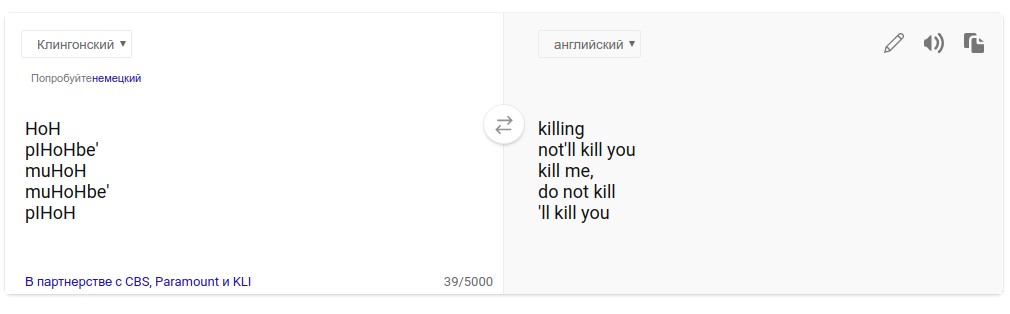
Видно, что хотя в топ-5 соседей к исходному слову «war» попал мусор (The unseen good old man), в целом нам удалось построить выравнивание.
А дальше следует непосредственно процесс обучения самой модели переводчика. Как мы говорили выше, для начальной инициализации создадим параллельный корпус, состоящий из пословного перевода предложений. На каждой следующей итерации будем обновлять этот корпус переводами нашей модели (которая, в теории, должна становиться лучше и лучше с каждой итерацией).
Посмотрим, как же работает наша модель после нескольких итераций обучения. Для оценки качества необходим истинный параллельный корпус. В качестве такого воспользуемся отрывком из Гамлета, который был переведен специалистами клингонского языка. Хотя клингонский канцлер Горкон уверен, что изначально перевод был сделан в другую сторону: «Вы никогда не поймете Шекспира, пока не прочитаете его в оригинале, на клингонском».

Обложка издания «Hamlet Prince of Denmark: The Restored Klingon Version», The Klingon Language Institute printed version, USA, 1996
Вот результат:
continuous or not.
now reference question.
like, noted since nice primarily, severely respectively condition?
or, crisis regulation battle bore condition,
and, fought, sudden?
died; sleeping
Qapla»! У нас даже есть одинаковые слова! Учитывая все допущения, которые мы сделали (чересчур маленький объем выборки, простая модель перевода и прочее), наличие хотя бы совпадающих слов уже является успехом.
При переводе текста модель статистического перевода учитывает несколько факторов (языковая модель, условные вероятности и пр.) с различными весами. Эти веса мы можем подкорректировать, дообучив модель на параллельном корпусе. В итоге перевод слегка улучшился:
be or not.
now example question.
like, noted since nice primarily, severely respectively condition?
or, crisis regulation battle bore condition,
and, fought, sudden?
died; sleeping
Для сравнения, посмотрим, как бы выглядел перевод, если бы мы воспользовались обычным машинным переводчиком, обучающимся на нашем параллельном корпусе:
sentence no survive. now vIqelnIS. to
a nice San, yabDaq quv’a' pu' SIQDI',? and cha
no, SuqDI' SuvmeH bIQ’a'Hey, nuHmey trouble
and rInmoHDI',, Suvmo'?
died.
sleep .
Может и норм, но для меня качество последнего перевода сопоставимо с дерьмом тарга.

Источник изображения: Кадр со съемочной площадки, снят во время производства 5 эпизода «Там, где никто не бывал», «Звездный путь: следующее поколение», 1987
Естественно, наш перевод тоже далек от идеала, но в целом возможность получить переводчик на основе очень маленького словаря и текстового массива на неизвестном нам языке поражает и радует. В реальности, конечно же, все происходит чуточку сложнее, и можно добиться довольно сносного качества перевода. Часто применяется комбинация нескольких переводчиков, как unsupervised, так и обученных традиционным способом. Можно значительно улучшить перевод, проанализировав особенности интересующего нас языка, но это уже совсем другая история. Впрочем, если вкратце, то мы уже занимаемся разработкой универсального алгоритма поиска текстовых пересечений для любых заданных пар языков и даже выиграли грант на этот проект от РВК .
Кроме того, в случае поиска переводных заимствований, как мы уже говорили, использование перевода по прямому назначению не предполагается. Полученный перевод далее используется модулем поиска заимствований, который не так требователен к качеству перевода. Однако это не отменяет того, что эту технику можно использовать и для построения модели, которая будет генерировать «читаемый» перевод. Об этом мы напишем в других статьях.
Большое спасибо Наталье Поповой за полезные консультации по вселенной Стартека и моим коллегам за помощь в подготовке статьи.
