Книга «Глубокое обучение с подкреплением. AlphaGo и другие технологии»
 Привет, Хаброжители! Мы издали книгу Максима Лапаня shmuma, это — подробное руководство по новейшим инструментам глубокого обучения с подкреплением и их ограничениям. Мы реализуем и проверим на практике методы кросс-энтропии и итерации по ценностям (Q-learning), а также градиенты по стратегиям.
Привет, Хаброжители! Мы издали книгу Максима Лапаня shmuma, это — подробное руководство по новейшим инструментам глубокого обучения с подкреплением и их ограничениям. Мы реализуем и проверим на практике методы кросс-энтропии и итерации по ценностям (Q-learning), а также градиенты по стратегиям.
Для экспериментов используются самые разные среды обучения с подкреплением (RL), начиная с классических CartPole и GridWorld и заканчивая эмуляторами Atari и средами непрерывного управления (на основе PyBullet и RoboSchool). Множество примеров основано на нестандартных средах, в которых мы с нуля разработаем модель окружения.
Для кого эта книга
Основная целевая аудитория — люди, которые обладают знаниями о машинном обучении и хотят на практике разобраться в том, что такое обучение с подкреплением. Читатель должен быть знаком с языком Python и основами глубокого и машинного обучения. Дополнительным плюсом будет знание статистики, но это не абсолютно необходимо для понимания большинства материала.
Глава 2 «OpenAI Gym» ознакомит читателя с практическим аспектом обучения с подкреплением с помощью библиотеки Gym с открытым исходным кодом.
Глава 3 «Глубокое обучение с помощью PyTorch» представляет собой краткий обзор библиотеки PyTorch.
Глава 4 «Метод кросс-энтропии» расскажет об одном из простейших методов обучения с подкреплением, помогая получить общее понимание проблем и методик данной области.
Глава 5 «Динамическое программирование и уравнение Беллмана» — это введение в семейство методик обучения с подкреплением с оценкой состояния.
Глава 6 «Глубокие Q-сети» описывает DQN — расширение базовых методов оценки состояний, которые позволяют работать над сложными средами.
Глава 7 «Расширения для DQN» дает детальный обзор современных расширений метода DQN, обеспечивающих бˆольшие стабильность и сходимость в сложных средах.
Глава 8 «Торговля акциями с использованием обучения с подкреплением» — это первый практический проект, в котором метод DQN применен к торгам на бирже.
Глава 9 «Градиенты по стратегиям» рассматривает другое семейство методов RL на основе оптимизации стратегии.
Глава 10 «Метод актора-критика» описывает один из наиболее широко используемых методов в RL.
Глава 11 «Асинхронный метод актора-критика» расширяет метод актора-критика взаимодействием с параллельными средами, чтобы улучшить стабильность и сходимость.
Глава 12 «Тренировка чат-ботов с помощью обучения с подкреплением» — второй проект, в котором методы обучения с подкреплением применены к задачам NLP.
Глава 13 «Веб-навигация» — еще один большой проект с применением обучения с подкреплением к навигации по веб-страницам; в нем использован набор задач MiniWoB.
Глава 14 «Непрерывное пространство действий» описывает специфику сред с использованием непрерывного пространства действий.
Глава 15 «Доверительные области — TRPO, PPO и ACKTR» — это еще одна глава о непрерывных пространствах действий, описывающая набор методов доверительной области.
Глава 16 «Оптимизация методом черного ящика в RL» показывает другой набор методов, не использующих градиенты в явном виде.
Глава 17 «Методы, основанные на моделях среды: воображение» представляет основанный на моделях подход к RL с использованием результатов последних исследований о воображении в RL.
Глава 18 «AlphaGo Zero» описывает метод AlphaGo Zero в применении к игре Connect Four.
Обучение seq2seq
Все это очень интересно, но как связано с RL? Связь заключается в процессе обучения модели seq2seq. Но прежде, чем перейти к современным подходам RL к проблеме, мы должны сказать пару слов о стандартном способе обучения.
Обучение с использованием максимального правдоподобия
Представьте, что нужно создать систему машинного перевода с одного языка (скажем, французского) на другой (английский), используя seq2seq. У нас есть хороший, большой набор предложений, переведенных с французского на английский, на которых мы собираемся обучать нашу модель. Как это сделать?
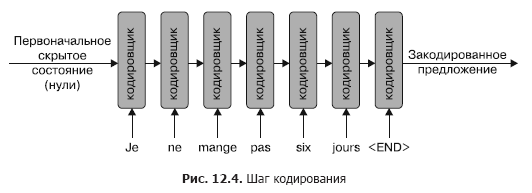
Фаза кодирования очевидна: мы применяем кодировщик к первому предложению в обучающей паре, создавая его закодированное представление. Естественным кандидатом на это представление будет скрытое состояние, возвращаемое из последнего применения RNN. На этапе кодирования мы игнорируем выход RNN, принимая во внимание только скрытое состояние из последнего применения RNN. А также расширяем предложение специальным токеном , который сигнализирует кодировщику об окончании предложения. Этот процесс показан на рис. 12.4.
Чтобы начать декодирование, мы передаем закодированное представление во входное скрытое состояние декодировщика с токеном в качестве сигнала для начала процесса. На данном этапе декодировщик должен вернуть первый токенпереведенногопредложения. Однако в начале обучения, когда кодировщик и декодировщик инициализируются случайными весами, выход декодировщика будет случайным, и наша цель заключается в том, чтобы подтолкнуть его к правильному преобразованию с помощью стохастического градиентного спуска (SGD).
Традиционный подход состоит в том, чтобы рассматривать эту проблему как задачу классификации, когда декодировщику необходимо вернуть распределение вероятностей по токенам в текущей позиции декодированного предложения. Обычно это делается преобразованием выходных данных декодировщика с использованием неглубокой (1–2 слоя) полносвязной сети, возвращающей вектор, длина которого равна размеру нашего словаря. Затем мы берем это распределение вероятностей и стандартные потери для задач классификации — перекрестную энтропию (известную также как потери максимального правдоподобия).
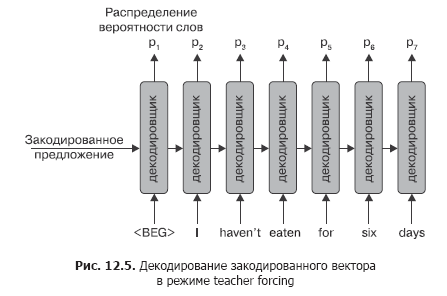
С первым токеном в декодированной последовательности, который должен порождаться токеном , заданным на входе, все ясно, но как насчет остальной части последовательности? Здесь есть два варианта. Первый — подача токенов из сопоставляемого предложения. Например, если у нас есть тренировочная пара Je ne mange pas six jours –> I haven’t eaten for six days, мы подаем токены (I, haven«t, eaten…) в декодировщик и затем используем потери на перекрестную энтропию между выводом RNN и следующим токеном в предложении. Этот режим обучения называется управляемым учителем (teacher forcing), и на каждом шаге мы вводим токен из правильного перевода, запрашивая у RNN корректный следующий токен. Данный процесс показан на схеме (рис. 12.5).
Выражение для потерь в предыдущем примере будет рассчитываться следующим образом:
L = xentropy(p1,"I") + xentropy(p2,"haven't") + xentropy(p3,"eaten") +
xentropy(p4,"for") + xentropy(p5,"six") + xentropy(p6,"days") +
xentropy(p7,"")
Поскольку и кодировщик, и декодировщик — это дифференцируемые НС, мы можем применить алгоритм обратного распространения к ошибке, чтобы принудить их обоих лучше классифицировать этот пример в будущем, тем же способом, каким обучаем, например, классификатор изображений.
К сожалению, предыдущая процедура решает проблему обучения seq2seq не полностью, что связано с тем, как модель будет использоваться после обучения. Во время обучения мы знаем как входную, так и желаемую выходную последовательности, поэтому можем передать действительную выходную последовательность в декодировщик, от которого требуется только создание следующего токена последовательности.
После обучения модели у нас не будет целевой последовательности, так как предполагается, что эта последовательность будет создана моделью. Таким образом, простейший способ использования модели — кодировать входную последовательность с помощью кодировщика, а затем попросить декодировщик генерировать один элемент вывода за раз, подавая полученный токен на вход декодировщика.
Передача предыдущего результата во входные данные может выглядеть естественно, но здесь есть опасность. Во время обучения мы не просили декодировщик задействовать собственный вывод в качестве входных данных, поэтому одна-единственная ошибка во время генерации может сбить с толку декодировщик и привести к выводу мусора.
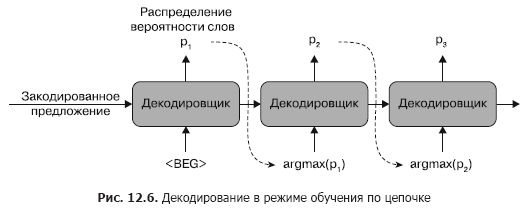
Чтобы не допустить этого, существует второй подход к обучению seq2seq, называемый обучением по цепочке (curriculum learning). Этот метод использует те же самые потери на перекрестную энтропию, но вместо передачи полной целевой последовательности в качестве входных данных декодировщика мы просто просим его декодировать последовательность таким же образом, каким собираемся применять ее после обучения. Данный процесс иллюстрируется на следующей схеме (рис. 12.6). Это добавляет надежности декодировщику, что дает лучший результат при практическом применении модели.
Недостатком этого режима может быть очень длительное обучение, так как декодировщик выучивает, как производить желаемый выход токен за токеном. Чтобы компенсировать это, на практике мы обычно обучаем модель с использованием как управляемого учителем, так и обучения по цепочке, просто выбирая случайным образом между ними для каждого обучающего набора.
Оценка Bilingual evaluation understudy
Прежде чем перейти к основной теме этой главы (RL для seq2seq), нам нужно ввести параметр, применяемый для сравнения качества вывода машинного перевода и обычно используемый в задачах NLP. Параметр Bilingual evaluation understudy (BLEU) является одним из стандартных способов сравнения выходной последовательности, создаваемой машиной, с некоторым набором опорных выходов. Он позволяет задействовать несколько эталонных выходов (одно предложение может быть переведено различными способами) и, по сути, вычисляет соотношение униграмм, биграмм и т. д., которые совместно используются полученными выводами и ссылочными предложениями.
Существуют и другие альтернативы, такие как CIDEr и ROGUE. В этом примере мы применяем BLEU, реализованный в библиотеке nltk из Python (пакет nltk.translate.bleu_score).
RL в seq2seq
RL и порождение текста могут выглядеть очень разными, но между ними есть точки соприкосновения, которые можно использовать для улучшения качества обученных моделей seq2seq. Первое, на что следует обратить внимание, — то, что наш декодировщик выводит распределение вероятностей на каждом шаге, что очень похоже на модели на основе градиентов по стратегиям. С этой точки зрения декодировщик можно рассматривать как агента, пытающегося решить, какой токен создавать на каждом этапе. У подобной интерпретации процесса декодирования существует несколько преимуществ.
Прежде всего, рассматривая процесс декодирования как стохастический, мы можем автоматически учитывать несколько целевых последовательностей. Например, услышав «Привет! Как дела?», мы можем ответить множеством способов, и все они верны. Оптимизируя показатель максимального правдоподобия, наша модель попытается выучить что-то среднее для всех этих ответов, но среднее для предложений «Все в порядке, спасибо!» и «Не очень хорошо» не обязательно будет осмысленной фразой. Возвращая распределение вероятностей и выбирая из него следующий токен, наш агент потенциально мог бы научиться создавать все возможные варианты, вместо того чтобы учиться какому-то усредненному ответу.
Вторым преимуществом является оптимизация интересующего показателя. При обучении с использованием максимального правдоподобия мы сводим к минимуму перекрестную энтропию между созданными и взятыми из эталона токена ми, но при машинном переводе и решении многих других задач NLP нас не особо волнует максимальное правдоподобие: мы хотим максимизировать оценку BLEU полученной последовательности. К сожалению, оценка BLEU недифференцируема, поэтому мы не можем использовать ее как ошибку в алгоритме обратного распространения. Однако такие методы PG, как REINFORCE (см. главу 9), работают даже тогда, когда вознаграждение недифференцируемо: мы просто увеличиваем вероятности для успешных эпизодов и уменьшаем для неудачных.
Третье преимущество, которое можно использовать, заключается в том, что мы сами определяем процесс генерации последовательности и знаем его внутренние компоненты. Вводя стохастичность в процесс декодирования, мы можем повторить его несколько раз, собирая различные сценарии декодирования из единственного обучающего примера. Это может быть полезно, когда обучающий набор данных ограничен, а это почти всегда так, особенно если вы не работаете в Google, Facebook или другой большой компании.
Для того чтобы понять, как переключить обучение с максимального правдоподобия на сценарий RL, рассмотрим их оба с математической точки зрения. Оценка максимального правдоподобия означает максимизацию суммы путем подстройки параметра модели, что является тем же самым, что и минимизация расстояния Кульбака — Лейблера между распределением вероятности данных и распределением вероятности, параметризованным моделью, которое может быть записано как максимизация выражения
путем подстройки параметра модели, что является тем же самым, что и минимизация расстояния Кульбака — Лейблера между распределением вероятности данных и распределением вероятности, параметризованным моделью, которое может быть записано как максимизация выражения 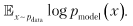
В то же время целью метода REINFORCE является максимизация выражения  Связь очевидна, и разница между ними заключается только в масштабном коэффициенте перед логарифмом и способе выбора действий, которые являются токенами в нашем словаре.
Связь очевидна, и разница между ними заключается только в масштабном коэффициенте перед логарифмом и способе выбора действий, которые являются токенами в нашем словаре.
На практике REINFORCE для обучения seq2seq может быть записан в виде следующего алгоритма.
1. Для каждого примера в обучающем наборе данных получить закодированное представление E, используя кодировщик.
2. Инициализировать текущий токен специальным значением T = ''.
3. Инициализировать выходную последовательность пустой последовательностью Out = [].
4. Пока T!= '':
- получить распределение вероятностей токенов и новое скрытое состояние, передав текущие токен и скрытое состояние: p, H = Decoder (T, E);
- сэмплировать выходной токен
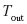 из распределения вероятностей;
из распределения вероятностей; - запомнить распределение вероятностей p;
- добавить в конец выходной последовательности Out += ;
- установить текущий токен T ← , E ← H.
5. Рассчитать BLEU или другой параметр между выходной и сопоставляемой последовательностями: Q = BLEU (Out, Outref).
6. Оценить градиенты 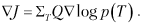
7. Обновить модель с помощью SGD.
8. Повторять до достижения сходимости.
Самокритичное обучение на последовательностях
Описанный подход, несмотря на свои положительные стороны, сопряжен с рядом сложностей. Обучаться с нуля практически бесполезно. Даже для простых диалогов выходная последовательность обычно содержит минимум пять слов, каждое из которых взято из словаря в несколько тысяч слов. Число различных фраз, состоящих из пяти слов со словарем из 1000 слов, равно 51000, что немного меньше, чем 10700. Таким образом, вероятность получения правильного ответа в начале обучения, когда веса для кодировщика и декодировщика являются случайными, ничтожно мала. Чтобы справиться с этим, можно объединить подходы, основанные на максимальном правдоподобии и RL, и предварительно обучить модель с показателем максимального правдоподобия (переключение между обучением, управляемым учителем, и обучением по цепочке), а после того, как она достигнет некоторого уровня качества, переключиться на метод REINFORCE для тонкой настройки. В общем, это можно рассматривать как единый подход к сложным задачам RL, когда большое пространство действий делает невозможным старт с агентом, чье поведение случайно, поскольку вероятность того, что такой агент случайно достигнет цели, незначительна. Существует множество исследований, посвященных включению сгенерированных извне примеров в процесс обучения RL, и в них в качестве одного из подходов называют предварительное обучение с использованием максимальных правдоподобий на правильных действиях.
Еще одна проблема с методом REINFORCE — высокая дисперсия градиентов, которую мы обсуждали в главе 10. Как вы, наверное, помните, для решения этой проблемы был применен метод актора-критика (A2C), который использовал специальную оценку ценности состояния в качестве дисперсии. Таким образом, мы можем применить метод A2C, конечно, расширив декодировщик другим выходом и вернув оценку ценности BLEU, учитывая декодированную последовательность, однако существует более удачный подход. В работе Self-Critical Sequence Training for Image Captionings, опубликованной С. Ренье (S. Rennie), Е. Марчереттом (E. Marcherett) и другими в 2016 году, был предложен лучший подход.
Авторы статьи применили декодировщик в режиме argmax для генерации последовательности, которая затем использовалась для вычисления параметра сход ства типа BLEU или аналогичного. Переключение в режим argmax делает процесс декодирования полностью детерминированным и обеспечивает базу для градиентов по стратегиям REINFORCE в формуле:

В следующем разделе мы реализуем и обучим простой чат-бот из набора диалогов, взятых из фильмов.
Об авторе
Максим Лапань — энтузиаст глубокого обучения и независимый эксперт. На протяжении 15 лет он занимается разработкой программного обеспечения и системной архитектуры, включая разработку низкоуровневых драйверов ядра Linux, а также оптимизацию производительности и архитектуры распределенных приложений, работающих на тысячах серверов. Имея обширный опыт работы в сферах больших данных, машинного обучения и больших распределенных систем, он обладает талантом объяснять сложные вещи простыми словами и на живых примерах. В данный момент в сферу его интересов входят практические приложения глубокого обучения, такие как глубокая обработка естественного языка и глубокое обучение с подкреплением.
Максим живет в Москве (Российская Федерация) с семьей и работает в израильском стартапе в должности старшего разработчика NLP (Natural Language Processing — обработка естественного языка).
О редакторах
Басем О.Ф. Алижла (Basem O.F. Alijla) получил степень кандидата наук по интеллектуальным системам в USM (Малайзия) в 2015 году. В данный момент преподает на кафедре разработки программного обеспечения Исламского университета сектора Газа (Палестина). Он автор нескольких технических работ, опубликованных в журналах и представленных на международных конференциях. Сейчас в круг его интересов входят оптимизация, машинное обучение и извлечение данных (Data mining).
Олег Васильев — специалист в области информатики и инженерии данных. Участвовал в разработке программы «Прикладная математика и информатика» для Национального исследовательского университета «Высшая школа экономики» (Москва), в частности раздела о распределенных системах. Принимал участие в разработке Git-course, Practical_RL и Practical_DL, преподавал в Высшей школе экономики и Школе анализа данных «Яндекса» (YSDA). Ранее Олег был научным сотрудником в Dialog Systems Group и Yandex. В данный момент он занимает должность вице-президента по управлению инфраструктурой в GoTo Lab — образовательной корпорации, а также сотрудничает с Digital Contract в качестве инженера-программиста.
Михаил Юрушкин — кандидат математических наук, трудится в области прикладной математики. В сферу его исследований входят высокопроизводительные вычисления и оптимизация разработки компиляторов. Он участвовал в разработке современной системы оптимизации параллельной компиляции. Михаил — старший преподаватель Южного федерального университета (Ростов-на-Дону, Россия). Он ведет курсы глубокого обучения, в частности на тему компьютерного зрения и NLP. Михаил восемь лет занимался кросс-платформенной нативной разработкой на С++, машинным обучением (ML) и глубоким обучением (DL). Сейчас он является консультантом в сферах ML/DL.
» Более подробно с книгой можно ознакомиться на сайте издательства
» Оглавление
» Отрывок
Для Хаброжителей скидка 25% по купону — Глубокое обучение
По факту оплаты бумажной версии книги на e-mail высылается электронная книга.
