Резервное копирование, часть 3: Обзор и тестирование duplicity, duplicati, deja dup

В данной заметке рассмотрены средства резервного копирования, которые выполняют резервное копирование путем создания архивов на резервном сервере.
Из тех, которые удовлетворяют требованиям — duplicity (к которому есть приятный интерфейс в виде deja dup) и duplicati.
Еще одно весьма примечательное средство резервного копирования — dar, но поскольку у него имеется весьма обширный список опций — методика тестирования покрывает едва ли 10% от того, на что он способен, — его в рамках текущего цикла не тестируем.
Ожидаемые результаты
Поскольку оба кандидата так или иначе создают архивы, то в качестве ориентира можно использовать обычный tar.
Дополнительно оценим, насколько хорошо оптимизируется хранение данных на сервере хранения путем создания резервных копий, содержащих только разницу между полной копией и текущим состоянием файлов, или между прошлым и текущим архивами (инкрементальные, декрементальные и т.п.).
Поведение при создании резервных копий:
- Сравнительно небольшое число файлов на сервере хранения резервных копий (сравнимо с числом резервных копий или размером данных в гб), но достаточно большой их размер (десятки-сотни мегабайт).
- Размер репозитория будет включать только изменения — дубликаты не будут храниться, таким образом размер репозитория будет меньше, чем при работе ПО на основе rsync.
- Ожидается большая нагрузка на процессор при использовании сжатия и/или шифрования, а также, вероятно, достаточно большая нагрузка на сеть и дисковую подсистему, если процесс архивации и/или шифрования будет работать на сервере хранения резервных копий.
В качестве эталонного значения запустим следующую команду:
cd /src/dir; tar -cf - * | ssh backup_server "cat > /backup/dir/archive.tar"Результаты выполнения получились такие:

Время выполнения 3m12s. Видно, что скорость уперлась в дисковую подсистему сервера хранения резервных копий, как и в примере с rsync. Только чуть быстрее, т.к. запись идет в один файл.
Также для оценки сжатия запустим тот же вариант, но включим сжатие на стороне сервера резервного копирования:
cd /src/dir; tar -cf - * | ssh backup_server "gzip > /backup/dir/archive.tgz"Результаты таковы:
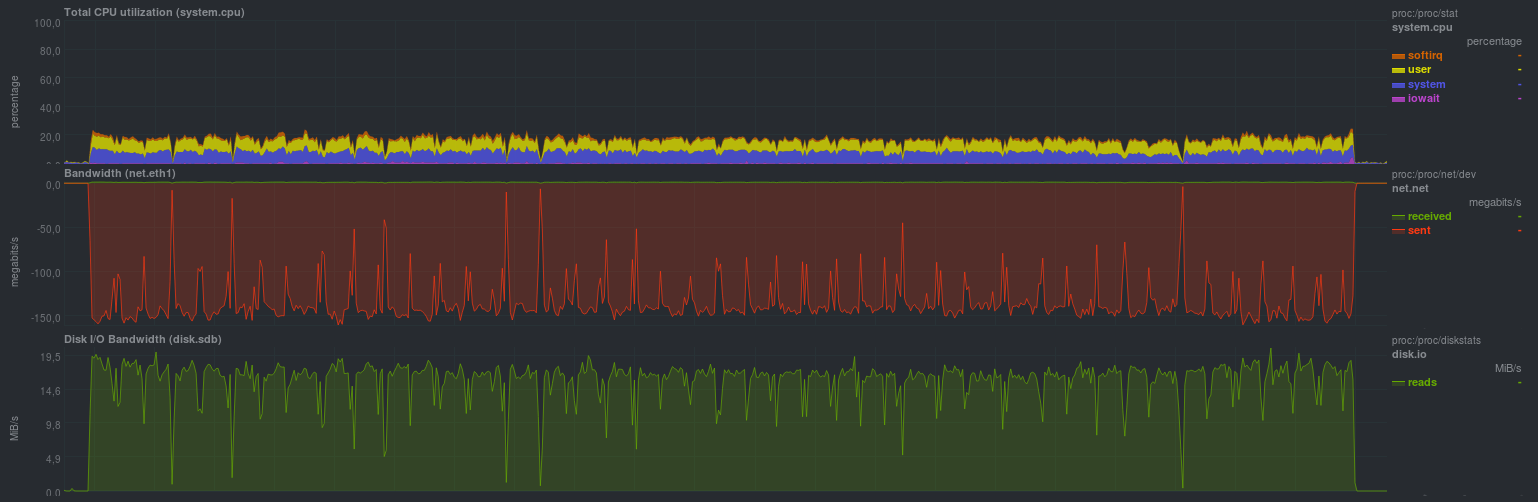
Время выполнения 10m11s. Вероятнее всего, узкое место — однопоточный компрессор на принимающей стороне.
Та же команда, но с переносом сжатия на сервер с исходными данными для проверки гипотезы, что узкое место — однопоточный компрессор.
cd /src/dir; tar -czf - * | ssh backup_server "cat > /backup/dir/archive.tgz"Получилось так:
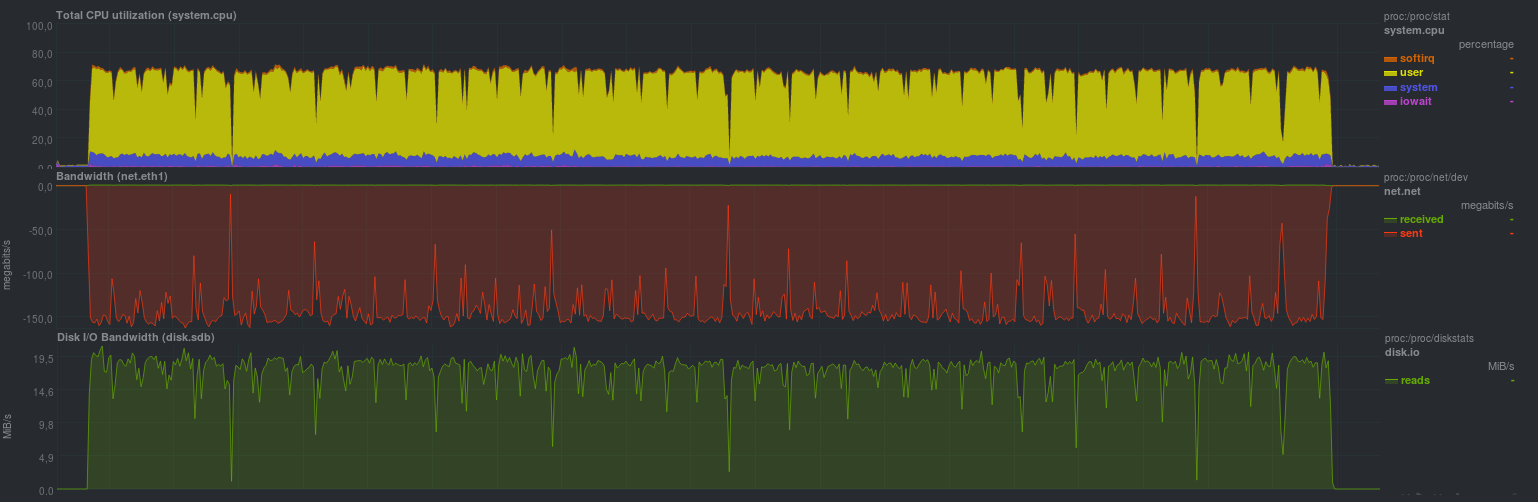
Время выполнения составило 9m37s. Явно видно загрузку одного ядра компрессором, т.к. скорость передачи по сети и нагрузка на дисковую подсистему источника — аналогичные.
Для оценки шифрования можно использовать openssl или gpg, подключая дополнительную команду openssl или gpg в pipe. Для ориентира будет такая команда:
cd /src/dir; tar -cf - * | ssh backup_server "gzip | openssl enc -e -aes256 -pass pass:somepassword -out /backup/dir/archive.tgz.enc"Результаты вышли такие:

Время выполнения получилось 10m30s, поскольку запущено 2 процесса на принимающей стороне — узкое место опять однопоточный компрессор, плюс небольшие накладные расходы на шифрование.
Тестирование duplicity
Duplicity — программное обеспечение на python для резервного копирования путем создания шифрованных архивов в формате tar.
Для инкрементальных архивов применяется librsync, следовательно, можно ожидать поведения, описанного в предыдущей заметке цикла.
Резервные копии могут шифроваться и подписываться с помощью gnupg, что немаловажно при использовании различных провайдеров для хранения резервных копий (s3, backblaze, gdrive и т.п.)
Посмотрим, какие будут результаты:
спойлер
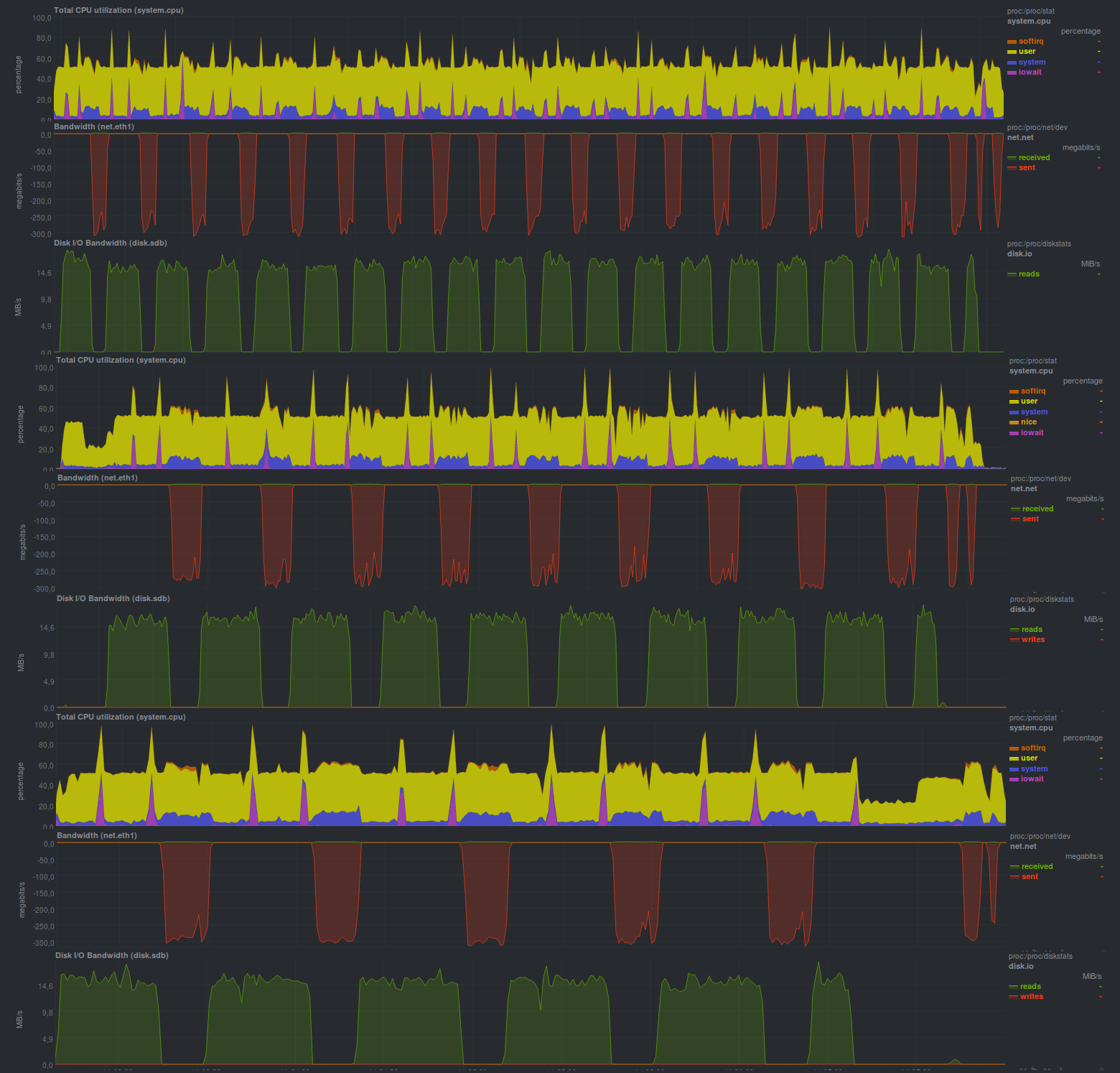
Время работы каждого тестового запуска:
А вот результаты при включении шифрования gnupg, с размером ключа 2048 бит:
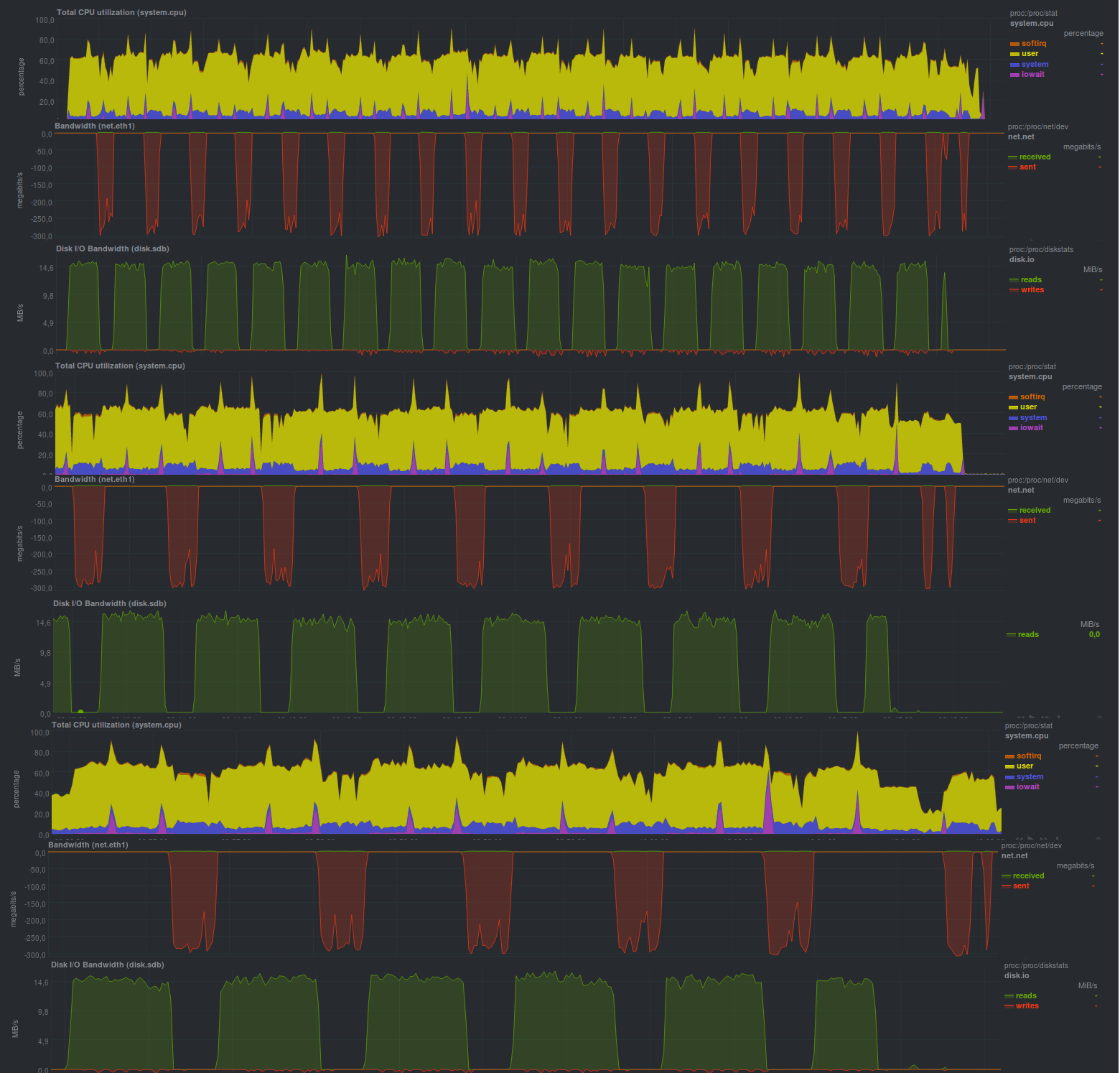
Время работы на тех же данных, с шифрованием:
Был указан размер блока — 512 мегабайт, что отчетливо видно на графиках; загрузка процессора фактически держалась на уровне 50%, значит, программа утилизирует не более одного процессорного ядра.
Также достаточно хорошо видно принцип работы программы: взяли кусочек данных, пожали его, отправили на сервер хранения резервных копий, который может быть достаточно медленным.
Еще одна особенность — предсказуемое время работы программы, которое зависит только от размера измененных данных.
Включение шифрования не особенно увеличило время работы программы, но повысило загрузку процессора примерно на 10%, что может быть весьма неплохим приятным бонусом.
К сожалению, данная программа не смогла корректно обнаружить ситуацию с переименованием каталога, и результирующий размер репозитория оказался равен размеру изменений (т.е. все 18 гб), но возможность использовать недоверенный сервер для резервного копирования однозначно перекрывает такое поведение.
Тестирование duplicati
Данное программное обеспечение написано на C#, запускается, используя набор библиотек от Mono. Имеется GUI, а также cli версия.
Примерный список основных возможностей близок к duplicity, включая различных провайдеров для хранения резервных копий, однако, в отличие от duplicity, большинство возможностей доступно без сторонних средств. Плюс это или минус — зависит от конкретного случая, однако для новичков, вероятнее всего, проще иметь перед глазами список сразу всех возможностей, нежели доустанавливать пакеты для python, как в случае с duplicity.
Еще один небольшой нюанс — программа активно пишет локальную базу sqlite от имени того пользователя, который запускает резервное копирование, поэтому нужно дополнительно следить за корректным указанием нужной базы при каждом запуске процесса используя cli. При работе через GUI или WEBGUI детали будут скрыты от пользователя.
Если выключить шифрование (причем WEBGUI делать этого не рекомендует), результаты таковы:
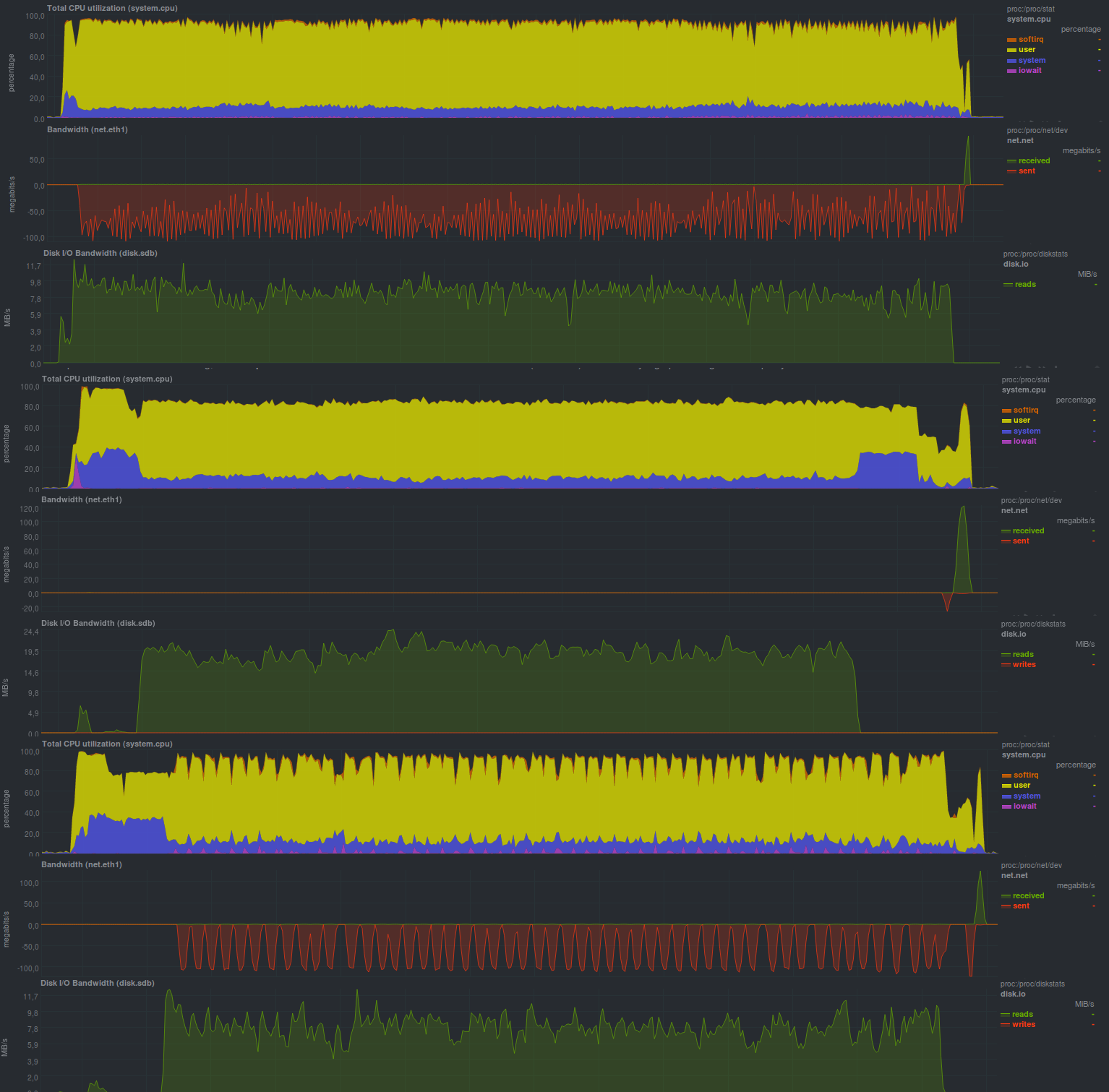
Время работы:
С включенным шифрованием, используя aes, получается так:
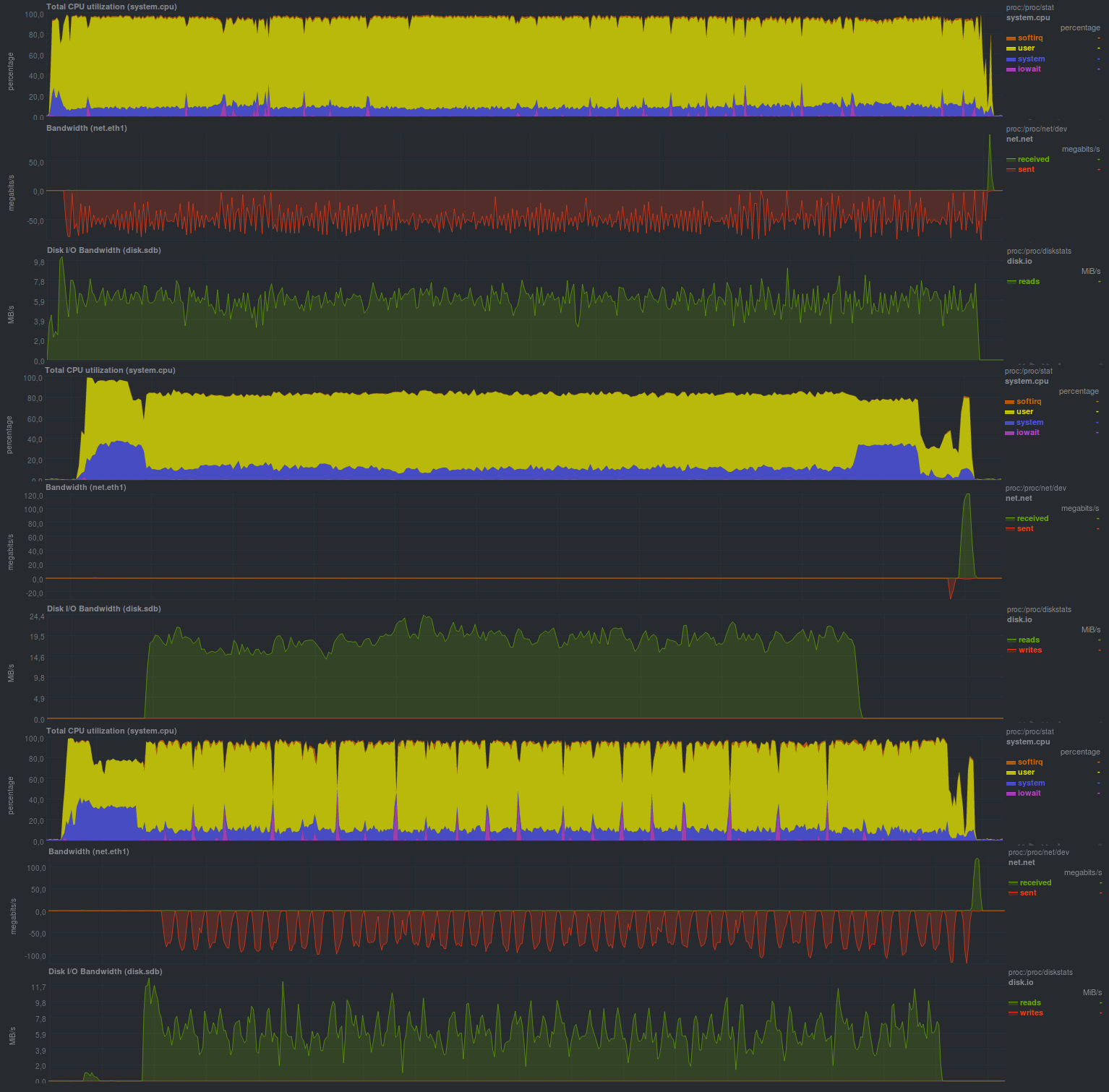
Время работы:
А если использовать внешнюю программу gnupg, выходят такие результаты:

Как видно — программа умеет работать в несколько потоков, но от этого не является более производительным решением, а если сравнивать работу шифрования — запуск внешней программы
получился более быстрым, чем применение библиотеки из набора Mono. Возможно, это связано с тем, что внешняя программа больше оптимизирована.
Приятным моментом также стал тот факт, что размер репозитория занимает ровно столько, сколько реально было измененных данных, т.е. duplicati обнаружил переименование каталога и корректно обработал данную ситуацию. Это можно увидить при прогоне второго теста.
В целом, достаточно положительные впечатления от программы, включая достаточную дружелюбность к новичкам.
Результаты
Оба кандидата достаточно неспешно отработали, но в целом, по сравнению с обычным tar, есть прогресс, как минимум у duplicati. Цена такого прогресса также понятна — заметная нагрузка
процессора. В целом, никаких особых отклонений при прогнозировании результатов нет.
Выводы
Если никуда спешить не нужно, а также есть запас по процессору — подойдет любое из рассмотренных решений, во всяком случае проделана достаточно большая работа, которую не стоит повторять путем написания скриптов-оберток поверх tar. Наличие шифрования весьма нужное свойство, если сервер для хранения резервных копий не может быть полностью доверенным.
Если сравнивать с решениями на основе rsync — производительность может быть хуже в несколько раз, несмотря на то, что в чистом виде tar отработал быстрее rsync на 20–30%.
Экономия на размере репозитория есть, но только у duplicati.
Анонс
Резервное копирование, часть 1: Зачем нужно резервное копирование, обзор методов, технологий
Резервное копирование, часть 2: Обзор и тестирование rsync-based средств резервного копирования
Резервное копирование, часть 3: Обзор и тестирование duplicity, duplicati, deja dup
Резервное копирование, часть 4: Обзор и тестирование zbackup, restic, borgbackup
Резервное копирование, часть 5: Тестирование bacula и veeam backup for linux
Резервное копирование, часть 6: Сравнение средств резервного копирования
Резервное копирование, часть 7: Выводы
Автор публикации: Павел Демкович
