[Перевод] Метаморфическое тестирование: почему об этой перспективной методике почти никто не знает
Должен признаться: я читаю ACM Magazine. Это делает меня «ботаником» даже по меркам программистов. Среди прочего, я узнал из этого журнала о «метаморфическом тестировании». Раньше я никогда о нём не слышал, как и все люди, которых я спрашивал. Но научная литература по этой теме на удивление объёмна: есть множество невероятно успешных примеров её применения в совершенно разных областях исследований. Так почему же мы не слышали о нём раньше? Существует только одна статья для людей вне научных кругов. Пусть теперь их будет две.
Краткая предыстория
В большинстве письменных тестов используются оракулы. То есть вы знаете ответ и явным образом проверяете, дают ли вычисления правильный ответ.
def test_dist():
p1 = (0, 3)
p2 = (4, 0)
assert dist(p1, p2) == 5
Кроме тестов-оракулов, есть и ручные тесты. Тестер садится за компьютер и сравнивает вводимые данные с результатами. В процессе усложнения систем ручные тесты становятся всё менее полезными. Каждый из них проверяет только одну точку в гораздо большем пространстве состояний, а нам нужно нечто, исследующее всё пространство состояний.
Это приводит нас к генеративному тестированию (generative testing): написанию тестов, покрывающих случайное множество в пространстве состояний. Самым популярным стилем генеративного тестирования является property based testing, или PBT. Мы находим «свойство» (property) функции, а затем генерируем входные значения и проверяем, соответствуют ли выходные значения этому свойству.
def test_dist():
p1 = random_point()
p2 = random_point()
assert dist(p1, p2) >= 0
Преимущество PBT заключается в покрытии большего пространства. Его недостаток — утеря специфичности. Это уже не оракул-тест! Мы не знаем, каким должен быть ответ, и функция может быть ошибочна, но таким образом, что обладает тем же свойством. Здесь мы полагаемся на эвристики.
Серьёзная проблема PBT — нахождение хороших свойств. У большинства функций есть простые, общие свойства и сложные, специфические свойства. Общие свойства могут применяться к большому множеству функций, но они не дают нам особо много информации. Более специфические свойства дают больше информации, но их сложнее найти и они применимы только в областях ограниченных задач. Если у вас есть функция, определяющая, является ли граф ациклическим, то какие property-тесты вы напишете? Дадут ли они вам уверенность в том, что функция верна?
Мотивация
Теперь рассмотрим более сложную задачу. Представьте, что вы хотите написать преобразователь речи в текст (speech-to-text, STT) для английского языка. Он получает звуковой файл, а выводит текст. Как бы вы его тестировали?
Проще всего использовать ручной оракул. Продиктовать предложение и проверить, совпадает ли с ним текст на выходе. Но этого даже близко недостаточно! Диапазон человеческой речи огромен. Лучше будет протестировать 1 000 или даже 10 000 разных звуковых файлов. Ручные оракулы с транскрипцией были бы слишком затратными. Это значит, что нам придётся вместо них использовать property-based testing.
Но как нам сгенерировать входные данные? Например, мы можем создать случайные строки, пропустить их через преобразователь текста в речь (text-to-speech, TTS), а затем убедиться, что наш STT выдаёт тот же текст. Но это опять же даёт нам очень ограниченный диапазон человеческого голоса. Сможет ли TTS создать изменения интонаций, «глотать» слова, имитировать сильный акцент? Если мы не справимся с ними, то будет ли STT особо полезен? Лучше использовать произвольные тексты, например, записи с радио, из подкастов и онлайн-видео.
Теперь возникает новая проблема. При использовании TTS мы начинали с письменного текста. В случае произвольных звуковых файлов у нас его нет, и в то же время мы не хотим выполнять транскрипцию вручную. Вместо этого мы ограничены использованием свойств. Какие же свойства нам нужно протестировать? Примеры простейших свойств: «программа не вылетает при любых входящих данных» (хорошее свойство) или «она не преобразует в слова акустическую музыку» (возможно?). Эти свойства не очень хорошо покрывают проверку основной задачи программы и слабо повышают уверенность в её качестве.
Итак, у нас есть две задачи. Во-первых, нам нужно большое множество входящих данных в виде речи. Во-вторых, нам нужно понять, как преобразовать их в полезные тесты, не тратя долгие часы на ручную транскрипцию голоса в оракулы.
Метаморфическое тестирование
При всё этом выходные данные рассматриваются по отдельности. Что если мы встроим их в более широкий контекст? Например, если звуковой клип транскрибируется в выходные данные out, то мы должны всегда получать out при:
- Повышении громкости вдвое
- Повышении частоты
- Увеличении темпа
- Добавлении фоновых помех
- Добавлении шума транспорта
- Любой комбинации из вышеперечисленного.
Всё это «простые» преобразования, которые мы можем легко протестировать. Например, для теста с «шумом транспорта» мы можем взять 10 сэмплов шума автомобилей, наложить их на звуковой клип и проверить, совпадают ли результаты распознавания всех 11 версий. Мы можем двое увеличить или уменьшить громкость, превратив 11 версий в 33 версий, а затем удвоить темп, получив 66 версий. Этот принцип можно применить к каждому звуковому клипу в нашей базе данных, существенно расширив пространство входящих данных.
Наличие 66 версий для сравнения довольно удобно. Но это ещё не всё: нам ещё и не нужно знать, какими должны быть выходные данные. Если все 66 преобразований возвращают out, то тест пройден успешно, если хотя бы одно возвращает что-то другое, то тест не пройден. Ни на одном из этапов нам не нужно проверять, что содержится в out. Это чрезвычайно важно. Так мы значительно увеличиваем тестируемое пространство с очень малым участием человека. Например, мы можем скачать эпизод сериала, выполнить преобразования и проверить, совпадают ли все результаты их преобразования в текст1. Мы получили полезные тесты, не прослушивая голосовой клип. Теперь мы можем генерировать сложные и глубокие тесты без использования оракула!
Два набора входящих данных, а также их выходящих данные связаны друг с другом. Такое свойство, относящееся к множеству входящих/выходящих данных называется метаморфической связью2. Тестирование, в котором применяется это свойство, называется метаморфическим тестированием. В сложных системах интересные метаморфические связи бывает найти проще, чем интересные свойства отдельных входящих/выходящих данных.
Изложим это чуть формальнее: если у нас есть x и f(x), то мы можем выполнить некие преобразования x, чтобы получить x2 и f(x2). В случае STT мы просто проверяем f(x) = f(x2), но можем использовать любые связи между этими двумя наборами данных. Могут быть и метаморфические связи типа f(x2) > f(x) или «является ли f(x2)/f(x) целым значением». Аналогичным образом можно расширить этот принцип на несколько наборов входящих данных, использовав f(x) и f(x3). Примером этого может быть сравнение результатов поискового движка без фильтров с результатами движка с одним или двумя фильтрами. В большинстве прочитанных мной описаний примеров использования применяется всего два набора входящих данных, потом что даже их достаточно для нахождения безумных багов.
Примеры использования
К слову о примерах использования: насколько эффективно метаморфическое тестирование на практике? Одно дело рассуждать о методике абстрактно или приводить искусственные примеры. Изучение примеров использования полезно по трём причинам. Во-первых, оно показывает, работает ли способ на самом деле. Во-вторых, из них можно узнать о потенциальных сложностях при использовании МТ. В-третьих, примеры показывают нам, как мы можем использовать методику. Любую метафорическую связь, применяемую в примере использования, можно попытаться адаптировать под решение наших задач.
В статье «Metamorphic Testing: A Review of Challenges and Opportunities» приводится список множества исследований, но все они являются научными статьями. Ниже представлены наиболее интересные. Статьи, помеченные (pdf), выложены, как можно догадаться, в PDF.
- METTLE: A Metamorphic Testing Approach To Validating Unsupervised Machine Learning Methods (pdf). Здесь описываются 11 разных метаморфических связей для тестирования неконтролируемой кластеризации, например, «получим ли мы тот же результат, если перемешаем входящие данные?» и «принадлежат ли дополнительные входящие данные по краям кластеров к этим кластерам?» Различные модели изменяются при разных связях. Например, около 5% протестированных моделей k-средних при перемешивании порядка входящих точек имеют среднюю погрешность кластеризации 20%
- DeepTest: Automated Testing of Deep-Neural-Network-driven Autonomous Cars (pdf). Тема статьи — системы зрения автопилотов в машинах. Примеры метаморфических связей (МС): «добавление фильтра дождя» или «небольшой наклон изображения». Авторы выложили результаты сэмплирования здесь: почти все протестированные ими системы не справлялись со своими функциями при изменении МС.
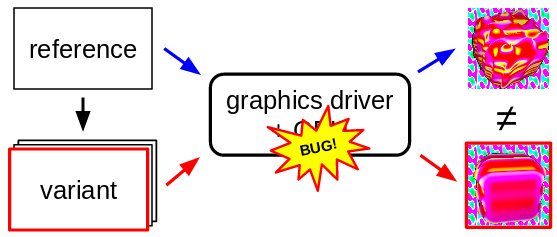
- Automated Testing of Graphics Shader Compilers (pdf). Инъекции «мёртвого» кода и констант времени выполнения в шейдеры приводили к исчезновению объектов на изображениях или превращению их в шум. Исследовали на основании своей работы создали стартап GraphicsFuzz, который был куплен Google, а сайт закрыт.
- Metamorphic Testing of RESTful Web APIs (pdf). Получим ли мы одинаковые элементы при изменении пагинации? Что если упорядочить их по дате? В этой статье приведена целая куча ошибок в Spotify и Youtube.
- An innovative approach for testing bioinformatics programs using metamorphic testing (раньше pdf, но теперь нет). Поиск ошибок в биоинформационных данных. Я слабо разбираюсь в биоинформатике, но статья показывает, что МС полезны и в специализированных областях.
Проблема
О, так ведь все эти источники в PDF.
На поиск всех этих статей ушло несколько часов. И эта проблема связана с самым большим препятствием перед освоением МТ: все приведённые выше ссылки являются препринтами или первыми черновиками будущих научных статей. Когда я начинаю разбираться в малоизвестных методиках, то в первую очередь задаюсь вопросом: «почему они малоизвестны?» Иногда причина очевидна, иногда это сложное множество мелких причин, иногда проблема просто в том, что методике «не повезло».
В случае МТ проблема очевидна. Почти вся информация спрятана за научными paywall. Если вы хотите изучать МТ, вам или нужен доступ к журналу, или требуется потратить несколько часов на выискивание препринтов3.
Дальнейшее изучение
Изобретатель МТ — Ти Чен (Ty Chen). Он же стал движущей силой множества исследований. Другие исследователи в этой области — Ци Цюань Чжоу (Zhi Quan Zhou) и Серхио Сегура (Sergio Segura); оба они выложили все свои препринты в Интернет. Большинство исследовательских работ выполнено кем-то из этих людей.
Наверно, лучше всего начать изучение с Metamorphic Testing: A Review of Challenges and Opportunities и A Survey on Metamorphic Testing. Хоть эта статья написана о метаморфическом тестировании, исследовали также применили метаморфические связи в целом к широкому множеству других дисциплин, например, к формальной верификации кода и отладке. Я пока подробно не изучал эти области применения методики, но, вероятно, на них тоже стоит взглянуть.
С точки зрения применимости, теоретически может оказаться возможным адаптировать большинство PBT-библиотек к проверке метаморфических свойств. На самом деле первый пример в Quickcheck тестирует МС, а в этом эссе по PBT косвенно применяются МС. В целом мне кажется, что большинство исследований PBT фокусируется на эффективной генерации и усечении входящих данных, а исследования МТ в основном сосредоточены на определении того, что нам нужно тестировать на самом деле. Следовательно, эти методики, вероятно, взаимно дополняют друг друга.
Благодарю Брайана Ына (Brian Ng) за помощь в исследованиях.
Постскриптум: просьба
На самом деле неудивительно, что я никогда не слышал раньше об этой методике. Существует множество действительно интересных и полезных техник, которые не смогли покинуть своего крошечного пузыря. Я узнал об МТ скорее благодаря везению, а не активным поискам.
Если вам известно что-то, стоящее широкого применения, то напишите мне, пожалуйста.
- Ну ладно, тут могут быть очевидные проблемы: в подкасте может быть музыка, фрагменты речи на других языках и т.д. Но теория надёжна: если мы способны получить сэмплы речи, то можем использовать их как часть тестов без предварительной ручной транскрипции/разметки.
- В спецификациях соответствующей идеей являются гиперсвойства (hyperproperties) — свойства множеств поведений, а не отдельных поведений. Большинство исследований гиперсвойств связано с ГС безопасности. Насколько я понял, её ГС являются надмножеством МС.
- У меня была вторая, теперь опровергнутая, гипотеза: так как большинство основных исследователей из Китая и Гонконга, возможно, эта методика более известна в сообществах программистов, общающихся на мандаринском, а не английском. Брайан Ын проверил для меня эту гипотезу, но не обнаружил никаких существенных признаков применения методики китайцами.
