Репликация KV1/KV2 в Deckhouse Stronghold: как добиться идентичности секретов
В нашем решении для безопасного управления жизненным циклом секретов Deckhouse Stronghold появился механизм репликации для хранилищ KV1/KV2. Он позволяет автоматически и централизованно синхронизировать секреты в распределённых и облачных системах.
Меня зовут Артём Данильченко, я ведущий инженер архитектурных решений в команде Stronghold. В этой статье поделюсь нашим опытом разработки репликации и расскажу, как мы решали возникающие сложности.

Зачем нужна репликация
Прежде чем рассказывать, как мы реализовали репликацию KV1/KV2 в Stronghold, давайте обсудим, когда она может пригодиться и какие проблемы можно решить с её помощью.
Допустим, есть компания федерального уровня с центральным офисом и достаточным количеством региональных представительств. В её ИТ-ландшафте применяется множество инструментов и технологий: различные системы хранения данных, брокеры сообщений, средства развёртывания, контейнеризации и так далее.
Для доступа ко всему этому многообразию необходимо не только придумать кучу учётных записей и паролей, но и правильно их хранить. Поскольку компания серьёзно относится к вопросам ИБ, для хранения секретов она использует HashiCorp Vault и Deckhouse Stronghold. Сами секреты предоставляют доступ к локальной (на уровне региона) и центральной инфраструктуре (региональные отделения могут подключаться к центральному офису):

С архитектурной точки зрения всё круто, безопасно и железобетонно. Но вот со стороны эксплуатации возникают неудобства.
Например, непонятно, как централизованно доставить в региональные отделения секреты для доступа к инфраструктуре центрального офиса. А если ещё для каждого региона свои учётки? Допустим, каждый региональный офис подключается к корпоративной шине данных с индивидуальными настройками — логином/паролем, именами топиков, в которые нужно писать или читать.
Другой пример: обновление скомпрометированных паролей на всей сети или переезд с Vault на Stronghold в рамках импортозамещения.
Все эти задачи выполнимы, но потребуют либо много ручного труда, либо дополнительных усилий в виде написания скриптов, создания конфигураций, применения сторонних инструментов или покупки enterprise-версий HashiCorp Vault, если такая возможность доступна.
В Vault EE для решения схожих задач существует механизм Performance Replication. Мы решили переосмыслить его в Deckhouse Stronghold и для начала реализовали репликацию хранилищ типа KV1/KV2.
Как устроена репликация KV1/KV2
Давайте рассмотрим подробнее, что это за механизм и как он работает.
Стоит отдельно подчеркнуть, что на данный момент в Stronghold механизм репликации реализован в виде однонаправленной (источник → получатель) pull-модели. Копируются только данные секретов без политик.
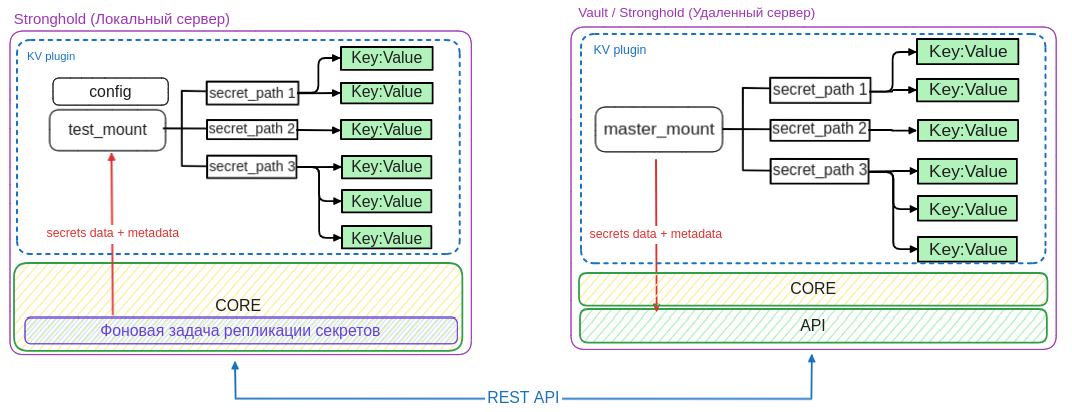
Верхнеуровневая архитектурная схема механизма репликации между распределёнными системами хранения секретов приведена ниже:

Разберём, что здесь изображено. В левой половине — два удалённых хранилища секретов: одно — на базе HashiCorp Vault, другое — на базе Deckhouse Stronghold. В правой половине — три сервера Stronghold, назовём их локальными, поскольку на их стороне будут производиться все настройки по репликации, получение и сохранение секретов.
На сервере Stronghold 1 создан движок KV. Он примонтирован c названием local_mount_path #1 и хочет получать данные из удалённого сервера Vault, в котором также есть KV, но примонтированный с другим именем — mount_path #1. Как мы видим, совпадение имён mount не требуется. Аналогично на серверах Stronghold 2 и Stronghold 3 есть свои KV, причём они одновременно настроены на разные удалённые серверы.
Теперь обратимся непосредственно к реализации данного архитектурного решения. Для понимания контекста начнём с общей архитектурной схемы Stronghold:

API — управление хранилищем и секретами (аутентификация, работа с политиками и ролями, чтение и запись секретов) производятся через API. Для получения доступа к этим операциям применяются токены, которые передаются в заголовках запросов.
Core — в ядре Stronghold реализованы механизмы шифрования секретов и управления хранилищем (инициализация, запечатывание, распечатывание), обработки поступающих от API запросов и так далее. Здесь работают фоновые задачи, которые предоставляют функционал автоматической инициализации и распечатывания (auto unseal) кластера Stronghold (требуется не менее 3 узлов в конфигурации Raft), репликации KV1/KV2, а также выполнения резервного копирования по расписанию.
Storage Backend — представляет собой способы физического хранения данных — файл, БД, in-memory storage и так далее.
Разберём на примере, как производится обработка запроса на запись значения в KV:

Команда на запись данных поступает через метод API и попадает в HTTP-обработчик в ядре. Здесь производятся первоначальная обработка запроса, проверка токенов и так далее. Затем HTTP-запрос преобразуется во внутреннее представление запроса — logical.Request. Этот логический запрос передаётся во внутренний роутер, который производит проверку path и определяет, в какой бэкенд нужно направить запрос далее. Также на этапе роутинга происходит дополнительное обогащение запроса информацией. В нашем случае будет добавлена структура routeEntry:

Далее запрос поступит на обработку в плагин KV. Так как плагин не имеет прямого доступа к данным и ключам шифрования, он выполнит операцию записи посредством методов, которые предоставляет сущность logical.Storage из структуры routeEntry:
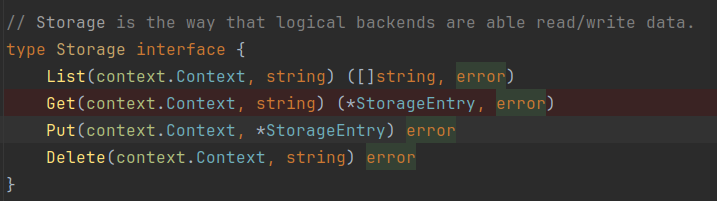
Все операции шифрования/дешифрования данных скрыты в реализации этого интерфейса.
Когда операция записи пройдёт успешно, будет сформировано подтверждение, которое Stronghold отправит в обратном направлении.
Разработка механизма репликации в Deckhouse Stronghold
Задачу разработки механизма репликации можно разделить на две части:
Настройка репликации и редактирование настроек.
Реализация механизма репликации.
Настройка репликации
Настройки репликации в Stronghold задаются при создании хранилища KV1/KV2 и не нарушают обратной совместимости с API HashiCorp Vault. Настройка производится на стороне локального хранилища одним из следующих способов:
через CLI-утилиты stronghold / d8 stronghold;
с помощью утилиты curl и обращения к REST API;
OpenAPI UI.
Также администратору необходимо обеспечить следующие условия:
Наличие доступа к удалённому серверу Vault/Stronghold. Наличие сетевой связности, сертификата и токена для доступа к API.
Наличие доступа к локальному серверу Stronghold. Возможность произвести настройки репликации через CLI или REST API-интерфейс.
Вот общая схема процесса настройки:

Рассмотрим операции настройки по шагам:
Пользователь выполняет команду монтирования нового хранилища KV1/KV2.
Настройки передаются в ядро Stronghold для валидации.
Stronghold производит валидацию настроек по следующим параметрам:
проверка наличия сетевой связности;
проверка актуальности сертификата и токена для доступа к API удалённого сервера Vault/Stronghold;
проверка существования удалённого mount kv1/kv2;
возможности чтения секретов из удалённого kv1/kv2.
Сохранение настроек во внутреннем хранилище, если все описанные выше условия выполняются. В противном случае пользователю будет возвращена ошибка валидации с указанием причины такого поведения.
Чтобы реализовать этот функционал, нам потребовалось произвести ряд доработок Stronghold.
Во-первых, мы расширили модели данных, которые передаются при выполнении запросов к API Stronghold. Мы создали свою структуру данных, описывающую настройки репликации, и внедрили её в базовую модель MountConfig.
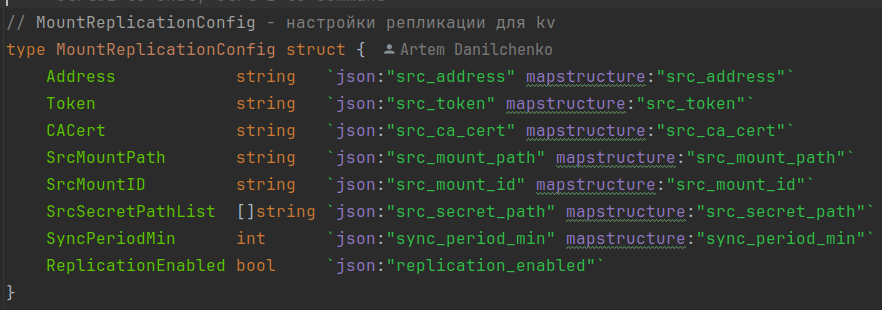
Настройки включают в себя следующие параметры:
адрес удалённого кластера Stronghold/Vault (источник данных);
токен для доступа к удалённому кластеру Stronghold/Vault (источнику данных);
сертификат TLS или путь к сертификату TLS для подключения к удалённому кластеру Stronghold/Vault (источнику данных);
имя mount-path KV1/KV2 на удалённом кластере Stronghold/Vault;
список secret path для репликации (по умолчанию реплицируются все секреты);
период запуска репликации данных (по умолчанию 1 минута);
включение/выключение репликации.
В свою очередь MountConfig является полем в структуре MountEntry, которая отвечает за описание примонтированного хранилища данных:
type MountEntry struct {
Table string `json:"table"`
Path string `json:"path"`
Type string `json:"type"`
Config MountConfig `json:"config"`
Options map[string]string `json:"options"`
........
}Таким образом, настройки репликации хранятся вместе с настройками монтирования и их редактирование доступно через метод POST /sys/mounts/{path}/tune.
Стоит отметить возможность включать и выключать репликацию после создания хранилища KV1/KV2. Все mount, у которых заданы настройки и включена репликация, переходят в режим RO. Отключение репликации переводит mount в режим RW. Надо понимать, что если пользователь в режиме RW внесёт какие-то изменения в секреты, а затем включит репликацию назад, то его изменения будут безвозвратно потеряны, так как состояние локального KV будет синхронизировано с KV удалённого сервера.
Узнать больше о настройках репликации в Stronghold можно в документации.
Механизм репликации
Вот общая схема работы репликации:
На локальном сервере выполняется фоновая задача, которая периодически сканирует все подключенные mount KV1/KV2 и проверяет их на наличие настроек репликации. Все полученные настройки группируются по адресу удалённого сервера Vault/Stronghold. Такая группировка нужна, чтобы снизить количество сетевых запросов и переподключений к серверам. При отсутствии настроек никакие действия не предпринимаются.
На следующем этапе выполнения будет создан HTTP-клиент, который будет выполнять запросы к API удалённого сервера с токеном, указанным в настройках репликации.
Сам процесс репликации включает в себя следующие действия:
Проверка на пересоздание/удаление/подмену исходного удалённого KV. Привязка к уникальному UUID каждого mount производится на этапе задания настроек.
Получение списка secret path, заданного в настройках mount path на удалённом сервере.
Проверка существования secret path на локальном сервере. Его создание, если это необходимо.
Синхронизация секретов из удалённого хранилища в локальное. Для этого автоматически выполняется запрос к API удалённого хранилища для получения метаданных и всех версий секрета. После получения данных происходит перезапись всех локальных версий секрета и его метаданных.
При необходимости автоматическое удаление или уничтожение неактуальных версий секрета.
Для реализации этого функционала нам потребовалось произвести некоторые доработки ядра Stronghold:
Реализовать механизм сканирования локальных MountEntry для получения сохранённых в них настроек.
Реализовать набор методов для выполнения служебных запросов через внутренний router. Например:

Добавить возможность производить запросы к стороннему API.
Реализовать свой планировщик репликации.
Первоначально был план ограничиться доработками в ядре и не лезть «под капот» плагина, но от этой идеи пришлось отказаться. Чтобы разобраться в причинах, давайте остановимся чуть подробнее на плагине KV. Он относится к категории built-in-плагинов и предоставляет две версии движка для хранения данных:
KV1 самый простой и понятный — это обычный алгоритм сохранения key-value без версионирования и прочих сложностей.
KV2 предоставляет расширенный функционал — возможность создавать версии секретов, удаление и восстановление данных, полное уничтожение определённой версии секрета, задание TTL для каждой версии, добавление metadata для каждого секрета.
И если с репликацией KV1 всё прошло легко и гладко, то с KV2 так не получилось. Основная проблема заключалась в том, что по умолчанию KV2 на любые изменения секрета создаёт новую версию его ключа и значения.

И тогда процесс репликации приобретает следующий вид:

При выполнении каждой синхронизации с удалённым сервером нам необходимо локально проверять кучу условий: было ли пересоздание секрета, изменились ли количество секретов и их значение, совпадают ли версии этих секретов, их TTL и удаление/восстановление, есть ли ограничение по количеству версий секретов, есть ли изменения в метаданных или настройках и так далее. А также обязательно не плодить дубли секретов и их версий от запуска к запуску.
Рассмотрим следующую ситуацию: на удалённом сервере для секрета установлено ограничение по количеству секретов — 6 версий. И уже есть 2 версии значений секрета. При первом запуске репликации на локальный сервер будут перенесены все значения секретов и их метаданные.
В промежутке между запусками процесса репликации на удалённом хранилище было добавлено ещё 8 версий секретов. Эта операция приводит к тому, что в хранилище будут лежать версии с 6-й до 10-й. И при попытке следующей репликации у нас возникают неопределённости — или локально создавать версии «вхолостую», чтобы синхронизироваться с источником, или же всё удалять и синхронизироваться на чистом хранилище. Но тут возникает новая проблема — в KV2 версии всегда начинаются с 1, а значит, опять надо делать «холостые» операции.

И это только одна проблемная ситуация.
Чтобы разобраться во всех нюансах, подводных камнях и багах, нам пришлось написать кучу unit-тестов. Логика программы разрасталась и усложнялась, несколько раз казалось, что мы уже готовы выпустить релиз, но ручное тестирование функционала нашими инженерами (огромное спасибо всем причастным) позволяло обнаруживать всё новые и новые недоработки.
Когда мы в очередной раз словили сложный баг, пришлось признать, что «настало время допиливать плагин KV». Закатав рукава и вооружившись дебагером, мы провели несколько дней в режиме парного программирования, проверили работу плагина на различных входных данных и-и-и… поправили буквально 30 строчек в плагине. Это позволило адаптировать его под задачу репликации. Как следствие, общая логика репликации существенно упростилась и, что немаловажно, позволила нам сократить количество сетевых запросов.
Мы смогли решить две основные проблемы.
Во-первых, научились создавать секрет нужной нам версии. Допустим, мы настроили репликацию на удалённый mount, а в нём секреты начинаются не с 1-й версии. А значит, мы отказываемся от «холостых» операций.

Во-вторых, теперь мы можем корректно обрабатывать ситуации пересоздания секретов на удалённом сервере.
Например, на удалённом сервере был создан секрет prod, и в него поместили логин и пароль, даже создали 5 версий. Локальный сервер выполнил репликации. Далее на удалённом сервере удалили секрет prod и создали его с тем же именем, но поместили другие логин и пароль и также создали 5 версий секрета. Нам достаточно просто переписать значения секретов в каждой из версий. Если количество версий не будет совпадать, то будет выполнена операция добавления или «сброса» значения, в зависимости от ситуации.
А теперь вернёмся к нашей первоначальной задаче из примера с федеральной компанией. Учитывая новый функционал репликации, мы можем построить следующую архитектуру системы:

Центральный офис выступает как единая точка актуальности данных, а все остальные отделения получают актуальные данные через механизм репликации. Например, в основном Vault центрального офиса можно создать secret_path с привязкой к определённому региону (r01, r23, r61 и так далее) и наполнить его значениями секретов. Чтобы не копировать в региональные отделения секреты других регионов, при настройке репликации можно задать фильтр на получение данных только из secret_path соответствующего региона. Для районных отделений соответствующие настройки можно задать через политики доступа.
Таким образом, со стороны источника данных мы можем ограничивать доступ, используя политики доступа, а со стороны потребителя задавать фильтр на получение определённых секретов.
Итоги и обратная связь
В версии Stronghold 1.15.0 появился механизм репликации KV1/KV2 по модели pull. С его помощью можно решать следующие задачи:
построение геораспределённых систем хранения секретов;
резервирование секретов;
горизонтальное масштабирование и увеличение пропускной способности операций доставки секретов;
построение системы централизованной доставки и обновления секретов;
возможность управлять доступом только к определённым секретам KV (аналог Namespaces Vault EE) посредством репликации этих секретов в отдельный Stronghold.
Хочется подчеркнуть, что это первая версия репликации. Мы планируем улучшать и расширять её, опираясь на обратную связь наших клиентов. Сейчас Stronghold доступен в составе Deckhouse Kubernetes Platform (под отдельной лицензией). Также мы активно ведём разработку standalone-поставки продукта, в которую будет включён функционал репликации.
Если у вас есть идеи или предложения по расширению функционала репликации KV1/KV2, буду рад обсудить их в комментариях к статье. Также приветствуются предложения и запросы реализации функционала, который нужен или будет полезен для вас как пользователей Stronghold.
P. S.
Другие материалы о Stronghold и безопасном хранении секретов:
Статья «Безопасная миграция данных из Vault одной командой».
Запись вебинара «Мы умеем хранить секреты».
