Рекомендовать нельзя спрятать
Привет, Хабр! Меня зовут Николай, и я занимаюсь построением и внедрением моделей машинного обучения в Сбербанке. Сегодня расскажу о разработке рекомендательной системы для платежей и переводов в приложении на ваших смартфонах.
У нас было 2 сотни тысяч возможных вариантов платежей, 55 миллионов клиентов, 5 различных банковских источников, полсолонки разработчиков и гора банковской активности, алгоритмов и всего такого, всех цветов, а ещё литр рандомных сидов, ящик гиперпараметров, пол-литра поправочных коэффициентов и две дюжины библиотек. Не то чтобы это всё было нужно в работе, но раз начал улучшать жизнь клиентов, то иди в своём увлечении до конца. Под катом история о сражении за UX, о правильной постановке задачи, о борьбе с размерностью данных, о вкладе в open-source и наших результатах.
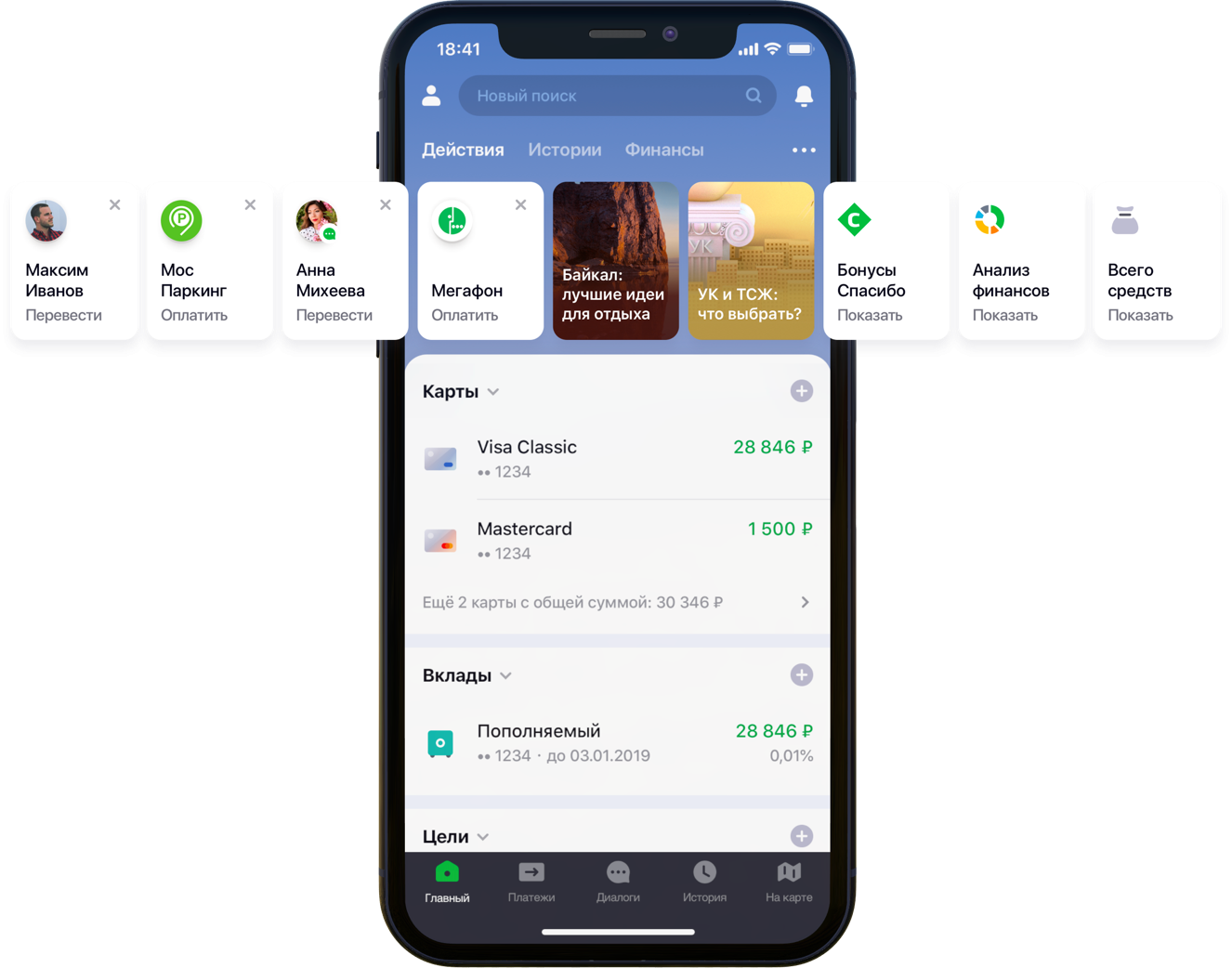
Дизайн главного экрана мобильного приложения с рекомендациями
Постановка задачи
По мере развития и масштабирования приложение Сбербанк Онлайн обрастает полезными возможностями и дополнительной функциональностью. В частности, в приложении можно переводить деньги или оплачивать услуги различных организаций.
«Мы внимательно посмотрели на все пользовательские пути внутри приложения и поняли, что многие из них можем существенно сократить. Для этого мы решили персонализировать главный экран в несколько этапов. Сначала постарались убрать с экрана то, чем клиент не пользуется, начав с банковских карт. Затем вынесли на передний план те действия, которые клиент уже совершал ранее и за которыми он мог зайти в приложение именно сейчас. Сейчас в список действий попадают платежи в пользу организаций и переводы контактам, потом список таких действий будет расширен», — отметил мой коллега Сергей Комаров, который занимается развитием функционала с точки зрения клиента в команде Сбербанк Онлайн. Необходимо построить модель, которая бы заполняла отведенные слоты в виджетах «Действия» (рисунок выше) персональными рекомендациями платежей и переводов вместо простых правил.
Решение
Мы в команде декомпозировали задачу на две части:
- рекомендация повторения операций по оплате услуг или переводу средств (блок «Рекомендуемые операции»)
- рекомендация примеров поисковых запросов оплаты услуг, ранее не использовавшихся этим клиентом (блок «Примеры поиска»)
Протестировать функциональность решили сначала на вкладке поиска:
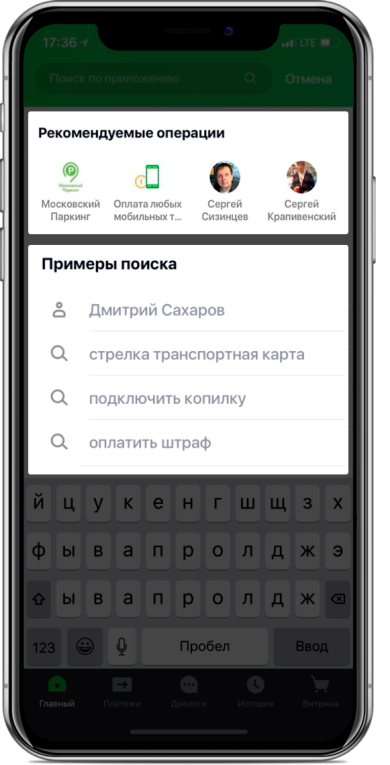
Дизайн экрана поиска с рекомендациями
Рекомендуемые операции
Оптимизация скоринга
Если мы ставим подзадачу в виде рекомендации повторения операций, это позволяет отвязаться от расчета и оценки триллионов комбинаций всех возможных операций по всем клиентам и сфокусироваться на гораздо более ограниченном их количестве. Если из всего множества доступных нашим клиентам операций гипотетический клиент с хэшем «YYY» пользовался только оплатой газа и парковки, то мы и будем оценивать вероятность повтора только этих операций для этого клиента:
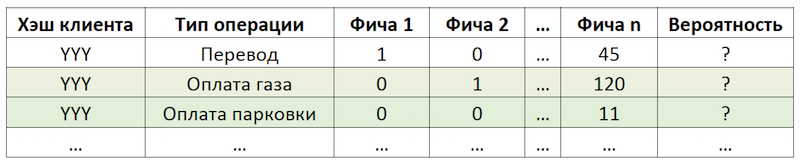
Пример сокращения размерности данных для скоринга
Подготовка датасета
Выборка представляет собой транзакционные наблюдения, обогащенные факторами клиентской демографии, финансовых агрегатов и различными частотными характеристиками конкретной операции.
Целевая переменная в данном случае бинарная и отражает факт события в день, следующий за днем расчета факторов. Таким образом, итеративно двигая день расчета факторов и простановки флага целевой переменной, мы одни и те же операции размножаем и маркируем по-разному в зависимости от положения относительно этого дня.

Схема формирования наблюдений
Рассчитывая срез на 17.03.2019 для клиента «YYY», мы получаем два наблюдения:

Пример полученных наблюдений для датасета
«Фича 1» может означать, например, баланс на всех картах клиента, «Фича 2» — наличие такого типа операции за последнюю неделю.
Возьмем те же транзакции, но сформируем наблюдения для обучения на другую дату:

Схема формирования наблюдений
Мы получим наблюдения для датасета с другими значениями как фичей, так и целевой переменной:

Пример полученных наблюдений для датасета
В примерах выше для наглядности приведены фактические значения факторов, но на самом деле значения предобрабатываются автоматическим алгоритмом: на вход модели подаются результаты WOE-преобразования. Оно позволяет приводить переменные к монотонной взаимосвязи с целевой переменной и одновременно избавляться от влияния выбросов. Например, у нас есть фактор «Количество карт» и какое-то распределение целевой переменной:

Пример WOE-преобразования
WOE-преобразование позволяет нам трансформировать нелинейную зависимость в как минимум монотонную. Каждому значению анализируемого фактора сопоставляется своё значение WOE и таким образом формируется новый фактор, а оригинальный убирается из датасета:

Влияние WOE-преобразования на взаимосвязь с целевой переменной
Словарь преобразования значений переменных в WOE сохраняется и используется в дальнейшем при скоринге. То есть если нам нужно рассчитать вероятности на завтра, мы формируем датасет как в таблицах с примерами наблюдений выше, преобразуем нужные переменные в WOE сохраненным кодом и применяем на этих данных модель.
Обучение
На выбор метода было наложено строгое ограничение — интерпретируемость. Поэтому для соблюдения сроков было решено объяснения с помощью того же SHAP отложить на вторую половину задачи и протестировать относительно простые методы: регрессию и неглубокие нейронки. Инструментом послужил SAS Miner — ПО для предобработки, анализа и построения моделей на различных данных в интерактивной форме, позволяющее сильно экономить время на написании кода.

Интерфейс SAS Miner
Оценка качества
Результаты сравнения по метрике GINI на out-of-time выборке показали, что нейронная сеть справляется с задачей лучше всего: 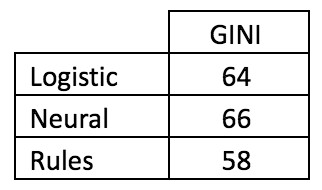
Сравнительная таблица качества моделей и частотных правил
Точек выхода у модели две. В рекомендации в виде карточек-виджетов на главном экране попадают операции, прогноз по которым выше определённого порога (см. первую картинку в посте). Граница выбрана исходя из баланса качества и покрытия, которое в такой архитектуре составляет половину от всех совершаемых операций. В блок «рекомендуемых операций» экрана поиска отправляется топ-4 операций (см. вторую картинку).
Примеры поиска
Переходя ко второй части задачи, мы возвращаемся к проблеме огромного количества возможных вариантов платежей за услуги провайдеров, которые нужно оценивать и сортировать в рамках каждого клиента — триллионы пар. В дополнение к этому у нас implicit данные, то есть нет как информации об оценке совершенных платежей, так и о том, почему клиент не совершал каких-то платежей. Поэтому для начала было решено проверить различные методы разложения матрицы платежей клиентов провайдерам: ALS и FM.
ALS
ALS (Alternating Least Squares) или Чередующиеся Наименьшие Квадраты — в коллаборативной фильтрации один из методов решения задачи факторизации матрицы взаимодействий. Представим наши транзакционные данные оплат услуг в виде матрицы, в которой столбцы — это уникальные идентификаторы всех услуг провайдеров, а строки — уникальные клиенты. В ячейках расположим количество операций конкретных клиентов у конкретных провайдеров за определенный промежуток времени:

Принцип матричного разложения
Смысл метода заключается в том, что мы создаем две таких матрицы меньшей размерности, перемножение которых дает максимально близкий результат к оригинальной большой матрице в заполненных ячейках. Модель учится создавать скрытое факторное описание для клиентов и для провайдеров. Была использована реализация метода в библиотеке implicit. Обучение происходит по следующему алгоритму:
- Инициализируются матрицы клиентов и провайдеров со скрытыми факторами. Их число — гиперпараметр модели.
- Фиксируется матрица скрытых факторов провайдеров и считается производная функции потерь для коррекции матрицы клиентов. Автор использовал интересный метод сопряженных градиентов, который позволяет сильно ускорить этот шаг.
- Предыдущий шаг повторяется аналогично для матрицы скрытых факторов клиентов.
- Шаги 2–3 чередуются, пока алгоритм не сойдется.
Подготовка
Транзакционные данные были преобразованы в матрицу взаимодействий со степенью разреженности ~99% с большой неравномерностью по провайдерам. Для разделения данных на train и validation выборки мы случайным образом маскировали долю заполненных ячеек:
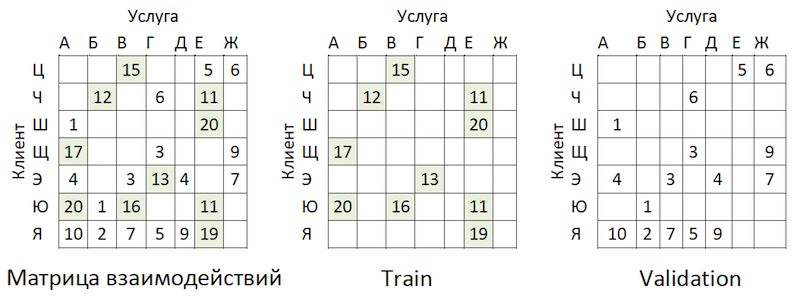
Пример разделения данных
В качестве test были взяты транзакции за временной промежуток, следующий за обучением, и уложены в матрицу такого же формата — получился out-of-time.
Обучение
У модели есть несколько гиперпараметров, которые можно корректировать для улучшения качества:
- Alpha — коэффициент, на который взвешивается матрица, корректируя степень уверенности (C_iu) в том, что данная услуга провайдера действительно «нравится» клиенту.
- Количество факторов в скрытых матрицах клиентов и провайдеров — количество столбцов и строк соответственно.
- Коэффициент L2 регуляризации λ.
- Количество итераций метода.
Мы использовали библиотеку hyperopt, которая позволяет проводить оценку влияния гиперпараметров на метрику качества методом TPE и подбирать их оптимальное значение. Алгоритм начинает с холодного старта и делает несколько оценок метрики качества в зависимости от значений анализируемых гиперпараметров. Затем по сути пытается подобрать такой набор значений гиперпараметров, который с большей вероятностью даст хорошее значение метрики качества. Результаты сохраняются в словарь, из которого можно построить график и визуально оценить результат работы оптимизатора (синее — лучше): 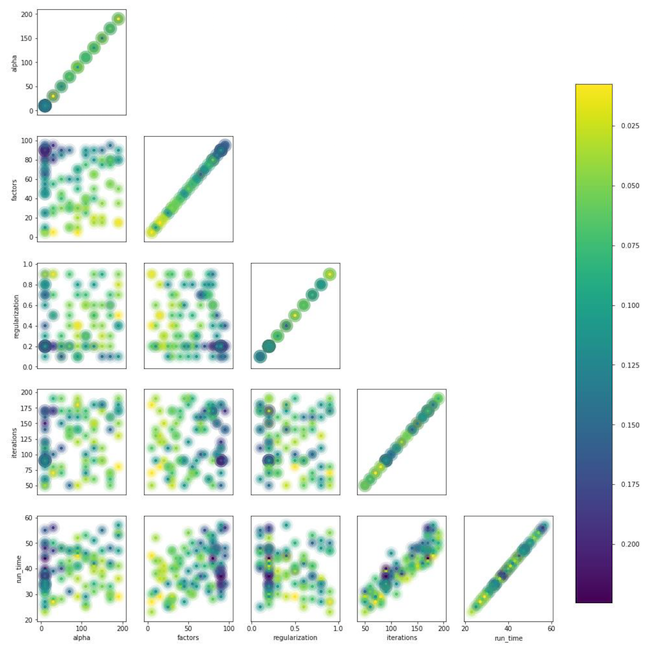
График зависимости метрики качества от комбинации гиперпараметров
Из графика видно, что значения гиперпараметров сильно влияют на качество модели. Так как на вход метода необходимо подать диапазоны по каждому из них, по графику можно дополнительно определить, есть ли смысл расширять пространство значений или нет. Например, в нашей задаче видно, что есть смысл протестировать большие значения для количества факторов. В дальнейшем это действительно улучшило модель.
Метрика и сложность оценки качества
Как же оценивать качество модели? Одной из наиболее часто используемых метрик для рекомендательных систем, где важен порядок, является MAP@k или Mean Average Precision at K. Эта метрика оценивает точность модели на K рекомендациях с учетом порядка элементов в списке этих рекомендаций в среднем по всем клиентам.
К сожалению, операция по оценке качества даже на сэмпле занимала несколько часов. Закатав рукава, мы начали профилировать функцию mean_average_pecision_at_k () библиотекой line_profiler. Задачу дополнительно усложняло то, что в функции использовался cython код и нужно было корректно это учитывать, иначе просто не собиралась нужная статистика. В итоге мы снова столкнулись с проблемой размерности наших данных. Для расчета этой метрики нужно получить некие оценки каждой услуги из всех возможных для каждого клиента и подобрать топ-K персональных рекомендаций сортировкой из получившегося массива. Даже учитывая использование частичной сортировки numpy.argpartition () со сложностью O (n), сортировка оценок оказалась самым долгим шагом, растягивающим оценку качества на часы. Так как numpy.argpartition () не использовало все ядра нашего сервера, было решено улучшить алгоритм, переписав эту часть на C++ и OpenMP через cython. Кратко новый алгоритм выглядит следующим образом:
- Данные нарезаются на батчи по клиентам.
- Инициализируется пустая матрица и указатели на память.
- Строки батчей по указателям сортируются в два захода: функцией partial_sort и затем sort библиотеки algorithm на C++.
- Результаты записываются в ячейки пустой матрицы в параллельном режиме.
- Данные возвращаются в python.
Это позволило ускорить расчёт рекомендаций в несколько раз. Доработка добавлена в официальный репозиторий.
Анализ результатов на OOT
А теперь пришло время оценить качество модели. Зачем нам нужна Out-Of-Time выборка? Если мы посмотрим на распределение операций по провайдерам, то увидим такую картину:
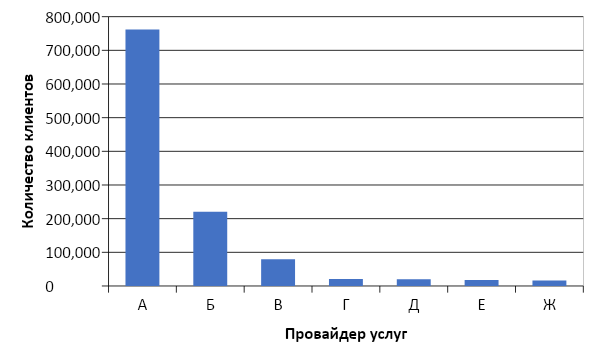
Распределение популярности услуг провайдеров
Налицо несбалансированность. Это приводит к тому, что модель старается рекомендовать популярные услуги. Вернёмся к рисунку выше: 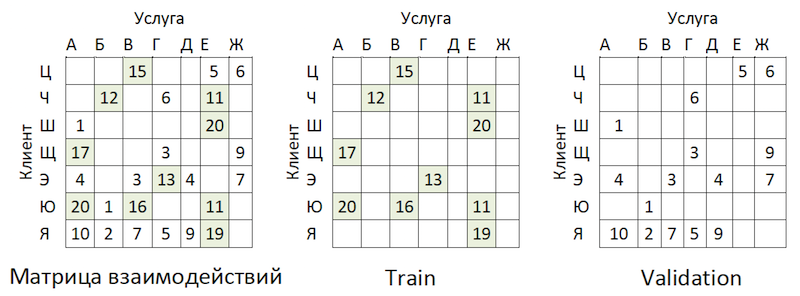
Проблема в том, что если проверять точность модели маскированием одной и той же матрицы, как почти везде советуют, то для большинства клиентов (предельные примеры: «Ш», «Э» и «Я») качество прогнозов на валидации (сделаем вид, что она не участвовала в подборе гиперпараметров) будет высоким, если это будут самые популярные провайдеры. В результате мы получим ложную уверенность в силе модели. Поэтому мы поступили следующим образом:
- Сформировали оценки провайдеров по модели.
- Исключили из оценок (см. рисунок ниже) и OOT-матриц существующие пары «клиент-услуга».
- Сформировали из оставшихся оценок топ-K рекомендаций и оценили MAP@k на оставшемся OOT.

Логика подготовки матрицы для формирования прогнозов
В качестве бейзлайна собрали список провайдеров, упорядоченный по популярности, и размножили на всех клиентов, опять же исключив существующие пары «клиент-услуга». Получилось грустно и совсем не то, что мы ожидали и видели на train\validation выборках:

Сравнительная таблица качества модели и бейзлайна
Стоп! У нас же есть клиентские факторы и параметры провайдеров. Достаем факторизационные машины.
FM
Factorization machines (факторизационная машина) — алгоритм обучения с учителем, разработанный для нахождения взаимосвязей между факторами, описывающими взаимодействующие сущности, которые представлены в виде разреженных матриц. Мы использовали реализацию FM из библиотеки LightFM.
Формат данных
В дополнение к нормированной матрице взаимодействий метод использует два дополнительных датасета с факторами по клиентам и по услугам провайдеров в виде one-hot-encoded матриц, соединенных с единичными:

Логика подготовки матрицы для формирования прогнозов
Оценка качества
Качество модели FM на наших данных оказалось ниже ALS:

Сравнительная таблица качества моделей и бейзлайна
Изменение архитектуры модели — Boosting
Было решено зайти с другой стороны. Вспоминая распределение популярности услуг, мы выделили из них 300 штук, транзакции по которым покрывают 80% всех операций, и натренировали на них классификатор. Здесь данные представляют собой агрегаты транзакций клиентов, обогащенные клиентскими фичами:
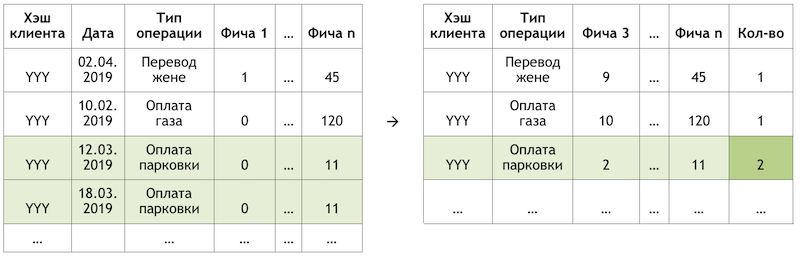
Схема агрегации транзакций
Почему только клиентскими, спросите вы? Потому что в таком случае для подготовки рекомендаций нам будет достаточно иметь одну строчку на клиента. Применив к ней модель, мы получим на выходе вектор вероятностей для всех классов, из которого легко выбрать топ-К рекомендаций. Если же мы добавим в обучающую выборку фичи услуг провайдеров, то на этапе применения модели мы будем вынуждены либо на каждого клиента подготовить по 300 строк — по одной на каждую услугу провайдера с фичами, описывающими их, либо построить ещё одну модель для предсортировки кандидатов на скоринг.
Добавление фичей по клиентам из ALS не дало прирост на наших данных, так как мы уже учитывали транзакционную активность — например, в разрезах MCC или категорий в стиле «геймер» или «театрал». В таком формате нам удалось получить хорошие результаты: 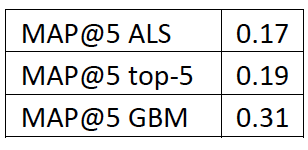
Сравнительная таблица качества моделей и бейзлайна
Региональный фильтр
Несмотря на высокое качество модели, в данном подходе остаётся ещё одна проблема. Так как архитектура данных и модели не предполагает использование фичей услуг провайдеров, модель не полностью учитывает географию и может рекомендовать людям оплатить услугу локального провайдера из другого региона. Чтобы минимизировать такой риск, мы разработали небольшой фильтр для предварительной отсечки вариантов перед выводом в рекомендации. На алгоритм накинут легкий флер рекурсии:
- Собираем информацию о регионе клиента из банковских анкет и других внутренних источников.
- Выделяем для каждого провайдера основные регионы присутствия.
- Уточняем/заполняем информацию о регионе клиента по регионам провайдеров, которыми он пользуется.
После этих манипуляций с помощью индекса Херфиндаля отделяем региональных провайдеров, которые представлены в ограниченном наборе регионов, от федеральных:

Разделение провайдеров по присутствию в регионах
Формируем маску с допустимыми региональными провайдерами для клиентов и исключаем из предсказаний модели лишнее перед формированием списка рекомендаций.
Заключение
Мы разработали две модели, которые вместе формируют полный набор рекомендаций по платежам и переводам. Удалось сократить клиентский путь для половины повторяющихся операций до одного клика. В дальнейших планах улучшить модель «рекомендуемых операций» с помощью данных обратной связи (карточки можно скрывать и т.д.), что позволит снизить порог отбора рекомендаций и увеличить охват. Также планируется расширить охват рекомендуемых платежей в модели «примеров поиска» и разработать для нее алгоритм оптимизации скоринга.
Мы прошли тернистый путь построения рекомендательной системы платежей и переводов. По дороге набили шишек и получили опыт декомпозиции и упрощения подобных задач, правильной оценки таких систем, применимости методов, оптимальной работы с большими объемами данных и значительно расширили своё понимание специфики таких задач. Попутно удалось внести вклад в open-source, которым сами пользуемся. Желаю вам интересных задач, реалистичных бейзлайнов и единичных F1. Спасибо за внимание!
