RBKmoney Payments под капотом — микросервисы, протоколы и конфигурация платформы
Привет Хабр! RBKmoney снова выходит на связь и продолжает цикл статей о том, как написать платежный процессинг своими руками.

Хотелось сразу погрузиться подробности описания реализации платежного бизнес-процесса как конечного автомата, показать примеры такого автомата с набором событий, особенности реализации… Но, похоже, без еще пары-тройки обзорных статей не обойтись. Уж слишком велика оказалась предметная область. В этом посте будут раскрыты нюансы работы и взаимодействия между микросервисами нашей платформы, взаимодействие с внешними системами и то, как мы управляем бизнес-конфигурацией.
Макросервис
Наша система состоит из множества микросервисов, которые, реализуя каждый свою законченную часть бизнес-логики, взаимодействуют друг с другом и вместе образуют макросервис. Собственно, развернутый в дата-центре макросервис, подключенный к банкам и другим платежным системам — это и есть наш платежный процессинг.
Шаблон микросервиса
Мы пользуемся единым подходом к разработке любого микросервиса на каком бы языке он не был написан. Каждый микросервис представляет из себя Docker-контейнер, который содержит:
- само приложение, реализующее бизнес-логику, написанное на Erlang или Java;
- RPClib — библиотека, реализующая коммуникацию между микросервисами;
- мы используем Apache Thrift, его основные преимущества — готовые клиент-серверные библиотеки и возможность строго типизированного описания всех публичных методов, которые отдает каждый микросервис;
- вторая особенность библиотеки — это наша реализация Google Dapper, которая позволяет нам возможность быстрой трассировки запросов простым поиском в Elasticsearch. Первый микросервис, получивший запрос от внешней системы генерирует уникальный
trace_id, который сохраняется каждым следующим по цепочке запросов. Также, мы генерируем и сохраняемparent_idиspan_id, что позволяет построить дерево запросов, визуально контролируя всю цепочку микросервисов, участвующих в обработке запроса; - третья особенность — активно используем передачу на транспортном уровне разной информации о контексте запроса. Например, дедлайны (устанавливаемый на клиенте ожидаемый срок жизни запроса), или от чьего имени мы выполняем вызов того или иного метода;
- Consul template — агент service discovery, который поддерживает информацию о расположении, доступности и состоянии микросервиса. Друг-друга микросервисы находят по DNS-именам, TTL зоны нулевое, умерший или не прошедший healthcheck сервис перестает резолвиться и таким образом получать трафик;
- логи, которые пишет приложение в понятном для Elasticsearch формате в локальный файл контейнера и
filebeat, который запущен на хостовой по отношению к контейнеру машине, подхватывает эти логи и отправляет их в кластер Elasticsearch;- поскольку мы реализовываем платформу по Event Sourcing модели, полученные цепочки логов также используются для визуализации в виде разных Grafana-дашбордов, что позволяет уменьшить время на реализацию разных метрик (отдельные метрики мы, впрочем, также используем).

При разработке микросервисов мы используем специально придуманные нами ограничения, призванные решить задачу как высокой доступности платформы, так и ее отказоустойчивости:
- строгие лимиты памяти для каждого контейнера, при выходе за лимиты — ООМ, большинство микросервисов живут в рамках 256–512М. Это заставляет более мелко дробить реализацию бизнес-логики, предохраняет от дрейфа в сторону монолита, уменьшает стоимость точки отказа, дополнительным плюсом дает возможность работать на дешевом железе (платформа развернута и работает на недорогих одно-двухпроцессорных серверах);
- как можно меньшее количество stateful-микросервисов и как можно большее количество stateless-реализаций. Это позволяет решать задачи отказоустойчивости, скорости восстановления и вообще, минимизации мест с потенциально непонятным поведением. Особенно это становится важно с увеличением срока эксплуатации системы, когда накапливается большое легаси;
- подходы let it crash и «это обязательно сломается». Мы знаем, что любая часть нашей системы обязательно выйдет из строя, поэтому проектируем так, чтобы это не сказалось на общей корректности информации, накопленной в платформе. Помогает минимизировать количество неопределенных состояний в системе.
Наверняка знакомая многим, кто интегрируется с третьими сторонами ситуация. На запрос о списании денег мы ожидали ответ от третьей стороны согласно протоколу, а пришел совершенно другой ответ, не описанный ни в какой спецификации, который неизвестно как интерпретировать.
Мы в такой ситуации убиваем конечный автомат, обслуживающий данный платеж, любые действия над ним снаружи будут получать ошибку 500. А внутри мы выясняем текущее состояние платежа, приводим состояние автомата в соответствие с действительностью и оживляем конечный автомат.
Protocol Oriented Development

На момент написания статьи в нашем Service Discovery зарегистрировано 636 различных проверок для сервисов, обеспечивающих функционирование платформы. Даже если учесть, что на один сервис идет несколько проверок, а также, что большинство stateless-сервисов работает как минимум в тройном экземпляре, то все равно получается под полсотни приложений, которые надо уметь как-то связать друг с другом и при этом не провалиться в RPC-ад.
Ситуация осложняется тем, что у нас в стеке три языка разработки — Erlang, Java, JS и им всем нужно уметь прозрачно между собой общаться.
Первая задача, которую нужно было решить — это спроектировать правильную архитектуру обмена данными между микросервисами. За основу мы взяли Apache Thrift. Все микросервисы обмениваются трифтовыми бинарниками, в качестве транспорта используем HTTP.
Трифтовые спецификации размещаем в виде отдельных репозиториев в нашем гитхабе, поэтому они доступны любому разработчику, имеющему к ним доступ. Изначально использовали один общий репозиторий для всех протоколов, но со временем пришли к тому, что это неудобно — совместная параллельная работа над протоколами превратилась в постоянную головную боль. Разные команды и даже разные разработчики вынуждены были договариваться о наименовании переменных, попытка разделения на namespace-ы также не помогла.
В целом, можно сказать, что у нас protocol-driven разработка. Перед началом любой реализации мы вырабатываем будущий протокол микросервиса в виде трифт-спецификации, проходим 7 кругов ревью, привлекая будущих клиентов этого микросервиса, и получаем возможность одновременного старта разработки нескольких микросервисов параллельно, ведь мы знаем все его будущие методы и уже можем писать их обработчики, опционально используя моки.
Отдельным шагом в процессе разработки протокола идет security-review, где ребята смотрят со своей, пентестерской точки зрения на нюансы разрабатываемой спецификации.
Также мы сочли целесообразным выделить отдельную роль владельца протоколов в команде. Задача сложная, человеку приходится держать в голове специфику работы всех микросервисов, но она окупается большим порядком и наличием единой точки эскалации.
Без финального одобрения pull request этими сотрудниками протокол не может быть объединен в мастер-ветку. В гитхабе для этого есть очень удобная функциональность — codeowners, пользуемся ей с удовольствием.
Таким образом мы решили проблему общения между микросервисами, возможных проблем непонимания, что за микросервис появился в платформе, и для чего он нужен. Этот набор протоколов, пожалуй, единственная часть платформы, где мы безусловно выбираем качество против стоимости и скорости разработки, ведь реализацию одного микросервиса переписать можно относительно безболезненно, а протокол, на котором завязано несколько десятков — уже дорого и больно.
Попутно аккуратное ведение протоколов помогает в решении задачи документирования. Разумно подобранные названия методов и параметров, немного комментариев, и самодокументированная спецификация экономит кучу времени!
Для примера так выглядит спецификация метода одного из наших микросервисов, позволяющего получить список событий, произошедших в платформе:
/** Идентификатор некоторого события */
typedef i64 EventID
/* Event sink service definitions */
service EventSink {
/**
* Получить последовательный набор событий из истории системы, от более
* ранних к более поздним, из диапазона, заданного `range`. Результат
* выполнения запроса может содержать от `0` до `range.limit` событий.
*
* Если в `range.after` указан идентификатор неизвестного события, то есть
* события, не наблюдаемого клиентом ранее в известной ему истории,
* бросится исключение `EventNotFound`.
*/
Events GetEvents (1: EventRange range)
throws (1: EventNotFound ex1, 2: base.InvalidRequest ex2)
/**
* Получить идентификатор наиболее позднего известного на момент исполнения
* запроса события.
*/
base.EventID GetLastEventID ()
throws (1: NoLastEvent ex1)
}
/* Events */
typedef list Events
/**
* Событие, атомарный фрагмент истории бизнес-объекта, например инвойса.
*/
struct Event {
/**
* Идентификатор события.
* Монотонно возрастающее целочисленное значение, таким образом на множестве
* событий задаётся отношение полного порядка (total order).
*/
1: required base.EventID id
/**
* Время создания события.
*/
2: required base.Timestamp created_at
/**
* Идентификатор бизнес-объекта, источника события.
*/
3: required EventSource source
/**
* Содержание события, состоящее из списка (возможно пустого)
* изменений состояния бизнес-объекта, источника события.
*/
4: required EventPayload payload
/**
* Идентификатор события в рамках одной машины.
* Монотонно возрастающее целочисленное значение.
*/
5: optional base.SequenceID sequence
}
// Exceptions
exception EventNotFound {}
exception NoLastEvent {}
/**
* Исключение, сигнализирующее о непригодных с точки зрения бизнес-логики входных данных
*/
exception InvalidRequest {
/** Список пригодных для восприятия человеком ошибок во входных данных */
1: required list errors
}
Thrift console client
Иногда перед нами стоят задачи вызова тех или иных методов нужного микросервиса напрямую, например, руками из терминала. Это бывает полезно для отладки, получения какого-то набора данных в сыром виде или в том случае, когда задача настолько редка, что разработка отдельного пользовательского интерфейса нецелесообразна.
Поэтому мы разработали для себя инструмент, совмещающий в себе функции curl, но позволяющего делать трифт-запросы в виде JSON-структур. Назвали мы его соответственно — woorl. Утилита универсальная, в нее достаточно параметром командной строки передать расположение любой трифт-спецификации, остальное она сделает сама. Очень удобная утилита, можно прямо из терминала запустить платеж, например.
Так выглядит обращение напрямую в микросервис платформы, отвечающий за управление заявками (например, на создание магазина). Я запросил данные по своей тестовой учетной записи:

Наблюдательные читатели наверняка заметили одну особенность на скриншоте. Нам тоже это не нравится. Надо прикручивать авторизацию трифтовых вызовов между микросервисами, надо по-хорошему TLS туда запилить. Но пока ресурсов, как всегда, не хватает. Ограничились тотальным огораживанием периметра, в котором живут процессинговые микросервисы.
Протоколы общения с внешними системами
Опубликовать наружу трифт-спецификации и заставить наших мерчантов общаться по бинарному протоколу мы посчитали слишком жестоким по отношению к ним. Нужно было выбрать человекочитаемый протокол, который бы позволил удобно интегрироваться с нами, проводить дебаг и иметь возможность удобного документирования. Мы выбрали стандарт Open API, также известный как Swagger.
Возвращаясь к проблеме документирования протоколов, Swagger позволяет довольно быстро и дешево решить эту задачу. В сети есть много реализаций красивого оформления Swagger-спецификации в виде документации разработчика. Мы просмотрели все что смогли найти и в итоге выбрали ReDoc, JS-библиотеку, которая принимает на вход swagger.json, а на выходе генерирует вот такую трехколоночную документацию: https://developer.rbk.money/api/.
Подходы в разработке обоих протоколов, внутреннего Thrift и внешнего Swagger у нас абсолютно идентичны. Это добавляет времени к разработке, но окупается на долговременном периоде.
Также нам нужно было решить еще одну важную задачу — мы не только принимаем запросы на списание денег, но и отправляем их дальше — в банки и платежные системы.
Заставить их реализовать наш трифт было бы еще более неосуществимой задачей, чем отдать это на публичные API.
Поэтому, мы придумали и реализовали концепцию адаптеров протоколов. Это просто еще один микросервис, который одной своей стороной реализует нашу внутреннюю трифт-спецификацию, которая едина для всей платформы, а второй — специфичный для конкретного банка или ПС внешний протокол.
Проблемы, возникающие при написании подобных адаптеров, когда приходится взаимодействовать с третьими сторонами — очень богатая на разные истории тема. В своей практике мы встречали разное, ответы вида: «вы, конечно, можете реализовать эту функцию так, как описано в протоколе, который мы вам дали, но я никаких гарантий не даю. Вот выйдет с больничного через 2 недели наш человек, который за все это отвечает, и вы у него подтверждения попросите». Также, нередки подобные ситуации: «вот вам логин и пароль от нашего сервера, зайдите туда и сами все настройте».
Особенно интересным мне кажется случай, когда мы интегрировались с платежным партнером, который, в свою очередь, до этого интегрировался с нашей платформой и успешно проводил через нас платежи (такое нередко бывает, бизнес-специфика платежной отрасли). На наш запрос о предоставлении тестовой среды партнер ответил, что как таковой тестовой среды у него нет, но он может зароутить трафик на интеграцию с РБК, то есть с нашей платформой, где мы и сможем затеститься. Вот так мы через партнера интегрировались сами с собой однажды.
Таким образом мы достаточно просто решили проблему реализации массового параллельного подключения различных платежных систем и прочих третьих сторон. В абсолютном большинстве случаев для этого не нужно трогать код платформы, достаточно просто написать адаптеры и добавить в enum-ы еще платежных инструментов.
В итоге у нас получилась такая схема работы — наружу у нас смотрят микросервисы RBKmoney API (мы называем их Common API, или capi*, это их вы видели в консуле выше), которые валидируют входные данные согласно публичной Swagger-спецификации, авторизуют клиентов, транслируют эти методы в наши внутренние трифт-вызовы и отправляют запросы дальше по цепочке следующему микросервису. Кроме того, эти сервисы реализуют еще одно требование к платформе, ТЗ которого было сформулировано как: «в системе всегда должна быть реализована возможность получить котика.»
Когда нам нужно сделать вызов какой-то внешней системы, внутренние микросервисы дергают трифт-методы соответствующего адаптера протоколов, те переводят их на язык специфичного банка или платежной системы и отправляют их наружу.
Трудности обратной совместимости протоколов
Платформа постоянно развивается, добавляются новые функции, изменяются старые. В таких условиях нужно либо вкладываться в поддержку обратной совместимости, либо постоянно обновлять зависимые микросервисы. И если ситуация, когда required поле превращается в optional все просто, можно вообще ничего не делать, то в обратном случае приходится затратить дополнительные ресурсы.
С набором внутренних протоколов все проходит легче. Платежная отрасль редко изменяется настолько, чтобы появились какие-то принципиально новые методы взаимодействия. Возьмем, например, частую для нас задачу — подключение нового провайдера с новым платежным средством. Например, локальный кошелечный процессинг, который позволяет процессить платежи на территории Казахстана в тенге. Это новый для нашей платформы кошелек, но принципиально от того же Qiwi-кошелька он ничем не отличается — у него обязательно есть какой-то уникальный идентификатор и методы, позволяющие списать/отменить списание средств с него.
Соответственно, наша трифт-спецификация для всех кошелечных провайдеров выглядит так:
typedef string DigitalWalletID
struct DigitalWallet {
1: required DigitalWalletProvider provider
2: required DigitalWalletID id
}
enum DigitalWalletProvider {
qiwi
rbkmoney
}
а добавление нового платежного средства в виде нового кошелька просто дополняет enum:
enum DigitalWalletProvider {
qiwi
rbkmoney
newwallet
}
Теперь остается бампануть все использующие данную спецификацию микросервисы, синхронизировавшись с мастером репозитория со спецификацией и выкатить их через CI/CD.
С внешними протоколами сложнее. Каждое обновление Swagger-спецификации, особенно без обратной совместимости практически нереально применить в разумные сроки — маловероятно, что наши партнеры держат свободные ресурсы разработчиков специально под обновления нашей платформы.
А иногда это просто невозможно, мы периодически сталкиваемся с ситуациями вида: «нам программист написал магазин и ушел, исходники забрал с собой, как это работает мы не знаем, работает и не трогаем».
Поэтому мы вкладываемся в поддержку обратной совместимости на внешних протоколах. В нашей архитектуре это сделать немного легче — поскольку мы используем отдельные адаптеры протоколов для каждой конкретной версии Common API, мы просто оставляем старые микросервисы capi работать, по необходимости меняя только ту часть, которая смотрит трифтом внутрь платформы. Так появляются и навсегда остаются с нами микросервисы capi-v1, capi-v2, capi-v3 и так далее.
Что будет когда появится capi-v33 посмотрим, придется deprecate-ить какие-то старые версии, наверное.
В этом месте я обычно начинаю очень хорошо понимать такие компании как Майкрософт и всю их боль по поддержке обратной совместимости решений, работающих десятилетиями.
Настраиваем систему
И, заканчивая тему, расскажем, как у нас устроено управление бизнес-специфичными настройками платформы.
Просто провести платеж — не так просто, как может показаться. К каждому платежу бизнес-заказчик хочет прицепить огромное количество условий — от комиссии до в принципе возможности успешного проведения в зависимости от времени суток. Мы ставили перед собой задачу оцифровать весь набор условий, который может придумать бизнес-заказчик сейчас и в будущем и применять этот набор к каждому вновь запускаемому платежу.
В итоге остановились на разработке своего DSL, к которому прикрутили инструменты для удобного управления, позволяющие нужным нам образом описывать бизнес-модель: выбор адаптеров протоколов, описание плана проводок, согласно которому деньги будут раскиданы по счетам внутри системы, настройка лимитов, комиссий, категорий и прочих, специфичных для платежной системы вещей.
Например, когда мы хотим взять комиссию 1% за эквайринг по картам маэстро и МС и раскидать ее по счетам внутри системы, мы конфигурируем домен так:
{
"cash_flow": {
"decisions": [
{
"if_": {
"any_of": [
{
"condition": {
"payment_tool": {
"bank_card": {
"definition": {
"payment_system_is": "maestro"
}
}
}
}
},
{
"condition": {
"payment_tool": {
"bank_card": {
"definition": {
"payment_system_is": "mastercard"
}
}
}
}
}
]
},
"then_": {
"value": [
{
"source": {
"system": "settlement"
},
"destination": {
"provider": "settlement"
},
"volume": {
"share": {
"parts": {
"p": 1,
"q": 100
},
"of": "operation_amount"
}
},
"details": "1% processing fee"
}
]
}
}
]
}
}
Упрощено говоря, у нас в одном месте собраны все настройки платформы, или конфигурация домена. Они хранятся в бинарном формате, но для удобства визуализации у нас есть инструменты представления его в виде JSON. Конфигурацией управляет отдельный микросервис, который решает задачи валидации, хранения и отдачи данных, управяет ревизиями. При каждом изменении конфигурации сохраняется полный набор данных, не дифф, и генерируется следующий номер ревизии. В принципе, классический CVS/SVN-подход.
Ревизии решают задачу «поменяли настройки комиссий и теперь никто не понимает почему прибыль в прошлом пересчиталась под новые условия». Например, платеж, запущенный с одной конфигурацией системы, например с комиссией в 1%, ссылается на ревизию, привязанную к тому моменту, когда платеж был запущен. А при изменении конфигурации, все следующие платежи ссылаются уже следующий номер ревизии, содержащей новые условия. В любой момент времени мы можем посмотреть и сказать, по каким условиям работала платформа при проведении конкретного платежа.
Использование cvs-like при реализации подобных сервисов подхода чревато непредвиденными проблемами, одна из которых с нами и приключилась. Нюанс работы сервиса, который заведует конфигурацией — он stateless, соответственно, для того чтобы предоставить последнюю версию конфигурации ему нужно последовательно вычитать и применить все коммиты. Все работало нормально пока количество изменений конфигурации было небольшим. Около полутысячи коммитов вычитывались с нуля и переваривались нормально.
В один прекрасный день где-то шестисотый коммит оказался последней соломинкой. Сервис просто перестал влезать в таймаут вычитки всех коммитов из персистентного хранилища, и мы остались без конфигурации домена, соответственно без платежей. День резко перестал быть прекрасным, особенно неприятно было то, что никаких выкаток в то время не проводилось и на первый взгляд платформа просто безо всяких причин перестала работать.
Тогда найти и быстро пофиксить увеличением таймаутов и памяти контейнеру проблему заняло примерно час. После этого вдумчиво запиливали снепшотинг, теперь каждые 10 коммитов сохраняется снепшот, а также библиотеку кеширующего клиента, которая периодически поллит сервис и сохраняет у себя конфигурацию в кэш.
Поскольку микросервис управления конфигурацией домена, также, как и все остальные, доступен по трифт-интерфейсу, им можно управлять с помощью нашего woorl-а. Но сотрудники поддержки почему-то были не слишком впечатлены перспективой постоянной правки JSON-ов в консоли. Поэтому мы разработали веб-интерфейс на JS, который также обращается к микросервисам по трифту, но имеет несравненно более приятный UX:
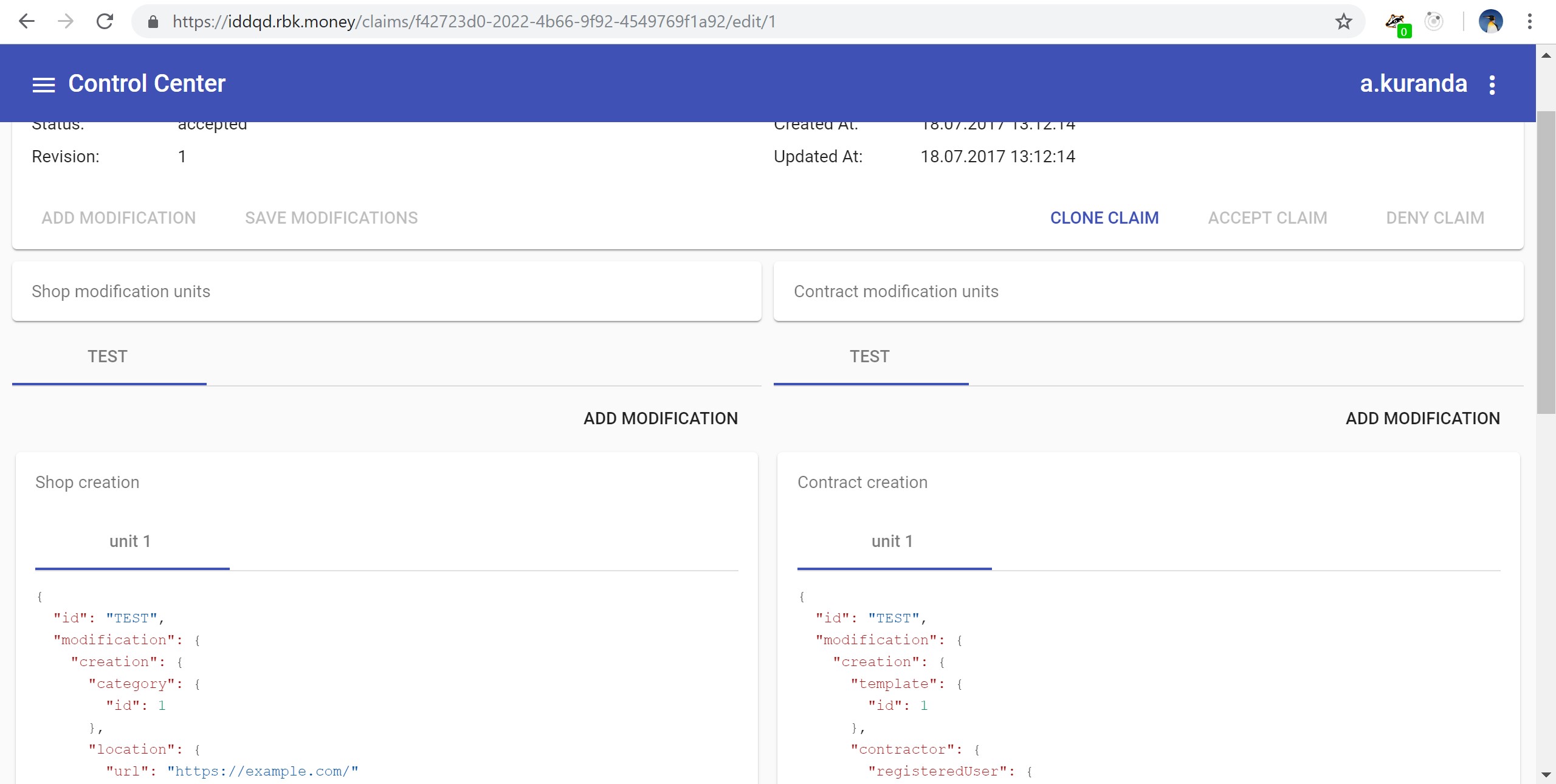
Таким образом мы решили для себя задачу удобного управления конфигурацией системы, у нас есть микросервис, предоставляющий возможность коммита и чекаута изменений нужной версии конфигурации, а каждый платеж ссылается на специфичный для него набор условий.
На этом про околопротокольную тему, пожалуй, все.
В следующей статье планирую описать логическую схему макросервиса, взаимосвязи между микросервисами и то, как эта система управляется с помощью SaltStack.
Спасибо, что были с нами!
